
Abstract
Background
Large language models (LLMs) have many clinical applications. However, the comparative performance of different LLMs on orthopedic board style questions remains largely unknown.
Methods
Three LLMs, OpenAI’s GPT-4 and GPT-3.5, and Google Bard, were tested on 189 official 2022 Orthopedic In-Training Examination (OITE) questions. Comparative analyses were conducted to assess their performance against orthopedic resident scores and on higher-order, image-associated, and subject category-specific questions.
Results
GPT-4 surpassed the passing threshold for the 2022 OITE, performing at the level of PGY-3 to PGY-5 (p = .149, p = .502, and p = .818, respectively) and outperforming GPT-3.5 and Bard (p < .001 and p = .001, respectively). While GPT-3.5 and Bard did not meet the passing threshold for the exam, GPT-3.5 performed at the level of PGY-1 to PGY-2 (p = .368 and p = .019, respectively) and Bard performed at the level of PGY-1 to PGY-3 (p = .440, .498, and 0.036, respectively). GPT-4 outperformed both Bard and GPT-3.5 on image-associated (p = .003 and p < .001, respectively) and higher-order questions (p < .001). Among the 11 subject categories, all models performed similarly regardless of the subject matter. When individual LLM performance on higher-order questions was assessed, no significant differences were found compared to performance on first order questions (GPT-4 p = .139, GPT-3.5 p = .124, Bard p = .319). Finally, when individual model performance was assessed on image-associated questions, only GPT-3.5 performed significantly worse compared to performance on non-image-associated questions (p = .045).
Conclusion
The AI-based LLM GPT-4, exhibits a robust ability to correctly answer a diverse range of OITE questions, exceeding the minimum
Keywords
Introduction
Artificial intelligence (AI)-based large language models (LLMs) have promising applications and have garnered considerable public interest. The utility of AI-based LLMs in the medical field, particularly with differential diagnoses and clinical decision-making, has been subject to much research.1,2 The most well-known LLM has been OpenAI’s ChatGPT (Generative Pretrained Transformer), which was launched to the public in November 2022. The first publicly available version of ChatGPT utilizes the GPT-3.5 language model, trained through a blend of supervised and unsupervised learning methodologies using large banks of textual data up until September 2021. GPT-3.5 was subsequently fine-tuned using reinforcement learning techniques grounded in human input. 3 The base model has since been updated to GPT-4.
Several studies have assessed the performance of GPT-3.5 and GPT-4 on examinations used to evaluate medical students and resident physicians for medical licensing and board certification.4,5 Kung et al. recently examined GPT-3.5’s performance on the United States Medical Licensing Examination (USMLE) Step 1, 2, and 3 – standardized examinations taken during medical school and residency that require approximately 400 h of study each for the average student – and demonstrated that GPT-3.5 achieved a passing score across all three exams. 4 The newly updated GPT-4 model exhibited even more accuracy, illustrating a 20% improvement on all three exams. 6
Given the established proficiency of GPT-based LLMs on clinical subjects covered during early medical education, recent studies have explored their performance on more advanced board examinations administered to trainees in orthopedics, plastic surgery, radiology, and neurosurgery.7–10 Of these studies, only Ali et al. compared GPT-based LLMs performance to another independently developed LLM, Google Bard. Google Bard, released in May 2023, utilizes the LaMDA language model trained using Infiniset, a dataset primarily focused on dialogues and conversations from public forums. 11 Unlike GPT-3.5 and GPT-4, Google Bard is able to search the internet in real-time when generating responses to user queries.
Due to this unique capability of Google Bard, the present study aims to assess and compare the performance of LLMs, specifically GPT-3.5, GPT-4, and Bard on the Orthopedic In-Training Examination (OITE) from the American Association of Orthopaedic Surgery (AAOS), a standardized multiple-choice test administered to orthopedic residents each year to gauge their knowledge of the field. 12 A recent study by Lum explored this topic with only GPT3.5, using publicly available practice OITE questions from Orthobullets. Building upon this previous work, we aim to provide a more comprehensive comparative analyses of multiple language models on official 2022 OITE questions. 13
Materials and methods
Language learning models
The three language learning models tested in the present study, GPT-3.5, GPT-4, and Bard, are designed to generate human-like text in response to user-generated prompts. These models utilize an underlying transformer architecture that breaks down a question into chunks of texts, called input tokens, which are processed by the model’s many layers to ultimately generate the output tokens that form the answer. To generate the output tokens, the models do not use a retrieval-based system where pre-existing answers are pulled from a database. Instead, responses are generated on-the-fly based on token patterns seen during training and do not represent new, real-time understanding or analysis. 14
While they share a common architecture and methodology, there are substantial differences in their training data and model complexity. GPT-3.5 and GPT-4, developed by OpenAI, use their proprietary language model which has been trained on approximately 175 billion parameters, though the exact number and list have not been disclosed. It is worth noting that when testing GPT-4’s performance against older models, older models use a scaled-down model which utilize 1/1000th of GPT-4’s computing power. 15 Both models can only access information up to September 2021.1,13 Bard, on the other hand, is built upon the LaMDA transformer-based neural language model which has been trained on approximately 137 billion model parameters and is able to access the internet to generate responses. 16
Orthopedic in-training examination
OITE is a comprehensive exam in orthopedic surgery designed to assess an orthopedic surgeon’s knowledge during residency. 17 Official OITE 2022 questions and compiled resident score reports are available from AAOS, making it an ideal tool for assessing the knowledge and problem-solving abilities of these LLMs. 18 While AAOS reports resident performance on all 264 test items, the OITE 2022 examination available from AAOS only contained 207 test items. Of the 207 questions available for this study, 18 questions that exclusively provided image data (radiograph, image, or video) without associated text were excluded due to the current constraints of these LLMs, which only accept text inputs. The remaining 189 questions, including 64 questions containing image references, were used for evaluation based solely on their text content. Each question was presented verbatim with corresponding answers labeled alphabetically. The responses from each LLM were recorded verbatim, and the answer corresponding to the response was identified as the chosen answer for each question. As comparison, ACGME-resident scores on the OITE 2022 were extrapolated from the technical report by AAOS.
Categorization of study questions
Two fellowship-trained orthopedic surgeons independently classified each question into one of 11 general orthopedic categories, including Basic Science, Foot & Ankle, Hand & Wrist, Hip & Knee, Oncology, Pediatrics, Shoulder & Elbow, Spine, Sports Medicine, Trauma, and Practice Management. Questions were separately classified based on their association with images into image-associated and non-image-associated. Finally, questions were stratified using two-level taxonomy into first order and higher order, with first order questions examining recall and higher order questions examining complex reasoning (comprehension, interpretation, inferencing) and application of knowledge. All classification was performed in a double-blinded manner with no discrepancies between the two reviewers.
Statistical analyses
All statistical analyses were performed using STATA version 16.0 software (Stata Corporation, College Station, TX). OITE scores were compared between LLMs and against ACGME-residents, overall and across post-graduate years (PGY), with Pearson’s Chi-square testing and post-hoc analysis. Performance on image-associated and higher-order questions was similarly assessed between LLMs and within each LLM (using performance on questions with non-image-associated and first-order questions for controls, respectively) with a Pearson’s Chi-square test and post-hoc analysis. Performance by subject category between LLMs was assessed with a Pearson’s Chi-square test or Fischer’s exact test when indicated by sample size. Statistical significance was set at p < .05. Bonferroni correction was used for post-hoc analysis to account for multiple comparisons and the family-wise alpha threshold was maintained at 0.05. Statistical significance was set to p < .008 and p < .006 in post-hoc analysis when six or eight tests were performed, respectively. Study findings are reported in accordance with the STROBE guidelines.
Results
Overall performance
LLMs and resident performance on the OITE exam.

Abbreviations: LLM, Large Language Models; OITE, Orthopedic In-Training Examination; GPT, Generative Pretrained Transformers. Bold represents statistically significant.
aMean ACGME resident scores on 264-items of the 2022 OITE were extrapolated from technical report published by the American Academy of Orthopedic Surgeons. 16
bLLM model performances were tested on 189 eligible official OITE 2022 questions.
After disaggregation of the resident scores by residency year, GPT-4 scored at the same level as a PGY-3 (p = .149), PGY-4 (p = .502), and PGY-5 (p = .818); GPT-3.5 scored at the same level as a PGY-1 (p = .368) and PGY-2 (p = .019); and Bard scored at the same level as a PGY-1 (p = .440), PGY-2 (p = .498), and PGY-3 (p = .036) (Table 1). Per these results, only GPT-4, scoring 74% correct, would pass the OITE (passing score is 68.6% correct). 15
Performance by categories
LLM performance questions by category type.
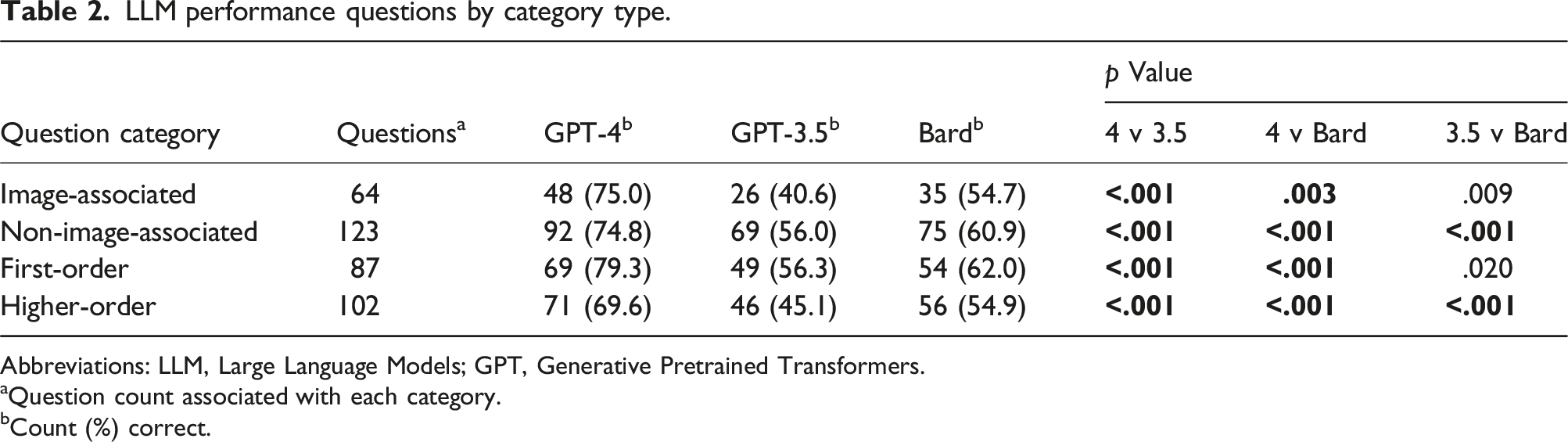
Abbreviations: LLM, Large Language Models; GPT, Generative Pretrained Transformers.
aQuestion count associated with each category.
bCount (%) correct.
LLMs performance based on subject category, reported as N (%) correct.
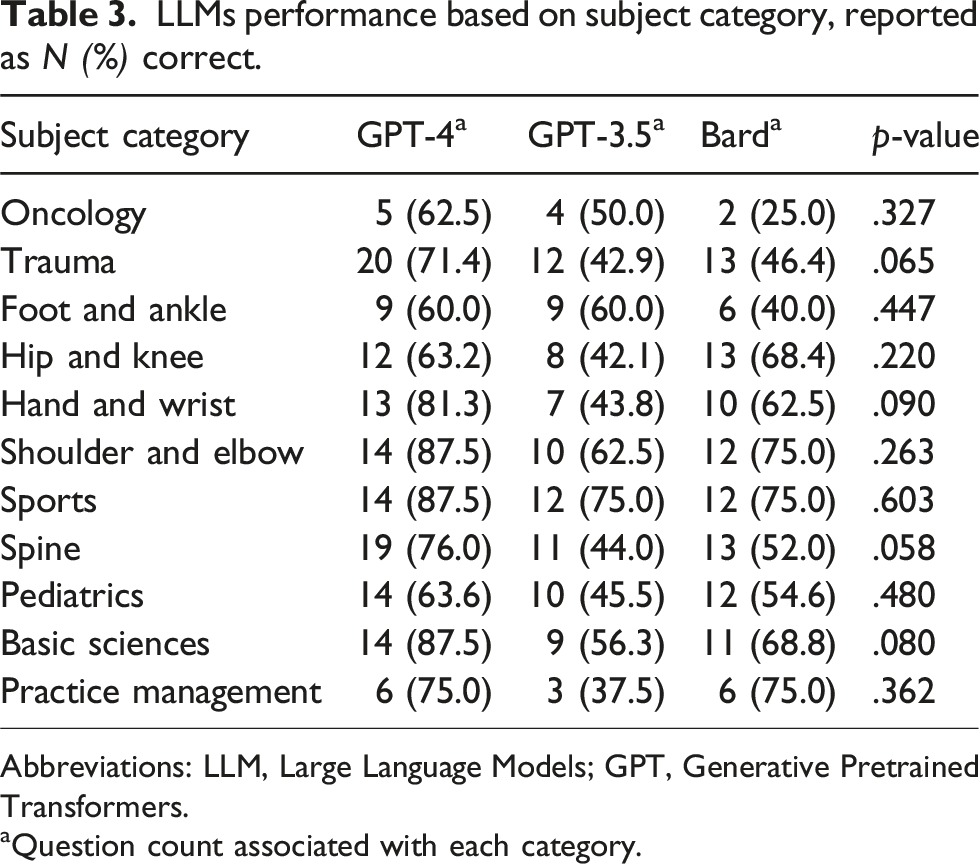
Abbreviations: LLM, Large Language Models; GPT, Generative Pretrained Transformers.
aQuestion count associated with each category.
When individual LLMs’ performance on each question category was analyzed, the taxonomy of the question had no influence on performance (GPT-4 p = .139, GPT-3.5 p = .124, Bard p = .319). However, when questions were stratified based on association with images, GPT-3.5 answered more image-associated questions incorrectly (GPT-3.5 p = .045). Whereas the performance of GPT-4 and Bard was not significantly impacted by association with images (GPT-4 p = .976, Bard p = .407).
Discussion
AI-based language learning models are of growing interest due to their utility in various fields, including healthcare. However, their ability to accurately and reliably address highly complex user-generated questions that may require years of clinical education and well-developed clinical reasoning and medical management skills has been heavily debated.19,20 The present study found that, besides GPT-3.5, GPT-4 and Bard scored similarly on the OITE to actual residents, with GPT-4 scoring at the level of PGY-3 to PGY-5 and Bard scoring at the level of PGY-1 to PGY-3. In addition, this investigation showed that GPT-4 is better at answering higher-order and image-associated questions compared to Bard and GPT-3.5. However, with the exception of GPT-3.5 performance on image-associated questions versus non-image-associated questions, no LLM performed significantly different on higher versus first-order questions or image-associated versus non-image-associated questions. Finally, no single LLM was better at answering specific categories of questions. These findings demonstrate that the newer LLMs may potentially be used in orthopedic education and may even serve as an adjunct tool in the clinical management of patients.
Multiple studies have previously assessed the performance of LLMs on board examinations.8,9,13 Ali et al., recently demonstrated that LLMs, particularly GPT-4, can outperform GPT-3.5 and human test-takers on neurosurgery written board examination, excelling in neuroanatomy, functional neurosurgery, and peripheral nerve sections. 8 It can even correctly answer higher-order questions that may pose a particular clinical challenge to residents. Bhayana et al. further illustrated the ability of GPT-3.5 to accurately answer radiology board-style questions without images, especially ones focused on clinical management. 9 However, in our study, GPT-3.5 and Bard, unlike GPT-4, did not meet the passing threshold and did not perform strongly on higher-order questions focused on application of concepts. More recently, Lum et al. placed GPT3.5 at the 40th percentile for first-year orthopedic residents and within the first percentile for third-year orthopedic residents, noting decreased performance with increased complexity of questions. 13 The current study expands on Lum et al.’s findings, noting the ability of GPT-4 to outperform its predecessor GPT-3.5 and pass the OITE. This is consistent with the performance of the two GPT models on other examinations, highlighting the superiority of GPT-4.8,21 However, contrary to Lum et al.’s findings, GPT-3.5 and GPT-4 were not significantly better at answering higher order. This discrepancy is possibly explained by Lum et al. implementing a three-tier system as opposed to our study’s two-tier system.
Within the field of orthopedics, this study is the first to compare performance of different LLMs, with the addition of Bard. In this study, Bard performed inferiorly to GPT-4 despite Bard’s live access to the internet. This finding may be explained by differences in the training datasets between the LLMs. Since Bard’s training set is largely conversational forums, Bard may have had insufficient training on patterns related to clinical inputs. In addition, Bard’s ability to access the internet may have served as a crux rather than an advantage. Although Bard can access the internet, it still processes information based on recognition of patterns rather than actively searching specific resources like Orthobullets. Furthermore, many correct answers on the OITE rely on the findings of a handful of studies and these studies’ findings may conflict with results from less rigorous studies. Since Bard is unable to assess the validity and limitations of the data it accesses, it may utilize patterns learned from the less rigorous studies in order to generate its answer.
AI has already garnered significant attention in orthopedic surgery and its current applications in the field are multifold, ranging from three-dimensional digital surgical planning to computer-assisted navigation of mechanical construction placement.22–24 Now, with GPT-4s ability to perform similarly to a PGY-5 on the OITE, there is a question of whether AI-based models could supplement surgeon care and independently treat patients. However, the practice of surgery extends beyond the ability to succeed on multiple choice questions and requires focused physical examination, manual dexterity, and surgical precision that AI cannot currently replace.25,26
Furthermore, although this study found that some AI models performed at a similar level as trained orthopedics residents, the individual LLMs perform similarly on all questions despite differences in taxonomy and association with images, suggesting their ability to answer correctly may be due to chance. This is supported by the science behind how transformer-based language models generate text. LLMs examine the context of the input, sample the probability of different text to come next, and deploy the text with the highest probability as their response. Since statistical patterns drive response generation, we cannot know if LLM’s have true understanding of the text they process or generate. As such, LLMs do not have the knowledge, beliefs, desires, or intentions of humans. They only identify patterns in the data they are trained on and use those patterns to generate plausible-sounding text. Despite their advanced capabilities, LLMs can potentially result in dangerous circumstances where misinformation sounds plausible.
Despite the limitations of AI-based LLMs, their use is becoming widespread with ChatGPT being integrated across many platforms, including emails. Thus, it is important that orthopedic surgeons recognize advantages and limitations of the different models. Knowing that Bard is primarily trained on conversational forums, surgeons and interested parties may want to further develop and train Bard to interface with patients to answer questions and write post-operative care plans. However, if the surgeon’s goal was to further develop a model to assist in triaging patients and orthopedic resident education, utilizing Bard would be suboptimal compared to the GPT platform.
GPT-4’s performance on the OITE holds promise for its use within orthopedics. Since GPT-4’s likelihood to answer correctly was not dependent on question taxonomy, GPT-4 may be advanced enough to assist in tasks that require interpretation of clinical data, such as triaging patients to determine which patients need specialized care. Although, future work is required to clarify whether GPT-4 can truly interpret information or if this finding is the result of random chance. Additionally, since GPT-4’s baseline orthopedic knowledge is sufficient to pass the OITE exam, it may provide a conversational format for trainees to discuss topics they have difficulty with and generate new practice questions. While these tasks may seem far off, GPT-4 compared to its predecessor GPT-3.5 already performs almost 25% better on the OITE, suggesting that future iterations of GPT may become increasingly useful adjuncts in clinical care.
The present study has several potential limitations. To begin with, the study only examines two of the most common language models (one across multiple updates) even though other advanced medically focused models may be available or be in development. Secondly, the study excludes exclusively image-based questions due to the current limitations in AI language models. Additionally, the study utilizes only 70% of the official 2022 OITE questions answered by orthopedic residents in the same year to compare LLM performance between models and residents. However, the proportion of questions utilized should capture the depth and breadth of orthopedics tested by the OITE. The study also does not examine the hallucination rates of the LLMs in the context of the OITE exam. LLM generated hallucinations are instances where the output has no relation to the input. Previous studies have shown that GPT-4 experiences 19%–29% less hallucinations than GPT-3.5. 15 Bard, likewise, has been shown to have a 57% hallucination rate. 21 These may ultimately limit the generalizability of our findings and highlight the need for continued research to assess AI use in orthopedic surgery.27,28 Further studies that leverage LLM APIs (Application Programming Interface) and image support may be able to address these limitations.
Conclusion
The AI-based LLM GPT-4 exhibits a robust ability to correctly answer a diverse range of OITE questions, exceeding the minimum passing score for the 2022 OITE, and outperforming its predecessor GPT-3.5 and Google Bard.
Supplemental Material
Supplemental Material - Comparative performance of artificial intelligence-based large language models on the orthopedic in-training examination
Supplemental Material for Comparative performance of artificial intelligence-based large language models on the orthopedic in-training examination by Andrew Y Xu, Manjot Singh, Mariah Balmaceno-Criss, Allison Oh, David Leigh, Mohammad Daher, Daniel Alsoof, Christopher L McDonald, Bassel G Diebo and Alan H Daniels in Journal of Orthopaedic Surgery
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.