
Abstract
Search engines, such as Google or Yandex, shape social reality by informing their users about current and historical phenomena. However, there is little research on how search engines deal with contested memories, which are subjected to ontological conflicts known as memory wars. In this article, we investigate how search engines circulate information about memory wars related to the Holodomor, a mass famine caused by Soviet repressive politics in Ukraine in 1932–1933. For this aim, we conduct an agent-based audit of four search engines—Bing, DuckDuckGo, Google, and Yandex—and examine how their top search results represent the Holodomor and related memory wars. Our findings demonstrate that search engines prioritize interpretations of the Holodomor aligning with specific sides in the memory wars, thus becoming memory warriors themselves.
Introduction
Memory wars are ontological conflicts that deal with the interpretation of the past in the public sphere and often involve institutional actors (e.g. states; Mälksoo, 2015). Such conflicts are particularly intense in the case of ‘fractured’ 1 (Bernhard and Kubik, 2016) memory regimes, which rely on exclusive historical narratives to legitimize their status and mobilize supporters. To sustain these exclusive narratives, regimes engage in memory wars to subjugate alternative interpretations of the past through legal prohibition of specific narratives (Koposov, 2017) or the subversion of grassroot memory practices (Fedor, 2017). In some cases, memory wars can justify the use of extraordinary measures (e.g. lethal force; Gaufman, 2015) by presenting the alleged distortions of the past as an existential identitarian threat. One example of such a case is Russia’s war against Ukraine, where the revision of the Soviet narrative of the Great Patriotic War in Ukraine has been utilized by the Kremlin to emphasize the existential threat for Russophone Ukrainians and justify the use of violence to counter it (Gaufman, 2015; Makhortykh, 2018).
Similar to other types of ontological conflicts, memory wars are affected by the rise of digital technologies. The unprecedented connectivity between producers and consumers of memories enabled by online platforms expands the range of actors involved in these memories’ contestation. Together with anonymity and possibilities for low-cost engagement with the past (e.g. linking or sharing the piece of content), individuals have more possibilities to partake in memory wars. Besides their less top-down nature, these online memory wars—or ‘web wars’ (Rutten et al., 2013)—enable new forms of contestation varying from hashtag protest campaigns (Bosch, 2017) to cyberattacks against heritage institutions (Shanapinda, 2018) to animations challenging the hegemonic nature of memory-related festivities (Makhortykh and Sydorova, 2022).
However, these digital transformations go beyond new possibilities to contest the past offered to human actors. They also enable the rise of non-human actors who are involved in memory-making and, potentially, memory contestation (Makhortykh, 2021). These actors are algorithmic systems used by platforms (e.g. YouTube) to curate an unprecedented volume of online content. While sometimes assumed to be more objective than humans (see Pethig and Kroenung, 2022), algorithms are shaped by the values of their designers and the data they are applied to. This dependency makes algorithmic systems subject not only to occasional errors, but also to systematic bias resulting in distorted treatment of certain subjects. The potential for such malperformance is particularly high for ontologically contested subjects (e.g. race; see Noble, 2018), and it means that algorithmic systems might be particularly prone to errors and bias in the case of memory wars.
In this article, we examine how one particular class of algorithmic systems, namely search engines, deals with information about the Holodomor, a human-made famine in the 1930s that took a particularly heavy toll on the Ukrainian population of the Soviet Union. Our choice is attributed to the intense contestation of Holodomor-related memories between Ukrainian, Russian, and Western historiographies, which makes the selection of prioritized sources a challenging task for search engines. The situation is further complicated by the tendency of some search engines (e.g. Yandex, a Russian search engine) to amplify pro-Kremlin narratives (Kravets and Toepfl, 2021), which can have implications for their curation of memory-related information. To investigate the performance of search engines under these circumstances, we conducted a comparative audit of search outputs for the query ‘Holodomor’ in Latin and Cyrillic script for four major search engines: Bing, DuckDuckGo, Google, and Yandex.
The rest of the article is organized as follows: First, we introduce our case study, the Holodomor, and discuss memory wars related to it. Then, we discuss the relationship between search engines and collective memory and introduce the methodology of our agent-based audit. Then, we present our findings about the types of sources prioritized by different search engines and their treatment of ontologically contested aspects of the Holodomor. Finally, we discuss the implications of our findings for understanding the role of algorithmic systems in the context of memory wars, and the limitations of the study.
The Holodomor in the context of memory wars
The Holodomor took place in 1932–1933 and was caused by Stalin’s politics of collectivization, which resulted in a mass famine in Soviet Ukraine and the Kuban region inhabited by Ukrainians, as well as several other parts of the Soviet Union (e.g. Kazakhstan and Volga region). Among the affected regions, Ukraine suffered the heaviest toll of the famine, resulting in millions of deaths 2 attributed not only to brutal grain requisitions, but also to the internal blockades that intentionally prevented Ukrainians from leaving their villages to search for food (Dyck, 2021). The purpose of this forced starvation is presumed to have been to suppress resistance to collectivization in Ukraine and to prevent further nationalist uprisings, which had occurred frequently in the 1920s (Applebaum, 2017).
Until Perestroika in the late 1980s, the subject of the Holodomor remained a taboo topic in the Soviet Union. While there was a growing recognition of the artificial nature of the famine in the West from 1950s to 1960s (mainly through the efforts of Ukrainian émigré groups; Applebaum, 2017), in Soviet Ukraine, the public debate was only initiated by the local intelligentsia in the 1980s. However, the Holodomor only started to be recognized as an all-Ukrainian tragedy on an official level after the regaining of Ukraine’s independence in 1991. The 60th anniversary of the Holodomor was marked by Ukrainian officials, including then President Kravchuk, and became an important milestone in Holodomor remembrance, followed by the establishment of the Day of Remembrance of Famine Victims in 1998 (Kasianov, 2008).
The period of Yushchenko presidency (2005–2010) marked another important stage in institutionalizing Holodomor remembrance, both in Ukraine and worldwide. Not only was the law recognizing the Holodomor as a genocide adopted in 2006 (Klymenko, 2016), but new public commemoration practices were also established and popularized around this time (e.g. the minute of silence and the practice of lighting candles in memory of the victims). Altogether, it resulted in the growing recognition of the Holodomor as a genocide in Ukrainian society.
The recognition of the Holodomor as an important element of collective remembrance in Ukraine and the establishment of new memory practices on the local and international level have also made Holodomor memory the subject of ontological conflicts. Some of these memory wars involve Ukrainian scholars and developed on the local level, whereas others relate to foreign politics and affect the relationship between Ukraine and other countries (mainly Russia). While it would be hard to establish an exhaustive list of ontological conflicts related to the Holodomor, we summarize some of the ones that we find of particular relevance for the current study below.
One of the key mnemonic conflicts relates to the interpretation of the Holodomor. While the Holodomor is recognized as the genocide in Ukraine and a number of Western countries, this claim was earlier contested within Ukraine and remains contested by a number of other countries, particularly Russia (Klymenko, 2016). The main argument here relates to the claim that not only Ukraine, but also other parts of the Soviet Union, suffered from the famine. Hence, the Holodomor was not necessarily a genocide against Ukrainian people but should be treated as a crime of the Soviet leadership. Thus, arguments about the Holodomor being a genocide are treated as a ‘common thesis of the Ukrainian nationalistic propaganda’ that undermines the communal suffering of the Soviet people (Nevedov, 2018: 17).
Besides the contestation of the status of the Holodomor as a genocide, which at times can also be attributed to the intent of avoiding parallels between it and other genocides (e.g. the Holocaust; Dyck, 2021), there are also claims denying the criminal nature of the Holodomor. Such denialist claims are often made by the Russian journalists-cum-conspiracy theorists who argue that the Holodomor was due either to natural causes or the efforts of enemies of the people (and, thus, cannot be blamed on the Soviet leadership; Prudnikova and Chigirin, 2013), or that it is another lie of the corrupt West aiming to pit Ukrainians against their Slavic brothers (Rambler, 2017).
Another subject of memory wars concerns the number of Holodomor victims. Because of the fragmentary data, existing estimates are usually based on statistical techniques that model the number of fatalities and vary rather broadly. In Ukrainian scholarship, the estimates range from 3.9 to 4.5 million victims (Rudnytskyi et al., 2015) to 7 (Marochko, 2017) or even 10.5 million (Petryshyn et al., 2021). Russian historiography tends to align with more conservative estimates, such as 2.9–3.5 million (Marchukov, 2008), or even lower numbers (e.g. 1–2 million; Shubin, 2008).
The already challenging task of estimating the human losses is complicated by the politicization of the number of Holodomor victims. In the case of Ukraine, it is reflected in the tendency of some institutions to propagate claims about the higher number of victims, such as in the case of President Yushenko’s claims of 10 million victims or the recent statements of the Ukrainian Holodomor Museum about the even higher number (Gadzins’ka, 2021). The lower numbers based on demographic estimates (Rudnytskyi et al., 2015) are labeled by some Ukrainian public figures as Russian propaganda aiming to downplay the importance of the Holodomor (see Gadzins’ka, 2021).
One more subject of mnemonic contestation is related to the comparability of the Holodomor with other atrocities. While such comparisons can facilitate understanding of the Holodomor, they also raise ethical concerns (e.g. by challenging the notion of each genocide being unique; Jonassohn, 1998). The Holodomor is often compared with other genocides, in particular, the Holocaust, to emphasize the genocidal nature of the former or stress its significance (e.g. by claiming that the number of victims is higher for the Holodomor). Such ‘competitions of victims’ (Jilge, 2006) are commonly criticized by scholars for their potential to undermine the significance of the atrocities that are compared to each other (Dyck, 2021) or even defend past crimes (e.g. by claiming that the Holocaust was justified because of the Jewish involvement in the Holodomor; Makhortykh, 2019).
In the case of Russia, the main emphasis is laid on comparisons between the Holodomor and other Soviet famines that occurred in 1932–1933, for instance, in Kazakhstan and the Volga region. Unlike the comparisons between the Holodomor and the Holocaust, the main purpose of the comparison in this case is to downplay the genocidal nature of the Holodomor by arguing that similar events occurred in other parts of the Union (Gudz’, 2019).
The algorithmic turn in memory wars
Technological infrastructures are increasingly recognized as an important factor in shaping collective memories. A number of studies (e.g. Mayer-Schönberger, 2011; Van House and Churchill, 2008) discuss the unprecedented possibilities for capturing and storing information about the past granted by digital infrastructures, together with their long-term effects on the complex dynamics of remembrance and forgetting. A related phenomenon is the disappearance of the clear distinction between private and public memories attributed by the rise of online platforms and increased interconnectedness between producers and consumers of memory (Hoskins, 2009; Van Dijck, 2011), which is amplified by new possibilities for engaging with mnemonic narratives through platform affordances (e.g. liking or sharing; Hood and Reid, 2018).
The majority of studies look at memory infrastructures from the point of view of human actors who employ those infrastructures to engage with the past. However, we argue that some infrastructures become memory actors themselves, considering their high degree of autonomy (e.g. in the form of the ability for automated decision-making). An example of such infrastructures are algorithmic information retrieval systems, which have substantial implications for the ways individuals and societies interact with the past (Esposito, 2017). By filtering and ranking online content, these systems become key information intermediaries (Wallace, 2018) that shape how their users perceive social reality (Noble, 2018). Search engines, in particular, play an important role in this process by prioritizing specific information sources and interpretations which define ontologies of present as well as historical phenomena (see, for instance, Zavadski and Toepfl, 2019).
Despite the growing importance of search engines as actors shaping the perception of the past (Makhortykh et al., 2021b), their impact on collective memories currently remains understudied. The few existing empirical studies usually focus on how search engines select sources when dealing with history-related queries. For instance, in the case of memories about Shanghai’s Jewish community, Jakubowicz (2009) found that search engines prioritize authoritative sources (e.g. governmental or educational websites). Similarly, Reading (2011) observed that search results prioritized Wikipedia, Facebook, and news sources while limiting the visibility of other mnemonic sources in relation to the protests in Iran.
Besides the tendency to prioritize specific groups of information sources, the way search engines circulate information about the past is subject to the lack of transparency (Paßmann and Boersma, 2017) and can inherit the distorted representations of social reality (Noble, 2018). These issues are highlighted by several studies discussing different forms of history-related search malperformance, ranging from the disproportionate visibility of the certain categories of mass atrocity victims (Makhortykh et al., 2021b) to the prioritization of interpretations supporting fractured memory regimes (Zavadski and Toepfl, 2019).
So far, however, there are no studies looking in detail at how search engines deal with ontologically contested memories. Research dealing with other contested subjects, such as the representation of race in the context of technological innovation (Makhortykh et al., 2021a) or of gender in the context of professional vocation (Kay et al., 2015) or face-ism (Ulloa et al., 2022a), suggests that the possibility of distorted treatment (e.g. by reinforcing stereotypes) of such subjects by search engines is high. In the case of memory wars, such treatment can result in the reiteration of existing misconceptions (e.g. denialist claims) and subjugation of alternative interpretations that can turn search engines into memory warriors actively taking sides in ontological confrontations.
Methodology
Data collection
To examine the role of search algorithms in the context of Holodomor-related memory wars, we conducted an agent-based audit of four search engines: Google, Yandex, Bing, and DuckDuckGo. This auditing approach uses virtual agents (i.e. software simulating user behavior, such as scrolling webpages) to generate system inputs and then record the resulting outputs (Ulloa et al., 2022b). In the context of search engine research, it allows controlling for personalization (Hannak et al., 2013) and randomization (Makhortykh et al., 2020) factors. In our study, we controlled for these factors by synchronizing agent activity to isolate the effect of time at which the inputs were generated, deploying agents in a controlled environment (i.e. virtual machines with the same operating systems made from scratch) to minimize personalization, and making the large number of agents simultaneously enter the same query to account for randomization-caused variation in output.
To implement the study, we built a network of CentOS virtual machines in the Frankfurt region of the Amazon Elastic Compute Cloud. Practically, it meant that the agents had German IP addresses similar to human agents from this part of Germany. On each machine, we deployed two agents: one in the Chrome browser and one in the Firefox one. Each agent consisted of two browser extensions: a bot and a tracker. The bot emulated human behavior by (1) visiting a search engine page, (2) entering the query, (3) scrolling down to capture top 10 outputs, (4) removing data accessible by the browser and the engine’s JavaScript to prevent personalization (e.g. earlier searches affecting the subsequent ones). The tracker collected the HTML of all pages visited by the bot and sent it to a storage server.
We conducted two rounds of data collection: on 27 February 2020 and 8 May 2021. We used 64 and 20 agents for the respective rounds (16 and 5 agents per each engine). The ‘.com’ version of each engine was used to make outputs more comparable (i.e. to avoid differences caused by different engine versions). While some engines, such as Google or Yandex, have regional versions (e.g. google.ru), others like DuckDuckGo do not or they redirect to the default .com version (as in the case of Bing).
Each agent searched first for the term ‘holodomor’ and then ‘голодомор’ (‘holodomor’ in Cyrillic script; the same spelling in Ukrainian and Russian). After collecting data, we extracted the top 10 organic search results (i.e. the ones not related to ads or interface panels) and aggregated them across all agents per engine. The resulting data set consisted of 208 search results for both search queries: the exact number of unique results per engine is shown in Table 1.
Number of unique links in the top 10 results aggregated across agents per search engine by the script of the query.
Data analysis
After extracting all unique links in the top 10 results across all agents per engine, 3 we used qualitative content analysis to examine how they circulate information about the Holodomor. Specifically, we focused on the four features of the linked content: (1) the type of the source, (2) the interpretation of the Holodomor, (3) the number of victims and (4) the comparisons with other atrocities. With the exception of the first feature, the selection of features was informed by the existing research on the Holodomor-related memory wars. The specific options for the four features are listed below; all of them have emerged through the data analysis as part of the inductive coding.
The type of the source defines what web resource the linked content is coming from: (1) activist: websites associated with activist and non-governmental organizations; (2) alternative: non-mainstream and niche political websites (e.g. anonymous blogs); (3) commerce: business-related websites (e.g. online shops); (4) educational: websites of educational institutions (e.g. museums and university departments); (5) entertainment: websites dealing with popular culture and entertainment (e.g. IMBD); (6) journalistic: websites of journalistic media organizations (e.g. CNN); (7) non-available: websites that are no longer available and were not retrievable via Internet Archive; (8) political: websites of political parties or governments; (9) reference: online encyclopedias or dictionaries (e.g. Wikipedia); (10) social media: social media platforms (e.g. YouTube).
The interpretation of the Holomodor determines how the linked content interprets the event: (1) crime: the criminal nature of the Holodomor is acknowledged but the event is not treated as a genocide; (2) denial: the criminal nature of the Holodomor is denied (e.g. by attributing it to natural causes or claiming that it did not happen); (3) genocide: the Holodomor is recognized as a genocide; (4) mixed: several interpretations of the Holodomor are noted without giving a clear priority to one of them; (5) none: no clear interpretation of the Holodomor is given (e.g. the event is mentioned, but is not explained).
The number of victims indicates the upper limit of the number of victims who perished during the Holodomor. Our decision to use the upper limit is attributed to the linked content often reporting a range of numbers (e.g. 3.5–7 millions) or multiple estimates. Hence, to standardize the coding, we relied on the highest number of victims (in millions) reported as a valid estimate (i.e. not used exclusively for the debunking purposes): (1) unspecified: the exact number of victims is not given (e.g. the result refers to ‘millions of victims’); (2) below 1: the reported number of victims is below 1 million; (3) 1–5: the reported number of victims is between 1 and 5 million; (4) 5–10: the reported number of victims is between 5 and 10 million; (5) above 10: the reported number of victims is above 10 million.
Finally, the comparison with other atrocities indicates whether the linked content draws parallels between the Holodomor and other atrocities (e.g. to facilitate its interpretation) and which ones: (1) Armenian genocide: the Holodomor is compared with the genocide of Armenians in 1915–1917; (2) Holocaust: the Holodomor is compared with the Holocaust; (3) mixed: the Holodomor is compared with multiple instances of mass atrocities (e.g. the Holocaust and the Stalinist repressions); (4) none: there are no parallels drawn between the Holodomor and other atrocities; (5) Soviet famines: the Holodomor is compared with other famines in the Soviet Union (e.g. the famine of 1921–1922 in the Volga region or the famine of 1932–1933 in Kazakhstan).
To measure the coding reliability, 53 links (i.e. 25% of the data) were coded by two coders, both of whom had working knowledge of English, Russian, Ukrainian and German. Based on this subsample, we calculated the Kripperndorf’s alpha values 4 for each of the features. The results showed a high level of reliability for most of the features: 0.97 (type of the source), 0.97 (interpretation of the Holodomor), 0.83 (the number of victims) and 0.69 (comparison with other atrocities). The lower level of reliability for the last feature can be attributed to the disagreement between coders on how detailed the comparison shall be to count: the final consensus was that even non-detailed comparisons (e.g. the statement that some Ukrainian politicians refer to the Holodomor as the Ukrainian Holocaust) shall count. Following the reliability assessment, the identified disagreements were consensus coded.
Findings
Types of sources
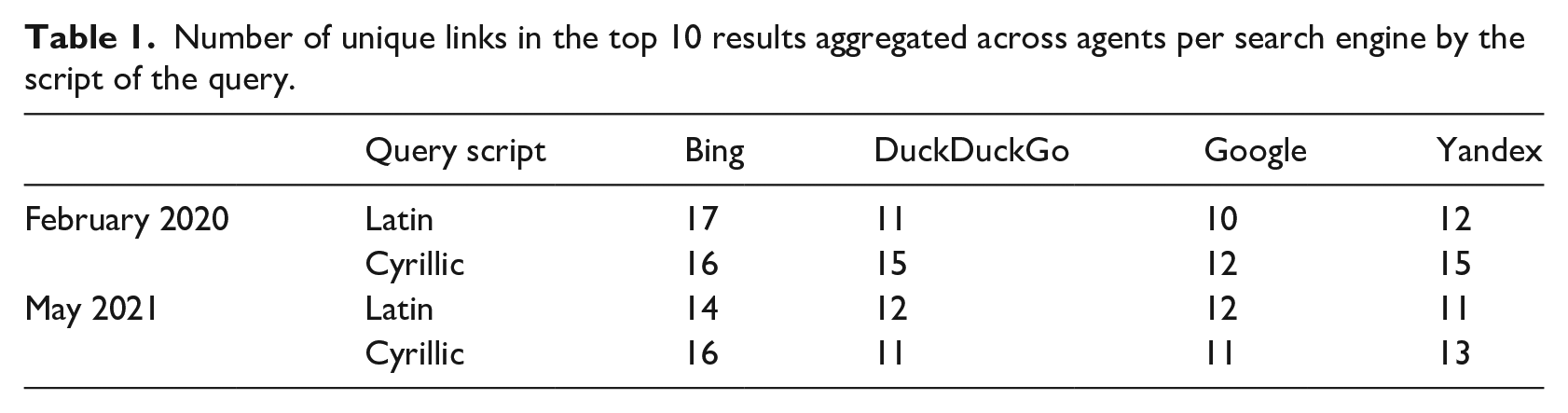
We started our analysis by examining the types of sources prioritized by search algorithms. Figure 1 shows that most common sources of information about the Holodomor were journalistic media (e.g. BBC or Ukrainska Pravda) and reference websites (e.g. Wikipedia or Britannica). These observations align with earlier findings (Zavadski and Toepfl, 2019) on the representation of historical phenomena by the search engines, with the exception of the small presence of personal websites in the case of the Holodomor. Journalistic media and reference websites are also frequently prioritized sources in the case of non-historical queries (e.g. ones related to current politics; Urman et al., 2021).
Types of information sources on the Holodomor across engines, time periods and queries.
Google was the most consistent in prioritizing journalistic/reference sources across both Latin and Cyrillic queries. For other engines (e.g. Yandex and DuckDuckGo), we observed substantial differences: for Latin queries, both engines put more emphasis on educational sources (e.g. Holodomor Research and Education Consortium), whereas for Cyrillic queries, such sources were replaced with reference (DuckDuckGo) and journalistic outlets (Yandex). Furthermore, in the case of Yandex, alternative websites (e.g. RationalWiki or holodomor.info) appeared more frequently for Latin queries (i.e. 2 results in February 2020 and 3 results in May 2021, as contrasted by 1 and 1 results for the Cyrillic queries).
Finally, some categories of sources appeared relatively infrequently among all search engines. Such categories included social media (e.g. YouTube videos and LiveJournal blogs), entertainment websites (predominantly discussing Holodomor-themed movies), and commercial websites (e.g. Amazon pages selling Holodomor-themed items).
Interpretation of the Holodomor
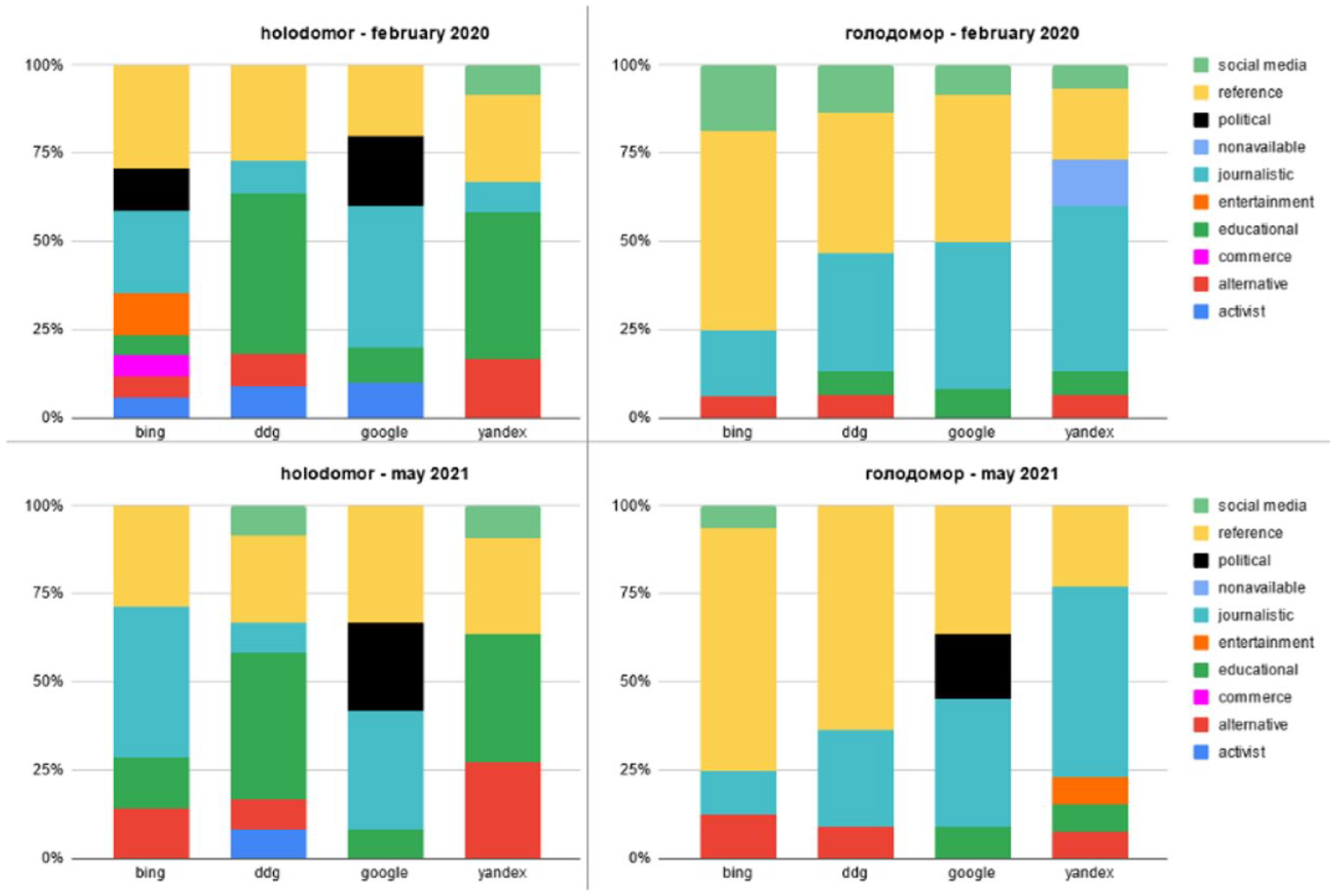
Figure 2 demonstrates substantial variation in the interpretations of the Holodomor prioritized by the search engines. The two most prevalent interpretations are of the Holodomor being a genocide (Yandex and DuckDuckGo for Latin queries) and of its status being debated (Google for Latin queries and Bing for Latin/Cyrillic queries). The number of search outputs interpreting the Holodomor as a crime of the Soviet leadership, but not a genocide, was relatively low across all engines.
Interpretations of the Holodomor across engines, time periods and queries.
In addition to the outputs discussing, in one way or another, the responsibility of the Soviet regime for the Holodomor, we observed outputs denying not only the interpretation of the Holodomor as a genocide, but also its criminal nature. Such denialist outputs were particularly visible in the case of Yandex, specifically for Cyrillic queries (i.e. 5 and 4 results for February 2020 and May 2021, respectively), and usually came from journalistic outlets and social media platforms.
Furthermore, some search outputs claiming that the Holodomor was a genocide did so in a rather concerning manner. A few results, primarily coming from Yandex and Bing, linked to anti-Semitic materials stressing the connection between Bolshevism and Jews and blaming Jews for orchestrating a genocide against other ethnicities. An illustrative example of such a stance is the holodomor.info website titled ‘The Jewish Ethnic Cleansing Of Europeans’ (currently not functioning, but still available via the Internet Archive).
The number of Holodomor victims
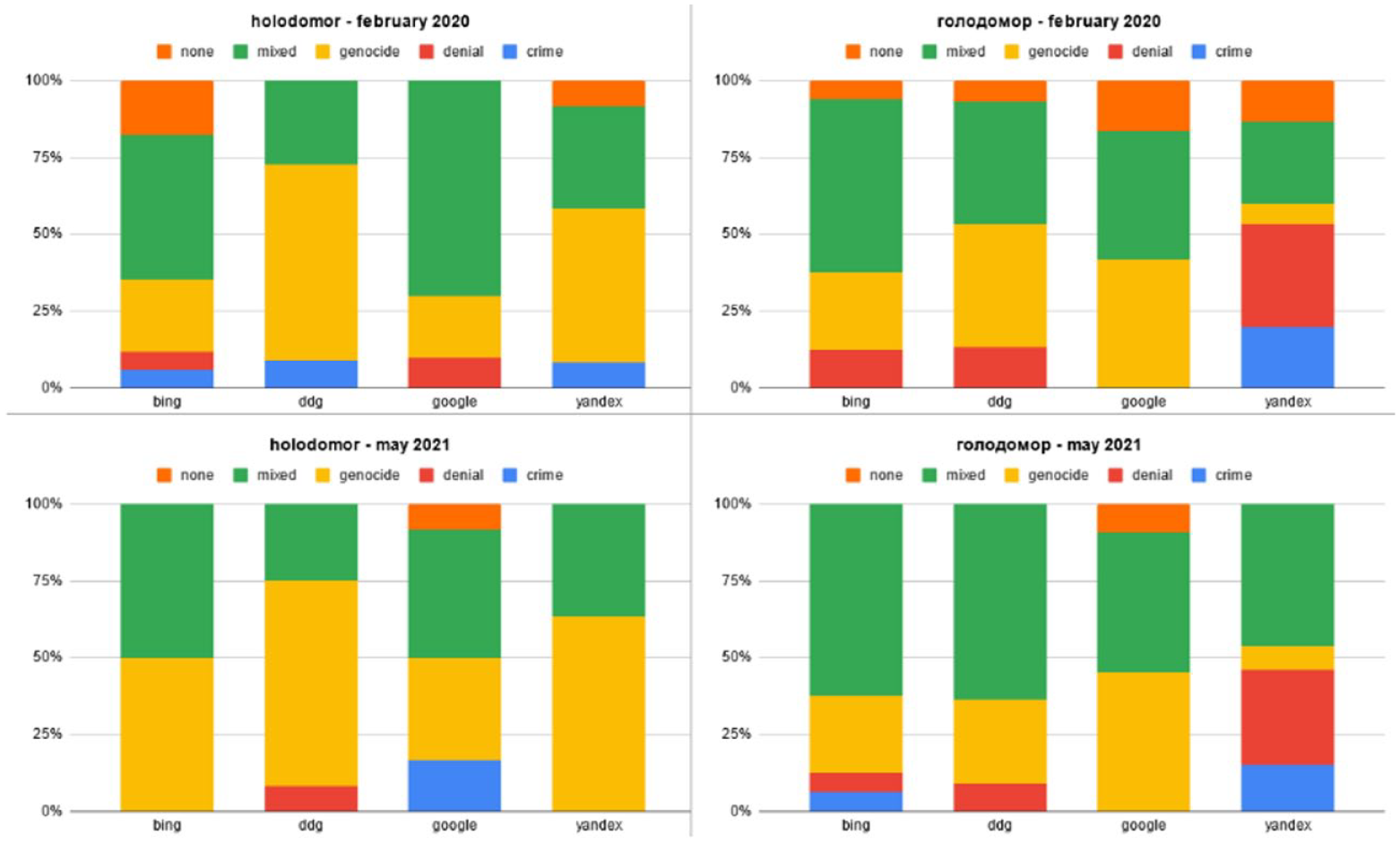
Following our examination of the Holodomor’s interpretations, we looked at what numbers of victims are prioritized by the search engines. Figure 3 demonstrates that for most engines (except DuckDuckGo for Cyrillic queries, where the range from 5 to 10 million was prioritized) the prevalent number is between 1 and 5 million, which also aligns with the numbers prevalent in the academic scholarship. While some results also reported extremely low numbers (i.e. below 1 million), their presence was marginal.
Reported number of victims of the Holodomor across engines, time periods and queries.
The high number of outputs reporting the numbers above 10 million, in particular, on Google and Bing, can be attributed to these search engines linking more frequently to the resources of political institutions (e.g. Ukrainian embassies), together with the German version of Wikipedia, which uses a higher estimate of victims (in contrast, for instance, to the English version with lower estimates). While such estimates of victims are criticized by scholars (e.g. Gadzins’ka, 2021) for being inflated, they still appear in the statements of the Ukrainian officials and the journalistic materials reporting on the ongoing debates. By prioritizing these estimates as part of their tendency to promote journalistic/political sources, search engines contribute to normalization of the higher estimates of the Holodomor victims (at least in response to the Latin queries).
Comparability of the Holodomor with other mass atrocities
Figure 4 shows that comparisons between the Holodomor and other atrocities vary depending on the query. For Latin queries, the majority of search outputs either abstain from drawing parallels between the Holodomor and other atrocities or discuss a number of possible comparisons (e.g. the Holocaust together with other Soviet famines). In some cases (e.g. Google), the Holodomor was compared only with the Holocaust and no other parallels were drawn, albeit the frequency of such comparisons was not too high.
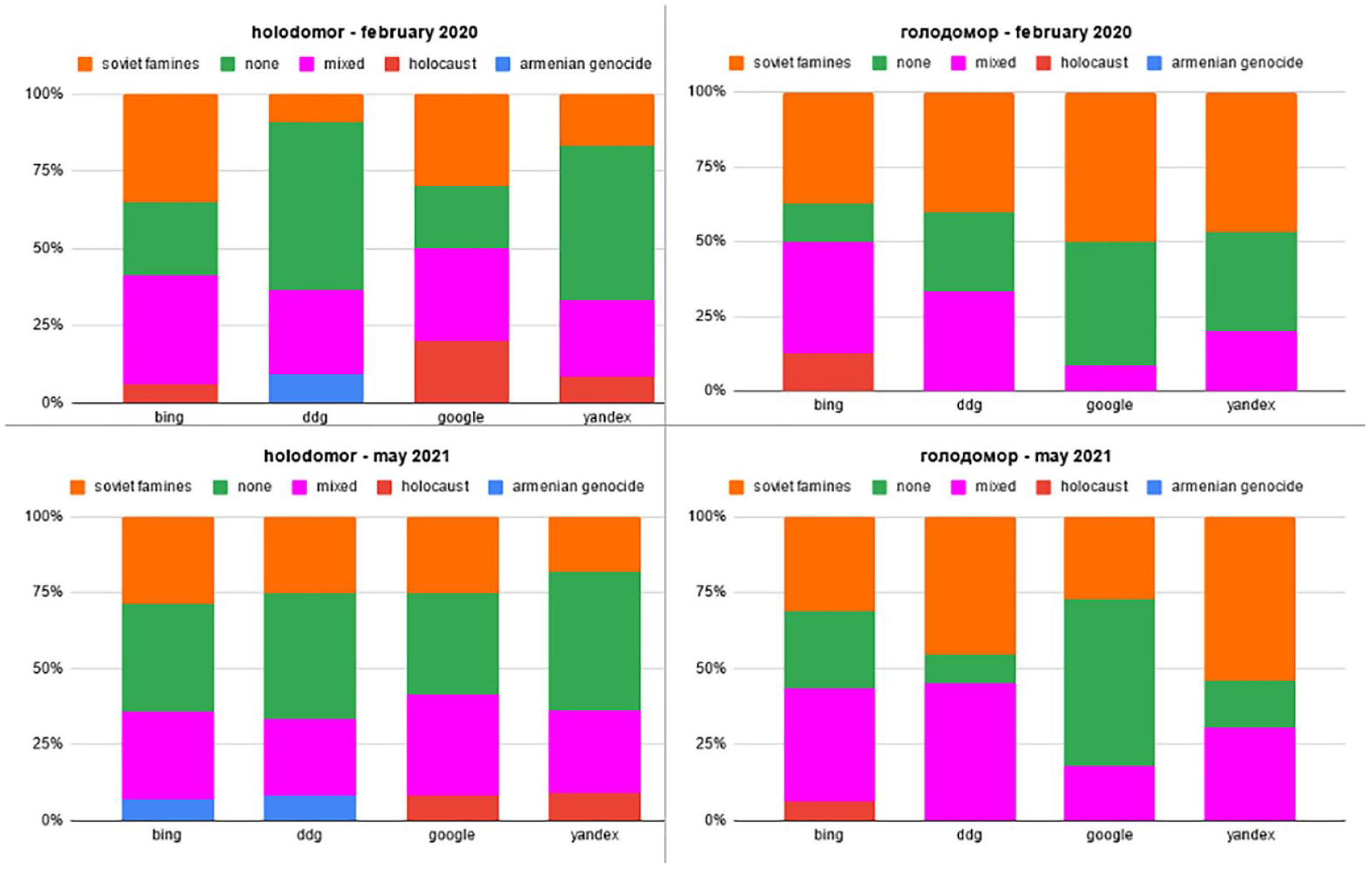
Comparisons between the Holodomor and other mass atrocities across engines, time periods and queries.
For Cyrillic queries, the distribution of comparisons turned out to be different. The number of comparisons to the Soviet famines substantially increased when using Yandex and DuckDuckGo (as well as Google for 2020). The prevalence of such comparisons, which are common for the Russian historiography of the Holodomor, tends to downplay the importance of the Holodomor as a genocide targeting specifically Ukrainians and normalizes it by drawing parallels with other famines in the Soviet Union.
Conclusion
In this study, we investigated how search algorithms circulate information about the Holodomor-related memory wars. Our observations demonstrate that search engines tend to prioritize journalistic media and reference websites as the main sources of information about the Holodomor. Such prioritization is attributed to several reasons: one of them is that some engines (e.g. Google; Google, n.d.) take into consideration the number of links to a specific website from other websites, together with interaction data. This benefits reference websites (e.g. Wikipedia), which are often extensively linked and interacted with. Another reason is the tendency of engines like Google to prioritize sources that demonstrate ‘authoritativeness and expertise on a topic’ (Google, 2020), which includes journalistic and government-related outlets. Furthermore, news organizations are known to be active in using search engine optimization to promote their content (e.g. Giomelakis and Veglis, 2016), which also contributes to the visibility of their websites.
The prevalence of journalistic media and reference websites has implications not only for how search algorithms represent the Holodomor, but also for how they deal with related ontological conflicts. The prevalence of journalistic commentaries translates into a focus on recent developments, including, for instance, public events around Holodomor anniversaries, but also provocative comments made by public figures in relation to the Holodomor. Together with sometimes fragmentary reporting on the historical nuances (e.g. the debates on the number of Holodomor victims) and the common presence of (self-)censorship in relation to the contested past, particularly in the case of the Eastern European fractured memory regimes, this results in journalistic outlets often fuelling memory wars. Similarly, reference websites, particularly crowd-sourced ones such as Wikipedia, often become memory battlegrounds where different mnemonic communities try to promote their preferred versions of the past (often aligning with official memory politics; Kaprāns, 2016; Makhortykh, 2017) and suppress alternative views.
The potential for search algorithms to reiterate memory wars by prioritizing sources that fuel these conflicts is amplified by the major ontological differences in the interpretation of the Holodomor depending on the engine and the query. Specifically, in response to Cyrillic queries, we observed the higher presence of results denying the criminal nature of the Holodomor (in particular, on Yandex) together with the larger number of outputs focusing on the comparison between the Holodomor and other Soviet famines. By contrast, Latin queries for most of the search engines (except Google) returned results offering a high estimate of the number of victims (i.e. more than 10 million), thus prioritizing interpretations that are criticized as the form of instrumentalization of the past (Gadzins’ka, 2021).
There are several reasons that can explain the abovementioned differences. The first of them is the unequal distribution of content with specific features (e.g. Holodomor denialism), which can be retrieved via Cyrillic and Latin queries. It is reasonable to expect that contextual factors (e.g. memory politics in Russia) might result in more Cyrillic content criticizing the interpretation of the Holodomor as genocide. At the same time, the very existence of such content does not imply that it has to be prioritized by search algorithms, thus suggesting that the differences we observe can be attributed to the different logic behind individual algorithms.
One example of this logic is the degree to which the search algorithm takes user engagement into consideration when prioritizing sources for a specific topic. While it can be assumed that the engagement is an important factor for most search engines, Yandex is assumed to pay more attention to it than its Western competitors (Niechai, 2020), which might result in a self-reinforcing loop of outlets that offer more engaging (but not necessarily high quality) content (e.g. tabloids) being prioritized and consequently engaged with more by Russian users. Another example is the varying notions of authoritative sources: while both Google and Yandex may prioritize sources of the same type (e.g. journalistic outlets), the exact choice of sources varies substantially with Google prioritizing more independent media, which are often critical of the Kremlin, and Yandex often giving priority to pro-Kremlin media (Makhortykh et al., 2022).
These observations highlight once more that non-human actors, such as search engines, are neither objective nor neutral in their treatment of collective memories. Similar to less complex analogue-focused information infrastructures (Bowker and Star, 2000), search algorithms shape social reality under a certain angle, and, by doing so, become memory warriors actively engaged in the ontological contestation of the past. While examined engines do not offer exclusive support to a specific interpretation of the Holodomor, the substantial variation in the interpretations’ visibility leads to the users’ awareness about the event being shaped rather differently depending on whether they search for it on Google or Yandex. Such differences not only lead to information inequalities, but also contribute to the reiteration of memory wars by exposing users to ideologically charged narratives.
The potential detrimental effect of search engines becoming memory warriors also stresses the importance of thinking about the ways of preventing them from fuelling memory wars. One approach could be to limit the presence of journalistic and reference sources, and instead put a larger emphasis on educational sources in order to decrease the visibility of one-sided interpretations of the past that often reiterate narratives associated with official memory politics. While educational sources can also be part of the memory wars, our observations suggest that they may offer a more nuanced treatment of the ontologically contested subjects as well as offering more scrutiny of new ontological claims.
Another possible solution could be to make users more aware about the ontological contestation of the subject which they are searching for (e.g. by including a disclaimer when retrieving search results). While such a disclaimer can possibly nurture a more critical treatment of the retrieved information, the practical implementation of such a solution will require a list of ontologically contested subjects, which itself may be ontologically contested. Establishing such a list, however, might be easier than finding a universally recognized baseline for Holodomor-related information (or for other subjects of memory wars), which would be required for the consistent prevention of prioritizing undesirable content (e.g. denialist claims).
Finally, it is important to note several limitations of the conducted study. First, it relies on a single search term (‘Holodomor’) written in Latin and Cyrillic script, whereas there are other general (e.g. ‘Ukrainian famine’) as well as more specific (e.g. ‘Holodomor Memorial Day’) terms that can be used to retrieve information about the Holodomor. Future research will benefit from expanding the selection of queries and using them in specific languages (e.g. Ukrainian) to conduct a more systematic audit of the role of search engines in the context of memory wars. Second, the current study looks at performance of search algorithms in a single location (i.e. Frankfurt), while earlier studies (e.g. Kliman-Silver et al., 2015) suggest that location plays a significant role in search personalization. Thus, future studies can examine potential variation in the role of search engines as memory warriors depending on where the user is located.
Footnotes
Acknowledgements
We would like to thank the anonymous reviewers and the guest editors of the special issue for their valuable feedback that helped us improve the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Data collections were sponsored from the SNF (100001CL_182630/1) and DFG (MA 2244/9-1) grant for the project ‘Reciprocal relations between populist radical-right attitudes and political information behaviour: A longitudinal study of attitude development in high-choice information environments’ led by Silke Adam (University of Bern) and Michaela Maier (University of Koblenz-Landau) and FKMB (the Friends of the Institute of Communication and Media Science at the University of Bern) grant ‘Algorithmic curation of (political) information and its biases’ awarded to Mykola Makhortykh and Aleksandra Urman.