
Abstract
In this article, we investigate how the visual, interactional, and interactive verbo-visual selections are utilized to qualify Arabic clickbait thumbnails to get extra views. To this end, we drew upon Kress and Van Leeuwen’s multimodal analysis and Hyland’s meta-discourse framework. The data comprised 100 Arabic YouTube clickbait thumbnails selected from five Arabic channels. Our analysis revealed that a fake clickbait is an ensemble of collaborative modes, each of which reflects an interplay of interactional, compositional, and representational strategic selections. Thumbnail creators tend to structure their thumbnails visually by frequently selecting negative representational actional and reactional processes to induce viewers to click the videos for further information. To accentuate the representational metafunction, the content creators opted for enticing engagement markers and interactive linguistic cataphoric cues that lead the viewers to search for the referents disguised in the videos associated with thumbnails. Emojis, sequences of exclamation marks, and consecutive dots were also used as pressure tactics to click the videos. Such results will hopefully contribute to recognizing fake visual media and raise vulnerable viewers’ awareness against such fake videos.
Keywords
Introduction
YouTube has viral usage among all age groups worldwide. Since May 2019, it has had more than 2 billion monthly viewers and consumers (Spangler, 2019). Consumers prefer video content to other forms because it is one of the most popular (McNeely, 2019) and financially beneficial entertainment platforms. According to O’Neill (2018), 88% of advertisers reflected their satisfaction in 2018 with the financial return of their video marketing. Thus, it has become a fiercely competitive marketing channel to obtain many viewers and customers to guarantee a monetary income. Considering the massive number of audiences and the amount of time spent on video platforms, YouTube makers created a smaller version of a full actual image of a video called ‘thumbnail’ that provides viewers with a preview that could easily be viewed while browsing images. Accordingly, viewers can choose what to watch. Koh and Cui (2022) point out that a thumbnail needs to be visually appealing to grab viewers’ attention to click and view. A catchy thumbnail can make viewers want to watch the video, which draws ‘the benefits of monetizing the public view into some remarkable royalties’ (Riyandi, 2022: 55–56). Bryant et al. (2019: 94) define thumbnail clickbaits as ‘articles with misleading titles, exaggerating the content on the landing page’. They encapsulate luring false news to entice users to click on the title to monetize the landing page.
Therefore, there is a substantial connection between clickbaits and fake content, especially when the actual video drastically under-delivers the content promised in the thumbnail. Thus, some clickbait thumbnail creators exploit viewers’ curiosity and encapsulate fake content to satisfy their cognitive desires (Chakraborty et al., 2016).
The clickbait thumbnail is multimodal, consisting of a preview visual image of a full actual video and a written title. To thoroughly analyze a clickbait thumbnail, we should examine its visual representation and the title associated with the image, as the visual forms may introduce meanings that verbal leaves unsaid and vice versa (Van Leeuwen, 2015: 450). Therefore, the present study aims to use a multimodal analysis to illustrate the integrated use of written language, images, and visual attributes that make these multimodal thumbnails visually appealing. We examine the multimodal strategic cues utilized to construct Arabic clickbait thumbnails to persuade viewers to click the videos.
To meet the purpose of the study, we drew on Kress and Van Leeuwen’s (2006) interactive multimodal framework that can reflect the social relation between producer, viewer, and the visual objects and their compositional metafunction to form coherent thumbnails (Kress and Van Leeuwen’s, 2006: 42–43). According to their framework, the interactive metafunction of an image can be encoded according to participants’ relationship represented by gaze (contact), (social distance), and display angle (attitude). The thumbnail compositional meta-function is realized by placing participants in particular syntagms that relate them to each other and the viewer in terms of left-right and top-bottom. To examine how the thumbnail written titles are composed in terms of the lexico-grammatical options, we utilized Van Leeuwen’s (2008) discourse practice to analyze the ideational meta-function in terms of processes and participants that include material, mental, verbal, and relational processes, each of which involves certain kinds of social participants. On the other hand, Hyland’s (2005) meta-discourse model was used to analyze the interactional and interactive functions. The interactional meta-function is realized by ‘self-mention’, ‘engagement markers’, and ‘attitude markers’. In contrast, the interactive meta-function analysis can convey how information is textually composed coherently in terms of ‘transition markers’, and ‘endophoric markers’.
Thumbnails in video views have been approached from different perspectives. Some have examined the relationship between the viewers’ selection of videos and the persuasive characteristics of genuine non-clickbait thumbnails associated with these videos. For example, Petty et al. (1997) and Kitchen et al. (2014) proposed routes to persuasion: the central route, the peripheral route, or both. In the former, viewers process the content of the message, whereas, in the second, they rely more on the thumbnail’s visual attributes, including celebrity endorsement, colorfulness, brightness, and image quality (Shin et al., 2020). On the other hand, other researchers have focused only on the written titles of fake clickbait thumbnails. They examined their stylistic features and functions and how they were utilized to entice viewers to click the videos related to these thumbnails (see Al-Ali et al., 2023; Biyani et al., 2016; Blom and Hansen, 2015; Kuiken et al., 2017; Pujahari and Sisodia, 2021; Tafesse, 2020; Veszelszki, 2017). For example, Pujahari and Sisodia (2021) isolated the following types of clickbait titles: the wrong, the re-directional, the graphic, the teasing, the inflammatory, the exaggerating, the bait and switch, and the ambiguous. Chakraborty et al. (2016) found that content creators of thumbnail-written titles frequently utilize inspiring expressions, punctuation patterns, and colloquial phrases to spark the users’ curiosity. Veszelszki (2017: 13–17) also found that fake thumbnail titles frequently include more punctuation marks and horrifying and deceptive information to get more views. It is evident that most of these linguistic studies have examined the written headlines of fake clickbaits. However, a dearth of attention has been paid to their visual elements.
Literature review and theoretical framework
Thumbnails need to be informative and visually appealing to persuade the viewers who browse through a video platform. Informativeness can be achieved by giving an idea about the content of the video, whereas the latter can be met by utilizing visual attributes that complement informativeness (Brown, 2017; Funk, 2020; Koh and Cui, 2022). Therefore, thumbnail creators use strategic visual, textual, and stylistic choices to encode informative written content and visual esthetic cues to enhance video attraction success, including celebrity, colorfulness, endorsement, image quality, and brightness (Shin et al., 2020).
The persuasiveness of content and visual attributes of thumbnails have been investigated in various contexts. Deng and Poole (2010) examined webpage design and found that visual complexity includes two dimensions: visual text and graphic diversity and the visual richness of a webpage. According to Lewis et al. (2013) and Kahn (2017), thumbnails express information via two design elements: text and pictures portraying the product and model. According to Luffarelli et al. (2019), high visually complex design images convey more information and are more engaging (Kusumasondjaja and Tjiptono, 2019; Pieters et al., 2010). However, they may hinder viewers in locating specific information (Rosenholtz et al., 2007) and affect communication effectiveness (Geissler et al., 2006).
Drawing on the machine learning (ML) method, many researchers have examined the visual esthetic attributes of good representative thumbnails. Some have focused on celebrity endorsement, colorfulness, and image quality (e.g. Shin et al., 2020). Koh and Cui (2022) found out that a thumbnail having a celebrity picture is more visually appealing than those that do not include any. They also reported that the more design and visual elements a thumbnail has, the more informative and persuasive it is. Likewise, Song et al. (2016) investigated the visual thumbnails’ esthetic qualities and their high relevance to video content to develop suitable frames that humans can choose. They suggested an excellent automatic thumbnail selection correlated with objective visual quality esthetic metrics. To help make automatic inference of whether a thumbnail is clickbait or not, Biyani et al. (2016: 94) utilized an automatic machine method to detect a variety of features extracted from the title and URL of a webpage, including a degree of informality and similarity between title and body.
However, other studies have only focused on clickbait thumbnail written titles. They revealed that creators of thumbnail titles tend to utilize certain linguistic, textual, and stylistic choices to construct persuasive titles. For example, Blom and Hansen (2015) recognized the frequent use of cataphoric forms and unresolved pronouns in thumbnail clickbait headlines. To produce a compelling headline, thumbnail creators tend to include short words, quotes, signal words, and sentimental words (Kuiken et al., 2017: 1312). Likewise, Tafesse (2020) noted that thumbnail creators use negative stimulators and less information to enhance audience engagement. They also utilize horrifying and deceptive headlines to spark readers’ curiosity to click, informal and personal styles to cause ambiguity, and overuse of exclamation marks and consecutive dots to make any situation suspicious (Veszelszki, 2017: 13–17). Moreover, clickbait titles were found to include inspiring expressions, slang words, and various punctuation patterns that can spark viewers’ curiosity (Chakraborty et al., 2016: 3).
The literature reviewed has shown that thumbnails in online social media have been examined from two main perspectives: the machine learning method and the discourse-pragmatic approach. The former attempted to devise objective visual quality esthetic metrics correlated with a good thumbnail. In contrast, the latter focused only on examining the discoursal and pragmatic features of fake clickbait thumbnail titles and their functions in enticing potential viewers to click the baits. Such enticing devices can increase viewers’ engagement and interaction with the post (Beckers et al., 2018), not only in viewing it but also in taking a further step to click it. The latter studies examined only the written titles of clickbaits, whereas they ignored the visual images, and all reference to context is completely missed. Since clickbait thumbnails consist of multimodal modes representing the verbal titles and the images accompanying them, and both contribute to meaning-making, we pursue a dual analysis that focuses on examining the written titles and the visual images to detect what verbo-visual strategic selections are utilized to attract viewers’ clicks. Such an attempt can improve performance in detecting fake clickbait thumbnails and identifying some verbo-visual quality features highly correlated with fake thumbnails.
Dataset and methodology
This study was based on a corpus of Arabic data composed of 100 YouTube clickbait thumbnails. We collected a dataset of 300 videos and their associated thumbnails, from which 100 thumbnails. They were isolated from the following unofficial Arabic channels: 5-Minute Crafts!; 123 Go!; تدري الأ ?alaa tadrii (Don’t you know?); معلومة في كتاب, ma’luumah fii kitaab (A piece of information in a book); and Noor Stars (See List of Arabic Channels). The data came from a period of 1 year covering 2021. The data covered different crafts, sports, entertainment, and science domains. The 5-Minute Craft channel had been placed as the ninth most subscribed channel on the platform. 5-Minute Crafts channel has over 14 million subscribers and over 4 billion views, while 123 Go! has over 7 million subscribers and 3 billion views. The content of such channels consists mainly of videos relating to crafts and life hacks, styled in how-to formats, and, occasionally, science experiments. (ألا تدري) ?alaa tadrii (Don’t you know?) and ma’luumah fii kitaab,(معلومة في كتاب) (A piece of information in a book) are YouTube entertainment channels owned by independent content creators and offer the most exclusive videos, facts, and events. ?alaa tadrii, (Don’t you know?) channel is Saudi, having over 1 million subscribers and over 160 million views. ‘A Piece of Information in a Book’ is Moroccan, having over 6 million subscribers and over 800 million views. Noor Stars is an Iraqi YouTube channel that has gained a massive following for making attractive videos related to beauty, comics, and vlogs. It is the first female channel to reach 18 million subscribers in the Middle East. It reached over 2 billion views. Such media have drawn criticism for their unusual and potentially dangerous life hacks, reliance on misleading content, and exaggerated experiences.
To isolate fake clickbait thumbnails, Biyani et al.’s (2016) framework was found very useful as a coding scheme. They discovered that creators of fake clickbait thumbnails tended to make headlines enticing by using one or more of the following categories: Titles exaggerating the content of the video; Teasing by omitting some details from the video title; Using inappropriate or vulgar expressions; Overuse of capitalization and exclamation marks; Using unclear or confusing titles; Using unbelievable subject matter; and factually wrong content.
Regarding data sampling, we examined the content of the 300 videos to isolate the most prototypical misleading thumbnails that promise viewers things that are not included in or irrelevant to the videos it describes. The content of each video was examined and compared to the clickbait thumbnail associated with it to identify the most likely category it belongs to. We isolated 100 representative instances of clickbait thumbnails. This does not mean that the other 200 thumbnails discarded are completely non-clickbaits, but they have some features of baity and fake content. In contrast, the 100 clickbait thumbnails selected drastically under-deliver the content promised in the thumbnail. To validate the 100 clickbaits coded, 50 thumbnails were selected randomly from the 100 and recoded by two other trained discourse analysts following the coding scheme suggested by Biyani et al. (2016). The coders worked independently and coded the 50 thumbnails. On a check of intercoder reliability, there was an 84% agreement with those coded by the researchers. For videos on which there was disagreement, the researchers and coders recoded the data together until they reached a consensus.
Data analysis
The following sub-sections present the results related to thumbnail metafunctions and the visual and written linguistic strategic options used to realize each metafunction.
Representational/ideational metafunction of clickbait thumbnails
This section focuses on the representational/ideational metafunction of the visual thumbnails and their written titles and how this function is articulated by the various processes and the represented participants involved in these interactions.
Table 1 indicates that the verbal and non-verbal action process presenting unfolding actions is the most frequent (35.6%) in comparison to the reaction process (32%) and conceptual and relational process (28%). The visual action processes constitute 28% of the visual processes, whereas the written material processes make up 43% of the verbal written ones. The following thumbnails exemplify these processes.
Representational/ideational metafunction realized by verbo-visual processes in clickbait thumbnails.
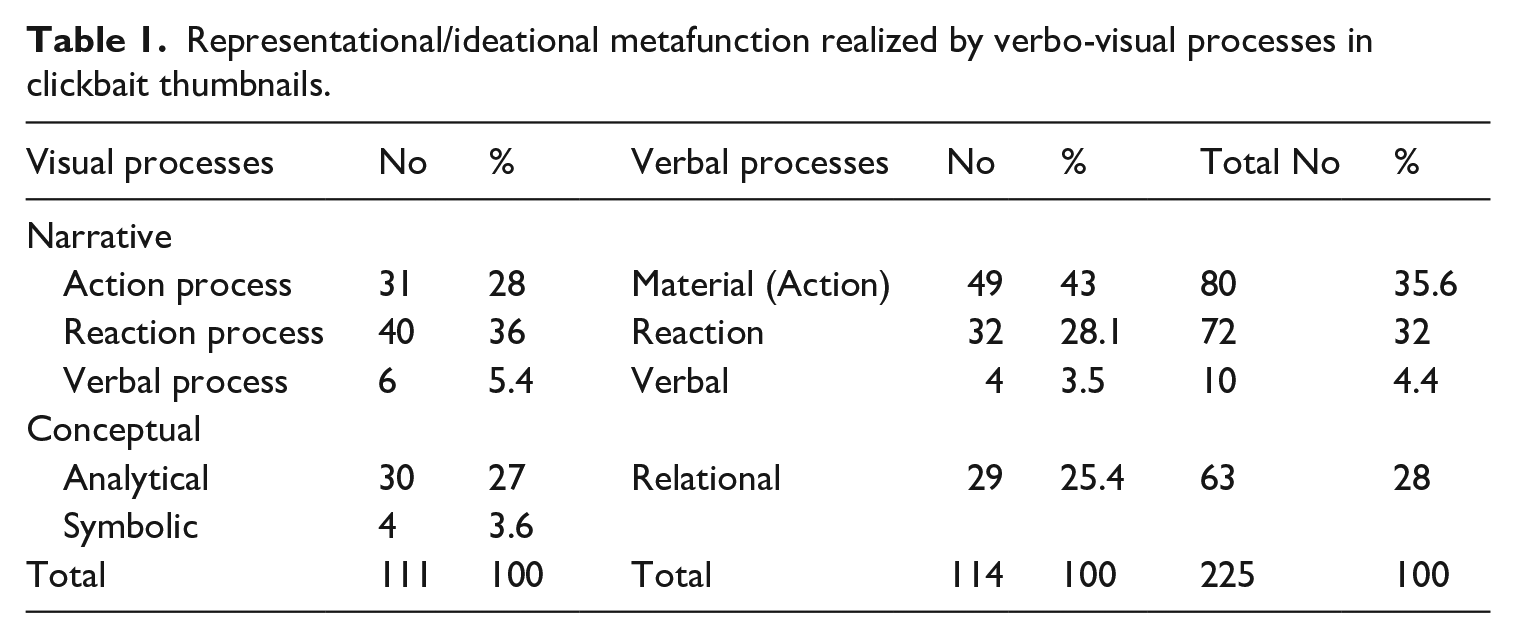
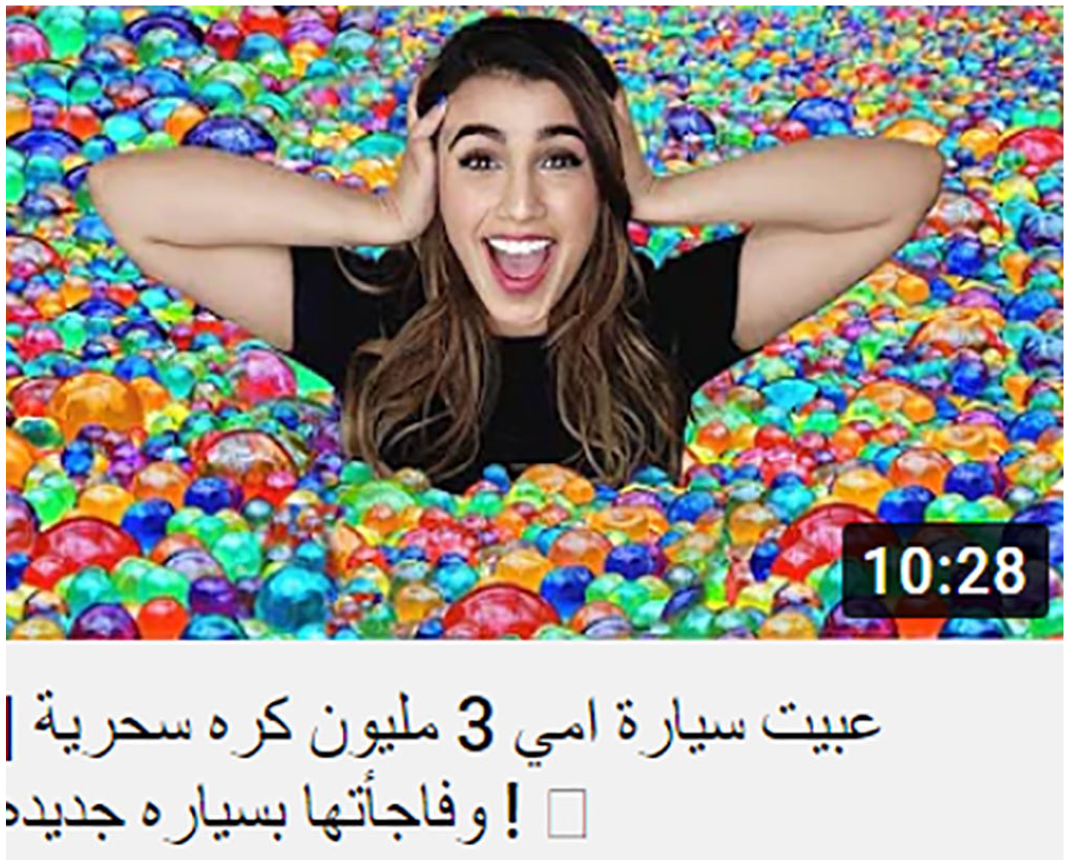
In Figure 1, the clickbait visual thumbnail and the written title associated with it have two actional processes, ‘beat’ and ‘damaged’, each of which has the implicit human actor ‘they’, which is visually realized by the vector that emanates from unknown actor and directed toward the girl’s face (i.e. the receiver of the action). The first singular pronoun, ‘me’, and ‘my car’ are the ‘goals’, respectively. Most of the clickbait thumbnail images included material actional processes realized by negative actions like ‘attack’, ‘beat’, ‘damage’, ‘burn’, ‘prison’, etc.
‘They
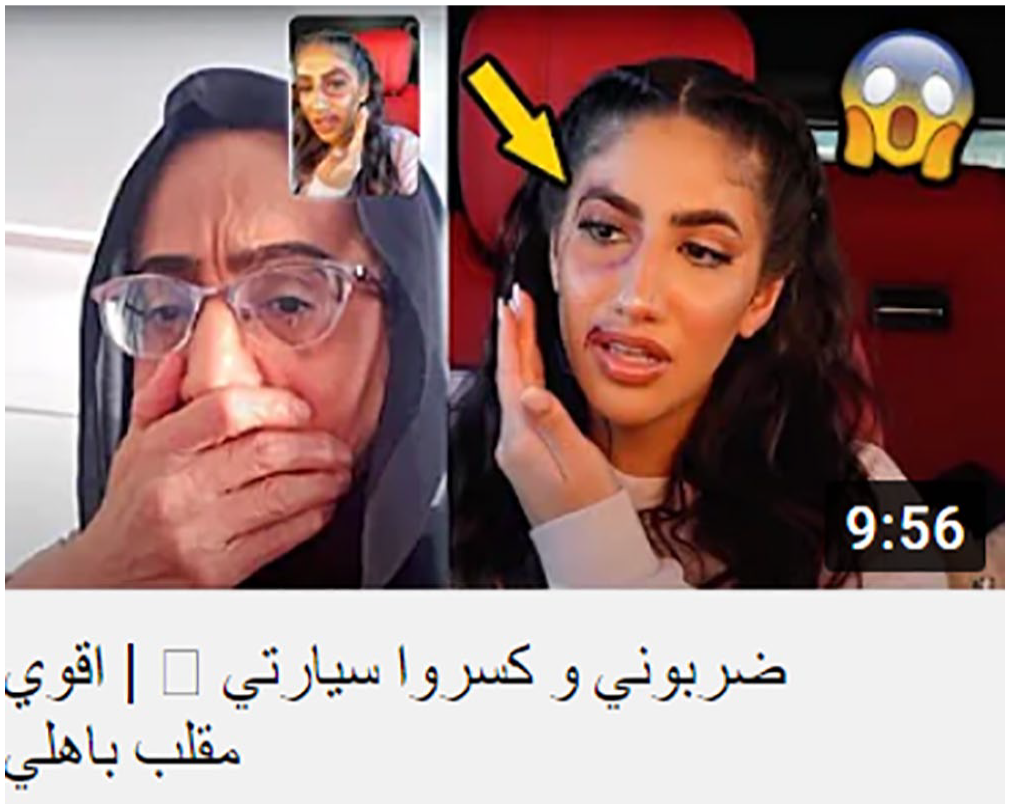
On the other hand, the reaction visual and written processes have two participants: the reactor, the reflector of the reaction process, and the phenomenon experienced by the reflector. This process is a reaction rather than an action. It describes the reflector’s feelings and the phenomenon s/he is involved in, as in Figure 2.
Reaction processes.
Visual Figure 2 includes two reactional processes: The first clause has ‘suffer’ as a reactional process, ‘this girl’ as its ‘reflector’, and ‘a severe itchy nose’ as its ‘phenomenon’. The second has the subject ‘they’ as the ‘reflector’ of the negative reaction process ‘shocked’, and ‘what they found’ as the ‘phenomenon’. The reactional clickbait thumbnails examined have a frequent occurrence of negative reactions (e.g. ‘suffer’, ‘weep’, ‘shock’, ‘cry’, and ‘astonish’) and negative phenomena (e.g. ‘severe itchy nose’, ‘tricks, etc.)’.
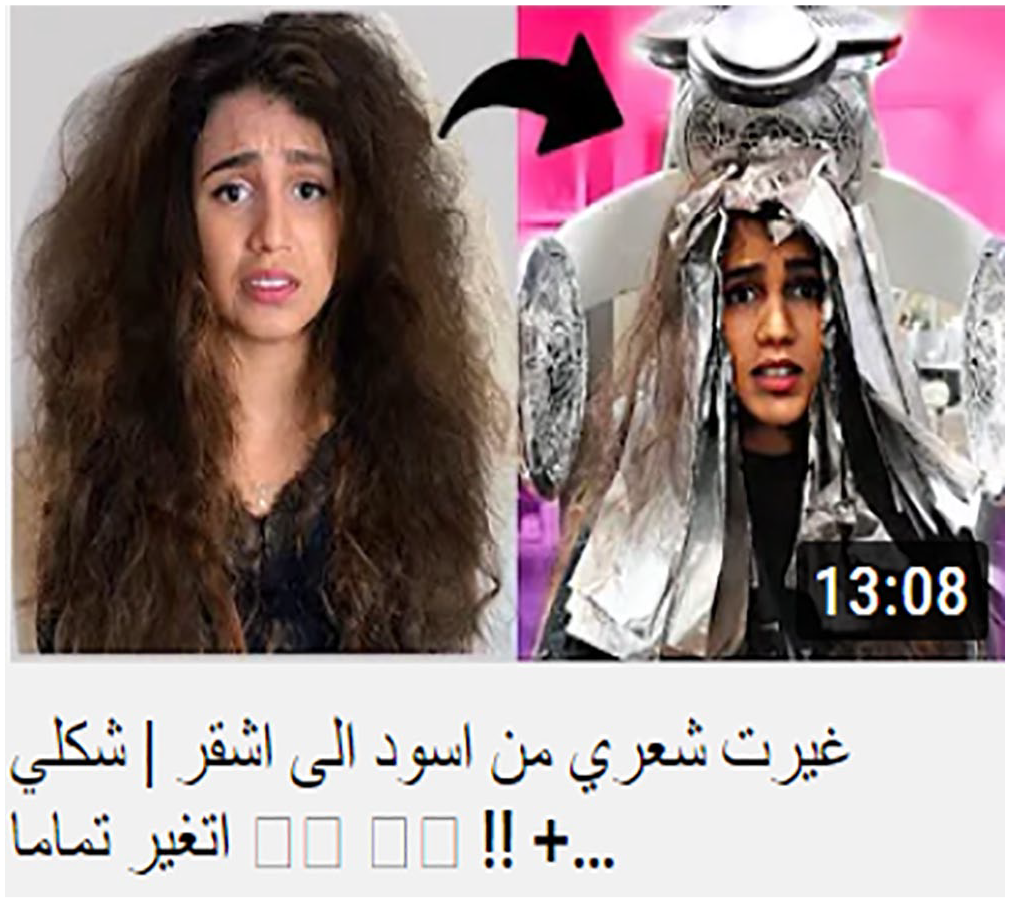
Regarding the conceptual visual thumbnails having relational written titles, Table 1 shows that this process constitutes 28% of the total clickbait thumbnails. This conceptual visual process relates participants to each other analytically or symbolically. The analytical processes relate participants in terms of a part–whole structure. They involve one participant, the carrier, representing the whole, while the possessive attributes constitute the parts. Each visual conceptual image is complemented with a written relational process caption at the bottom. The relational written processes make 25.5% of the total written processes, each of which is typically realized by a topic followed by a complement. The topic specifies the participant’s role (i.e. carrier), and the complement realizes the ‘attribute’ of the ‘carrier’, as it is shown in Figure 3.

‘Astonishing tricks for hairdressing. Astonishing beauty ideas for your hair’.
In Figure 3, the analytical process of hairstyling occurs in two steps. The first represents the girl’s hair before styling, whereas the one on the right presents her after hairstyling. Likewise, the written title associated with this image involves the ‘carrier’ and the possessive attributes. The title consists of two nominal verbless sentences, each of which has a topic presenting the ‘carrier’ realized by ‘tricks’, whereas ‘for hairdressing’ of the first sentence and ‘for your hair’ of the second constitute the ‘topics’ realizing the attributes of these two nominal sentences, respectively.
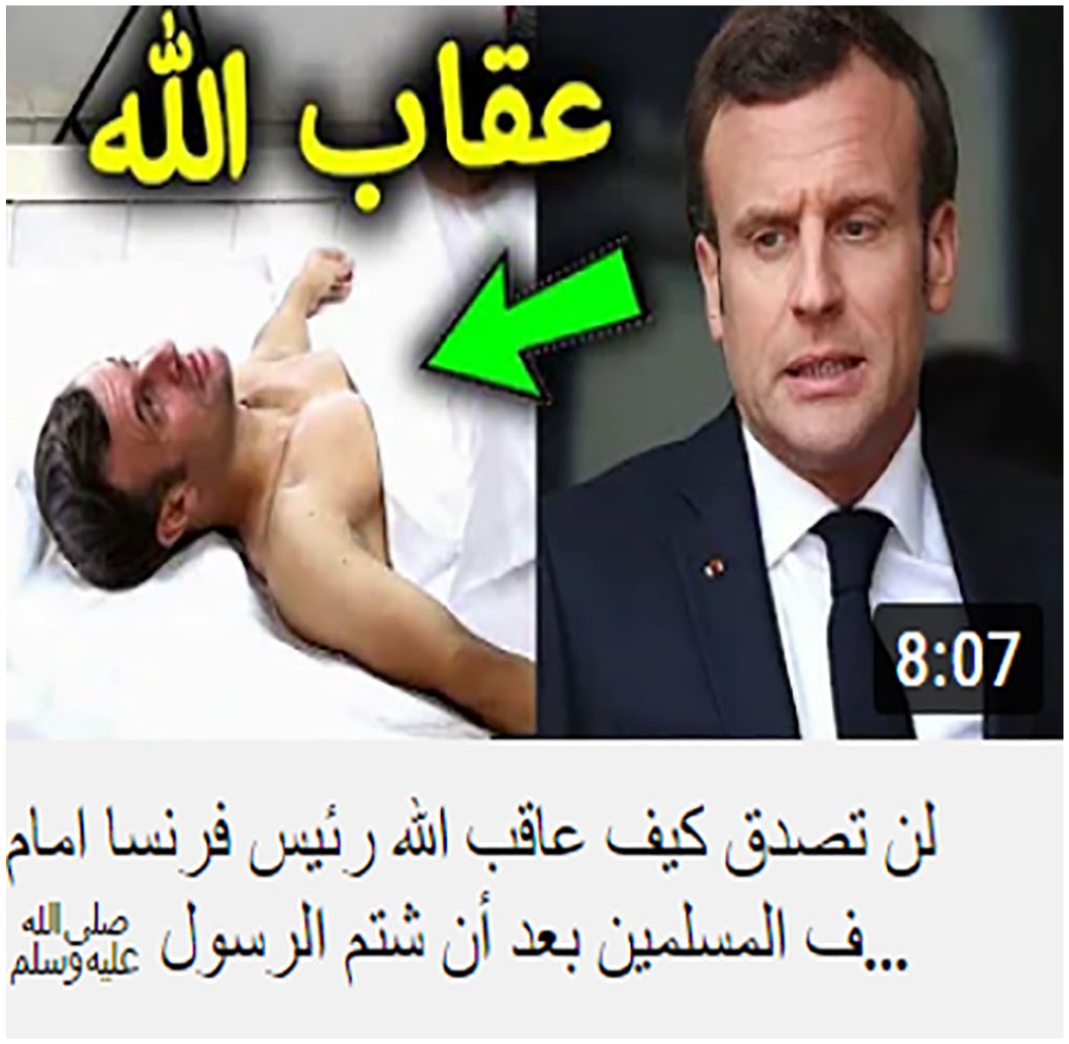
On the other hand, Figure 4 exemplifies the visual symbolic process, which includes the ‘carrier’ of the ‘attribute’, realized by the ‘dead animal’, and the ’attribute’ symbolized by the widespread famine. Figure 4 indicates that the meaning of the carrier as a participant is established by relating it to a specific symbolic value (i.e. famine). As a participant, the dead animal poses for the viewer rather than being involved in an action. This visual image is complemented by the written title consisting of two nominal verbless sentences, each of which has a topic presenting the ‘carrier’ (‘the video’, and ‘a scene’), respectively, followed by the complements ‘made everyone watched it cry’, and ‘that chills one to the bone’ realizing the attributes of these two nominal sentences, respectively.

Visual symbolic process.
‘The video that made everyone watched it cry. . . A scene that chills one to the bone’ (Figure 4).
As can be noticed, these relational processes encode stative meanings presented as if they were facts rather than opinions, as the addressee is told neither bout the ‘who’ (actor) nor about the explicit actions, obscuring the real explicit action, and the actor’s, responsibility.
Interactive/interactional metafunction in verbo-visual clickbait thumbnails
Interactive metafunctions in visual clickbait thumbnails
Drawing on Kress and Van Leeuwen (2006), interactive metafunctions were investigated in visual clickbait thumbnails in terms of the following visual markers: contact, social distance, and angle of point of view/attitude relations between the represented participants and the viewer.
Table 2 indicates that the visual interactive metafunction can be articulated by contact, which can be realized by ‘demand’ (82 instances), or ‘offer’ (58 instances). The left side of Figure 3 shows that ‘demand’ is articulated by the participant’s facial defensive and frightened gesture demanding the viewer to stay away. In contrast, the smiling participant on the right side demands the viewer to enter a positive relationship with her. Figure 4, conversely, does not contain participants looking directly at the viewer; instead, it offers the viewer information to think about. It reflects a widespread famine, where the dead animal as a participant poses for the viewers rather than looking at them.
Interactive metafunctions in visual clickbait.

The social distance reflects the kind of social relationships between the represented participant and the viewer. In the clickbaits analyzed, the intimate relation is the most frequent (56 instances), followed by the personal relationship (20 cases).

Intimate relation.
Thumbnail 5 reflects an intimate relationship in which the head and shoulder parts of the participant are visible. In contrast, Figure 6 reflects a personal relation in which the represented participant’s head and waist are visible. However, the formal relationship rarely surfaces (6 instances); it is realized by the whole Image and the space around it (e.g. Figure 7).

Personal relation.
Formal relation.
The data analysis also revealed that the relation between the represented participants and the viewer could be articulated by the angle of point of view/attitude realized by a frontal eye-level angle, oblique angle, high-level angle and low angle. According to the results, most of the thumbnails (90 instances) displayed participants with frontal eye-level angles reflecting viewers’ involvement. Figure 8 exemplifies a horizontal frontal eye-level shot that indicates involvement and equality between the represented participant and the viewer, whereas 7 represents an oblique shot showing viewers’ detachment (20 instances).
Horizontal frontal eye-level shot.
On the other hand, when the image is taken from a high vertical angle, it expresses viewers’ power, as exemplified by the left side of Figure 9, but it signals the represented participant’s power if the shot is taken from a low angle.
Vertical high-level angle shot.
Interactional verbal linguistic choices in clickbait thumbnails
Hyland’s (2005) metadiscoursal model was utilized to analyze the interactional metafunctions of the written titles associated with the visual thumbnails. Table 3 shows that thumbnail creators opt for three primary strategic markers: self-mention, engagement markers, and attitude markers to realize the interactional metafunction.
Interactional verbal linguistic choices in clickbait thumbnails.

Self-mention
The thumbnail creators utilized a high frequency (61 instances) of the first-person pronouns (I, me, mine) to indicate the represented participants’ presence. The first-person singular pronoun bound morphemes, ت (I) and ي (my) in Figure 10, are used to connect with the addressee and report an actual personal experience.
Attitude markers
In the analyzed data, attitude markers are realized by assessment markers (82 instances), emotional expressions (64 cases), exclamation marks, and emojis to inspire the addressee to express surprise, importance, obligation, etc.
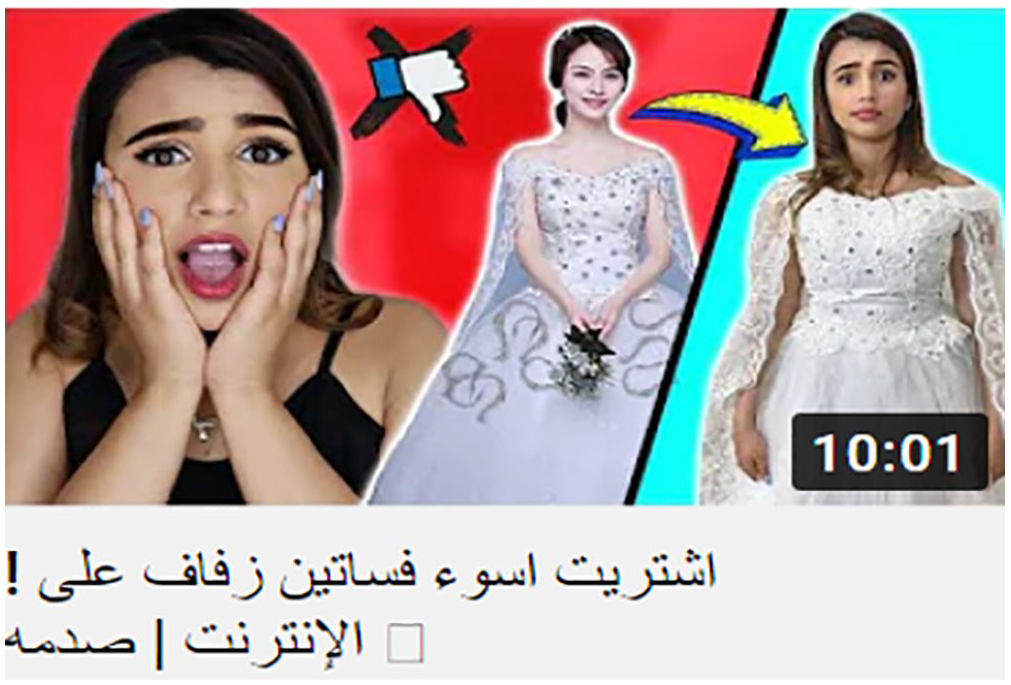
Assessment markers are signaled by comparative adjectives such as أسهل (easier), and superlatives likeاكبر (largest) and أسوء (the worst) as in Figures 11 and 12, respectively. On the other hand, attitude cues are mostly realized by the frequent use of negative emotional expressions (64 examples) such as أسوء (the worst) and صدمه (shock) to reflect the represented participants’ affectional attitude toward an entity they encounter as in Figure 12. Clickbait thumbnail creators also employ successive exclamation marks frequently (70 instances) to reflect astonishment and exert pressure on the target viewer, as in Figure 10.

‘I bought the
‘I bought the
A further attitude marker utilized was emojis (32 instances). They reflect a reactional effect on the part of the viewer to click the videos associated with the thumbnails, as is shown in the titles of Figures 1, 6, and 11.
فاجأني بمليون وردة *مؤثر

“He surprised me with 1 million roses *Touching* ”
These emojis indicate that the shocked emoji, “ ”, reflects a surprise; the crying emoji, “”, symbolizes tears of joy, while the heart emoji, “”, reflects love and gratitude.
”, reflects a surprise; the crying emoji, “”, symbolizes tears of joy, while the heart emoji, “”, reflects love and gratitude.
Engagement markers
Table 3 above shows that video creators utilized the second-person pronouns, directives including the imperative mood and obligation modals, consecutive dots, and informal expressions to structure the thumbnail written titles. The second-person singular and plural pronouns were frequently employed (62 instances) to acknowledge the addressee’s presence. For example, the implicit second-person singular pronoun, أنت(you), in Figure 11, functions as the subject of the imperative verb, شوفو (see). Imperative verbs like ‘look’ and ‘see’ are frequently used. They always have the function of directing the viewers to perform an action or ‘to see things in a way determined by the writer’ (Hyland, 2005: 154). Besides, obligation modals like يجب (must) are meant to pull the viewers to click the videos associated with the thumbnails.
The data analysis also revealed that 45% of the thumbnail titles were written in an informal style. The thumbnail creators often switch from formality to informality within the same title. For example, informal Arabic lexical expressions like شوفوا ايش (See what) are used instead of the formal انظروا ماذا in Figure 11. Such a casual style tolerates colloquial expressions like شوفوا ايش (See what) instead of عبيت,أنظروا كيف (filled) in Figure 8 instead of the formal expression ملئت, and ما بتصدقوا ايش لقيت (You won’t believe what I found) instead of the formal one لن تصدقوا ماذا وجدت. Besides, the titles include many grammatical and spelling mistakes, like the missing hamza (glottal stop sound). The primary function of the frequent use of informal style is to create links of fellowships, involvement, and rapport with the viewers.
Clickbait creators also endeavored to pull their addressees into discourse at specific points by frequently using consecutive dots (38 clickbait instances) to focus the viewer’s attention, as shown in Figures 2, 4, 7, and 15. This strategy is performed by three or four-spaced periods (. . . .) that substitute for a deleted element rather than four dots in a row. Besides, these written titles tend to include asterisk symbols; they are frequently placed before and after the clause to focus readers’ attention (See Figures 5 and 6).
The data analysis also revealed that thumbnail headlines include 20 instances of boosters realized by expressions like ‘تماما’,‘بالكامل’ (completely) as in Figure 10, and من المستحيل (impossibly). Such boosters indicate the creators’ certainty of what they say, which in turn suggests that the viewers confront a confident point of view. On the other hand, hedges rarely surface in the data.
Compositional metafunction in clickbait
The visual compositional analysis of thumbnails shows how the representational and interactional elements are put together in terms of ‘left-right’, or ‘center-margin’. In the clickbait thumbnails analyzed, the left-right value of information is dominant (F = 64) in contrast to elements placed in the center (F = 38). The photograph on the left side of each image includes the given information or background, whereas the right side embodies the new or key information.
The left sides of Figures 13 and 14 present contestable problems that viewers encounter daily, something the viewer is assumed to know already. These problems form vectors leading the viewer’s eye to the photograph on the right, which includes vital information carrying solutions (i.e. using cola to get rid of the stuck gum in 13 and toothpaste as insect repellent in 14).
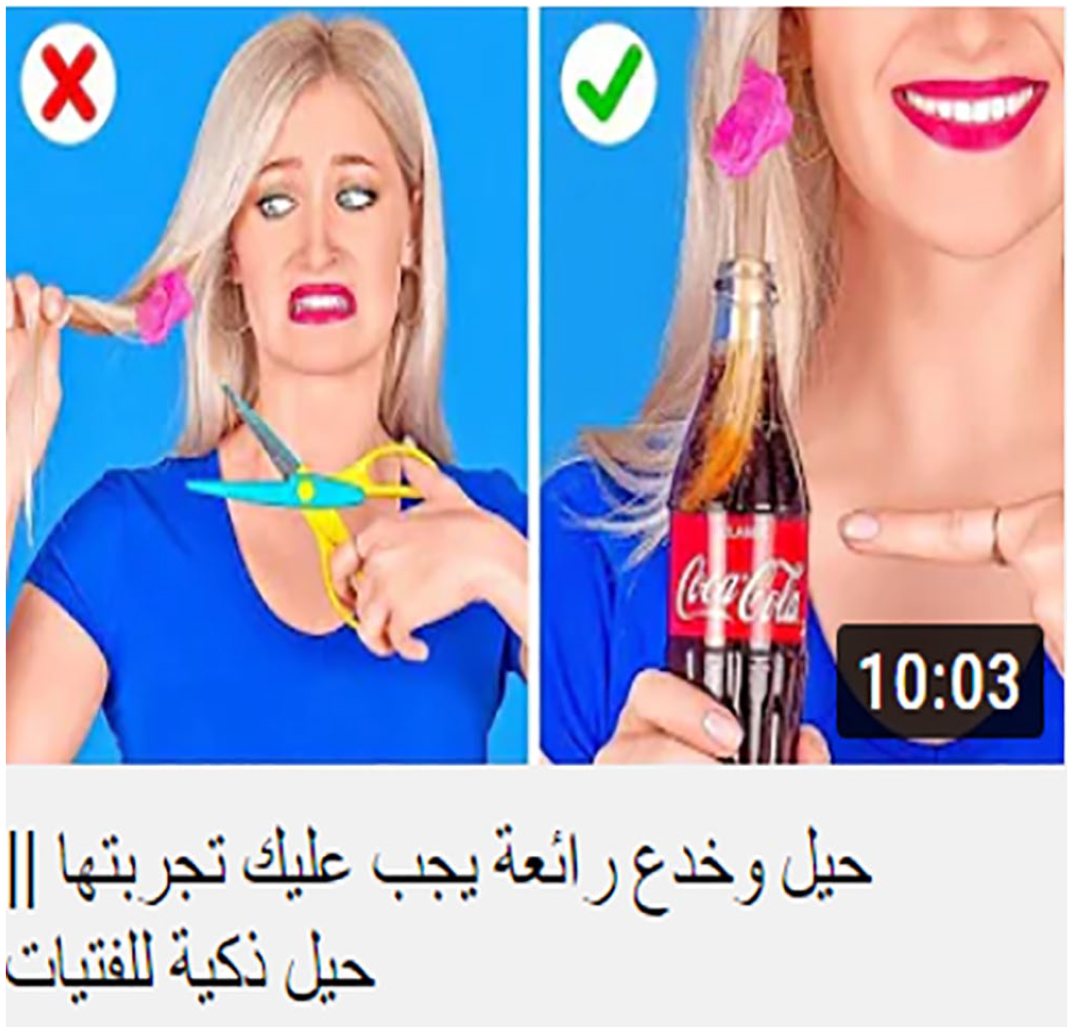
Left-right information.

Left-right information.
The compositional interactive written markers found in the data analyzed were endophoric markers and logical connectives. Endophoric references were very frequently employed. They include cataphoric reference (100 instances) to lead viewers to information in the videos associated with these thumbnails or anaphoric reference (50 cases), which points backward to words or phrases in the preceding clause. Cataphoric reference is overwhelmingly used in these titles, although it is generally infrequently used in written texts. As shown in Figure 15, the phrase, ‘this video’ in the second clause, points forward to the video associated with the thumbnail headline; it inspires the viewer to switch between the thumbnail and the video to uncover what happened.

‘Watch what happened to this man. . . . You will not sleep after watching
The logical connectors were mainly used in the thumbnail titles to express semantic relations between main clauses; they are realized by additives (6 instances), adversatives (10 cases), and causals (12 instances). For example, the adversative function of ‘but’ in Figure 16 is to clarify the adversarial relationship between the two parts of the headline to the reader.
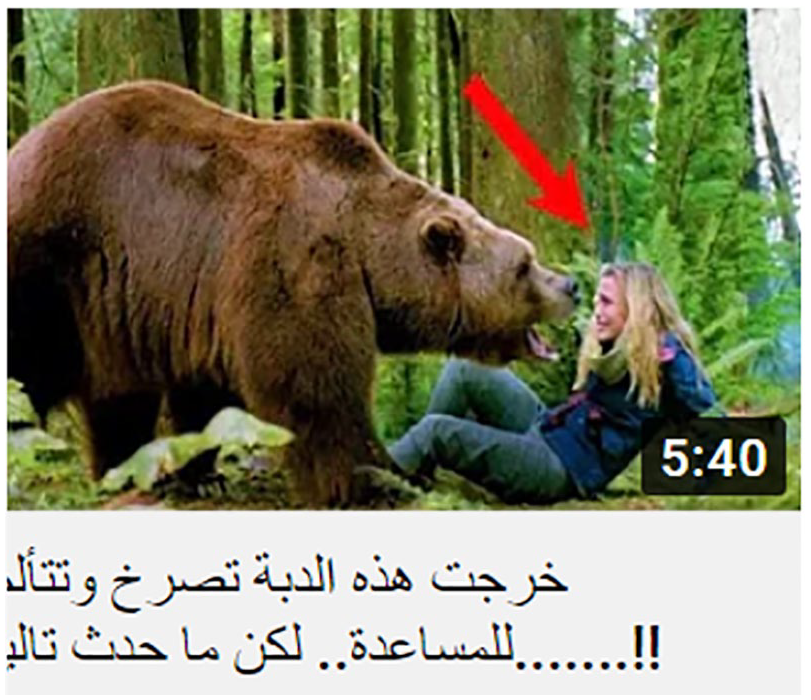
‘This bear came out screaming in pain for help. . . but what happened next was. . . .
Discussion
The data analysis revealed that thumbnail creators put a great effort in selecting and organizing the clickbait verbo-visual content to produce attractive thumbnails and obtain many views. Their primary purpose is to provide viewers with the essence of the videos to foster their engagement and persuade them to click the video. Therefore, these verbo-visual selections are purposive and far from being innocent.
The visual representational and ideational written meta-function informs the viewer about the visual thumbnail’s propositional content and the associated title. To fulfill this purpose, the content creators utilized two complementary modes to create thumbnails, visual images, and written titles. These modes present interaction between the representational visual action processes, including narrative and conceptual ones, and their equivalent written processes articulated by material, mental, relational, and verbal and the participants involved in them. This mode complementarity has been evident in most of the images to provide a vivid characterization of the action and reactional processes. For example, the visual reactional process in Figure 2 is complemented by the written processes to describe the girl as a reflector, suffering from her severely itchy nose. Therefore, viewers are presented with a vivid perception of the thumbnail, sparking their curiosity to click the video for further information. The visual representational and ideational written meta-function of clickbaits is remarkably realized by the frequent use of negative visual images and negative written actional and reactional processes. Negative actional and narrative processes like ‘attack’, ‘hit’, ‘burn’, and ‘scream’, surface frequently. Similarly, negative reaction processes such as ‘shocked’, ‘surprised’, ‘suffered’, and ‘astonished’ are commonly utilized to provoke viewers to click the video associated with the thumbnail to satisfy their curiosity. This result corresponds to Veszelszki’s (2017) finding that the horrifying and fake headlines can spark viewers’ curiosity to click.
The actional processes presenting unfolding actions are frequently used (35.6%). This process is action-packed used to describe doings lively; it functions to spark viewers’ curiosity to enter some imaginary relation with the represented participants to react and click the video for further information about this process. The conceptual and relational processes make up 28% of the total processes. What is noticeable about the written relational process in Arabic is that it is realized by verbless nominal sentences, each consisting of a topic and a complement to convey the intended meaning in short. That is because they exclude the main verbs (i.e. processes) and disguise the participants related to them to one, except for the ‘carrier’. Such a structure qualifies the ‘topic’, which functions as the ‘carrier’ of the attribute, to be further modified by more qualifiers like epithets, classifiers, or adjuncts.
Regarding the interactional meta-discourse, it is meant to create a persuasive representation of the propositional content to facilitate social relationships with the viewers to get them to click the videos (i.e. the bait). Our analysis revealed that the content creators utilized interactional metadiscoursal options such as self-mention, attitude signals, and engagement markers to achieve this aim. The high frequency of self-mentions embedded in clickbait titles was adopted to acknowledge the addressees’ presence, report their personal experience, as shown in Figure 10, and invite potential viewers to undergo such an experience. Furthermore, clickbait titles were found to include affective attitude markers to encode the propositional content of the messages. This strategic option was expressed by assessment markers, emotional expressions, exclamation marks, and emojis as valuable signals to communicate surprise, importance, and obligation to inspire viewers to click the bait. Assessment markers, including comparative and superlative adjectives and visual images, were also frequently employed to reflect the represented participant’s preference (e.g. the ‘largest random box’ in 11 and the represented participant’s negative facial expressions in 12). To increase the effect of attitude markers, clickbait creators tended to include more negative emotion expressions (64 instances). Montgomery (2007) emphasizes that using negative words in any given discourse can spark readers’ curiosity and draw their attention toward a particular event. The attitudinal interactive function of the written thumbnail titles was also complemented by the visual interactive metafunction associated with these thumbnails. The ‘demand’ relation (82 instances) articulated the latter, established by the represented participant’s look at the viewers to connect with them. For example, the left side of Figures 4 and 16 shows the participants’ frightened faces demanding the viewer to stay away. In contrast, the smiling faces on the right-side demand viewers to relate to them positively.
To further accentuate the represented participants’ astonishment and reactions, the thumbnail creators utilized emojis beside the written and visual modes, as shown in Figures 1, 6, and 11, in which the shocked emoji, “”, denotes surprise or disbelief; the crying emoji, “”, represents overwhelming joy; and the heart emoji, “”, indicates love. To exert much pressure on the viewers to click the thumbnail, the thumbnail creators used consecutive exclamation marks (70 instances). According to Veszelszki’s (2017) view, overusing exclamation marks any situation suspicious. Using emojis and exclamation marks impart an informal tone, encouraging viewers to engage with the thumbnail (Al-Ali et al., 2023).
To enhance engagement and shorten the social distance between the represented participants and the viewers, and to reflect equality, the thumbnail creators employed horizontal frontal eye-level and high-level angle shots. Fifty-six images were used to describe the intimate relation with viewers, and 40 were employed to reflect personal relations. The content creators frequently used second-person pronouns, imperative and obligation modals, colloquial expressions, asterisk symbols, and consecutive dots to further engage with the viewers. For example, the second-person pronouns, directives signaled by imperative, and modals of necessity indicate a relationship of solidarity and involvement to pull the viewers into the video to undergo the similar experience the represented participants underwent. Furthermore, clickbait producers attempted to break formality boundaries using informal expressions (45%). They codeswitch from formality to informality, injecting colloquial expressions (20 examples) in the same written title. This agrees with Chakraborty et al.’s (2016) who found a high frequency of slang phrases in clickbait titles. Such a tendency may indicate a growing rapport to enhance the positive face of the interlocutors. However, Veszelszki (2017) assumed that any informal and personal styles in writing can cause misunderstanding and ambiguity.
Furthermore, content creators frequently utilized asterisks and consecutive dots. Asterisks were inserted before and after some constituents of thumbnail titles to attract the viewers’ attention. The latter engagement cue usually includes four-spaced periods or more (. . . .), indicating that they substitute or stand for some deleted constituents. Such a strategic option can be considered an invitation to uncover the deleted elements by clicking the video associated with the thumbnail to satisfy the viewer’s knowledge gap, even though this video may look suspicious. Therefore, engagement cues can be considered viewer-oriented strategies since they add more to the viewer’s involvement than to the thumbnail’s propositional content. These verbo-visual modes interact to provide an intermodal complementarity that sends viewers a clear signal of involvement to engage more and proposes a specific reading of the whole thumbnail.
Regarding the visual compositional metafunction and its equivalent interactive metafunction related to the written titles, the former is more about positioning the thumbnail’s visual elements and their interconnectedness in terms of ‘left-right’, or ‘center-margin’. The interactive meta-function focuses on the relationship between the constituents of the written titles associated with the videos. In the thumbnails analyzed, the photograph on the left side of each image includes given information, whereas the right side embodies new information. A glimpse at the corpus reveals that the designers utilized the left-right value frequently (F = 64) in contrast to elements placed in the center (F = 38). The left-right alignment option represents issues that viewers encounter in daily life. The left side of the image presents a problematic issue; it forms a vector directing viewers to the photograph on the right offering the solution (i.e. using cola to get rid of the stuck gum in 13 and toothpaste as an insect repellent in 14). In other words, such images present visual rhetorical patterns of information structure, including problem-solution and cause-effect relationships. These visual relationships are further complemented by the logical connectives and cataphoric markers signaling the interactive meta-function of the written titles. The written connectives are utilized to link the constituents of the titles. For the cause-effect conjunction relation, one clause embodies a cause or a problem, whereas the clause following it provides the written solution, which cannot be recovered unless the viewer takes a further step (i.e. clicking the video to recover the solution). Concerning the cataphoric reference, it is overwhelmingly used in these titles; unresolved pronouns realized them. Viewers have to find out their referents in the subsequent discourse to make sense of the thumbnail. As shown in Figure 15, ‘this video’ points forward to the video associated with the headline and inspires the viewer to switch between the thumbnail and the video to uncover what happened. This agrees with Blom and Hansen's (2015) and Al-Ali et al.’s (2023) views that cataphoras are luring techniques in clickbaits used in commercial sites to evoke viewers’ curiosity to click the links.
Conclusion
We have attempted to provide insightful multimodal and metadiscoursal analyses of the visual and verbal strategic selections adopted to construct and qualify clickbait thumbnails to increase their views. This analysis showcases how the visual and written modes interplay to index the clickbait thumbnails’ visual and linguistic characteristic features. It reveals that a clickbait thumbnail is an ensemble of collaborative multimodal modes, each of which reflects an interplay of interactional, compositional, and representational strategic functions. Each meta-function has a particular affordance of meaning that contributes to the overall function of the thumbnail (i.e. enticing the viewers to click the videos). Our analysis reveals that constructing an alluring thumbnail undergoes three stages. The thumbnail creators first provide visual and written representational content. Then the interactional visual and verbal linguistic selections are added to qualify and enhance this core content and provide a vivid characterization and persuasive representation. The final representation incorporates the positioning of the visual elements and the structuration of the written titles associated with the thumbnail.
Clickbait creators structure their texts interactionally using more enticing attitude and engagement markers, and self-mentions to emphasize a closer relationship with viewers to persuade them. This tendency is further heightened by deliberately leaving parts of the headlines opaque, realized by the frequent use of consecutive dots, interactive compositional selections attained by cataphoric markers, and viewer-attitude connective signals.
To secure more clicks, the thumbnail creators opt for frequently selecting negative visual and verbal actional and reactional processes that reflect how the represented participants affect the things they acted upon negatively and how the represented participants react to the phenomena described. They also opt for non-actional clickbaits using conceptual and symbolic images together with verbless clauses expressing some stative reality, portraying a part-whole relationship, and symbolizing how the represented participants pose for the viewer. To further accentuate the representational meta-function of clickbait thumbnails, content creators frequently use enticing attitude and engagement markers, and self-mentions to induce viewers to click the baits. Besides, interactive compositional linguistic selections like cataphoric cues are often utilized to direct the viewers to find out the disguised referents by clicking the bait. Emojis, sequences of exclamation marks, asterisks, and consecutive dots are also utilized to attract the viewers’ attention. Such cues function as pressure tactics exerted on the prospective viewers to click the videos so they can undergo the overwhelming joy, disbelief, or astonishment experienced by the represented participants to fulfill their curiosity.
This complementary multimodal analysis has revealed much about the nature of clickbait thumbnails’ visual and written characteristic features and how the multimodal and metadiscoursal visual and linguistic features collaboratively and persuasively qualify the clickbait thumbnails secure extra responses. Such results will hopefully contribute to the recognition of fake visual media, which can frustrate viewers and discover different novel perspectives in media analysis. Such a step is required to raise inexperienced vulnerable viewers’ awareness of such enticing fake videos. It can assist in detecting and recognizing such clickbaits as a further step to avoid watching or demoting them.
Nevertheless, this study is not without limitations. Firstly, the sample chosen for the analysis may appear inadequate as it includes 100 clickbait thumbnails. Further research should collect data from more informal channels covering more topics to further generalize the results. Secondly, our study focuses on analyzing and interpreting what the visual and verbal cues of thumbnails might mean. Still, it does not consider what viewers think or do in their actual interaction with these thumbnails or to what extent their features entice them. To counter this, Cameron (2001) suggests that analysts’ subjective claims can be reduced by going beyond the texts analyzed to explore viewers’ interpretations of these texts. Our analysis can be extended further using critical multimodal analysis to investigate the differences between fake clickbait thumbnails and genuine non-clickbaits regarding their visual and verbal attributes. To improve the detection of clickbaits as a timely topic, it would be valuable to complement our multimodal analysis with a machine-learned model to help viewers differentiate between fake clickbaits and genuine ones.
List of Arabic channels
5-minute crafts. About [YouTube Channel].
https://www.youtube.com/channel/UCy7QvWo7uV_AcoLJL5RIwkQ/about
123Go! Arabic. About [YouTube Channel]. https://www.youtube.com/c/123GOArabicArabic/about
ألا تدري About [YouTube Channel]. https://www.youtube.com/channel/UCnk3aVDgs2i_2cDl_YYhWow/about
معلومة في كتاب About [YouTube Channel].
https://www.youtube.com/channel/UChWczoJxcrAk-XwyIoHLJuQ/about.
Noor Stars. About [YouTube Channel].
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.