
Abstract
The variable nature of wind, including wind speed, direction, barometric pressure, and air temperature, presents significant challenges for accurately predicting wind power output. This paper addresses the issue of contextual prediction accuracy, highlighting limitations of existing methods in analyzing temporal information in depth. It introduces a Transformer-based Dynamic context-aware power forecasting model that combines the Long short-term memory (LSTM) to enhance contextual wind power prediction. The model identifies significant factors influencing wind power generation and integrates various conditions affecting wind power output into a unified embedding. To improve the forecast accuracy, the model adopts a two-layer architecture. The first layer uses LSTM units to extract essential temporal features from the data stream. The subsequent layer utilizes the Dynamic context-aware model's hierarchical multihead self-attention mechanism to discern global information and contextual interrelations. The results reveal that the LSTM-based dynamic context-aware model significantly outperforms other models in forecasting wind power plants output.
Introduction
The wind energy resources assessment is crucial to predict energy performance accurately. The capacity and efficiency of wind turbines have increased significantly in the scientific community as a vital asset for global sustainable development, supporting wind spread adaptation and decreasing costs in electricity generated by wind turbines.1,2 However, it is complex because wind turbine technology involves nonlinear and time-changing uncertainties in wind-related forecasting. 3 Researchers made continuous efforts in related fields to explore techniques to predict short-term wind speed using mathematical models and machine learning algorithms to advance the efficiency and cost-effectiveness of wind energy systems.
Researchers have used deep learning procedures such as recurrent neural networks (RNN) to analyze loads data from high-dimensional load. However, the original RNNs are difficult to handle due to gradient vanishing and long-term dependency problems.4,5 Thus, Oslobo et al. introduced the long short-term memory (LSTM) algorithm by inserting cell states into RNN. 6 The LSTM algorithm may be influenced by parameters with a larger number, which ultimately leads to overfitting. 7 Kim et al. also introduced an algorithm, such as GRU, to decrease the number of intrinsic parameters, thus reducing the risk of overfitting based on the simplest model. 7 Furthermore, Almuzaini et al. propose the Bi-GRU algorithm to fully exploit current and past data. This model is also a combination of the attention mechanism, highlighting significant features of the data. The authors established the capability of the proposed algorithm to improve the accuracy and efficiency of classification. 8
Deep learning has appeared as an emerging method for processing complex temporal data in many domains recently. It has made notable achievements in natural language processing, deep learning, and various combination methods, 9 including long short-term memory (LSTM), 10 convolutional neural networks (CNNs), and other commonly used models for power prediction. Deep learning designed for wind farm clustering has increased the accuracy of prediction and capturing complex dependencies in the case of time series forecasting. 11 Deep learning models possess a wide range of possible practices in time series forecasting, with a particular focus on solar and Wind power potential. Scientists have studied many deep learning frameworks that outclass in catching temporal dependencies, handling data sequences, and increasing prediction accuracy.
Moreover, considerations and limitations, such as interpretability, training efficiency, and handling missing or noisy data specific to each architecture, must also be taken into account while handling sequential data. 12 Time series predictions have a huge scope in developing deep learning hybrid models, where they can improve the performance and address the related limitations. A Hybrid model is a combination of two or more architecture networks to gain the benefits of each network and better interpretability, improving prediction accuracy and more efficient dealing with data limitations.
Transformer is perhaps one of the most successful sequence modeling architectures, representing unprecedented performance in numerous applications such as natural language processing (NLP) and speech recognition.13,14 Recently, there has been a great increase in transform-based solutions for time series analysis. 15 The notable popular models focusing on the challenging and less discovered problems of time series long-term forecasting (LTSF) comprise LongTrans, Informer, Autoformer, Pyraformer, and Triformer.16–19 The main achievement of Transformers lies in its self-multihead attention mechanism, which has the remarkable ability to extract semantic associations between elements of a large sequence (2D patches in images or words into texts). However, self-attention is an immutable permutation and to some extent “anti-order.” Although some ordering information can be preserved using various types of position coding techniques, it is still inevitable that the temporal information will be lost after peak self-attention. In semantically demanding applications such as natural language processing, this is generally not a serious problem. For example, if we rearrange some words, the interpretive meaning of a sentence remains largely preserved. Nevertheless, there is typically a limitation of semantics in the numerical data when dealing with time series data, where we are primarily concerned with modeling temporal changes between a set of continuous points.
This paper addresses the challenges of low forecast accuracy arising from the inability of existing methods to comprehensively analyze temporal data by proposing a dual layer time series Transformer-based Dynamic context-aware power forecasting model combined with LSTM (Long-short-term memory) to filter irrelevant noise out for wind power forecasting. The model starts with correlation analysis to identify key factors affecting wind power and gathers various conditions into an integrated contextual embedding. It employs LSTM to distill the essential temporal features extracting, and structuring dependencies from the raw data, followed by a Dynamic context-aware hierarchical multihead self-attention mechanism to recognize the global information and interrelationship. This method detects important features of the current interval and tackles challenges such as computational demands and temporal forecasting limitations to enable accurate time-series wind power forecasting. Moreover, a comparative analysis is established against three available forecasting models: Gated Recurrent Unit (GRU), LSTM, and Transformer. The results reveal that the Dynamic context-aware model significantly exceeds these models in forecasting power output for wind power plants.
Related work
Machine learning methods that include transforming time series data into a suitable form for supervised learning are extensively employed in time series forecasting. 20 The predominant methods include SVR, which fits linear regression model problems; Light Gradient Boosting Machine (LightGBM), a framework for gradient boosting that employs decision tree-based algorithms learning; and extreme Gradient Boosting (XGBoost), an application of algorithms boosting with the technology improvement.21,22 Moreover, deep learning models have a vast application predicting time series, including RNN, which has memory capabilities with recursive process; GRU, an alternative of LSTM that improves computational efficiency and simplifies the structure of the model; LSTM, to handle long-term dependencies, and efficiently achieve series features; 1D convolutional neural networks (1D-CNN), which can easily capture short-term spatial information and local dependencies; and Transformer model, which is ideal for long-term dependencies modeling and time series interaction forecasting, however unable to extract temporal features. 23 Since the publication of the Transformer model in 2017, it has made remarkable progress in natural language processing. 13
Time series forecasting such as Traditional statistical models, is generally based on autoregression (AR) in which the past forecast is demonstrated as a linear function of earlier observations. 24 It is appropriate for unweighted data with no seasonality or trends. The autoregressive moving average (ARMA), which is of AR and MA combination, models the next forecast sequence residuals from past observations as a linear function. 25 The autoregressive integrated moving average (ARIMA), which represents wind power forecasts, is appropriate for time series univariate data with trends but not with seasonality. 26 Seasonal Autoregressive-integrated moving average (SARIMA) represents the sequence of the next prediction as a linear function of previous observations, such as seasonal errors and observations. 27 The methods mentioned above possess productive efforts to model the time series dynamics data but generally acquire extensive engineering feature engineering and achieve poor performance in prediction.
The Transformer model has been extensively used in different fields, including time series prediction, document retrieval, and image processing. 28 The transformer encoder-decoder models are composed of a point-wise CNN layer, a self-attention layer, and a one-dimensional CNN layer. With the combination of referred constituent layers, the encoder excerpts the spatiotemporal compressed features from the time series multivariate data from the decoder similar structure layer. Furthermore, a temporal attention pattern method to select relevant multivariate forecasting time series is also advised by Shih et al. 29 Samaher et al. proposed artificial intelligence (AI) algorithm and mixed-integer programming to adjust flight altitude dealing with real-time data through comprehensive performance metrics. Techniques like team work optimizer were also used to get higher accuracy in green energy sources such as fuel cells.30,31 Du et al. also proposed a combined attention mechanism in a structure like an encoder–decoder to excerpt multivariate correlations. 32 Zhou et al. presented the attention mechanism twice to represent both dependencies among variables and temporal patterns. 16 Several variants of Transformer are proposed for time series forecasting, such as Longformer, Reformer, Powerformer, and Informer.33–36 Currently, more and latest techniques and methods are adopted in the field of wind farms, such as the adaptive decomposition method combined with the Quaternion convolutional long-short-term memory neural model to predict wind speed in the northern Aegean islands. 37 Wind speed prediction using a machine learning approach and a Sentinel family satellite imagery, as well as Wave power prediction involving a bidirectional convolutional model based on efficient decomposition with a Nelder-Mead equilibrium optimizer, are practiced. 38
Data processing
Data acquisition
The data of a 50-MW wind power plant are employed in this research which contains local measurement data from 32 different wind turbines in Jhimpir city site, Pakistan. This site dataset documents electricity production at 10-min intervals, resulting in a dataset of 52,560 records from February 16, 2022, to February 17, 2023. The dataset includes five attributes: temperature (°C) and atmospheric pressure (hPa), wind speed (m/s), wind direction (°), and relative humidity (RH). It also includes corresponding Numerical Weather Prediction (NWP) data, covering 32 wind turbines, temperature, pressure, relative humidity, wind direction, wind speed, and wind power output. One anther data set is also employed from a real-time wind power plant of 30 MW from a wind farm of Texas including wind speed, direction, atmospheric pressure, and temperature. The integrity of the dataset is critical for the impact of deep learning models. Fixing missing data and other anomalies in datasets is crucial to improve model accuracy, reduce computational effort, and enable effective training. Missing values can significantly affect the accuracy of forecasting models in time series analyses based on continuous data streams. In this study, linear interpolation was used to impute missing values. In addition, due to the different scales between parameters, data normalization is essential to avoid bias toward higher-rank variables and ensure equal consideration of features. Normalization also speeds up algorithmic calculations and convergence during the training process. Noise reduction techniques such as Kalman Filter and min–max scaler method are used to normalize the data to a range [0, 1].
39
The normalization formula is expressed as follows:

Dataset creation
The dataset should be structured as a supervised regression task for operative time series prediction using deep learning with defined inputs and outputs. Here, X indicates the input data matrix for forecasts, where X∈Rn×5, with n = 144 corresponds to the number of time intervals predicted, with 5 signifying the selected weather features for each interval. The output matrix Y, where Y∈Rn×1, shows the predicted power values for the n intervals. The dataset undergoes a random split, with 80% dedicated to training the deep learning model and 20% dedicated to testing its accuracy and performance.
Methodology
Wind power generation forecasting is challenging for multivariate time series, which are affected by various climatic features such as wind speed, direction, humidity, and temperature. A LSTM model captures the features of multivariate time series, but they can easily overfit large dataset, require significant memory, and limit to interpret and handle long-range sequences. Besides, the self-attention mechanism in the Transformer-based frameworks instantaneously reflects all positions in the input sequence, regardless of the distance between features. To overcome these challenges, this study presents a novel time series Transformer-based Dynamic context-aware power forecasting model with a combination of LSTM model for processing time-series data for long and short-term while extracting and structuring features from raw sequential data. The model starts with correlation analysis to identify key factors affecting wind power and gathers various conditions into an integrated contextual embedding. It employs LSTM to distill the essential temporal features extracting and structuring dependencies from the raw data, followed by a Dynamic context-aware hierarchical multihead self-attention mechanism to recognize the global information and interrelationship. This method detects important features of the current interval, and tackles challenges such as computation high demands and temporal forecasting limitations accuracy to enable accurate time-series wind power forecasting. The contextual dynamic model can identify complex relationships in multivariate time series. The framework of the proposed model is presented in Figure 1.

Flow chart of wind power forecasting for dynamic context-aware power forecasting model.
LSTM-based embedding
The mechanism of self-attention mechanism in the encoder-decoder network may struggle to effectively capture sequential data. Even with the integration of scalar, local, and global time stamps (including units such as durations like minutes, hours, weeks, months) as location embeddings, the model's capacity to derive features from time series data can be limited. To address this, an LSTM layer is introduced postembedding to harness its strong capability in learning temporal attributes and sequential information. 16 The standout feature of LSTM is its management of long-term data dependencies. It employs a “memory cell” that maintains and transmits information over prolonged intervals, allowing it to adeptly discern temporal dependencies and patterns in sequences with extended time gaps. The output from the LSTM not only reflects insights from various time steps but also captures hidden node data from each of those steps, thus enhancing the model's proficiency in recognizing hidden details at every stage. This process is detailed in Figure 2. After passing through the embedding layer, the time series data is processed by the LSTM layer to pull out temporal features. This extracted information from each node's hidden layer is then utilized as input for both the encoder and decoder.

The structure of LSTM-Dynamic context-aware power forecasting model.
The formula is as follows:


Where the t-th node output formula through LSTM:



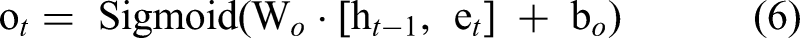


Transformer layer
This research employs a Transformer architecture composed of an Encoder and a Decoder, each built from multiple identical layers. Every layer integrates two key components: a position-wise feed-forward neural network and a multihead attention mechanism, as illustrated in Figure 3. To enhance model performance and data flow, residual connections and layer normalization are incorporated.
25
The attention mechanism is formulated as a mapping from a query to a combination of key-value pairs,
13
utilizing scaled dot-product attention, mathematically represented as:





Structure of transformer model.
This allows each input position to attend to all other positions in the sequence, capturing contextual relationships effectively

Context-aware embedding
Context-aware Embedding Context-aware embedding is a good collection in Dynamic context-aware power forecasting models as it is good to capture and utilize contextual information that processes an entire sequence within the data rather than focusing on individual elements in isolation.
40
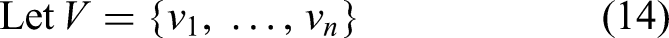

Let Li be the i-th context utterance, then

Hierarchical multihead self-attention
In this section, an approach to reduce the computational and space requirements associated with using the H-MHSA mechanism is presented. Instead of focusing attention on the entire input, a hierarchical strategy is adopted that allows each stage to process only a limited number of tokens.


The values and query, key is then calculated by

Where




Since the local attention feature



Then we calculate the query, key, and value as follows


The final output of H-MHSA is written as

Evaluation metrics
To evaluate the efficiency of a predictive model or algorithm, the evaluation metrics can be utilized. The numerical quantities help us assess, how best a model or algorithm resolves a problem. It is probable to develop measures using both quantitative and qualitative methods. In addition, it allows the comparison, of numerous models by providing objective criteria against which the effectiveness of a model can be evaluated. 42 In addition, evaluation metrics help make knowledgeable judgments about applying a model to an assigned task and determine its complete effectiveness. Therefore, they also help evaluate the satisfaction of a particular problem's accuracy, generalizability, and consistency.
Mean absolute error (MAE)
The evaluation method employs the absolute average deviation between predicted values and observed values to decide. In this method, any changes in the data are considered the same.

Mean square error (MSE)
This metric is calculated by squaring the difference between the actual values and predicted, placing greater emphasis on larger deviations by penalizing them more heavily.

Root mean square error (RMSE)
Root mean square error (RMSE) is a well-known used metric for evaluating the precision of predictive models. It is computed by considering the square root of the average of the squared differences between the predicted and actual values. Due to its sensitivity to large errors, RMSE is considered a crucial indicator in evaluating model performance.

Correlation
Coefficient of correlation is used to show the strength relationship between any two variables which has an absolute worth less than one or equal to one. The absolute value reaches to 1 to represent the linear correlation between two features. It is usually expressed as Pearson correlation coefficient (r) which has a range from −1 to 1 with n data points each showing “x” and “y” which is expressed as:

Results and discussion
Data description
The dataset used in this study is one year data from a 50 MW wind power plant situated in Jhimpir city of Sindh province of Pakistan and 30 MW wind power plant of Texas. It consists of seasonal trends and patterns highlighting wind power generation and variations over a period of 2 years. Annual fluctuation output of different variables, such as wind speed, temperature, wind direction, and humidity, are highlighted. Historical data play a crucial role for developing accuracy in predictive models and strategies examining these input variables and utilizing time series data. Variables like temperature, wind shear and humidity are key features in considering forecasting model. The integration of these models through mathematical relationship correlates with wind power and other external environmental key factors. Even though in this study does not tackle these environmental factors directly, but the modelling approach incudes them mathematically in order to enhance the accuracy and develop a better understanding to forecast within the boundaries of available time series wind power data.
Results and discussions
To forecast wind power, a series of GRU, Bi-LSTM, Transformer, and an innovative Dynamic context-aware power forecasting time series model with combination an LSTM is employed to predict wind power plant output. This model is executed and evaluated on an Intel i7 processor coupled with an NVIDIA Quadro RTX 6000 with 16GB of RAM. The model's various algorithms were developed and refined using a both datasets, divided into 70% for training, 15% for validation, and 15% for testing. 45 Figure 4 depicts the frequency histogram of the actual data available.
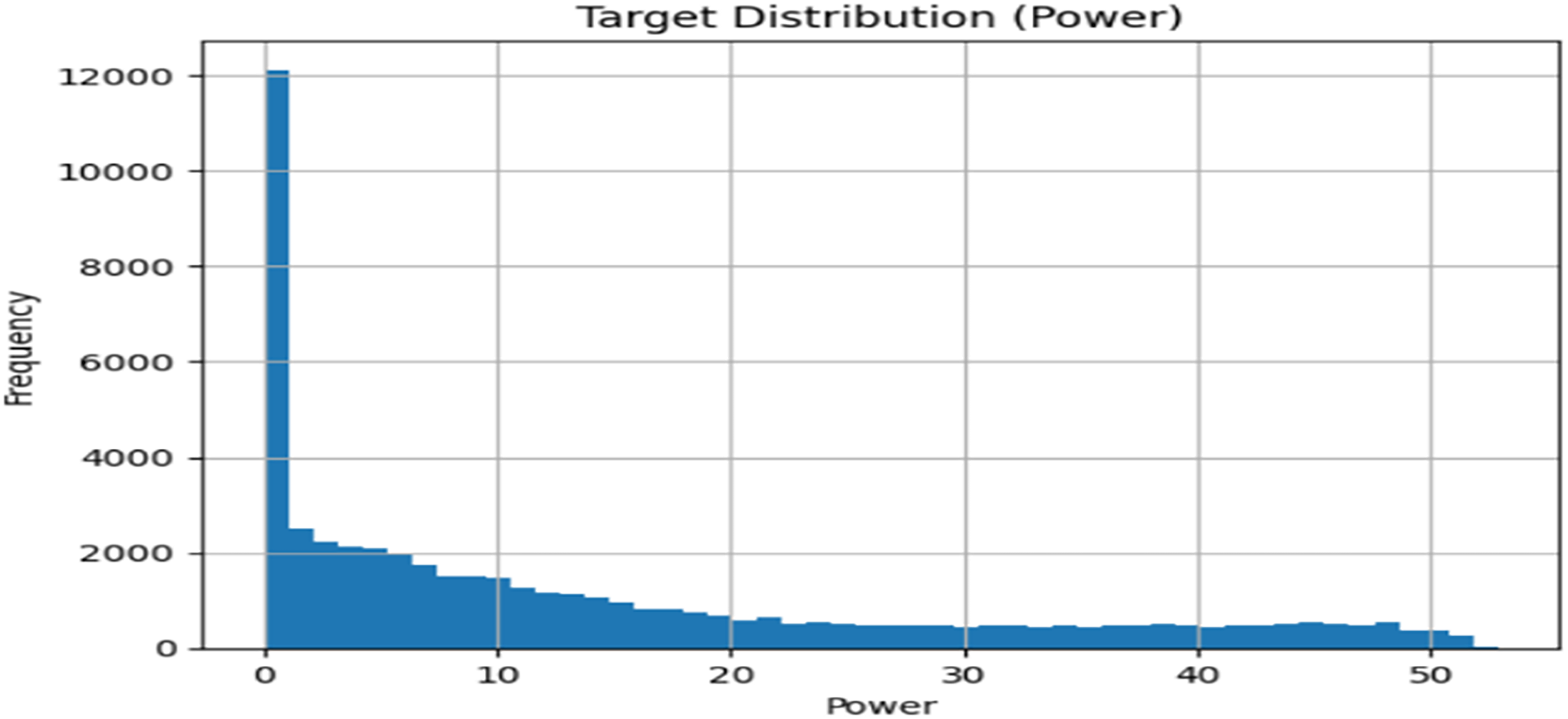
Frequency histogram for the actual wind power plant of Jhimpir dataset.
The learning rate for the model is configured at 0.001, utilizing an Adaptive Moment Estimation Optimizer (ADAM) for training. Training and validation of the models occur on their respective datasets, with the LSTM-Dynamic context-aware model's validation and training losses displayed in Figure 5. The performance metrics for the GRU, Bi-LSTM, Transformer, and LSTM-Dynamic context-aware models are shown in Figure 6 and 7, while their average normalized scores are presented in Tables 1 and 2. Further evaluation of the LSTM-Dynamic context-aware model with different optimizers like Adam, Adamax, Adagrad, and RMSprop is detailed in Figure 8, with normalized average values in Table 3. These optimizers were used to enhance and test the model's predictions for both Jhimpir and Texas wind power time series dataset. Among them, the Adam optimizer yielded the most favorable outcomes, with the lowest average error values of 1.262, 1.721, and 2.523, while adagrad with highest values 1.747, 2.351, and 4.240 for normalized mean NMAE, NRMSE, and NMSE, respectively, indicating that different optimizers can significantly impact model performance.
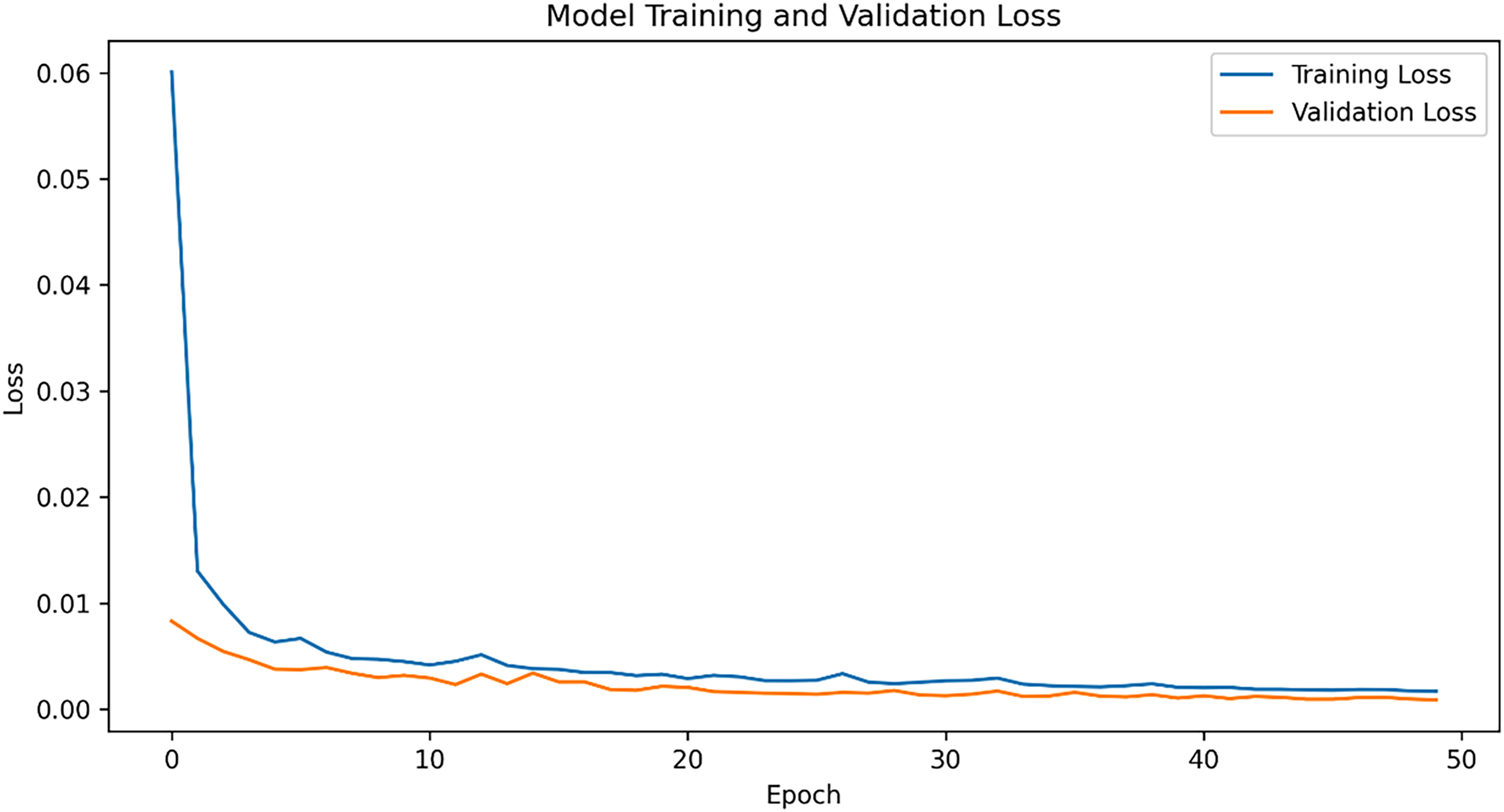
Training and validation loss plot for dynamic context-aware power forecasting model.

Avarage monthly normalized prediction error of different models for Jhimpir site dataset.
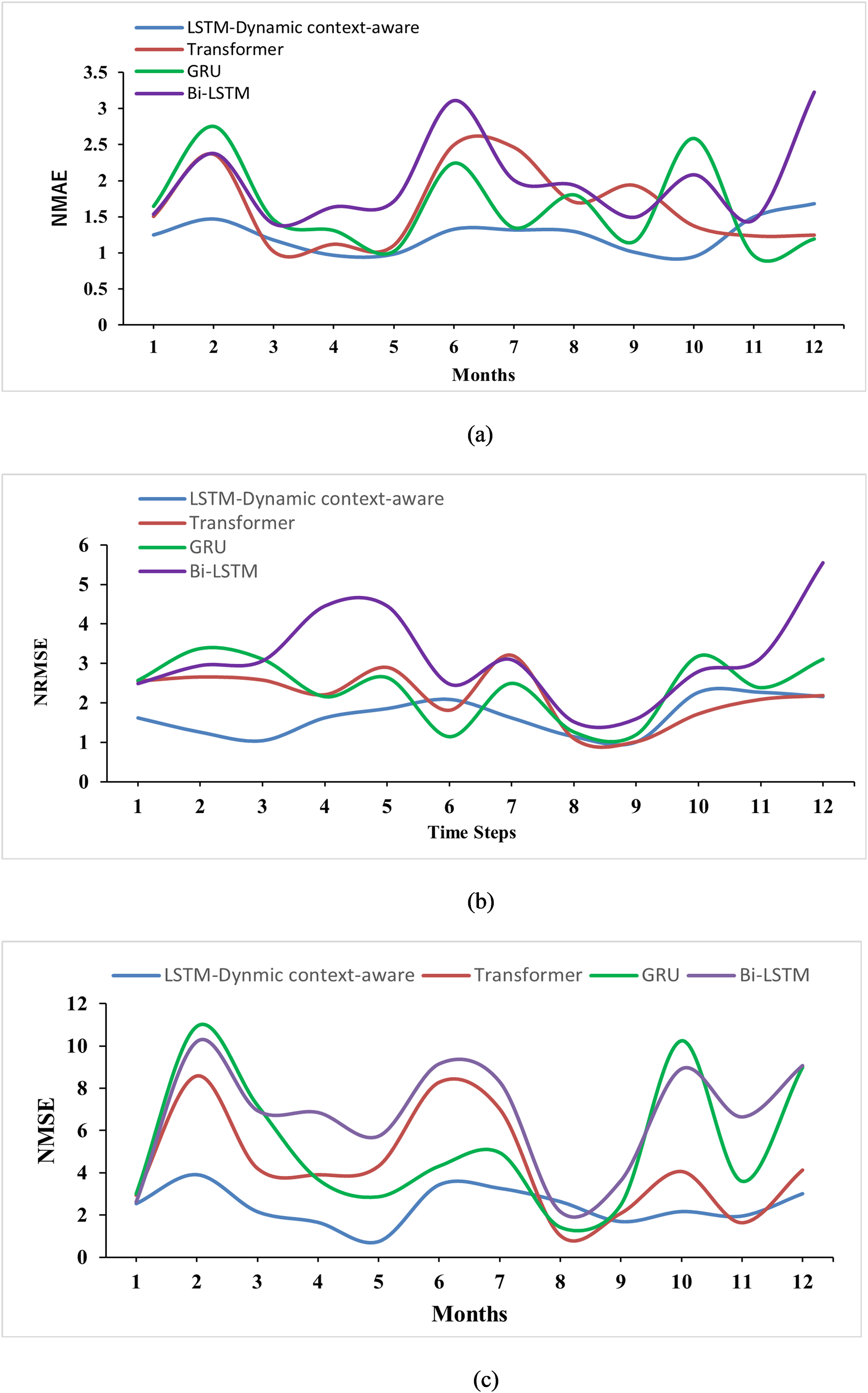
Average monthly normalized prediction error of different models for Texas site dataset.
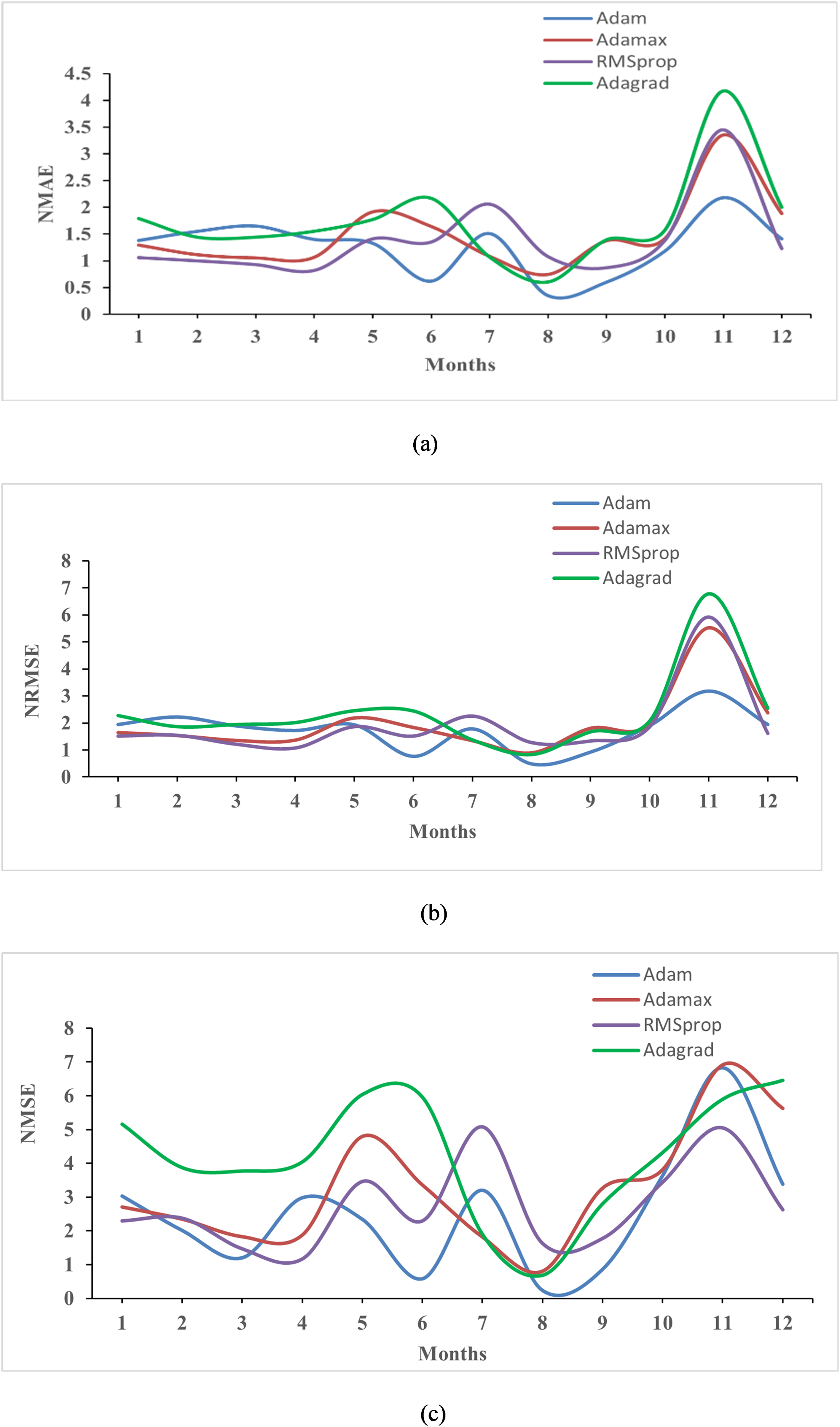
Average monthly normalized prediction error of dynamic context-aware model using different optimizers.
Average normalized evaluation results of all models in the Jhimpir site dataset.

Average normalized evaluation results of all models in the Texas site dataset.

Average normalized prediction performance for LSTM-dynamic context-aware model with respective optimizers.

Selected samples from the wind power dataset are randomly chosen to demonstrate the prediction capabilities. The models forecast power output for the forthcoming 12 h, as illustrated in Figure 9. These trained and validated models are then tested on the test dataset to predict wind power performance based on wind speed, direction, and ambient temperature. The features used in the datasets are correlated to in Figure 10 which shows a strong positive correlation between the wind speed and power. The results indicate that the LSTM-Dynamic context-aware model outperforms others with an average NRME of 1.721, 1.263, and 2.842 for NMAE and NMSE while Transformer model closely following with a NRMSE of 2.192, 1.511, 4.754 for NMAE, and NMSE, respectively, for Jhimpir dataset. Furthermore, LSTM-Dynamic context-aware model leads the other models with an average NRME of 1.518, 1.243, and 2.427 for NME and NMSE while as discussed above the Transformer model continues to follow closely with a NRME of 1.800, 1.631, and 4.351 for NMAE and NMSE analyzing the Texas dataset.

The forecasting result for the next 12h on the Jhimpir dataset of different models.
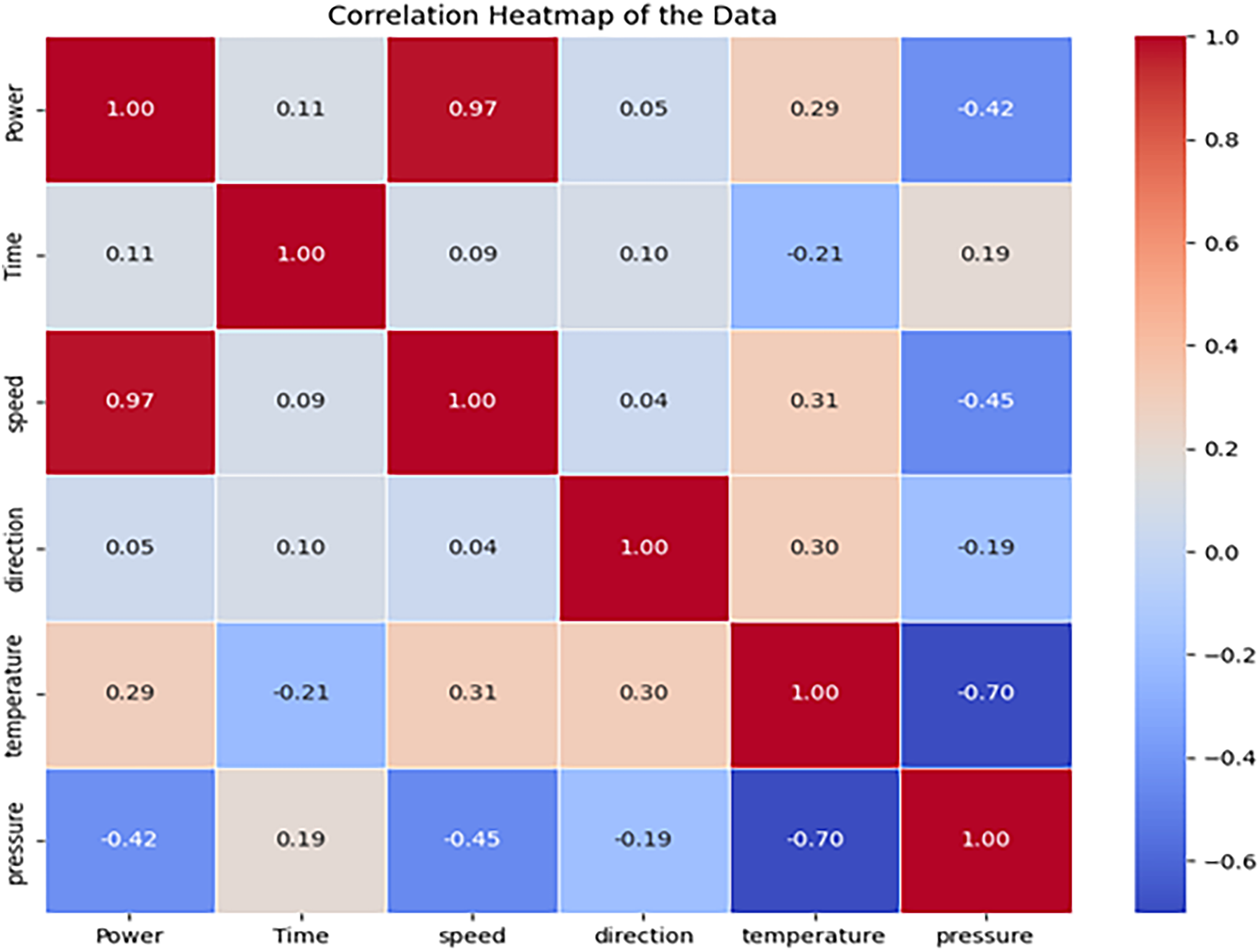
Correlation among the target power and the features.
However, the performance of GRU and Bi-LSTM models lag behind due to overfitting, leading to inaccurate power value predictions during training. Forecasting wind power is crucial for wind turbine management and preparation of hybrid wind power systems, playing a pivotal role in the generation of wind turbines. Wind interval forecasting, which assesses changes in predicted performance due to uncertain factors, provides vital information for power system planning. The comprehensive capabilities of wind interval forecasting are crucial for grid design and operation, including wind farms. Furthermore, deep learning models offer insights that can guide decision-makers in wind turbine manufacturing to optimize wind power generation. Balancing supply and demand are essential for a sustainable energy economy and cost efficiency, while congestion could reduce energy efficiency, compromising grid stability and security, and leading to higher long-term costs and conservation issues.
Conclusion
Wind power is a low-carbon, zero-emission energy source that brings major technological advancements. Forecasting the wind energy generated from wind power is crucial for renewable technologies and environmental progress. Deep learning techniques have recently emerged as effective methods in advanced forecasting. In this paper, a novel LSTM-Dynamic contextual time-series performance forecasting model is provided, which is an improved transformer framework implemented to address the limitations of existing time-series forecasting models. To predict difficult operational problems by minimizing risks and improving efficiency, the model results are compared with three different models, GRU, LSTM, and transformer, using two datasets of the Jhimpir and Texas power plant electrical system. The results are compared using the performance predictions for the next 12 h after training and testing the dataset. Moreover, the accuracy of different models is tested using the evaluation matrix, where the contextual dynamic model shows high accuracy with the lowest error values. The combination of LSTM with Contextual Dynamic model is useful for extracting extremely nonlinear and complex data from a real-time input dataset to drive wind power prediction improve energy storage optimization and grid stability. This model can be extended and improved to provide comprehensive knowledge to decision-makers interested in wind turbines and energy optimization.
Footnotes
Acknowledgments
We are very thankful to Prof. Yong Wang, School of New Energy, North China Electric Power University who gave precious suggestions on revision. We would also extend our heartfelt appreciation to Mr Shoaib Ahmed, site data analyst at Jhimpir Power Plant, Pakistan for providing us with the required 50-MW wind power plant dataset. Moreover, the authors are grateful for the generous support from the School of New Energy at North China Electric Power University, Beijing, China facilitating and awarding through the Chinese Scholarship Council 2020.
Author contributions
Jan Yasir: writing—original draft and writing—review and editing. Ahmed Saeed: data curation and review and editing. Sydney Mutale: review and editing. Yan Jie: supervision and review and editing. Ishwor KC: review and editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration of generative AI tools
The authors declare that they have not used any type of generative artificial intelligence, for the writing of this manuscript nor the creation of images, graphics, tables, or their corresponding captions.
Data availability statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.