
Abstract
In a classification problem, before building a prediction model, it is very important to identify informative features rather than using tens or thousands which may penalize some learning methods and increase the risk of over-fitting. To overcome these problems, the best solution is to use feature selection. In this article, we propose a new filter method for feature selection, by combining the Relief filter algorithm and the multi-criteria decision-making method called TOPSIS (Technique for Order Preference by Similarity to Ideal Solution), we modeled the feature selection task as a multi-criteria decision problem. Exploiting the Relief methodology, a decision matrix is computed and delivered to Technique for Order Preference by Similarity to Ideal Solution in order to rank the features. The proposed method ends up giving a ranking to the features from the best to the mediocre. To evaluate the performances of the suggested approach, a simulation study including a set of experiments and case studies was conducted on three synthetic dataset scenarios. Finally, the obtained results approve the effectiveness of our proposed filter to detect the best informative features.
Keywords
Introduction
Feature selection 1 has become a primordial process in all classification problems. Given the recent technologies in the field of high-dimensional data collection, the large number of features has become a real curse for researchers and data analysts, its presence can penalize learning methods and increase the risk of over-fitting. The benefits of feature selection include facilitating the analysis, understanding, and interpretation of data, improving predictive results, and reducing compilation time. Feature selection is a procedure characterized by four principal elements: the type of approach, the search strategy and search direction, the evaluation function, and the stopping criterion. In the literature, there are many feature selection methods, which are subdivided into three types2–4 including filters, wrappers, and embedded methods. One of the major challenges for feature selection is the dimension of the search space, which increases exponentially with the number of features, this makes the search strategy exhaustive and computationally difficult to implement. To overcome this problem, many search strategies have been developed to find a near-optimal solution. As for the search direction, it can be of three types: forward selection, backward elimination, and bidirectional search. In order to evaluate the discriminating power of features or also a set of features, an evaluation function is applied in this purpose, the evaluation criteria generally can be subdivided into five categories based on the quantity of information, distance, independence, consistency, and precision provided by a classifier. Information-based criteria are based on the amount of information contributed by a variable to the target one. Independence criteria include all measures of association or correlation, they assess the dependence between the target feature and the explanatory ones, while precision criteria are based on the classifiers as an evaluation function. The stopping criterion is used to stop the selection process, it can be a number predefined by the user, the choice of the stopping criterion can also depend on the obtained results, this is the case when adding or removing a feature does not give any performance improvement.
Filters 5 for feature selection evaluate features according to their intrinsic properties, among its advantages are the rapidity and also the independence of the learning methods. We can also distinguish between univariate and multivariate filters, for univariate filters, the features are evaluated according to their individual discriminating power, in multivariate filters, we are essentially looking for subsets that can collectively answer the given classification problem and taking into consideration the notion of complementarity and interaction between features. We cite in this category, mutual information, 6 gain ratio, 7 relevance-complementarity preordonnances based, 8 symmetrical uncertainty, 9 Fisher score, 10 information gain, 11 chi-square test, 12 minimum redundancy maximum relevance, 13 relevance-redundancy preordonnances based, 14 the correlation-based filter selection, 15 Pearson correlation, 16 the fast correlation-based filter, 17 and Relief-based algorithms. 18 In wrapper methods, the process of selecting features is carried out in parallel with the learning process, where each subset of features is evaluated by a learning method, this simultaneous evaluation of the subsets of features allows us to take into account the interactions between features. Among the existing wrapper methods, we cite the Recursive feature elimination algorithm, 19 also there are those with a population-based search strategy, such as the genetic algorithm20,21 and the particle swarm optimization algorithm, 22 and those with a sequential search strategy such as the sequential forward selection algorithm 23 and the sequential backward selection algorithm. 23 Finally, in embedded methods, feature selection is integrated into the learning method. They also have the advantage of being generally faster than wrapper methods by avoiding the back-and-forth process between selection and learning evaluation and can be influenced by the choice of the learning method and also allow for the consideration of interactions between features. For example, we cite Lasso 24 or elastic net algorithm, 24 random forest algorithm, 25 recursive feature elimination for support vector machines, 19 …etc. Among the best-known filters in the field of feature selection is Relief, 26 an algorithm invented by Kira and Rendall inspired by instance-based learning methods, it is exclusively designed for binary classification problems, which evaluates features using a global score through randomly selected instances. In order to adapt Relief to handle problems such as missing data, multiclass data, regression problems as well as noise handling, several variants of Relief have been developed, the most famous being ReliefF, 27 also many extensions 18 have been introduced after the ReliefF algorithm, such as RReliefF, EReliefF, SURF, SWRF*, MultiSURF, MultiSURF*, TuRF, Evaporative Cooling ReliefF, ReliefMSS, LH-RELIEF, ReliefSeq, and iVLSReliefF. In the evaluation process by Relief, there is often the possibility that some instances contribute excessively to the scoring process, leading to the penalization of many features. The main objective of this work is to propose a new filter for feature selection, by combining the Relief method and the multi-criteria decision-making (MCDM) method named TOPSIS (Technique for Order Preference by Similarity to Ideal Solution), 28 we have developed a multi-criteria-based approach to select the relevant features. Through the Relief method, we have constructed a decision matrix on which we have applied TOPSIS, each feature is scored individually without being penalized, and at the end, we get a ranking for all features.
The main contributions of this work are presented as follows:
Modeling feature selection as a MCDM problem exploiting the fundamental concepts of Relief. By combining a filter and a powerful MCDM method, a new filter has been proposed allowing the ranking and selection of relevant features. The TOPSIS method is used to determine the relevant features. A simulation study including different scenarios was conducted to validate the efficiency of the proposed method.
This article is structured as follows, an introduction is presented in the first section, then, the related work and used background are given in the “Related work and background” section, next, we describe our proposed approach in “The proposed method” section, the experimental results are given in “the Experiments and results” section, and finally, a conclusion is presented in the “Conclusion” section.
Related work and background
In the field of feature selection, filter methods are commonly used due to their rapidity and simplicity. In general, filters use the intrinsic or statistical characteristics of the features as an evaluation measure and adopt ranking techniques. Instead of an explicit optimal subset of features, the filter methods generate a ranked list of features. They have the advantage of being independent of the classification algorithms, which leads to the generality of selection results and avoids the problem of over-fitting. Filters generally require less computational time than other feature selection techniques which makes them easily adapted to deal with high-dimensional data. As already mentioned, they can be divided into two categories: univariate and multivariate. Univariate methods assess features individually, but multivariate methods consider subsets of features in the assessment procedure. The
Relief
Relief is a very well-known and commonly univariate used filter in feature selection due to its simplicity, it is created by Kira and Rendall inspired by instance-based learning methods. It is designed only for binary classification problems. The Relief algorithm is also designed to handle noisy and redundant data. The process of the feature weighting in the Relief algorithm is essentially based on an analysis of instance pairs, more precisely, on a study of differences and similarities between an instance and its nearest neighbor in the same class as well as its nearest neighbor in the different class. The quality of a feature increases if it brings two instances of the same class closer together and separates two instances of two different classes, if the opposite is true, then the quality decreases. In other words, the more a feature varies within a class, the less relevant it is, and on the other hand, the more it moves between different classes, the more its importance score increases. Given a randomly selected instance

Pseudo code of the Relief

The
For continuous (ordinal or numerical) features, the delta function


Relief-based algorithm family
After the creation of the Relief
26
algorithm in 1992, many extensions have been developed over the years, the use of k nearest neighbors in updating the score following each instance instead of restricting to one hit and one miss was introduced by the ReliefA
27
extension in 1994, it is addressed to noisy data, with time complexity
Two extensions of ReliefF have been developed, the first one was developed in 1996, and it is called RReliefF, 29 it is essentially dedicated to regression problems, the second one named Relieved-F 30 is a deterministic variant of ReliefF created in 1997 which uses the set of all instances and for each instance, it determines the set of all nearest neighbors. It is designed to handle missing data.
To eliminate the bias of ReliefF in the case of non-monotonic variables, in 2003, an iterative version named Iterative Relief
31
was created, its time complexity is
In 2007, three methods have been introduced; an extension called TuRF
33
was introduced to improve the quality of the score calculated by ReliefF by removing a percentage of noisy features at each iteration. By combining ReliefF and mutual information, Evaporative Cooling ReliefF
34
was developed in the same year addressing noisy features. In order to solve the problem of missing data for some instances, a new version of ReliefF named EReliefF
35
has been created with time complexity
Another extension of ReliefF was proposed in 2008 under the name VLSReliefF
36
to detect interactions between features and to solve the problem of the influence of the large number of features on the selection of the nearest neighbors as well as on the weight computed by ReliefF. The method relies primarily on random subsets of features in the scoring mechanism, its time complexity is
In 2009, a method named ReliefMSS
37
was introduced which proposes a modification of the weight of ReliefF, its complexity is
Then in 2010, an extension of the SURF method was proposed under the name SURF*, 39 it introduced the use of the farthest individuals in the scoring process to improve the detection of interactions between features.
In 2012, a variant of SURF* was introduced called SWRF*,
40
it used a sigmoid function to weight the nearest neighbors, and its complexity is
In 2013, an improvement of the SURF* method was developed under the name MultiSURF*,
42
it is faster and with a complexity
In 2018, a new variant of MultiSURF* was developed under the name MultiSURF,
44
its execution time is
MCDM concepts and TOPSIS
When we have to make decisions in a complex reality where there are several conflicting viewpoints, MCDM methods are adapted to solve this problem, to enlighten our decisions, or to make recommendations to the decision-makers. In general, a multi-criteria decision problem is characterized by a set of alternatives
Multi-criteria decision matrix B.

The first step in TOPSIS is to normalize the decision matrix B.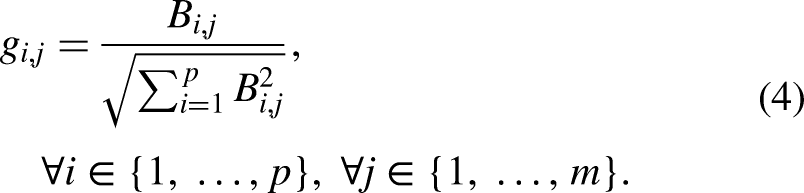




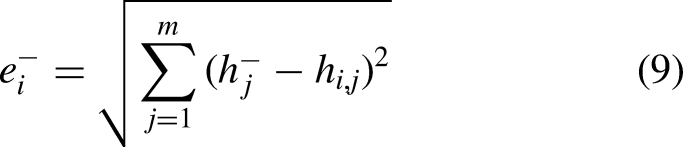

Overview of using MCDM for feature selection
In the literature, many MCDM-based selection methods have been introduced recently, among them, two approaches for the evaluation of selection methods have been developed. The first one 45 is based on TOPSIS, it has been proposed to evaluate selection methods for the Network Traffic dataset by considering different performance measures as decision-making criteria. The second one 46 is for text classification and small data, it suggests an evaluation of selection methods by comparing several MCDM methods. For feature selection, a method named MFS-MCDM 47 has been introduced for the multi-label dataset, it is a modeling of the selection task as an MCDM problem, by adopting the correlation between features and labels as criteria and using Ridge regression to calculate the decision matrix, the method applies TOPSIS in order to generate a ranking of the features. Another algorithm was introduced under the name EFS-MCDM, 48 on a decision matrix constructed through the rankings provided by different selection algorithms, the MCDM method called VIKOR is applied to rank the features. An approach was developed under the name VMFS 49 for multilabel data, where a decision matrix was constructed by calculating the correlation between features and labels using cosine simulation, then the matrix is provided to the VIKOR multicriteria method to rank the variables. The TOPSIS method was also used in a hybrid method called TOPSIS-JAYA, 50 after combining several filters in a decision matrix, TOPSIS ranks the features and then, a wrapper method uses the best features selected by TOPSIS to find the optimal subset. Finally, in another method 51 intended for cost-sensitive data with missing value, an MCDM strategy was used to evaluate the features, after, a forward greedy selection is conducted to find the optimal subset.
The proposed method
The main objective of our proposed approach is to select the relevant features and eliminate the noise, by modeling the feature selection as a multi-criteria decision problem, the proposed method used the fundamental concepts of the Relief method to compute a decision matrix by considering the feature weights corresponding to the randomly chosen instances as decision-making criteria (Figure 1). As shown in Algorithm 2, at each iteration, the features are weighted corresponding to a randomly chosen instance

Schematic diagram representation of the proposed approach.
Pseudo code of the proposed algorithm

We present binary data with an X matrix containing the features and a Q vector of labels as shown in Figure 2. The rows in the matrix X represent the instances and the columns represent the features, the vector Q contains the labels of instances.
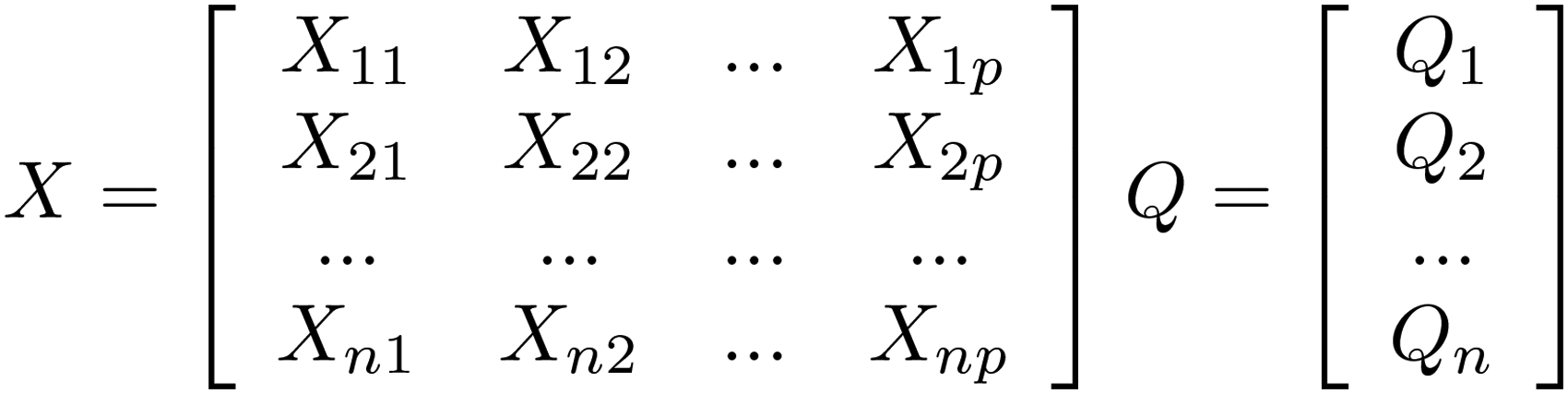
The structure of the data.
In the first step, we calculate the feature weights corresponding to the instances using the Relief method, the formula for measuring the weight of a feature 

Next, the decision matrix B and the instance weight vector w are provided to the TOPSIS method to generate the ranking of features. The first step in TOPSIS is to normalize the decision matrix B using equation (4). Then, the weighted normalized matrix h is constructed by multiplying the normalized matrix g by the weight vector w using equation (5). The weighted normalized matrix is structured as shown:
Time complexity
In general, one of the factors that makes an algorithm efficient is its ability to decrease the execution time as a function of the input size, which determines the number of operations performed by an algorithm. In this study, a time complexity analysis is proposed. The time complexity of our algorithm depends mainly on the identification of the hit and miss, this phase has time complexity
Experimentally, let’s consider a dataset with 20 samples (

Microbenchmark timings to compute the decision matrix.
Average run-time in seconds to compute the decision matrix.

After the construction phase of the decision matrix, TOPSIS generates the ranking of the features with an average time presented in Table 3. The TOPSIS algorithm is generally characterized by its low time complexity. According to Table 3, with
Average run-time in milliseconds of Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) phase.

Experiments and results
To test the proposed algorithm, we propose a simulation study for evaluating its performance and ability to select relevant features. In this simulation study, we will generate data under three scenarios, two scenarios contain numerical features, and one contains categorical ones.
50% are labelled with the class 1 and 50% are labeled with the class
For 70% of observations (
For 70% of observations (
For 30% of observations (
The features
The target feature
A target vector Y is generated for the binomial distribution, where
Conditional on

Given
For all remaining features
The goal of this study is to evaluate how well the suggested algorithm can identify the relevant features that have previously been indicated and reject the irrelevant ones. The three models already described are random, for this reason, the experimental protocol adopted in our simulation study consists mainly in generating M different datasets according to each of the three scenarios after choosing the number of instances n, the number of features p, and the number of iterations m. On each database, we applied the proposed method and we obtained a feature scoring vector
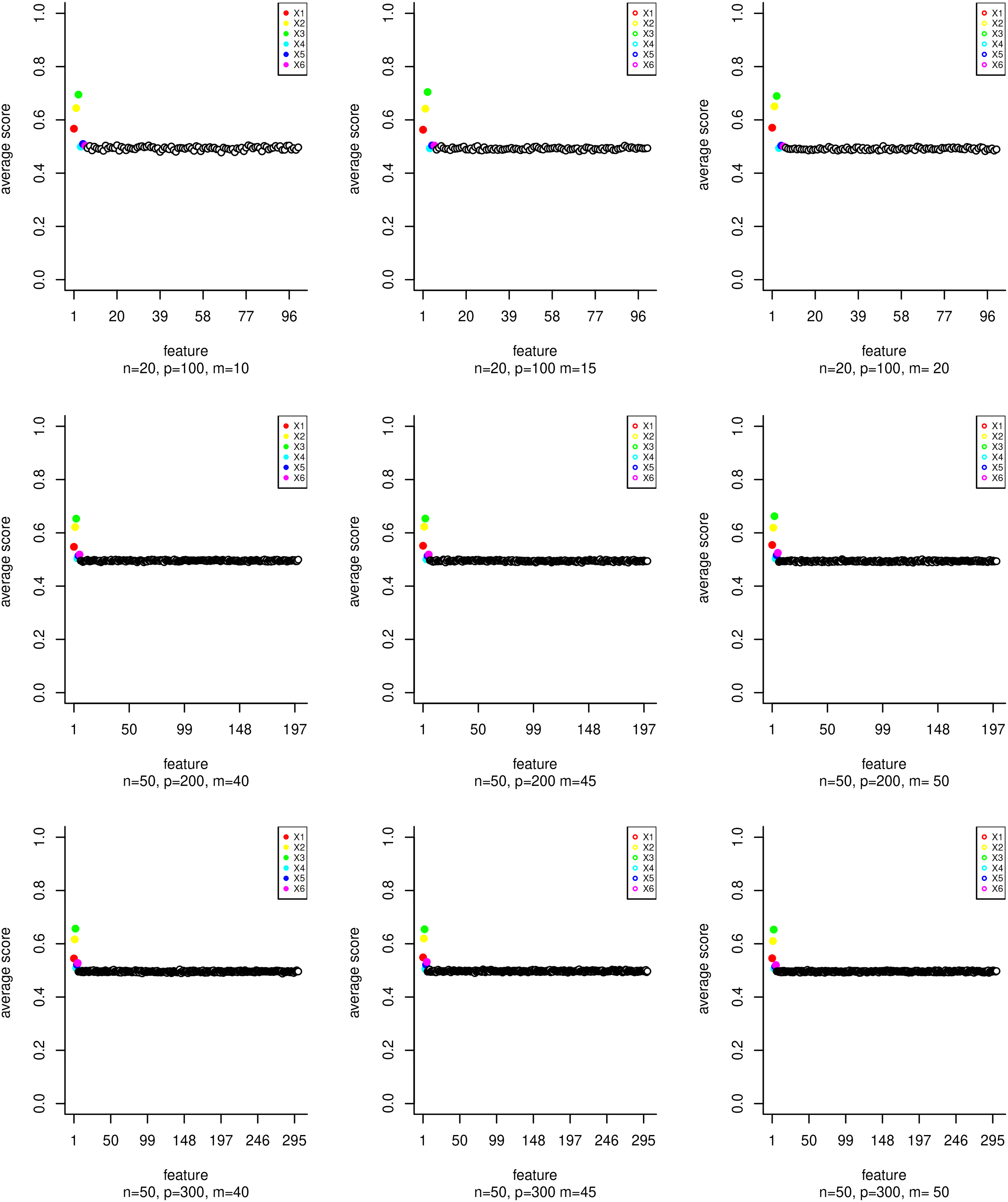
Average Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) score of features generated using scenario 1 for many options of n, p, and m.
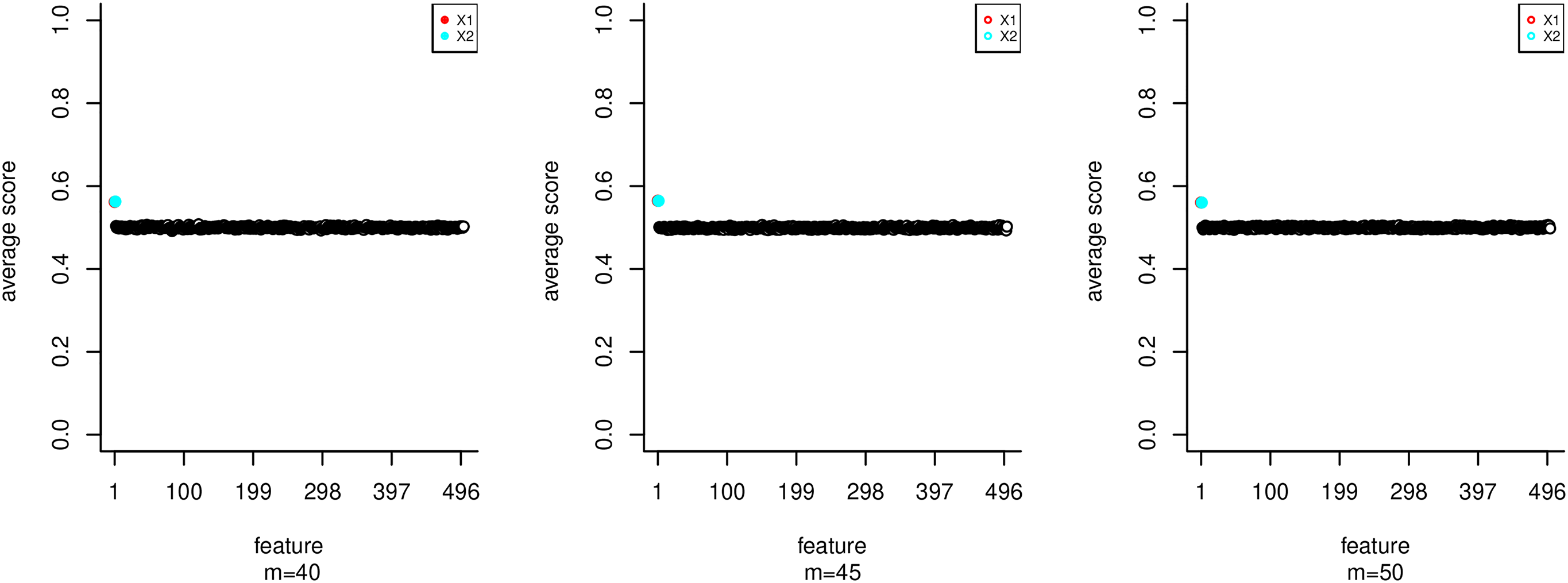
Average Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) score of features generated using scenario 2 for many options of m.

Average Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) score of features generated using scenario 3 for many options of m according to beta values.
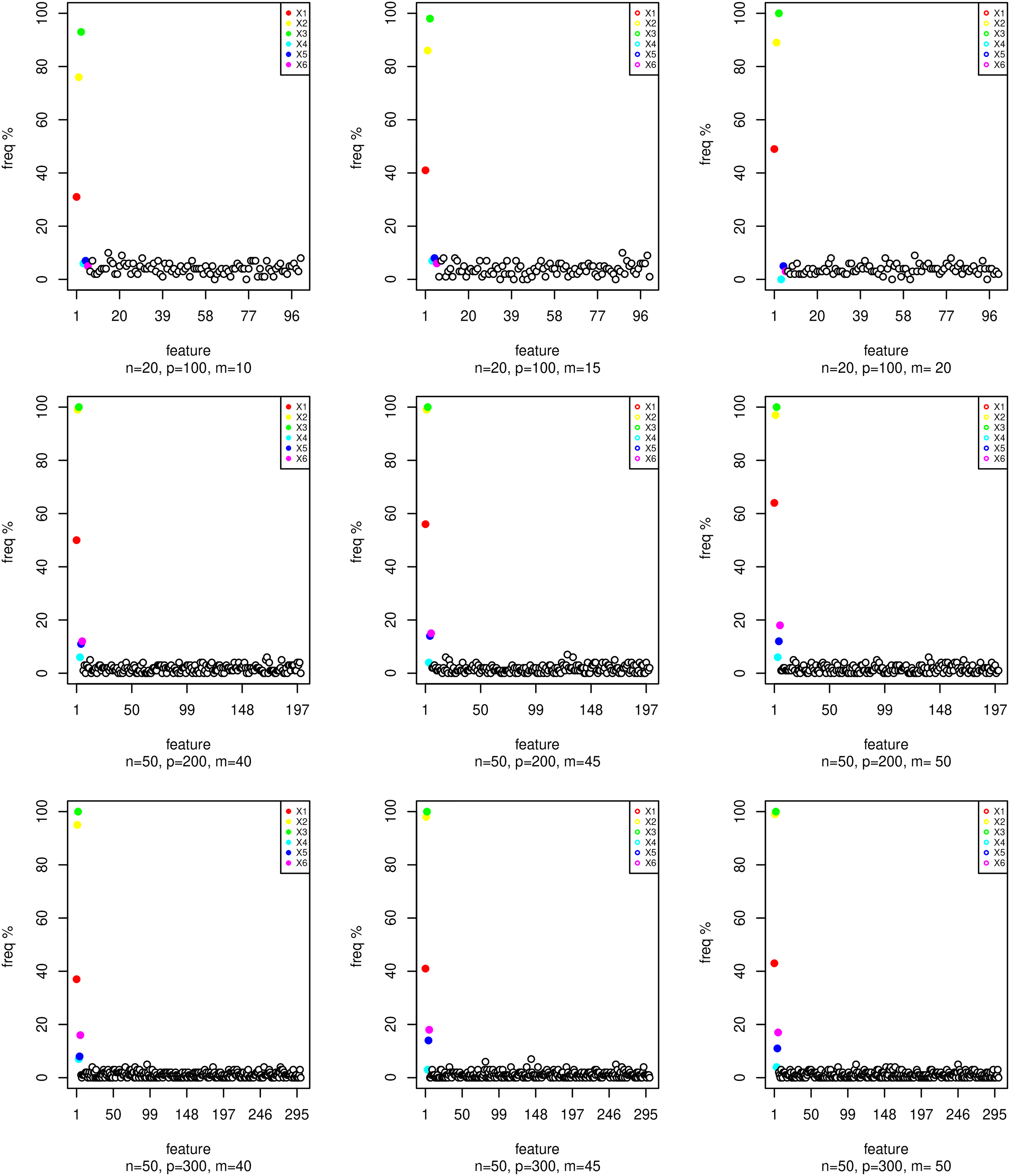
Selection frequency in the top 6 of features generated using scenario 1 for many options of n, p, and m.
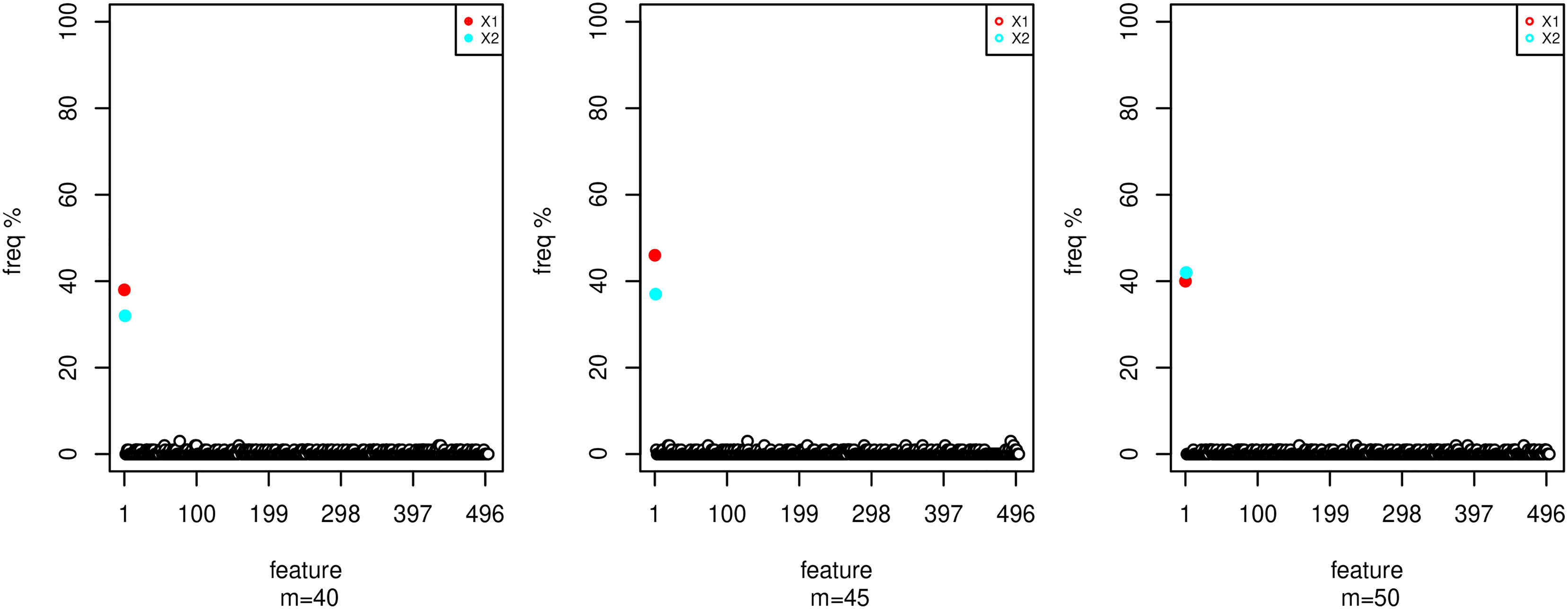
Selection frequency in the top 2 of features generated with scenario 2 for many options of m.

Selection frequency in the top 8 of features generated with scenario 3 for many options of m according to beta values.
Selection frequency in the top 6 of relevant features generated with scenario 1 for many options of n, p, and m.

Selection frequency in the top 2 of relevant features generated with scenario 2 for many options of m.

Selection frequency in the top 8 of relevant features generated with scenario 3 for many options of m according to beta values.

Conclusion
Before dealing with a classification problem, extracting the relevant information is a crucial step. In this article, we proposed a filter method for feature selection, which is mainly designed to deal with two-class databases. Through the Relief method, we have computed a decision matrix considering the feature weights corresponding to the instances our decision criteria, this matrix is provided to the TOPSIS method to generate the ranking of the features. Through a simulation study of three scenarios, we have evaluated the performance of our method. The results obtained approve the efficiency of our method to detect the relevant features.
In our future work, to improve the proposed approach, the variant method named ReliefF can be used to address the multiclass selection problem and make the method more robust. We also intend to implement our method on real datasets such as microarray datasets and make comparisons with existing methods.
Footnotes
Authors’ note
The paper was selected from ICAMDS22.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.