
Abstract
The Weeks method for the numerical inversion of the Laplace transform utilizes a Möbius transformation which is parameterized by two real quantities, σ and b. Proper selection of these parameters depends highly on the Laplace space function F(s) and is generally a nontrivial task. In this paper, a convolutional neural network is trained to determine optimal values for these parameters for the specific case of the matrix exponential. The matrix exponential eA is estimated by numerically inverting the corresponding resolvent matrix
Introduction
In 1966, while working at IBM, William Weeks presented an algorithm to perform a numerical Laplace transform inversion by expanding in terms of Laguerre polynomials. In his approach, he introduced two real parameters σ and b. He then proceeded to provide a few heuristic rules for determining optimal
Machine learning is currently quickly evolving into a powerful tool for solving a wide variety of pattern recognition and optimization problems. Convolutional neural networks in particular are now readily available and can be quickly constructed in high level languages such as MATLAB. In previous works, the authors have explored the optimal selection of Weeks’ method parameters by conventional search algorithms and also applied Weeks’ method to the solution of practical engineering problems. Given these experiences and the growth of machine learning, training a neural network to assist with the optimal
In this paper, we demonstrate that this machine learning approach can in fact be effective in the Weeks method for numerical inversion of the Laplace transform. To illustrate, we apply the Weeks method to the computation of the matrix exponential. The use of Laplace transform methods for matrix exponentiation is method twelve of the nineteen approaches described in the often cited work by Moler and Van Loan.
1
This follows from the general definition of a complex function

In the particular case that scalar integrand function

One recognizes from this that the Laplace transform space function corresponding to the matrix exponential

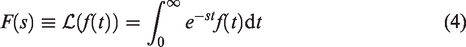



The importance of the matrix exponential in the numerical solution of partial differential equations and in numerous practical engineering problems has also motivated its accurate calculation as a focus for this paper.
Our paper is organized into five parts. After this first introductory section, the second part of the paper reviews the Weeks method. Of particular important here are the role of the Möbius transformation and the introduction of the two parameters (
The Weeks method
Weeks’ method is one of the most well known algorithms for the numerical inversion of a Laplace space function.3–6 (The notation in this paper follows the conventions used by Weideman.7–9 ) A recent survey of numerical inversion algorithms lists the Weeks’ method and three of its variants on the top of this list.
10
It is in part due to its popularity when compared to other inversion algorithms that it has been chosen for this paper. One of the strengths of the Weeks method over other well known approaches, such as the Talbot method,11–14 the Fourier series method
15
, or Post’s formula16–18 is that it returns an explicit expression for the time domain function. In particular, Weeks’ method assumes that a smooth function of bounded exponential growth

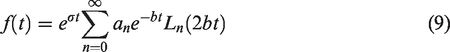
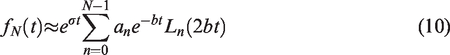
The polynomials

The coefficients an, which may be scalars, vectors, or matrices, contain the information particular to the Laplace space function F(s) and may be complex if f(t) is complex. More importantly, these coefficients are time independent so that f(t) can be evaluated at multiple times from a single set of coefficients.
The two free scaling parameters σ and b in the expansion must be selected according to the constraints that

Laguerre polynomials
To compute the coefficients an for a general vector or matrix function F(s) one must perform the contour integration in the complex plane of equation (8). If one chooses the Bromwich contour


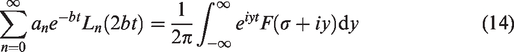
Conveniently, the weighted Laguerre polynomials have the Fourier representation
7

Performing the appropriate substitution, assuming it is possible to interchange the sum and integral, and equating integrands thus leaves

The functions
In principle, one could try to use directly the orthogonality of the basis to determine an. These functions are highly oscillatory but could possibly be accurately estimated with adaptive integration. Weeks’ insight was however to apply a Möbius transformation.
The Möbius transformation is one of the most fundamental mappings in mathematics.19–21 Algebraically, it can be expressed as the conformal mapping from the complex plane s to complex plane w according to
In his method, Weeks’ choose for the Möbius transformation

For the Bromwich contour

Using
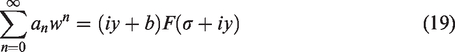

The coefficients an of the original expansion (9) are the coefficients of a Maclaurin series. The radius of convergence R is strictly greater than unity due to our selection of functions F(s) which do not have a singularity at infinity. Furthermore, within this radius, the power series converges uniformly.
Cauchy’s integral theorem
22
provides a method to compute an. Since the function is analytic inside the radius of convergence R > 1, the integration can be performed along the unit circle


Numerically the evaluation of the integral can be computed very accurately using the midpoint rule;

For N = M, this sum can be efficiently computed using the fast Fourier transform
7
in
Once the coefficients have been computed and the parameters selected, it is necessary to perform the Laguerre expansion. A naive approach is to generate the Laguerre polynomials using the recurrence relation



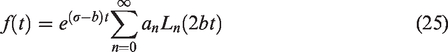
The Laguerre polynomials however can be large for increasing n and thus lead to an unstable summation. A stable method which does not require explicit evaluation of the Laguerre polynomials is the backward Clenshaw algorithm. 23
This brings us now to consider is the effect of the

The multifaceted roles that the b parameter plays in the Weeks method is more complex. The parameter can be seen to play at least three roles. One role is that b is a time scaling parameter in the Laguerre polynomial expansion. A second role is that it is 1/2 the determinant in the Möbius transformation. As noted earlier, a Möbius transformation
In the third role, b defines the amount of contour truncation that is acceptable when evaluating the Bromwich integral numerically. Consider the w contours in Figure 3 where the truncated contour

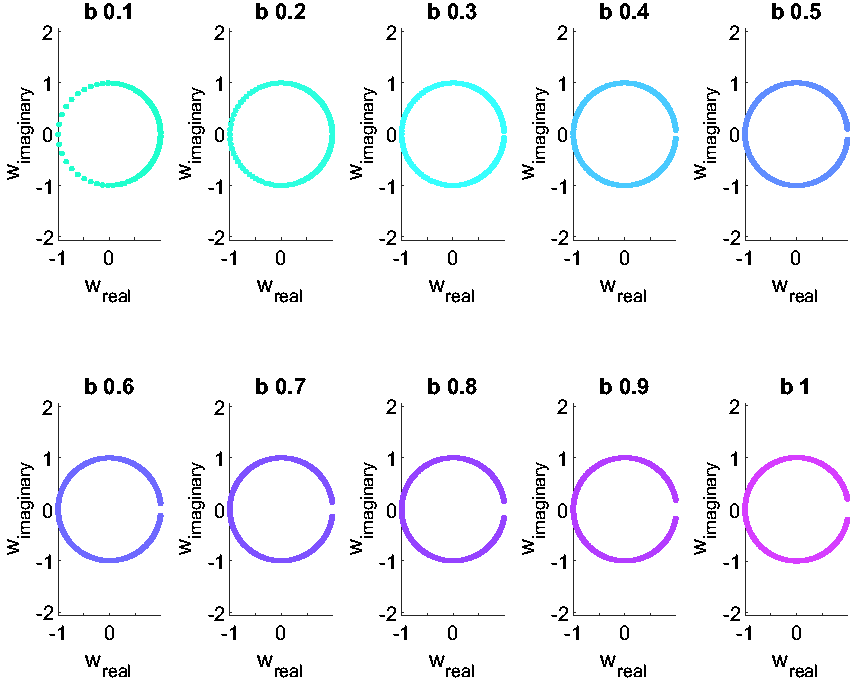
In the case of the Weeks method, the three points pairs can be chosen as
Machine learning
Neural network
Optimization problems are one of the most important applications of machine learning .24–27 A currently active of research regarding machine learning is its application to optimal numerical integration.
28
While certainly optimization algorithms have been used for parameter selection in numerical Laplace transform algorithms, to our knowledge neural network techniques have not been used previously for optimal parameter selection in the Weeks’ method. In this paper, supervised learning was implemented to train a regression network where the input to the network are the values of the matrix itself and the corresponding continuous output are the
To implement the network, we have leveraged the existing capability provided in the MATLAB machine learning toolbox.
29
With the basic components provided in the toolbox, we constructed simple convolution neural networks for four classes of matrices. The weights in a network were adjusted to accurately estimate a matrix exponential from the Weeks method with a particular
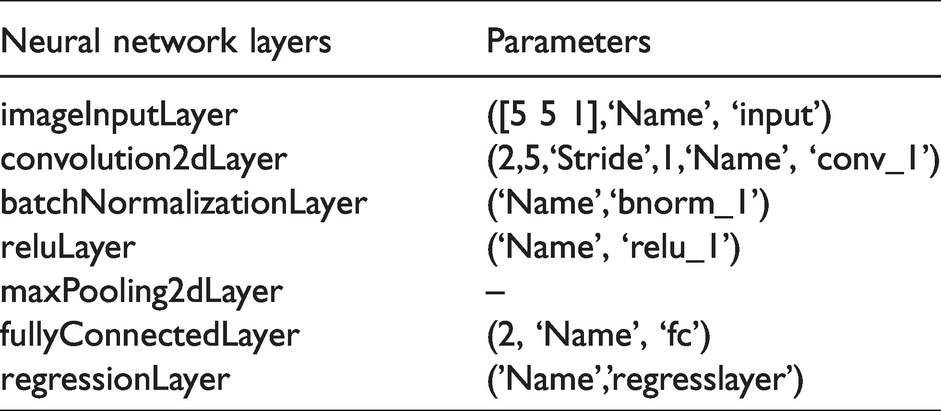
To illustrate, we limited ourselves to square matrices of real values of size 3,4, 5, and 6. A more detailed description of the selected matrices is provided below when describing network training. With respect to the network however, the actual convolutional neural networks used are quite simple. These small matrices allowed for only a few layers such as that shown in Figure 4. The contents on each of the layers is summarized in the Tables 1 to 4 for the four classes of matrices.

Convolution neural network example.
3 × 3 Direction cosines matrices evolution.

4 × 4 Quaternions evolution.

5 × 5 Random matrices.
6 × 6 Dramadah matrices.
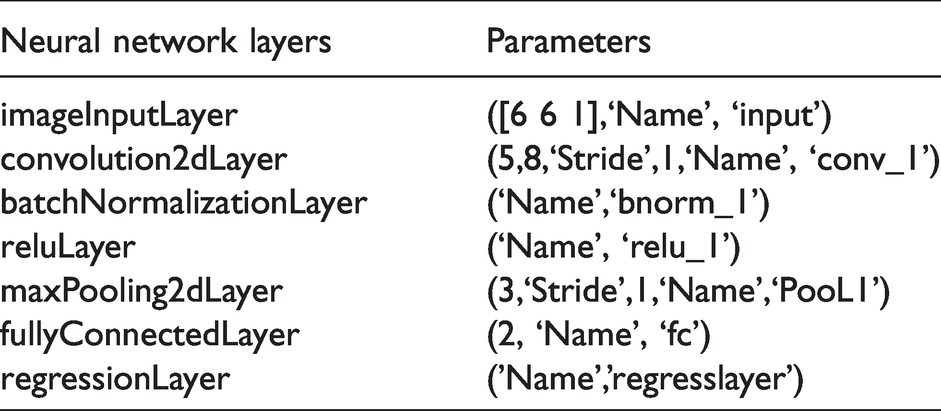
Detailed descriptions of each of the layers and their available options can be found in the MATLAB toolbox documentation.
29
For this specific implementation,the initial layer consists of a MATLAB image layer, where here the ”image” is the matrix A. After this a single convolution layer is applied to the matrix. The results from the convolution are normalized and thresholding is applied. For the activation function, a standard rectified linear unit (ReLu)
Certainly, a more sophisticated analysis could be performed to develop more accurate neural networks for this application. We choose simple networks in order to illustrate the approach and settled on those shown after some experimentation.
Regarding network training, a summary of the options used can be found in Table 5. The validation and training data are a 5% and 95% fraction of the total database created, respectively.
Network training options.

Training metrics
To gauge accuracy and to train the network, we considered three different metrics:
Jacobi Identity:
Max Element Error:
Total Elements Error:
The Jacobi identity metric is particularly interesting in that it provides a self-contained error estimate that depends only on the original matrix A and its approximation eA. There is no need for another approximation method to utilize for validation.
For the other two metrics based on comparing the Weeks estimated matrix exponential with a truth value, it was necessary to obtain ”truth”. Clearly, utilizing another trusted approximation method and simply comparing approximations is straight forward and is in-fact the approach we have utilized in past publications.13,30,31 When dealing with two high accuracy methods however, this direct comparison of the two approximations leaves one questioning which of the two is actually the more accurate and thus leads to some ambiguity in the error metric. In this paper, to avoid that ambiguity, we have a employed a 2-out-of-3 error estimate approach. For the max element and total elements error metrics, we have computed the matrix exponential via three different algorithms1,32–34
Weeks Method Padé Rational Approximation Cayley-Hamilton Theorem
The max element and total elements errors are then defined as the minimum of the differences between the Weeks and the Padé approximations and the differences between the Weeks approximation and the Cayley-Hamilton expression.


It is assumed that if two of the algorithms agree up to n decimal digits that those digits arose because the algorithms agree up to that accuracy and not due to round-off.
The Padé rational approximation is the algorithm implemented for the matrix exponential in MATLAB’s expm function.
35
Briefly, the original matrix is scaled by a factor of 
The Padé rational approximation approach has the advantages of possessing a well understood error estimate and widespread use due to its inclusion in MATLAB.
For a small square matrix it is not necessary to approximate the matrix exponential as it can be expressed analytically via the Cayley-Hamilton theorem.
34
The theorem states simply that every matrix satisfies its own characteristic equation. That is, given a square matrix A with dimension n and with a characteristic polynomial


A consequence of this theorem, is that the analytic function of a matrix A of dimension n may be expressed as a polynomial of degree (n-1) or less.

The exponential function is analytic and thus the matrix exponential can be determined by finding expressions for the coefficients 
To find those coefficients, it is sufficient to solve the corresponding set of equations given by the eigenvalues of A. For distinct eigenvalues, the eigenvalue equation is

For any eigenvalue of multiplicity m, the first 

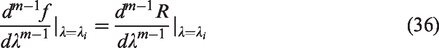
The main disadvantages of the Cayley-Hamilton expressions are the complexity of the analytic expressions and their sensitivity to round-off error. Except for 2 × 2, 3 × 3, and 4 × 4 matrices, analytic expressions for eigenvalues are generally impossible to derive. For our training purposes, however, the formula is tractable and to solve the equations we have used Mathematica (2019). 36 Since the Cayley-Hamilton matrix exponential expressions in MATLAB are not easily obtained and they are central to our analysis, we have included for the reader the exact Mathematica script used for solving the equations and their conversion to MATLAB in the supplemental material. 37 We also present the specific case of the Cayley-Hamilton theorem applied to a 4 × 4 matrix.
Briefly, for a general square 4 × 4 matrix, there are five eigenvalue cases to consider
All distinct: One pair, other 2 distinct: Two distinct pairs: 3 identical, 1 unique: All identical:
If we allow All distinct
One pair, other 2 distinct
Two distinct pairs
3 identical, 1 unique
All identical
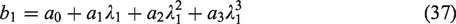


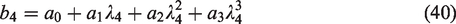







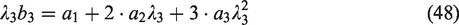





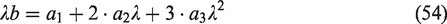


A simple check of these equations is to note for the case that all of the eigenvalues are identical, the coefficients are simply



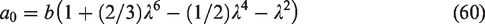
If the matrix is the 4 × 4 identity matrix, then 



Now performing the sum (32),
Test case matrices
To illustrate the formalism outlined above, we have computed the matrix exponential of four square matrices
3 × 3 Skew Symmetric Direct Cosine Matrix Evolution Matrices 4 × 4 Quaternion Evolution Matrices 5 × 5 Random Correlation Matrices 6 × 6 Dramadah Matrices
The 3 × 3 and 4 × 4 skew symmetric and quaternion evolution matrices are those in the ordinary differential equations that describing rigid body rotation.38,39 For a 3 × 3 direction cosines matrix (DCM) M, its evolution in the absence of external forces is described by a cross product of the rotation rates vector with the DCM. This cross-product can be expressed as a skew symmetric 3 × 3 matrix A.


Since the 3 × 3 matrix is real and skew-symmetric it has eigenvalues which are are either zero or purely imaginary, specifically
The case is similar for the 4-vector of quaternions 
One can define an ordinary differential equation for the evolution of 

This choice for
For 5 × 5 matrices, real square 5 × 5 random correlation matrices were selected. The matrices were chosen to stress the neural network approach studied here. We have also studied the matrix exponential of random matrices to some extent in our previous publication, 13 which utilized a Dempster-Shafer evidential theory approach to parameter selection in Talbot’s method for numerical inversion, and thus it seemed appropriate to do so again here. To create the database, we leveraged the MATLAB gallery matrix function gallery(’randcorr’,n) with n = 5. This generates a random square correlation matrix that is symmetric positive semidefinite with ones on the diagonal. The eigenvalues from these matrices are real, drawn from a uniform distribution, and thus are distributed fundamentally differently in the complex plane than for the 3 × 3 and 4 × 4 rotation matrices.
The 6 × 6 Dramadah matrix is the largest matrix for which we computed the matrix exponential using the Weeks, Padé, and Cayley-Hamilton methods. This matrix was also constructed by leveraging the MATLAB gallery matrix gallery(’dramadah’,6,3). This is a binary matrix (70) of zeros and ones.

An interesting fact is that the determinant of the nth Dramadah matrix is the nth Fibonacci number, in this case 8. This can be verified directly from the product of the eigenvalues, which are approximately equal to:
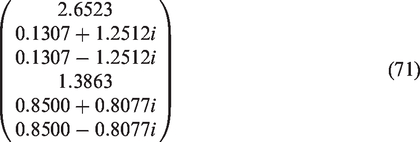
To vary the values of the Dramadah matrix, the matrix was multiplied by random values from 
Given that
Results
With the Weeks method and machine learning approaches outlined above, results from their application are reported here. Two separate sets of results are discussed. First are the results of the supervised training to construct the twelve neural networks, four tests case with the three metrics. The main takeaway from this section is that the simple networks employed were able to capture the shape of the error surface as a function of
The second set of results focus on validation. In particular, we have focused on the neural networks created using the Jacobi identity. The networks based on the other two metrics work very well, but because they require a second approximation for training, we decided to focus on the metric which leads to a self-contained algorithm. Even for the simple neural networks, the validation results demonstrate that machine learning can be utilized with the Weeks method to accurately compute the matrix exponential.
Neural network training results
Table 6 contains a summary of the specific set parameters chosen to construct the databases of matrices used to train the networks. In all cases, sixteen Laguerre polynomials were used in the estimate of the matrix exponential. Clearly, accuracy will be dependent on the number of basis functions but for illustration purposes, this number of polynomials was found to be sufficient.
Training database resolution parameters.

For the 3 × 3 DCM evolution and 4 × 4 quaternion evolution matrices, the matrices were constructed from the angles rates. The roll and yaw rates were taken from dividing the interval
To illustrate the results from the training phase, two types of plots have been constructed. The first is a set of surface plots for error of the Weeks method estimated matrix exponential as a function of

Error surfaces: 3 × 3 skew symmetric. (a) Jacobi. (b) Max element. (c) Total.
What one finds from these surface plots is that there are general structures to the error surfaces for each of the three metrics. It is therefore possible to find a minimum that corresponds to an optimal
Also plotted on these surfaces are cross and circle pairs from each of the 5% of validation matrices reserved from the total set of matrices utilized in the process of training the neural network. The crosses mark the
The second set of plots further illustrates that there is a pattern to the predictions of the neural network that overlaps with the underlying minimal error surfaces across matrices of a class. Plotted in Figure 6 for the DCM evolution, Figure 8 for the quaternions, Figure 10 for the random, and Figure 12 for the Dramadah, are the truth and neural network estimated σ and b parameters as a function of the test case. These too show that the simple neural networks used for this analysis none-the-less capture the distribution of optimal
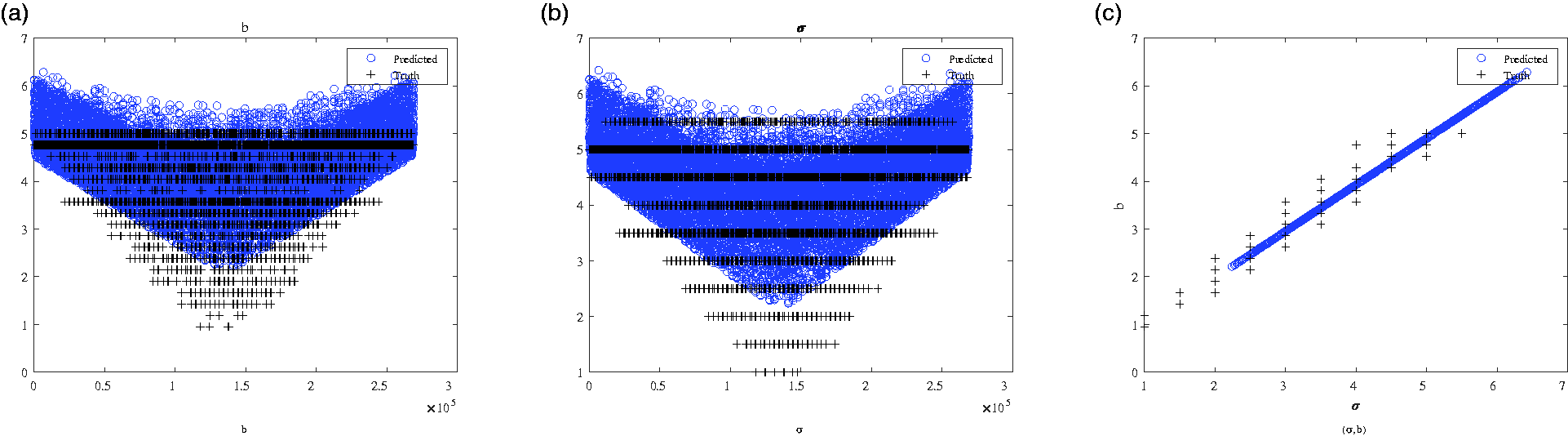
Truth vs. prediction: 3 × 3 skew symmetric.

Error Surfaces: 4 × 4 quaternions. (a) Jacobi. (b) Max element. (c) Total.

Truth vs. Prediction: 4 × 4 quaternions.

Error surfaces: 5 × 5 random. (a) Jacobi. (b) Max element. (c) Total.

Truth vs. prediction: 5 × 5 random.
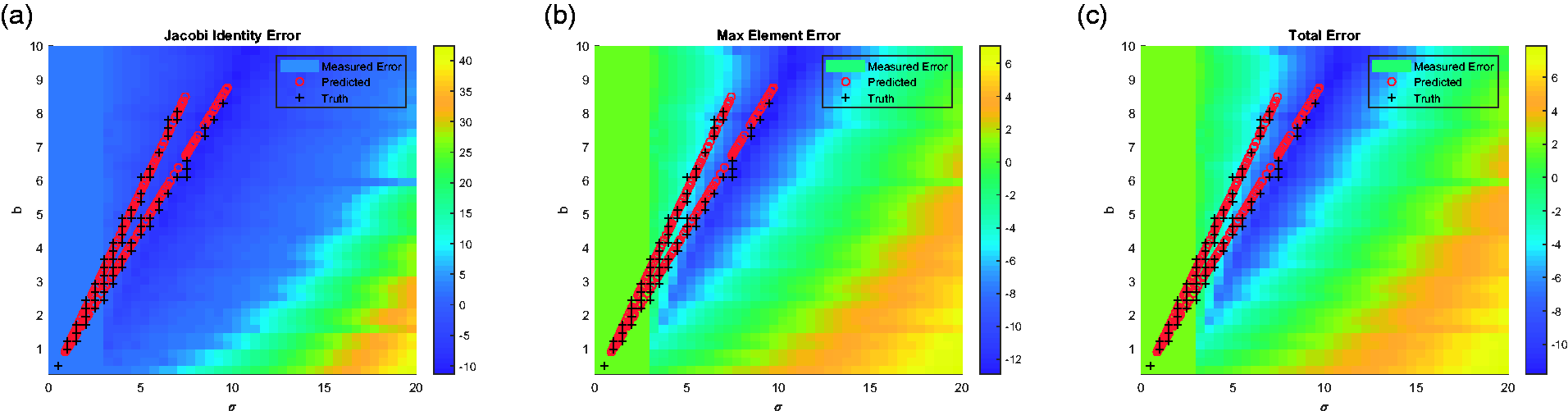
Error surfaces: 6 × 6 Dramadah. (a) Jacobi. (b) Max element. (c) Total.
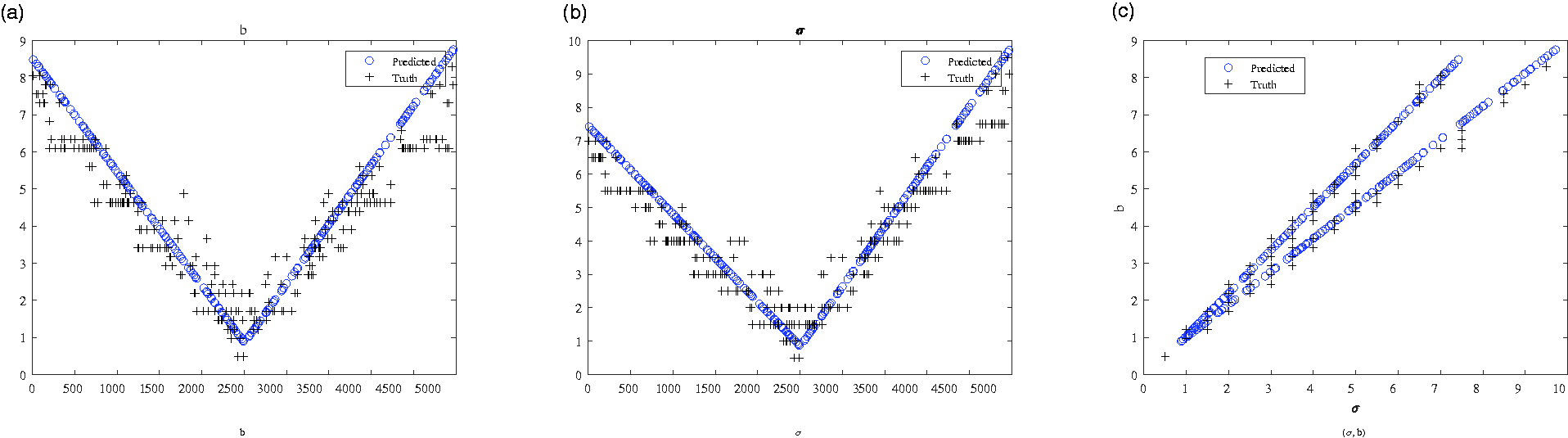
Truth vs. prediction: 6 × 6 Dramadah.
Validation
In the previous training results, the optimal
What one observes in the following figures is that while they disagree in the exact amount of error, all demonstrate that the approach outlined in this paper is feasible. Specifically, the error as measured with respect to the Jacobi identity can be found in Figures 13 to 16 for the 3,4,5,and 6 square matrices, respectively. The plots are in log base 10 with the left side being the error based on the network

Jacobi error: 3 × 3 skew symmetric matrix.

Jacobi error: 4 × 4 quaternions evolution matrix.

Jacobi error: 5 × 5 random matrix.
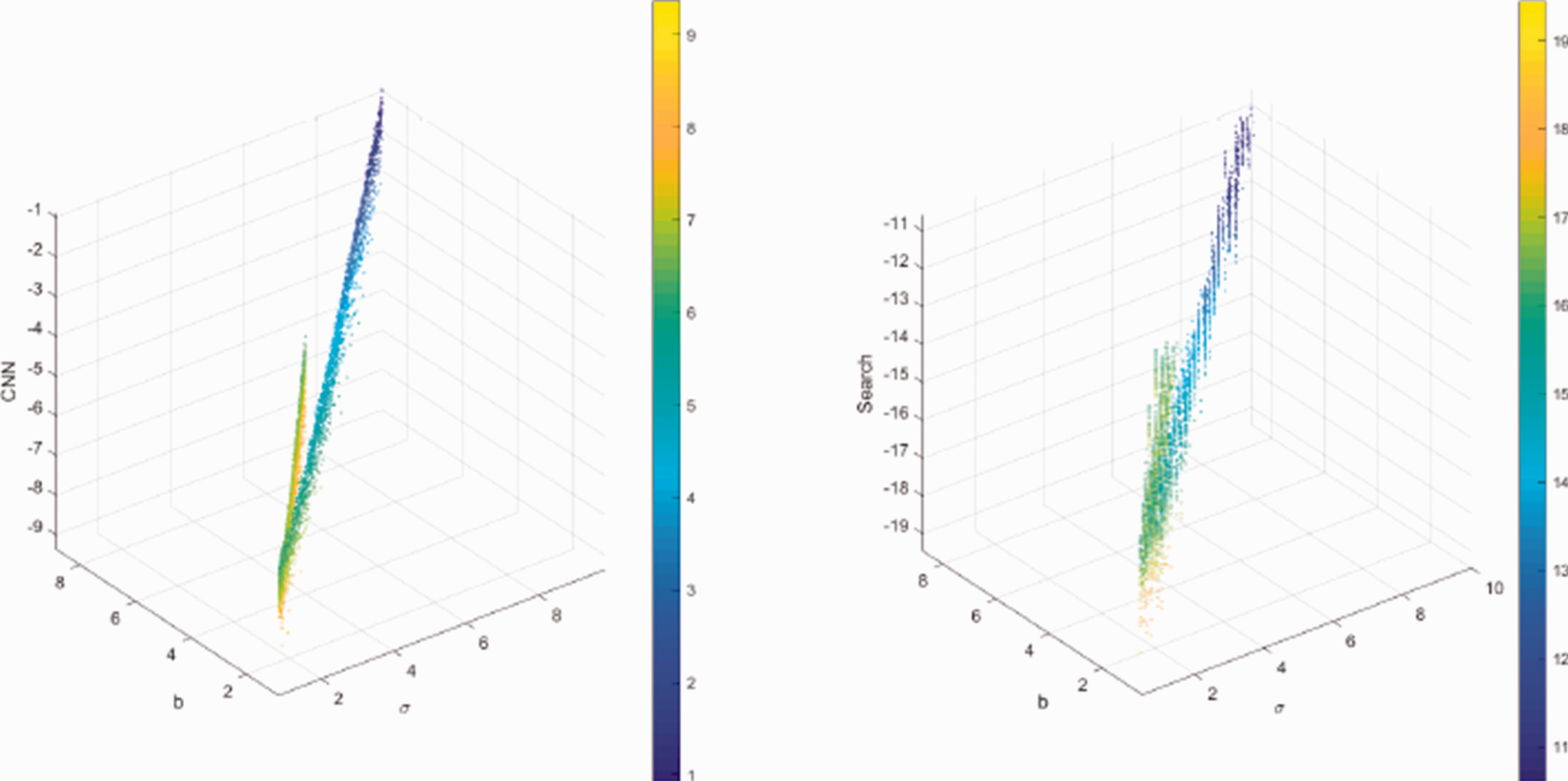
Jacobi error: 6 × 6 Dramadah.
The maximum per element matrix error results are plotted in Figures 17 to 20 for the four matrix families. Finally, those based on the total element error are found in Figures 21 to 24. The points across the three metric plots are for the same matrix exponential estimates. The maximum element and total element error calculations also provide a clear picture that the simple neural networks have been able to reasonably capture the basic minimum error surface shape for the four classes.

Max element error: 3 × 3 skew symmetric matrix.

Max element error: 4 × 4 quaternions evolution matrix.

Max element error: 5 × 5 random matrix.

Max element error: 6 × 6 Dramadah.
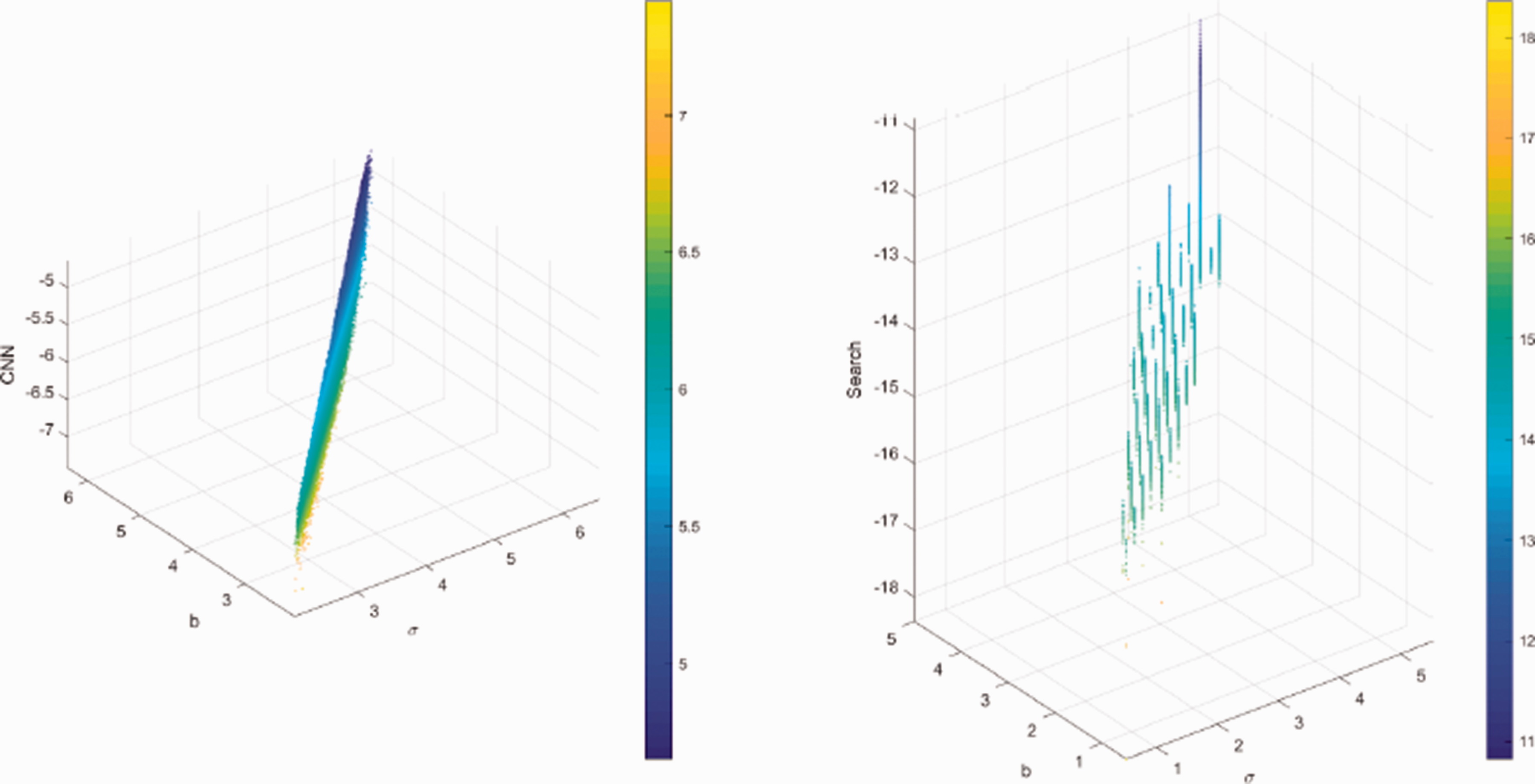
Total elements error: 3 × 3 skew symmetric matrix.
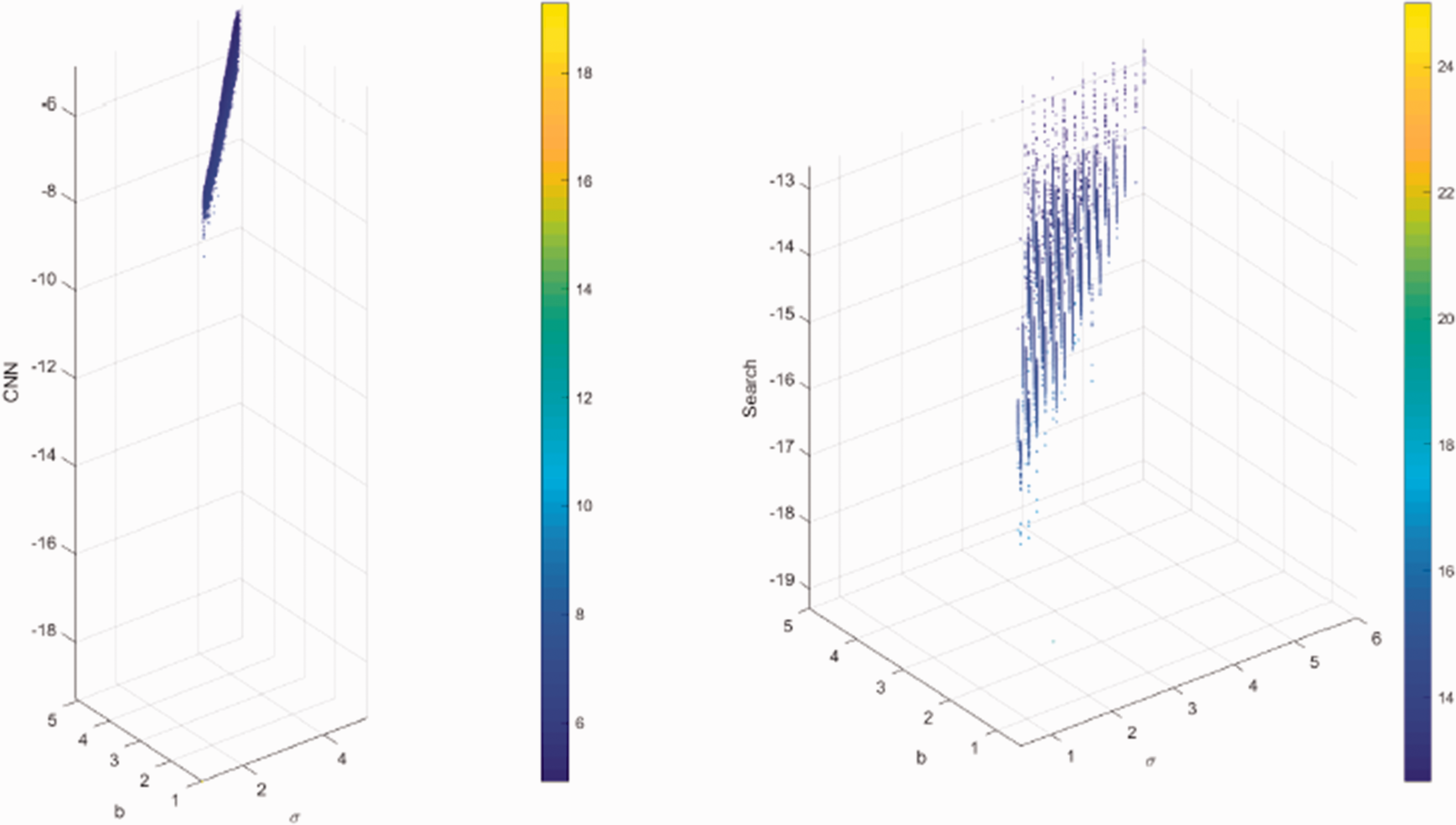
Total elements error: 4 × 4 quaternions evolution matrix.

Total elements error: 5 × 5 random matrix.

Total elements error: 6 × 6 Dramadah.
As a final summary note on the validation results, in Figures 25 and 26 are the 95% confidence intervals for the error metrics recorded in the previous validation figures. That is, the means and confidence intervals are of the matrix exponential error from the neural network predicted parameters and the direct minimization. From these figures one sees that the neural network based approach does yield similar confidence intervals relative to the mean error as observed from the full minimization. Another interesting result seen is that the Jacobi error metric has considerably wider confidence intervals for the larger matrices than for the smaller two matrices. Given that the Jacobi metric has potentially broader utility for larger matrices than the other two metrics, this fact about the confidence intervals may be of importance in practical applications or for training a network with larger matrices.

Confidence intervals for network derived errors.
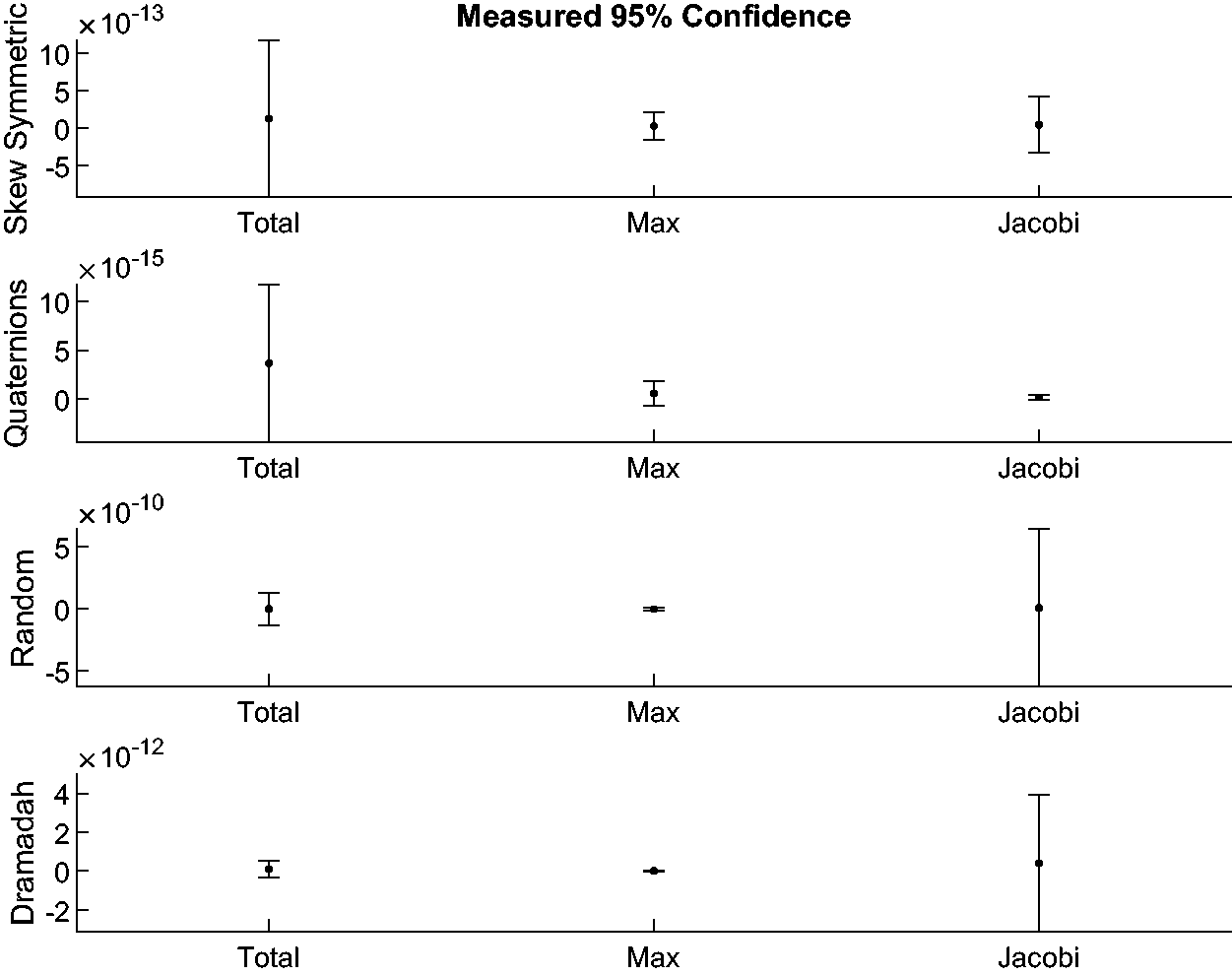
Confidence intervals for measured errors.
Conclusion
In this paper, we have introduced a machine learning based approach to the problem of selecting optimal parameters in Weeks method for the numerical inversion of the Laplace transform. Specifically, we have demonstrated that it is possible to train a convolutional neural regression network to estimate a
To illustrate, we have focused on the estimation of the matrix exponential eA by numerically inverting the corresponding resolvent matrix
A particularly useful result which came out of this analysis is the ability to train the Weeks method for the matrix exponential directly from the Jacobi identity. Practically speaking, this allows one to potentially train a neural network with the Weeks method for the exponential of matrices of any size without the need for comparison with a truth value. The small matrices used in this study were chosen to illustrate the approach and because it is relatively straightforward to compute their exponentials via the Cayley-Hamilton formula. Moreover, with the rational Padé approximations and the Cayley-Hamilton expressions for these small matrices, it has been possible to accurately estimate the matrix exponential from the Weeks method as the Möbius transformation parameters
For future mathematical research, three avenues are suggested. One is a more thorough investigation into different machine learning techniques for Weeks’ method optimization. The simple convolutional neural networks presented here demonstrate the efficacy of the approach but the choice of network layers and layer options was not fully optimized. There is a rich diversity of neural network architectures which may be more effective than those utilized here.
A second avenue is to reduce the parameters to only σ and allow b to be fixed. This would simplify the neural network training considerably. To compensate for a fixed b parameter, it may be possible to utilize adaptive integration for the numerical quadrature along the Möbius transform mapped unit circle contour in w. With adaptive quadrature, one might be able to outperform the trapezoidal rule approach used in this paper. 40
Expanding this approach to other Laplace transform pairs is an obvious third avenue for future work. The accurate solution of the differential equations describing viscoelastic beams, 41 the modeling of fluids, 42 and the high accuracy propagation of electromagnetic waves 18 are only a few specific examples of difficult problems which may benefit from the machine learning based approach to the Weeks method.
Supplemental Material
sj-zip-1-act-10.1177_1748302621999621 - Supplemental material for Optimal parameter selection in Weeks’ method for numerical Laplace transform inversion based on machine learning
Supplemental material, sj-zip-1-act-10.1177_1748302621999621 for Optimal parameter selection in Weeks’ method for numerical Laplace transform inversion based on machine learning by Patrick O Kano, Moysey Brio and Jacob Bailey in Journal of Algorithms and Computational Technology
Footnotes
Acknowledgements
This paper would not have been possible without the support from a number of colleagues at Raytheon Missile Systems. The authors especially wish to thank Michael Stinely who has been encouraging from the earliest conceptual phases of this work. Also to thank for their support are Nitesh Shah, Chanon Stewart, and Ross Newton. Ultimately, preparing this paper has required time and understanding from family. P. Kano particularly wishes to thank his son Brennan who challenges him with interesting discussions. The idea to explore the application of the approach in this paper to quaternions arose from one such conversation.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.