
Abstract
Methods for solving differential equations based on neural networks have been widely proposed in recent years. However, limited open literature to date has reported the choice of loss functions and the hyperparameters of the network and how it influences the quality of numerical solutions. In the present work we intend to address this issue. Precisely we will focus on possible choices of loss functions and compare their efficiency in solving differential equations through a series of numerical experiments. In particular, a comparative investigation is performed between the natural neural networks and Ritz neural networks, with and without penalty for the boundary conditions. The sensitivity on the accuracy of the neural networks with respect to the size of training set, the number of nodes, and the penalty parameter is also studied. In order to better understand the training behavior of the proposed neural networks, we further investigate the approximation properties of the neural networks in function fitting. A particular attention is paid to approximating Müntz polynomials by neural networks.
Introduction
Differential equations have received enormous attention for hundreds of years because of their applications in describing various phenomena and processes. For some differential equations, of classical types in particular, there exist explicit expressions for their exact solutions. 1 On the other side, a huge body of literature has been devoted to studying their numerical solutions, it is impossible to give even a very brief review here. Nevertheless, we refer to2–4 for a review on some classical numerical methods, such as finite difference, finite element, and spectral methods, frequently used for numerically solving differential equations.
However there is still a need to develop more efficient and universal methods to solve differential equations. With the emergence of computer science and scientific computing, artificial neural networks (ANN for short) is considered as one of such methods. Algorithms based on ANN have been extensively proposed since Lee & Kang’s pioneer work on neural network algorithms for solving first-order ordinary differential equations. 5 Later on Meade & Fernandez introduced an algorithm6–8 based on feedforward neural networks for solving ordinary differential equations. Subsequently, Lagaris et al. proposed algorithms for solving partial differential equations on regular and irregular domains.9,10 The key idea of their algorithm is to use the output of a single-layer neural network to construct numerical solutions that satisfy the exact boundary conditions. Based on the same idea, Mall & Chakraverty introduced a Legendre neural network 11 to solve ordinary differential equations. Some related works include the ANN by Pakdaman et al. proposed for solving fractional differential equations 12 , and Deep Galerkin Method by Sirignano & Spiliopoulos 13 for high-dimensional PDEs. A number of parabolic equations were used to demonstrate the efficiency of their method. E & Yu 14 proposed a deep neural network method, which consists in minimizing the Ritz functional associated to the underlying boundary value problems. They termed their approach as Deep Ritz Method. Recently, Piscopo et al. applied a neural network method to the calculation of cosmological phase transitions. Michoski et al. 15 investigated deep networks for compressible Euler equations, and compared the ANN to conventional finite element and finite volume methods.
For decades, ANN has been used as black boxes with a lack of theoretical understanding. Although it is an effective method for solving a wide range of problems, there has been no breakthrough in related theoretical research. To have an idea about how error analysis is possible, let’s take the example of elliptic equations. For some classical methods, such as finite element or spectral methods formulated in the Galerkin framework, the numerical solution is indeed the minimizer of the associated energy functional, and the error of the numerical solution can be bounded above by the best approximation of the exact solution in the polynomial or piecewise-polynomial space. In ANN, if the problem is formulated as the same minimization problem, that means one seeks the best approximation among all neural network functions. Therefore in principle the error of the ANN solution depends on how good the network approximates the exact solution. However one of main obstacles in ANN comes from the fact that the energy functional or other commonly used loss functions are rarely convex with respect to the hyperparameters. Thus the minimizer may never be attained. As a consequence the best approximation of the network functions tells not much about the quality of actual ANN solution. Glorot & Bengio 16 showed that standard gradient descent from random initialization converges poorly with deep neural networks. They also investigated the influence of the non-linear activation functions, and proposed an initialization scheme leading to faster convergence. On the other side, there exist approximation results on neural network functions. The first contribution at this direction can be traced back to the late 80’s when Cybenko proved that a single hidden layer network can approximate any function with arbitrary errors. 17 In the following years, some analysis of the function approximation using single hidden layer networks have been carried out successively; see, e.g.,12,18–22 However, few studies have focused on the choice of the hyperparameters of the network and how it influences the numerical solution of differential equations. Nevertheless we notice the work by Shen et al., 23 who have studied deep network approximation, characterized by the number of neurons.
To summarize, the weaknesses of the ANN in solving differential equations include: (i) loss functions are generally non-convex with respect to the hyperparameters. (ii) lack of theoretical convergence guarantees for the non-convex residual minimization. (iii) lack of efficient tool for the error analysis of ANN-based approaches for differential equations.
The aim of the present paper is to address some of these weaknesses, and intend to get a better understanding on some points. Precisely, we will first discuss possible choices of the objective functionals to be minimized in ANN for solving differential equations. Then we investigate the convergence behavior for different choices of objective functions, and how does the accuracy depend on the chosen network architecture. Finally we study the parameter sensitivity of ANN and how the hyperparameters have impact on the solution accuracy and algorithm efficiency.
The paper is organized as follows: In the next section we discuss the possible choice of the objective functionals and neural network approaches to be used in solving differential equations. Then presents numerical tests to demonstrate how the ANN solution behaves for different choices of loss functions. The treatment of the boundary condition is also discussed. In the subsequent section a series of numerical experiments will be conducted to study the effect of the parameters on the accuracy, including number of training points, number of hidden layer nodes, penalty parameter, etc. The penultimate section is devoted to studying the approximation behavior of ANN methods to target functions, and characterizing the training process in approximating specific functions. Finally, we give some concluding remarks in the final section.
Artificial neural networks and choices of loss function
This section is devoted to discuss about the possible ways to find an approximation solution to differential equations and attempts to provide some choices for loss functions in which ANN solutions can be obtained. First we regard neural networks as functions to fit exact solutions of differential equations. Notice that ANN are well suited to solving optimization problems, and a wide class of differential equations can be cast as an optimization task. Considering an ANN of a single hidden layer, that means we look for solution under the form

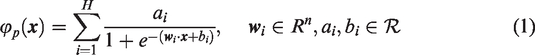
In the following subsections, we will explain the specific steps of solving differential equations by this method and how to construct the loss function.
Conventional numerical methods
Consider the general form of differential equations:


In many cases, the problem (2) is equivalent to the following variational problem: find


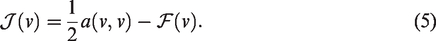
The problem turns out to be finding the function in the admissible function space V so that it minimizes the functional

Or equivalently, if

The choice of Vh distinguishes one method from another. For example, the spectral method or finite element method takes Vh as polynomial or piecewise polynomial space, while the wavelet method makes use of the space spanned by the so-called Wavelets functions.
Another way to construct numerical solutions is the so-called collocation method. To explain the idea, let’s consider the polynomial space, where the collocation approach is by far more successful than any other one. The spectral collocation solution is a polynomial uN of degree N that satisfies

Natural ANN method
As we have seen in the collocation method, to obtain a numerical solution for (2), we first need is to decide how to represent the solution, and then how to determine the solution. A natural idea is to take some points
In commonly proposed ANN methods for differential equations, the numerical solution is constructed under the form


To illustrate this method, we consider the following problem:

Then the ANN solution can take the form

Obviously the choice is not unique. One usually chooses the form that is easier to perform the derivatives. The drawback of the method lies in the fact that it is not always possible to find simple function satisfying the exact boundary condition, especially for complex domains.
To avoid the difficulty in constructing the boundary function, we may consider to relax the exact boundary condition by treating it as a penalty term in the loss function. That is, instead of minimizing the loss function (10), we look for a solution of form

For both loss functions, (10) and (11), the ANN solution will be obtained by finding
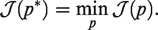
The superiority of the penalty method (11) over the ANN with exact BC (10) is that it is more universal, and can be easily used for any type of boundary condition. Apart from the different features of these two methods emphasized above, another interesting and important issue is about their performance, which, as far as we know, has not yet been addressed in the literature. One of the purpose of the present paper is to carry out numerical experiments to compare the performance of these two methods in term of the accuracy and convergence.
Ritz ANN method
The Ritz ANN method for differential equations was inspired by the observation that ANN is well suited for solving optimization problems, and many of differential equations can be formulated as optimization problems.
Supposing we are solving the equation (2). As we have pointed out in subsection ‘Conventional numerical methods’ , in some cases (2) can be reformulated as a minimization problem (4). Contrastly to the conventional methods which consist in finding the approximative solution in polynomial or piecewise polynomial space, the Ritz ANN method aims at seeking a function


If we don’t want to have trouble with constructing admissible function in V, we can choose to relax the essential boundary condition by treating it as a penalty term in the loss function. In this case we seek the solution
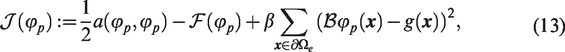
In actual calculations, it may be difficult to accurately calculate the integral, especially in high-dimensional space. Therefore some kind of numerical integral becomes indispensable. In our numerical experiments carried out later we will use Monte Carlo integral approximation as follows:

It now remains to compute the gradient of the loss functions, which can be (10), (11), (12), or (13). This is necessary if we want to use the gradient method to solve the minimization problems. Consider an ANN with n input units, one hidden layer with H sigmoid units and one output unit. For a given input vector

With the help of the above formulas, we can give the expression of each term of the loss function. To minimize the loss function

In practice, there are many factors that affect the efficiency of optimizing the loss function, such as the structure of the ANN, the structure of the loss function, the value of learning rate, and so on. We will study these in depth in subsequent sections.
Comparative investigation among conventional, natural, and Ritz ANN methods
In this section, we carry out a series of numerical tests to compare the accuracy and convergence behavior between the conventional method and ANN method, and investigate the impact of different forms of loss functions on the performance of ANN method. We will give three differential equations as examples to figure how different loss functions can influence the accuracy of the numerical solutions. To ensure that the numerical solutions obtained by different loss functions are comparable, our ANN only has one hidden layer, and its nodes will be fixed. The minimization algorithm used in our numerical experiments that follow below is the AdamOptimizer module in TensorFlow.

The exact solution is
This is a classical elliptic problem, which can be reformulated into an equivalent symmetric variational problem so that its solution can be obtained either by solving a conventional Galerkin-based numerical method or by solving the corresponding minimization problem. We first compare the accuracy of the conventional Galerkin-based piecewise linear finite method (6) and the method of minimizing the Ritz functional (5) in the piecewise linear finite element. i.e., (7). The computed results are shown in the left figure in Figure 1, in which we compare the errors of the two methods using 130 equidistance grid points. It is observed that the pointwise errors of the numerical solutions computed by the two methods are almost the same. This implies that the minimization algorithm successfully found the global minimizer of (7) in the finite element space, which is also the solution of the Galerkin-based finite element problem (6). In the right figure of Figure 1 we plot the error history of the solutions as a function of the number of the grid point. It is found that the error decays as
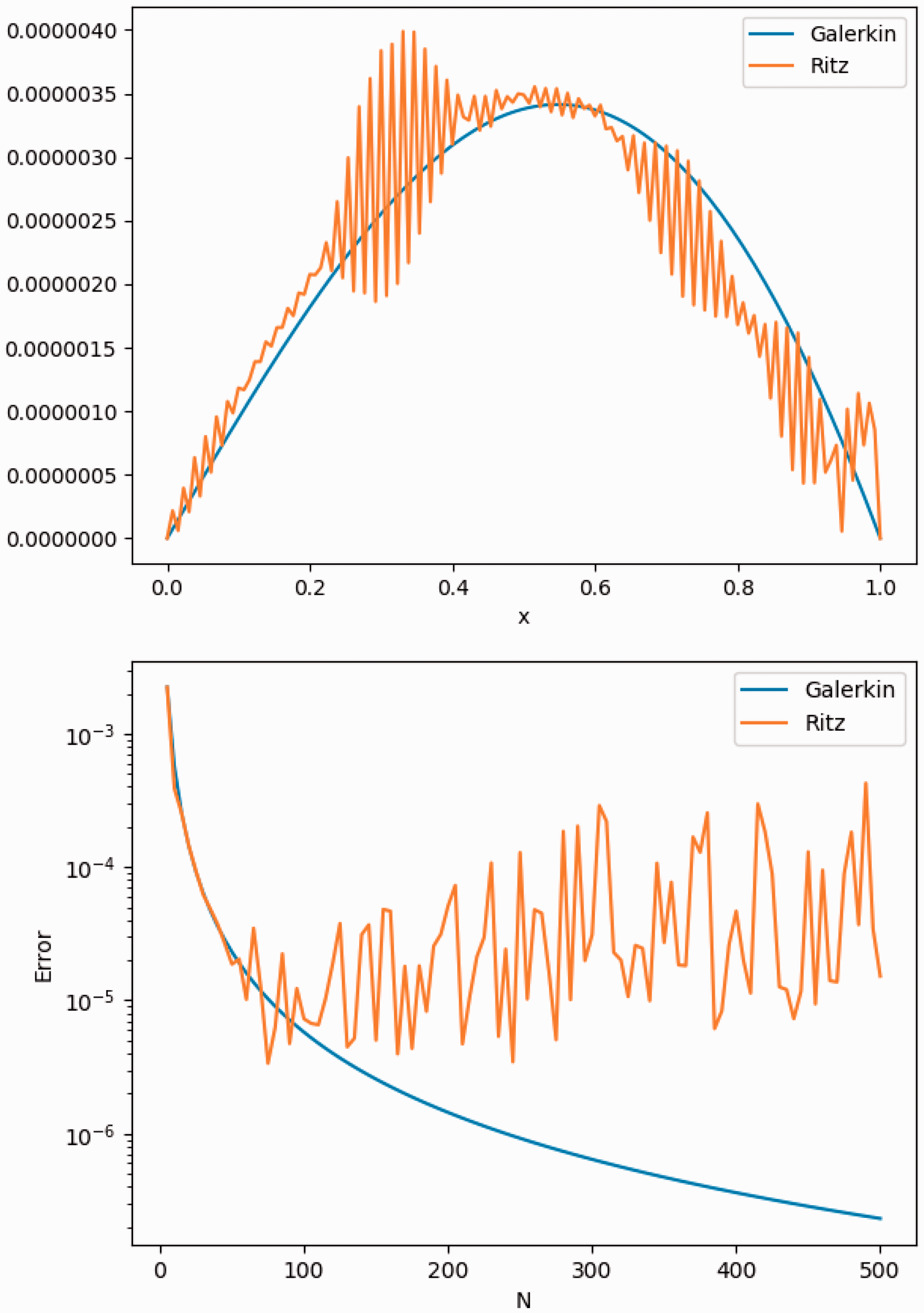
Upper: errors for the piecewise linear finite element method and Ritz minimization with 130 equidistance points. Lower: errors versus the grid number N.
Next test concerns the performance of the ANN method, and the accuracy comparison among different loss functions. We will test the ANN method with the loss functions defined in (10), (11), (12), and (13). The error history versus the iteration number of the minimization algorithm is presented in Figure 2 for all four methods, i.e., ANN with exact BC (10), ANN with penalty (11), Ritz-ANN with exact BC (12), and Ritz-ANN with penalty (13). The calculation is performed with


Error decay with respect to the iteration number for the loss functions (10), (11), (12), and (13).
From Figure 2 we can see that all four ANN methods generate numerical solutions with relatively high accuracy, which confirms the effectiveness of the ANN methods.
Also observed from this figure is that the error curves become flat or oscillating after about 20,000 iterations, which means that the minimization algorithm reaches the minimizer (probably local minimizer) at this iteration, and continuing running the algorithm does not improve the accuracy. The minimum errors captured during the iterations for different methods are listed in Table 1. As can be seen from this table, although the traditional Galerkin FEM has high accuracy dealing with this equation, some ANN methods, like (10) and (11), achieve higher accuracy with fewer parameters. It’s also obvious from this example that the accuracy of the natural ANN method is much higher than that of the Ritz ANN method. In the meanwhile, for the same type of the loss functions (natural or Ritz), a better accuracy is obtained if we enforce the numerical solution to exactly satisfy the boundary conditions. This experiment shows the superiority of enforcing the exact boundary conditions in the ANN function space compared to the penalty strategy. It is worth to point out that in the penalty formulations the choice of the penalty parameter β is an issue, and in some case, taking β = 1 in (13) for instance, the algorithm does not converge to the exact solution.


The exact solution is
Notice that the bilinear form associated to this example is no longer symmetric, so we can’t apply Ritz ANN methods in this situation. We will only compare the Galerkin method and the natural ANN method. First, we fix

Upper: pointwise errors for Galerkin method. Lower:
Then we test the accuracy for the same problem with a smaller ε, i.e.,

Upper: pointwise errors for Galerkin method. Lower:
In the following example, we will solve a two dimensional partial differential equation by the natural ANN and Ritz ANN methods, and compare their performance. Due to the difficulty of constructing exact boundary conditions for multiple dimensional problems or complex domains, we will only consider the loss functions (11) and (13). We take
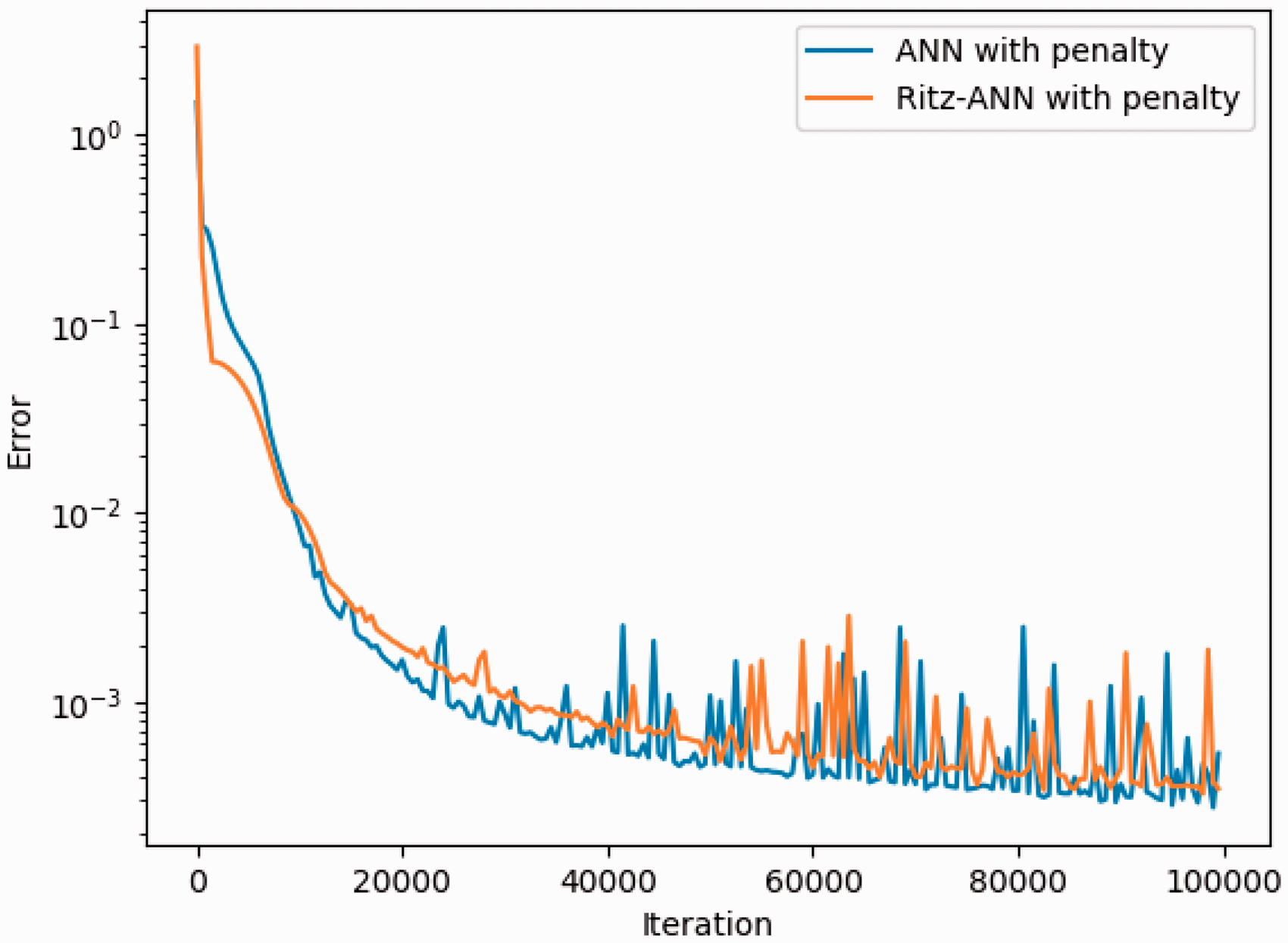
Error evolution during the training process for Example 3.

The exact solution is
It is readily seen from the presented numerical result that the minimization algorithm has almost same behavior for the two loss functions (11) and (13), and minimizing the two functions in the ANN function space gives almost same accuracy. This is in contrast with what we have observed in Example 1, where the result reported in Figure 1 showed that the accuracy of using (11) is better than that of (13). This seemingly contradictory result implies that the type of differential equations will affect the effectiveness of different ANN methods, and we would better not claim that one method is definitely better than others by only a few examples.
Parameter sensitivity investigation on single-layer network
In the previous section, we have shown by several examples that the ANN function has good approximation property, and minimizing suitable loss function (natural or Ritz type) in the ANN function space led to satisfying numerical solutions. We now turn to investigate how the ANN parameters have impact on the approximation property of the ANN function and on the convergence of the minimization algorithm. Before doing numerical experiments, a few things need to be stated in advance.
Firstly, we will use the examples tested in section ‘Comparative investigation among conventional, natural, and Ritz ANN methods’ for experiments. In each example, we fix the values of other parameters and only vary the parameter being tested. We will record the errors in
For some differential equations whose operator
Size of the training set
In this subsection, the network will be trained over a training set of equidistant points of increasing sizes. That is, we will increase the value of

Errors of different methods versus the number of training points N. Upper: Example 1. Middle: Example 2 with
Number of nodes in hidden layer
In this subsection, the network will be trained over a fixed training set of equidistant points with increasing number of hidden layer nodes

Errors versus the hidden layer nodes H for different methods. Upper: Example 1. Middle: Example 2 when
It is found that for Example 1, the maximum errors of the numerical solutions from all tested methods remain almost same when the hidden layer node H changes. This is probably due to the fact that the exact solution of Example 1, i.e., a trigonometric function, can be well approximated by only a few nodes. For Examples 2 and 3, the error decreases with increasing hidden layer node H at the beginning up to a value, then increases with increasing H. Notice that the solution space becomes larger as H increases, and theoretically more accurate solution should be found in a larger space. The numerical results given in Figure 7 seems to contradict with the theoretical prediction. To explain this contradiction, let’s emphasize that enlarging the solution space results in an increase of the local minimum, which makes the loss function easily fall into the local minimum. Furthermore, an excessively large solution space will cause overfitting, which will increase the error of the numerical solution at the test point.
Impact of the penalty parameter of loss function
This test concerns investigation of the impact of the penalty parameter used in loss function to deal with the boundary condition. As reported in section ‘Comparative investigation among conventional, natural, and Ritz ANN methods’, when we take β = 1 in (13), the numerical solutions lose accuracy dramatically in Example 1. When optimizing the loss function, the penalty parameter can be regarded as weights to the corresponding term, which plays a role to balance the satisfaction of the equation and boundary condition. Other parameters are fixed as in subsection ‘Number of nodes in hidden layer’. The errors respectively on the domain and the boundary versus the penalty parameter β are plotted in Figure 8. An interesting finding from this test is that increasing the penalty parameter results in damaging the accuracy of the natural ANN methods. This seems to indicate that for the natural ANN methods, we would better fix β to a smaller value to avoid possible lose of the accuracy. On the contrary, the Ritz ANN methods produce more accurate solution for relatively larger β, especially for Example 1. The accuracy of the Ritz ANN method is significantly improved as β gradually increases. However when the penalty parameter becomes extremely large, the same phenomenon as the natural ANN appears. This suggests use of a moderate penalty parameter, say

Errors versus the penalty parameter β for different ANN methods. Upper: Example 1. Lower: Example 3.
Fitting a target function
In the previous section, we performed a series of sensitivity analyses on the parameters in the neural network algorithm for solving differential equations. As we have observed from the numerical experiments, different forms of loss function and the hyperparameters of ANN will affect the efficiency of the algorithm to find accurate numerical solutions. Theoretically, increasing the number of hyperparameters enlarges the ANN approximation space, and thus results in a better accuracy for the approximation to a given function. However we have seen that this did not equally lead to a better accuracy of the numerical solution as expected in some of the numerical examples. This is one of our key observations from the previous numerical tests, which we want to further understand here. Apparently the efficiency of the ANN methods is related not only to the form of the loss function, but also to the feature of the exact solution. Therefore, in this section we aim at studying the approximation behavior of the ANN methods to target functions using different activation functions, and characterizing the training process in approximating specific functions.
Given a function f, an ANN approximation consists in finding suitable parameters p that minimizes the loss function:

For fitting functions with neural networks, Barron
18
proved that the mean integrated squared error between the output of the network and the target function is bounded by
Choice of activation function
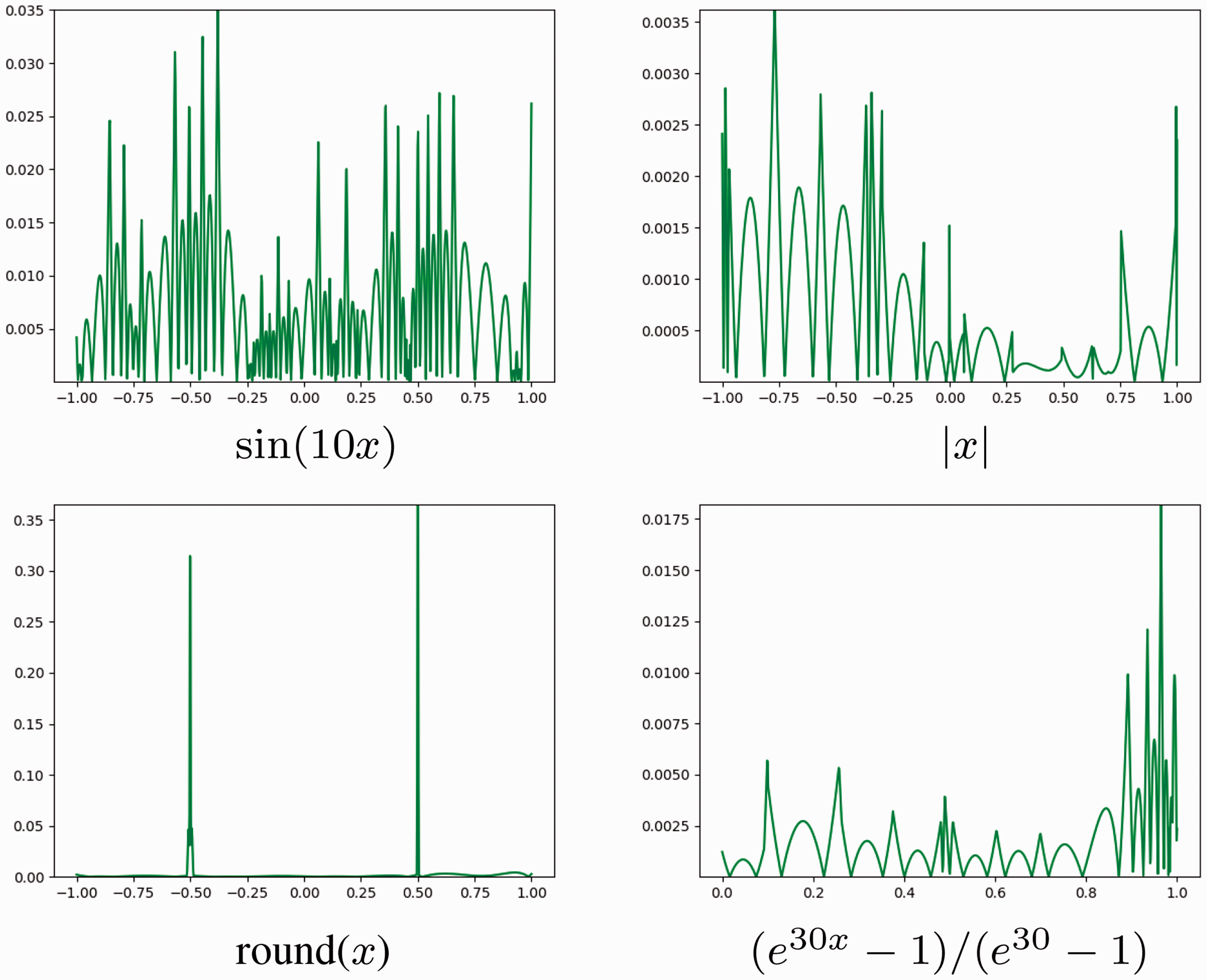
In this subsection, we want to figure out whether an activation is suitable to approximate the target function and how shall we choose the activation function according to the target function. We will use the following functions as examples to test the effect of ANN in fitting functions.

The above target functions have their own characteristics respectively. Among them,
We first test for a sigmoidal function, and the result is presented in Figure 9. We can observe from this figure that when the target function is smooth, the accuracy is quite satisfying. When there exists a discontinuous point or a non-differentiable point, the ANN method results in a less precise approximation. Nevertheless, it is notable that the effect of the discontinuity on the precision seems to be local. That is, the precision remains satisfying outside a small region surrounding the discontinuities or large gradient. This is one of the superiorities of ANN methods compared to conventional approximations in which the effect of the discontinuity is often global.

Fitting errors of ANN methods for four functions with a sigmoidal activation function.
We then test for the Relu function, i.e.,

Fitting errors of ANN methods for four functions with the Relu activation function.
These observations motivate us to consider a compromise: constructing a mixed ANN approximation using both Relu and sigmoidal basis functions. It is expected that such a mixed ANN may take the advantages from both activation functions. To this end, we divide the hidden layer into two parts, and use the sigmoidal basis function in one part and the Relu basis function in another. More precisely, we construct the mixed ANN as follows:

Figure 11 shows the fitting result by using the mixed ANN. It is clearly seen that, except of the first target function for which the sigmoidal basis function produces a little lit better accuracy, the mixed network improves the accuracy for all other three target functions, especially for the second.
Fitting errors of ANN method with the mixed activation function.
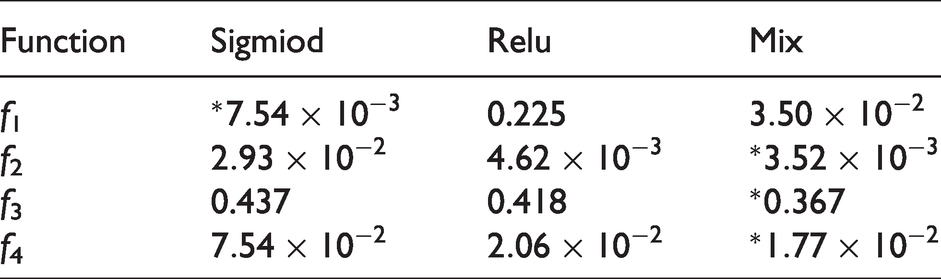
We present some more details of the above experiments in Table 2, from which it becomes clear that the mixed ANN is most accurate for almost all tested target functions.
Fitting Müntz polynomials
Müntz polynomials show unique advantages in many situations, whose application covers a large number of problems. In particular, it has been found 27 that the Müntz polynomials can more accurately approximate the solution of some equations, such as integro-differential equations, fractional differential equations, and so on, than the traditional polynomials. In this subsection we aim at investigating the capability of ANN methods to approximate Müntz polynomials. This can be regarded as the first step toward constructing efficient ANN methods to solve integro-fractional differential equations.
A n terms Müntz polynomial can be written as 

There are only two terms in this Müntz polynomial, therefore there are two coefficients and two power values to be optimized in the neural network. Figure 12 shows parameter fitting during the training process. We can readily see that after 20,000 iterations, both the power wj and the coefficient parameter aj in the neural network gradually stabilizes at their exact values, i.e., –2 and
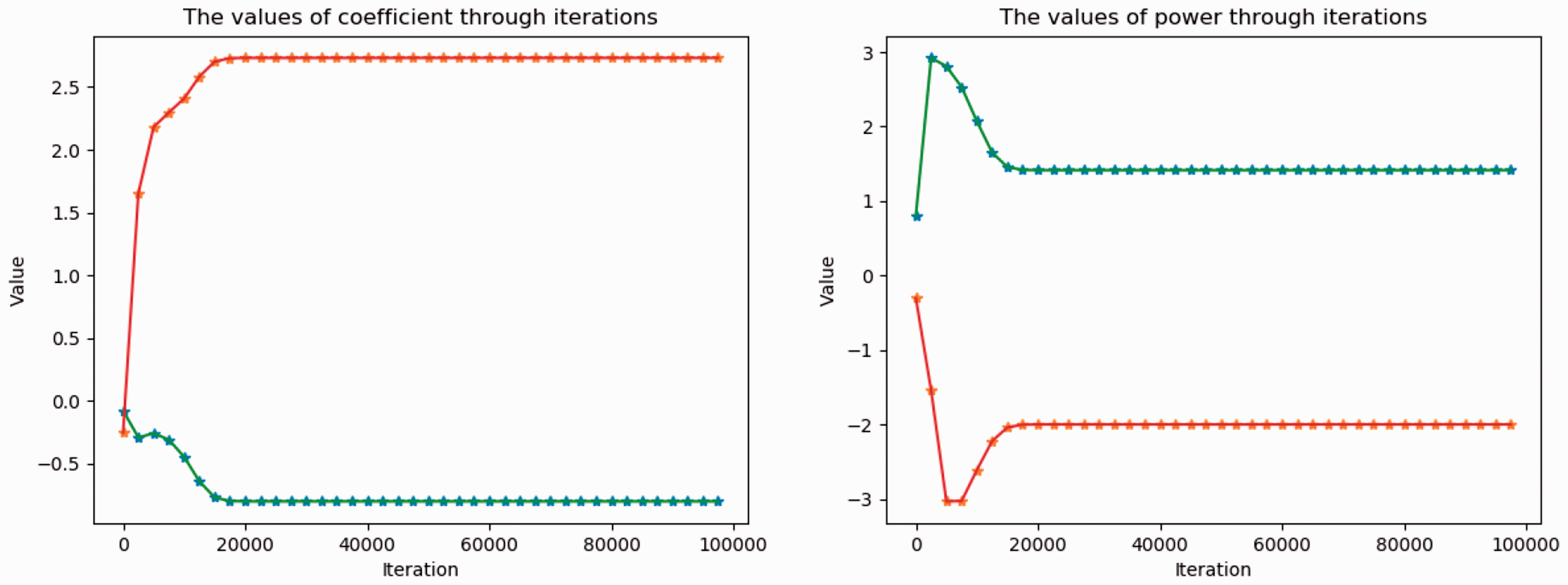
Parameter fitting during the training process for Example 4.

Errors of the convergent solution for Example 4 and Example 5.
Example 4 showed how the neural network learns each parameter step by step, and precisely find the parameters of the target function. Now we consider a three-term Müntz polynomial in Example 5. The corresponding result is presented in Figures 13 and 14. Surprisingly, although the approximation error remains good enough, the networks fails to find the exact parameters of the target function, neither the coefficients nor the powers. A reasonable explanation for this failure is that increasing the number of terms, which means increasing the parameter space, makes the number of local or global minimum larger. In fact, it can be directly checked that for a Müntz polynomial with n terms, there are
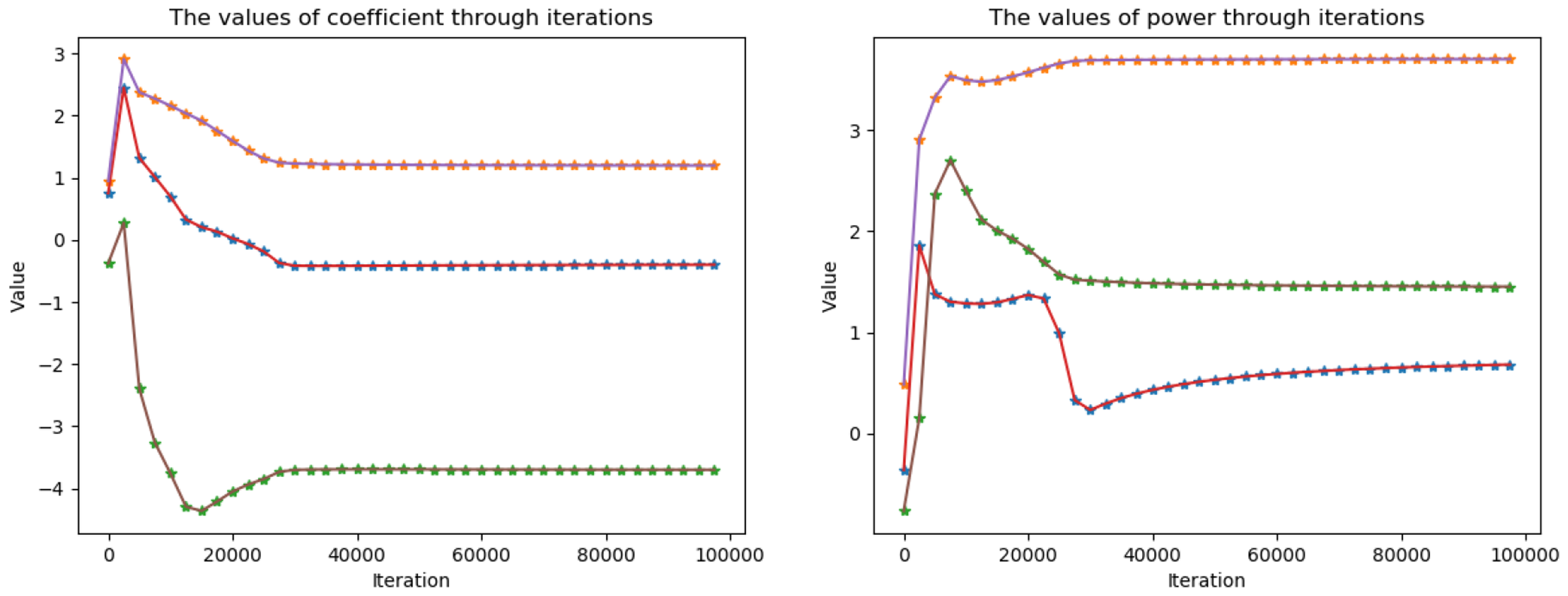
Parameter fitting during the training process for Example 5.

Conclusion and discussion
In this paper, we have discussed possible forms of loss functions in an ANN method for solving differential equations, and investigated their efficiency through a number of numerical examples. In particular, a comparative investigation was carried out between the natural ANN and Ritz ANN methods, and between the penalty strategy and imposing the exact boundary condition in the ANN function space. The sensitivity on the accuracy of the ANN methods with respect to the size of training set, the number of nodes in hidden layer, as well as the penalty parameter was also studied. Finally, in order to better understand the training behavior of the proposed neural networks, we have selected several types of functions, and studied their approximation properties by the ANN methods.
Although no decisive conclusion was reached regarding the choices of loss functions or activation functions, some interesting points can be drawn from our numerical study:
– in most of our tests, the natural ANN has demonstrated its superiority compared to the Ritz ANN;
– an ANN with exact boundary conditions is more accurate than an ANN with penalty;
– smooth activation function is preferable over nonsmooth activation function in approximating smooth functions. On the contrary, it is better to use nonsmooth activation function such as Relu in approximating nonsmooth functions. Generally, mixed use of smooth and nonsmooth activation function is recommended.
– the proposed Müntz ANN is only capable of finding few-term Müntz polynomials, more investigation is needed to see how an ANN can be trained to find a general Müntz polynomials.
The numerical experiments carried out in the current paper did not give a solid mathematical foundation to ANN for solving differential equations, but might provide guidance for subsequent theoretical analysis. As part of the future work, we will try to study the convexity of different forms of loss functions under specific examples. Another interesting direction that is worth exploring is to establish the relationship between loss function and errors.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research of the authors is partially supported by NSFC grant 11971408, NNW2018-ZT4A06 project, and NSFC/ANR joint program 51661135011/ANR-16-CE40-0026–01.