
Abstract
In recent years, the research of deep learning has received extensive attention, and many breakthroughs have been made in various fields. On this basis, a neural network with the attention mechanism has become a research hotspot. In this paper, we try to solve the image classification task by implementing channel and spatial attention mechanism which improve the expression ability of neural network model. Different from previous studies, we propose an attention module consisting of channel attention module (CAM) and spatial attention module (SAM). The proposed module derives attention graphs from channel dimension and spatial dimension respectively, then the input features are selectively learned according to the importance of the features. Besides, this module is lightweight and can be easily integrated into image classification algorithms. In the experiment, we combine the deep residual network model with the attention module and the experimental results show that the proposed method brings higher image classification accuracy. The channel attention module adds weight to the signals on different convolution channels to represent the correlation. For different channels, the higher the weight, the higher the correlation which required more attention. The main function of spatial attention is to capture the most informative part in the local feature graph, which is a supplement to channel attention. We evaluate our proposed module based on the ImageNet-1K and Cifar-100 respectively. Through a large number of comparative experiments, our proposed model achieved outstanding performance.
Keywords
Introduction
In computer vision, image classification is a subject worthy of long-time research, and it is an important foundation in some fields such as object detection1–5, face recognition6–10, pose estimation11–13, population density estimation14,15, image segmentation16–19 etc. Therefore, image classification20–26 has always been a hot topic. At present, the image classification algorithm mainly relies on the deep neural network model. Besides, a lot of high quality images are needed. After training the deep neural network model, an input image can be correctly recognized. However, due to the large number of image categories and the limitation of computing resources, it is difficult for traditional classification algorithms to achieve satisfactory accuracy. In fact, deep learning is an extension of machine learning and many scholars have done a lot of research on it. Different from the traditional image classification method, it does not require complex feature decomposition of the target image. Deep learning uses deep neural network models and a large number of images to learn features. Thus, the deep learning algorithm is suitable for image classification task.
In daily life, when we look at a image, the most basic task is what the image is, whether it is a landscape image or a figure image, whether it describes a building or food. For computer vision, this is an image classification task. The main difficulty of image classification is the step of feature extraction. Once a distinguishable feature is found, the iamge classification becomes very easy. The so-called feature extraction refers to constructing an algorithm to extract features in the target image, such as the edge feature of the face, the color feature of the skin etc. The extracted features are used to distinguish the target object as much as possible from other objects. For example, what you need to distinguish is a black cat from a white cat, so the color feature is definitely a good feature. However, the difficulties encountered in life are often difficult to extract features, such as detecting pedestrians and vehicles on noisy streets. The task requires high accuracy of the detection algorithm to avoid a car accident.
At present, the best approach is to use deep neural network model27,28 for image classification tasks. The experimental result of VGGnet29–31 shows that the block with the same shape can obtain better classification accuracy by constructing deeper convolutional neural network model. With the same idea, the deep residual network is constructed by cross-layer connection method and it achieves higher classification accuracy. GoogLeNet 32 increases the adaptability of the network to different scales, showing that adjusting the width of model is also an important method to obtain better classification accuracy. ResNeXt 33 and Xception 34 added cardinality to the network model, proving that the cardinality can not only reduce the overall parameters of the model, but also has a strong ability of representation.
The attention mechanism is similar to human vision. When we look at the scene around us, we always focus our attention on the main things to get key information. The main purpose of the attention mechanism is to make the system focus its attention on key information in the scene. Attention mechanics can be used in a wide range of scenarios. The neural network captures key information with the help of the attention mechanism and we can take use of attention mechanism to observe things in the environment better. In the traditional neural network model, adding convolution channels and operating multiple convolutions on features in the same channel usually bring a certain degree of accuracy improvement. The attention mechanism make neural network model know how to pay attention on channel dismension and spatial dismension. In order to verify the role of attention mechanism in computer vision more clearly, the CAM and the SAM are analyzed from the point of attention domain. The attention domain mainly consists of three types: spatial domain, channel domain and mixed domain. In our experiments, it is found that better performance is obtained with using the CAM before the SAM.
Wang fei et al. propose a novel model based on the attention mechanism
35
and it is named the residual attention network. As the network layer deepens, attention modules can extract key information from different layers. Finally, it got 4.8 We propose a large-scle image classification algorithm. By combining RestNet and attention module, our prposed algorithm obtains lower Top-1 error and Top-5 error performance on Image-1K and Cifar-100 respectively. We introduce channel attention module and spatial attention module. To verify the order in which module is used first, we experiment much ablation study. The result confirms that the channel attention module should be used before the spatial attention module.
Channel and spatial attention module
For the convolutional neural network model, depth, width and attention mechanism45–49,51 are the main factors affecting the accuracy of image classification. At present, attention mechanism contains CAM and SAM. CAM acts on the channel domain, weighting different channel features. For a
After convolution operation, the intermediate feature map,
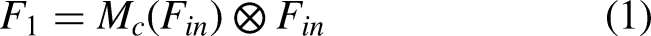
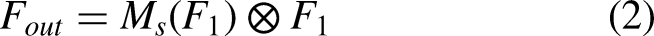

The overview of model.
Channel attention module
The CAM captures the relationship between channel features. It pays attention to the key channel information and weakens the influence of the useless channel information. It uses an attention mechanism similar to the self attention mechanism (query, key, value) to get the similarity between channel graphs, and then use the weight of channel graphs to update. Finally, the matrix of computation attention is obtained, which can enhance the key features. The CAM makes the neural network model to pay attention to the channel features with the key information. On the basis of convolution, we first extrude the feature graph to obtain the global feature of each channel. Then, we use the global feature to get the relationship between different channels and the get the weight of different channels. Finally, we multiply the weights to get the features on the basis of the original feature graph.
In a convolutional neural network, the convolution operation only performs on image feature space, it is difficult for the convolution module to get the relationship between different feature channels. To get an eigenmatrix, an image needs go through several convolutional layers and the number of channels represents the number of cores in the convolutional layers. In a normal neural network, the number of convolution kernels is usually as high as 1024 or 2048. Therefore, not every channel is useful for feature extraction. The CAM will help the neural network model to select more informative channels. Besides, We encode spatial features using a global average pool that provides feedback for each pixel on the feature map. The following formula shows the global average pool calculation process.

In order to capture the relationships between different channels when obtaining the global description features, two conditions need to be met for CAM: firstly, it must be flexible, because it needs to learn the nonlinear relationship between different channels; Secondly, the learning relationship is not mutually exclusive, because it allows for a multi-channel feature instead of a hot spot form. We describe the channel attention map
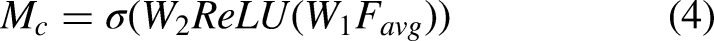

The details of channel attention module.
Spatial attention module
Unlike CAM, SAM only plays the role of distinguishing key information within a single image feature map. First of all, we use average pooling and max pooling to compress the input feature and then we use mean and max operations on the input feature at channel dismensions. Finally, we get two two-dimensional features. Considering different channel size, the two two-dimensional features are spliced together to obtain the feature with channel number of 2. And they are convolved to ensure that the resulting features are consistent with the input feature in spatial dimension.
Spatial attention map is generated by paying attention to the internal relationship. As shown in Figure 3.
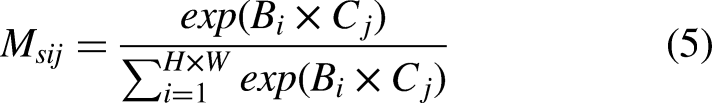
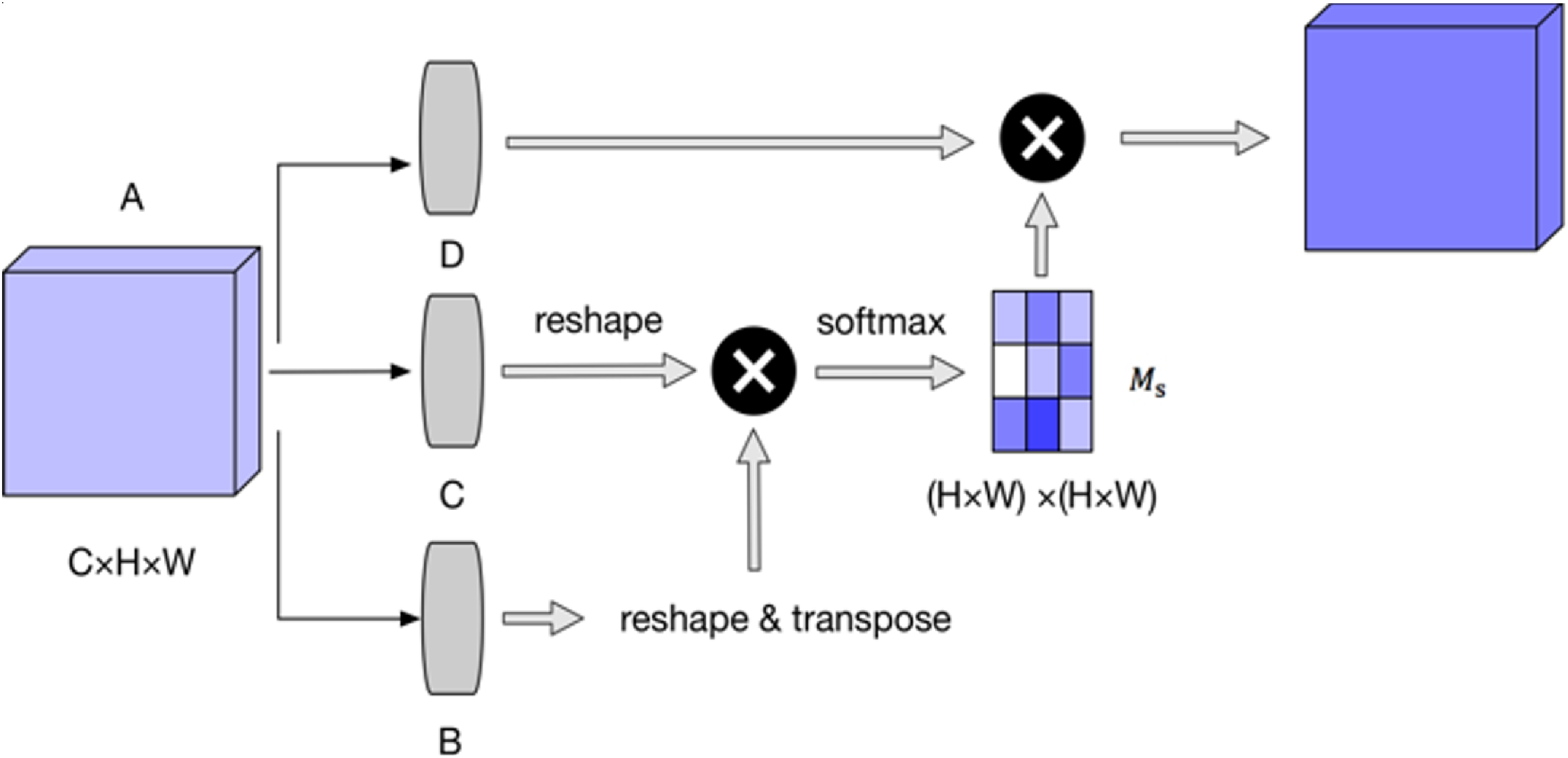
The details of spatial attention module.

Diagram of the visualization results.
Experiments
The dataset is used in the experiment including ImageNet-1K and Cifar-100
50
. The Cifar-100 contains 100 classes and every class has 600 color images. But every images is only a size of

Visual examples of the Cifar-100.
ImageNet-1K is an image dataset and each concept image is quality-controlled and manually tagged. At present, ImageNet-1K consists of 1,4197,122 images. The major categories include: animal, bird, fish, flower etc. In Figure 6 shows the visual examples of the ImageNet-1K.

Visual examples of the ImageNet-1K.
Ablation studies about different attention module
In experiment, we compare the effectiveness between the CAM and the SAM. We compared 4 different network models: baseline network, baseline network with CAM, baseline network with SAM, baseline network with CSM. The result of experiment is shown in Figure 7.

Comparison of different network models.
From Figure 7, it is easily concluded that the ResNet-50 model with CSM (channel attention module and spatial attention module) has achieved higher accuracy. We can observe that CAM perform better than SAM. Besides, combination of two attention modules can bring better performance. The experiment shows that it is effective to conduct CAM and SAM at the same time. The experimental results are shown in Table 1.
Comparison of different module combination order on the ImageNet-1K dataset.

Ablation studies about the order of attention module
Based on the above part of the experiment, we find that it is effective to conduct CAM and SAM at the same time for improving the expression ability of neural networks. We want to know if the CAM should be used before SAM. So, in the ablation experiment, we compare the effect of CAM and SAM in different order of use. The baseline network with CAM and SAM, baseline network with SAM and CAM are conducted respectively. Figure 8 shows the result of experiment.

Comparison of different combination methods.
Consistent with the above experiment, adding the attention module still bring improvement on image classification accuracy from Figure 8. We can observe that the CAM-first combination method achieves better performance. The experimental result shows that CAM-first combination method is more effective.
Experiment condition and computational complexity
In this paper, we verify our proposed algorithm on a server with 8 NVIDIA Tian X. With the deeper of the residual network, the better our proposed algorithm performs. ResNet-50 obtains the best performance. Thus, we give the time consumption of ResNet-50. For a single pass forwards and backwards, ResNet-50 takes 190 ms with a trainging minibatch of 256 images. SE-ResNet-50 takes 209 ms. BAM-ResNet-50 takes 195 ms. CBAM-RestNet-50 takes 210ms and our proposed method takes 215 ms. Furthermore, it can be found that the larger the batch size, the higher the stability of the experiment data. To avoid the uncertainty of the parameters in the training model, the experimental data (classification error and classification accuracy) was recorded by mean.
Image Classification on ImageNet-1K
In this part, we use ResNet and WideResNet as the baseline model. On this basis, we add attention mechanism for comparison. The extensive image classification experiments are conducted based on the ImageNet-1K. The structure of ResNet with adding SE module is shown in Figure 9 and the results of the experiment is shown in Table 2.

The structure of ResNet with adding SE module.
Results of the experimental on the ImageNet-1K dataset.

The experiment still prove that networks with CSM performs better than the baseline module, indicating that attention mechanism can be well used on the various network models. Besides, the depth and width of the neural network also greatly affect image classification accuracy. SENet won the ILSVRC2017 classification task championship. But CSM fuses channel features with spatial features for better representation capabilities and CSM performs better than SENet.
Image Classification on CIFAR-100
Based on Cifar-100, we carry out image classification experiment to verify the effectiveness of the CSM. ResNet and WideResNet are used as baseline model. Table 3 shows the experimental result. The experimental results prove that the combination of CAM and SAM can improve classification accuracy. Besides, the depth and width of the neural network also greatly affect image classification accuracy.
Result of the experiment on the Cifar-100 dataset.

Conclusion
Different from the previous research on image classification, we propose an attention module based on spatial dimension and channel dimension. This module derives the attention map by CAM and SAM respectively. Then it multiplies the attention map into the input feature map. The experiment shows that adding the attention module to some image classification algorithms is an effective method. In order to make image classification perform better, combination of CAM and SAM can improve classification accuracy and the CAM should be used before SAM. The CAM selectively enhances some feature channels and suppresses some feature channels by learning the relational mapping. The SAM aggregates features by weighting features at spatial dismension. We conducted a lot of image classification experiments for comparison based on the ImageNet-1K and Cifar-100. In fact, the attention module can be well embedded in different deep neural networks and it improves the deep neural network’s ability of expression. Besides, the width and depth of the neural networks are also worth considering.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (NO. 61702226); the 111 Project (B12018); the Natural Science Foundation of Jiangsu Province (NO. BK20170200); the Fundamental Research Funds for the Central Universities (NO. JUSRP11854, NO. JUSRP11851).