
Abstract
Many eye-related diseases will lead to blindness or worse when it is lack of treatment in the early stages of the disease. Retinal vessel is important for doctors to detect eye diseases, even though the increase of some thin vessels may also mean the occurrence of certain diseases. Therefore, automatic retinal vessel segmentation is of great help to doctors in diagnosing diseases. In this paper, an automatic vessel segmentation method is proposed for retinal image, which is based on support vector machine combining multi-scale feature fusion model and B-COSFIRE filter response. Firstly, the inverted green channel image is enhanced by B-COSFIRE filter to strengthen bar-like vessel structures. Then the features are extracted by means of line operator in a multiresolution way, namely that each filtered image is down-sampled to cover a wider area, hence each sampled pixels can obtain not only the global but also local information. Then the final obtained features from three scales together along the depth direction are combined to train the SVM model. Finally, we use the classifier model to predict blood vessels. The proposed algorithm is evaluated on the public available fundus images datasets (DRIVE: Precision = 0.8657, Se = 0.7088, Sp = 0.9660 and ACC = 0.9900; STARE: Precision = 0.8782, Se = 0.6189, Sp = 0.9908 and ACC = 0.9494). The experiment results show that our proposed algorithm has effects on retinal vessels segmentation.
Introduction
Automatic retinal blood vessels segmentation is good for the detection of vascular diseases such as cardiovascular and cerebrovascular diseases, diabetes, and ophthalmological diseases.1,2 But manual vessel segmentation for retinal image is time consuming and laborious tasks. Therefore, the automatic retinal vessel segmentation provides a convenient way to assist doctors' analysis and follow-up treatment.3–5
Many automatic retinal vessel segmentation methods5–7 have been proposed. The current retinal vascular segmentation methods are mainly divided into two categories: unsupervised methods and supervised methods.
The unsupervised methods mainly utilize the features to segment retinal blood vessels without training sample. Sahin et al. 8 proposed a multi-scale segmentation algorithm combining hybrid region merging with watershed segmentation. Liu et al. 9 proposed a threshold segmentation method based on principal component, which use singular value decomposition (SVD) algorithm to accurately locate the principal component and reduce the synthesis strength through threshold segmentation. Pin et al. 10 utilized wavelet decomposition and multi-scale region-growing to derive regions of interest for accurate location. Dong et al. 11 utilized a novel sub-Markov random walk algorithm with prior label to iron out slender objectssegmentation. Shafiullah et al. 12 concatenated local and global information to do intensity inhomogeneous image segmentation. Montuoro et al. 13 proposed a surface segmentation model based on graph theory algorithm. Saroj et al. 14 used principal component analysis (PCA) method to transformoriginal color image into gray-scale image and designed Fréchet matched filter to select best parameters.
Compared with unsupervised methods, supervised learning methods are to learn vessel features from a plenty of labeled training images or to train vessel pixel classifier model for vessel segmentation. The existing supervised methods can be divided into deep learning related methods15–19 and traditional machine learning methods. Hinton et al. 20 formally proposed the concept of deep learning in 2006 and the deep learning method immediately aroused great repercussions in the academic circle. Since Alexnet 21 won the famous Imagenet image recognition competition in 2012, the deep learning algorithm has stood out in the world competition and once again attracted the attention of academia and industry in the field of deep learning. Deep learning algorithms have increasingly been developed. In deep learning related methods, deep convolutional neural network had superior performance on a variety of tasks in image processing and computer vision. Ronneberger et al. 22 proposed a u-shaped deep learning network called U-net, which only need a small amount of image to train the model, and it can obtain good segmentation accuracy. Some similar networks have been proposed one after another, such as V-Net 23 , Res-U-Net 18 , U-Net++ 24 . Ma et al. 25 proposed a multi-task segmention method that can segment blood vessels while also distinguishing arteries and veins. Liskowski et al. 7 used the deep learning method to do multi-pixel classifification, which can train large samples. These methods can achieve satisfactory performance, but they need a highly configured running environment. Many traditional machine learning methods work well for medical image processing tasks. For instance, the support vector machine (SVM)is extensively used in retinal blood vessel segmentation owing to its great performance. Ricci et al. 26 proposed a retinal vessels segmentation method with SVM. Aiping et al. 27 proposed a novel pixel-wise SVM classifier to extract multiple morphological characteristics of tumor nests and segment tumor nests and stroma from images. Wang et al. 28 proposed a method which possessed corrected morphological transformation and fractal dimension. Li et al. 29 designed a new deep network to segment retinal blood vessels through cross-modality data conversion, which has strong induction ability. M. Liu et al. 30 proposed a multi-template method based on relational induction to obtain important structural imformation in order to maximize performance.
In this paper, a supervised learning method based on the SVM is proposed, which combines B-COSFIRE (the Combination of Shifted Filter Responses with B standing for bar, which is an abstraction for a vessel) filter and multi-scale features fusion. Firstly, the B-COSFIRE filter is used for the retinal image to increase the contrast information of vascular structure and non-vascular areas. Secondly, considering the particularity of retinal vascular structure, the image features are extracted by improved line operator and the image is convoluted with 12 rotated versions of 2D matched filter impulse response. And the maximum response relative to angle is reserved. The multi-scale features fusion is used to obtain not only the global but also local information. Then the training dataset is composed of multi-scale feature vectors and filtered images to train the SVM classifier. Finally, vascular classification results for retinal vessel images are obtained by SVM classifier. And the image binarization operation is done by post processing operation for obtaining final vessel tree.
Method
Our goal here is to obtain satisfactory vessel segmentation result by SVM method 32 for retinal image. In our proposed method, we adopt two stages retinal blood vessel segmentation method: train stage and test stage. There are four main processes. (1) Image enhancement. This is a preprocessing operation to increase the contrast information of vascular structure and non-vascular areas by B-COSFIRE filter for inverted green channel image. (2) Multi-scale features fusion. The features are extracted by means of line operator from fifiltered image in a multiresolution way to obtain not only the global but also local information. (3) Train SVM classifier. The filtered image and the corresponding extracted features are combined as the train data to train a SVM classifier. (4) Application of SVM classifier. The final segmentation image is obtained by SVM classifier from training stage. And the test data is done by using the same operation as the training stage. It includes image enhancement, multi-scale features fusion and train SVM classifier in training stage. It includes the image enhancement, multi-scale features fusion and application of SVM classifier in testing stage. The schematic illustration of the proposed segmentation process is showed in Figure 1, and we will elaborate on our proposed supervised learning method hereinafter.

The schematic illustration of the proposed segmentation process: (1) Image enhancement, (2) Multi-scale features fusion, (3) Train SVM classifier, and (4) Application SVM classifier.
Train stage
Image enhancement
Considering the linear characteristics of retinal blood vessels, two line operators are utilized to calculate the feature vector instead of one line operator. Firstly, we used the all-green channel image throughout the training and testing process considering the noise of red channel and blue channel. The results of image prepocessing are shown in Figure 2. Then the inversion method is used to increase the contrast information of vascular structure and non-vascular areas. Then B-COSFIRE filter31,33,34 is used for distinguishing blood vessels from non-vascular information, which is a kind of two line detectors and effective to detect strip structures.
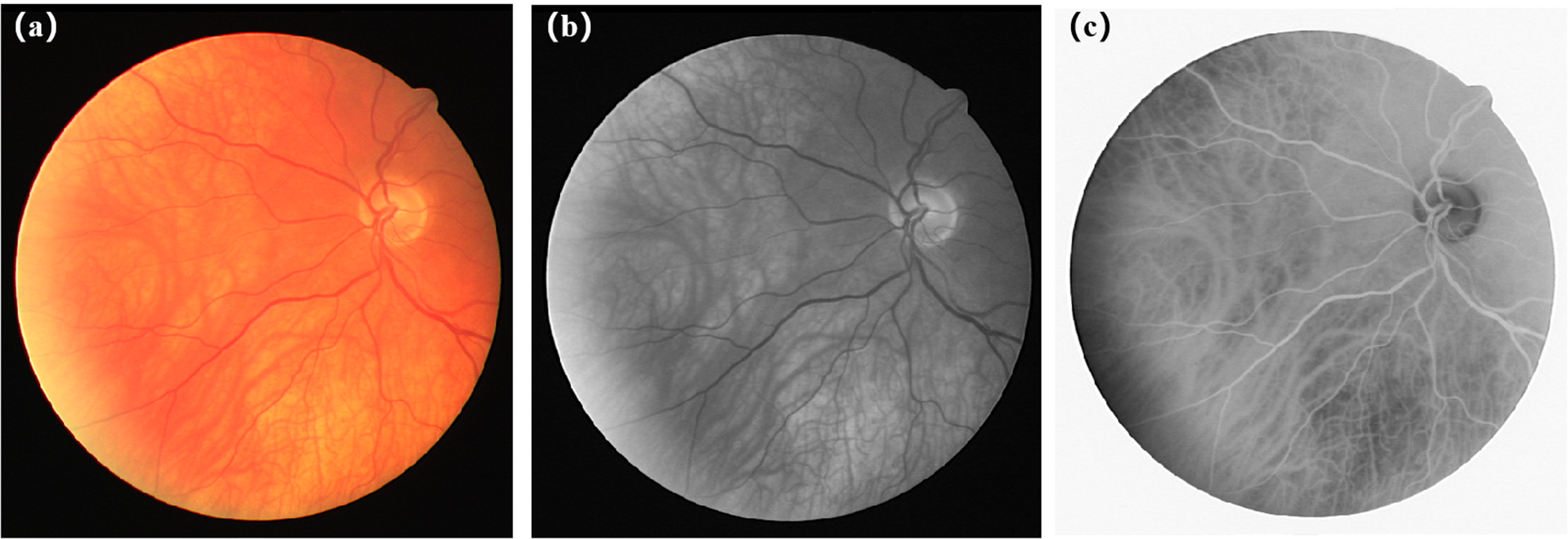
The results of image preprocessing. From left to right, (a) is original image, (b) is the retinal image of the extracted green channel part, (c) is the inversion image after extracting green channel, respectively.
The filter is defined by the product of a set of Gaussian of differential (DoG) filter responses to achieve B-COSFIRE response. For a retinal image


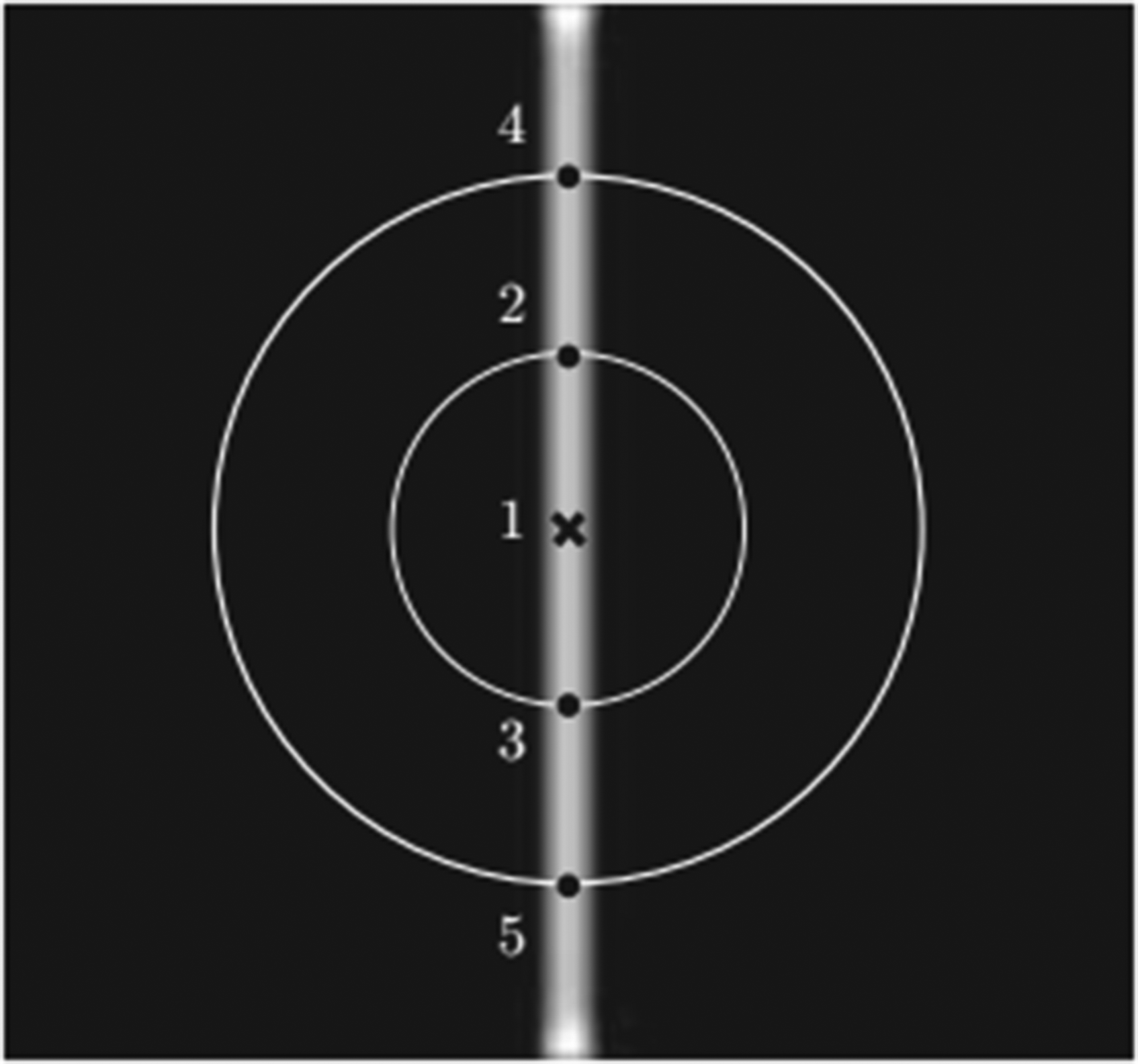
B-COSFIRE’s selective configuration. 31

Schematic diagram of B-COSFIRE.

The results of image enhancement with B-COSFIRE for two images from datasets DRIVE and STARE. And (a) is originalimage from DRIVE, (b) is (a) corresponding fifiltered image, (c) is original image from STARE, (d) is (c) corresponding fifiltered image.
Multi-Scale Feature Fusion
Linear feature extraction is done by linear operator for the feature map images. These features are extracted by means of line operator in a multi-resolution way, namely that each filtered image is down-sampled to cover a wider area, hence each sampled pixels can obtain not only the global but also local information.
For calculating the corresponding line strength
26
to each pixel on the feature map, we first calculate the average gray value of point in different directions to obtain the line intensity

Linear feature extraction. (a) is the selected line (15 gray point pixels) of blood vessel, (b) is orthogonal line (3 gray point pixels).


Generally, smaller scale sampling can observe the details of the image while larger scale sampling can grasp the overall characteristics of the image. In the single scale segmentation, the line operator of length 15 pixels performs best. Compared with single scale sampling, multi-scale sampling can obtain the global and local information. We chose a lot of different scales and the three scales of 7, 15 and 23 works best. Then the final obtained features from three scales together along the depth direction with the feature map image is integrated to train the SVM classifier.
Train SVM classifier
The feature map of linear features extracted from three different scales and extracted gray image from original image are used for fusion operation, and the feature map obtained is used as the input of SVM classifier for image segmentation. Usually, SVM
32
is used for settling the problem of binary classification of data. N samples are input and the label of output samples is represented by
Test stage
For each test image data, the image enhancing and multi-scale features fusion are done as same as the train stage. Then the SVM classifier is applied for obtaining the final vessel tree map, which is obtained from the train stage.
Experiments
Dataset and Parameter Setting
The public dataset DRIVE 40 (The Digital Retinal Images for Vessel Extraction) and STARE 41 (Structured Analysis of the Retinal) are used for evaluation. There are 40 retinal images in DRIVE dataset and evenly divided as training set and testing set respectively. In STARE dataset, we use first 14 images to train the method and 6 images for testing. All retinal images are manually segmented by two experts and the manual segmentation images from the first expert in DRIVE and STARE dataset are adopted to evaluate the performance of the our method.
And for multiresolution manner, the number of multi-scale is 3 and the patch size is 7*7, 15*15 and 23*23 for each scale since the best performance can be obtained when the patch size is 15*15.
Evaluation Criteria
The segmentation performance of our proposed method in different procedures is compared with several state-of-the-art blood vessel segmentation methods. And four evaluation criteria are used for evaluating the segmentation performance, including Accuracy (ACC), Precision, Sensitivity (Se) and Specificity (Sp). They are defined as follow:



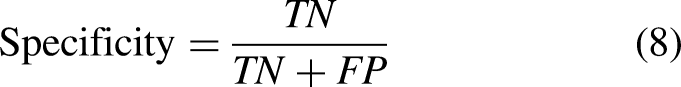
Experiment and Analysis
First, the performance of the proposed method on DRIVE and STARE is as shown in Tables 1 and 2, and four evaluation criteria for each image and their mean and standard deviation (mean
The performance for the proposed method on DRIVE dataset. The best results are shown in bold.

The performance for the proposed method on STARE dataset. The best results are shown in bold.

Then, we compared the performance of different procedures in our method with several state-of-the-art blood vessels segmentation methods by four evaluation criteria on DRIVE dataset: (1) our method without BC and MCM is single scale without B-COSFIRE, (2) our method without MCM is single scale with B-COSFIRE, (3) our method combines multi-scale and B-COSFIRE. We provided the vascular segmentation results of DRIVR dataset, as shown in Table 3, Figure 7 and Figure 8. And we also compared the performance of our best method with several state-of-the-art blood vessels segmentation methods by four evaluation criteria on STARE dataset. The segmentation results of retinal vessels in STARE dataset are shown in Table 4. It is shown that our method is effective for improving the performance including precision, specificity and accuracy by using B-COSFIRE operation and multiresolution manner.
The comparison of experimental results between different other methods and our proposed method with and without B-COSFIRE(BC), with and without multiresolution manner(MSM) on DRIVE dataset. The best results are shown in bold.

The comparison of experimental results between different other methods and our proposed method with B-COSFIRE(BC) and multiresolution manner(MSM) on STARE dataset. The best results are shown in bold.

The exemplar results of vessel segmentation are given in Figure 7. For the first row, it is the original retinal fundus image, the manual annotation, the segmented result, and the highlighted differences between the manual annotation and the segmented result, respectively. And for the second row, they are local enlarged results from the first row images. For the highlighted differences image, the red color pixels indicate that vessels are correctly classified as blood vessel pixels, while green color pixels indicate that background pixels are incorrectly classified as blood vessel pixels and the blue color pixels indicate that vessels pixels are incorrectly classified as background pixels.

Exemplar result of vessel segmentation on DRIVE. For the first row, from left to right: the retinal image, the manual annotation,the segmented result using our proposed method, and the highlighted differences between manual annotation and the segmented image using proposed method, respectively. For the second row, they are the locally enlarged results from the images of the fifirst row.
The segmentation results are shown in Figure 8 and Figure 10. It shows segmentation results with our different procedures compared with the ground-truth, which is selected by the best and worst segmentation map among all segmentation evaluation criteria for test images in the DRIVE database. In Figure 8, column (a) are original retinal images, column (b) are manual segmentation images, column (c) are the segmentation images using single scale without B-COSFIRE filtering, column (d) are the segmentation images using single scale after B-COSFIRE filtering, respectively. Column (e) in Figure 8 are the segmentation images after B-COSFIRE filtering with multiresolution manner. And in column (e), the first row is the test image with the highest precision and specificity in the DRIVE testset, which are 0.9404 and 0.9950 respectively. And the test images with the highest sensitivity and accuracy criteria are displayed in the second and third lines, with sensitivity and accuracy of 0.7729 and 0.9717 respectively. The fourth row is the test image with lowest precision and specificity, which are 0.7585 and 0.9827 respectively. And the last row is the test image with lowest sensitivity and accuracy criteria, which are 0.6216 and 0.9561 respectively. It is shown that, (1) the perfomance of the proposed procedure is gradually improved as more procedures are trained with additional features which are obtained by multiresolution manner. (2) The B-COSFIRE filtering can improve the performance for the vessel segmentation. And in Figure 9, it shows segmentation results with our best model procedure 3 compared with the ground-truth for test images in STARE dataset. From left to right in Figure 9, column (a) are original retinal images, column (b) are manual segmentation images, column (c) are the segmented images by our proposed method, column (d) are the highlighted differences between manual annotation and the segmented image using our proposed method, respectively.

The vessel segmentation results for retinal images in DRIVE dataset. From left to right, (a) is original image, (b) is manual segmentation image, (c) is our method without BC and MCM, (d) is our method without MCM, (e) is our method, respectively.

The vessel segmentation results for retinal images in STARE dataset. From left to right, (a) is original image, (b) is manual segmentation image, (c) is the segmented image by our proposed method, (d) is the highlighted differences between manual annotation and the segmented image using our proposed method, respectively.
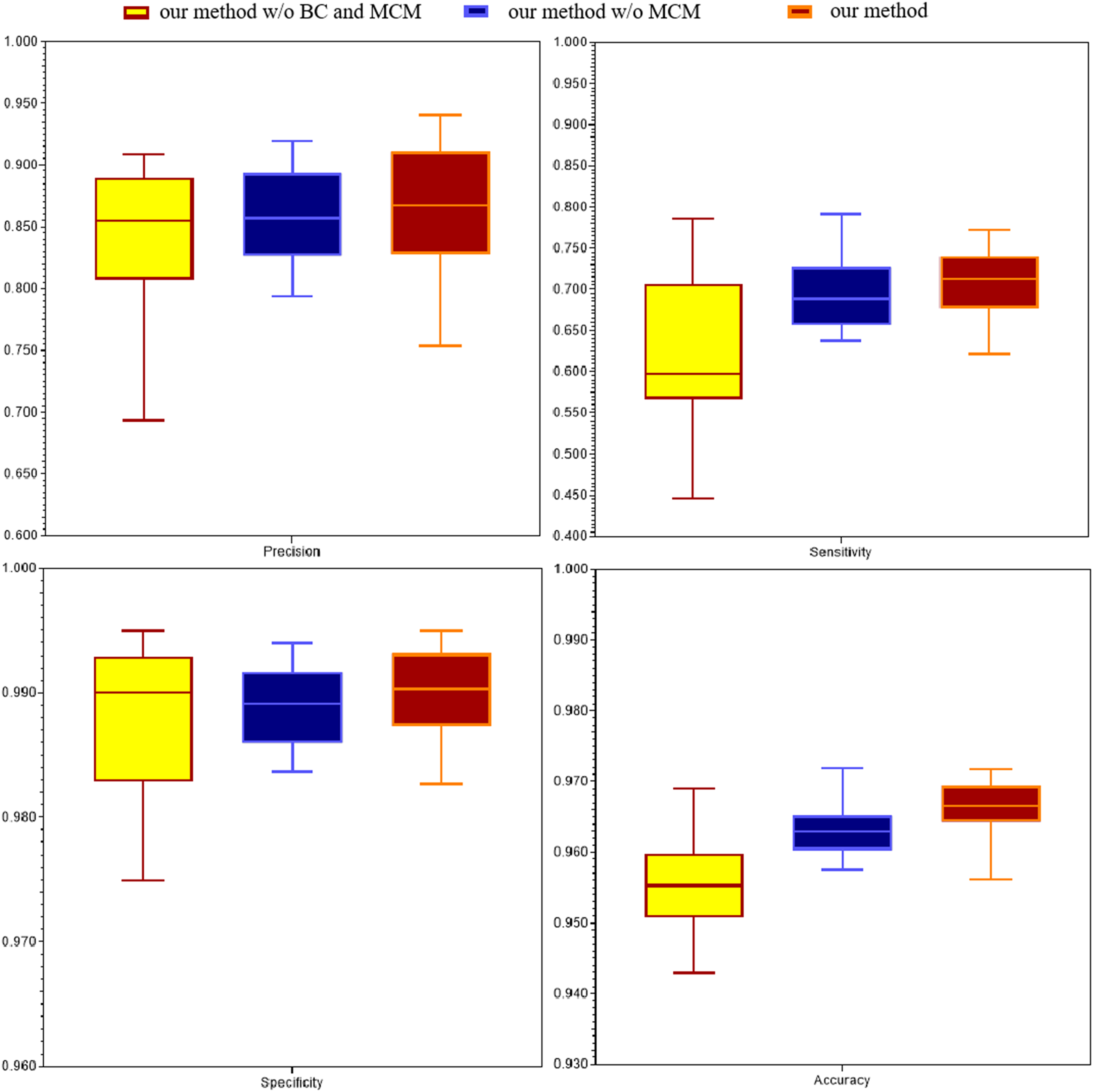
The comparison with different procedure in DRIVE dataset. Evaluation criteria are precision, sensitivity, specificity and accuracy, respectively.
Conclusion
In this paper, we propose an automatic vessel segmentation method for retinal fundus image, which is founded on support vector machine combining multi-scale feature fusion model and B-COSFIRE filter response. Firstly, the inverted green channel part of images are extracted and the B-COSFIRE filter was utilized to strengthen bar-like vessel structures. Then the features are extracted by line operator in a multiresolution manner. Then the final obtained features from three scales together along the depth direction is combined to train the SVM classifier model. Finally, the classifier is utilized to predict the vessel map. It is shown that our proposed procedure have effect on achieving higher performance from experimental results. And the decrease of sensitivity is mainly due to the omission of small blood vessels, which will be the key point of the future work. The effect of our method to strengthen the sensitivity in retinal fundus images which have lesions is scant. And deep learning algorithms, especially U-Net, 22 and U-shaped improved network algorthms, have been proven to be effective way to to segment medical image in recent years. In the future, we will investigate and study how to improve U-shaped networks instead of SVM to train more efficient models for better retinal images segmentation in the future work.
Footnotes
Acknowledgement
Han Zhou and Hongtao Xu checked the sentence errors and formatting in the revision process of the paper. Changcai Yang and Riqing Chen put forward and guided me through many opinions on the later stage of the thesis.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work is supported by the Natural Science Foundation of Fujian Province (Grant No. 2020J01573), National Natural Science Foundation of China (Grant No. 61701117, 61802064) and the Fund of Cloud Computing and Big Data for Smart Agriculture (Grant No. 117-612014063), the Research Foundation for Education Bureau Young Scientists of Fujian Province (Grant No. JAT180748), the subject of Education Science Planning of Fujian Province in 2020 (FJJKCG20-178) and Fuzhou Science and Technology Project (Grant No. 2019-SG-7).