
Abstract
Recently, in the area of artificial intelligence and machine learning, subspace clustering of multi-view data is a research hotspot. The goal is to divide data samples from different sources into different groups. We proposed a new subspace clustering method for multi-view data which termed as Non-negative Sparse Laplacian regularized Latent Multi-view Subspace Clustering (NSL2MSC) in this paper. The method proposed in this paper learns the latent space representation of multi view data samples, and performs the data reconstruction on the latent space. The algorithm can cluster data in the latent representation space and use the relationship of different views. However, the traditional representation-based method does not consider the non-linear geometry inside the data, and may lose the local and similar information between the data in the learning process. By using the graph regularization method, we can not only capture the global low dimensional structural features of data, but also fully capture the nonlinear geometric structure information of data. The experimental results show that the proposed method is effective and its performance is better than most of the existing alternatives.
Introduction
Clustering analysis is a commonly used processing and analysis tool in artificial intelligence and machine learning fields. At present, researchers have proposed a large amount of clustering analysis methods, and have been widely used. However, due to the continuous progress of data science, the rapid development of data sources and access methods, the data obtained is more and more complicated. Among them, multi-view data is a wide-ranging phenomenon. However, traditional clustering methods are mostly proposed and developed for single-view data, in the face of multi-view data clustering, the performance is not ideal. Therefore, how to design a clustering analysis algorithm for multi-view datasets is a huge challenge. In order to effectively solve the problem of multi view data clustering, researchers have proposed many multi view cluster analysis methods from many aspects.
The multi-view clustering analysis algorithm can be roughly divided into two categories: multi-view K-means clustering1–3 and multi-view spectral clustering algorithm.4–6 These two types of algorithms are multi-view extensions based on K-means clustering and spectral clustering algorithms, respectively. At present, multi-view k-means clustering algorithm has achieved good performance in many fields, but due to the inherent deficiency of K-means clustering algorithm, the selection of initial central data points has a greater impact on the final clustering results. This greatly limits the application of multi-view k-means clustering algorithms. The multi-view clustering algorithm based on spectral clustering can obtain relatively stable clustering performance. Therefore, many researchers have recently focused on multi-view spectral clustering algorithms.7–9
Numerous studies have shown that high-dimensional data can usually be embedded in a specific set of low-dimensional subspaces, so the multi-view subspace learning algorithm based on spectral clustering has been widely applied and achieved good performance. Representative algorithms include multi-view subspace clustering algorithm (MSC), 7 diversity-induced multi-view subspace clustering algorithm (DiMSC), 8 and potential multi-view subspace clustering algorithm (LMSC). 9 The MSC 7 algorithm learns the self-representation coefficient matrix of each view and unifies it into a common indicator matrix to obtain the final clustering result. However, the MSC algorithm ignores the differences between different views. For this problem, the diversity-induced multi-view clustering algorithm (DiMSC) 8 uses the Hilbert-Schmidt independent criterion (HSIC) to learn the diversity of different views and improve the performance of clustering. However, both the MSC and DiMSC algorithms learn the self-representation coefficient matrix of the data in the original space of the data. This may greatly reduce the performance of the cluster due to possible noise in the original space of the data. Therefore, the LMSC 9 algorithm will potentially represent combined with subspace clustering in a unified optimization framework, the self-representation coefficient matrix is learned in the potential representation space obtained by learning, which can greatly avoid the influence of noise on the clustering result and improve the clustering performance.
The LMSC 9 algorithm adopts low rank representation (LRR) for subspace learning. If all the data in a high dimensional space is actually located on the union of a set of linear subspaces, the LRR can be easily acquired in the data. However, in practical applications, this assumption cannot be guaranteed. The data is often embedded in a low-dimensional manifold structure. For example, widely used face images are sampled from nonlinear low-dimensional manifolds embedded in high-dimensional space. 10 Therefore, in this case, the LRR method may not be able to discover the inherent geometry and discriminant structure of the data11,12 and this information is indispensable for practical applications.
In order to maintain the local geometry embedded in high-dimensional space, the researchers proposed a number of manifold learning algorithms, including representative manifolds, locally linear embedding (LLE), 13 ISOMAP, 14 and locality preserving projection (LPP) 10 neighborhood preserving embedding (NPE) 15 and Laplacian Eigenmap (LE). 16 The starting point for all these algorithms is based on the so-called local invariance, 17 which aims to estimate the geometric and topological result information of an unknown manifold from random points (scattered data).
In practical application, a reasonable assumption is adopted for general production. If two data sample points are very close in the internal manifold of data distribution, then the two points are also very close in a new representation space. 18 In order to make full use of the inherent geometric structure information of data distribution, Lu et al. 12 proposed a graph regularization LRR algorithm.
Based on the above analysis, we propose a Laplacian regularized multi-view clustering algorithm based on latent representation. At the same time, we further introduce sparse and non-negative constraints in the algorithm model to improve the performance and rationality of the algorithm.
Related works
Subspace clustering
Let

Multi-view subspace clustering
Multi-view datasets contain a wealth of information from multiple sources, which is very useful for clustering analysis. Therefore, studying multi-view clustering is very important. Based on the single-view subspace clustering algorithm, a low-rank tensor constrained multi-view subspace clustering (LT-MSC)
21
is proposed. The algorithm model can be expressed as follows:

Where

However, the fusion method is too simple to fully and accurately explore the complementary information between different view data samples. At present, there are also many studies that use weight-and rules to fuse multi-view representations. However, it still cannot solve the error problem of multi-view fusion. In the single-view subspace clustering analysis algorithm, the Latent Space Sparse Subspace Clustering (LS3C)
22
algorithm can simultaneously reduce the dimensionality and sparse representation of the data set. Inspired by this idea, the work in
9
proposed a latent multi-view subspace clustering (LMSC), which treats different views as projections from the same latent space and performs subspace aggregation on this latent space. The LMSC model can be expressed as follows:

In the above optimization problem,
However, there is a problem of this method is that the complementary information between different data views is ignored, and no structural constraints are used on the representation coefficient matrix
Non-negative sparse Laplacian regularized latent multi-view subspace clustering (NSL2MSC)
In this paper, we do some research on the subspace clustering problem of multi-view latent representations. Given a multi-view data set
The objective function of the proposed Non-negative Sparse Laplacian regularized Latent Multi-view Subspace Clustering (NSL2MSC) is formulated as

In the objective function, the third term is the constraint term added based on the manifold assumption. Under the manifold assumption, the relationship between the two samples can be expressed as

Where,
Manifold constraints are important for the construction of many algorithm models, such as dimension reduction algorithm, clustering algorithm and semi-supervised learning algorithm. Where
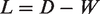
In addition, the objective function of graph embedding (5) can easily be expressed as follows

Therefore, through these algebraic transformations, the model of the proposed method can be represented as the following matrix form
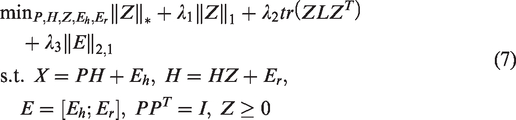
Model optimization
The objective function in equation (6) proposed in this paper can get a latent representation of the data and get meaningful similarity matrix from the latent representation which learns from multiple views. Although for the variables in the algorithm model, such as
In order to optimize the objective function, we first introduce an auxiliary variable

The augmented Lagrange function of the above problem is

In addition, in order to facilitate the subsequent calculation and representation, we give the definitions of
-subproblem
With the other variables fixed, we obtain the expression of

s.t.
24
Given the objective function
The optimal solution of the

According to theorem 1, if
-subproblem
With the other variables fixed, we obtain the expression of H by solving the following optimization problem

Taking the derivative with respect to H and setting it to zero, we get

With
The above equation is a Sylvester equation. In order to avoid instability, we strictly limit
The Sylvester equation (11) has a unique solution.
The Sylvester equation
Accordingly, the Sylvester equation (11) has a unique solution.
-subproblem
Fix the other variables, we update


Then according to LADMAP, minimizing


-subproblem
The reconstruction error

-subproblem
Fix the others, the Lagrange function with respect to

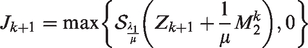
Updating multipliers
We update the multipliers by

The entire algorithm is summarized in Algorithm 1.

Complexity and convergence
The method proposed in this paper is optimized through six subproblems. The complete algorithm is shown in algorithm 1. Where, the time complexity of solving the
Experiments
Experimental setting
Dataset description
We chose four real datasets (MSRCV1,3 Extended YaleB, Still DB,
26
BBCSport
5
) as test data to verify the effectiveness of the proposed method. The basic information for the four datasets is as follows:
– The MSRCV1 dataset contains 240 images in 8 classes. In this experiment, we selected 7 classes of them, such as tree, building, air-plane, cow, face, car and bicycle. In the experiment, we extracted 6 features of each image, namely CENT (view1), CMT (view2), GIST (view3), HOG (view4), LBP (view5) and SIFT (view6). And use these features to make up 6 different views. – The Extended Yale-B dataset contains a total of 2414 face images of 38 people, each with 64 near frontal images under different illuminations. In the experiment, we select the first 10 classes as the final dataset, which has 640 frontal face images in total, we chose three features of the image, intensity (view1), LBP (view2) and Gabor (view3) to form 3 different views of the dataset. – The still DB dataset contains 467 images in 6 classes. In the experiment, we extract three features of each image: sift bow (view1), color sift bow (view2) and shape context bow (view3) to form three different views of the dataset. – The BBCSport dataset contains sports news in five subject areas, all of which are from the BBC sports website and are associated with two views.
Compared methods
We compare the algorithm proposed in this paper with the state-of-the- art algorithm proposed recently. The compared algorithms are as follows:
– SPC: The standard spectral clustering algorithm. In the experiment, we choose the view with the most information to do the spectral clustering. – LRR
20
: The low rank representation. In the experiment, we run the LRR algorithm on each single view and record the best clustering results. – Co-Reg SPC
4
: In this method, the clustering method is combined with regularization to make the corresponding data points in the same cluster. – RMSC
5
: This method first clusters each view, and then uses the shared low-rank transition probability matrix to integrate them to get better clustering results. – FCMSC27: The algorithm deals with the problem that multiple views have different statistic properties and simply concatenating them directly cannot derive a satisfied clustering performance. – LMSC
9
: This method searches for latent representations and reconstructs the data according to the learned latent representations.
Experimental results
Performance comparison
To evaluate the characteristics of each algorithm, we adopt four evaluation indexes, NMI (normalized mutual information), ACC (accuracy), F-measure and RI (rand index). For the 5 compared algorithms in the experiment, we adjust all parameters to the best performance in the corresponding paper. In the experiment, for all experimental data sets, the dimension of latent space of the proposed algorithm is set to
For each algorithm, we run it 30 times independently and give the mean value and standard deviation.
The detailed clustering results of the proposed algorithm and the comparison algorithm on four real datasets are shown in Tables 1–4.
Clustering results on the MSRCV1 dataset.

Clustering results on the Extended Yale B dataset.
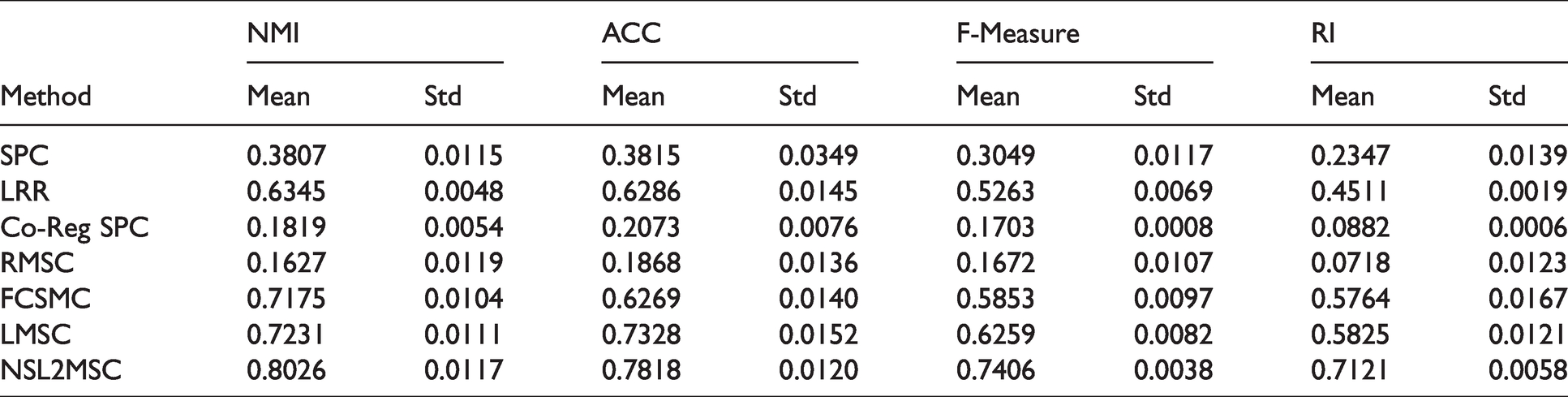
Clustering results on the still DB dataset.

Clustering results on the BBCSport dataset.

Table 1 shows the clustering results on the MSRCV1 data set. On the MSRCV1 dataset, we can see that the proposed method is much better than the compared method. The reason behind this is that the latent representation space learned can make better use of multiple views of data.
Table 2 shows the clustering performance on the Extended YaleB dataset. The clustering performance of most algorithms on this dataset is poor, the main reason is that the illumination changes greatly in the dataset, which seriously affects the clustering performance. However, the NSL2MSC algorithm proposed in this paper has achieved better results. It is 7.95%, 4.9%, 11.47% and 12.96% higher than LMSC algorithm in NMI, ACC, F-measure and RI indexes, respectively.
Table 3 shows the clustering results on the still DB dataset. The clustering performance of each algorithm is not very good. However, from the four indicators, the NSL2MSC algorithm proposed in this paper has achieved relatively promising clustering results.
Table 4 shows the clustering results on BBCSport dataset. The clustering performance of NSL2MSC proposed in this paper is at least 2% higher than that of RMSC. Compared with LMSC method, our NSL2MSC method still achieves better result.
Parameters effect
In the NSL2MSC algorithm model proposed in this paper, there are several regularization parameters. Next, the Extended YaleB data set is taken as an example to test the effect of the four parameters

The parameter effect of
Conclusion
In this paper, a new multi view subspace clustering method was proposed, which is called NSL2MSC. The main innovation of this algorithm lies in the use of graph regularization to make full use of the complementary information among views in the process of learning multi view latent subspace representation. In this way, this method can not only represent the global information of the data, but also can capture the local geometric structure information of the data. A large number of image clustering experiments show the effectiveness of this method.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (Grant No. 61902160, 61806088), the Natural Science Foundation of the Jiangsu Higher Education Institutions of China (Grant No.19KJB520006) and the foundation of Changzhou Science and Technology Plan (Applied Basic Research) (Grant No. CJ20190076).