
Abstract
Due to the existence of multiple views in many real-world data sets, multi-view clustering is increasingly popular. Many approaches have been investigated, among which the subspace clustering methods finding the underlying subspaces of data have been developed recently. Although the subspace-based multi-view methods can achieve promising performance, the shared subspace information has not been fully utilized. To address this problem, a novel multi-view clustering model by simultaneously learning shared subspace and affinity matrix is proposed. In our method, a shared subspace is learned to preserve the effective consensus information of all views. Then, a subspace-based affinity matrix with adaptive neighbors is learned to assign the most suitable cluster to each data point. An iterative strategy is developed for solving this problem. Moreover, experiments on four benchmark data sets demonstrate that our algorithm outperforms other state-of-the-art algorithms.
Introduction
In recent years, multi-view learning has attracted much attention in various real-world applications because data are becoming more diverse and can be collected from different domains or feature sets. For instance, web pages can be represented by different characteristics, for example, text and hyperlinks. An image can also have various representations with respect to many kinds of different features, such as texture, shape, and color features. Although each single view could be adequate or complete for a learning task, multi-view learning fully exploiting the complementary and consensus information is often effective for improving performance. Therefore, how to integrate these multi-view features is a key problem. A naive method is that we can concatenate the multi-view features into one long vector, but this is not physically meaningful. In this way, the complementary information of different views cannot be explored efficiently because the specific statistical characteristic in each view is different. 1 In the past decades, many approaches that focus on multi-view learning have been proposed, among which supervised or semi-supervised methods account for a large proportion. 2,3 In this article, we concentrate on unsupervised scenarios, for example, multi-view clustering, which is a more challenging problem because of the unknown label information for multi-view data.
To fuse different views into a unified framework, many graph-oriented multi-view clustering models have been investigated. The method in Selee et al. 4 proposes a new tensor decomposition in which the authors store object-feature matrices as the slices of a tensor. In another study, 5 canonical correlation analysis is utilized to map original data with high dimension to a low-dimensional subspace, which is a typical dimension reduction method. To explore complementary information, some methods adopt co-training or co-regularization strategies, such as the studies by Kumar et al. 6,7 The method in Cai et al. 8 explores a shared Laplacian matrix by integrating multi-view heterogeneous features and uses a nonnegative constraint to improve robustness. The method in Nie et al. 9 jointly performs multi-view clustering and local structure learning. In this method, the weight for each view is automatically determined and does not need additional parameters. Generally, graph-based methods have excellent performance. However, in the real world, graphs are often unreliable since these original data always have noise and outliers.
Recently, various subspace learning algorithms have been proposed 10 –15 since data always distribute on certain underlying low-dimensional subspaces. In these methods, self-representation-oriented subspace clustering has been extensively developed to multi-view domains. The goal of these subspace clustering methods is to find underlying subspaces embedded in original data so that data points can be segmented correctly. The multi-view clustering method in Yin et al. 16 introduces a pairwise sparse subspace representation and maximizes the correlation of different views. The method in Feng et al. 17 utilizes the local reconstruction relationships of data. Besides, a low-rank tensor constraint in Zhang et al. 18 is employed to exploit the multi-view complementary information. In this method, representation matrices of all views are regarded as a tensor taking the high-order correlations of multi-view data into account. Additionally, the method in Cao et al. 19 introduces a diversity property named diversity-induced multi-view subspace clustering (DiMSC) in which the Hilbert Schmidt independence criterion (HSIC) is utilized as a diversity term to learn the complementarity for original multi-view data. These above multi-view clustering methods based on subspace execute subspace clustering on each view. Although these methods are able to explore the multi-view complementary information, the structure of affinity matrix might be destroyed. Additionally, these methods do not take the consensus subspace information into account. The method in Qi et al. 20 introduces a common global affinity matrix for all views. Also, a regularization term in this method is used to minimize the differences between this common affinity matrix and individual affinity matrix for each view in this method, which results in errors to some extent and makes the final clustering results not optimal.
To address the above problems, a novel multi-view clustering approach is proposed to explore consensus subspace information of all views. In our method, we directly learn a shared subspace from original data. Further, we learn an affinity matrix with adaptive neighbors by utilizing the shared subspace rather than raw data, which avoids the influence of noise and outliers existing in original data and improves the robustness of our algorithm. The main contributions are as follows: Based on self-representation, the basic subspace clustering model is extended to multi-view clustering. A shared subspace is exploited to obtain the multi-view consensus information that is important for multi-view clustering tasks. An affinity matrix is learned by arranging the adaptive neighbors based on the learned shared subspace, which uncovers the subspace structure and guarantees the clustering consistency. We develop an iterative algorithm with fast convergence. In addition, we compare with other clustering methods on four data sets. Experiments verify that our method outperforms other approaches.
Multi-view subspace clustering
For a data set, it always distributes on certain underlying low-dimension subspaces. Subspace clustering methods aim to find the underlying subspace structure, then obtain an affinity matrix based on the subspace and perform clustering on this affinity matrix.
Let

where
Generally, we can write the basic subspace clustering model as
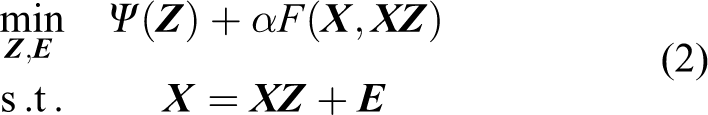
where Ψ(
Recently, many subspace clustering methods are extended to the multi-view domains for clustering. Generally, these algorithms can be formulated as

where
The proposed method
In this section, we introduce a novel multi-view subspace clustering algorithm. According to the formula (3), previous multi-view subspace clustering algorithms generate an individual subspace representation
Instead of computing an individual
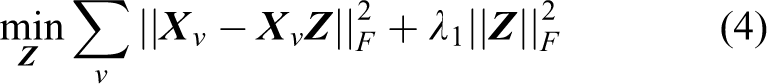
where λ1 > 0 is the trade-off parameter and
For clustering tasks, it is an effective strategy to explore the local connectivity of original data. Recently, a new graph-based method with adaptive neighbors is used to cluster data. Given the data set
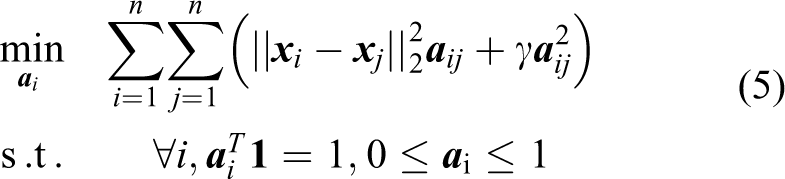
where
In this article, we utilize the shared subspace representation to learn the affinity matrix rather than the raw data, which avoids the influence of noise and outliers existing in original data. Thus, we can write the model as

The problem (6) is equivalent to

where λ2 > 0 is the trade-off parameter and
Thus, the final multi-view clustering model can be written as follows
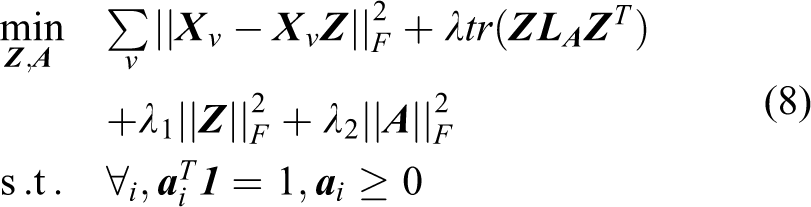
where λ, λ1, and λ2 are three nonnegative regularization parameters. Different from concatenating all features into one long vector, in our model, we explore the complementary and consistency information by each
Optimization algorithm
To solve our challenging problem (8), we use an efficient iterative optimization strategy. Next, we also offer a convergence analysis.
Optimization procedure
Fixing

Set the first derivative of equation (9) to zero and we can get the following formula

which is a Sylvester equation with a unique solution.
Fixing

which is equivalent to the following form

where

For each data point

where Λ and

In addition, λ2 can be determined using the property of adaptive neighbors. Since

where

Therefore, we do not need to tune the parameter λ2 in the experiments. For more detailed information about adaptive neighbors, please refer to the study by Nie et al. 24
Algorithm for solving the model (8).

By iteratively solving problem (8), we can get the final affinity matrix
Convergence analysis
We prove the convergence of the proposed algorithm in this section. The objective function in problem (8) is denoted as J(
For the

Similarly, for the

By combining (18) and (19), we can have

Consequently, we can notice that the objective value monotonically decreases at each iteration. In addition, since
Experiments
In this section, we will compare our proposed method with other state-of-the-art multi-view clustering algorithms on four benchmark data sets.
Data set descriptions
3-Sources Text data set (http://mlg.ucd.ie/datasets/3sources.html.) is from Reuters, BBC, and the Guardian which are three online news sources, respectively. The total numbers of distinct news are 416 and they are divided into six classes. In our experiments, each source is seen as an independent view and we use 169 of distinct news to form three views.
Oxford Flowers data set is composed of 1360 examples which consist of 17 flower categories, and each category has 80 images. 26 For each image, three visual features (color, shape, and texture) are used to describe it. In our experiments, three different views are constructed by utilizing the χ2 distance matrices for three visual features.
COIL-100 object data set is composed of 100 categories with 7200 images. Each category contains 72 images. In addition, each image is captured with five-degree rotation. In our experiments, these images are seen as four views: view 1
Handwritten numerals (HW) data set contains 2000 examples from 0 to 9 digit categories, and each category has 200 examples. In our experiments, we use six public features (KAR, FOU, FAC, PIX, ZER, and MOR).
We summarize the information of four data sets in Table 1 including the number of data points, views, and clusters for each data set.
Data sets.

HW: handwritten numerals.
Experiment setup
To evaluate our proposed algorithm better, we compare the proposed algorithm with subspace-based method (SSC)
22
for each single-view counterpart and report the best performance (SSC-BSV). Also, we perform the SSC
22
on concatenated features (SSC-Con). In addition, we compare with other multi-view clustering approaches: co-regularized spectral clustering (Co-reg),
7
multimodal spectral clustering (MMSC),
8
DiMSC,
19
and multi-view learning with adaptive neighbors (MLAN).
9
The detailed information is listed as follows: SSC-BSV: SSC is a classic subspace clustering method. In this method, subspace representation is obtained at first, and then spectral clustering method is performed on the subspace representation. In our experiments, for each single view, we run the SSC method and report the best results. SSC-Con: We first concatenate all features into one and then perform SSC method to obtain the clustering results. Co-reg: This method uses a centroid-based co-regularization term to make the clustering results consistent for all of the views. MMSC: A shared Laplacian matrix is explored by integrating multi-view heterogeneous image features in this method. In addition, this method uses a non-negative constraint and improves the model robustness. DiMSC: This method utilizes a diversity term named HSIC to explore the complementarity information of multi-view data. MLAN: This method simultaneously performs multi-view clustering and local structure learning in which the weight for each view is automatically determined and does not need additional parameters.
Our model has three parameters λ, λ1, and λ2. The parameter λ2 can be determined by using the property of adaptive neighbors according to equation (17). Therefore, we only need to tune the parameters λ and λ1 to get their best values. In our experiments, we tune the parameters λ and λ1 from the range
Experiment results
We adopt two evaluation metrics, namely, accuracy (ACC) and normalized mutual information (NMI) to evaluate our clustering results. The clustering ACC and NMI on the four data sets are shown in Tables 2 and 3, respectively. Generally, our proposed method that utilizes the shared subspace information can achieve superior results apparently compared with single view approaches. At the same time, as for clustering ACC, we can see that our method can also outperform the other state-of-the-art multi-view clustering approaches in our experiments. And the clustering performance improvements over the MLAN method on four data sets are around 1.2%, 4.7%, 9.3%, and 0.4%, respectively. For clustering NMI, on the contrary, the MLAN method achieves superior clustering results compared with our proposed method on 3-Sources Text data set, but the value of our method is very close to the MLAN method. Thus, the proposed method considering the consensus information can achieve superior clustering results and is relatively robust to parameters compared with other clustering methods.
Clustering ACC (mean and standard deviation) of different methods.a

ACC: accuracy; HW: handwritten numerals; SSC-Con: SSC on concatenated features; Co-reg: co-regularized spectral clustering; MMSC: multimodal spectral clustering; DiMSC: diversity-induced multi-view subspace clustering; MLAN: multi-view learning with adaptive neighbors.
aThe best results are in bold font.
Clustering NMI (mean and standard deviation) of different methods.a
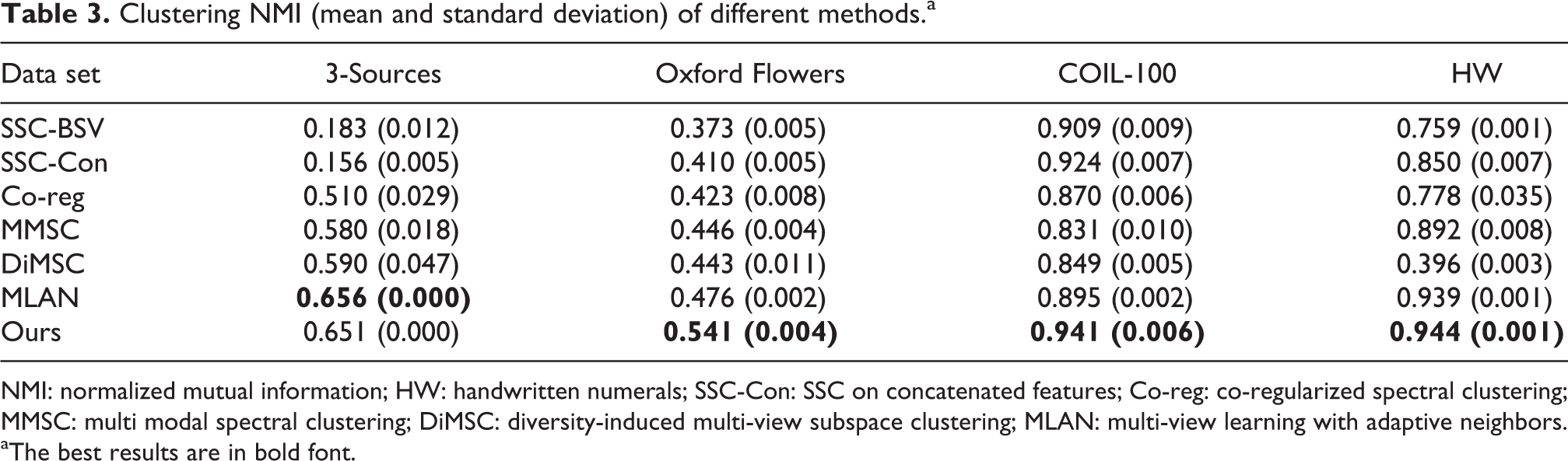
NMI: normalized mutual information; HW: handwritten numerals; SSC-Con: SSC on concatenated features; Co-reg: co-regularized spectral clustering; MMSC: multi modal spectral clustering; DiMSC: diversity-induced multi-view subspace clustering; MLAN: multi-view learning with adaptive neighbors.
aThe best results are in bold font.
In our experiments, the stop criteria is given by

where J(t) is the objective function value in the tth iteration. In Figure 1, the convergence of our method is experimentally illustrated by curves on two data sets. From Figure 1, we can see that our method converges fast.
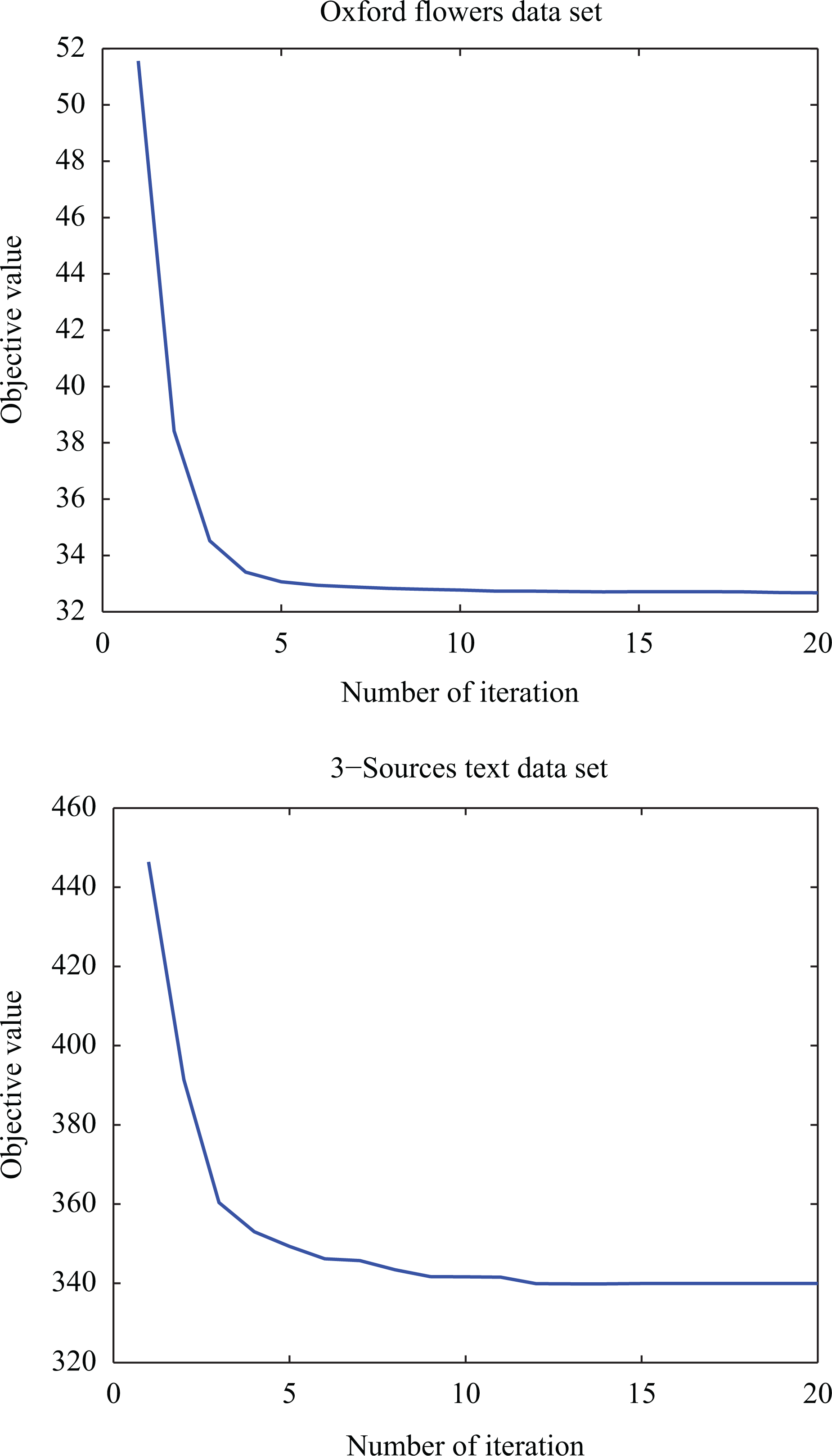
Convergence curves of our method on two data sets (3-Sources and Oxford Flowers data sets).
Parameter selection
In our experiments, the logarithms (base 10) of two parameters are taken. We introduce the selection of parameters according to Figure 2. For 3-Sources data set, the accuracies suddenly increase and a peak will appear when λ1 = 10, but the results are stable within the range

Clustering results (ACC) on four data sets (3-Sources, Oxford Flowers, COIL-100, HW) with two parameters λ and λ1. ACC: accuracy; HW: handwritten numerals.
Major parameters.

HW: handwritten numerals.
As for clustering NMI, it is similar to the clustering results of ACC with respect to parameter selection. Therefore, we do not discuss it in this section.
Conclusion
In this article, we design a novel model for multi-view clustering by simultaneously learning shared subspace representation and affinity matrix. Our proposed method is a self-representation-oriented multi-view subspace clustering method. In this work, we make all views share the same subspace representation, which explores the multi-view consensus information and guarantees the clustering consistency across all views. Then the affinity matrix with adaptive neighbors is learned by utilizing the shared subspace representation rather than raw data, which uncovers the subspace structure and improves the robustness. Additionally, we compare with other multi-view clustering approaches on four data sets. Experimental results validate that the proposed algorithm is more effective and can achieve superior clustering results.
Footnotes
Authors’ note
This article was presented in part at the CCF Chinese Conference on Computer Vision, Tianjin, 2017. This article was recommended by the program committee.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is funded by the National Natural Science Foundation of China (grant nos. 61402079, 61379151, and U1636219), the Foundation for Innovative Research Groups of the NSFC (grant no. 71421001), and the Open Project Program of the National Laboratory of Pattern.