
Abstract
Different from image segmentation, developing a deep learning network for image registration is less straightforward because training data cannot be prepared or supervised by humans unless they are trivial (e.g. pre-designed affine transforms). One approach for an unsupervised deep leaning model is to self-train the deformation fields by a network based on a loss function with an image similarity metric and a regularisation term, just with traditional variational methods. Such a function consists in a smoothing constraint on the derivatives and a constraint on the determinant of the transformation in order to obtain a spatially smooth and plausible solution. Although any variational model may be used to work with a deep learning algorithm, the challenge lies in achieving robustness. The proposed algorithm is first trained based on a new and robust variational model and tested on synthetic and real mono-modal images. The results show how it deals with large deformation registration problems and leads to a real time solution with no folding. It is then generalised to multi-modal images. Experiments and comparisons with learning and non-learning models demonstrate that this approach can deliver good performances and simultaneously generate an accurate diffeomorphic transformation.
Introduction
Image registration consists in constructing a reasonable geometrical correspondence between given two or more images of the same object taken at different times or using the same or different devices in order to locate different or complementary information. Applications of image registration include diverse fields such as astronomy, optics, biology, chemistry, remote sensing and particularly in medical imaging. For an overview of image registration methodology, approaches and applications, we refer to Fischer and Modersitzki
1
; Gigengack et al.
2
; Modersitzki
3
; Oliveira et al.
4
; Sotiras.
5
Though the topic is actively studied and useful models exist, there remain many challenges to be tackled mathematically, particularly in registration of images from different modalities. There exist various deformable variational models for image registration where the unknown displacement field

In recent years, deep learning approaches were proposed where the aim is to optimise and learn spatial transformations between pairs of images to be registered,12–16 often, they require ground-truth deformation fields for the training task. They are called supervised models and their main drawback is the inability to predict transformations that may not be in the same range or class of the training transformations. As example, a deep learning model, which is learned and trained on a dataset where the ground-truth contains only small displacement fields, fails to predict and to give accurate results for large displacement.
In order to remedy these drawbacks, another class of deep leaning models was proposed. These unsupervised models do not require ground-truth deformation fields for training. The deformation fields are self-trained and driven by image similarity metrics computed on the input data. In Jaderberg,
12
a spatial transformer network is developed to learn transformations for 2D images; however only affine and thin plate spline transformations were used. More general non-parametric transformations were considered in Haskins et al.
13
; Li and Fan
14
; Theljani and Chen 6,25 for mono-modal images. In these approaches, the transformations are controlled by penalising the derivatives of the deformation
To overcome the folding problem, some deep learning approaches have addressed the question of getting diffeomorphic transformations, i.e. topology-preserving and invertible. These conditions were guaranteed by either adding an extra layer to the networks to enforce the output deformation to be diffeomorphic as in Krebs et al., 17 or by controlling the back-and-forth registration as in Kuang. 18 In this case, the network is learning a deformation that maps T to R and its possible inverse deformation that maps R to T. Moreover, these approaches were only applied for mono-modal images
In this paper, we propose an alternative approach to overcome the folding problem. The model is unsupervised, i.e. do not require any ground truth data, and is applied for registering mono- and multi-modal images. It can deliver diffeomorphic transformations without adding any extra layer to the neural network or enforcing it compute a deformation and its inverse. In fact, the diffeomorphisms are guaranteed by using a suitable loss function for training that controls the folding in the deformations.
A learning model
In this section, we introduce a learning based diffeomorphic model for both mono- and multi-modal image registration. The idea is that the deformation fields are self-trained by minimizing a specific loss function that guarantees the transformation to be physical. In Figure 1, we present an overview of the method:
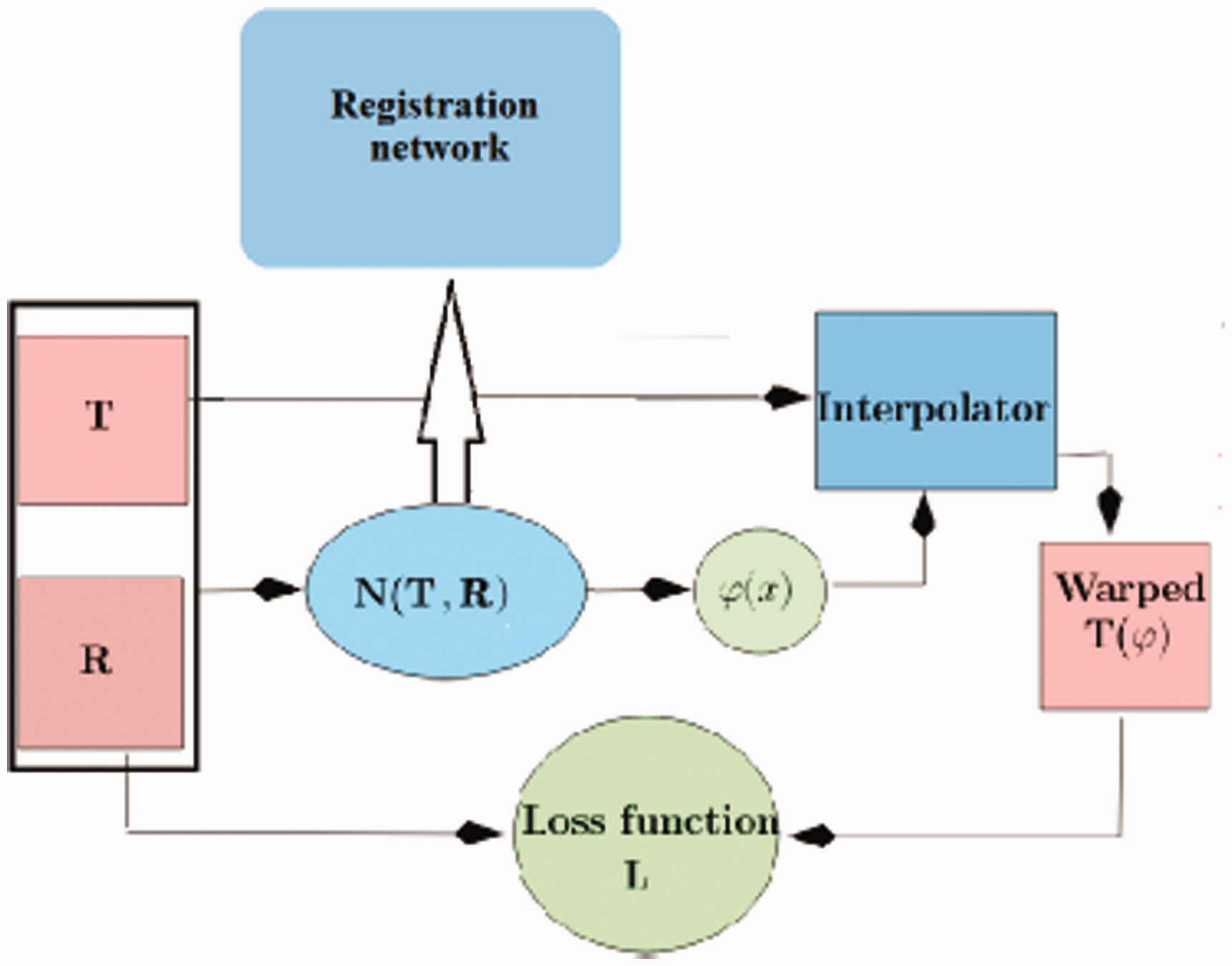
The work-flow of the registration model. The fixed and moving images T and R and first concatenated and fed to the registration network N(T, R). The latter composed of many convolution layers, followed by activation functions, and ended by a final layer that produces the deformation
The pair of images T and R are concatenated and fed to the registration network N(T, R) as a single multichannel image. The registration network, with weight parameters θ, processes the two images through a series of convolutional and pooling layers, and outputs a 2-channel map representing the 2D deformation field, denoted by
Once the estimated transformation
During training, the parameters θ of the registration network N(T, R) are adjusted by minimising a loss function

Generally, only the similarity measure
Regularisation
The regularisation that we use consists in a smoothing constraint on the first- and second order derivatives and a constraint on the determinant of the transformation in order to obtain spatially smooth and plausible solutions Droske and Rumpf
19
; Burger et al.
7
The second-order derivatives allows getting smooth transformations and penalise affine linear transformations which are not included in the kernel of the first-order derivatives based regularises.
20
The term depending on
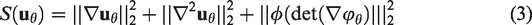
The similarity measure
Measuring similarity for mono-modal images
Various similarity terms can be used to measure the goodness of the registration. In this work, we use an alternative measure to the correlation coefficient and which is well suitable for measuring linear dependence between images, hence mono-modal images. More precisely, we set


Measuring similarity for multi-modal images
Multi-modal images are often non-linearly correlated and the similarity measure
Parallel level set measure
Various similarity terms can be used in the registration of multi-modal images such as mutual information Pluim et al.,
21
normalised gradient fields Ruhaak et al.
22
normalised gradients fitting Theljani and Chen
6
; Zhang et al.
23
In this work, we use parallel level sets similarity measure which is well suitable for measuring alignment between the gradients of two images. More precisely, consider
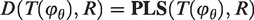
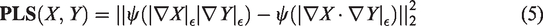
Data and numerical tests
In the numerical validation, we assess the performance of the proposed model that we call
Registration network
We have tested two networks for the registration task. The first one, in Figure 2, is a small network (SN) which contains four blocks containing different kernels with different sizes and ReLU activation is used at the end of each block. The second one is a light version of U-net network, denoted by LU-net
27
. The last block of each network is responsible for generating the deformation

The architecture of the SN network for registration. The image T and R are concatenated to form a 2-channel image that will be fed to the network. The later output the deformation
Choice of λ in (2)
We have tested three different values of

(a) The reference image R. (b) The moving image T. (c) Registered image

The transformed meshes for different values of λ for the of images in Figure 3. (a) λ = 200,

The architecture of the light U-net network for registration.
In the rest of the numerical examples, we consider λ = 60.
Part 1: Synthetic data
In the part of the numerical examples, we assess the importance of the term New: It is our proposed model and where
Total variation: The regularisation in this model is given by Diffusion (Diffu): We consider

As shown in Figure 7, different
Part 2: Real data
We test the performance of the proposed
We also compare with traditional deformable registration model Burger et al.,
7
which is a non-learning model and that we call

Mono-modal images
We trained our model on 160 mono-modal MRI heart images and compare with the classical variational model
Comparison between learning


Dataset of 10 images used for the training, testing and comparing between different regularisers for large displacement.

Comparison between different regularisers in registering an unseen pair of images. From left to right, Template T, Reference R, registered using different regularisation terms: i) the diffusion
Comparison between the LU-net and SN networks in registering 4 mono-modal MRI heart images.

We also compared the two used networks in term of registration quality. The comparison details are reported in Table 2. The training curves of the registration model using the two networks are illustrated in Figure 8 and Figure 9. These curves present the learning rate values at each epoch, and we see that the model converges for the two networks after 800 epochs.

The LU-net: Training and testing losses for the registration model for mono-modal (top) and multi-modal (bottom) images.

The SN network: Training and testing losses for the registration model for mono-modal (top) and multi-modal (bottom) images.
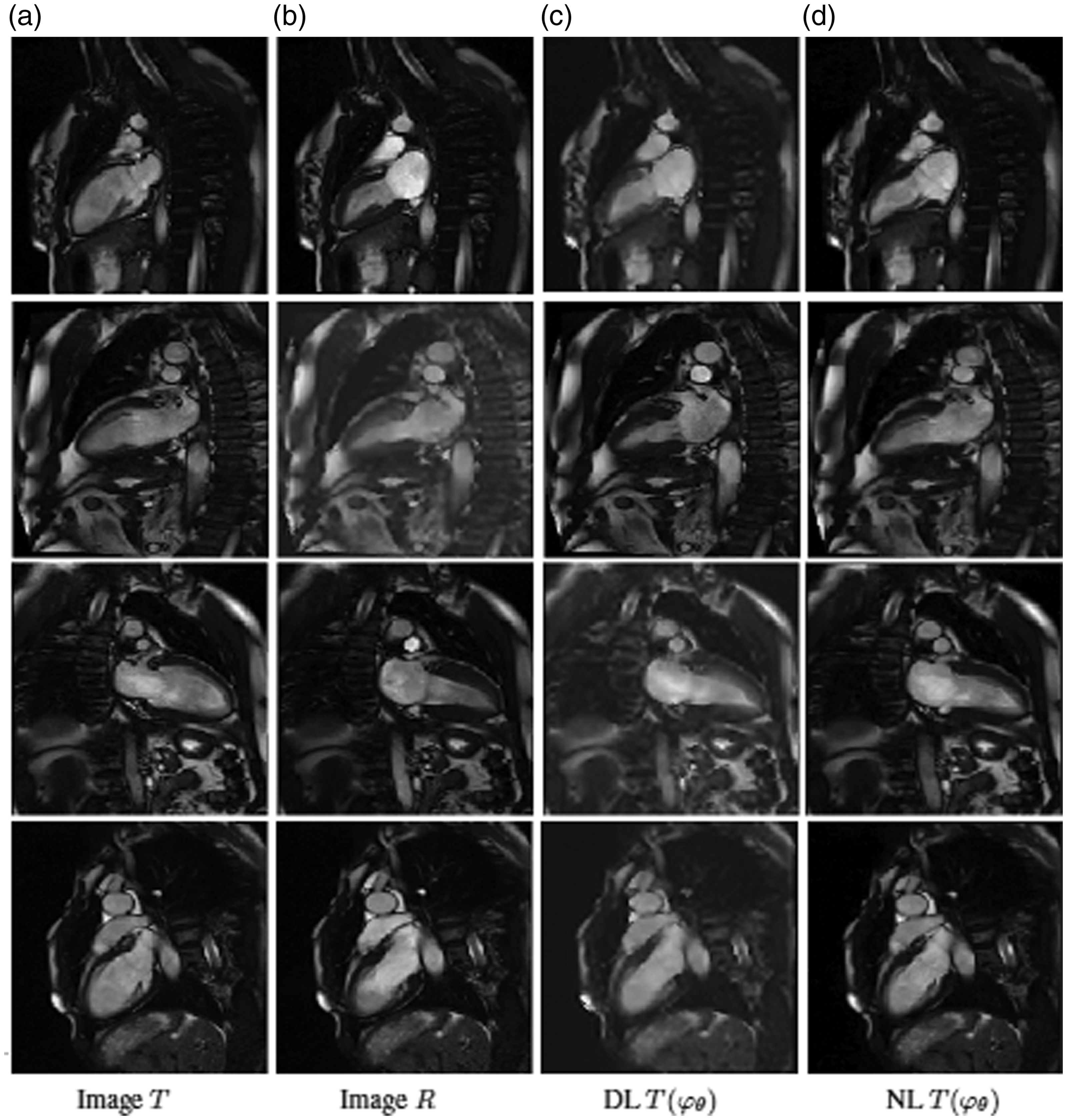
Pairwise registration results for 4 pairs of MRI images. Each row represents the result for a pair test. (a) Moving images T. (b) Fixed images R. (c) and (d) are the registered images using

Pairwise registration results for 4 pairs of MRI-CT images. Each row represents the result for a pair test. (a) Moving images T. (b) Fixed images R. (c) registered images using
Multi-modal images
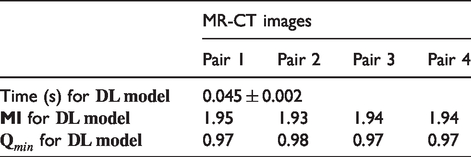
For multi-modal images, we trained the network on 120 pairs of CT and MRI images. In Figure 11, we display the prediction results for registering 4 pairs of MRI and CT images. To see the quality visually, we show the fused CT and MRI images for the four examples before and after registration. Clearly after the registration the images are well aligned. We give the mutual information errors and the run-time during the prediction in Table 3.
Conclusions
We have developed and presented an unsupervised deep learning approach for mono-and multi-modal images registration. We tested and compared different choices of regularisation constraints on the deformation fields. The results have shown that control on the Jacobian determinant of the deformation is necessary in the loss function in order to get a diffeomorphic map, mainly for large displacements. The learning model was first designed and tested for mono-modal images. The same learning approach works effectively for multi-modal images, by only changing the similarity measure to fit with the multi-modal setting. For for mono- and multi-modal images, we tested 2 choices of networks. We found that LU-net is recommended.
Future work will consider generalisations to 3 dimensional images registration.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Both authors are supported by the UK EPSRC grant EP/N014499/1 through the EPSRC LCMH.