
Abstract
Nowadays, datasets containing a very large number of variables or features are routinely generated in many fields. Dimension reduction techniques are usually performed prior to statistically analyzing these datasets in order to avoid the effects of the curse of dimensionality. Principal component analysis is one of the most important techniques for dimension reduction and data visualization. However, datasets with missing values arising in almost every field will produce biased estimates and are difficult to handle, especially in the high dimension, low sample size settings. By exploiting a Lasso estimator of the population covariance matrix, we propose to regularize the principal component analysis to reduce the dimensionality of dataset with missing data. The Lasso estimator of covariance matrix is computationally tractable by solving a convex optimization problem. To illustrate the effectiveness of our method on dimension reduction, the principal component directions are evaluated by the metrics of Frobenius norm and cosine distance. The performances are compared with other incomplete data handling methods such as mean substitution and multiple imputation. Simulation results also show that our method is superior to other incomplete data handling methods in the context of discriminant analysis of real world high-dimensional datasets.
Introduction
In the present era of Big Data, datasets with hundreds or even thousands of variables are generated and collected in many fields such as genomics, e-commerce, engineering, education, etc.1,2 When the number of variables becomes too large, we usually need a reduced representation of the variables to analyze or visualize the data. So dimension reduction techniques which aim to reduce the dimension from high-dimensional space to a lower dimensional space are often necessary before conducting statistical analysis. Principal component analysis (PCA) is one of the most popular techniques among them. It has been widely used in statistical data analysis, pattern recognition, and image processing. 3
However, until recently, most PCA are conducted based on the assumption of a complete data set despite the fact that missing data are a rule rather than an exception in quantitative researches. 4 Data can be missing due to different reasons. For example, people may refuse to answer some sensitive questions. In telescope data, missing observations may be caused by a cloudy sky or sporadic instrument failures. The problem of missing data is common in almost all research and may lead to biased estimates and decreased statistical power. 5
The traditional method to handle missing data is to delete the sample that has one or more missing observations. This complete case analysis is one of the methods commonly implemented in statistical software. When the missing rate is moderate or large, however, complete case analysis can be inefficient because a large number of observations will be excluded. Another common method to deal with the missing data is mean substitution. Mean substitution assumes that a missing variable is missing completely at random, that is, the variable’s missingness depend neither on the true value of the missing variable nor on the values of other variables in the dataset. If this assumption is not met, mean substitution may lead to biased estimate. Additionally, the variances are usually underestimated by mean substitution. 6 Multiple imputation is also a popular strategy to fill the incomplete dataset. In multiple imputation, each missing data is replaced by a set of plausible values that represent the uncertainty about the true value to impute. These imputed data sets are then analyzed by using standard procedures for complete data and combining the results from these analyses. This approach is becoming increasingly popular to handle missing data as it has the potential to correct the bias appeared in the complete case analysis or other alternative analyses. 7 The methods of matrix factorization or nearest neighbor imputation have also been used in a host of disciplines to handle missing values.8,9
The problems of missing data are also discussed in the context of PCA. In Audigier et al., 10 an imputation method based on the factorial analysis and principal component (PC) method is proposed, which perform well especially for categorical variables. In Serneels and Verdonck, 11 two approaches are presented to perform PCA on data which contain both outlying cases and missing elements: one approach is based on the eigendecomposition of the covariance matrix, the other is an expectation robust algorithm to deal with the data where the number of variables exceeds the number of observations. Several methods for dealing with missing data in PCA are reviewed and compared in Ginkel et al. 5 Their comparative theoretical advantages and disadvantages are also presented.
Another aspect that seriously challenges PCA is the so-called high dimensional, low sample size settings. The essential characteristics of a high-dimensional dataset is that its dimension p is close to, or even larger than, the number of observations N. Obviously, the statistical analysis of high-dimensional data will transcend the “large N, fixed p” asymptotics in the classical multivariate statistics. In the high dimensional, low sample size settings, the sample covariance matrix S is well-known to be an inconsistent and biased estimator of the population covariance matrix Σ.12,13 As a result, the PCs obtained by the eigendecomposition of S will have a great deviation from the true ones. By assuming the principal loading vectors are sparse, Lee et al. have proposed a modification of the conventional PCA that works in very high-dimensional spaces. 14 In Lee et al., 15 it is demonstrated that the PC scores for samples which were not included in the original PCA can be substantially biased toward 0 in the high-dimensional setting. Meanwhile, a bias-adjusted PC score prediction algorithm is proposed. A general asymptotic framework for studying the consistency properties of PCA is developed in Shen et al. 16 It allows one to rigorously characterize how the PCA consistency is evolved as a function of the dimension, the sample size, and the spike size.
In this paper, we aim to improve the performance of PCA when dataset contains small or moderate amount of missing values and belongs to the high dimensional, low sample size settings. For the incomplete dataset, we first optimally estimate the covariance matrix Σ via Lasso estimation and then regularize the conventional PCA procedure. The good performance of the proposed method is demonstrated by comparing with other popular imputation methods through extensive simulations on some synthetic and real world datasets.
PCA and the covariance matrix estimation
Let

For a N × p data matrix X with N independent observations of the p-dimensional random vector

Using the above projection of X on the
In practice, the population covariance matrix Σ is usually unknown and we only have the data matrix

By decomposing

Regularized PCA for high-dimensional dataset with missing observations
An unbiased estimator of Σ with missing observations
In the last section, we have shown that PCA is a method based on spectral decomposition of the covariance matrix. Unfortunately, the sample covariance matrix S is not a good estimator of the population covariance matrix Σ in high dimension. Furthermore, we cannot estimate Σ accurately for dataset containing missing values. So we will introduce an unbiased estimator of Σ following the approach proposed in Lounici, 18 which is based on the fundamental results in random matrix theory.
Suppose an entry Xij in a data matrix X is missing at random and the entry will be observed with probability
We begin with the covariance matrix estimation by filling all the missing observations of variable xj with the mean value of the observed entries in the jth column. If a random variable xj is assumed to be zero-mean, then the missing data is filled with 0. After mean imputation, we have a complete data matrix XComplete. Its empirical covariance matrix

Based on the results from random matrix theory,
17
a Lasso estimator for Σ can be obtained by solving the following convex minimization problem
18


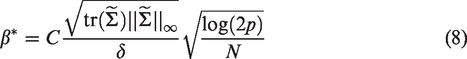
The estimator
The RPCA algorithm
The proposed PCA algorithm handling high-dimensional dataset with missing observations is shown in Algorithm 1. Estimate δ by computing the proportion of the observed entries in the incomplete data matrix XIncomplete Impute XIncomplete with the mean of the observed entries for each variable (in column wise) and obtain the complete data matrix XComplete Normalize each variable in the data matrix to have zero-mean and unit-variance Compute the empirical covariance matrix Compute Solve the convex minimization problem in equation (6) and obtain the estimator Eigen-decompose Do the projection of XComplete on the m leading eigenvectors return XLow
Simulations
First of all, we create an p × p population covariance matrix Σ of Toeplitz structure with entries
It has been shown in Algorithm 1 that the PC scores XLow are mainly determined by the
(i) The mean value substitution (MS) method
In this method, the missing data for each variable is replaced by the mean value of the observed data for that variable.
(ii) The multivariate imputation by chained equations (MICE) method
The MICE package in R language generates multivariate imputations by chained equations. 23 Using this package, each incomplete variable is imputed by a separate model and then inference is combined across the completed datasets. This method is becoming increasing popular for handling missing data.
Note that we are not going to compare the proposed algorithm with the complete case analysis method because, for moderate or large missing rate, nearly all of the samples will be deleted. This phenomenon becomes even more evident when the dimension p is close to or larger than the number of samples N.
To quantitatively measure the consistency between the true PC

to measure the similarity between the true PCs
Another measure to evaluate the similarity is the cosine distance. Given the true eigenvectors Uj and the estimated eigenvectors

And the cosine distance is defined as

For different proportions of observing rate δ, the performance of the various methods for the synthetic data matrices XIncomplete with size
The Frobenius norm and the cosine distance (Fn, Cs) of the principal component directions for the synthetic dataset (N = 60, p = 60).

PCA: principal component analysis; RPCA: regularized PCA.
The Frobenius norm and the cosine distance (Fn, Cs) of the principal component directions for the synthetic dataset (N = 30, p = 60).

PCA: principal component analysis; RPCA: regularized PCA.

First two principal component score plot of (a) the original complete data, (b) the imputed data with MS+PCA, (c) the imputed data with MICE+PCA, and (d) the imputed data with RPCA. The settings are
Application to classification problems
Linear discriminant analysis (LDA) is a well-established supervised learning technique applicable in a variety of fields. 25 The classification of high-dimensional dataset is quite common but difficult to solve for most of the classification algorithms including LDA. 26 So the techniques such as PCA and factor analysis are essential to reduce the dimension before classifying the high-dimensional dataset. In this section, we will show that LDA together with our RPCA algorithm can significantly reduce the misclassification rate when dealing with high-dimensional as well as incomplete dataset.
Synthetic data analysis
In LDA, one or more new samples are classified into one of the predefined classes 
We generated the synthetic dataset from two multivariate Gaussian distributions
Averaged correct classification rate of LDA together with different dimension reduction methods (δ = 90%).

LDA: linear discriminant analysis; PCA: principal component analysis; RPCA: regularized PCA.
Averaged correct classification rate of LDA together with different dimension reduction methods (δ = 70%).

LDA: linear discriminant analysis; PCA: principal component analysis; RPCA: regularized PCA.
Real data analysis
The performance of our RPCA algorithm are also examined with two real world datasets. One is the prognostic Wisconsin breast cancer dataset, 27 the other is the ozone level detection dataset. 27 The breast cancer dataset is a complete dataset which contains 569 samples for p = 30 variables. Each sample has been assigned with one of the two class labels: malignant or benign. We reserve each entries in the dataset with probability δ and randomly pick N training samples to train the LDA classifier. For different settings of δ and N, the numerical results are shown in Table 5. The predicting accuracy for each setting is averaged over 20 runs. We can see that the classification performance of LDA classifier is relatively high along with the proposed dimension reduction algorithm.
Averaged predicting accuracy of LDA together with different dimension reduction methods on the breast cancer dataset.

LDA: linear discriminant analysis; PCA: principal component analysis; RPCA: regularized PCA.
The ozone level detection dataset has 73 variables and 2534 samples. We have randomly selected 160 samples labeled with ozone day and an equal amount of samples labeled with normal day. All the samples selected have missing data and the proportion of the observed data is calculated. Among the selected samples, we randomly choose 54 samples as training data, and the 266 remaining samples are used as testing data. The performance for each dimension reduction methods are shown in Table 6 and the predicting accuracy is averaged over 10 simulation runs. Although the predicting accuracy for each method is not very high, our proposed RPCA algorithm achieves a better performance in these high-dimensional settings.
The averaged predicting accuracy of LDA together with different dimension reduction methods on the ozone level dataset (N = 54, p = 73).

LDA: linear discriminant analysis; PCA: principal component analysis; RPCA: regularized PCA.
Conclusion
We have proposed an RPCA algorithm to reduce the dimension in the dataset where the dimension is close to, or larger than, the sample size and also in which some observations are missing due to various reasons. The proposed algorithm is based on solving a convex optimization problem and some theoretical results from random matrix theory. One of the prominent advantages of this method is it circumvents the intricate imputation of missing data. Its good performance is validated by analyzing both the synthetic datasets and some real world datasets.
We would like to note that the proposed algorithm does not perform well when the missing rate of the dataset is relatively high (roughly
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported, in part, by the Science and Technology Program of Xuzhou (Grant No. KC18069) and the Postgraduate Research & Practice Program of Education & Teaching Reform of CUMT.