
Abstract
Memory limitation and slow training speed are two important problems in sentiment analysis. In this paper, we propose a sentiment classification model based on online learning to improve the training speed of the sentiment classification. First, combining the adaptive adjustment of learning rate of the Adadelta algorithm and the characteristics of avoid frequent jitter of Adam algorithm in the later stage of training, we present a novel Adamdelta algorithm. It solves the problem that learning rate of traditional follow the regularized leader (FTRL)-Proximal online learning algorithm will disappear with the increase of training times. Moreover, we gain an optimized logistic regression (LR) model and use it to the sentiment classification of online learning. Finally, we compare the proposed algorithm with five similar models with the experimental data of the IMDb movie review dataset. Experimental results show that the improved algorithm has better classification effect and can effectively improve the precision and recall of the classifier.
Keywords
Introduction
Online real-time analysis and processing of network emotional information can help the governments and enterprises to detect and handle crisis public relations in advance, so that the governments and enterprises can understand the dynamics of events and correctly guide errors and false statements. Based on the research of online learning algorithm and considering the advantages of dealing with massive emotional data, this paper combines them with sentiment analysis technology to propose an online learning sentiment analysis model, which aims to improve the speed and accuracy of online public opinion analysis.
With the rapid development and application of technology such as big data and artificial intelligence, the comprehensive improvement of the real-time, comprehensiveness, validity, and accuracy of sentiment analysis has attracted the attention and research of many scholars. For example, the largest existing taxonomy of common knowledge is blended with a natural-language-based semantic network of common-sense knowledge, multidimensional scaling is applied on the resulting knowledge base, which is beneficial to opinion mining and sentiment analysis in the open field. 1 Using different regularization constraints to learn the domain shared knowledge and domain-specific information from different sentiment review domains, a new method for modeling and mining domain shared knowledge from different emotional review domains is proposed, which greatly reduces the data distribution gap between source domain and target domain and improves the accuracy of sentiment classification. 2 Convolutional neural network combined with regional long short-term memory provides a deep neural network model, which can reduce the training time of neural network models and effectively infer the sentiment polarities of different targets in the same sentence. 3 According to the different influence of relationships between the modifier and the emotion word and the contribution of each sentence to the sentiment calculation, the understanding of short text emotions is improved. 4
This paper draws on the simulation of Newton iterative solution of Adadelta algorithm and Adam algorithm’s deviation correction of parameter update quantity and obtains the improved learning rate optimization algorithm to replace the original learning rate, and obtains the online learning LR model, and uses this model as a sentiment classification tool to construct a complete system of online learning sentiment classification.
The rest of this paper is organized as follows. The next section discusses related work. In “FTRL-Proximal algorithm for improving learning rate” section, we propose an improved learning rate optimization algorithm to replace the original learning rate of FTRL-Proximal algorithm. In “Sentiment classification model based on online learning” section, we present an online learning LR model using the improved online learning algorithm to optimize the parameters of LR and use this model as a sentiment classification tool to construct a complete system of online learning sentiment classification. “Experiment and result analysis” section compares the performance of the improved learning rate algorithm with other similar methods through experimental analysis and verification, and compares the classification effects between online and offline models. And the final section summarizes this paper.
Related work
Online gradient descent (OGD) is a basic online learning algorithm that solves the problem that traditional algorithms cannot process data update models in real time, but the sparseness obtained is not ideal. McMahan et al. proposed the FTRL algorithm, so that the parameter learning rate can be adjusted according to the characteristics of different features. It is proved that this algorithm has better effect of advertisement click prediction. 5 Yang et al. 6 limited the regret bound of the algorithm through the gradual change of the loss function, which makes the FTRL algorithm have the online nonsmooth optimization function of the gradual variation constraints. Ta 7 integrated the FTRL algorithm into the second-order factorization machine and presented the FRFFL algorithm with a faster speed of convergence. Huynh et al. 8 proposed the FTRL-ADP algorithm to solve the problem of drift in noisy environments. Orabona and Pal 9 achieved adaptiveness to the norms of the loss vectors by scale invariance, making the algorithm based on FTRL work for any decision set, bounded or unbounded.
Learning rate is an important factor affecting the results of online learning algorithms. A good learning rate can ensure that the algorithm converges to the optimal value quickly and accurately. Kingma and Ba 10 proposed the Adam algorithm by introducing and correcting first- and second-order moment estimation, which are suitable for nonstationary targets and problems with noise or sparse gradients. Erven and Koolen 11 proposed the MetaGrad method, which has the learning rate that does not monotonically decrease over time and adapts to various types of random and nonrandom functions. Roy et al. 12 used the RMSProp algorithm to enhance the training process and achieve faster convergence. However, when the adaptive learning rate algorithms are applied in the fields of target recognition, machine translation, etc. the optimization effect may not be as good as the SGD algorithm. McMahan and Streeter 13 extended AdaGrad to propose a delay-tolerant algorithm. When the delay is larger, the performance is significantly better than the standard adaptive gradient methods. Zhang et al. 14 proposed the AEDR algorithm, which can adaptively calculate the exponential decay rate and reduce the Adaldelta’s and Adam’s hyperparameters. Chen et al. 15 proposed the Ada-PGD algorithm by combining Adagrad and the near-end gradient descent, which makes ADAE have excellent anomaly detection performance. Wang et al. 16 greatly improved the recognition rate of end-to-end systems by studying the per-dimensional learning rate method of Adagrad and Adadelta.
In order to improve the effect of the adaptive learning rate optimization algorithms, Denkowski and Neubig 17 adopted the multiple restart and step size annealing strategies for the Adam algorithm to make the algorithm converge faster and improve the reliability of the model. Smith 18 proposed a periodic learning rate method that achieves higher accuracy with fewer iterations. Loshchilov and Hutter19,20 proposed the stochastic gradient descent with warm restarts (SGDR) algorithm, which can reduce the number of model iterations and extend the hot start to the Adam algorithm that fixes the weight attenuation; they implemented standard weight attenuation on Adam by adding gradient updates to parameter updates, which has better generalization and has comparable performance to the driven SGD in image classification tasks.
FTRL-Proximal algorithm for improving learning rate
FTRL-Proximal algorithm
As a widely used online learning algorithm, FTRL-Proximal algorithm has the characteristics of fast convergence and sparse solution generation. Its optimization formula is shown below

Learning rate optimization algorithm
Appropriate learning rate can improve the convergence speed of the gradient descent algorithm and avoid falling into the local optimal solution. The OGD algorithm uses the global learning rate to avoid the problem that the algorithm cannot converge, but it is easy to converge to the local optimal solution. In addition, sparse data features for some different frequencies may require different learning rates, and the global learning rate does not meet the requirements. In response to the above situation, the FTRL-Proximal algorithm optimizes the learning rate so that it can adaptively assign different learning rates to different features. For features with fewer occurrences, a larger learning rate is set to ensure convergence speed; for features with more occurrences, a smaller learning rate is set to ensure stability of the solution. The expression of the optimized learning rate algorithm in equation (2) is similar to the Adagrad algorithm


It can be seen from formula (3) that the Adadelta algorithm will not lead to the infinite attenuation of the learning rate with the increase of the number of iterations, and the process of manually searching the global initial learning rate is eliminated.
On this basis, the Adam algorithm updates the first-order moment estimation and the second-order moment estimation of parameter gradient, and then dynamically adjusts the learning rate of each parameter by combining them. The process is as follows




Adam’s formula is obtained

Normally, η = 0.001, ρ1 = 0.900, ρ2 = 0.999, ϵ = 10−8. Adam algorithm has a certain range for each iteration learning rate after deviation correction, which makes the parameters relatively stable and can converge quickly when the gradient is sparse.
Improved learning rate optimization algorithm
The Adadelta algorithm solves the problem that the learning rate of Adagrad algorithm is always attenuated, and the unit of left and right updating is not uniform. It has the advantage of not setting the initial learning rate manually. And it has good acceleration in the middle of training. The disadvantage is that it is easy to shake near the extreme value in the later stage of training. Based on the Adagrad algorithm, Adam algorithm introduces and corrects the first- and second-order moment estimation of the gradient, which makes the parameter update more stable and avoids frequent jitter. Therefore, the optimal value can be found faster in the later stage of training, but still depends on manual input of the global initial learning rate.
In order to improve the frequent jitter of the late training of the Adadelta algorithm training and the Adam algorithm relying on the manual input initial learning rate, this paper introduces the Adam algorithm’s deviation correction method for the first- and second-order moment estimation of the gradient into Adadelta, it is named Adamdelta: At first, using the Momentum method calculate the first- and second-order moment estimation of the gradient




Since


Use Δθ to update the expected value of cumulative parameter update amount

Finally, update the parameters according to the above formula to get the final update formula: θt=θt−1 + Δθt.
FTRL-Proximal algorithm for optimizing learning rate
The Adamdelta algorithm inherits the characteristics that are suitable for processing sparse data and adaptive adjustment of learning rate from Adam and Adadelta algorithm. It solves the problem that the learning rate disappears due to the cumulative gradient explosion in the late stage of training for Adagrad algorithm. It also has the advantage of updating stability of Adam algorithm, and Adadelta does not need to manually search for the initial learning rate. Therefore, the Adamdelta algorithm is used to adjust the learning rate of FTRL-Proximal to improve the performance of the online learning algorithm. Setting

The change rate that step size of iteration can be expressed as

The regular term coefficient of L1 is λ1, then, the parameter update formula of the FTRL-Proximal algorithm can be calculated as follows

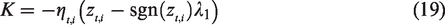
This paper uses the Adamdelta algorithm to replace the learning rate of FTRL-Proximal to improve the performance of the online learning algorithm. The update formula is

In this equation,

At the same time, using
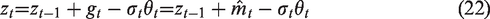
The parameter update formula of the improved FTRL-Proximal algorithm is obtained by the above derivation. The flow of the algorithm is given as follows.
Initialization θ1,1…
N
= 0, z1,1…
N
= 0, first- and second-order moment m0,1
…N
= 0, v0,1
…N
= 0, E[Δθ2]0,1…
N
= 0, ρ1 = 0.900, ρ2 = 0.999, ρ3 = 0.950, ϵ = 10−8 For t = 1 to T According to the specific distribution of online learning dataset, setting and learning the corresponding optimization objective loss function For all i ∈ N Calculation
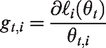

Calculate σt from equation (21);
Deviation correction of first- and second-order moment estimation using equations (9) to (12)
Use equation (13) to correct the root mean square deviation of the parameter variation
Use equation (14) to update parameter Δθt,i
Use equation (15) to update the history cumulative amount
Use equation (22) to calculate zt
6. Use
Use equations (16) to (20) to update parameter θt
7. End For 8. End For
Sentiment classification model based on online learning
Machine learning is divided into offline learning and online learning according to different training methods. Among them, offline learning has problems such as slow training speed and memory limitation when dealing with massive data. 21 Therefore, this paper proposes an emotional classification model based on online learning to process sentiment data.
The model of Doc2vec
The Word2vec model will obtain word vectors through training and measures the relationship between words by calculating the distance between word vectors, but it lacks the ability to analyze semantics between sentences and texts. Therefore, Le and Mikolov 22 proposed the Doc2vec model based on Word2vec. Doc2vec is almost identical to Word2vec except for adding a paragraph vector; it includes two models, PV-DM and PV-DBOW.
The PV-DM model uses the context and the added paragraph vector to predict the word probability, and the added one paragraph vector holds the semantic information of the sentence or text. Each paragraph vector uniquely identifies a sentence or text, and the word vector shares a paragraph vector during the same sentence or text training process. Add the paragraph vector and the word vector to average or connect them to as input of Softmax function. PV-DBOW uses the paragraph vector to predict the probability of a list of random words in a paragraph.
Online learning logistic regression algorithm
Traditional logistic regression can obtain a high-precision classification model by training many samples but loading many samples into memory has high requirements on computer memory. Model training is not possible if the number of samples exceeds the computer’s memory. This article uses online learning to train the model, updating the model once each sample is trained, reducing the memory requirements of the computer. The FTRL-Proximal of the improved learning rate optimization algorithm is used to replace the gradient descent to update the parameters of the logistic regression model, and the online learning logistic regression model is obtained. The flow of the algorithm is as follows.
Initialization θ1
…N
= 0, z1
…N
= 0, first- and second-order moment m0,1
…N
= 0, v0,1
…N
= 0, E[Δθ2]0,1…
N
= 0, ρ1 = 0.900, ρ2 = 0.999, ρ3 = 0.950, ε = 10−8 While(Stop condition is true) Take a sample (xt, yt) from the training sample set According to the specific dataset, the corresponding target function is set. In this paper, use the sigmoid function to construct the target function The negative logarithmic likelihood is used to obtain loss function J(θ); in this paper, use the above likelihood function to get loss function as For all i ∈ N

Update parameter θ //FTRL-Proximal algorithm for optimizing learning rate
7. End For 8. End While
Online learning sentiment classification model
For Chinese emotional information data, it is necessary to preprocess about word segmentation, stop words, filter punctuation, and so on. For English sentiment information data, it is necessary to filter punctuation, stop words, change case, and so on. Then the Doc2vec model is used to train the preprocessed sentiment information to obtain the paragraph vector and word vector representation. After obtaining the vector representation of the sentence or text, the online learning classification model is used for online training, and the classification ability of the model is improved by continuously learning and updating the model. After a period of learning, the classification ability of the model can achieve the desired effect, and the text or sentence of the unknown emotion category can be emotionally classified. A schematic diagram of the entire model is shown in Figure 1.

Online learning sentiment classification model.
Experiment and result analysis
Experimental environment and dataset
To verify the effectiveness of the improved learning rate optimization algorithm, experiments were performed on the Ubuntu Kylin 16.04 system, and the experimental program was written for Python 2.7. The experimental data are the IMDb movie review text. The dataset includes two categories, one is optimistic commentary and the other is pessimistic commentary, with 25,000 comments per category.
Data preprocessing
Above all, the text comment data are first processed in word segmentation, and then the words and punctuation are stopped, and input the processed text into the Doc2vec model, and the vector representation of each text is obtained through training. Doc2vec uses the PV-DM model for training; using negative sampling for optimization, the number of negative sampling noise words is set to 5, the sliding window size is set to 10, and the dimension of the output feature vector is set to 100. The obtained text feature vector is used as the training set and test set of the classification model, and the ratio of them is 1:1.
We choose four common evaluation metrics, Accuracy, Precision, Recall, and F1 in this paper. Their calculation formulas are described as follows.
Accuracy=(TP+TN)/(TP+FN+FP+TN). Precision=TP/(TP+FP). Recall=TP/(TP+FN). F1 = 2×Precision×Recall/(Precision+ Recall).
Results analysis
Experiment 1: Comparison of learning rate optimization algorithms
To understand the characteristics of each optimization algorithm intuitively, compare the advantages and disadvantages of each algorithm, and visualize the algorithm by the three-dimensional running track on the saddle face (z = −2(x2−y2)) and the trajectory on the two-dimensional contour line. Using SGD, Momentum, Adagrad, Adadelta, Adam as the comparison algorithm, compare with the improved algorithm Adamdelta. The parameter settings of each algorithm are shown in Table 1. “–” indicates that the algorithm does not have this parameter.
Parameter settings of each algorithm.

SGD: stochastic gradient descent.
Thereby, a trajectory diagram as shown in Figure 2 is obtained, and Figure 3 is a corresponding diagram of Figure 2 on the two-dimensional contour line, which is derived from the same parameter setting. It is found through experiments that if the initial position of the algorithm on the x-axis is set to 0, all algorithms will fall into the center point of the saddle plane, that is (0, 0, 0); therefore, the initial position of the algorithm is set to (0.001, 0.8), The number of iterations in Table 1 reaches the position shown in Figure 2. Each dot in the figure represents the position after one iteration.

Running track diagram on three-dimensional saddle surface. SGD: stochastic gradient descent.

Trajectory diagram of a two-dimensional saddle surface contour. SGD: stochastic gradient descent.
As can be seen in conjunction with Figures 2 and 3, the trajectory of the SGD algorithm is always updated along the direction in which the gradient falls the fastest, since each update direction is only related to the current gradient. The Momentum algorithm does not adjust direction immediately after it has moved to the center position because its update direction combines the last update direction and the current gradient descent direction.
The Adagrad algorithm has a large update distance of per step in the early stage, and the later update distance is smaller and smaller because it uses the cumulative gradient squared sum as the denominator of the learning rate. Therefore, as the number of iterations increases, the learning rate becomes smaller and smaller. It can be seen that Adagrad iterated 85 times before reaching the position in Figure 2, which is the most iterative compared to other algorithms. The Adadelta algorithm has a small update distance of per step in the early stage, and the later update distance is larger. This is because it eliminates the step of manually setting the initial learning rate. Therefore, the previous update speed is greatly affected by the ε value, where the ε value is 1e-8, so the initial update distance is small; if the ε value is set to 1e-4, only needs to be iterated 12 times to reach the position shown in Figure 2; it can be seen that this update speed is faster than other algorithms, so there will be jitter in the later stage.
The Adam algorithm has little difference in the update distance each time because it performs deviation correction on the gradient and the algorithm is relatively stable. The update distance of the Adamdelta algorithm in each step is larger than that of the Adadelta. The algorithm corrects the parameter update amount, so the algorithm starts faster than Adadelta. As the number of iterations increases, the algorithm update tends to be stable and the update direction is reasonable. It shows that the improved learning rate algorithm solves the problem that the learning rate disappears compared with Adagrad. At the same time, it has the advantages that the Adam algorithm is stable, the Adadelta algorithm does not have to manually search for a suitable initial learning rate and does not start too slowly.
Experiment 2: Comparison of online learning sentiment classification effects
To measure the influence of the algorithm on the classifier, SGD, Momentum, Adagrad, Adadelta, Adam and the Adamdelta algorithm proposed in this paper are combined with the LR classifier to classify the sentiment data processed by the Doc2vec model using online learning. The parameter settings of each algorithm are shown in Table 2. To prevent the Adadelta from starting too slowly, set its parameter ε to 1e-4.
Parameter settings of each algorithm.

SGD: stochastic gradient descent.
Set the number of initial iterations to 100, set the maximum number of iterations to 7100 and increase 250 times per round. The classification accuracy of each algorithm under different iterations is obtained on IMDb dataset, as shown in Figure 4, and the time consumed by each algorithm is shown in Figure 5.

Comparison of classification accuracy. SGD: stochastic gradient descent.

Comparison of consumption time. SGD: stochastic gradient descent.
As can be seen from Figure 4, the accuracy of the Adamdelta algorithm is significantly higher than that of SGD, Momentum, Adagrad, and Adadelta, and a small increase compared to Adam. After the number of iterations is more than 3500, the accuracy of SGD, Momentum, Adagrad, and Adadelta is no longer improved, and the accuracy of Adam and Adamdelta is still increasing with the number of iterations. The Adamdelta algorithm proposed in this paper solves the problem that the algorithm effect cannot be improved due to the learning rate disappearing in the late stage of training for Adagrad algorithm. It can be seen from the trend of the curve that Adamdelta is more stable than other algorithms. The introduction of Adam’s deviation correction method is used to correct the gradient and parameter update amount, which has a good effect on improving the stability of the algorithm. From Figure 5, the SGD, Momentum, Adadelta, and Adamdelta algorithms consume almost the same time, while the Adagrad and Adam algorithms consume more than three times longer than the former. Explain that Adamdelta inherits the advantages of Adadelta training speed. The comparison of the accuracy and time consumption shows that the improved learning rate algorithm proposed in this paper has obvious advantages (not only) in classification accuracy and (but also) speed compared with Adagrad. Compared with Adadelta, there is a certain advantage in accuracy. Comparing with the Adam, there is obvious advantage in training speed.
Experiment 3: Comparison of offline learning and online learning for sentiment classification
The following three models are respectively used for offline learning or online learning for sentiment data processed by the Doc2vec model. Using the LR classifier as the classification model for offline learning, using the batch gradient descent to update the parameters of the LR model, using the online learning classification model based on Adagrad's FTRL-Proximal combined with LR, and the online learning classification model based on Adamdelta's FTRL-Proximal combined with LR. Since offline learning and online learning use different numbers of samples per iteration, they are not compared with the results of the same number of iterations but are compared with the classification indicators and training time when the respective models achieve the best results. The experiment found that the offline learning model was stable up to 140 times, and the index values were basically unchanged. When the online learning model was iterated to 6000 times, the index values were stable. Therefore, the number of iterations of the offline learning model was set to 20–140 times, increasing 10 times of each round, the number of iterations of the online learning model is set to 100–6100 times, increasing 300 times of each round, and the classification accuracy, precision, recall rate, the value of F1 and training time are compared in Figures 6 and 7.
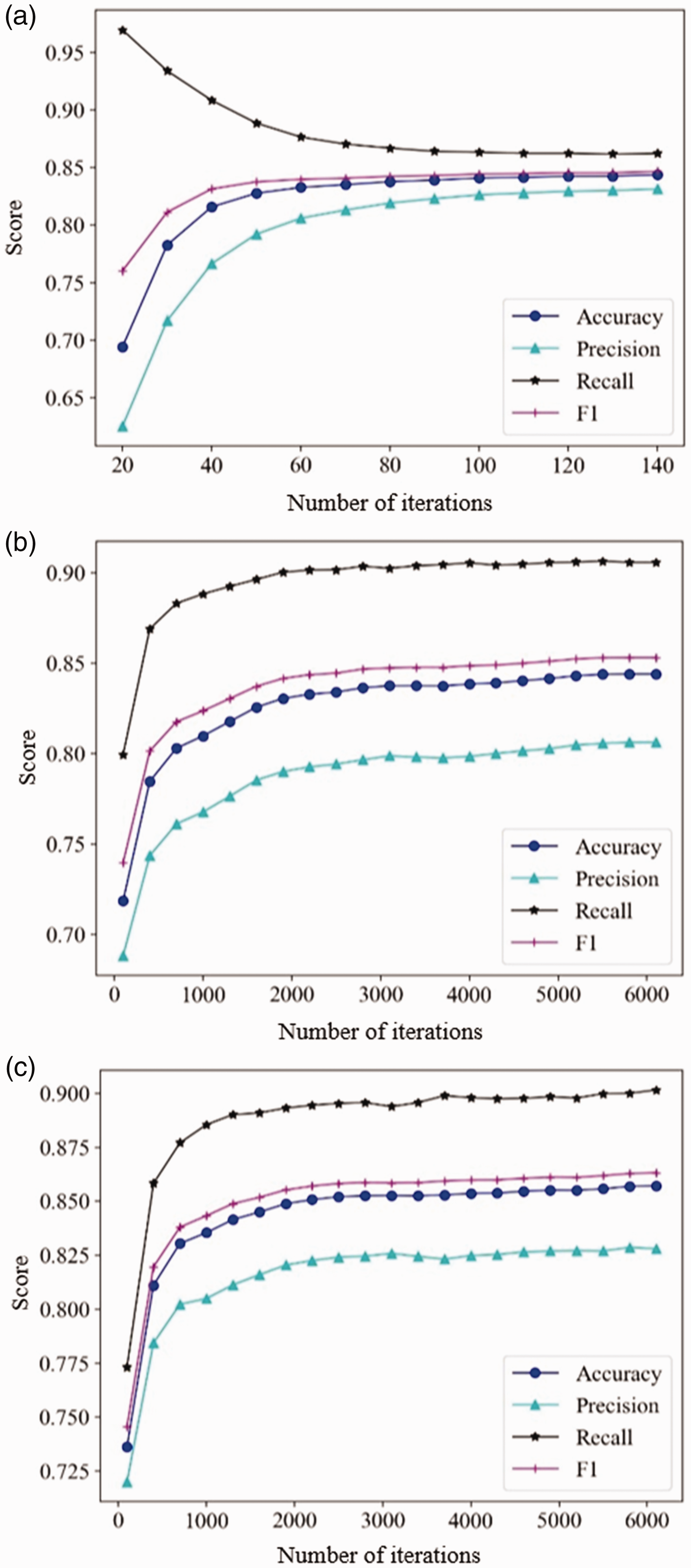
Analysis of the evaluation indicators of the learning model. (a) Indicator values for offline learning, (b) indicator values of FTRL+Adagrad, and (c) indicator values of FTRL+ Adamdelta.

Time-consuming analysis of learning models. (a) Time spent on offline learning, (b) consumption time of FTRL+Adagrad, and (c) consumption time of FTRL+Adamdelta.
Comparing the classification index values of the three models in Figure 6, the accuracy of the offline learning model is not much different from the original FTRL-Proximal algorithm, and the accuracy of the improved FTRL-Proximal algorithm is 1–2% higher than offline learning and the original algorithm. Compared with the offline learning model, the online learning model has a high recall rate, a low accuracy rate, and a slightly higher value of F1. It shows that the online learning model tends to predict pessimistic comments as optimistic comments. Comparing the training time of the other three models in Figure 7, the proposed model achieves the best effect of training, the offline learning model consumes about two times that of the original online learning model and about six times better than the improved online learning model. It shows that the online learning model has a great advantage about training speed compared with the offline model. So, the improved online learning has a significant improvement about training speed compared with the original algorithm.
With the offline learning model, the online learning model using improved learning rate can improve the accuracy and shorten the training time. It shows that the online learning sentiment classification model proposed in this paper has a certain feasibility.
Conclusion
The learning rate of FTRL-Proximal algorithm is analyzed first. For the problem that the learning rate disappears in the later stage of training, deviation is corrected at the root mean square of the parameter update quantity and the first- and second-order moment estimation of the gradient. And then, the improved FTRL-Proximal algorithm is used to iteratively solve the parameters of the LR model and the online learning LR model is obtained. This model is used as the classifier of sentiment classification model. The text feature vector generated by Doc2vec tool is used as the input vector of the model to form a complete online learning sentiment classification model. Finally, the improved algorithm and model are verified and evaluated through experiments. The experimental results show that (1) the proposed algorithm has an advantage with the Adam algorithm and Adadelta algorithm to update stability and faster starting speed, and it solves the problem of the learning rate of Adagrad disappearing and has a better classification effectiveness; (2) the online learning model can improve learning rates with higher accuracy and significantly shorter training time.
Footnotes
Acknowledgements
The authors would like to thank the editor and all the referees for their useful comments and contributions for the improvement of this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Jilin Province (20150101054JC), Postdoctoral Research Fund of Jilin Province (40301919), the Key Program for Science and Technology Development of Jilin Province (20150204036GX), Major Science and Technology Bidding Project of Jilin Province (20170203004GX), and Industrial Technology Research and Development Special Project of Jilin Province (2016C090).