
Abstract
In this work, we summarized the characteristics and influencing factors of load forecasting based on its application status. The common methods of the short-term load forecasting were analyzed to derive their advantages and disadvantages. According to the historical load and meteorological data in a certain region of Taizhou, Zhejiang Province, a least squares support vector machine model was used to discuss the influencing factors of forecasting. The regularity of the load change was concluded to correct the “abnormal data” in the historical load data, thus normalizing the relevant factors in load forecasting. The two parameters are as follows Gauss kernel function and Eigen parameter C in LSSVM had a significant impact on the model, which was still solved by empirical methods. Therefore, the particle swarm optimization was used to optimize the model parameters. Taking the error of test set as the basis of judgment, the optimization of model parameters was achieved to improve forecast accuracy. The practical examples showed that the method in the work had good convergence, forecast accuracy, and training speed.
Keywords
Introduction
In this work, the short-term load is forecasted by the least squares support vector machine (LS-SVM) and improved particle swarm optimization (PSO) algorithms. In Shawe-Taylor and Cristianini,1, 2 PSO and chaos optimization algorithms are used to select the parameters of a support vector machine (SVM) model, respectively. After that, the two methods are combined to forecast the short-term power load. In Suykens and Vandewalle, 3 the short-term power load is forecasted by combining SVM based on PSO with the fuzzy reasoning. In Gong, 4 the short-term load forecasting, SVM regression, and sequential minimal optimization (SMO) theory are conducted with intensive research. Then, the short-term loads are forecasted by linear regression, SVM regression, and SMO. Based on the analysis of parameters and performances of SVM, the Grid-search method is introduced to the short-term load forecasting algorithm based on SVM, solving parameter selection problem of SVM.5 In Heng, 6 the input variables are pretreated by rough set theory to realize the optimal selection, reducing the dependence on experience and improving model adaptability. Combined with rough set theory, genetic algorithm (GA) is used to optimize the model parameters of LSSAM, establishing the short-term load forecasting model of LSSVM. In Yang and Cheng,7 the reasonable historical data are filtered by clustering to form training samples. Then, the forecast smoothness and error loss function are integrated to constitute the objective function of problem. LIBSVM is a set of support vector machine library developed by Professor Chih-Jen Lin in 2001. This library is fast in operation and can be used to classify and regression data conveniently. Because libSVM program is small, flexible to use, less input parameters, and is open source, easy to expand, so it has become the most widely used SVM Library in China. Using LIBSVM algorithm, large-scale optimization problem of SVM is transformed into secondary optimization problem with analytic solution. Based on the chaotic characteristics of load time series and LS-SVM, a short-term load forecasting model is established by combining phase space reconstruction theory of chaotic time series and regression theory of SVM.7 In literature,2 PSO and chaos optimization are applied to select the parameters of the SVM model respectively. Finally, the two methods are combined to predict short-term power load. In literature, 8 the SVM and fuzzy inference of PSO are integrated for the short-term load forecasting. In literature, 9 the short-term load forecasting, support vector regression, and SMO theory are deeply studied, and linear regression, support vector regression, and SMO are used to predict the short-term load in three ways. 10 Based on the analysis of the SVM's parameter performance, the Grid-search method is introduced to the SVM-based short-term load forecasting algorithm, in order to solve the problem of parameter selection in SVM. In literature, 11 the input variables are preprocessed by rough set theory, which realizes the optimal selection of input variables, reduces the dependence on experience in the process of establishing prediction models, and improves the adaptability of models. The GA is used to optimize the model parameters of the LS-SVM. A short-term load forecasting model of LS-SVM is established, which combines rough set theory and GA. Literature 12 in filtering the historical data through clustering of the training sample, smoothness and error loss function prediction combined constitute the objective function of the problem, using LIBSVM algorithm for large-scale optimization problems SVM into two analytical solutions of optimization problems. 13 Based on the chaotic characteristics of load time series, combined with the theory of phase space reconstruction of chaotic time series and the regression theory of SVM, a short-term load forecasting model based on load chaos characteristics and LS-SVM is established.
After going through mass data, we obtain the following difficulties from the perspective of short-term load forecast.
Overall consideration of the factors affecting load forecast
The load forecast is to predict the future value of power load according to its past and present. However, the historical data of the load are lost or wrong due to measurement and human factors. It is unfavorable to grasp the changing trend of load, increasing the difficulty of load analysis. Therefore, it is necessary to finish the identification and correction of bad data before the training and forecast of the historical data.
2. Selection of load forecasting method
Correct selection of forecasting model is the most critical step in load forecasting. With the deepening of load forecasting technology research, various load forecasting methods come into being, with different research characteristics and working conditions. No method can be suitable for all situations. In order to improve the forecast accuracy, the appropriate forecasting method is selected according to the actual situation.
With the rapid development of science and technology, the research and application of artificial intelligence methods have great advantages and application potential. The main algorithms areLS-SVM(Least squares support vector machine ) 14,15,16, neural network algorithm 17, fuzzy reasoning system 18, genetic algorithm, chaos theory 19. These methods and expert systems, Tabu search, mosquito search, simulated annealing, data analysis, adaptive, self-learning and other technologies closely combined, complementary prediction methods, collectively known as intelligent technology.(1) artificial neural network method. In 1991, Park. D. C. et al. first introduced artificial neural network into load forecasting, and then, the research on neural network load forecasting emerged in endlessly.20 The advantage of neural network technology is that it can imitate the intelligent processing of human brain and has adaptive function to a large number of non-structural and non-accurate laws. The disadvantage is that the training process is slow, and it can not guarantee its convergence. At the same time, the structure of the neural network, the appropriate selection of input variables, the number of hidden layers and other issues need to be explored in practice.(2) fuzzy control method. Fuzzy prediction method only simulates the reasoning and judgment of experts, and does not need to establish an accurate mathematical model.21 Fuzzy theory is suitable for describing widely existing uncertainties, and it has powerful nonlinear mapping ability. It can uniformly approximate any nonlinear function defined on a compact density with arbitrary precision, and can extract their similarity from a large number of data. However, with the further study and application of fuzzy theory, fuzzy theory has exposed some shortcomings: the learning ability of fuzzy is weak; when the mapping area is not fine enough, the mapping output is rough.22,23 (3) genetic algorithm. Genetic algorithm is a stochastic, iterative and evolutionary search method based on natural selection and population genetic mechanism. Genetic algorithm has the ability of global optimization. Generally, genetic algorithm is used to optimize ANN weights in order to overcome the shortcomings of BP algorithm in convergence performance and local minimum, and improve the prediction accuracy. (4) support vector machine. A new machine learning algorithm, Support Vector Machine (SVM), was proposed by Vapnik et al. of Bell Laboratory in 1995. Unlike the empirical risk minimization (EMR) induction principle that most machine learning methods are based on, it is based on structural risk minimization (SRM) and VC dimension theory, and achieves a good balance between model complexity and learning ability. Therefore, its generalization ability is much better than that of artificial neural network and fuzzy logic. SVM regression algorithm has the advantages of short convergence time, high prediction accuracy,24 less adjustable parameters and easy structure determination, and it does not need too much prior information and use skills. Therefore, more and more attention has been paid to the application of SVM in the field of power load forecasting. SVM has broad application space and development prospects, and is considered as the best alternative to neural network method.
SVM regression principle
LS-SVM is firstly proposed by Suykens and Vandewalle.3 It is an extension of the standard SVM. Compared with other versions of SVM, the LS-SVM has fewer parameters to be selected. In addition, the equation constraints are used to replace the original inequality constraints, reducing some uncertainties. The loss function is directly defined as the sum of squares of errors to transform the optimized inequality constraints into equality constraints. Therefore, the quadratic programming problem is transformed into linear equations to reduce the computational complexity, accelerating the solution speed. The basic principle is as follows.
For the nonlinear load forecasting model

Given a set of data points:



According to Karush-Kuhn-Tucker (KKT) condition

After the elimination of


PSO theory
Principle of standard PSO
PSO is a swarm intelligence evolutionary computation technology based on iterative optimization. A swarm of random particles is initialized to find optimal solution by iterations. In each iteration process, the particle updates the velocity and the position in the next iteration by tracking individual extreme
It is assumed that there are
The standard PSO updates the speed and position of the particle by the following equations.


Improved PSO theory
In the work, we designed an improved PSO, which controls population characteristics by diversity metrics, to solve premature convergence of particle swarm. Specific implementation process includes the following two aspects.
Selection of initial particle swarm
The initial particle swarms are randomly selected. Ideally, the positions spread over the entire solution space to increase the probability of finding the global optimal solution. However, the initial particle swarm has limited particles and large solution space. If limited particles are not uniformly distributed in the whole solution space, then the possibility of local optimum will be increased.
The concept of average inter-particle distance is introduced and defined as equation (9).
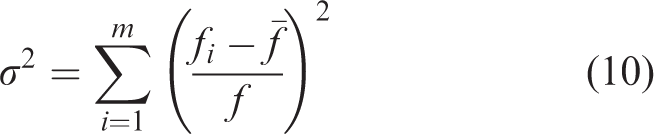
The average inter-particle distance indicates the dispersion degree of particles in the swarm. The smaller D(t) leads to the more concentrated swarm; the larger D(t) leads to the more dispersed swarm.
2. Judgment of premature convergence
In the whole iterative process of standard PSO, the particles approach to global history optimum solution. Standard PSO reaches fast and slow convergence rates at the initial and latter stages, respectively. If the local extreme point is encountered, the speeds of all particles will soon drop to zero. The swarm loses the ability to evolve, and then the algorithm gets into local optimal point because of premature convergence. For the particle, the position determines the fitness. Therefore, the current state of the swarm can be judged according to the overall change in the fitness of all particles. If the current fitness of the i-th particle is

Fitness variance reflects the aggregation degree of particles in the swarm. The smaller
Load forecasting procedure
The concrete process of the improved PSO is as follows. In the premise of uniform initial swarm distribution, the basic operation of standard PSO is firstly implemented until the particles are in the precocious state. After that, the particle solution space is reallocated to guide particles to quickly jump out of local optimum, thus accelerating the convergence. The specific algorithm and flow chart are presented in Figure 1.

The flow chart. PSD: particle swarm optimization; SVM: support vector machine.
The particle swarm is initialized according to the above method. The swarm size is set as m; the number of maximum evolutional generations as
The fitness values
We calculate the average inter-particle distance D(t) and fitness variance
The particle swarm is re-initialized according to the method described above.
The velocity and position of each particle are updated according to equations (7) and (8) to produce new swarm X(t).
The fitness values of new positions of particles in X(t) are calculated to compare with the historical optimal positions of individuals and swarm, respectively. If the new position has better fitness value, then the historical optimal position will be replaced; otherwise, it will remain unchanged.
Check whether the end condition of optimization is satisfied (equal to
Error Evaluation Index
Absolute Error (AE)
Relative Error (RE)
Mean Absolute Error (MAE)
Mean Absolute Percentage Error (MAPE)
Mean-Square Error (MSE)
where




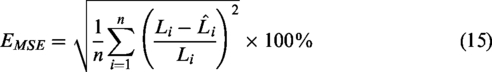
Simulation and experiment
The simulation is implemented in MALAB2008a. Firstly, LS-SVM algorithm was used to predict the load data of certain region in Taizhou, Zhejiang Province in 2015. The predicted results are compared with the actual load data of the forecast day using MAE. Figure 2 shows the forecasted and actual load curves by LS-SVM. Multiple samples are forecasted to overcome contingent factors (see Table 1).

Forecast results by LS-SVM algorithm (green: actual load; red: forecast load).
Forecast results of multiple samples by SVM.

SVM: support vector machine.
In Software MALAB2016a, the improved PSO was used to predict the critical parameters of the SVM model. The predicted results are compared with the actual load data by MAE. Similarly, different sample sets in certain region of Taizhou, Zhejiang in 2009 are forecasted and averaged to reduce the impact of contingent factors. Table 2 shows model parameter optimization results after the iteration calculation. Figure 2 shows the forecasted and actual load curves.
Forecast results of multiple samples by improved PSO.

PSO: particle swarm optimization.
Table 2 and Figure 3 show that the improved PSO has better searching ability and precision. Within four forecast days, the MAEs of the forecast model have total average of 2.06% and the maximum error of less than 3.02%. Therefore, the algorithm is effective and feasible for short-term load forecasting. On 28 February, the error of forecasted value is large probably because of equipment maintenance and circuit breaker tripping. It is difficult to reflect the change only by the data.

Forecasted and actual load curves by improved PSO (green: actual load; red: forecasted load).
In Figure 3, the curves marked by circle and triangle are actual and predicted loads. Comparative results show that the forecast errors of LS-SVM method are less than 4% in general working days or holidays. However, these forecast errors are still large. The prediction method has slightly larger forecast error in holidays than in working days, which basically accords with the reality. On 31 March and 20 May, the forecast values have large errors. This is probably because equipment maintenance and circuit breaker tripping result in large load fluctuations. It is difficult to reflect the change only by the data.
The precocious convergence judgment mechanism based on the population diversity information is guided by the particle location updating, reducing the randomness of the algorithm, making the improved new algorithm can jump out of the local most advantages, always keep the particle better dispersivity, and gradually search the better regions outside the current optimal region and reach the better area. Global optimization and global optimization ability are significantly enhanced without slowing down the convergence speed.
Theta is Gauss's normalization parameter that determines the width of the function around the center point. The kernel width coefficient reflects the correlation between the support vectors, which is related to the input space range of the learning samples. The larger the sample input space is, the greater the value is. The relationship between support vectors is relatively relaxed, the learning machine is relatively complex, and the generalization ability is not guaranteed. It is difficult to achieve enough accuracy in the regression model because of the large influence between the support vectors. The normal number of C to coordinate the two needs the testers' experience to determine which is difficult for testers and sometimes takes a long time.
Conclusions
As the main basis for development of power generation and transmission schemes, short-term load forecasting is an important daily work in dispatching operation department of power system. It has become one of the important contents of power system management modernization. In the work, the short-term load was forecasted by LS-SVM and improved PSO. SVM can better solve practical problems such as small sample, nonlinear, high dimension, and local minimum point based on profound theory. Consequently, the SVM model achieved the ideal effect in short-term load forecasting.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.