
Abstract
This article presents a case study determining the optimal preventive maintenance policy for a light rail rolling stock system in terms of reliability, availability, and maintenance costs. The maintenance policy defines one of the three predefined preventive maintenance actions at fixed time-based intervals for each of the subsystems of the braking system. Based on work, maintenance, and failure data, we model the reliability degradation of the system and its subsystems under the current maintenance policy by a Weibull distribution. We then analytically determine the relation between reliability, availability, and maintenance costs. We validate the model against recorded reliability and availability and get further insights by a dedicated sensitivity analysis. The model is then used in a sequential optimization framework determining preventive maintenance intervals to improve on the key performance indicators. We show the potential of data-driven modelling to determine optimal maintenance policy: same system availability and reliability can be achieved with 30% maintenance cost reduction, by prolonging the intervals and re-grouping maintenance actions.
Introduction
Public transportation networks are being consistently indicated as a key player to ensure sustainable, affordable, and high-quality mobility in urban areas. 1 In reality, much has still to be done to ensure a high level of system performance when providing safe and comfortable transport services to its customers. High level of system performance comes from carefully planned operations and a high availability of the asset during operations (reliability of operations, disturbances, and disruptions) as well as outside operations (workforce for maintenance and repairs, availability of extra vehicles to run the planned services). Keeping a high level of service encompasses these three aspects which are conflicting, with direct impact on capital-intensive issues. 2
This article presents a case study to support decisions by a public transport operator, Haagsche Tramweg Maatschappij (HTM), which manages and operates tram and light rail systems in the region of The Hague, The Netherlands. The main decision to be tackled is to balance maintenance operations (cost and workforce required) versus system performance, expressed in terms of reliability and availability. The maintenance actions of HTM follow a pre-determined maintenance policy: a set of preventive maintenance (PM) tasks is performed at fixed, distance- or time-based intervals. The maintenance policy is the sequence of tasks with a positive impact on the performance and life expectancy of the subsystem and its components, described in terms of task level (ranging from a simple check to a full repair), and their timing.
We focus on the braking system of light rail rolling stock (Alstom Citadis), more details in Appendix 1. For light rail rolling stock, it is currently the task of the manufacturer to determine a maintenance policy on forehand, based on reliability, availability, maintainability, and safety (RAMS) specifications and based on the degradation, failures, and repairs expected in the warranty period. Maintenance tasks and intervals were never evaluated, and it is suspected (based on experience and gut feelings, not on quantitative indicators) that they are very conservative, resulting in a high workshop load and high maintenance costs. The goal of this article is to report on a test case on dedicated optimization of PM policy which targets directly reliability, availability, and maintenance costs. We combine the existing failure records with a dedicated maintenance model to improve the maintenance of a rolling stock system.
The main contribution of this article is the application to a relevant test case of a comprehensive approach used to determine a PM policy and comparison against the current state of practice. To the best of our knowledge, no similar test case bridging data-driven failure modelling and data-driven maintenance modelling has been reported yet in the literature, despite its very high practical interest. The approach proposed goes through the following systematic steps:
Failure modelling: describing the failure behaviour with Weibull functions. The values of Weibull coefficients were also derived from the recorded failures.
Characterization of maintenance actions and related costs: the downtime and costs of preventive and corrective maintenance actions are determined based on recorded data.
Development of the maintenance model: the model relates the maintenance actions with the failure behaviour, based on the sequence of PM actions, and time intervals between them. We consider three levels of PM actions, based on Tsai et al. 3
Model validation and sensitivity: we determine the sensitivity, influence of uncertainties, impact of input parameters, and uncertainties related to model’s input parameters towards availability and costs. A benchmark maintenance model is determined for the current maintenance policy and validated against observed availability and costs.
Definition of optimal maintenance policy for a given key performance indicator: the model is used to determine maintenance policies aimed at the maximum reliability, maximum availability, and minimum costs, and a compromise between them.
Based on available historical data of past repairs and maintenance actions, optimized maintenance policies can be determined, which allow consistent savings compared to current approaches, while keeping the operational performance higher than current state of practice. We schematize the combination of data-driven system modelling, expert knowledge, and company strategies and objectives in Figure 1. We remark that due to the confidentiality of the data, we can only report aggregated and relative improvements, concerning the company objectives.
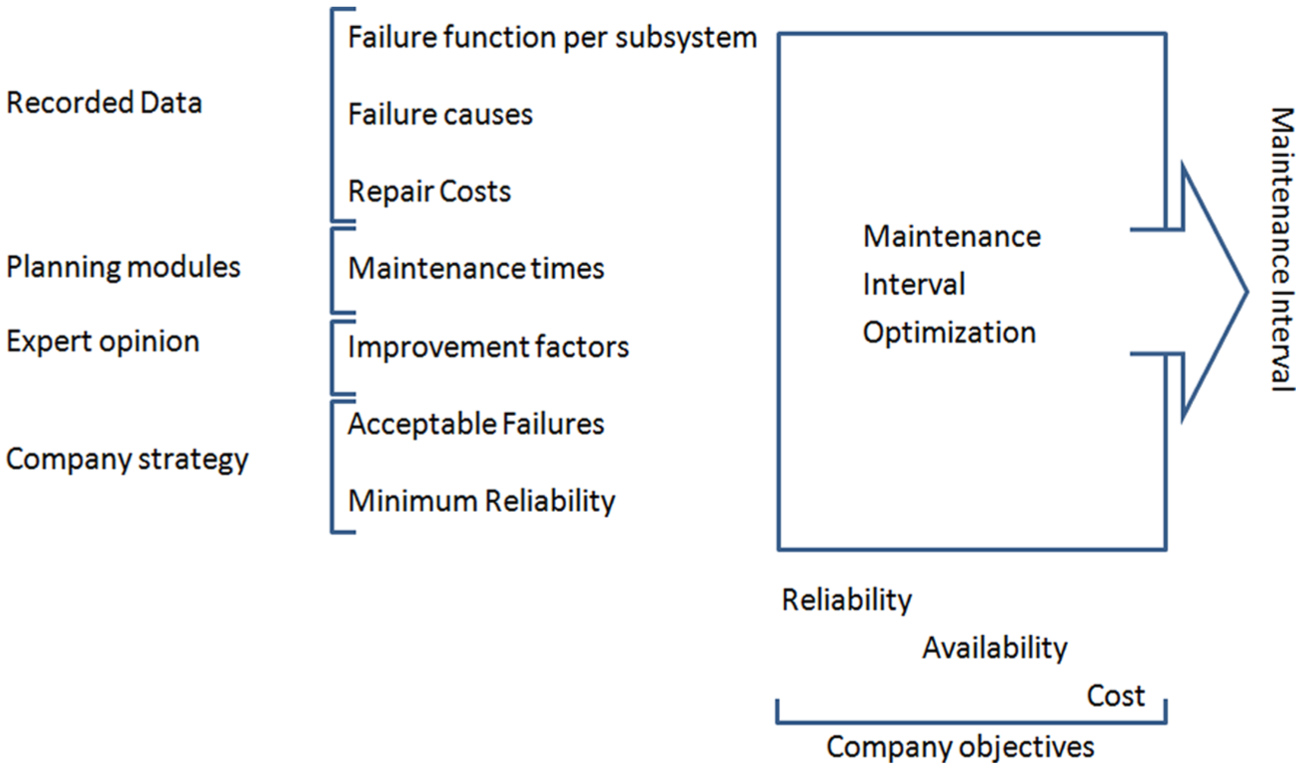
Combination of approaches identified to determine the optimal maintenance policy.
The article is organized as follows. Section ‘Literature review on PM’ reports on the existing literature. Section ‘Modelling failure functions’ describes the possibilities given by data-driven approaches for modelling failures and definition of maintenance actions. Section ‘Modelling PM’ determines the maintenance model, and proposes an optimization scheme targeting a set of key performance indicators, which is evaluated in section ‘Results and discussion’. Section ‘Conclusion and recommendations’ concludes the research, with directions for future research. This article is based on Kraijema. 4
Literature review on PM
Applications of PM to rolling stock systems have often analysed and targeted a single subsystem rather than a holistic perspective of the overall system (air conditioning system 5 and door systems 6 ). We also point to the reader to Giacco 7 for a longer discussion of maintenance issues in rolling stock. In general, PM targets avoiding the system failure and keeps the system available and reliably working for longer periods. In fact, PM actions are proactive in nature and are performed before the systems fail. There are various models of the effects of PM actions on the overall performance of the system; this section gives a short overview of the possible models. For systems where a condition based monitoring system cannot be easily set up, most research efforts are currently directed to better quantifying the intervals for PM and modelling the impact of different maintenance levels and maintenance operations. We call this a PM policy: the set of maintenance actions that are to be performed on specific components or subsystems of a technical system. It also defines the maintenance intervals for these actions.8,9
There are three types of models that can be used to describe the relation between the failure behaviour of a system and components (SC) and the applied maintenance policy:
Constant failure rate (age reduction PM): the failure rate, as a function of the effective SC age, is assumed the same throughout its life cycle. The effects of PM actions are modelled by an effective age reduction (for the period of PM action τ > 0) of the SC, and the failure rate λ(t) becomes λ(t − τ).
Failure rate reduction: the second category assumes that the effects of PM actions on the SC’s failure behaviour are modelled by a reduction of the failure rate of the SC, that is, the failure rate λ(t) becomes
Combined: the effect of PM actions is modelled by a reduction of the effective system age as well as the failure rate, that is, the failure rate λ(t) becomes
All these modelling approaches use the failure distribution function to predict the SC’s reliability. The distinctive difference is found in the way the assumed failure behaviour continues after PM actions are performed. PM actions influence the failure times of system and components (SC). PM actions are described in literature in three typical classifications: perfect, minimal, and imperfect. 10 Perfect PM actions restore the system to an optimal state, that is, the reliability of the system is increased to the ‘As Good As New’ (AGAN) level. Minimal PM actions restore the system to a state comparable to the state just before the maintenance actions were performed, that is, the reliability is increased by a minimal amount. This is referred to as ‘As Bad As Old’ (ABAO). Most PM actions performed in real life are neither perfect nor minimal. These in-between actions are often referred to as imperfect PM. In general, imperfect maintenance models can be grouped into following groups: age reduction models, 11 hazard rate reduction models, 12 combined age-hazard reduction models, 13 and others. 14 Detailed overview of different PM policies can be found in Pham and Wang 15 and Wang. 16
Cheng et al. 17 proposed a linear PM model that optimizes the PM intervals between preventive replacements by minimizing the cost while maintaining a certain minimum level of reliability. The systems reliability is derived from a Weibull failure rate distribution. An improvement factor µ is introduced to model the effects of PM actions on the system’s effective age. This means considering a = (1 − µ) and b = 0. Schutz and Rezg 18 proposed a nonlinear PM model based on the effectiveness of PM actions on the system reliability versus cost. The effectiveness factor ρ and PM interval length T define the effective age reduction of the system. This means considering c = (1 − ρ) and d = T. Cheng and Tsao 19 stated that PM actions do not always directly reduce the systems effective age or failure rate. PM actions such as cleaning, adjusting, or lubricating will only impact the systems degradation rate and will not improve the reliability of the system.
Coria et al. 20 proposed a maintenance model with a more general relation between PM interval and failure rate. Weibull parameters can thus be estimated from real-life failure time data of a system that has been maintained from day one. Imperfect PM actions are performed at fixed intervals tk = kT, with T length of the PM interval. Tsai et al. 3 also use three different levels of PM actions. This provides the ability to closely match the real-life situation and allows for detailed insight into cost savings at a higher system availability and reliability level than models that only consider component replacement. The improvement of PM actions to the reliability is described as a function of the failure mechanisms of the component. Based on the literature surveyed, we found that the models of Coria and Tsai were the most suitable for the rolling stock system due to the possibility to leverage imperfect data about past (possibly imperfect) maintenance tasks.
Modelling failure functions
Available data of recorded failures and identification of subsystem
We start from a database of about 2200 failure, repairs, and maintenance actions which span 5 years between 1 January 2010 and 31 December 2014. In this period, a uniform maintenance policy has been used, for the entire fleet of light rail rolling stock. Burn-in of the vehicles is neglected as the vehicles started operations in 2006. Instead, a period of 2 weeks (estimated with the help of the maintenance engineer (HTM, personal communications, 2015)) is considered after each maintenance action to avoid considering burn-in or imperfect repairs. We filtered the dataset as to not consider censorship, by restricting to a set of records where maintenance actions were anyway performed at fixed intervals, and have been numerous, for all vehicles considered. Relaxing this assumption only needs different methods for estimation of failure rate. 21
Among the subsystems, the braking system has been selected as the most relevant one, being responsible for more than a third of failures, costs, and downtime (see Appendix 1). This has a direct impact on the maintenance policy of the rolling stock systems. The braking system is functionally divided into the four following subsystems: brake control, hydraulics, magnetic track, and electro-dynamic (ED) braking. This latter is excluded from the study as no failure has ever been recorded.
Failure data for the remaining three subsystems are available from different sources: vehicle diagnostics system, driver input, work from inspection, and work order data. Each of these data sources were used and crosschecked to get detailed failure records. The information provided on the corrective work orders will be used to derive the distance to failures for each of the components in the braking system. The mean distance between failures (MDBF) of components in the braking system (the equivalent for transport units of the mean time between failures (MTBF), with the distance covered replacing the time elapsed) can be derived more accurately based on the position of the failed component. When this data are not reported in the computerized maintenance management system (CMMS), information might be given by the mechanic as a remark on the repair work order.
For each of the subsystems, a standard Weibull distribution was used to characterize the failure rate; the scale and shape factors of Weibull distributions are determined from recorded failures to model their failure behaviour. Due to the fact that most failure repairs are imperfect or not effective at all, those distributions cannot be fitted right away.
Failure rate modelling
The failure rate distribution is modelled by means of Weibull distribution, where travelled distance was used instead of time. 22 The distance between failures of the components in the braking system is also influenced by the current PM policy. Formally, the failure probability density function is defined as

where f is the failure probability distribution function, d is the distance travelled between failures,

The data give sufficient evidence that the failure rates of three subsystems are almost constant.
Reliability related to maintenance actions
Three PM actions considered in this model are:
Service (PM1): this includes easily performed maintenance actions such as cleaning, adjustment, retightening, refilling, or adding consumables (oil, grease, etc.). Service actions are assumed to help maintain the SC’s current state of reliability. The current level of reliability is not improved, but the rate of deterioration is reduced.
Low-level repair (PM2): this includes more time-consuming PM actions, such as small spare part replacement in addition to the service activities. Low-level repair is assumed to improve the SC’s reliability to a state in between AGAN and ABAO.
High-level repair (PM3): this includes SC overhaul or replacement. High-level repair is assumed to return the reliability to an AGAN state.
The effects that these PM actions have on the reliability of the SC are defined by two improvement factors m1 and m2. m1 is used to alter the deterioration rate of the SC’s reliability after PM1, and m2 is used to define the reliability increase after PM2. Using standard Weibull distributions for the failure rate, the reliability of the system after maintenance interval j with interval duration T is defined as
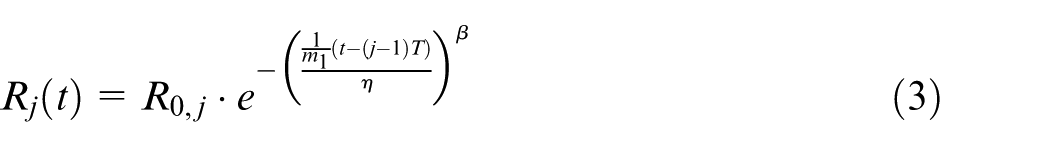
with
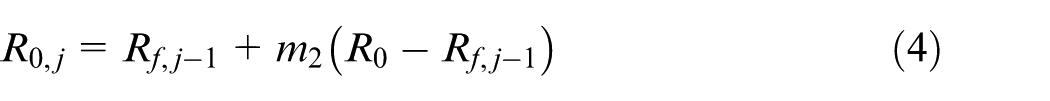
where R0,j is the initial reliability at maintenance stage j, R0 is the initial reliability of a new SC, and Rf,j − 1 is the final reliability before maintenance in the previous stage.
The improvement factors can be defined as a function of some s failure mechanisms, for example, fatigue; wear (contact stress); ageing; and others, such as contamination, corrosion, and heat. 25 The improvement factors are defined as

where i refers to the failure mechanisms, pf is the failure probability, and I is the probability for system improvement caused by the PM action. The two improvement factor parameters m1 and m2 have value of 1 for high-level repair (PM3), m2 has value of 0 for the service (PM1); in the other cases, they have a value between 0 and 1. Determining the precise value for those two parameters is a crucial task as it describes the influence of all maintenance actions. To this end, we refer to expert opinion.
Tsai et al. 3 optimize the system for availability, which also involves determining the relation between reliability and the maintenance actions performed. We here briefly introduce the key relations between those three concepts. The system-level reliability is defined using the Advisory Group on the Reliability of Electronic Equipment (AGREE) method,26,27 assuming that the general system can be decomposed into a series of independent SCs, in this case the four braking subsystems. This leads to the expression of the reliability of the system over time, where αi is the probability of system failure due to subsystem i
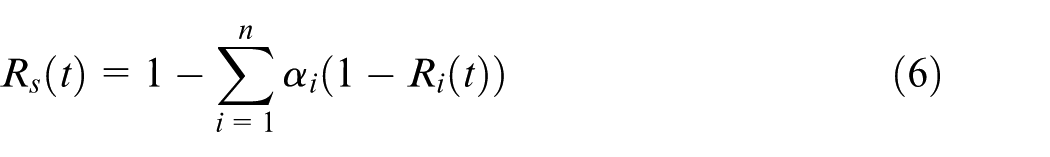
The system-level availability in stage j is defined as
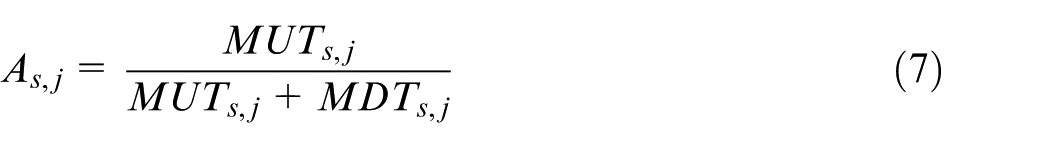
where MUT is the mean uptime of the system defined as
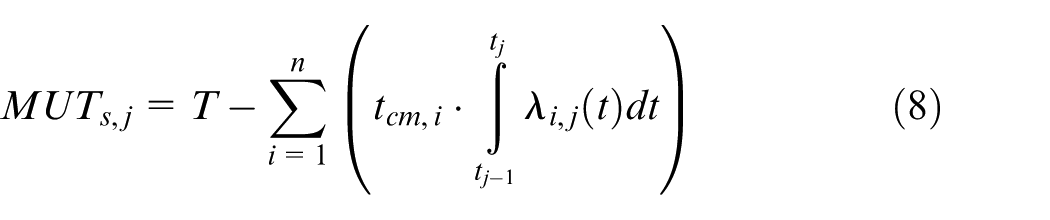
And MDT is the mean downtime of the system defined as
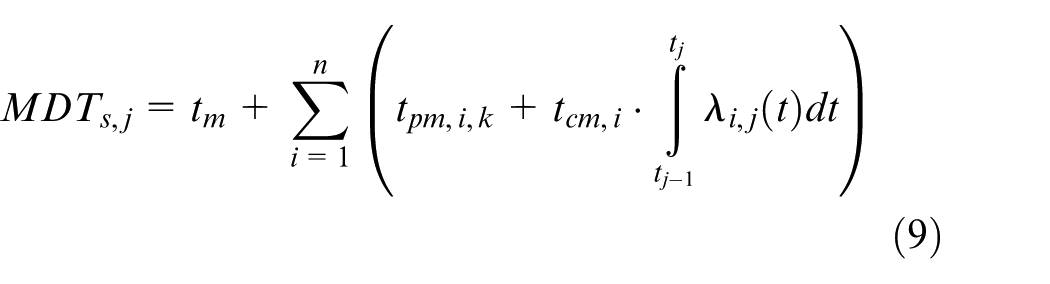
where tcm,i represents the average repair time for subsystem i, tpm,i,k is the time required to perform PM action k on subsystem i, and tm is an additional system-level time for grouped maintenance actions. The average repair time tcm,i is dependent upon the severity of the failure. All times are derived from the planning module of HTM. Braking system failures are always ‘critical’ for safety and need to be dealt with as soon as possible. This takes an extra downtime tdt due to failure and includes the time required to evacuate passengers (if applicable), transfer of the vehicle to the depot, and waiting time for repair; tcm,i,m is the mean repair time for subsystem i

Modelling PM
Input parameters
The impact of maintenance actions on the failure behaviour is described by multiplying the failure probability with the improvement probability associated with the associated PM action per failure mechanism. We use the available failure records to estimate the failure probabilities per failure mechanism. The improvement probabilities of associated PM actions are instead estimated using expert opinion. However, before estimating the improvement probabilities of PM actions, it is necessary to define the content of PM actions. Table 1 gives an overview of the maintenance tasks that are assumed to be performed when a PM action is applied to the subsystem, and Table 2 gives an overview of the related parameters to each subsystems and failure cause.
Identification of subsystems and related PM actions.
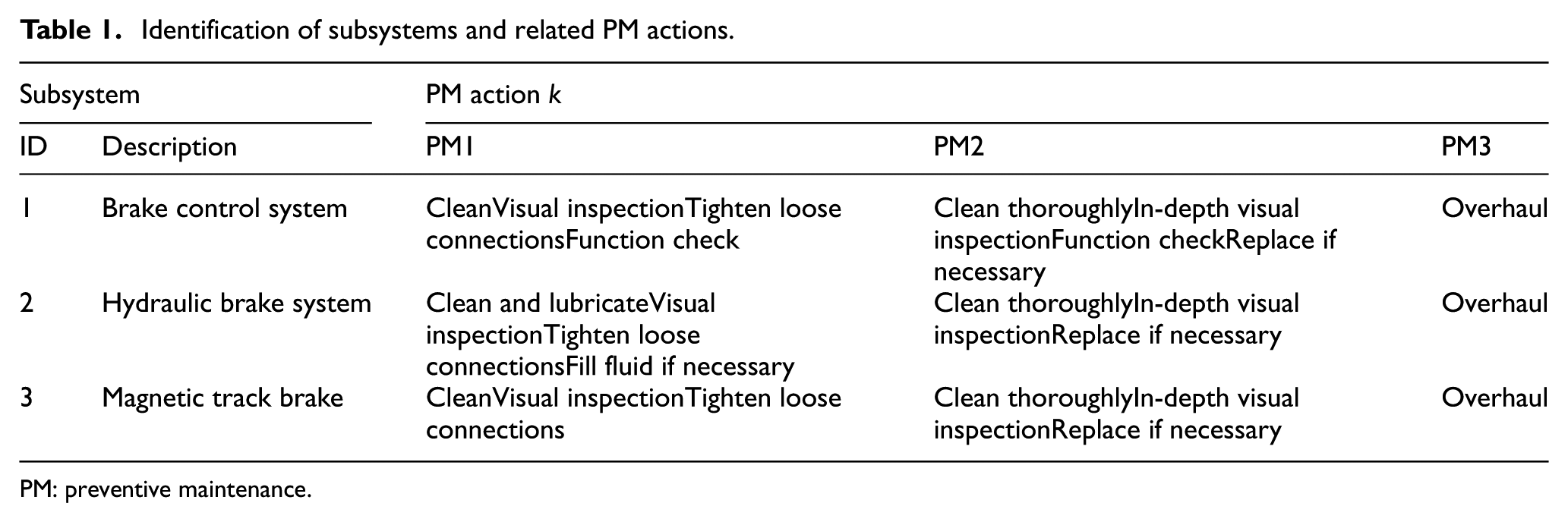
PM: preventive maintenance.
Parameter values for subsystems, PM actions, and failure probabilities (FP).
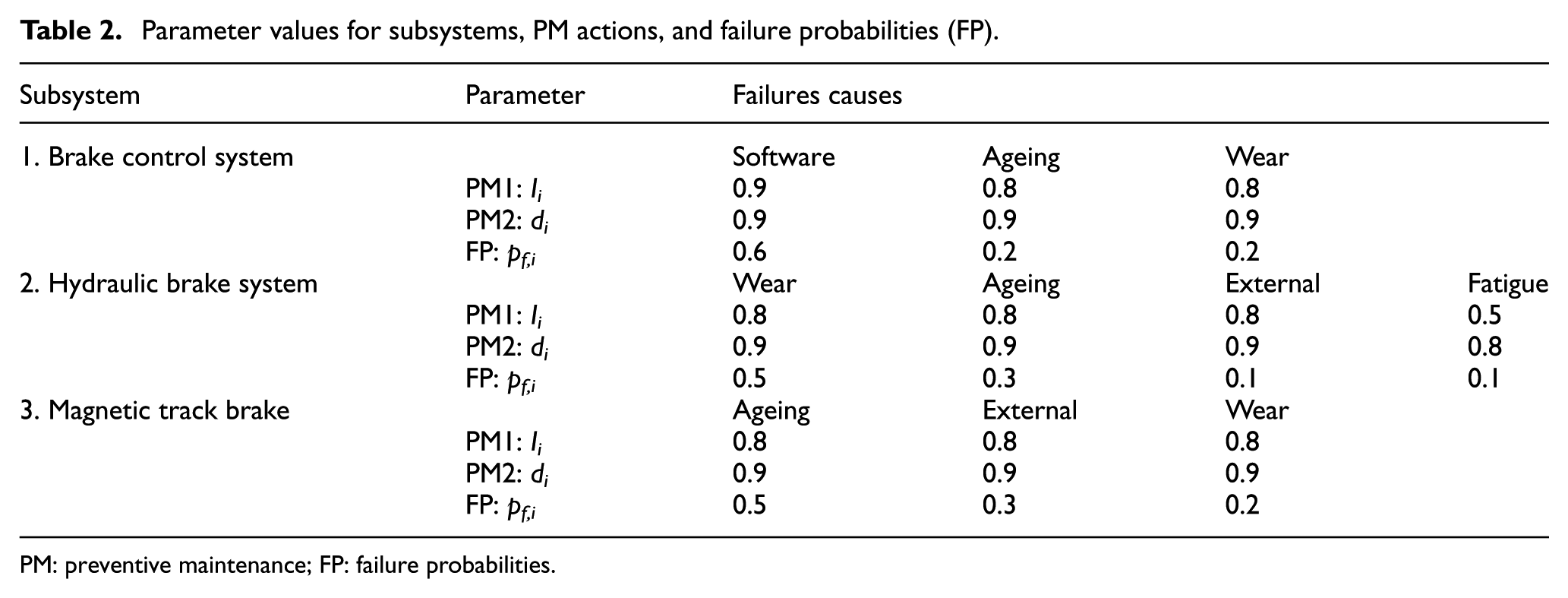
PM: preventive maintenance; FP: failure probabilities.
For each subsystem, we identified up to four common failure causes, which make up the majority of the failures and give the results of the failure cause analysis. We report in Table 2 the failure probability (as recorded in the CMMS) per cause and subsystem, and the estimated improvement factors associated with the PM actions, determined with help of maintenance experts from HTM. Here, m1 can be computed as the improvement Ii to the operational condition of each subsystem, due to PM1 actions; m2 is defined as the repair success rate di of PM2 actions.
PM model
We can finally determine the link between maintenance intervals and performance indicators: total costs, availability, and reliability. The total cost at system level, due to maintenance actions Cs,j in the jth PM interval depends on the sum of PM cost Cpm and Corrective maintenance (CM) cost Ccm
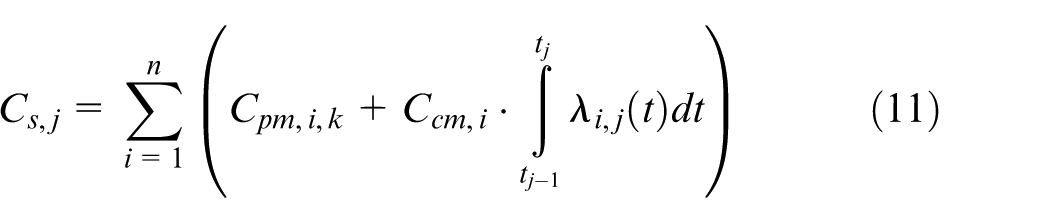
The components of equation (11) that are related to costs are defined using the CMMS system by deriving the internal hourly rates and spare parts costs.
Based on the expression of reliability in equations (8), (10), and (11), and the structure of the SC, different intervals tp,I are associated to different subsystems, as they have independent, unrelated failure rate. For each subsystem, the smallest optimal subsystem-level interval tp,i, based on maximizing the availability y, is:
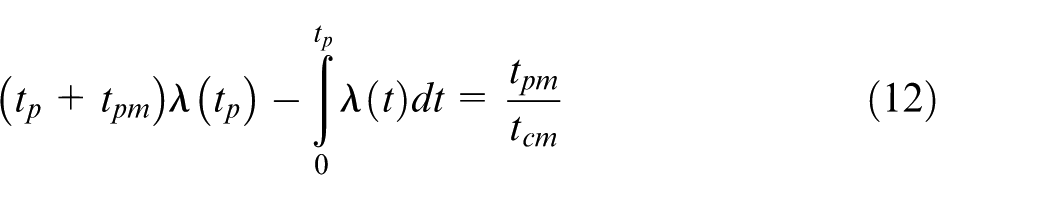
The optimal interval T which allows to keep availability always above the threshold can then be assumed to be the smallest of them, that is, T = tp = min i {tp,I} Subsystems i with tp,i = T receive maintenance at any maintenance interval; those with tp,i > T receive maintenance when the reliability would decrease below the minimum acceptable reliability Rmin within a time interval T, that is, before the next planned maintenance action. At any maintenance interval, the type of PM actions will be selected by means of a maintenance benefit function Bi,k. For the jth PM interval, benefit Bi,k is defined as the ratio between the reliability improvement and the cost involved
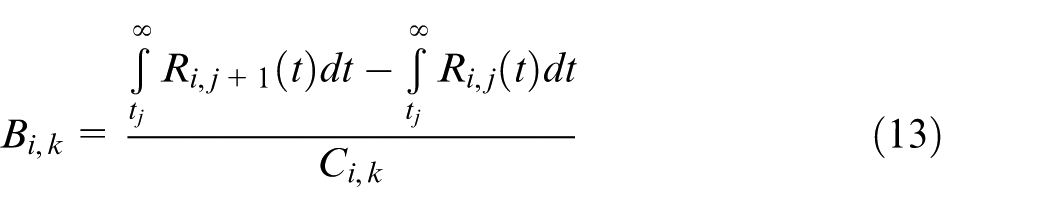
The availability of the system can be expressed as in equation (7). To this end, we need to define the maintenance times associated with PM1, PM2, and PM3 and with the corrective maintenance actions. The mean downtime (MDT) due to PM, related to a given maintenance interval T, is defined as
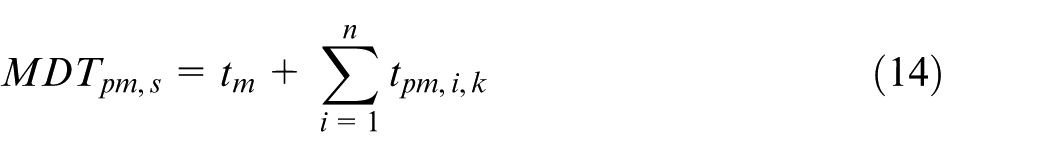
where tm is the time required for the (overall) system-level maintenance, and tpm,i,k is the time required to perform PM action k on subsystem i for all n subsystems.
The values of PM times tpm,i,k and tm in equation (14) are derived from the planning module in the CMMS system and verified by the maintenance engineer. The values of CM times (see equation (10)) are also derived from the CMMS system: tcm,i,m mean repair time for subsystem i; tdt, extra downtime due to failure of system I together with the extra downtime includes the time required to evacuate passengers (if applicable), transfer of the vehicle to the depot, and waiting time for repair.
Tsai et al. 3 define the minimum reliability at the system level; while we define the minimum reliability at subsystem level and as a function of the risk associated with the failure of the subsystem. The risk of failure is calculated by relating the probability of occurrence with the impact on corporate objectives. Combining the calculated risk values with the minimum reliability, which is set by company policies to 0.85, the minimum reliability of each subsystem was calculated. The AGREE method is used, as presented in equation (7). The values of the system probability failure due to a specific subsystem can also be derived from CMMS: those are, respectively, 0.42, 0.44 and 0.14 for the brake control system, the hydraulic brake system, and the magnetic track brake.
Maintenance interval optimization
The optimization of the maintenance policy relates to choosing the interval of maintenance between maintenance stages j and the most beneficial maintenance action k for subsystem i in stage j. For maximizing overall availability, Tsai et al. 3 determine analytically the minimum maintenance interval in the multi-component setting. The minimum interval drives the all maintenance process, based on some economic/structural dependence. 25 We remark that this approach is inapplicable in the system considered, as no explicit check of subsystem reliability is performed. Moreover, for the other performance indicators, a closed-form solution is not easy to derive. We thus resort on a simple sequential optimization approach to determine simultaneously maintenance interval and maintenance actions along time. The key problem investigated is the precise determination of the sequence of maintenance actions to be performed in a PM scheme, that is, when to perform which maintenance action, based on a set of performance indicators.
The algorithm is shown in Figure 2. The possible time intervals for maintenance (time_interval) are scanned in sequence within a range {min_time_interval; max_time_interval}. Given a time interval, the timing of PM maintenance is given. To determine the actions chosen, for all stages j until the expected end of life of the system, we determine the required and potential maintenance actions. The required maintenance actions are those that are required as the current reliability is below the threshold. Note that there is a substantial difference with the approach of Tsai et al., 3 where there is no minimum reliability setting prescribed. In the case when the most beneficial maintenance action k does not improve the reliability of the system to the minimum required level, the next best k is selected, which allows reaching the target reliability. The potential maintenance actions are those which would not be required at current stage j, but would be required between the current maintenance stage j and the next one j + 1. For those, the benefit function as in equation (13) is used.

Pseudocode of the optimization approach.
The reliability, availability, and the costs are then assessed at system level. The time_interval which leads to the minimum costs, maximum availability, or maximum reliability is, respectively, selected. As final output of the optimization model, the sequence of maintenance actions is outputted, as well as the evolution of the performance indicators over time. The model is implemented in MATLAB R2014b and reports quickly the optimal maintenance interval, as well as the sequence of maintenance actions. Depending on the amount of intervals evaluated, the entire optimization takes between 5 and 45 min of computation time on a standard computer.
Model validation and sensitivity analysis
To validate the PM model of section ‘PM model’, a benchmark PM model was created by setting the system-level maintenance interval T to match the current maintenance policy together with all other input parameters. The resulting availability, PM cost, and CM cost compared favourably with the data extracted from the records (Table 3).
Relative difference in availability, PM cost, and CM cost between the calculated and recorded values.
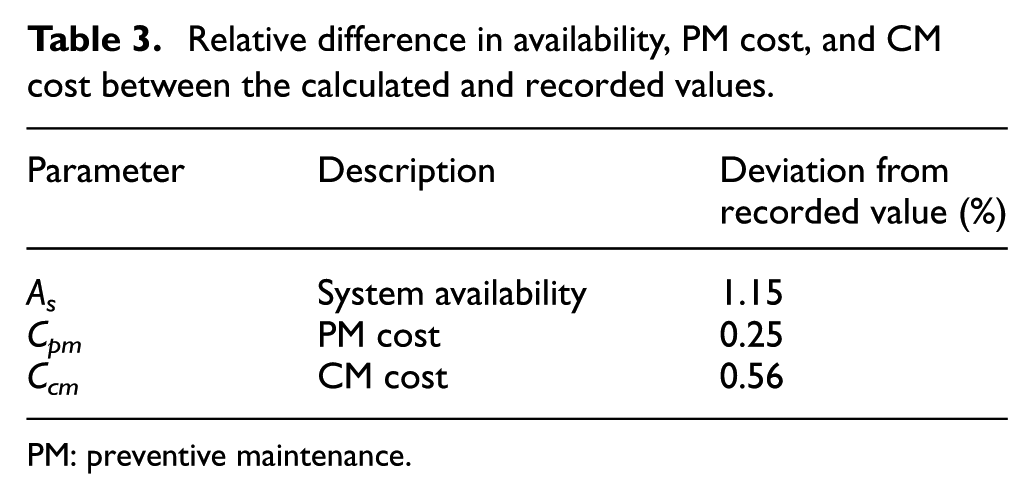
PM: preventive maintenance.
To determine the impact of changes, uncertainties, and error in estimation in the input parameters on the output of the model, we have performed a sensitivity analysis. Precisely, we evaluated the influence of the improvement factors (m1 and m2), maintenance times (tpm and tcm), maintenance costs (Ccm and Cpm), and minimum reliability (Rmin) on the resulting availability and total maintenance costs. Table 4 gives an overview of the input parameters with their low and high values that are included in the sensitivity analysis. Both low and high values are selected in such a way that they represent the 90% confidence interval for the specific parameter. Note that the high values of parameters such as improvement factors and minimum reliability parameters are limited to a maximum value of 1.
Parameters and variations considered in the sensitivity analysis.
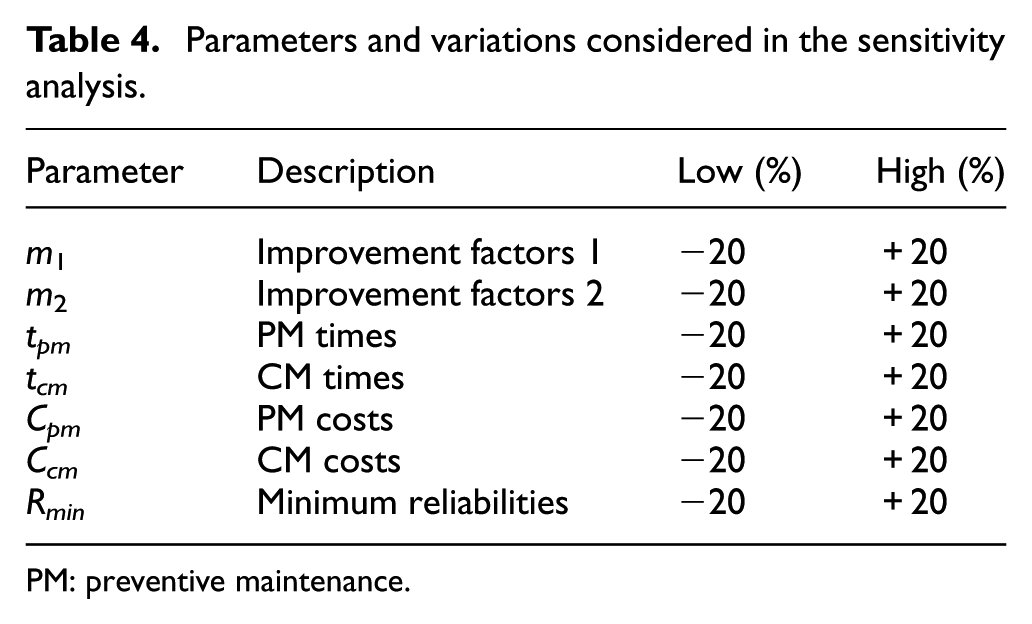
PM: preventive maintenance.
The sensitivity analyses for availability and total maintenance costs are reported as tornado charts in Figure 3. The reference value of output parameters is given by the vertical axis. The blue/red bars represent the output parameter value for the low/high input parameter values, respectively.
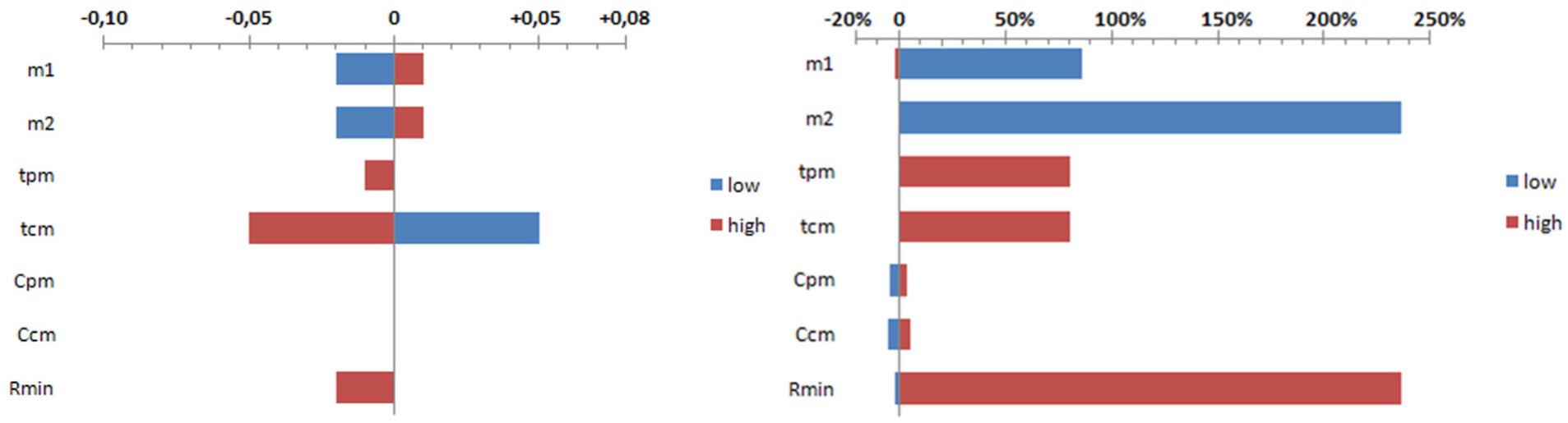
Model sensitivity: availability (left) and maintenance costs (right), in percentage of base case.
Looking at the results of sensitivity analysis for availability, it can be observed that tcm has the highest influence on the availability. While this was not surprising, it was a surprise to see how strong the influence of improvement factors on the total costs is. If improvement factors were to be lower, then a higher level of PM actions is required to ensure the minimum reliability. An expert check on the interval derived confirmed the validity of the model.
Results and discussion
Results
We determine quantitatively the best maintenance intervals and their impact to the company objectives and the results correspond to the general intuition. Figure 4 shows how the maintenance interval has significant impact on the PM costs. The costs and intervals are reported scaled down to the benchmark policy currently implemented. Looking only at PM costs, the minimum is found for a maintenance interval which is about 90% longer. Even though a reduction of the maintenance interval significantly increases the reliability of the system, it also increases the PM cost (and reduces the availability, due to the continuous maintenance visits). This relationship is rather regular. A similar behaviour in cost increase is found, much stronger, for long maintenance intervals. After a certain threshold, PM costs jump significantly because high-level PM actions are required to recover the system to the desired reliability levels, and high-level PM actions yield higher maintenance costs. The erratic behaviour for very long maintenance intervals is due to the interaction of failures and the extensive repairs needed when maintenance is performed.
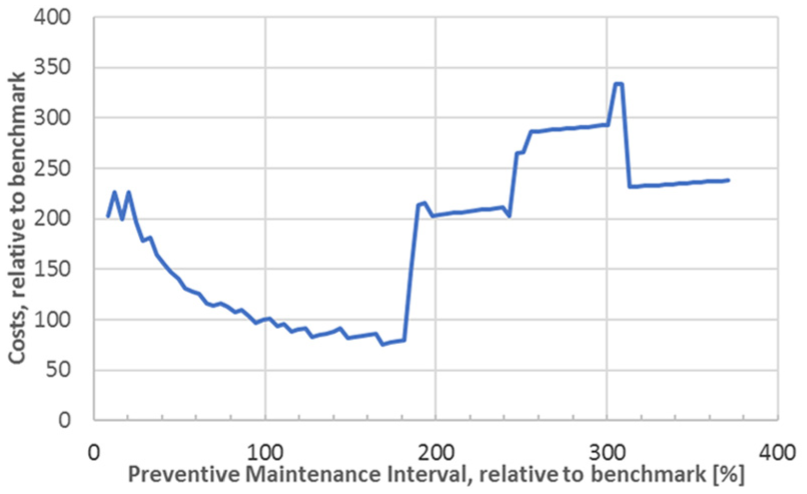
Total maintenance cost as a function of the maintenance interval, relative to the benchmark.
We now discuss the relationship between maintenance intervals and the performance indicators. Figure 5 shows the relation between maintenance intervals and reliability. The maintenance interval is reported relative to the benchmark, while the reliability is reported in absolute number. Two curves are plotted: the one reporting the mean reliability given a maintenance interval (Rs,mean, blue solid line) and the one reporting the minimum reliability given a maintenance interval (Rs,min, red dotted line).
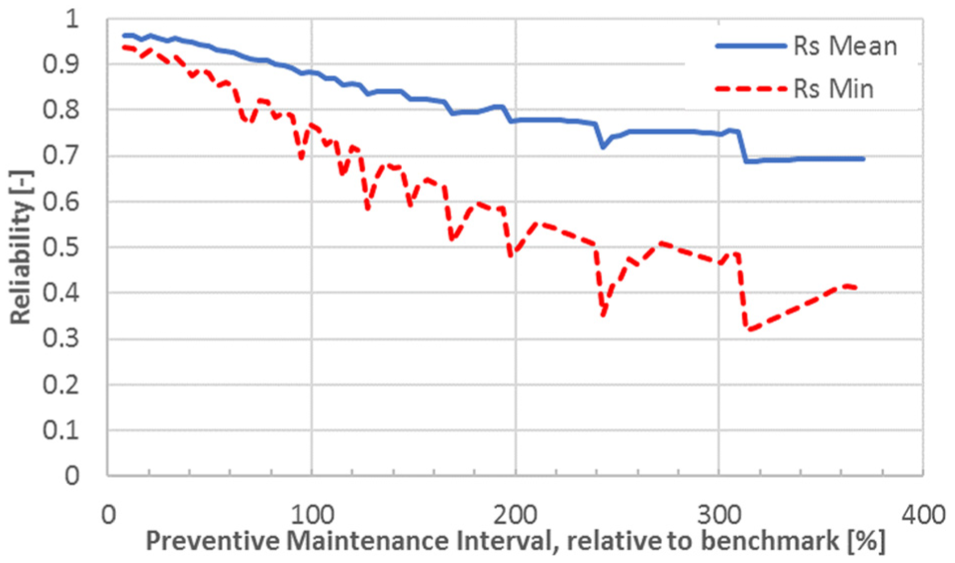
System-level reliability as a function of the maintenance interval.
It is evident from the figure how the Rs,min drops at a higher rate than the Rs,mean, since reliability before maintenance is directly decreasing with longer maintenance intervals, while the reliability after maintenance is roughly the same, after the PM actions are performed. Overall, high minimum reliability requirements are associated to a smaller maintenance interval, and therefore, increased maintenance cost of the system.
Figure 6 reports on direct connections between reliability, availability, and costs. Allowing the subsystem reliability to drop significantly below the minimum reliability Rmin prescribed by the key performance indicators results in high PM cost. In this case, the only feasible PM action is PM3, which is the most expensive maintenance action. However, the maintenance cost rapidly increases when the minimum system reliability requirements exceed 0.85. The minimum costs, within the feasible range of intervals, correspond to a smaller reliability, as shown in Figure 6 (top). The resulting maintenance policy is very similar to the availability driven policy, in terms of maintenance interval. Figure 6 (bottom) shows the relation between minimum reliability and availability of the system. A rapid decrease in availability is observed when the minimum system reliability requirements exceed 0.85. This corresponds to increased system downtime due to short maintenance intervals. The availability of the current benchmark solution is the lowest, before the sharp increase in reliability. This is one of the motivations for choosing a different, optimized, maintenance interval.
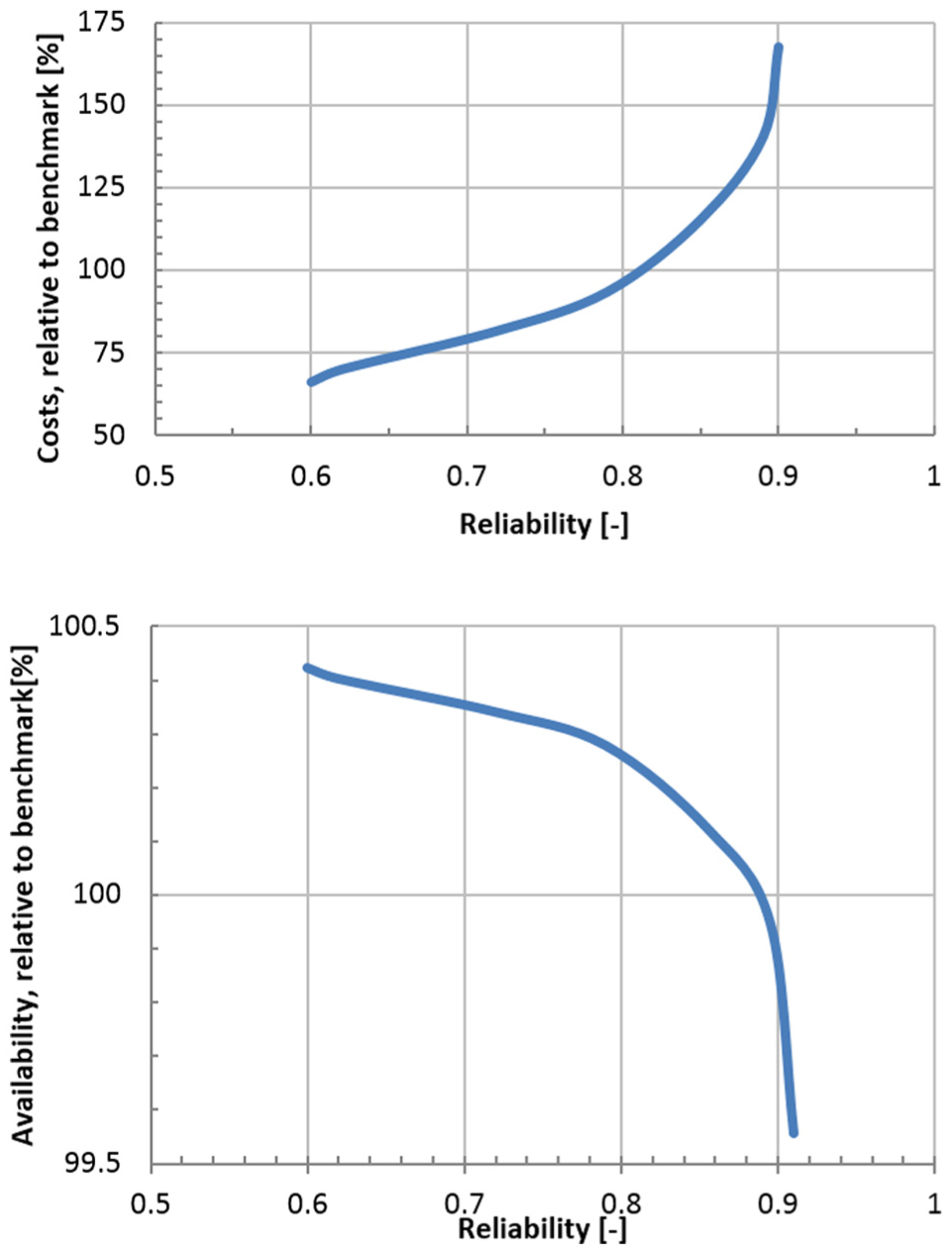
Relative maintenance cost (top) and relative availability (bottom) as a function of the minimum reliability for maintenance intervals between 30% and 180% of the benchmark interval.
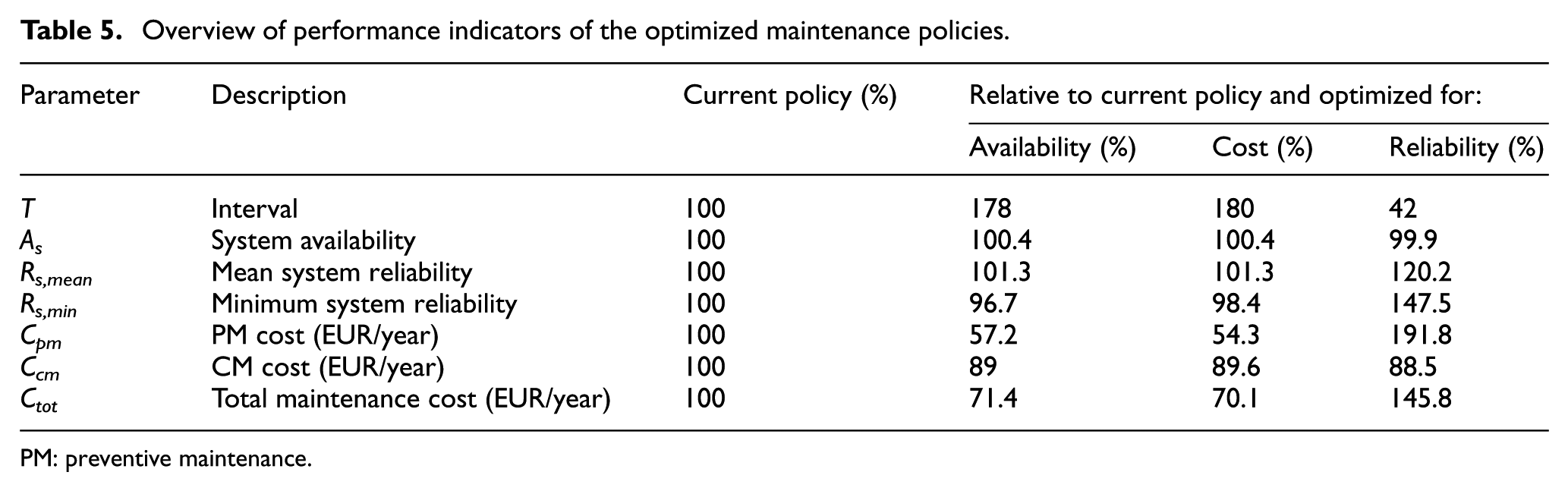
The results in the previous sections show that the total maintenance cost and system availability are highly dependent upon the minimum reliability requirements of the system. Both availability and cost driven maintenance policies allow the reliability of the system to drop below the accepted minimum. Table 5 gives the values of the key parameters for the availability-, cost-, and reliability-driven maintenance policies, relative to the current situation.
Overview of performance indicators of the optimized maintenance policies.
PM: preventive maintenance.
Discussion
Compared with the benchmark figures of the current policy, both availability and cost driven maintenance policies show a potential maintenance cost reduction of 30%. They moreover maximize the system availability without sacrificing the current mean and minimum reliability; the maintenance intervals are almost 100% longer. The reliability-driven maintenance policy shows a potential increase of 20% in average system reliability and 48% of the minimum system reliability, without compromising the availability of the system or raising the total maintenance cost significantly. Increasing the reliability is related to achieve higher customer satisfaction. Interesting directions for integral assessment of maintenance in transport systems direct towards the level of service, by means of quantifying uncertain travel time and delay in operations 28 or in evaluating the societal costs of delay as perceived by the different users.
A key feature of the system is the strong relation between a reduction in the time required for maintenance (related to workforce employed, and quality of maintenance actions) and an improved availability of the system. Quality of maintenance actions is very important: the cost increase due to reduction of m2 (the improvement factor of maintenance) is equivalent to the cost increase associated with reliability increase. While quality assurance of PM actions is difficult, it is usually even more difficult to increase system’s reliability. The imperfect repair action PM2 has also a strong influence on the maintenance costs and needs to be quantified carefully. Further steps should investigate the possibility of identifying parameters of concurrent processes (such as failure/condition degradation and maintenance/condition improvement) from the data, possibly suggesting new data to be acquired. We also believe that analysis of the sensitivity of the reliability and the costs gives insights on the confidence bound of the expert values which are currently used. In fact, the high sensitivity to parameters m1 and m2 means it is relatively easy to calibrate those values based on the recorded costs.
Conclusion and recommendations
This article describes a case study of optimized maintenance policy for a light rail braking system, achieving great insight using readily available work order data, synthesizing the approach from few separated works in the reliability literature. We use a data-driven approach to determine the failure rates for a specific subsystem, integrate this into a maintenance model relating maintenance actions and improvements. We perform an exhaustive optimization to find the best maintenance policy based on reliability, availability, and maintenance cost. We found that focusing on availability and cost, the reliability of the system would drop below the accepted minimum, but allowing for substantial cost savings. The maintenance policy based on reliability proves improves reliability significantly without increasing the maintenance cost, compared to the benchmark situation currently performed. In general, extending maintenance intervals needs to be done carefully because maintenance costs are discontinuous and have sudden jumps.
We recommend exploring further possibilities to optimize the maintenance intervals based on multi-component optimization, which could then expand beyond the braking system and encompass multiple systems with more complex economic/structural dependence.29,30 This would result in more complex expressions of failure rates, an expression of reliability, availability dependent on more processes. Finally, optimizing the PM interval for such a situation would need agreement between systems, severity of the failure of the different systems, and availability of different workforce for performing the required check/maintain operations. We did an exploratory step in this direction towards multi-component systems given in Haans. 31 The maintenance interval could be further optimized by some combinatorial optimization methods. 32 In our work, we used an exhaustive numerical optimization approach where we investigated maintenance actions for specific maintenance intervals. The computation time is acceptable for the current setup, but might require more sophisticated approaches with more complex systems. As the maintenance time has been evaluated as crucial with regard to availability of the system, the workshop capacity could be studied more in detail. The company showed extreme interest in the theoretical work here described, which has been picked up by maintenance managers in their vision. A (gradual) path towards implementation of the PM policy is therefore a very interesting idea.
Footnotes
Appendix 1
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.