
Abstract
Multiple-object tracking (MOT) involves monitoring the positions of multiple targets as they move among identical distractors. Pylyshyn proposed that the mechanisms employed to track targets in MOT are also integral to coordinated actions. In support of this, previous research demonstrates that MOT and visually guided touch interfere with one another. However, in these early studies, reporting the MOT targets at the end of the trial involved touching them, making it unclear whether interference reflected competition for a shared limited-capacity item individuation mechanism or similarity in the motor responses required by the two tasks. To address this issue, we had participants touch items that changed colour during MOT with the index finger of their dominant hand and manipulated how participants later reported MOT targets at the end of the trial. We compared performance when participants reported MOT targets by touching them with the index finger of their dominant hand with that when they identified targets verbally or by typing them in. Two findings emerged. Firstly, the target report method had an effect on the size of the difference between single- and dual-task performance (general interference). Secondly, the target report method had no effect on differential interference (the size of the dual-task performance advantage when participants touched targets rather than distractors during MOT). The dissociation between the effects of target report on general and differential interference suggest these two types of interference reflect different processes. This research has implications for those who study the formation of action plans.
Introduction
Whether turning left at a busy intersection or playing team sports, many tasks in daily life require keeping track of the positions of several moving items among others. These dynamic visual environments can be studied in the laboratory using the multiple-object tracking (MOT) task, which involves selecting several target items and keeping track of their positions as they move among identical distractors (Pylyshyn & Storm, 1988). Because the targets in the MOT task appear identical to the distractors and change locations, the visual system needs some mechanism for individuating, selecting and tracking the targets to distinguish them from the distractors. Pylyshyn (1989, 2001) proposed that the cognitive mechanisms necessary for keeping track of the locations of targets in MOT are used more generally for visually guided actions such as pointing or touching items. However, to date, few studies have tested this assumption. One way to investigate this potential shared mechanism is to employ a dual-task methodology where participants carry out an MOT task while touching any items that change colour (a task that requires visually guided action). Importantly, in dual-task studies, interference may emerge for a variety of reasons. Interference may occur because the two tasks compete for limited perceptual resources, though it could also reflect the demands of coordinating two different motor responses (one for touching items that changed colour and another for reporting MOT targets). The present study was designed to distinguish which of these two factors produced the interference between MOT and visually guided action. To accomplish this goal, we manipulated the way participants reported the identity of the MOT targets at the end of the trial. We then measured performance in both tasks: MOT performance as the percentage of correctly reported targets, and touch performance as latencies to touch items in MOT that changed colour. In the sections that follow, we will first consider research on MOT and then discuss an experiment designed to determine how MOT target report methods affect performance.
Pylyshyn and Storm (1988) performed the first MOT study and since their initial investigation researchers continue to employ the MOT task to study sustained visual attention in moving displays. A typical trial in the MOT task involves the following stages. Firstly, a display of randomly positioned identical items appears on screen (e.g. 10 circles). Then, during the target assignment phase, a subset of the items briefly flash to indicate they are targets (e.g. 1–4 circles). Following this, the targets stop flashing, making them identical to the non-targets (distractors) once again. Then the item motion phase begins, in which all of the items (targets and distractors) move randomly and independently of one another, shifting so rapidly and erratically that it would be impossible to check the items one at a time with the attentional focus (Alvarez & Franconeri, 2007). Typically, this period of item motion lasts 8 to 10 s. Finally, item motion stops and participants report the positions of the targets. Performance in the MOT task is often measured as the percentage of targets that are correctly identified during the report phase at the end of the trial.
Based on the results of these early MOT studies, Pylyshyn and Storm (1988) concluded that young adults are capable of tracking 4 to 5 independent targets at once, though performance began to decline once there were 5 or more targets. Though a number of different explanations for MOT have been proposed, Pylyshyn (1989) proposed that this ability relies on a limited-capacity individuation mechanism that works by assigning spatial indexes called FINSTs (for FINgers of INSTantiation), to each of a small number of targets. These indexes are “sticky” and stay with their assigned targets as they move, making it possible to perceive a target as the “same one” across changes in position and appearance.
In a world where items constantly move, directing and “landing” an action on a specific item among others requires a way to refer to the item that is independent of its properties and position. Thus, visually guided action necessitates some way to “individuate” selected items (targets), treating them as individuals, distinguished from even identical others. Pylyshyn proposed that the spatial indexes used in MOT are also used to “pass” the current locations of selected items to motor programmes to direct visually guided actions such as pointing and touching. In other words, this would mean that the same spatial indexes used in MOT are also used in visually guided touch. However, the implications of Pylyshyn’s core idea, the idea that MOT involves the same item individuation system as visually guided touch, have yet to be fully explored.
Nonetheless, since Pylyshyn’s initial account, a number of other theories have emerged to account for how participants can simultaneously track multiple moving objects. For example, Yantis (1992) proposed that MOT involves a grouping process whereby targets are surrounded by a mental elastic boundary, which permits the individual targets to be tracked as a single group. Evidence from a variety of dual-task studies show that attention-demanding secondary tasks interfere with tracking (Allen et al., 2004; Howard et al., 2020; Kunar et al., 2008; Lochner & Trick, 2014). This suggests MOT requires attention and a number have concluded that the reason that participants can distinguish targets from distractors in an MOT task has to do with attention. For example, according to multifocal attention theory (Cavanagh & Alvarez, 2005) each MOT target has its own attentional focus, though this theory also suggests there is fixed limit to the number of targets that can be tracked (a fixed number of foci). Others, perhaps inspired by evidence that suggests that the tracking capacity can vary based on the item speed and item density (Alvarez & Franconeri, 2007, Franconeri et al. 2008; Holcombe & Chen, 2012), suggest that MOT is supported by a flexible resource limited attentional mechanism (e.g. the FLEX model: Alvarez & Franconeri, 2007; spatial interference theory: Franconeri et al., 2010). According to these models, the number of items that can be tracked simultaneously varies based on the attentional demands of the task. Given the variety of theories, there remains debate about the specific mechanisms that support MOT. In light of this, we focus primarily on Pylyshyn’s FINST theory because it is, to our knowledge, the only theory that discusses and makes clear predictions about there being a special and integral relationship between MOT and visually guided touch (Pylyshyn, 2001).
However, historically there has been research on goal-directed action that highlights links between perceptual selection and the preparation of motor responses. In this literature, a relationship between action and attention has long been predicted (e.g. selection-for-action hypothesis: Allport, 1987), with some theories even suggesting that attention and action are controlled by the same mechanism (theory of event coding: Hommel et al., 2001; premotor theory: Rizzolatti et al., 1987). Generally, these frameworks propose that when a person prepares an action, an integrated representation is formed that binds together the perceptual features of the stimulus (e.g. its location) with the features of the intended response (e.g. which effector will be used, the anticipated outcome). Importantly, even small differences in these features can influence how easily two responses can be coordinated. To date, this work has largely examined single-target static displays, though visually guided action in daily life involves selecting and acting on many items that move. Thus, coordinating actions to moving objects requires some sort of object-based form of reference, as moving objects change spatial locations and visual similarity may prevent them from being distinguishable by their features (see also Scholl, 2001). Taken together, these factors underscore the need to study visually guided touch in the context of tasks such as MOT.
One way to investigate the relationship between two tasks is by using a dual-task methodology, in which performance is compared when two tasks are carried out concurrently (dual-task) to when they are carried out separately (single-task). When dual-task performance is worse than single-task performance, the tasks are said to interfere with one another. For example, messages are typically typed more quickly and with fewer errors when texting on the couch (single-task) as compared to texting while walking (dual-task). Walking interferes with typing. Similarly, telephone conversation interferes with tracking, for example (Kunar et al., 2008). The degree to which the tasks interfere with one another is dependent on the degree to which they rely on a specific and shared limited-capacity resource (Tombu & Jolicœur, 2003). Most deliberate cognitive tasks require attention, and attention is thought to be limited. Thus, there is broad agreement that the reason that dual-task performance is worse than single-task performance is that when two tasks are performed together, each task receives less attention (Allen et al., 2004; Howard et al., 2020; Kunar et al., 2008).
If the two tasks rely on a specific, limited-capacity mechanism then there is reason to expect interference between the two tasks beyond general interference (i.e. differential interference). For example, Terry and Trick (2021) found that MOT interfered differentially with visually guided touch. Participants in their study carried out two independent tasks: MOT while touching any item in MOT that changed colour. As expected, when performing two attentionally demanding tasks, results of their study indicated general interference: overall dual-task performance was worse than single-task. MOT accuracy was lower and latencies to touch items that changed colour were higher when participants performed both tasks concurrently than when they did each task separately. However, there was also evidence of differential interference, suggesting that the two tasks might rely on a shared, limited capacity resource. MOT accuracy was higher and latencies to touch items that changed colour were lower when participants touched targets in MOT during the motion phase rather than distractors. Terry and Trick (2021) interpreted their findings in terms of Pylyshyn’s theory, specifically the idea that the spatial indexes used to individuate targets in the MOT task are also used when participants touch specific items among others in a dynamic scene. According to this interpretation, MOT performance was worse when participants touched distractors rather than targets because touching an item causes it to be assigned a spatial index, and when the touched item is a distractor, MOT accuracy is reduced because the distractor is confused for a target.
Pylyshyn’s account also explains why latencies to touch items that change colour are slower when the item is a distractor in MOT rather than a target. Because distractors do not have an existing spatial index, distractors must first be “found” in the display and then assigned a spatial index, a process that takes additional time. In contrast, MOT targets already have a spatial index which allows their location to be accessed directly. Nonetheless, the observed pattern of results may arise for reasons unrelated to target individuation. In Terry and Trick (2021), participants touched items that changed colour during the item motion phase and later touched items to report targets at the end of the trial. Because the same motor response was used for both tasks, it is possible that the observed differential interference is an artefact produced by the similarity in the motor responses required for each task rather than a shared individuation mechanism. Dual-task studies often show greater interference when the motor requirements of the two tasks are similar to one another, and indeed Wickens’ (2002) multiple resource attention theory proposes different attentional resources for different types of response (e.g. manual responses vs. vocal responses). From this perspective, dual-task interference should be reduced when the MOT targets are reported vocally rather than through an additional manual action.
To investigate this idea, in the present study, we manipulated the method used to report MOT targets at the end of the trial. In one condition, participants reported MOT targets by touching them, as in Terry and Trick (2021). In the other, letters were projected on all the items once item motion stopped, and participants named the letters associated with the targets. If the previously observed differential interference was an artifact of the similarity between the two manual responses, the differential interference should disappear when participants reported targets vocally, as a vocal response does not share motor overlap with touching a specific item.
However, one complication is that these two report methods (touch report, vocal report) differ in their complexity. In the touch report condition, participants simply touched the items they believed to be targets. In the vocal report condition, by contrast, participants had to read the letters and vocalize which letters were associated with the target locations. Although participants can report the targets at their leisure, the vocal report condition is more complex as it introduces additional processing steps. Because differences in report complexity could influence dual-task interference, a third condition was brought in as a partial control from Terry et al. (2023). Terry et al. (2023) used exactly the same displays and tasks as in the present study, but rather than vocalizing letters, participants typed in the letters associated with the targets using the index finger of the opposite hand that was used to touch items that changed colour. If manual responses compete for the same attentional resources, there should be significantly more general interference when participants typed in the letters associated with targets manually rather than when they vocalized them.
Thus, to summarize, according to Pylyshyn’s spatial index theory, differential interference should emerge whenever participants touch items while tracking, regardless of how participants report MOT targets. Because MOT targets are assigned spatial indexes, their locations can be accessed directly resulting in faster touch latencies and better MOT performance for targets than for distractors in MOT, as targets must first be individuated. Based on Pylyshyn’s account, there is no reason to expect that there would be a relationship between general (dual-task) interference and differential interference because the two types of interference are produced by different mechanisms.
A second possibility, the response overlap account, predicts that the differential interference reflects the degree of overlap between responses required for the two tasks. Touch-based reporting requires the same type of manual response used during the motion phase, whereas vocal and typed reporting do not. From this perspective, differential interference should be the strongest for touch-based reporting and minimal when targets are identified verbally. According to Wickens (2002), there is more competition for attention when two operations involve the same type of response (e.g. a manual response). Thus, when participants report targets by pronouncing letters associated with targets there should be significantly less general interference than would occur when reporting targets in a way that required some sort of manual response (e.g. typing in letters associated with targets, touching the targets) See Table 1.
Summary of the target report methods used in the present study (Touch Report, Verbal Report) and the method used in a study being compared (Typing Report).
Methods
Design
MOT performance was measured in terms of accuracy and quantified as the percentage of MOT targets that were correctly reported (e.g. if 3 of 4 targets were reported correctly, the accuracy would be 75%). For the track + touch trials, we also measured latencies to touch items in MOT that changed colour, which was the time in milliseconds from when the item changed colour to when the participant touched it. The number of MOT targets to be tracked (1–4), the task load (track alone, track + touch), and the item that changed colour and was touched (target, distractor in MOT; nested within the track + touch condition) were all within-subjects factors. Target report method (touch, verbal) was the only between-subjects factor.
Participants
The experimental procedure was reviewed and approved by the University of Guelph Research Ethics Board (REB 19-01-011). Participants (n = 82) were recruited from the University of Guelph student participant pool and paid in course credit. Participants were randomly assigned to either the touch report condition (n = 42, Mage = 22.43, 29 females, 5 left-handed) or the verbal report condition (n = 40, Mage = 20.05, 35 females, 3 left-handed). This sample size was deemed adequate to detect the primary effect of interest based on a G*Power a priori power analysis that indicated that we would require 36 total participants (18 per group) to have adequate power (p = .95) to detect a target report method by task–load interaction on MOT accuracy. This was estimated using the following parameters: η2p = .09 for the interaction effect as found by Terry et al. (2023), α = .05, correlation among repeated measures = .50, and ε = 1. However, to ensure we were sufficiently powered to detect other secondary effects of interest, we aimed to collect 40 participants per target report group, as informed by prior similar work (Terry & Trick, 2021; Terry et al., 2023). All participants reported normal or corrected to normal vision at the time of data collection.
Apparatus, Stimuli, and Tasks
Participants completed the Catch the Spies variant of the MOT task (Trick et al., 2005) on a 15 × 20 cm iPad, seated 50 cm away. The goal was to keep track of the positions of one to four spies (targets) who had disguised themselves like regular people (happy faces: distractors). The MOT stimuli appeared on the iPad within a black rectangular tracking field that occupied a 22 × 17° visual angle. Each trial consisted of the same four phases: initialization, target assignment, item motion, and target report (see Figure 1). To start the trial, participants held the index finger of their dominant hand on the home box – a rectangle at the bottom of the screen occupying 1.72° × 3.44° visual angle. Following this, the initialization phase began, and 10 stationary green happy faces (1.50° visual angle) appeared at random locations within the tracking field. Next, was the target assignment phase, where one to four spies (1.49° visual angle) revealed themselves by flashing out from behind the green happy faces. This informed the participants of the happy faces that were to serve as targets in that trial (the items they needed to track). Once the target assignment phase was complete, the spies disappeared, so all that was left on the screen were 10 identical green happy faces. Following this, the motion phase began, where the 10 happy faces moved randomly and independently of one another for 10 s at an average speed of 2.3° per second. The happy faces would never occlude; instead, they bounced off the edges of the tracking field and each other.

Participants completed the track alone (A) and track + touch (B) conditions in a counterbalanced order. During the final target report phase, participants either reported targets by touching them or by saying the letters corresponding to the target locations.
In the single-task MOT (track alone) trials, the only task for the participants was to track targets (spies) and report their identity at the end of the trial. In this condition, none of the items changed colour during the item motion phase of the trial. 1 In the track alone trials, participants rested the index finger of their dominant hand on the home box throughout the item motion phase. In all conditions, the non-dominant hand was always placed comfortably away from the display. Target report began after the item motion stopped where participants reported the targets at their leisure. They were instructed to prioritize accuracy and were allowed to modify their answer if they felt they had made a mistake. Responses could be modified by touching the selected items to deselect them. Once they were satisfied, participants submitted their response. However, the specific technique participants used to report targets varied based on the condition. In the touch report condition, participants used the index finger of their dominant hand to touch each happy face they believed to be hiding a spy. In the verbal report condition, letters appeared on top of all the happy faces once the item motion stopped, and participants verbally stated the letters corresponding to the locations of the happy faces they believed to be hiding the spies. A research assistant used a keyboard to type the letters that the participant verbally stated. After participants submitted their target selection, the spies showed themselves providing feedback to the participants.
In the track + touch trials, participants tracked the MOT targets while also touching any of the items that changed colour during the item motion phase of the trial (before report). As in the track alone trials, participants began with the index finger of their dominant hand resting on the home key. However, in the track + touch trials, sometimes items changed colour. In the display of green happy faces, one would suddenly turn orange and remain orange until it was touched – at which time it would become green again. There was no way for participants to predict from trial to trial which items would change colour. Participants were instructed to use the index finger of their dominant hand to touch the item that changed from green to orange – and then return their finger to the home key as quicky as possible. Touch latencies were recorded as the time between the colour change and when the participant touched the item. Following Thornton and Horowitz (2015), we had several item colour changes per trial to ensure that participants remained focused on looking for colour changes among items throughout the item motion phase. The first colour change occurred 2 to 3 s after motion onset, and the second colour change occurred 6 to 7 s after motion onset. Consecutive changes occurred on the same type of item (target or distractor). To shorten the presentation, in this study only latencies for the first touch are reported because those are the most informative, and there was no danger of the same item being touched twice. 2
To ensure that participants were paying adequate attention to colour changes, trials were aborted and restarted if the participant failed to touch the item within 2 s of it changing colour. Moreover, if participants lifted their finger from the home box before the item changed colour or failed to return their finger to the home box immediately after each touch, the trial was aborted and restarted with a new item configuration. The report phase in the track + touch trials was the same as in the track alone trials. Item motion stopped and participants identified the items that they thought were targets (spies). Based on the condition that they were assigned to, participants either reported the MOT targets by touching them or by verbally naming the letters printed on the targets.
Procedure
Participants completed the task load blocks (track alone, track + touch) in a counterbalanced order. In the track alone block participants completed 4 practice trials and 32 test trials where the only task was to track the spies. In the track + touch block, they completed 8 practice trials and 64 test trials (8 repetitions × 2 item touched × 4 target numerosities). The study took approximately 1 hour to complete.
Results
This study involves an examination of dual-task interference between MOT and touching items that changed colour. This required analyses of two different dependent measures: MOT performance and the latencies to touch items that change colour. In the sections that follow, we start with an analysis of MOT accuracy and move on to the latency analysis. To clarify the presentation, we will present the results for each of the two dependent measures in the same order: first we will begin with the analyses of general interference and then move on to differential interference. Greenhouse–Geisser corrections were applied in cases of violations to the sphericity assumption throughout. Bonferroni tests were used for post-hoc comparisons.
MOT Accuracy (% of Correctly Reported Targets)
In dual-task studies, it is important to ensure participants are carrying out the primary task. Consequently, the MOT data were screened for atypical scores. Three participants’ data were excluded from analysis because their tracking performance was more than 2.5 standard deviations below the mean for other participants. This brought the total sample sizes down to n = 79 (touch report: n = 38, verbal report n = 41).
General Interference in MOT as a Function of Target Report
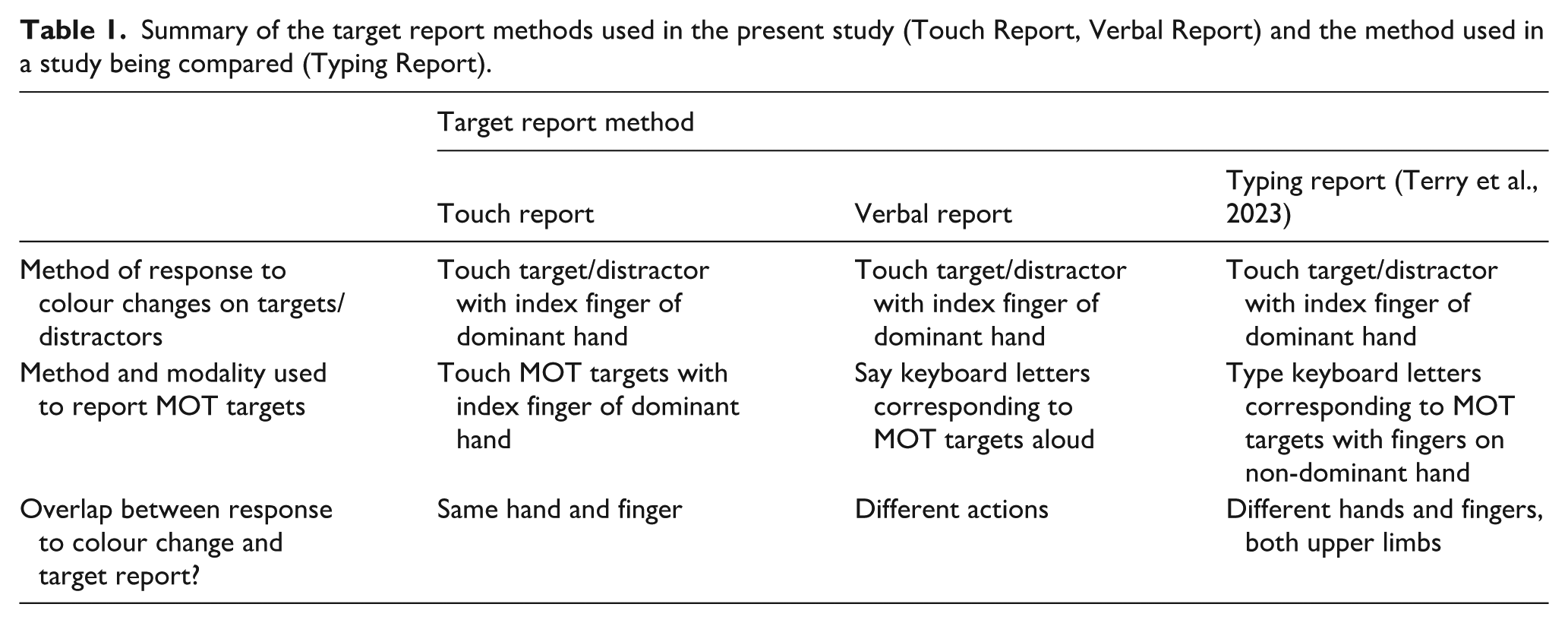
General interference was quantified as the magnitude of the difference between single- and dual-task performance. To ensure that the MOT task was sufficiently difficult and that results aligned with findings from past research, we started by analysing single-task MOT performance (the track alone condition). This involved investigating how MOT performance varied as a function of the number of targets to be tracked (1–4) and the way that targets were reported at the end of the trial (touch, verbal). As is typical in MOT studies, tracking accuracy decreased with increases in the number of targets to track (F[2.65, 203.72] = 32.55, p < .001, η2p = .30) with tracking performance comparable to that seen in other tracking studies. However, as can be seen from Figure 2, the target report method had no effect on MOT performance (F[1,77] = 0.13, p = .723, η2p = .00), and there was also no significant Target Report × Number of Targets interaction (F[2.65, 203.72] = 0.29, p = .805, η2p = .00). Thus, contrary to what might be expected from a multiple resource theory, single-task MOT performance was not significantly better when participants reported MOT targets verbally rather than by touching them (Mdiff = 0.22%). This result is consistent with Terry et al. (2023); in that it also found no difference in single-task MOT performance based on the way that targets were reported, although in that case the comparison was between touch report and typing in letters associated with the targets.
Mean percentage of multiple-object tracking targets correctly identified in the track alone condition as a function of the target report method (touch, verbal) and the number of targets to track (1–4). Target report method had no effect on tracking accuracy in the track alone condition. Error bars represent standard error.
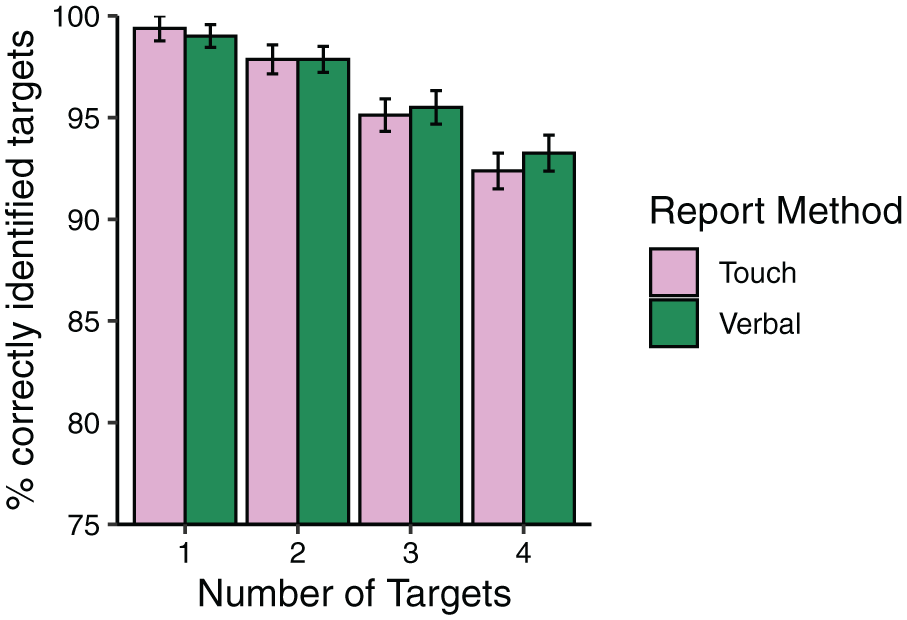
To assess general interference, was then analysed MOT accuracy as a function of the task load (track alone, track + touch), the number of targets to track (1–4), and the target report method (touch, verbal). As predicted, general interference emerged such that tracking performance was 6.11% worse in the track + touch conditions compared to the track alone condition, F(1,77) = 106.63, p < .001, η2p = .58. As always, the number of targets had an effect on MOT accuracy (F[2.44, 187.93] = 85.30, p < .001, η2p = .53). General interference increased with increases in the number of targets to track (number of targets × task load: F[2.95, 227.20] = 11.05, p < .001, η2p = .13, Bonferroni test of means: p < .01 for all). However, the amount of general interference was not significantly greater for the verbal report condition than the touch report condition (task load × target report method: F (1,77) = 2.21, p = .141, η2p = .03; Mdif = 1.76%; see Figure 3). Otherwise, there were no significant effects (target report method: F[1.00, 68.69] = 0.63, p = .432, η2p = .01; number of targets × target report method: F[2.44, 187.93] = 0.04, p = .978, η2p = .00; number of targets × task load × target report method: F[2.95, 227.20] = 0.93, p = .427, η2p = .01).
Mean percentage of multiple-object tracking (MOT) targets correctly identified as a function of the target report method (touch, verbal), the number of targets to track (1–4) and the task load (track alone, track + touch). General interference emerged in that tracking performance was 6.11% worse overall in the track + touch conditions than the track alone condition. The amount of general interference increased with increases in the number of targets to track but did not differ by target report method. Error bars represent standard error.
Thus, in the verbal report condition, when there was no overlap at all between the actions necessary for touching items and later reporting them, performance was comparable to that in the touch condition, when there was complete overlap between the two actions. The difference between the two conditions was only 1.76%, and not statistically significant. Furthermore, contrary to what might be expected based on Wickens’ (2002) multiple-resource theory, if anything there was slightly more interference in the verbal condition rather than less but this difference was negligible.
This finding also provides little support for the idea that the performance would suffer when participants had to report letters associated with targets. There was no difference in the amount of general (dual-task) interference between the verbal report and touch report conditions although the verbal report procedure was more complex. However, a comparison between the verbal report condition in this study and the typing report condition in Terry et al. (2023) revealed that there was slightly more interference when participants typed in letters associated with targets rather than pronouncing them, though this difference was minimal and not statistically significant (Mdiff = 1.78%; F[1,72] = 1.89, p = .173, η2p = .03).
Differential Interference in MOT as a Function of Target Report
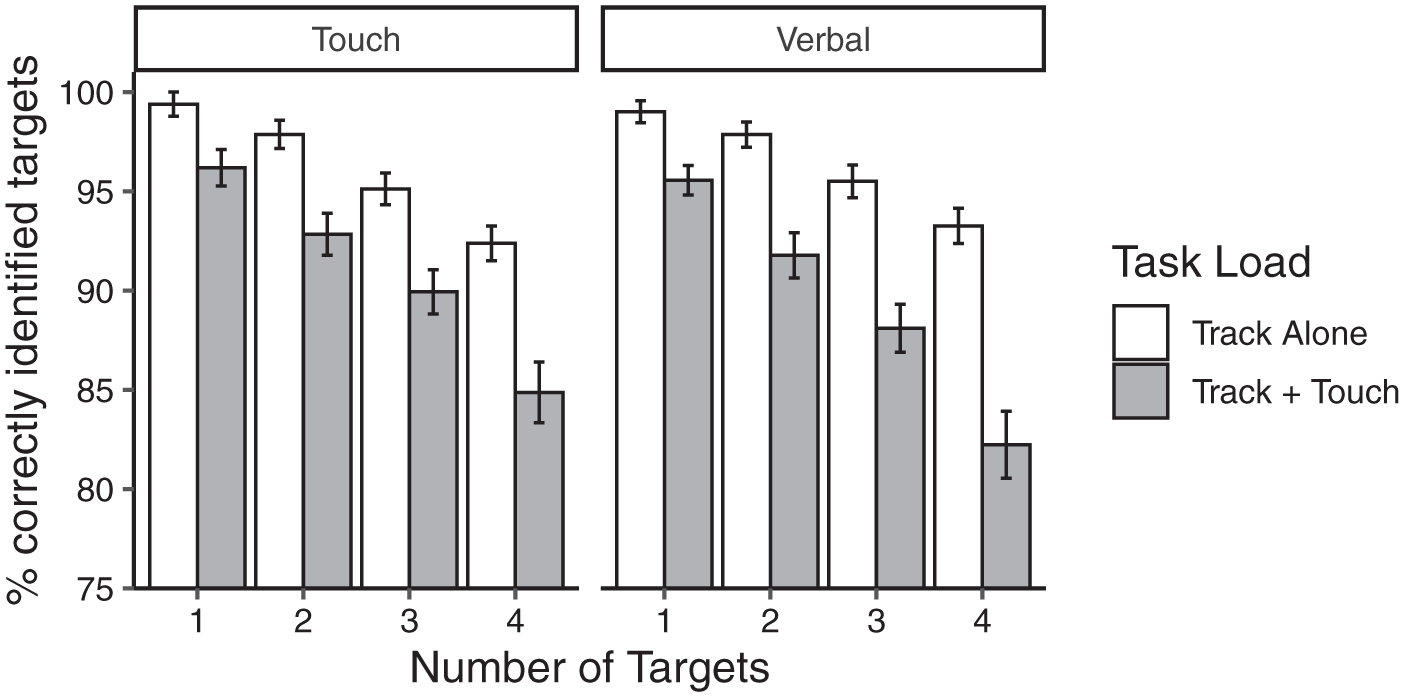
To investigate differential interference, we analysed MOT accuracy in the track + touch trials as a function of the item touched during tracking (target, distractor), the number of targets to track (1–4), and the target report method (touch, verbal). As in the previous studies (Terry & Trick, 2021, 2022; Terry et al., 2023) differential interference emerged: MOT accuracy was overall 5.72% worse when distractors in MOT were touched compared to targets (item touched: F[1,77] = 89.14, p < .001, η2p = .54); see Figure 4. However, contrary with what might be expected from the action overlap hypothesis, the amount of differential interference did not vary significantly based on the way that targets were reported (item touched × target report: (F[1,77] = 0.89, p = .350, η2p = .01). Moreover, there was also neither a main effect of target report method (F[1,74] = 0.29, p = .59, η2p = .00) nor any interactions involving target report method (number of target × target report: F[2.68, 206.20] = 0.48, p = .700, η2p = .01; number of targets × item reported × target report method: F[2.90, 223.45] = 0.02, p = .994, η2p = .00, respectively). As might be expected from the analyses of general interference, the number of targets had its usual effects on MOT accuracy (number of targets: F[2.68, 206.20] = 67.46, p < .001, η2p = .47), but it did not interact with other factors (number of targets × item touched: F[2.92, 223.45] = 1.96, p = .121, η2p = .03).
Mean percentage of multiple-object tracking (MOT) targets correctly identified as a function of the target report method (touch, verbal), the number of targets to track (1–4), and the item in MOT that changed colour and was touched (target, distractor): (A) across the number of targets to track and the target report method, MOT target report was always more accurate when participants touched targets in MOT during the tracking interval as compared to distractors, (B) while accuracy was overall higher when touching targets in MOT as compared to distractors, the difference between the target- and distractor-touch conditions remained consistent across target report method. Error bars represent standard error.
Thus, overall, these findings are consistent with those of Terry et al. (2023), who also found that the method used for reporting MOT targets had no effect on the amount of differential interference observed. These findings are more consistent with Pylyshyn’s spatial index interpretation for differential interference, suggesting that the advantage of the targets- over distractor-touch conditions is due to the competition for spatial indexes rather than the degree of overlap in the actions required for making the two motor responses.
Latencies to Touch the First Item That Changed Colour
Latencies to touch items that changed colour were also compared across touch report conditions. For the touch latency analyses, the data from an additional three participants had to be dropped because they had too few latencies that met the screening criteria for individual latencies. This reduced the sample size to n = 76 (touch report: n = 35, verbal report n = 41). The criteria for exclusion for individual touch latencies were as follows. Individual touch latencies for specific items were excluded if participants were incorrect about the identity of that item in the final target report (i.e. they confused a distractor for a target or vice versa). These individual latencies were excluded because the comparison of the target- and distractor-touch conditions was predicated on the assumption that the participants were truly considering the targets as targets and distractors as distractors when they touched them during the item motion phase of MOT. Latencies were also excluded if they were more than two standard deviations from the participant’s condition mean, representing an additional loss of 3.59% of the sample (177 touch latencies).
General Interference in Touch Latencies as a Function of Target Report
Earlier studies demonstrated that MOT interferes with touching items that change colour. This involved comparing single-task touch latencies (touch alone) to dual-task (touch + track) latencies (Terry & Trick, 2021, 2022). The results indicated that dual-task touch latencies were higher than single-task touch latencies. However, because we were specifically looking at the effect of MOT target report, it did not make sense to have a single-task touch condition. Instead, we simply analysed latencies in the touch + track condition, looking for differences between the verbal and touch report conditions. Latencies were analysed as a function of the target report method (verbal, touch) and the number of targets to be tracked (1–4). In the present study, latencies to touch items that changed colour were slightly higher when participants later reported MOT targets verbally rather than by touching them, but this difference was negligible and not statistically significant (Mdiff = 13.20 ms; F[1, 74] = 0.29, p = .592, η2p = .00).
Thus, in the present study, the target report method (verbal, touch) did not have a significant effect on touch latencies even though participants had to read letters before reporting them verbally. In contrast, Terry et al. (2023) found that touch latencies were significantly higher when participants later reported targets by typing in letters rather than touching the targets directly (M difference = 48 ms, p = .037). Together, these results suggest that the previously observed differences in general interference were unique to the demands of reporting the MOT targets by typing in the letters rather than reporting them verbally.
To follow-up this line of reasoning, we brought in data from the typing report condition from Terry et al. (2023) to compare with the verbal report condition in the present study. Using data from the track + touch condition from both studies, we analysed the latencies to touch items that changed colour as a function of the MOT target report method (typing, verbal), the number of targets in MOT (1–4), and the item touched (target, distractor in MOT). The results provided limited support for the idea that typing in letters associated with MOT targets increased the latencies to touch items that changed colour more than verbally pronouncing the letters. Although latencies to touch items that changed colour during the item motion phase of MOT were indeed higher when participants later reported the MOT targets by typing in the letters rather than verbalizing them (Mdiff = 42.80 ms), this difference was only marginally significant (F[1,69] = 2.57, p = .110, η2p = .04; Mtyping = 1,042.49 ms; Mverbal = 999.69 ms). Target report did not interact with any other factor in this analysis (p > .1); see Figure 5.
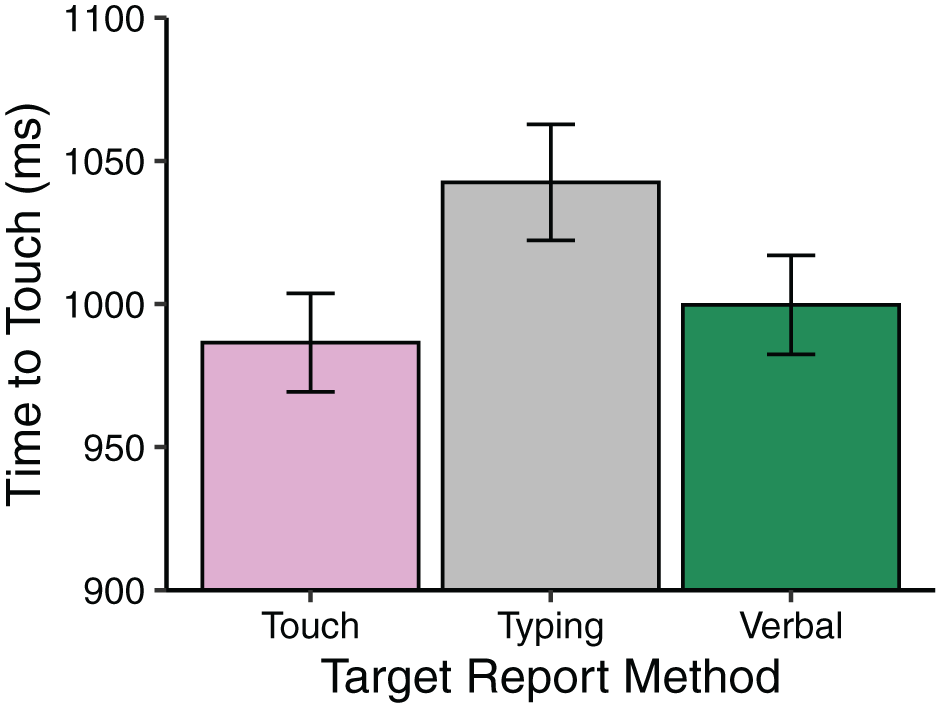
Mean time to touch items in multiple-object tracking (MOT) that changed colour (ms) as a function of the target report method (touch, typing, verbal). Touch latencies were overall faster when later reporting the targets by touching them as compared to typing in the letters, but there were no significant differences in touch latencies when comparing touch report and verbal report. The difference between the verbal and typing condition was only marginally significant (p = .11). Error bars represent standard error. *represent a significant mean difference.
Differential Interference in Touch Latencies as a Function of Target Report
For this analysis, the time to touch items that changed colour (ms) was measured as a function of the number of targets to track (1–4), the item touched (target, distractor), and the target report method (touch, verbal), see Figure 6. Differential interference emerged once again: the time to touch items that changed colour was on average 48 ms faster when targets in MOT were touched as compared to distractors, F(1,74) = 64.30, p < .001, η2p = .47. However, contrary to what might be expected given the action overlap hypothesis, the amount of differential interference did not vary based on the target report method (item touched × target report method: F[1,74] = 0.22, p = .644, η2p = .00). These results are consistent with those of Terry et al. (2023), who showed that the amount of differential interference did not vary based on whether touched items to report targets or typed them in. Similarly, in the present study, there was no difference in the amount of differential interference when the action overlap was maximal (the touch report condition) as compared to when it was minimal (the verbal report condition). This finding, combined with the MOT data discussed earlier, is most consistent with Pylyshyn’s spatial index theory, which suggests that the differential interference is the result of competition for spatial indexes and action overlap between different responses.
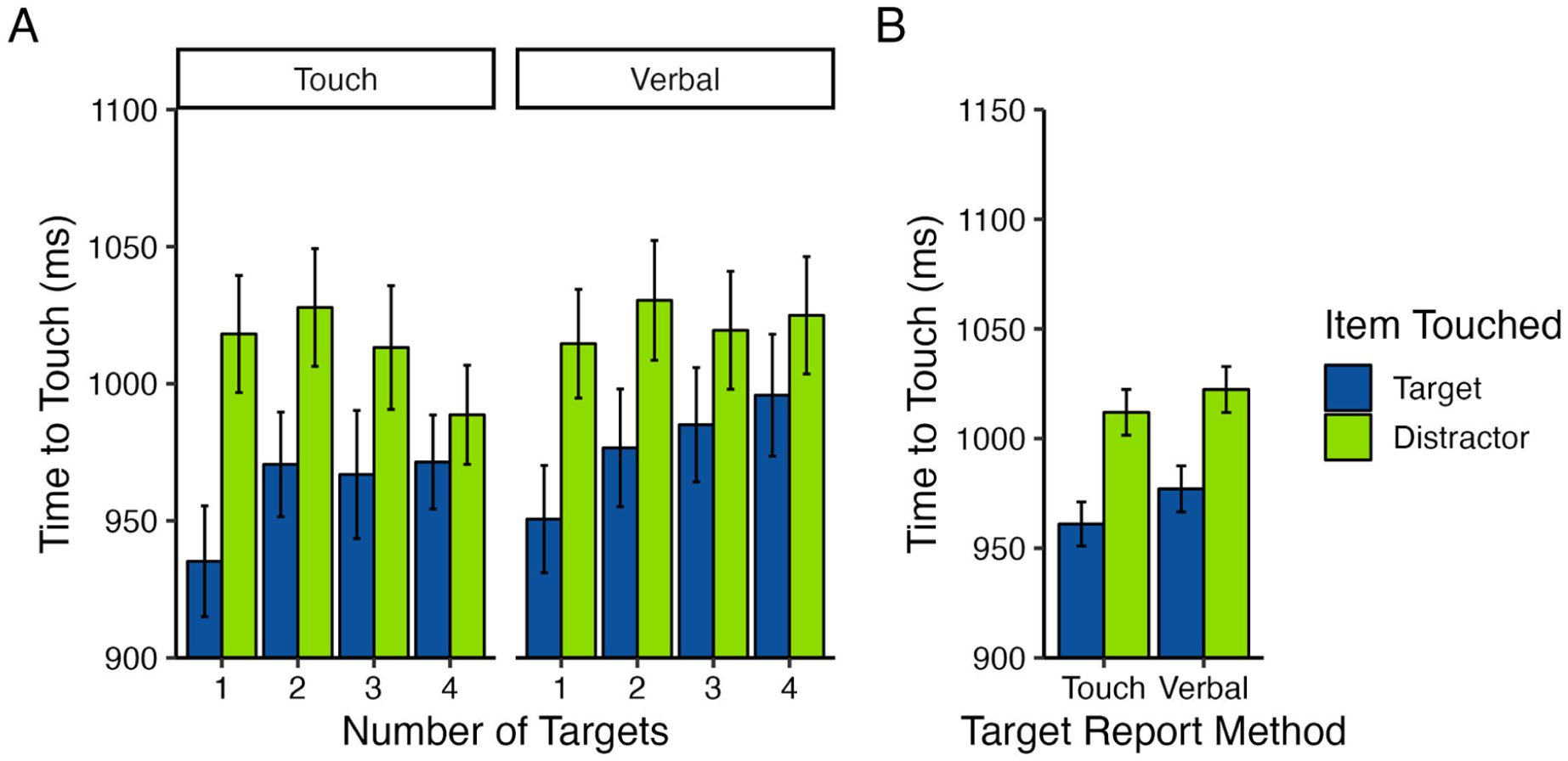
Mean time to touch items in multiple-object tracking (MOT) that changed colour (ms) as a function of the target report method (touch, verbal), the number of targets to track (1–4), and the item in MOT touched that changed colour and was touched (target, distractor): (A) Across the number of targets to track and the target report method, touch latencies were always faster when touching targets in MOT as compared to distractors, (B) Touch latencies were overall faster when touching targets in MOT as compared to distractors, but the difference between the target- and distractor-touch conditions remained consistent across target report method. Error bars represent standard error.
In summary, the target report condition did not affect the amount of differential interference. However, there was an unexpected interaction between the item touched and the number of targets. Results revealed that though the effect size was small, differences in the time to touch targets as compared to distractors in MOT were modulated by the number of targets to track (number of targets × item touched: F[2.86, 211.92] = 3.12, p = .029, η2p = .04). Follow-up paired t-tests demonstrated that touch latencies were significantly faster for targets as compared to distractors when tracking 1–3 targets in MOT, but the amount of interference decreased with increases in the number of targets to track (1 target: Mdiff = 73 ms, p = .001, 2 targets: Mdiff = 56 ms, p = .001, 3 targets: Mdiff = 40 ms, p = .001). When tracking 4 targets, the target-distractor difference in touch latencies was marginally significant, Mdiff = 23 ms, p = .056, though it is important to note that by the time there were 4 targets in MOT, accuracy was considerably lower, thus reducing the number of correct latencies to analyse, especially in the distractor-touch condition. All other effects and interactions were not statistically significant (number of targets: F[2.89, 213.84] = 2.11, p = .102, η2p = .03; number of targets × target report method: F[2.89, 213.84] = 0.86, p = .47, η2p = .01; number of targets × target report method × item touched: F[2.86, 211.92] = 0.30, p = .818, η2p = .00).
Discussion
In the present study, we examined the relationship between MOT and visually guided action by analysing the patterns of interference produced when participants completed two concurrent tasks. Previous work observed differential interference: MOT performance was more accurate and touch latencies were faster, when participants touched targets rather than distractors in MOT (Terry & Trick, 2021). In that study, however, participants employed the same manual response for touching items that changed colour and reporting MOT targets at the end of the trial. Thus, it is possible that these results reflect overlap in response demands rather than item individuation effects. By manipulating the method used to report MOT targets, the present study allows these factors to be distinguished. In the sections, below we outline the two main empirical contributions of this work, discussing their implications and identifying directions for future work.
Empirical Contributions of the Present Study
The first and most critical contribution of this study is to demonstrate that the differential interference reported by Terry and Trick (2021) is not limited to situations where participants report targets by touching them. Here, we compared two different methods of MOT target report that were maximally different: touching MOT targets and vocally pronouncing letters associated with the targets. Despite the large difference in motor demands between these responses, we observed differential interference in both conditions, and the magnitude of the effect was comparable. This finding indicates that the differential interference observed previously cannot be attributed solely to the similarity between the actions used to touch items that change colour and those used to report MOT targets. Instead, it supports the generality of the differential interference effect that emerges whenever participants touch items while tracking.
This pattern of results is consistent with Pylyshyn’s (2001) spatial index theory. According to this account, participants are faster to touch items that change colour when they are targets rather than distractors in MOT because targets already possess spatial indexes that provide direct access to their current locations, allowing faster initiation of visually guided action. These indexes provide direct access to the locations of targets, which means this information can be passed over directly to the motor programmes necessary for touching a specific item. In contrast, the reason that MOT performance is worse when participants touch distractors rather than targets is because touching a distractor causes it to be assigned a spatial index, which may increase the probability that the distractor will be confused for a target in the report phase of the trial (Terry & Trick, 2021, 2025).
We interpreted the findings of the present study in terms of Pylyshyn’s theory, not because it was the only theory of MOT, but because it was the only theory that made a clear prediction about what would happen when participants touched items that changed colour while tracking. In particular, Pylyshyn’s spatial index theory predicts that differential interference depends on item individuation, and thus it should emerge regardless of how the MOT targets are reported. According to Pylyshyn’s theory, the differences in the effects of touching targets and touching distractors are unrelated to the way that MOT targets are reported at the end of the trial.
In contrast, attention-based theories for MOT do not produce clear predictions about the effects of touching items while tracking. Because such theories vary in how attention is defined, ranging from multifocal attention to flexible resource allocation, they could as easily explain the presence as the absence of differential interference. For example, the presence of differential interference in the vocal report condition could be attributed to attention being preferentially allocated to targets. If differential interference was absent, it could be interpreted as attentional effects manifesting in only general interference, or alternatively, it could be argued that different report tasks require different attentional resources (Wickens, 2002). Finally, if neither general nor differential interference emerged, it could be argued that the attentional theory of MOT is true, but touching items that change colour while vocalizing targets is not sufficiently demanding to tax those attentional mechanisms, perhaps because the items were not moving rapidly enough or coming into close enough proximity. In summary, the breadth of what “attention” can mean in this literature makes it challenging to derive clear, falsifiable predictions for the present task. This experiment could produce a variety of different findings, and all could be claimed as evidence for attentional theories of MOT.
Empirical Contributions of This Study in Combination With Terry et al. (2023)
Our second contribution emerges from considering the present findings together with those of Terry et al. (2023). In Terry et al (2023), there was a condition where participants reported MOT targets by typing in letters associated with the targets. The results of that study indicated that there was significantly more general interference when participants reported targets by typing them in rather than touching them. Not only was MOT performance better but also latencies to touch items that changed colour were faster when they reported the MOT targets at the end of the trial by touching them rather than typing in letters associated with the targets (Mdiff = 48 ms p = .037). This is remarkable because it suggests that the plan to execute a certain action at a specific time in the future (e.g. typing in MOT targets at the end of the trial) can affect performance 7 to 8 s before that plan is carried out. Participants took longer to touch moving items if they expected to type using their non-dominant hand 7 to 8 s later. This highlights the importance of action plans, which are commonly conceived as plans for future motor activities, which specify the actions to be taken and the locations where those actions are carried out (Hommel & Colzato, 2004; Hommel et al., 2001; Stoet & Hommel, 1999).
However, the results of present study also show that it is not the complexity of the report process that produces higher latencies to touch items that change colour. The present study showed that there was no difference between the vocalized report (which was a relatively complex task because it required reading) and touch report (that did not). However, there were two conditions that had relatively complex target report procedures – both required reading letters projected on the targets before reporting them. One required vocalizing letters (the present study) and the other required typing them in (Terry et al., 2023). When these two complex report conditions were compared, results reveal that latencies to touch items that changed colour were 43 ms slower when participants had to later report MOT targets by typing letters in rather than vocalizing them, though in this case, the difference was only marginal (p = .11).
However, the most important overall lesson to be taken from this second empirical contribution is that the target report manipulation has different effects on general and differential interference. Specifically, these studies show target report affects general but not differential interference. This suggests a dissociation between general and differential interference – one that might occur because dual-task interference and target/distractor differentiation involve different mechanisms. This interpretation is in line with Pylyshyn’s spatial index theory that the target/distractor distinction is based on the fact that MOT targets are assigned spatial indexes and distractors are not. However, this finding might also be predicted by attentional theories that posit a variety of distinct types of attention: one related to single/dual-task differences another related to target/distractor differences. For example, target/distractor differences might reflect the fact that each target has its own attentional focus, whereas single/dual-task differences might reflect some other (empirically distinct) type of attention that is associated with multi-tasking.
General Conclusions and Future Directions
The present findings support Pylyshyn’s (1989) contention that the item individuation mechanism used in MOT is also necessary for coordinated actions, while showcasing the separable effects of motor responses. Although the current work advances our understanding of how tracking and action interact, several questions remain unanswered. Firstly, it is not yet clear how broadly the effects of touching specific items will generalize across different forms of visually guided action. In the present studies, participants responded using the index finger for their dominant hand, and related work shows similar patterns when participants used a computer mouse to move the cursor to “touch” the item that changed colour (Terry & Trick, 2022). Future work should test whether comparable effects emerge when individuals act with different effectors such as the non-dominant hand, the feet, or tools such as hockey sticks. If MOT is to be used to predict performance in dynamic tasks such as soccer (Romeas et al., 2016), it is critical to develop a comprehensive understanding of how the demands of more complex coordinated actions interact with those of MOT.
Secondly, the present studies focused primarily on manual response latencies. However, differences between target and distractor touch conditions may also manifest in eye movement patterns or in the precision and timing of specific components of the touch response. Incorporating eye tracking and kinematic analyses would therefore provide a more complete account of how perceptual selection and action preparation unfold during MOT.
Finally, this research suggests promising avenues for interdisciplinary research. There may be an important relationship between theories of MOT and broader frameworks that examine how perceptual information is linked to planned or upcoming actions (Hommel & Colzato, 2004; Hommel et al., 2001). At present, these literatures are relatively separate as research on planned actions typically involves static and single-target displays, while MOT research focuses on dynamic environments that involve multiple targets. Connecting and integrating these literatures may help illuminate how people select and act on specific objects within complex, changing environments, an ability that lies at the core of visually guided behaviour in daily life.
Footnotes
Acknowledgements
This article was written in its entirety by Mallory Terry and Lana Trick with no help from outside sources (human or AI). We would like to thank Tara Briar, Olivia Branchaud, Kaitlyn Large, and Alexandra Pluchowski, who helped in data collection for this article. Portions of the results were presented at the 2024 meeting of OPAM (Object Perception, Attention, and Memory).
Ethical Considerations
Consent to Participate
This study involved informed consent. Only individuals who signed consent forms were allowed to participate in the study.
Consent for Publication
This research is our original work, and we have the right to publish (on acceptance, we give consent to have it published).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a grant to the second author from the Natural Sciences and Engineering Research Council of Canada (Discovery Grant: 400713).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.