
Abstract
Visual short-term memory (vSTM) refers to the subset of the cognitive system responsible for storing visual information over short periods of time. While much research has focused on its capacity limitations, less is known about how vSTM operates in dynamic environments where priorities shift across feature dimensions. In this study, we bridge research on vSTM and cognitive control by embedding change detection (Experiments 1 and 2) and delayed estimation (Experiment 3) paradigms within a task switching paradigm, where the relevant feature dimension (colour or orientation) either repeated or switched across trials. Across all experiments, we observed a cost to vSTM performance on switch relative to repetition trials. Mixture modelling of delayed estimation responses revealed that these switch costs were not due to reduced memory precision or memory failures, but rather to a selective increase in non-target responses reflecting feature–location binding errors. We propose that dimension switching selectively impairs the binding of feature values to locations and allows interference from irrelevant (but recently attended) feature dimensions. Our findings demonstrate that vSTM is sensitive to failures of attentional control, not just capacity limits.
Keywords
Introduction
Visual short-term memory (vSTM) refers to the subset of the cognitive system responsible for the retention of visual information over short periods of time (Phillips, 1974). Considerable work has been directed at understanding the nature of vSTM, in particular, understanding its capacity limitations (for reviews, see Bays et al., 2024; Ma et al., 2014). Such an understanding is essential as vSTM is the interface between sensory perception of the external visual world and higher-order cognition. Understanding these capacity limitations, therefore, not only provides insight into fundamental constraints of cognitive processing but it also informs how vSTM interacts with more complex cognitive functions.
A consensus emerging in the literature is that capacity limitations arise in vSTM due to the allocation of a limited, continuous, memory resource across memoranda (Bays & Husain, 2008; Bays et al., 2009, 2024; van den Berg et al., 2012; for an alternative view see Luck & Vogel, 2013; Zhang & Luck, 2008). When the number of visual elements to retain is low, each element receives plentiful resources and is encoded and retained in vSTM with high fidelity, leading to enhanced probability and precision of later recall. Conversely, when the number of elements to retain is high, each element receives considerably fewer resources, resulting in reduced probability and precision of later recall. Capacity limitations arise—and memories therefore fail—when memoranda are not represented with sufficient precision due to insufficient allocation of limited resources (Bays et al., 2024).
Understanding how memoranda are represented in vSTM is essential for understanding vSTM capacity limitations because it determines at what level the limited memory resources are applied. Whether vSTM representation is object-based (i.e. memory resources are applied to whole objects, D. Lee & Chun, 2001; Luck & Vogel, 1997; Ngiam et al., 2024; Ramaty & Luria, 2025; Sone et al., 2021; Vogel et al., 2001) or feature-based (i.e. memory resources are applied to individual features such as colour or orientation, Bays et al., 2011; Brady et al., 2011; Brown et al., 2021; Fougnie et al., 2010; Li et al., 2022; Markov et al., 2019, 2021; Marshall & Bays, 2013; Shin & Ma, 2016, 2017) has been a topic of intense debate, with recent reviews generally favouring a feature-based account (Bays et al., 2024; Brady et al., 2024).
Early research into vSTM representation used the change detection paradigm in which participants are briefly (e.g. 100 milliseconds) presented with an array of objects of varying set size to encode. After a retention interval (e.g. 1,000 ms) in which the objects are removed, participants are presented with a second array of objects in which one object may have changed (e.g. from red to black). It is the participants’ task to make a change/no-change judgement on the test array. Whilst early research suggested change detection performance is unaffected by the number of feature dimensions per object (Luck & Vogel, 1997; but see Wheeler & Treisman, 2002)—consistent with models assuming object-based representation in vSTM—later research has shown that the precision of memory representations does decrease with increasing features (Fougnie et al., 2010). In addition, it has been shown that memory capacity is more readily consumed by complex, multi-feature, objects in comparison to simple objects (Alvarez & Cavanagh, 2004), which is hard to reconcile with a purely object-based representation in vSTM.
Further evidence for feature-based representation in vSTM comes from studies that show memory performance for each feature dimension of a single object is independent. This independence is evidenced using the delayed-estimation paradigm (Prinzmetal et al., 1998; Wilken & Ma, 2004). This paradigm is similar to the change detection paradigm in that participants encode a set of memoranda, followed by a retention interval. However, at test, participants are cued to the location of one of the memoranda and must recall its feature value by reproducing it on a continuous scale. For example, in a task requiring memory for colour, participants are presented with a colour wheel at test and select the colour that best matches the recalled feature value of the cued item. Memory precision is then estimated by taking the angular difference between the true target feature value and the participant’s response. Supporting the feature-based representation account, Fougnie and Alvarez (2011) found that when participants were asked to remember objects with colour and orientation features, memory precision for an object’s colour remained high even when precision for that object’s orientation was very low (and vice versa), supporting the view that feature dimensions are represented independently (see also Bays et al., 2011; but see Ramaty & Luria, 2025).
The Current Study
The need to allocate a limited memory resource across multiple features distributed across multiple objects presents an interesting challenge for the cognitive system: Since the resource is limited—and since successful (and precise) recall of visual information requires that memoranda receive sufficient resources—it is imperative for the cognitive system to prioritise the allocation of this limited resource to features that are task-relevant if goal-directed behaviour is to be achieved. As the limited vSTM resource is thought to be flexible in that it can be concentrated more on certain features to enhance their representation (Bays & Husain, 2008), cognitive control is required in dynamic environments when goals change to ensure that memory resources are allocated optimally to task-relevant features. Without such control, task-irrelevant features compete for a share of limited vSTM resources, which in turn reduces the precision of all memoranda.
This challenge is similar to the one faced by the cognitive system during task switching. In typical task-switching paradigms, participants are presented with stimuli that afford multiple tasks (e.g. digits) and are cued on each trial to perform one of two tasks. For example, participants may be presented with a cue “Parity” which requires them to judge whether the digit is odd or even, or the cue “Magnitude” which requires them to judge whether the digit is lower or higher than five. The critical manipulation is whether the task on the current trial has switched from that of the previous trial (e.g. Parity to Magnitude) or whether it has repeated (e.g. Magnitude to Magnitude). It is a consistent finding that response time and errors are increased on task switch trials relative to task repetition trials (Grange & Houghton, 2014; Kiesel et al., 2010; Koch et al., 2018; Logan, 2003; Monsell, 2003; Vandierendonck et al., 2010).
Task performance requires establishing a stable mental representation—a so-called task set—that comprise attention settings (stimulus sets, i.e. which object/feature to attend to) and stimulus-response mappings (response sets, i.e. how to respond to these objects) necessary to perform a particular task (Grange, 2025; Schneider, 2014; Schneider & Logan, 2007). The switch cost in task switching performance has been explained by (a) time-consuming reconfiguration of the relevant task set component on switch trials that is not required on repetition trials (Monsell, 2003; Rogers & Monsell, 1995), (b) interference caused by persisting activation of the previously relevant task set component on switch trials (i.e. carryover effects, Allport et al., 1994), and (c) a combination of both reconfiguration and interference (Meiran, 2000; Meiran et al., 2000; Vandierendonck et al., 2010). Recent work has shown that stimulus set and response set are unique components of the overall task set that can be independently controlled and updated, and each contributes to the overall switch cost (Grange, 2025).
The current study examines how the allocation of limited memory resources to task-relevant features in vSTM is influenced by changes in task demands in dynamic environments. Specifically, we embed vSTM change detection (Experiments 1 and 2) and delayed-estimation (Experiment 3) paradigms within a task switching paradigm where the relevant feature dimension on each trial either repeats (e.g. colour–colour) or switches (e.g. colour–orientation) from that of the previous trial. In conventional vSTM tasks, which hold the relevant feature dimension constant, participants can adopt a stable strategy by maintaining consistent allocation of resources; in contrast, the paradigm reported in the current work requires participants to dynamically adjust which feature is prioritised on a trial-by-trial basis, helping elucidate the interplay between dynamic task demands and memory resource allocation. We expect that—analogous to classic task switching—there will be a cognitive cost when the target feature changes.
Experiments 1a and 1b
In Experiment 1, a change detection paradigm was used to explore the impact of dimension switching on vSTM performance. In Experiment 1a, bivalent stimuli (coloured circles with an orientation) were used, whereas in Experiment 1b, univalent stimuli (two coloured circles with no orientation, and two circles with an orientation but no colour) were used. The total set size in each Experiment was four, although the effective set size (i.e. the set size of stimuli with features of the relevant dimension) in Experiment 1b was two. The feature load was eight and four in Experiments 1a and 1b, respectively.
Method
Participants
A total of 57 participants completed Experiment 1a and 45 completed Experiment 1b. As these experiments were part of the initial exploratory set, our sample size was determined by collecting data from as many participants as possible within a specified time frame. Participants whose proportion accuracy was not significantly better than chance (i.e. 0.50, as determined by a binomial test) were removed. As a result, the final sample size was 44 for Experiment 1a and 45 for Experiment 1b. Participants were recruited via Prolific Academic (prolific.co), and both experiments had unique participants. Participants were aged between 18 and 60 years of age (inclusive) 1 and self-reported normal or corrected-to-normal visual acuity and colour vision. Recruitment was limited to participants from the United Kingdom and the United States. Participants were paid a small fee for participation. A constraint was added to allow only those accessing the experiment from a desktop or laptop computer.
Materials
The experiment was programmed and delivered using Gorilla (Anwyl-Irvine et al., 2020). Stimuli in Experiment 1a consisted of four bivalent circular shapes with a rectangular segment removed to indicate orientation (i.e. each stimulus had two feature dimensions of colour and orientation). In Experiment 1b, all stimuli were univalent with a single feature dimension: two stimuli were coloured circles (with no segment cut out and thus no orientation), and two stimuli were white circles with an orientation (see Figure 1, e.g. stimuli from each Experiment).
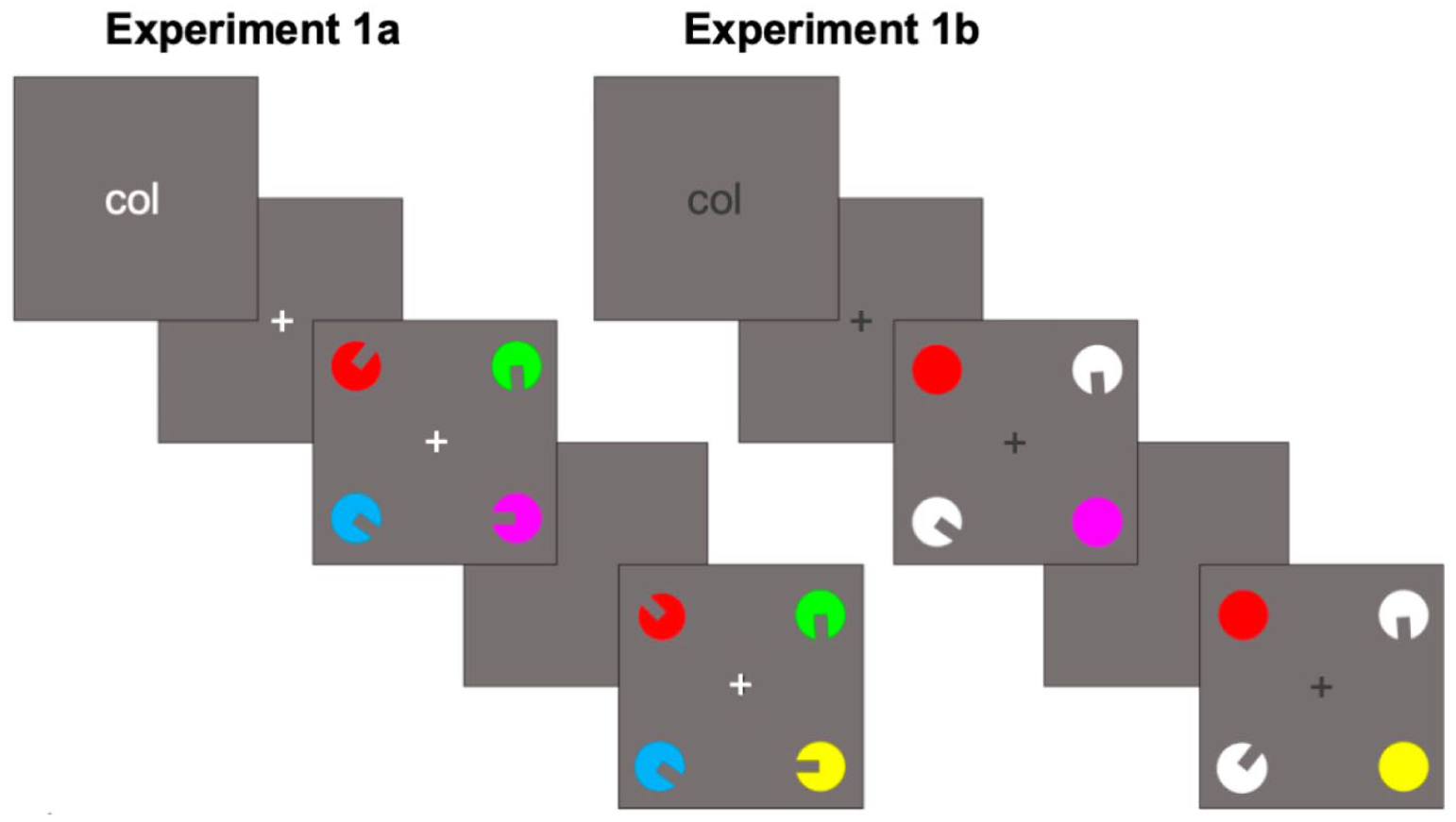
An example trial from Experiment 1a (left) and Experiment 1b (right). In both examples, the cue “col” indicates participants must memorise the colour of the stimuli on the first screen (the memory display). After a short retention interval, the test display appears, and participants must judge whether a stimulus has changed on the cued feature dimension. In both examples, the bottom-right stimulus has changed feature value. Note that in all trials, a change always occurs in the uncued feature dimension (e.g. the orientation of the top-left stimulus in example A and the bottom-left stimulus in example B).
The feature dimension of colour could take on one of seven colours in both experiments (defined here with the Red, Green, Blue [RGB] values): Black (0, 11, 16), blue (65, 105, 225), cyan (20, 253, 255), green (0, 250, 3), purple (255, 41, 255), red (255, 54, 31), or yellow (253, 254, 21). The univalent orientation stimuli in Experiment 1b were presented in white (255, 255, 255), which was not a possible colour feature dimension. The feature dimension of orientation could be any value between one and 360 degrees with the constraint that the minimum orientation difference between all stimuli on a single trial was 40 degrees. The RGB value for the background was light grey (127, 128, 128). Stimuli were presented within a dark grey (89, 89, 89) frame positioned in the centre of the display. Feature dimension cues on each trial were either the word “col” (to cue attention to the colour feature dimension) or “ori” (to cue attention to the orientation feature dimension). In Experiment 1a, dimension cues and fixation crosses were white, but were dark grey in Experiment 1b due to the use of white stimuli.
Procedure
In both experiments, a change detection paradigm was used. Participants were required to monitor for a change in any of the stimuli across two successive screens (the memory display and the test display). Importantly, on each trial, participants were presented with a cue that indicated which feature dimension—colour or orientation—should be monitored. Participants completed two types of blocks across the experiment: In pure blocks, the relevant feature dimension repeated throughout the whole block (i.e. participants only monitored for changes in colour or orientation). In mixed blocks, the relevant feature dimension was randomly selected on each trial such that on some trials the relevant feature dimension could repeat from that of the previous trial (e.g. colour–colour) or switch (e.g. colour–orientation).
Prior to the main experimental blocks, participants completed practice blocks consisting of 40 trials (10 pure colour, 10 pure orientation, and 20 mixed) to familiarise them with the task. Accuracy feedback was provided at the end of each trial in the practice blocks. The main experimental section consisted of a total of 450 trials; these were separated into three cycles following the same pattern of 25 pure orientation trials, 25 pure colour trials, and two blocks of 50 mixed trials. Self-paced breaks were provided every 50 trials.
On each trial, participants were presented with a cue for 500 milliseconds (ms), indicating which feature dimension was relevant for that trial. The cue was then replaced with a central fixation cross for 500 ms, after which the memory display consisting of four stimuli was presented. The stimuli were organised such that each stimulus occupied the corner of an invisible square (see Figure 1). In Experiment 1b, stimuli containing the same feature dimension were constrained to always appear diagonally opposite each other to prevent stimuli for the relevant feature dimension from being presented on one side of the display. The memory display was present for 200 ms, after which time they disappeared and were replaced by a blank screen for a retention interval of 1,500 ms. After this time, the test display was presented for 200 ms. On change trials, the value of one stimulus (randomly selected) on the relevant feature dimension would change, whereas on no-change trials, all values of the relevant feature dimension were identical to the memory display. On all trials, the value of one stimulus (randomly selected) on the irrelevant feature dimension would change. 2 Participants were instructed to ignore this change and to only monitor for change on the cued feature dimension. On change trials, the stimulus selected to feature the change on the relevant dimension was always different to the stimulus selected to feature the change on the irrelevant dimension.
After the test display had been presented for 200 ms, the stimuli disappeared, and participants were required to make their response: they were instructed to press the “M” key on the keyboard to indicate a change response, and the “Z” key to indicate a no-change response. Participants were instructed to respond as quickly and as accurately as possible. Response time (ms) and accuracy were recorded on each trial. After a response had been registered, the frame went blank for 250 ms, after which a fixation cross appeared for 750 ms before the cue for the next trial was presented.
Design
To summarise the design, both experiments featured one independent variable of Sequence with three levels (pure repetition vs. mixed repetition vs. mixed switch). We analysed the impact of this independent variable on four dependent variables: proportion accuracy and response time (in milliseconds, ms) were supplemented by measures of signal detection theory d’ and response bias,

and

where
Results
All of the data wrangling, statistical modelling, and visualisation utilised R (R Core Team, 2023) and various packages.
3
Prior to all analyses, the first trial of each block was removed as these cannot be classified as repetition or switch trials. For accuracy and signal detection analysis, trials immediately following an error were removed. For response time (RT) analysis, error trials and the trials following an error were removed. Correct RTs were also trimmed using the R package trimr (Grange, 2022); RTs shorter than 150 ms were removed, as were RTs longer than 2.5 standard deviations above the mean per participant per cell of the design. Bayesian one-way ANOVAs (with the factor dimension Sequence, with levels pure, dimension-repetition, and dimension-switch), were conducted for each of the dependent variables proportion accuracy and RT, as well as signal detection theory measures sensitivity (d’) and response bias (
Experiment 1a
All of the results for Experiment 1a and 1b can be seen in Figure 2. Analysis of proportion accuracy (Figure 2a) across Sequence showed extreme evidence for the alternative (
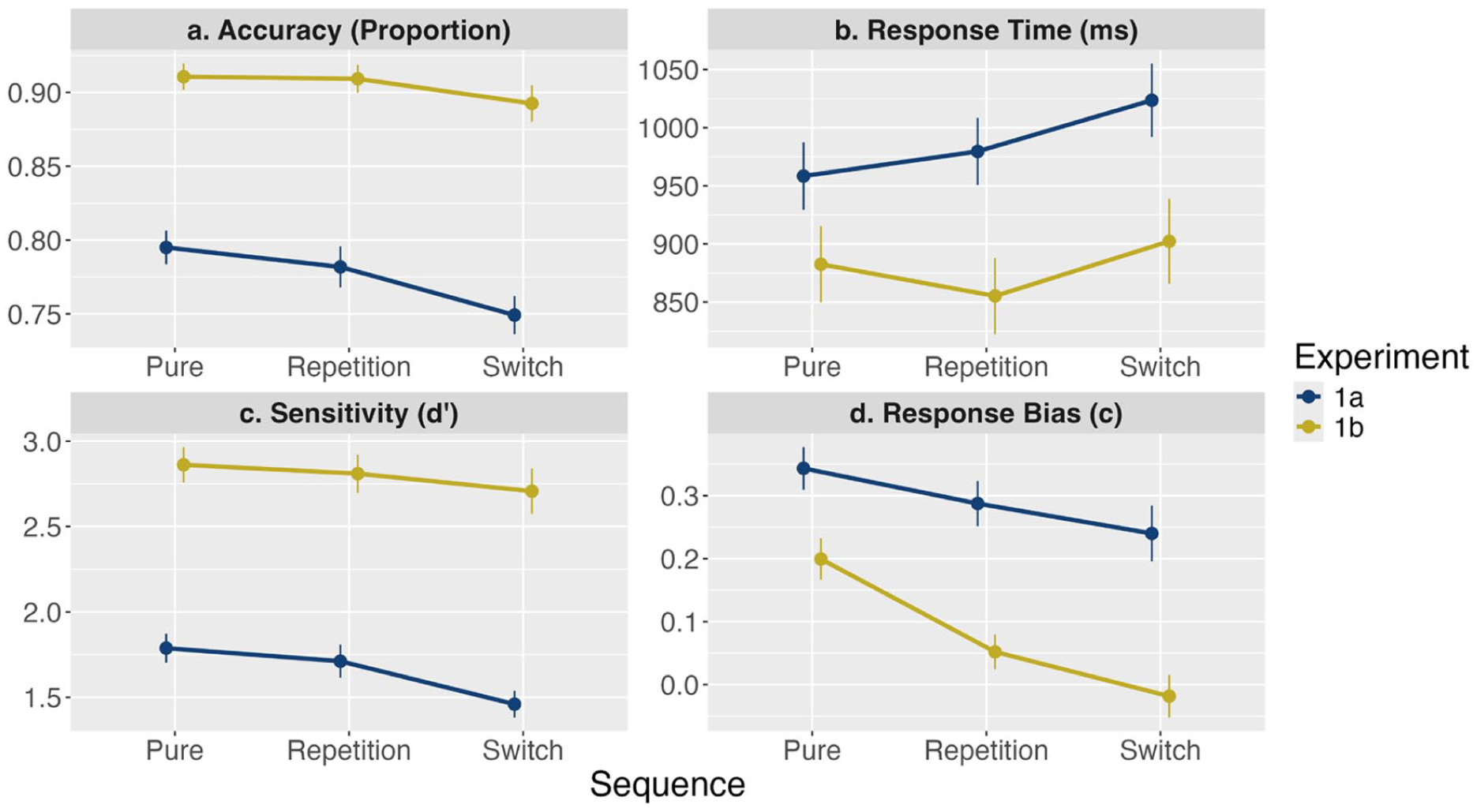
The results from Experiments 1a and 1b. Data points represent the mean for each dependent variable (a) Accuracy, (b) Response Time, (c) Sensitivity, and (d) Response Bias.
Experiment 1b
Analysis of proportion accuracy (Figure 2a) across Sequence showed no evidence for the alternative (
Discussion
Experiment 1 provides evidence for a cost to visual short-term memory performance on dimension switch trials in mixed-block conditions where participants need to switch to encoding a new feature dimension (cf., feature dimension repetitions). There were no consistent effects of mixing cost. For mixed-block performance, there was a switch cost for accuracy for bivalent stimuli (Experiment 1a) but not for univalent stimuli (Experiment 1b), a pattern which also manifested in sensitivity (
These results together provide initial evidence that feature dimension switching disrupts visual short-term memory performance, and that this is to some extent moderated by the feature load of each object, with costs to accuracy and sensitivity when the feature load was higher (and stimuli were bivalent) in Experiment 1a in comparison to Experiment 1b. However, there were some inconsistencies in results across experiments for different outcome measures, so in Experiment 2, we replicate and extend these findings.
Experiment 2
We conducted four experiments (Experiments 2a–2d) providing a conceptual replication of Experiment 1 utilising similar stimuli to that of Markov et al. (2019). These authors were interested in whether features from different dimensions are stored independently, and—if so—whether this independence is supported regardless of whether the features belong to the same or different objects. They presented participants with feature dimensions of colour and orientation, and were asked to memorise both features (cf., our experiments, where only one feature dimension is cued). After a delay period, participant was probed to recall the feature value of one of the memoranda and reproduce it in on a continuous scale (e.g. colour/orientation wheel). The main manipulation relevant to the current paper was whether the feature dimensions belonged to the same or different objects.
The stimuli used in the current experiments are shown in Figure 3 corresponding to Experiments 2a–2d. In Experiment 2a, stimuli were coloured, oriented isosceles triangles with both feature dimensions (colour and orientation) integrated into the same object (similar to Experiment 1a). There were four objects, and the feature load of each object was two. In Experiment 2b, stimuli were distinct unidimensional objects comprising coloured circles and oriented white triangles, with feature dimensions distributed across objects (similar to Experiment 1b). There were four objects, and the feature load of each object was one. These two experiments together provided conceptual replications of Experiments 1a and 1b. Experiment 2c extended Experiment 2b by increasing the number of unidimensional objects to eight—four coloured circles and four oriented triangles. This increases the overall number of objects (from two to four), and the effective set size of each feature dimension (from two to four). Stimuli in Experiment 2d were the same as in Experiment 2c (coloured circles and oriented triangles), but were spatially overlapping such that each oriented triangle had a coloured circle placed on top. This arrangement may lead participants to encode these items as unified bivalent objects due to perceptual grouping principles. If so, the overall number of objects is four, and the effective set size of each feature dimension is two; if not, the overall number of objects is eight, and the effective set size of each feature dimension is one.
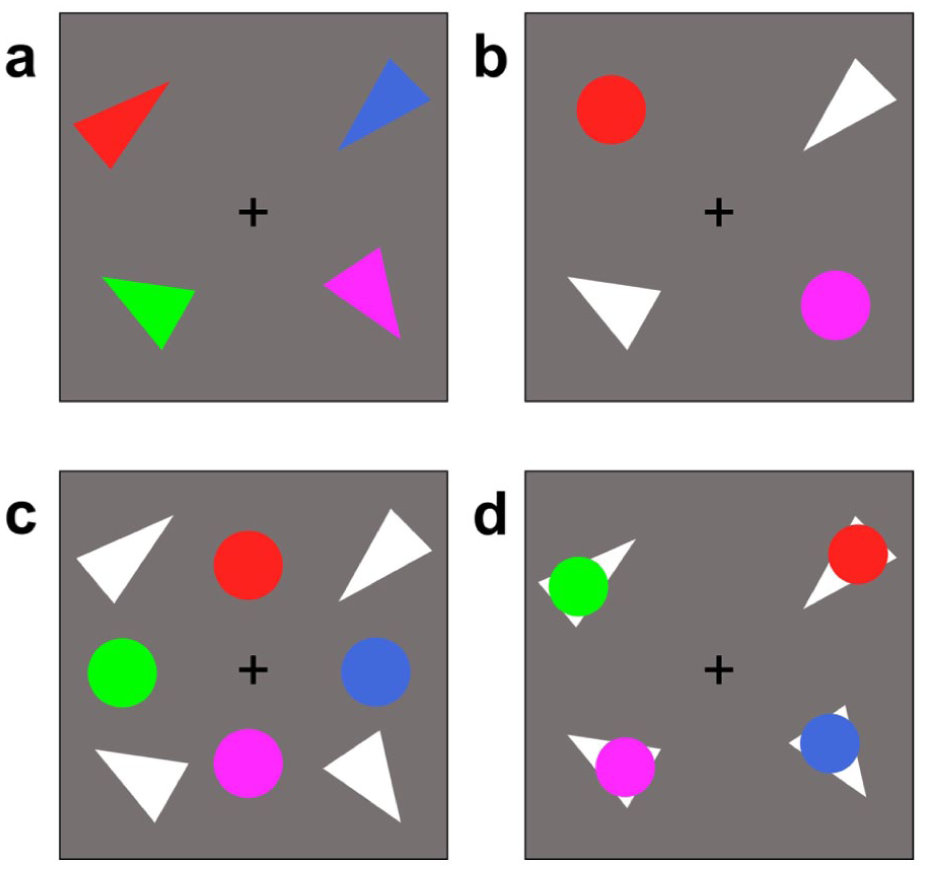
Example stimuli from Experiments 2a–2d.
This overall configuration of stimuli across conditions allows us to ask a number of questions. The primary question is whether we replicate the switch cost in accuracy and signal detection measures (and with lesser interest, response time). If so, such a switch cost may reflect difficulty in resource allocation on switch trials relative to repetition trials. Our design further allows us to ask whether this resource allocation is moderated by (a) feature integration vs. overlap (e.g. Experiment 2a vs. 2d); total set size and integration vs. distribution of features (e.g. Experiment 2a vs. 2b); selective increases in effective set size (Experiment 2b vs. 2c); manipulation of integrated vs. spatially separated features (Experiment 2a vs. 2c); and spatial separation vs. spatial overlap of features (Experiment 2c vs. 2d).
We also made other modifications from Experiment 1 in order to enhance the sensitivity to detect effects of dimension switching on vSTM performance. First, we removed the pure blocks, so participants were only exposed (after practice) to mixed-block trials where repetitions and switches were equally likely. This allowed for an increase in the number of trials. In addition, we utilised a sequential Bayes factor design (Schönbrodt & Wagenmakers, 2018) to better determine the sample size of each experiment.
Method
Participants
Sample size for each experiment was determined by sequential Bayes factor analysis (Schönbrodt & Wagenmakers, 2018). We established that our minimum sample size would be 20, and our maximum (due to time and resources) would be 70. Once the minimum sample size had been reached, we conducted a Bayesian t-test on proportion accuracy comparing repetition and switch performance. If the
The total number of recruited participants was 47, 73, 72, and 75 for Experiments 2a–2d, respectively. As in Experiment 1, participants were removed if their performance was not statistically better than chance. This led to a final sample size for analysis of 45, 70, 70, and 70 for Experiments 2a–2d. Participants were recruited through a combination of the participant panel run by the School of Psychology at Keele University and Prolific, with unique participants in each experiment. All participants completed the study online. Participants were aged between 18 and 60 (inclusive), and self-reported normal or corrected-to-normal visual acuity and colour vision. Prolific recruitment was limited to the United Kingdom and United States. Participants recruited via Prolific were paid a small fee, and participants recruited via the Psychology participant panel received partial course credit.
Materials
The task was again a change detection task; however, different stimuli were used (see Figure 3). In Experiment 2a, the stimuli consisted of four bivalent (coloured and oriented) isosceles triangles. In Experiment 2b, four univalent stimuli were presented: two of the stimuli were coloured circles, and two were white triangles. The stimuli of Experiments 2a and 2b therefore mimic the stimuli and effective set sizes used in Experiments 1a and 1b (respectively). In Experiment 2c, eight univalent stimuli were presented: four coloured circles, and four white triangles. In Experiment 2d, as in 2c, eight univalent stimuli were presented; however, unlike Experiment 2c, in Experiment 2d, the stimuli were spatially overlapping such that each white triangle had a coloured circle on top. Feature values for colour and orientation were selected as in Experiment 1; in Experiments featuring the white univalent triangles, participants were informed that white would never be a colour-dimension feature value. Dimension cues were identical to Experiment 1, as were the stimulus frames and fixation crosses. The experiment was programmed and delivered using Gorilla (Anwyl-Irvine et al., 2020).
Procedure
The procedure was similar to Experiment 1 with the exception that only mixed blocks were used. Therefore, participants made a change detection judgement in blocks of trials wherein the relevant feature dimension could repeat (e.g. colour–colour) or switch (e.g. colour–orientation) from the previous trial. A total of 40 practice trials were presented (10 colour only trials; 10 orientation only trials; 20 mixed trials) followed by 400 mixed trials separated into blocks of 50. There was a self-paced rest screen at the end of each block.
Results
The analytical approach was different from that of Experiment 1. Here, data across Experiments 2a–2d were analysed in a single model. Specifically, we calculated Bayes factors for factorial designs as described by Rouder et al. (2017), with the factors Sequence (repetition vs. switch, within-subjects) and Experiment (2a–2d, between-subjects). To assess the evidence in favour of each factor (plus the interaction), we first constructed a full model which included all predictors (one predictor for each factor plus one for their interaction). Then, separate models were constructed that selectively omitted one predictor at a time. The evidence for each predictor is the Bayes factor for the omitted model compared to the Bayes factor for the full model. Specifically, the Bayes factor for a particular predictor is calculated as
The results are shown in Figure 4. For the accuracy analysis, there was extreme evidence for both the main effect of Sequence (
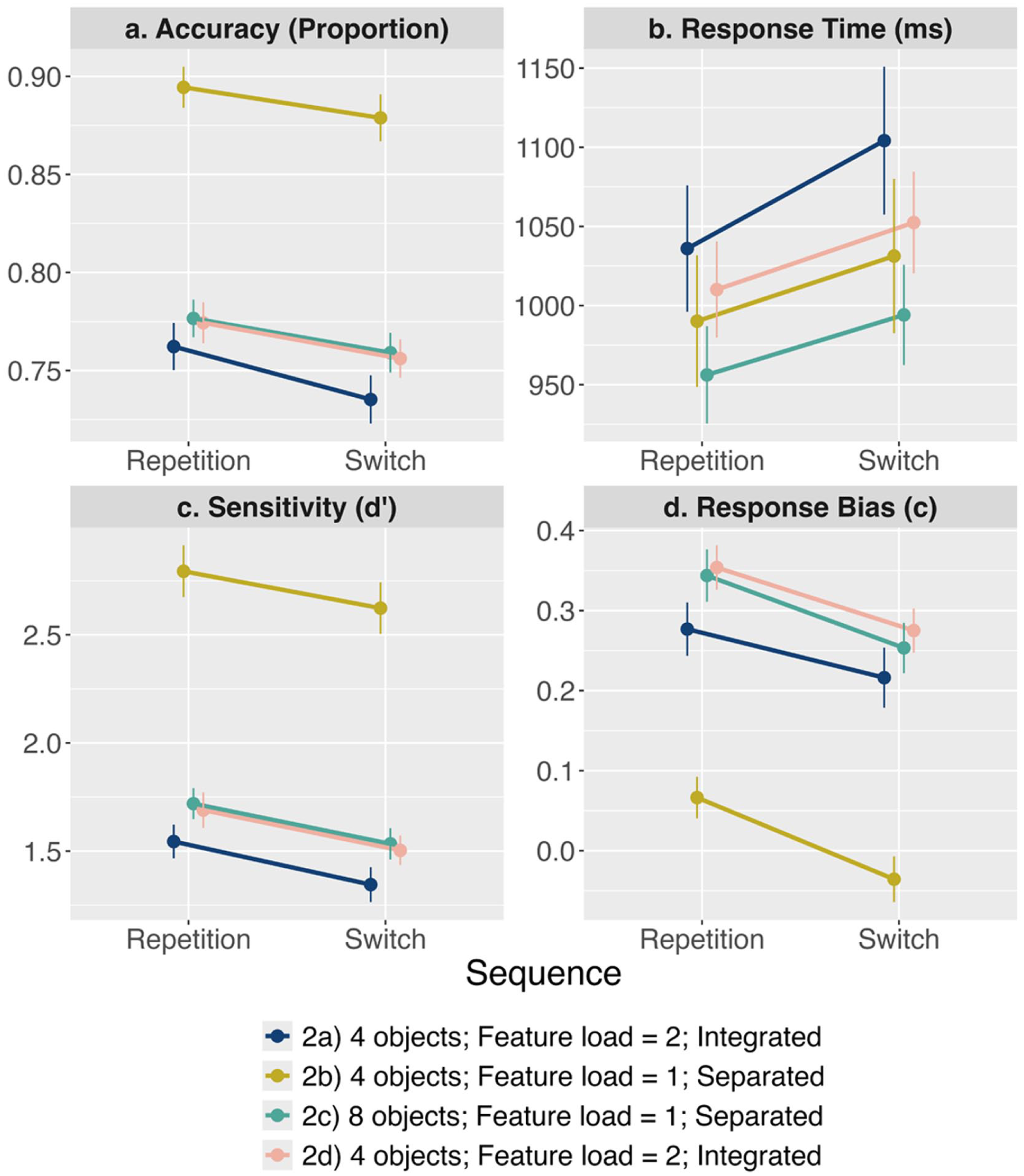
The results from Experiment 2a–2d. Each panel represents a different dependent variable (a) Accuracy, (b) Response Time, (c) Sensitivity, and (d) Response Bias.
Bayes Factors (
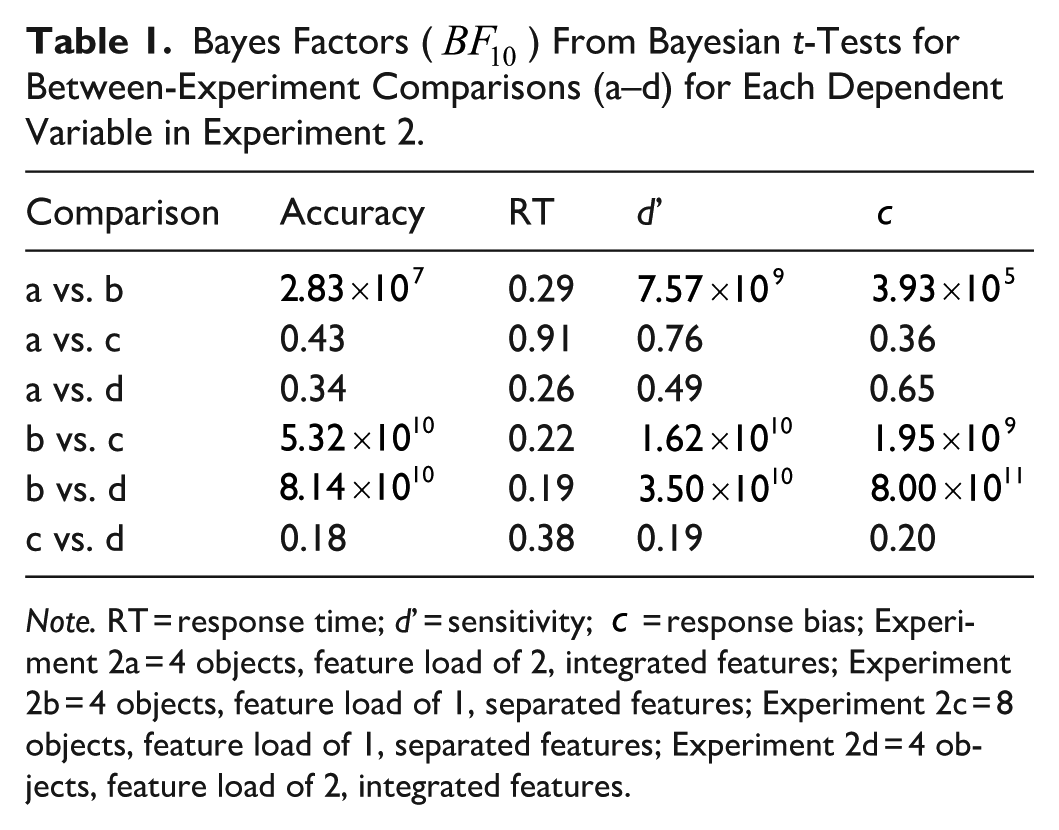
Note. RT = response time; d’ = sensitivity;
For response time, there was extreme evidence for the main effect of Sequence (
For sensitivity, there was extreme evidence for the main effect of Sequence (
For response bias, there was extreme evidence for the main effect of Sequence (
Discussion
The results of Experiment 2 were clear: Switching feature dimension incurred a cost to all measures of visual short-term memory performance. Importantly, all dependent variables demonstrated switch costs that did not interact with the between-experiment manipulations of set size, feature load, or feature overlap.
In addition, the results offer insight into a potential explanation of the reduction of accuracy and sensitivity with dimension switching. For most experiments and conditions, response bias (
Experiment 3
The purpose of Experiment 3 was to generalise the findings from the first two experiments to the delayed estimation paradigm (Prinzmetal et al., 1998; Wilken & Ma, 2004). Recall that in this paradigm, participants are presented with memoranda to encode similarly to experiments presented thus far; however, at test, participants are probed to the location of one of the memoranda, and are asked to recall and reproduce the probed object’s feature value on a continuous wheel. The novel extension in Experiment 3 is to embed this delayed estimation task within a task switching paradigm. Similar to Experiments 1 and 2, participants are cued on each trial to encode either the colour or orientation of four bivalent circular shapes with a rectangular segment removed to indicate orientation. At test, participants are probed to recall the task-relevant feature value of a probed object; if the task is colour, participants reproduce the feature value on a colour wheel, and if the task is orientation, participants reproduce the orientation on an orientation wheel (see Figure 5). Memory precision can therefore be inferred from the magnitude of response error (calculated as the angular deviation between the true feature value and the participant’s response), with higher memory precision leading to smaller response error.
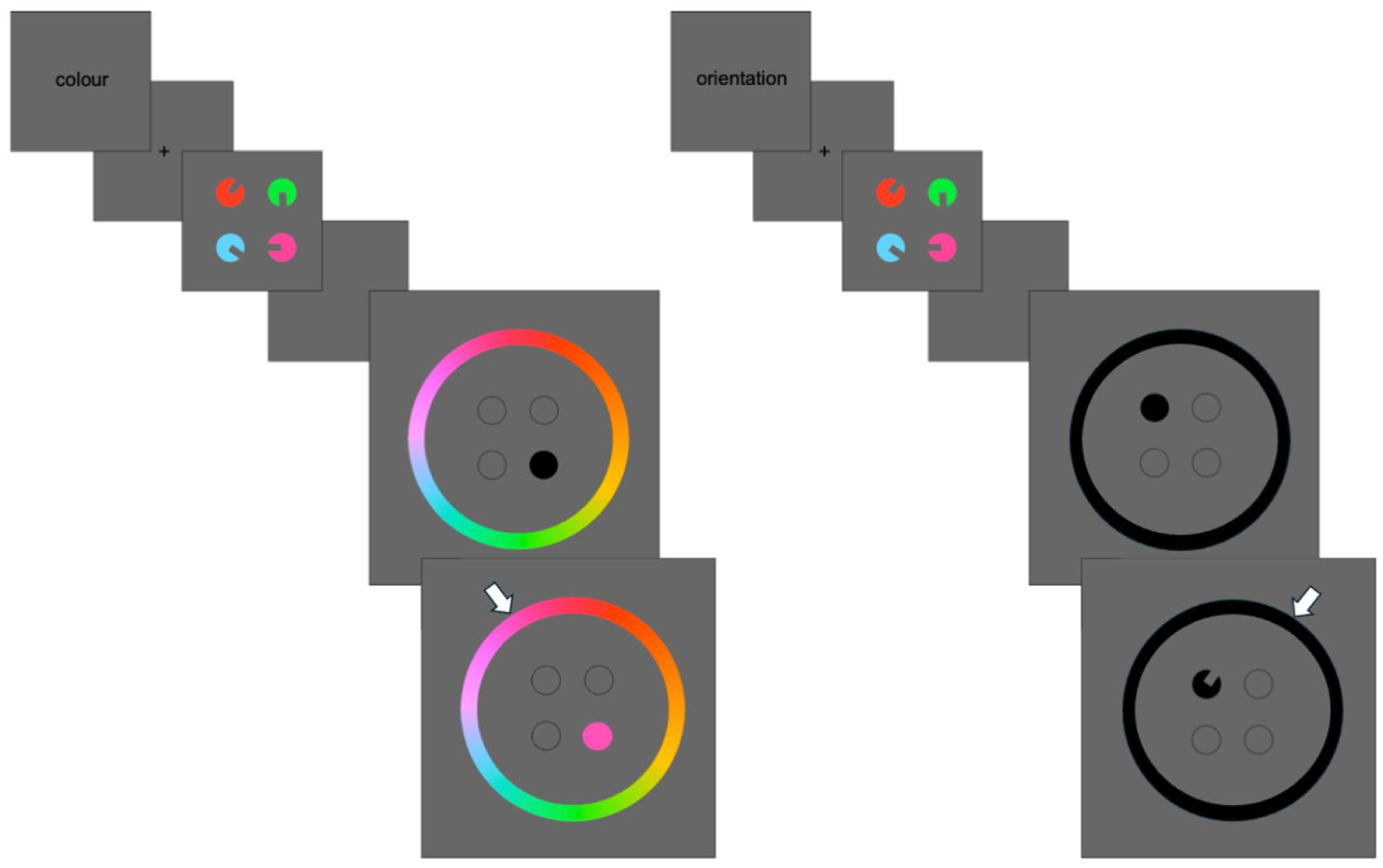
Example trials from Experiment 3. The left shows a colour trial where participants are cued to memorise the colour of the stimuli. At the probe screen, one of the stimulus locations is indicated (filled black circle), and a colour wheel is presented. Participants move their mouse on the colour wheel (indicated by the white arrow, not visible to participants), which changes the colour of the probed location to match the hue on the colour wheel. The right shows an example location trial.
As well as assessing the generalisability of the findings from Experiments 1 and 2, employing the delayed estimation task allowed us to apply a formal mathematical model of visual short-term memory in order to identify a mechanistic explanation of the source of the switch cost so far observed. Specifically, we applied the three-component mixture model of Bays et al. (2009). This model formalises the proposal that response errors arise due to (a) noisy internal representations of the true feature values, (b) incorrectly retrieving the feature value of one of the non-probed objects (a form of binding error), and (c) random guessing when memory fails.
The three-component model is defined as
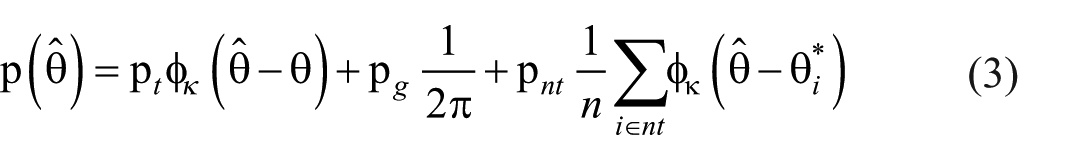
where
The key parameters are therefore
Method
Participants
A total of 50 participants completed Experiment 3 in an in-person study. All participants were aged between 18 and 60 and reported normal or corrected-to-normal visual acuity and colour vision. Participants were recruited via the participant panel run by the School of Psychology at Keele University and were awarded course credit or paid a small fee for taking part.
Sample size was again determined by a sequential Bayes factor analysis, with a minimum sample size of 20 and a maximum sample size of 70. When the minimum sample size was reached, the participant exclusion criterion was checked (see “Results” section). Specifically, we removed participants whose probability of guessing (as determined by the
Materials
The experiment was programmed and delivered using PsychoPy (Peirce et al., 2019). The experiment was run on a 24.5 inch monitor (ASUS ROG SwiftTM PG258Q) at a viewing distance of 52 cm. which was held constant through use of a chin rest. Stimuli were similar to Experiment 1a in that the memory display comprised of four coloured circles with rectangular segments removed to provide orientation (see Figure 5). Colours were selected from a colour wheel situated within the CIE L-a-b colour space (radius = 60; L = 90; a = 20; b = 38). Each stimulus had a radius of 30 pixels (px.). The background was light grey (RGB: 170, 171, 171), and the cues and fixation crosses were presented in black. The cues were “colour” and “orientation” for the colour and orientation dimensions, respectively. On the test display, four empty black circles were presented to represent the location of each of the memoranda’s locations from the memory display. One of these black circles were filled black to indicate which location was relevant for recall (i.e. the “probe”). These location templates were surrounded by a circular colour wheel (on colour trials) or a circular wheel that was completely black (on orientation trials). These wheels had a radius of 250 px. and width of 35 px.
Procedure
Participants were first provided a demonstration of the task requirements by the software, which walked through three trials each for colour and orientation dimensions. After this, participants completed a practice session of 20 trials (10 colour-only trials, followed by 10 orientation-only trials). Participants then completed the main experimental blocks, which consisted of 8 blocks of 50 trials, with self-paced rest at the end of each block.
Each trial began with the presentation of a cue indicating which feature dimension was relevant on the current trial. The relevant cue was randomly selected and was presented for 500 ms. The cue was then replaced by a fixation cross for 500 ms, after which time the four stimuli of the memory display were presented for 200 ms. The colour of each stimulus was randomly selected as locations on the colour wheel (i.e. from 1 to 360 degrees) with the constraint that there be at least 40 degrees separation between each selected colour so as to minimise stimulus confusability. Similarly, orientation of each stimulus was randomly selected (from 1 to 360 degrees) with the same 40-degree minimum separation constraint. The display then went blank for a retention interval of 1,000 ms, after which the probe screen was presented, which remained on screen until a response from the participant was registered. The probe display consisted of the four templated locations, as well as a colour wheel (on colour trials) or black wheel (on location trials; see Figure 5). One of the four memoranda was probed for recall based on location; for example, if the bottom-right stimulus location was probed, the participant was required to recall the feature value of the relevant dimension for the stimulus in that position on the memory display (i.e. recall the colour or orientation, depending on the current trial’s cue).
Participants responded by moving the mouse cursor to the location on the wheel which they believed best matched the feature value of the probed stimulus. When the mouse was clicked over the wheel, the probed stimulus would take on the feature value under the cursor; for example, on colour trials, if the participant moved their cursor towards a pinkish hue, the probe stimulus would take on the same hue (see Figure 5). If the participant moved the mouse to a different location whilst holding the click down, the probe would dynamically take on the feature value of what colour the mouse was over. The participant finalised their response by pressing the space bar; responses were not time-limited so participants were free to move their cursor to different locations on the wheel prior to selecting their final response. However, participants were instructed to respond as quickly and accurately as possible. On each trial, the response location of the finalised response (in degrees) was recorded, as well as response time. Once a response was provided, the display was removed for 500 ms, after which time a fixation cross appeared for 500 ms, and then the cue for the next trial was presented.
As the relevant feature dimension was randomly selected, across participants there were roughly equal number of repetition trials (M = 192, SD = 9.98, min. = 170, max. = 211) and switch trials (M = 188, SD = 9.76, min. = 171, max. = 211). Parameter recovery simulations have shown that around 200 trials provide very accurate parameter estimation of the three-component model (Grange & Moore, 2022).
Results
Prior to analysis, participant exclusion checks were conducted. First, trials in which the response time was shorter than 150 ms or longer than 2.5 standard deviations above the mean per participant per cell of the design were removed. Then, the three-component mixture model was fitted to individual participant data (see the “Mixture Modelling” section for details), and participants who had a probability of guessing (as estimated via the
Behavioural Analysis
There was extreme evidence that response times were shorter for dimension repetition trials (M = 2,559, SE = 110) than for dimension switch trials (M = 2,638, SE = 115),
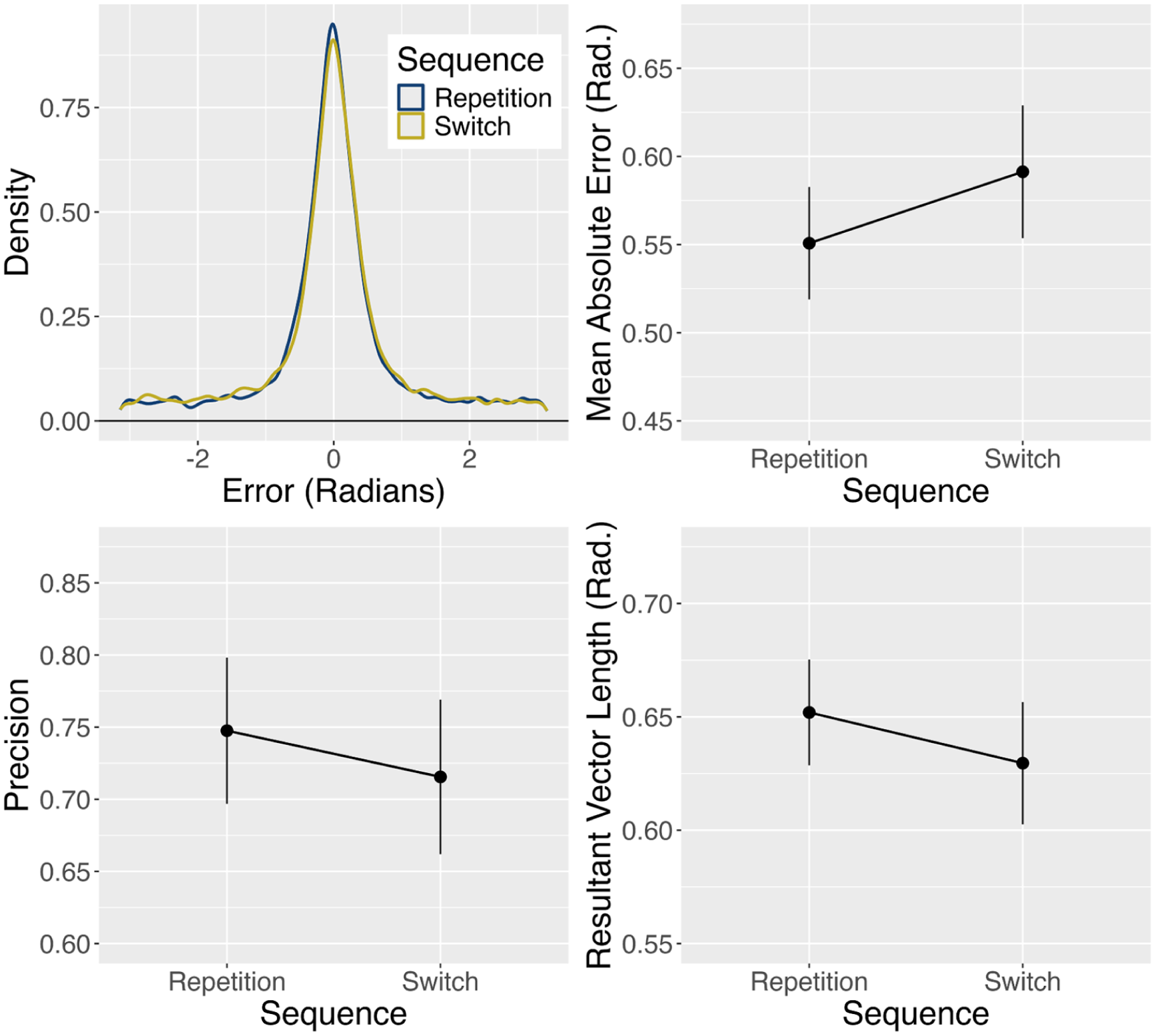
Model-free summary statistics of response error from Experiment 3. Error bars denote ± one standard error around the mean.
Response error was summarised using the model-free metrics of precision, mean absolute error, and resultant vector length (calculated via the mixture R package, Grange & Moore, 2023): Mean absolute error is the circular mean of the (absolute) response error, with higher values reflecting larger response error; precision is the reciprocal of the standard deviation of responses (for circular data) accounting for values expected by chance 4 ; and resultant vector length measures response error variability, with values close to one indicating little error variability and responses close to zero indicating response errors spread uniformly across the circle.
These metrics are summarised in Figure 6 and were analysed via Bayesian paired samples t-tests (one for each metric). Analysis showed a strong effect of sequence for mean absolute error (
Mixture Modelling
The three-component model of Bays et al. (2009) was fitted to individual participant data per sequencing condition using the R package mixtur (Grange & Moore, 2023). The model fitting provided—for each participant and for each level of dimension sequence—three model parameters:
Mean parameter values can be seen in Figure 7. Analysis of
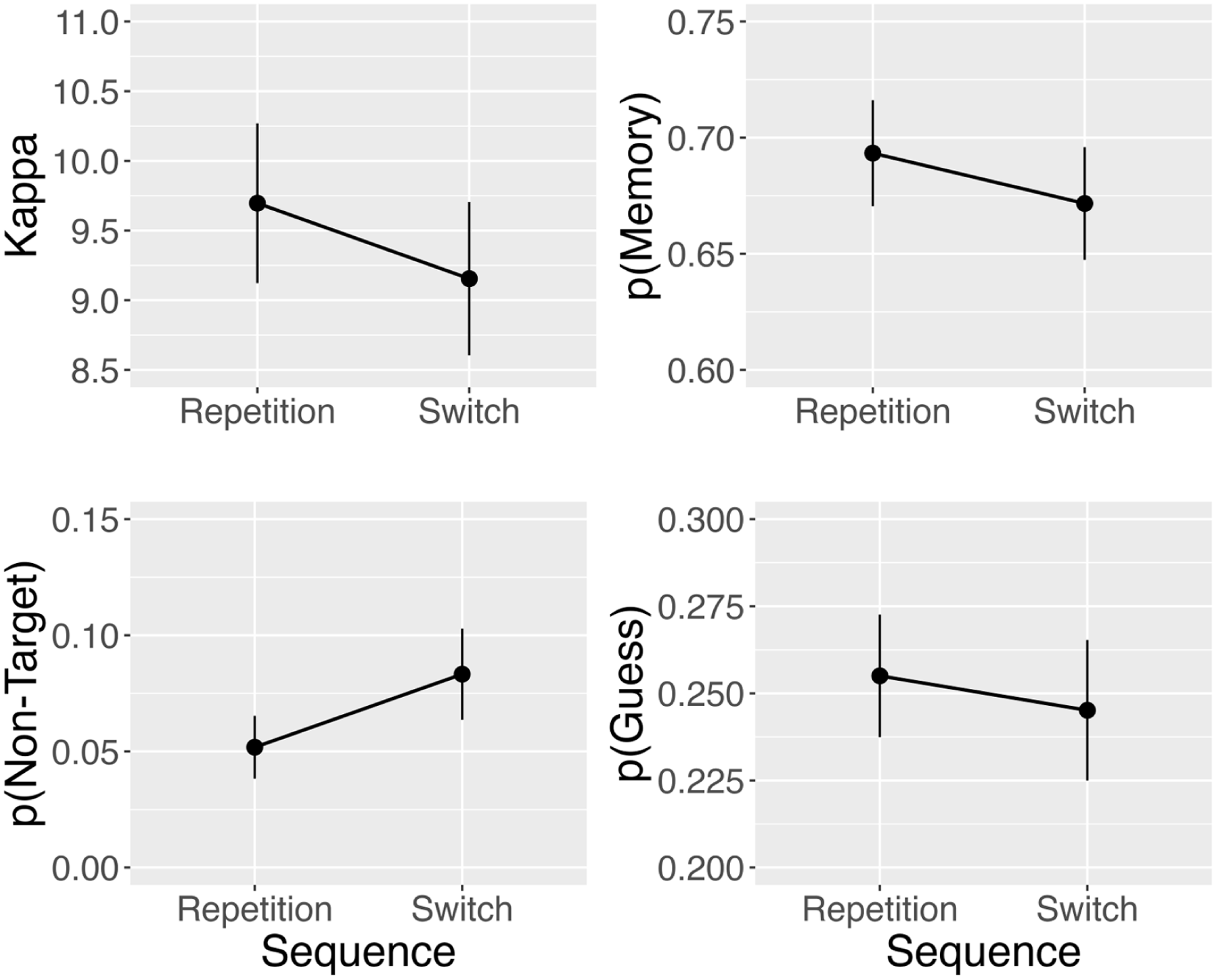
Mean parameter estimates from the three-component mixture model. Error bars denote ± one standard error around the mean.
Discussion
Experiment 3 generalised the change detection findings from Experiments 1 and 2 to a delayed estimation paradigm. Results showed a strong effect of dimension switching on mean absolute error, replicating and extending the findings from Experiments 1 and 2 of impaired visual short-term memory performance on dimension switch trials relative to dimension repetition trials. The use of a delayed estimation task allowed us to apply the three-component model of Bays et al. (2009) to explore potential mechanistic explanations of the source of the dimension switch cost to vSTM. This model decomposes response errors in the delayed estimation task into (a) memory imprecision due to noisy internal representations of the true feature value, (b) erroneous recall of a non-probed object’s feature value, and (c) random guessing when memory fails.
Results from the modelling showed a selective—albeit modest—increase in the probability of retrieving a non-target feature value on dimension switch trials relative to dimension repetition trials. No other parameter was impacted by dimension switching, suggesting that dimension switching did not affect the quality of memory representation (i.e.
General Discussion
The goal of the present study was to investigate how changes in task demands within dynamic environments impacts the allocation of limited visual short-term memory (vSTM) resources to task-relevant features. Previous work has established that resource allocation is responsible for the fidelity of feature representations in memory, with features receiving more resources being represented in memory with greater precision (Bays & Husain, 2008; Bays et al., 2009, 2024; Ma et al., 2014). Therefore, these limited resources must be accurately applied to task-relevant features so that task-irrelevant features do not consume limited resources. We embedded two classic vSTM paradigms within a task switching paradigm where the relevant feature dimension could repeat (e.g. colour–colour) or switch (e.g. colour–orientation) from that of the previous trial. On dimension switch trials, some degree of cognitive control is required to update the relevant task set (Grange, 2025) so that the limited resources are applied to the correct (i.e. goal-relevant) feature dimension.
We found a clear negative impact of dimension switching on vSTM performance that replicated and generalised across both change detection (Experiments 1 and 2) and delayed estimation (Experiment 3) paradigms, as well as across different stimulus types (Experiments 2a–2d). This impairment was evidenced by reduced accuracy and sensitivity (i.e.
Theoretical Interpretation
Our main expectation in this study—as outlined in the introduction—was that dimension switching would lead to weaker memory representations due to suboptimal encoding of memoranda caused by a reduction in—or a misallocation of—memory resources (Bays & Husain, 2008; Bays et al., 2009). The reduction in sensitivity (
As the task demands are quite different between change detection and delayed estimation (Lin & Oberauer, 2022), it is possible that the negative impact of dimension switching on vSTM performance may arise from different mechanisms in each paradigm. However, we propose that the collective findings can be explained by binding errors induced by incomplete attentional reconfiguration of the relevant task set and/or persisting activation of the irrelevant (but previously relevant) task set on switch trials. Binding is a core mechanism in many formal models of vSTM (Oberauer & Lin, 2017; Schneegans & Bays, 2017, 2019). For example, in the conjunctive coding model of Schneegans and Bays (2017), multi-feature objects are encoded and maintained via separate neural population codes that bind each single feature dimension to location (e.g. there is one conjunctive code binding colour and location, and another conjunctive code binding orientation and location). On switch trials, incomplete reconfiguration of the relevant feature dimension and/or persisting activation of the previous (but now irrelevant) feature dimension may induce noise into the binding process.
This framework naturally explains the observed increase in non-target responses in the delayed estimation task in Experiment 3 (as measured by the
The framework can also explain the pattern of results found for change detection (i.e. reduction in
The conjunctive coding framework may therefore help to provide a unified account of the varied findings across experiments, suggesting a common underlying mechanism in which incomplete reconfiguration of the relevant feature dimension and/or persisting activation of the irrelevant feature dimension leads to degradation of conjunctive representations. We acknowledge, however, that this framework provides a natural explanation for the delayed estimation data and that its application to the change detection data remains tentative and requires further research. Such work should include formal modelling of both change detection and delayed estimation data (Lin & Oberauer, 2022; e.g. using the interference model framework, Oberauer & Lin, 2017), which will be valuable to test whether a single mechanism can explain dimension switch costs across vSTM paradigms.
Object-Based vs. Feature-Based Representation
Although the current study was not designed to address whether vSTM representations are object-based or feature-based, our finding of a robust dimension switch cost contributes to this debate. Specifically, we suggest that our findings are compatible with feature-based representation in vSTM. If memoranda were represented at the object level (D. Lee & Chun, 2001; Luck & Vogel, 1997; Ngiam et al., 2024; Ramaty & Luria, 2025; Sone et al., 2021; Vogel et al., 2001), then both feature dimensions (colour and orientation) of each stimulus should be encoded together regardless of the cued dimension. As a consequence, the object-based account makes a prediction of no switch cost: Once integrated objects are stored, all of their features should be equally available, and switching the relevant dimension should not impair performance. In contrast, the feature-based account (Bays et al., 2011, 2024; Brady et al., 2011, 2024; Brown et al., 2021; Fougnie et al., 2010; Li et al., 2022; Markov et al., 2019, 2021; Marshall & Bays, 2013; Shin & Ma, 2016, 2017) does predict a switch cost because on switch trials the system must prioritise resource allocation to the currently cued feature dimension which can be error-prone due to either incomplete reconfiguration of the currently relevant task set or persisting activation from the previous—and now irrelevant—task set.
Our findings are therefore hard to reconcile with object-based representation in vSTM and instead favour feature-based representation. However, it is possible that the representation could be object-based and switch costs emerge at the decision or response stage rather than during encoding and/or maintenance.
Future Research and Limitations
Our main theoretical explanation requires further empirical work supplemented by fitting of explanatory models, which—in contrast to measurement models that aim to quantify latent psychological processes—provide mechanistic explanations for behaviour (for a discussion of measurement vs. explanatory models, see Oberauer & Lin, 2017). One obvious candidate is fitting the extended neural population model of Schneegans and Bays (2017; which extends the neural population model of Bays, 2014), which would allow a more direct assessment of our proposal that dimension switching impacts feature–location binding in conjunctive coding. Lin and Oberauer (2022) have provided a framework in which explanatory models of vSTM can be applied to a variation of the change detection paradigm by extending the interference model of Oberauer and Lin (2017), which would facilitate our efforts to integrate our findings between change detection (which we could not model given our design 6 ) and delayed estimation (which we could model). This is an important next step in the research programme.
Another avenue for future research is to fit variants of the three-component model to our delayed estimation data (Experiment 3). For example, the model we fitted (Bays et al., 2009) assumes fixed precision of memory representations across memoranda and across trials [i.e. fixed
Future modelling work could also benefit from taking into account response time. In our studies, we consistently found robust switch effects in response time, which is a common outcome variable in studies of task switching. In the task switching literature, response time is the primary dependent variable, and switch costs are thought to reflect the delay caused by the time it takes to reconfigure task set parameters (Rogers & Monsell, 1995; see Grange, 2025), the time it takes to resolve proactive interference from the previously relevant task (Allport et al., 1994), or both (Meiran, 2000; Meiran et al., 2000). We refrained from interpreting these switch costs as response time is not a commonly used dependent variable in vSTM studies. However, they could provide an important constraint on theoretical explanations of our effects. Recent extensions of the diffusion framework—which is a prominent modelling architecture in speeded decision-making tasks (Voss et al., 2013)—to data from the delayed estimation paradigm uses the so-called circular diffusion model (Smith, 2016; Smith et al., 2020) which provides a theory of both speed and precision of responses. Such a framework would allow us to incorporate effects of dimension switching on response time into our theoretical explanations, and remains an important avenue for future research.
The current study’s broader contribution is to the potential for theoretical integration across domains in cognitive science (visual short-term memory and cognitive control during task switching) to provide complementary perspectives. For example, working memory gating models (Chatham & Badre, 2015; Chatham et al., 2014; O’Reilly & Frank, 2006) propose that cortico-striatal structures provide gating mechanisms that control what information enters working memory, and of that information what is then allowed to influence ongoing behaviour. In our study, the observed switch cost could be explained by a failure to effectively gate the currently relevant feature dimension allowing the intrusion of the irrelevant feature dimension to vSTM. In addition, the dual mechanism theory of cognitive control framework (Braver, 2012) proposes that control processes act in a proactive or a reactive manner. The observed switch costs in the current study, therefore, may reflect a failure to engage proactive control (leading to incomplete reconfiguration of the currently relevant dimension, DeJong, 2000), thereby necessitating late reactive control. In the task switching literature, there is a rich history of distinguishing between proactive control (i.e. task-set reconfiguration theories, Rogers & Monsell, 1995) and reactive control (i.e. overcoming the effects of task-set inertia, Allport et al., 1994). The current paradigm, therefore, has the potential to speak to these broader concepts via empirical and theoretical integration.
In terms of limitations, it is important to note that there was some inconsistency in results in the change detection experiments. Specifically, whilst Experiment 1a found switch costs in accuracy and sensitivity, this was not the case for Experiment 1b. However, there were very strong switch cost effects for these outcome variables in Experiment 2. In addition, there was no clear statistical effect (although there was a numerical effect) of bias in Experiment 1, but this was strong in Experiment 2. We view Experiment 2 as the better experiment—and hence weight our interpretations more from this experiment—for several reasons. First, Experiment 1 was primarily exploratory as it was the first in this research programme. We therefore had fewer participants, and as such, the observed inconsistencies (both across Experiments 1a and 1b, as well as across Experiments 1 and 2) could be a power issue. Experiment 2 had much better power—both within each sub-experiment individually, but also collectively as data were pooled across sub-experiments in the analysis. Contributing to lower power was the fact that we had three levels of dimension sequence in Experiment 1 (pure repetition, mixed repetition, and switch), meaning each condition had fewer trial numbers (Experiment 1 had 150 pure block trials, and 300 mixed block trials; each sub-experiment of Experiment 2 had 400 mixed block trials, and there were 4 sub-experiments). It is likely, therefore, that design issues contributed to the lack of consistency in some of the findings. It is important to note, though, that in Experiment 2, there were strong switch costs in all outcome variables, and these switch costs did not vary across subexperiment.
Although the switch cost was robust across the vast majority of experiments (e.g. Experiment 1a, Experiments 2a–2d, and Experiment 3), the magnitude of the effects observed is rather small. Design aspects could have reduced the magnitude of these effects. For example, in the change detection experiments, the test screen on the current trial appeared 3,700 ms after the response from the previous trial (taking into account inter-trial intervals, cuing intervals, fixation time, encoding time, etc.). In the delayed estimation task, whilst the time between the response to the previous trial and the onset of the test screen on the current trial was much shorter (2,200 ms), it is still much longer than typically seen in task-switching studies. Whilst we made these design choices to be consistent with timings typically found in vSTM studies, research in task switching has consistently shown that increasing the inter-trial intervals can have strong effects on the reduction of the magnitude of switch costs (Kiesel et al., 2010; Meiran, 2000; Rogers & Monsell, 1995; Vandierendonck et al., 2010). Thus, the effect size of the observed switch costs is likely reduced by these design factors, and future work should look to find ways to reduce the inter-trial intervals without compromising the ability to compare findings to the broader vSTM literature.
We also recruited a wide age range of participants (18–60 years). Although age was not a primary variable of interest in the current study, it remains possible that age-related changes to cognitive control and visual short-term memory could have impacted our results. Future research should either restrict the age range further or include participant age as an additional predictor in the analysis.
Another limitation is that—like many studies of vSTM—the stimuli we employed are rather basic and abstracted away from the complexities of real-world items. Recent research has been interested in adapting studies of visual memory to incorporate more complex, meaningful stimuli (Brady et al., 2019, 2024), and research has generally shown that memory is enhanced for such realistic stimuli (Chung et al., 2024; Markov et al., 2021; Sahar et al., 2024). The extent to which our findings generalise to such contexts remains an important avenue for future work.
Conclusion
In conclusion, our study is, to our knowledge, the first to explore the impact of dimension switching on visual short-term memory performance. Collectively, the results provide evidence for a cost to performance on dimension switch trials. We suggest our findings reflect a limitation of dynamic prioritisation of relevant feature dimensions that impacts feature–location binding, and therefore that visual short-term memory is sensitive to attentional control failures, not just capacity limits.
Supplemental Material
sj-pdf-1-qjp-10.1177_17470218251404415 – Supplemental material for The Impact of Dimension Switching on Visual Short-Term Memory
Supplemental material, sj-pdf-1-qjp-10.1177_17470218251404415 for The Impact of Dimension Switching on Visual Short-Term Memory by Stuart B. Moore and James A. Grange in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
Components of the work were presented at the 2021 and 2022 Spring meetings of the Experimental Psychology Society.
Author Note
For the purposes of open access, the authors have applied a Creative Commons Attribution (CC-BY) licence to any Accepted Author Manuscript version arising from this submission.
Author Contributions
The authors made the following contributions. Stuart B. Moore: Conceptualisation, Formal analysis, Investigation, Methodology, Writing (Original draft preparation), Writing (Review & editing); James A. Grange: Conceptualisation, Formal analysis, Funding acquisition, Methodology, Supervision, Writing (Original draft preparation), Writing (Review & editing).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a PhD studentship (funding obtained by JAG and awarded to SBM) from the School of Psychology, Keele University.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.