
Abstract
In a typical item-method directed forgetting task, study words are presented one at a time, each followed by an instruction to Remember or Forget. Subsequent recognition shows a directed forgetting effect, with better recognition of to-be-remembered words than to-be-forgotten words. This study determined whether recognition depends only on the intention to remember or forget or also on the words used to frame the trial-by-trial instructions or task. In Experiments 1 and 3, participants were instructed, trial-by-trial, to Remember and Forget, Remember and Don’t Remember, Don’t Forget and Forget, or were told that some words were Important and that others were Not Important. There was no compelling evidence that the directed forgetting effect was altered by the specific words used as these trial-by-trial instructions. However, in Experiment 2, a smaller directed forgetting effect occurred when the task was framed as requiring participants to Remember unless instructed otherwise, compared to when it was framed as requiring participants to Forget unless instructed otherwise. These findings emphasize the freedom that researchers have for deciding how to frame trial-by-trial instructions and the caution they must use in deciding how to frame the task itself.
Control over memory encoding is studied using an item-method directed forgetting paradigm. On study trials, participants are presented with items one at a time, each followed by an instruction to Remember or by an instruction to Forget (e.g. Basden et al., 1993). On subsequent test trials, a directed forgetting effect is revealed as better recall or recognition of to-be-remembered (TBR) items compared to to-be-forgotten (TBF) items (see MacLeod, 1998 for a review). This directed forgetting effect is not attributable to demand characteristics (MacLeod, 1999) but instead reflects selective rehearsal of TBR items over TBF items (e.g. Basden & Basden, 1998). The notion is that participants must pay attention to each study item as it is presented and then maintain that item in working memory until they receive the memory instruction (e.g. Gardiner et al., 1994; Hsieh et al., 2009; Paz-Caballero et al., 2004). If the instruction is to Remember, the participant engages in elaborative rehearsal of that item (Hsieh et al., 2009), thinking about its meaning and connecting this to other knowledge stored in long-term memory (Montagliani & Hockley, 2019). If the instruction is to Forget, the participant stops ongoing rehearsal of the TBF item – whether through an inhibitory process (Hubbard & Sahakyan, 2021; Oehrn et al., 2018; Rizio & Dennis, 2012; Ten Oever et al., 2021) and/or a withdrawal of attentional resources (e.g. Fawcett & Taylor, 2010; Taylor, 2005; Taylor & Fawcett, 2011).
The directed forgetting effect has been revealed for many different types of study item, including words and pictures (Quinlan et al., 2010), photographic images (Hauswald & Kissler, 2008), emotionally and expressive neutral human faces (Corenblum et al., 2020; Quinlan & Taylor, 2014), unnameable symbols (Fawcett et al., 2016; Hourihan et al., 2009; Lo et al., 2024) and videos (Fawcett et al., 2013a, 2013b). This effect is also robust across stimuli used as the Remember and Forget instructions. For example, directed forgetting effects occur when instructions consist of the words remember and forget (e.g. Scotti & Maxcey, 2022) or their logographs (Lee, 2012); are represented by the language-specific first letter of these words (e.g. Hauswald & Kissler, 2008), whether presented singly (e.g. R, F; Ahmad et al., 2019) or in a repeating string (e.g. RRR. . ., FFF. . .; Cheng et al., 2012; Quinlan et al., 2010); and also when they are mapped onto high- and low-frequency tones (Taylor, 2005; Taylor & Fawcett, 2011) or onto coloured symbols (e.g. Chiu et al., 2021; Fawcett & Taylor, 2010; Rizio & Dennis, 2012; Ten Oever et al., 2021) or outline frames (e.g. Fawcett et al., 2013b). There has not, however, been a systematic investigation into whether the directed forgetting effect is influenced by the specific words used to describe the memory task, even though verbal framing is known to influence memory directly as well as indirectly.
With respect to direct effects of verbal framing on memory, Loftus and Palmer (1974) showed that the words used to describe a witnessed event – whether one car smashed into versus contacted another – can influence later reports of whether there was broken glass at the scene. Less directly, forming an intention to forget a word or face leads participants to emotionally devalue that stimulus – for example, rating it as less pleasant – than if they form an intention to remember that item (Vivas et al., 2016). This tendency to devalue TBF items likely exacerbates a forgetting bias in which items that are actually forgotten – a fate more likely for TBF items than TBR items – are deemed less important than those that are remembered (Castel et al., 2012). And, when importance is manipulated by assigning arbitrary point values to words, participants selectively remember more high-value words when their goal is framed in terms of maximizing the total points of items remembered than when their goal is framed in terms of minimizing the total points of items forgotten (Murphy & Knowlton, 2022).
Underscoring how verbal framing could potentially influence the strategies participants use to remember and forget, there is also substantial evidence that participants make memory predictions differently depending on how they are asked to make those predictions. One such prediction is a judgement of learning (JOL), which requires participants to predict how likely it is that they will remember a given item. JOLs are generally considered to be the product of an inferential process that combines various types of cues available at the time of judgement (see Koriat, 1997), based both on beliefs about various memory factors and the current experience with the stimulus being judged. However, participants can instead be asked to predict how likely it is they will forget a given item, which is referred to as a judgement of forgetting (JOF; e.g. Finn, 2008). With many specific exceptions, participants tend to be overconfident when providing JOLs, in that their subsequent memory performance is typically somewhat lower than their predictions, but less so when providing JOFs, after inverting the judgement scale to align with memory performance measures (e.g. Serra & England, 2012). In other words, participants seem to use the prediction scale differently for JOFs than for JOLs (England et al., 2017), potentially due to how the framing influences whether specific beliefs about memory (and forgetting) are used when making the judgement (Dunlosky & Tauber, 2014). This makes it clear that participants do not necessarily view ‘Remember’ and ‘Forget’ as the inverse of one another and gives us good reason to believe that there may be verbal framing effects that influence how participants allocate their cognitive processing in the context of an item-method directed forgetting task.
The goal of the present study was straightforward: To determine whether the verbal descriptors used to designate words as TBR versus TBF on a trial-by-trial basis, or those used to frame the task itself, influence the magnitude of the directed forgetting effect. In Experiment 1, participants were presented with a word, followed with equal probability by one of two visual symbolic instructions (<::>, >::<). In a between-subjects manipulation, these instructions were mapped onto instructions to Remember and Forget (R-F), to Remember and Don’t Remember (R-DR) or to Don’t Forget and Forget (DF-F). In Experiment 2, a single symbolic memory instruction appeared on a random half of the study trials, with no instruction on the other half of trials. In a between-subjects manipulation, the default task was to Remember (R-default) or to Forget (F-default), with the appearance of the instruction serving as an explicit countermand to that default task. As such, in the R-default group, participants were required to Remember, unless countermanded by an instruction to Forget; in the F-default group, participants were required to Forget, unless countermanded by an instruction to Remember. In Experiment 3, participants were again presented with an instruction on every trial, with this designating study words as either Important or Not Important for a later memory task, with no explicit reference made to either remembering or forgetting.
Experiment 1
In Experiment 1, a random half of the study words were designated TBR, and the other half TBF. Symbolic instructions (<::> and >::<) were used to make these designations. Across different groups of participants, these were described as Remember and Forget (R-F) instructions as per a typical item-method directed forgetting task, as Remember-Don’t Remember (R-DR) instructions, or as Don’t Forget-Forget (DF-F) instructions.
Method
Participants
Undergraduate Psychology and Neuroscience students were recruited online, using Sona-Systems participants management software and were awarded 1 course credit point in exchange for participation. Before conducting the experiment, an a priori power analysis was conducted using G*Power 3.1 (Faul et al., 2009). Specifying a repeated measures within-between interaction with a medium effect size of 0.25, a standard alpha level of .05, and three groups with two measurements each (presumed correlation of .5 for repeated measures), the required sample size was 42. Accordingly, the goal was to stop data collection once we obtained data from at least 42 participants in each of the 3 between-subjects conditions. In Sona-Systems, participants who follow a link to an online experiment count against the specified recruitment target, even if they never actually participate before the link availability ends. For this reason, we did not limit recruitment to our intended sample size. Instead, we periodically downloaded and counted the number of datasets contributed by participants who not only gave informed consent to participate, but who also gave explicit permission to use their data for research purposes. We stopped data collection as soon as these counts indicated that we had met or exceeded the intended sample size in all three groups. This stopping rule was triggered when we had a total of 55 datasets in the R-F condition, 52 in the R-DR condition and 45 in the DF-F condition.
Stimuli and apparatus
The graphical user interface provided by the Builder feature in PsychoPy version 2021.2.3 (Peirce et al., 2019) was used to generate python3 code. This code was customized as needed and converted automatically to JavaScript from within the Builder interface. The JavaScript code was uploaded and synchronized to the Pavlovia server, where it was used to control online stimulus presentation and data collection. To launch the experiment, participants clicked a URL from within Sona-Systems. Doing so generated a random participant number that was communicated to Pavlovia for coordinating the award of credit points and used to select a stimulus file configuration as described below.
A list of 816 nouns downloaded from the MRC Psycholinguistics database (Coltheart, 1981; Wilson, 1988) were sorted in descending order based on concreteness, familiarity and Kuçera-Francis word frequencies, with the top 192 words selected for use in this study. Through 100 iterations, these 192 words were randomized before being written to stimulus files numbered 00 to 99. These stimulus files were assigned sequentially to the REMEMBER-FORGET (R-F), REMEMBER-DON’T REMEMBER (R-DR) and DON’T FORGET-FORGET (DF-F) conditions. This resulted in a unique randomization of words to each of 34 stimulus files in the R-F condition and 33 in each of the other two conditions. This unequal assignment of files to conditions was unavoidable: The last two digits of the participant number generated by Sona-Systems were used to select a stimulus file, such that the stimulus files needed to be numbered from 00 to 99 despite the fact that there were only three between-subjects conditions. In any case, because participant numbers were randomly assigned, there was no inherent bias in the selection of stimulus files.
Of the 192 words randomly output to each of the stimulus files, a total of 96 were presented on the study trials. A random half of these words (48) were designated TBR and the other half (48) were designated TBF. The remaining 96 words served as unstudied foil words for the recognition test. All study words and test words were presented in lowercase with vertical height set to 10% of the device screen used to run the experiment.
Verdana was the default font used for all text. Text for the informed consent form and debriefing was presented in white on a black background. All other instructions and prompts were presented in black on a white background. In all cases, the background was set to fill the full window, with default to a full-screen view. On study trials, fixation crosshairs (‘+’) were presented in grey and then changed to blue to signal the start of the trial; all other study trial and test trial stimuli were presented in blue. The memory instructions consisted of two strings of identical symbols presented in different configurations: ‘<::>’ was used to designate study words as TBR such that it mapped onto REMEMBER and DON’T FORGET instructions; ‘>::<’ was used to designate study words as TBF such that it mapped onto FORGET and DON’T REMEMBER instructions.
Procedure
Participants were presented with an online informed consent form and asked to press ‘y’ (for ‘yes’) or ‘n’ (for ‘no’) to explicitly give or withhold their consent to participate; a ‘n’ response caused the software to exit without saving any information. In a similar fashion, participants were likewise asked to give explicit consent to use their data for research purposes, and all data reported herein received permission for use.
Written instructions indicated that participants would be presented with study trials followed by a memory test, with instructions for the memory test deferred until completion of the study trials. Instructions for the study trials included the visual depiction shown in Figure 1, along with a narrative description of key trial events. In the R-F condition ‘<::>’ was described as a REMEMBER instruction and ‘>::<’ as a FORGET instruction; in the R-DR ‘<::>’ was described as a REMEMBER instruction and ‘>::<’ as a DON’T REMEMBER instruction; and, in the DF-F condition ‘<::>’ was described as a DON’T FORGET instruction and ‘>::<’ as a FORGET instruction. This mapping of TBR (‘<::>’) and TBF (‘>::<’) instruction to verbal labels was the only difference between conditions: All stimuli, instructions and trial events were otherwise identical.
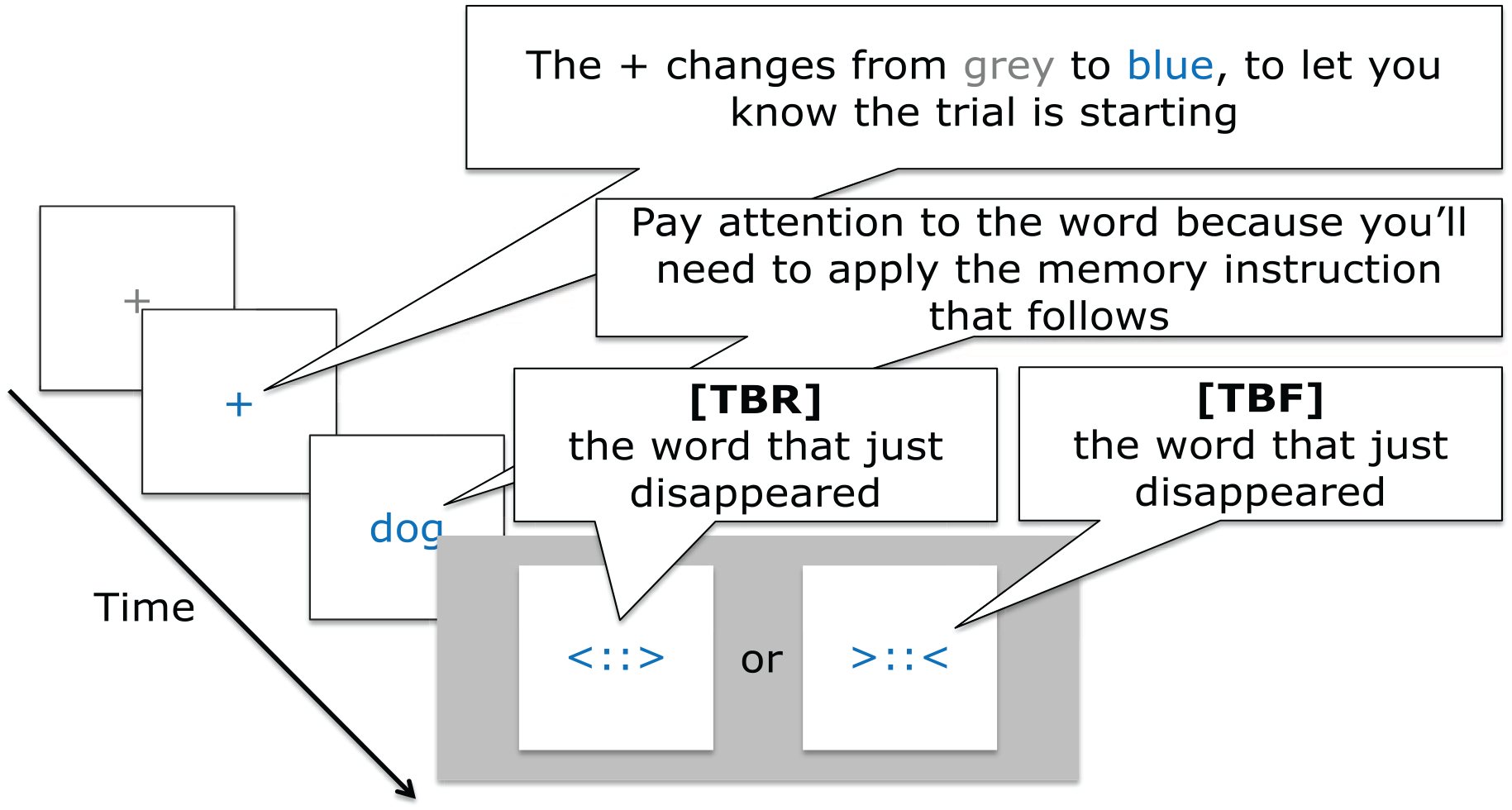
Study trial events with [TBR] representing to-be-remembered instructions and [TBF] representing to-be-forgotten instructions. As described in-text, three between-subjects conditions presented the following TBR-TBF combinations: REMEMBER-FORGET; REMEMBER-DON’T REMEMBER and DON’T FORGET-FORGET. Participants were presented with this same depiction in the context of the study trial instructions, except that the relevant instructions were presented where the placeholders are indicated in this figure.
Familiarization trials
Before proceeding to the study phase, participants were presented with 20 instruction familiarization trials. Each trial started with a 1.5 s delay during which the screen remained blank. On a random half of these trials, the TBR instruction then appeared alone in the centre of the screen; on the other half of these trials, the TBF instruction appeared. After 1 s, a prompt appeared beneath the instruction to remind the participant of the mapping used in the given experimental condition (e.g. ‘<::>’ prompted with ‘REMEMBER’ in the R-F and R-DR conditions and with ‘DON’T FORGET’ in the DF-F condition). The instruction and prompt remained onscreen together for 2 s before the start of the next familiarization trial. No study words were presented on these trials, and therefore no memory was required; only the symbolic instruction and its verbal referent were presented.
Study trials
Following the familiarization trials, participants were alerted to the start of the study trials and presented again with the visual depiction of the study trials (see Figure 1) and the verbal narrative describing trial events and mapping of TBR and TBF instructions to verbal labels. As shown in Figure 1, at the start of each trial, a grey fixation stimulus (‘+’) appeared in the centre of the screen in for 1 s before changing to blue and remaining visible for another 1 s. After a 500 ms delay, this was replaced by a study word that remained visible for 1 s. Then, after a 1 s delay, the memory instruction appeared for 1 s, after which the screen went blank and remained so for 2.5 s until the end of the 8 s trial.
Recognition test
Following the last study trial, participants were instructed that they would be presented with words, one at a time, on a recognition test. The instructions emphasized that – regardless of the memory instruction presented at study – if participants recognized a word from the earlier study trials, they were to depress the ‘y’ (‘yes’) key on the computer keyboard; if not, they were to depress the ‘n’ (‘no’) key. The trial would not advance until a single ‘y’ or ‘n’ response was input to the keyboard. Although there was no imposed time limit for making this recognition response, the time to do so was nevertheless recorded and used in an outlier check (described later) to remove participants who might have tended to respond too fast for lack of care in evaluating their memory contents or too slow possibly due to distraction or lack of engagement with the online task. A total of 192 test trials were presented, consisting of all 96 words presented at study randomly intermixed with the 96 unstudied foil words.
Data analysis
For the data analysis, recognition test trials were conceptualized as having one within-subjects factor with two levels (Memory Intention: TBR, TBF) and one between-subjects factor with three levels (Designation: R-F, R-DR, DF-F). Data were collated in R Studio 2024.09.0+375 running R 4.4.2 (R Core Team, 2024) and loaded with packages dplyr (Wickham, François et al., 2023), ggplot2 (Wickham, 2016), plyr (Wickham, 2011), stringr (Wickham, 2023) and tidyr (Wickham, Vaughan et al., 2023), with ancillary analyses performed using kSamples (Scholz & Zhu, 2023), purrr (Wickham et al., 2025, 2023), and afex (Singmann et al., 2024). Descriptive statistics, t-tests, and Analyses of Variance (ANOVAs) were calculated using jamovi 2.3.28.0 (The Jamovi Project, 2022), which was built using R version 4.1 (R Core Team, 2021) and the afex (Singmann, 2018) and emmeans (Lenth, 2020) packages, and loaded with the jsq-Bayesian Methods module developed by the JASP Team (2018) and built using the BayesFactor package (Morey & Rouder, 2018; see Rouder et al., 2009).
Results
During data pre-processing, we determined that 3 participants in the R-F group, 8 in the R-DR group and 3 in the DF-F group had incomplete data files, operationally defined as having finished fewer than 60% of test trials. In most cases, this was due to participants abandoning the experiment less than halfway through the study trials; in cases where these participants proceeded to the recognition trials, they completed on average fewer than 10 trials. All other datasets were confirmed to have the full complement of both study and test trials.
Given that directed forgetting effects in an item-method task are associated with differences in attention within (e.g. Fawcett & Taylor, 2010; Lee, 2018; Taylor, 2005; Taylor & Fawcett, 2011), and possibly also across study trials (e.g. Lee, 2012), we did not include explicit attention checks, lest they interact with our memory instructions. Instead, we presumed that better subsequent recognition of TBR words compared to TBF words would serve as prima facie evidence that participants engaged with the study task. To assess engagement with the recognition test, we performed an outlier check on recognition reaction times. We reasoned that participants who were unusually slow to make a recognition decision might have been distracted or otherwise not fully engaged with the task. To perform this outlier check, we collapsed over all participants across all three groups to calculate a single mean and standard deviation for recognition response times (M = 1.3 s, SD = 1.5 s). Outliers were identified based on individual means that were 2 standard deviations higher or lower than the means of all participants. Long recognition response times led to data being excluded for one participant in R-F group (11.9 s) and one in the DF-F group (13.0 s). After these exclusions, there were a total of 51 participants in the R-F group, 44 in the R-DR group, and 41 in the DF-F group. Given that our sample sizes were selected based on an assumption of equal group sizes, we opted to match the smallest of these groups and achieve equal sample sizes for subsequent analyses. Accordingly, a random 41 data files from each of the R-F and DF-F groups were selected for inclusion, using a fixed random seed to ensure reproducibility.
Mean recognition yes responses are shown in Table 1 as a function of word type (TBR, TBF, foil) and group (R-F, R-DR, DF-F); these responses represent hits for TBR and TBF words and false alarms to foils. A one-way ANOVA indicated that the false alarm rates did not differ significantly across the three groups, F(2,120) = 2.31, p = .10. And while an independent samples t-tests showed that the 19% false alarm rate in the R-F group was not significantly lower than the 26% false alarm rate in the R-DR group, t(80) = 1.65, p = .10, d = 0.36, it was significantly lower than the 27% false alarm rate in the DF-F group, t(78.39) = 2.06, p < .05, d = 0.45. 1 To account for differences between groups in the tendency to respond ‘yes’ on the recognition test, we subtracted the foil false alarm rate from both the TBR and the TBF hit rates on a subject-by-subject basis within each group. Because the same foil false alarm rate was subtracted from both TBR and TBF hits within a group, this correction did not affect the magnitude of the directed forgetting effect.
Mean percent ‘yes’ responses on the recognition test for all experiments.
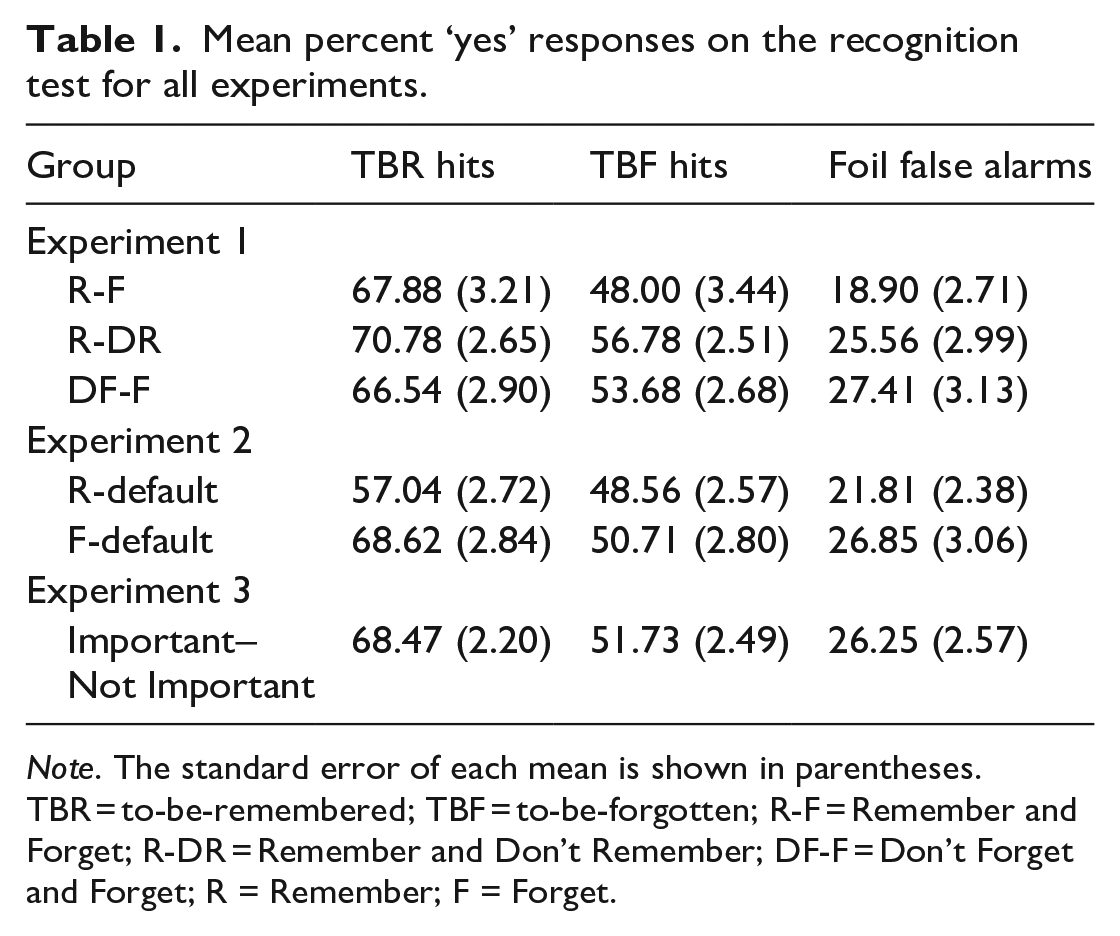
Note. The standard error of each mean is shown in parentheses. TBR = to-be-remembered; TBF = to-be-forgotten; R-F = Remember and Forget; R-DR = Remember and Don’t Remember; DF-F = Don’t Forget and Forget; R = Remember; F = Forget.
The corrected hit rates for TBR and TBF items in each group are shown in Figure 2a. Paired-samples t-tests on these data revealed a significant directed forgetting effect in all groups. Compared to TBF items, TBR word recognition was 20 percentage points higher in the R-F group, t(40) = 6.33, p < .01, d = 0.99, 14 percentage points higher in the R-DR group, t(40) = 5.60, p < .01, d = 0.87, and 13 percentage points higher in the DF-F group, t(40) = 4.75, p < .01, d = 0.74. Accordingly, an ANOVA with memory intention (TBR, TBF) as a within-subjects factor and group (R-F, R-DR, DF-F) as a between-subjects factor confirmed an overall directed forgetting effect, with significantly greater recognition of TBR items than TBF items, F(1,120) = 93.21, MSe = 160.11, p < .01,
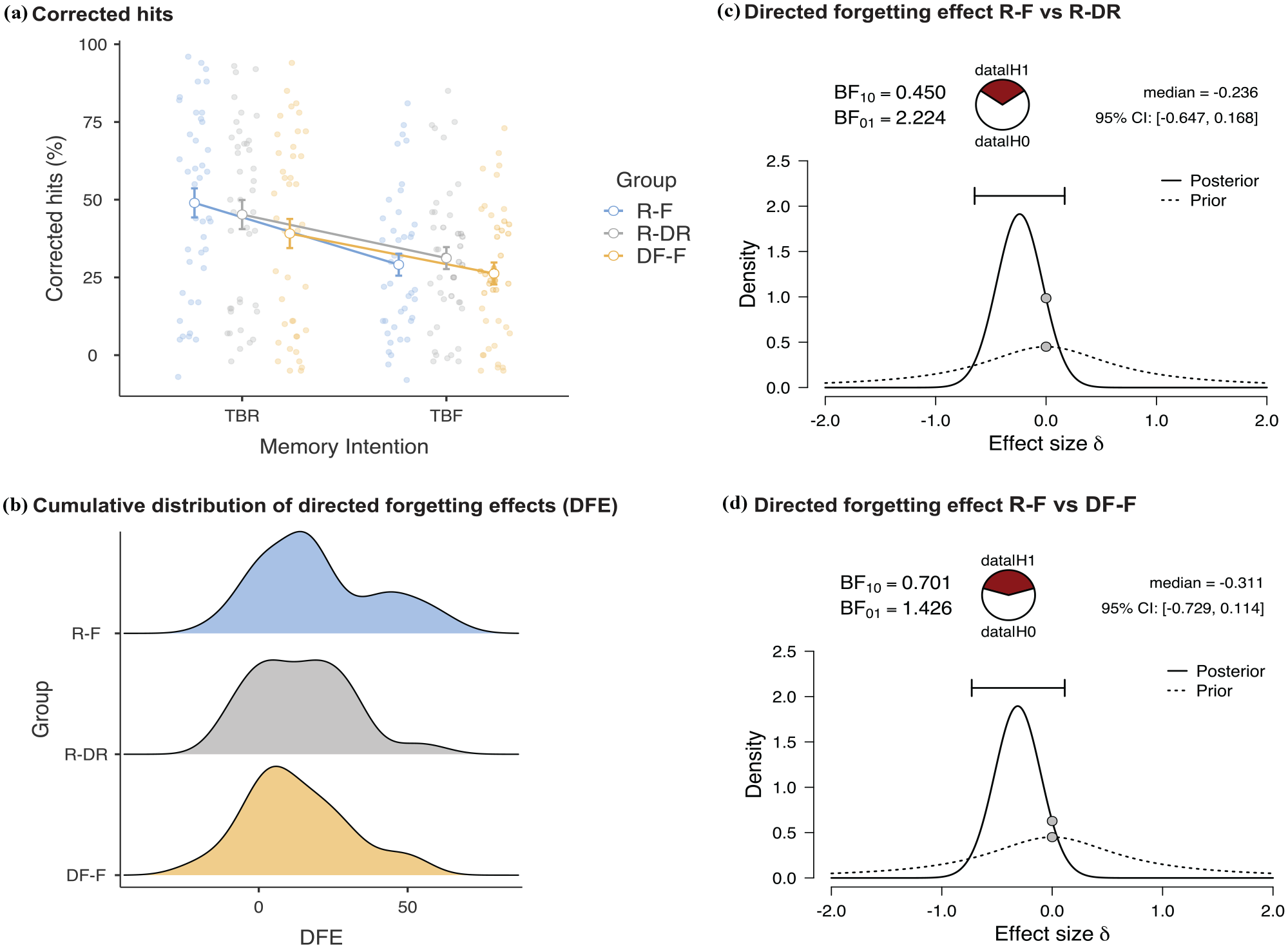
Results of Experiment 1. Depicted top left (a) are the mean corrected hit rates (hits – false alarms, %) as a function of whether the intention was for a studied word TBR or TBF and according to whether the group formed these intentions after being instructed to R-F, to R-DR or to DF-F. Anchor points for the lines that depict mean group values are jittered horizontally to enable a display of observed scores (circles) within each Group. The R-F group is jittered to the left and shown in blue, the R-DR group is in the middle in grey, and the DF-F group is jittered to the right and shown in orange. Error bars are the standard error of the mean. Maintaining the same group colour-coding, depicted bottom left (b) are the cumulative distributions of the DFEs that were calculated on a subject-by-subject basis within each group by taking the difference between the corrected TBR hit rates and the corrected TBF hit rates. Depicted top right (c) is a summary of the Bayesian independent samples t-tests of the DFE in the R-F group compared to the R-DR group. The proportion of evidence for the alternative hypothesis (H1) versus the null hypothesis (H0) is captured in the pizza plot. The prior distribution is shown with a dashed line and the posterior distribution with a solid line. On each line is a grey dot representing an effect size of 0. As explained by Goss-Sampson et al. (2020), the alternative hypothesis (of a difference between groups) is supported when the dot on the prior distribution is higher than the dot on the posterior distribution. Also shown are the median effect size and 95% credible intervals. Depicted bottom right (d) is a similar plot comparing the DFE in the R-F group to that in the DF-F group. Note that Bayesian analyses involve random sampling from the posterior distribution, which may cause variability in the distribution itself across runs, as well as in the resulting median and credible intervals.
To ensure that these ANOVA results were not specific to the particular subset of participants selected to match sample sizes across groups, we performed bootstrap resampling. For each of 10,000 iterations, we randomly selected datasets from the two larger groups (R-F, R-DR) to match the sample size of the smallest group (DF-F) and ran a mixed ANOVA (afex::aov_ez). Across all iterations, the p-value for the main effect of memory intention was <.01. The p-values for the main effect of group had values of .28, .38 and .48 at the first, second and third quartiles, respectively, and the interaction effect had p-values of .07, .13 and .21. Thus, with considerable consistency across samples, there was a robust main effect of memory intention, but no significant main effect of group, and no significant interaction.
To further explore the non-significant interaction, we calculated a directed forgetting effect by subtracting the corrected TBF hits from the corrected TBR hits on a subject-by-subject basis within each group. The cumulative distributions of these means are shown in Figure 2b. Suggesting similar overall shapes, a non-parametric Anderson–Darling k-sample test revealed no significant difference across these distributions (Version 1: AD = 1.83, T.AD = 0.16, p = .46; Version 2: AD = 1.79, T.AD = 0.20, p = .48). To compare the mean values of these distributions, we conducted Bayesian independent samples t-tests on the directed forgetting effect. We compared the R-F group (typical of the item-method directed forgetting task) first to the R-DR group and then to the DF-F group. Before conducting these tests, we generated boxplots of the directed forgetting effects within each group to confirm that there were no outliers (Goss-Sampson et al., 2020). A Shapiro–Wilk test indicated that the distribution of difference scores was not normal within the R-F group (W = 0.94, p < .04) but was normal within the R-DR (W = 0.96, p = .14), and DF-F W = 0.97, p = .39) groups.
To account for the violation of normality within the R-F sample, a Bayesian Mann–Whitney U test (5,000 samples) was used to compare directed forgetting effects in the R-F group first to those in the R-DR group, and then to those in the DF-F group. The comparison of the R-F group to the R-DR group is shown in Figure 2c. The BF10 value was 0.450 and represents a ratio of the likelihood of the data given the alternative hypothesis (R-F directed forgetting effect ≠ R-DR directed forgetting effect) to the likelihood of the data given the null hypothesis. The BF01 value was 2.224 and represents the inverse ratio. These values provide anecdotal evidence in favour of the null hypothesis of no difference in the magnitude of the directed forgetting effect between these two groups. The outcome of the second independent samples Bayesian t-test, comparing directed forgetting in the R-F group to that in the DF-F group, is shown in Figure 2d. This analysis likewise provided anecdotal evidence in favour of the null hypothesis of no difference, with a BF10 value of 0.701 and a BF01 value of 1.426. 2
Discussion
No matter how the instruction to remember or to forget was framed, Experiment 1 revealed a directed forgetting effect, with better recognition of TBR items than TBF items. Despite the R-F condition producing a numerically larger 20% directed forgetting effect, with better recognition of TBR words over TBF words, the data did not provide a compelling reason to think that this directed forgetting effect was meaningfully larger than the 14% difference observed in the R-DR condition or the 13% difference observed in the DF-F condition. 3 That said, there was also no compelling evidence in favour of the null hypothesis of no difference.
Ambiguity over the critical interaction occurred even though our analysed sample size (n = 41) was very near the sample size goal informed by our a priori power analysis (n = 42). It is possible that this ambiguity reflects, in part, inadequacies in how G*Power calculates power for mixed-effects designs. 4 However, it might also reflect the fact that our power analysis was predicated on a medium effect size, whereas the observed effect size on the interaction was a small effect. In light of this, we conducted a sensitivity analysis using Monte Carlo simulations in the Superpower package in R (Lakens & Caldwell, 2021). This allowed us to determine the minimum effect size that our study could detect reliably, given our sample size. This analysis systematically increased the effect size by increments of 10%, while holding sample size constant at 41 participants per group. At each scaling step, 10,000 simulations were conducted to estimate statistical power, allowing us to identify the effect size that could be detected with at least 80% power. Results indicated that the effect size on our interaction needed to be scaled by a factor of more than 1.6 to be detected reliably given our sample size. In other words, with 41 participants per group, the interaction effect size would have needed to be approximately 60% larger for our study to have detected it reliably. As it was, the observed interaction effect accounted for <1% of the variance in corrected hit rates, and a simulation-based power analysis suggested that a sample size of at least 109 participants per group would be required to detect this effect with 80% power.
If our findings reflect a limitation in statistical power – rather than a true absence of an effect – it remains possible that the magnitude of the directed forgetting effect does, in fact, depend on the verbal descriptor in ways that were not detectable in the present study. However, given that the observed effect size on the interaction was small and would be detected reliably only with a much larger sample size than would otherwise be required to study the effects of memory intentions, there is currently no strong reason to believe that recognition performance is likely to be compromised by a researcher’s decision to frame remembering in terms of ‘not forgetting’ or to frame forgetting in terms of ‘not remembering’. Of course, whether memory intentions generated by R-F, R-DR and DF-F instructions are implemented via the same underlying cognitive mechanism(s) remains to be determined. But if directed forgetting reflects a genuine cognitive process, it would seem necessary for the mechanism(s) controlling access to long-term memory to remain effective despite minor changes in instructional wording.
Experiment 2
In Experiment 1, encoding intentions were established using semantic equivalencies, such that instructions to ‘Remember’ and ‘Don’t Forget’ designated an item as TBR and instructions to ‘Forget’ and ‘Don’t Remember’ designated an item as TBF. It seems possible that our use of semantic equivalencies in everyday life – for example, we might be as likely to tell a partner to ‘Remember that we have dinner plans on Thursday’ as we are to tell them ‘Don’t Forget that we have dinner plans on Thursday’ – might have reduced the impact of verbal re-framing on the directed forgetting effect in Experiment 1. Experiment 2, therefore, took a different tack and instead informed participants that there was a default memory task that they were to engage on every trial, unless countermanded by an instruction. For half of the participants, the default task was to Remember (R-default), with a memory instruction serving as a countermanding instruction to Forget (see Hourihan & Taylor, 2006); for the other half of participants, the default task was to Forget (F-default), with a memory instruction serving as a countermanding instruction to Remember. Despite establishing either Remembering or Forgetting as the default task, a random half of the study items were TBR and the other half were TBF in all cases.
Method
Participants
Undergraduate Psychology and Neuroscience students were recruited online in the same manner described for Experiment 1. We used G*Power 3.1 (Faul et al., 2009) to conduct an a priori power analysis for a mixed within-between interaction, specifying a desired power of 80%, a standard alpha level of .05, and two groups with two measurements each (with a correlation of .5 for repeated measures). We estimated the f parameter by inputting an
Stimuli and apparatus
The stimuli and apparatus were identical to Experiment 1.
Procedure
The procedure was identical to Experiment 1, except that the memory instruction mapped to TBR and TBF intentions was never displayed for the default memory task; instead, the screen remained blank for a duration equal to that of the memory instruction used on countermanding trials. The instructions were altered accordingly to inform participants in the R-default group that the instruction indicated that they were to Forget the word and to inform participants in the F-default group that the instruction indicated that they were to Remember the word. Half of the stimulus files with each mapping of stimulus (<::> or >::<) to memory intention (TBR, TBF) were assigned to the R-default group and the other half to the F-default group (even though the instruction for the default task was never presented). In this way, participants were as likely to be assigned to either group and as likely to be presented with <::> and with >::< as their only memory instruction.
Results
During data pre-processing, we determined that four participants in the R-default group and three in the F-default group had incomplete files, operationalized as having completed fewer than 60% of test trials. In fact, participants thus excluded from the R-default group had completed an average of only 16 study trials before aborting the experiment, and participants excluded from the F-default group had completed an average of only 19 study trials, with none of these participants completing any recognition trials in either group. We confirmed that all other datasets had a full complement of study and test trials.
As we had done for Experiment 1, after removing these incomplete datasets, we averaged over both groups of participants to calculate a single mean and standard deviation for recognition response times (M = 1.3 s, SD = 1.1 s). Outliers were identified based on individual means that were 2 standard deviations higher or lower than the means of all participants. Long recognition response times led to data being excluded for two participants in F-default group only (10.6 s, 4.6 s). After these two exclusions, there were a total of 55 participants in the R-default group and 52 in the F-default group. We selected for inclusion a random 52 datasets from the larger R-default group to match sample size to the F-default group, using a fixed random seed to ensure replicability.
Mean recognition yes responses are shown in Table 1 as a function of word type (TBR, TBF, foil) and group (R-default, F-default). An independent samples t-test showed that the 22% false alarm rate in the R-default group did not differ significantly from the 27% false alarm rate in the F-default group, t(102) = 1.30, p = .20, d = 0.26. Nevertheless, as was done for Experiment 1, the foil false alarm rate was subtracted from both the TBR and the TBF hit rates on a subject-by-subject basis within each group. These corrected hit rates for TBR and TBF items are shown in Figure 3a.
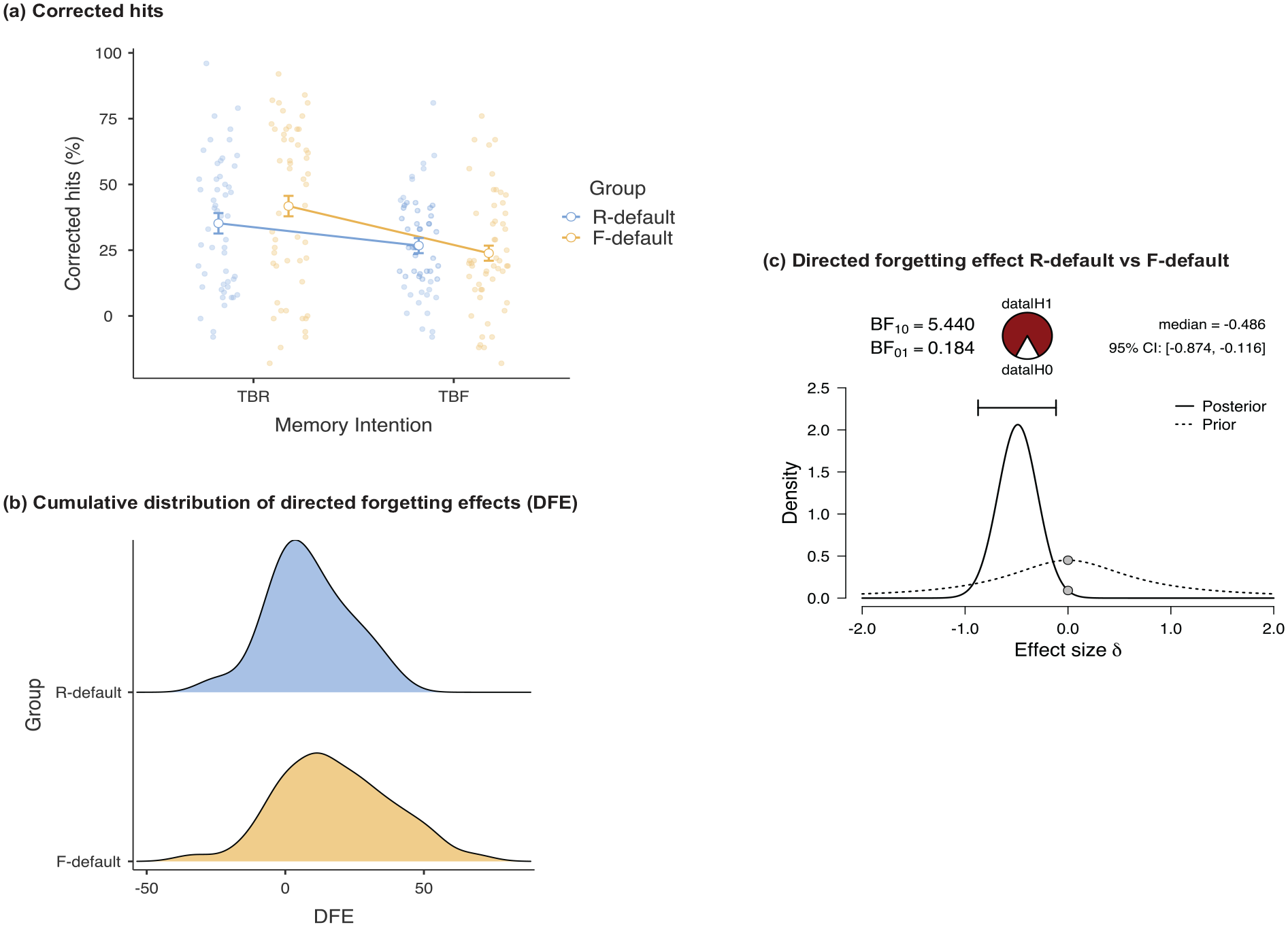
Results of Experiment 2. Depicted top left (a) are the mean corrected hit rates (hits – false alarms, %) as a function of whether the intention was for a studied word TBR or TBF and according to whether the default task for the group was to remember (R-default) or to forget (F-default). Anchor points for the lines that depict mean group values are jittered horizontally to enable a display of observed scores (circles) within each Group. The R-default group is shown in blue and the F-default shown in orange. Error bars are the standard error of the mean. Maintaining the same group colour-coding, depicted bottom left (b) are the cumulative distributions of the DFEs that were calculated on a subject-by-subject basis within each group by taking the difference between the corrected TBR hit rates and the corrected TBF hit rates. Depicted right (c) is a summary of the Bayesian independent samples t-tests of the DFE in the R-default group compared to the F-default group. The proportion of evidence for the alternative hypothesis (H1) versus the null hypothesis (H0) is captured in the pizza plot. The prior distribution is shown with a dashed line and the posterior distribution with a solid line. On each line is a grey dot representing an effect size of 0; the alternative hypothesis (of a difference between groups) is supported when the dot on the prior distribution is higher than the dot on the posterior distribution. Also shown are the median effect size and 95% credible intervals. Note that Bayesian analyses involve random sampling from the posterior distribution, which may cause variability in the distribution itself across runs, as well as in the resulting median and credible intervals.
Paired-samples t-tests showed that, compared to TBF items, TBR word recognition was 8 percentage points higher in the R-default group, t(51) = 4.24, p < .01, d = 0.59, and 18 percentage points higher in the F-default group, t(51) = 6.38, p < .01, d = 0.89. Not surprisingly, an ANOVA with memory intention (TBR, TBF) as a within-subjects factor and group (R-default, F-default) as a between-subjects factor confirmed an overall directed forgetting effect, with significantly greater recognition of TBR items than TBF items, F(1,102) = 58.63, MSe = 154.37, p < .01,
As we did for Experiment 1, we used bootstrap resampling to ensure that these ANOVA results were not specific to the particular subset of R-default participants that were selected to match sample size to the F-default group. On each of 10,000 iterations, we randomly selected R-default datasets to match the sample size of the F-default group and ran a mixed ANOVA (afex::aov_ez). Across all iterations, the p-value for the main effect of memory intention was <.01. The main effect of group had p-values of .52, .59 and .66 at the first, second and third quartiles. The interaction effect had p-values of <.03 across all iterations. These findings demonstrate that the pattern of results was consistent across sampled datasets, revealing a robust main effect of memory intention, no significant main effect of group, but a significant difference in the magnitude of the directed forgetting effect in the R-default and F-default groups.
As was done for Experiment 1, the directed forgetting effect was calculated by subtracting the corrected TBF hits from the corrected TBR hits on a subject-by-subject basis within each group. The cumulative distributions of these means are shown in Figure 3b. A non-parametric Anderson–Darling k-sample test verified significant differences in the shape of these distributions (Version 1: AD = 3.84, T.AD = 3.80, p < .01; Version 2: AD = 3.99, T.AD = 4.00, p < .01). To further evaluate the means of these distributions, a Bayesian independent samples t-test examined the directed forgetting effect as a function of the R-default and F-default groups. Before conducting this test, we confirmed that there were no outliers on the directed forgetting effect in either group. A Shapiro–Wilk test confirmed that the distribution of directed forgetting effects was approximately normal within the R-default (W = 0.98, p = .48), and F-default (W = 0.99, p = .87) groups. The outcome of the Bayesian independent samples t-test is shown in Figure 3c. The BF10 value was 5.440, whereas the BF01 value was 0.184, indicating that the data were more than 5 times more likely under the alternative hypothesis (of a difference in the magnitude of the directed forgetting effect between groups) than under the null hypothesis. This provides moderate evidence in favour of the conclusion that the magnitude of the directed forgetting effect was smaller for the R-default group than for the F-default group.
Discussion
In Experiment 2, half of all study items were designated TBR, and half were designated TBF, yet the magnitude of the directed forgetting effect was smaller for the R-default group than for the F-default group. This interaction between memory intention and group occurred despite a final sample size that was slightly smaller than originally intended (52 vs. 56) and was supported by a power analysis indicating that only a modest increase in the sample size (n = 59) would be needed to achieve 80% power given the observed effect size. Bootstrap resampling confirmed the stability of the interaction effect, providing additional evidence for the reliability of this key finding.
In the R-default group, the corrected hit rate was 35% for TBR items and 27% for TBR items, resulting in a directed forgetting effect of 8%. 6 In the F-default group, the corrected hit rate was 42% for TBR items and 24% for TBF items, yielding a directed forgetting effect that was twice as large, at 18%. Note the similarity in the corrected hit rate for TBF items in the two groups (27% vs. 24%). Given that the directed forgetting effect is calculated as the difference in TBR and TBF item recognition, the similarity of these TBF scores suggests that the difference in the magnitude of the directed forgetting effect in the R-default and F-default groups was attributable primarily to differences in TBR item recognition: Participants recognized fewer TBR words when their default task was to remember than when their default task was to forget, with a less obvious influence of task framing on TBF word recognition.
The fact that the R-default task produced lower recognition of TBR words than the F-default task hints at metacognitive differences in how participants might have approached the task. Just as the prediction scale is used differently for JOLs versus JOFs, participants may have approached their memory task differently when the default was to remember compared to when the default was to forget. As suggested for the judgement framing effect, it seems likely that the instructions to treat remembering as the default task or to treat forgetting as the default task activated different beliefs in the participants (cf. Dunlosky & Tauber, 2014). Possibly, participants who were required to remember unless instructed otherwise perceived the task as more difficult than those who were required to forget unless instructed otherwise. If so, perceived difficulty might have led participants in the R-default task to engage in more active monitoring of rehearsal and control processes, thereby diverting limited-capacity resources away from the successful implementation of those processes (cf. Beilock & Carr, 2005). This seems unlikely, however, given that intentional forgetting also requires the engagement of active cognitive control (Cheng et al., 2012; Fawcett & Taylor, 2008; Wylie et al., 2008) and yet – compared to TBR items – TBF items were recognized at similar rates in the R-default and F-default groups. Instead, perceived difficulty of the R-default task compared to the F-default task might have made the R-default task seem more threatening – as might happen, for example, if participants equate achievement with intelligence (e.g. Theobald et al., 2020). Such a threat could limit the efficiency of working memory (e.g. Beilock et al., 2007; Van Ast et al., 2016), reducing the successful encoding of TBR items that R-default participants intended to commit to long-term memory.
A final possibility is that perceived difficulty of the R-default task was less important than the emphasis on forgetting in the F-default group. This emphasis on forgetting in the F-default group might have led participants to strategically focus more rehearsal on the TBR items than participants in the R-default group. This would be akin to what participants do when presented with loud and quiet items in an item-method directed forgetting task (Foster & Sahakyan, 2012). Even though loud items are not, in fact, usually recalled at a higher rate than quiet items, participants’ expectation that loud items are more memorable leads them to focus more rehearsal on loud TBR items than on quiet TBR items, giving rise to a loud-item advantage in subsequent recall. Importantly, this loud-item advantage does not occur for participants who must commit all items to memory, but only for those who are instructed to remember some items and to forget others. This suggests that the loud-item advantage arises from a strategy engaged by participants to try to ensure successful forgetting. These participants focus their encoding efforts on those TBR items that seem easiest to commit to memory (the loud items), presumably thinking that the more items they are able to remember, the better they will be able to forget.
No matter the mechanism(s) involved, the results of Experiment 2 make it clear that a default task focused on remembering results in smaller directed forgetting effects than a default task focused on forgetting – despite equal numbers of TBR words and TBF words in both tasks. Researchers wanting to use a single instruction in the context of a default task must therefore be careful in choosing how to frame that default task, informed by whether they are primarily interested in studying processes that lead to successful intentional remembering – in which case, the way the default task is framed may be particularly important – or whether they are primarily interested in studying processes that lead to successful intentional forgetting.
Experiment 3
Whereas semantic equivalencies across TBR and TBF instructions provided no compelling evidence of framing effects on directed forgetting in Experiment 1, presenting an instruction as a countermand to a default instruction to Remember or Forget did influence the magnitude of the directed forgetting effects observed in Experiment 2 – predominantly, it seems, through changes in the way participants approached intentional remembering, rather than intentional forgetting.
The pattern of findings across these two experiments raises the possibility that framing effects are relevant to directed forgetting only for task-level instructions, such as those used in Experiment 2, and not for trial-level instructions, as used in Experiment 1. To further investigate the potential impact of trial-level instructions, Experiment 3 presented participants with study words one at a time, each followed by an indication of whether the study item was Important or Not Important to the subsequent memory test. By omitting explicit reference to remembering and forgetting, participants in Experiment 3 were left to determine how to apply these instructions, bridging the highly constrained trial-by-trial mapping of verbal labels to intended memory outcomes in Experiment 1 and the more flexible emphasis on remembering or forgetting established by the default task in Experiment 2. The question is whether the effectiveness of trial-by-trial instructions depends on explicit framing of the task in terms of memory outcome – whether stated in the positive (Remember, Forget) or in the negative (Don’t Forget, Don’t Remember) – or if instructions that signal the need to engage with an item (Important) or not (Not Important) likewise support deliberate encoding control, possibly by implying the need to remember or forget. Arguably, such instructions may better reflect how encoding control is exercised in real life (Fawcett et al., 2024), where we are seldom given explicit instructions to Forget and, instead, regulate the contents of our own long-term memories by attempting to remember information that seems important and discarding information that does not.
Despite the surface similarity to value-directed remembering, the trial-by-trial indication that a study word is Important or Not Important maintains a trial structure typical of the item-method paradigm and keeps the focus on whether participants can strategically control their encoding processes – committing some items to long-term memory while limiting the encoding of others. Whereas a value-directed memory paradigm may assign point values to study items to encourage subjective prioritization and selective encoding, the intention is generally to remember as many items as possible while maximizing points (e.g. Murphy & Knowlton, 2022). Accordingly, the fact that participants tend to remember fewer low-value items than high-value items is more likely due to unintentional forgetting of information that was not prioritized for encoding, rather than an active attempt to discard it. In contrast, in our task, the importance of each item is clearly defined on each trial, and any forgetting of words designated as Not Important is more likely to reflect encoding strategies aimed at controlling the commitment of items to long-term memory rather than decision-making strategies aimed at maximizing rewards.
Method
Participants
Undergraduate Psychology and Neuroscience students were recruited online in the same manner described for Experiments 1 and 2. Using the means and standard deviations of the R-F group from Experiment 1, a priori power analysis in G*Power 3.1 (Faul et al., 2009) showed that we needed a sample size of only 34 participants to test the difference between two dependent means (⍺ < .05, power = 80%, r = .5); however, we opted to instead set 56 as our goal, similar to Experiment 2. Although we anticipated comparing our results to more typical R-F directed forgetting group of Experiment 1, we reasoned that matching to the largest sample sizes from Experiments 1 and 2 would facilitate other cross-Experiment comparisons, should they be warranted. To increase the likelihood of meeting our sample size goals even after having to remove any incomplete files, we halted online data collection only after we had collected data from a total of 65 participants.
Stimuli and apparatus
The stimuli and apparatus were identical to Experiment 1.
Procedure
The procedure was identical to Experiment 1, except that the mapping of memory instruction to TBR and TBF intentions was not explicit. Instead, the instructions were described as indicating whether each study word was Important (implied TBR) or Not Important (implied TBF) for the subsequent test of memory. In all other respects, the procedure was identical to Experiment 1.
Results
During data pre-processing, we determined that a total of eight participants had incomplete data files, operationalized as fewer than 60% of test trials. In fact, these participants had aborted the experiment after an average of only 24 study trials; none had proceeded to the recognition test trials. We confirmed that all remaining datasets included the full complement of study and test trials.
After removing the incomplete data files, we averaged over all trials for all remaining participants to calculate a single mean and standard deviation for recognition response times (M = 1.0 s, SD = 0.4 s). Outliers were identified based on individual means that were 2 standard deviations higher or lower than the means of all participants. Data contributed by two participants were excluded based on long recognition response times (2.4 s, 2.2 s). After exclusions, there were data from a total of 55 participants.
Mean recognition yes responses are shown in Table 1 as a function of word type (TBR, TBF, foil). As was done for Experiments 1 and 2, the foil false alarm rate was subtracted from both the TBR and the TBF hit rates on a subject-by-subject basis. These corrected hit rates for TBR and TBF items are shown in Figure 4a. A paired-samples t-test on corrected hit rates confirmed a significant 17% directed forgetting effect, with better recognition of TBR items than TBF items, t(54) = 6.21, p < .01, d = 0.84.
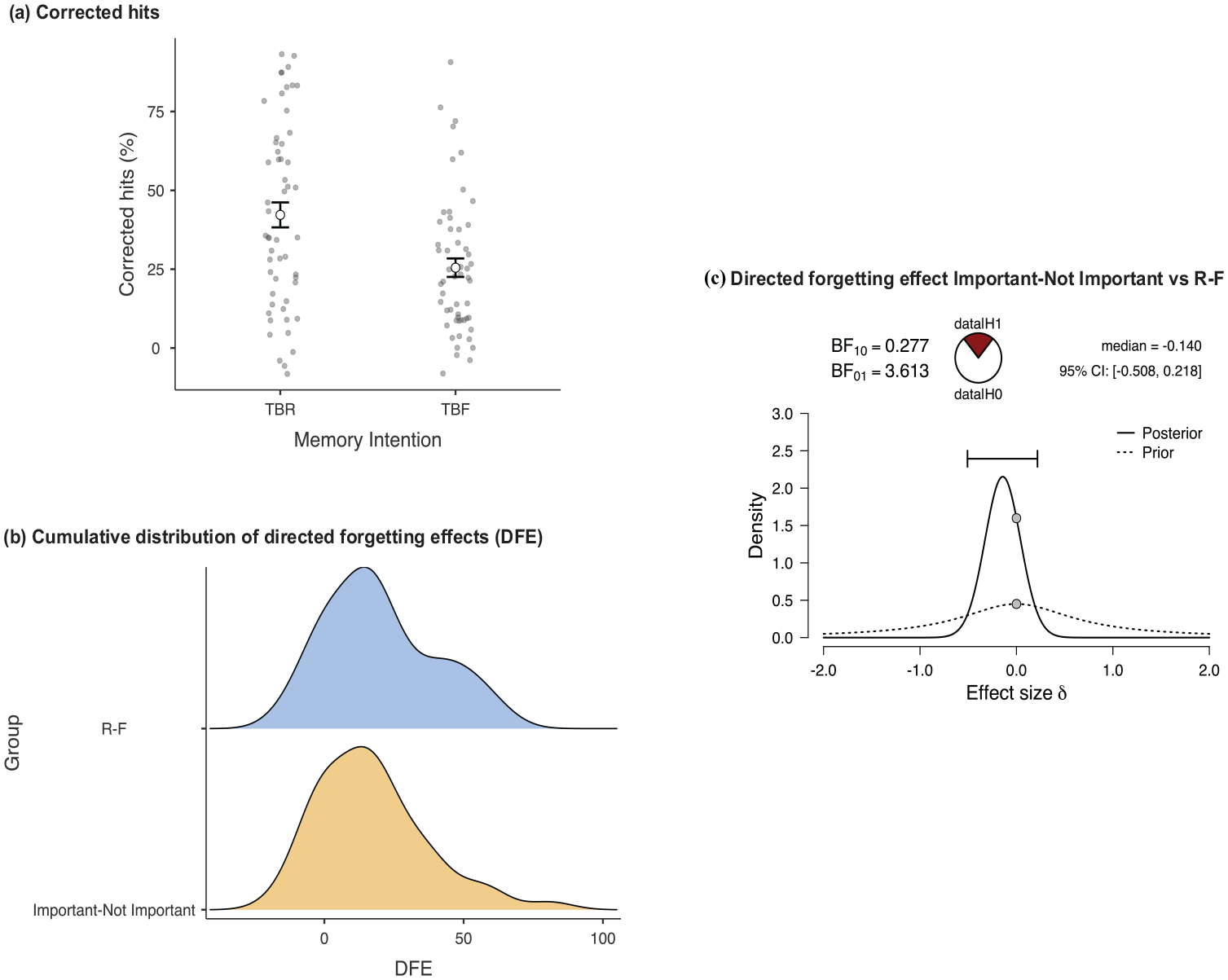
Results of Experiment 3 and comparisons with R-F group of Experiment 1. Depicted top left (a) are the mean corrected hit rates (hits – false alarms, %) for the full sample of Experiment 3 data, as a function of whether the intention was for the studied word TBR or TBF, with observed scores shown as circles. Error bars are the standard error of the mean. Depicted bottom left (b) are the cumulative distributions of the DFEs that were calculated on a subject-by-subject basis by taking the difference between the corrected TBR hit rates and the corrected TBF hit rates. The top distribution, shown in blue, represents the full R-F dataset from Experiment 1; the bottom distribution, shown in orange, represents a random sample of Experiment 3 data (Important–Not Important) matched in size to the R-F group. Depicted right (c) is a summary of the Bayesian independent samples t-test comparing the DFE for the Experiment 3 sample to that of the R-F group from Experiment 1. The proportion of evidence for the alternative hypothesis (H1) versus the null hypothesis (H0) is captured in the pizza plot. The prior distribution is shown with a dashed line and the posterior distribution with a solid line. On each line is a grey dot representing an effect size of 0; the alternative hypothesis (of a difference between groups) is supported when the dot on the prior distribution is higher than the dot on the posterior distribution. Also shown are the median effect size and 95% credible intervals. Note that Bayesian analyses involve random sampling from the posterior distribution, which may cause variability in the distribution itself across runs, as well as in the resulting median and credible intervals.
To determine how these data compare to a more typical directed forgetting task, we randomly selected 52 datasets from Experiment 3 to compare to the full R-F dataset from Experiment 1, setting a fixed random seed for replicability. This sample of Experiment 3 data had a false alarm rate of 26%, which was significantly higher than the 18% false alarm rate obtained in the full set of R-F group data, t(100.60) = 2.22, p < .03, d = 0.44.
7
As was done for Experiments 1 and 2, we subtracted false alarms from both TBR and TBF hits on a subject-by-subject basis within each group. An ANOVA on the corrected hit rates confirmed a main effect of memory intention, with better recognition of TBR items than TBF items, F(1,102) = 89.61, MSe = 194.50, p < .01,
As we did for Experiments 1 and 2, we used bootstrap resampling to ensure that these ANOVA results were not specific to the particular subset of Experiment 3 participants who were selected to match the full sample size of the Experiment 1 R-F group. On each of 10,000 iterations, we randomly selected Experiment 3 datasets to match the sample size of the R-F group and ran a mixed ANOVA (afex::aov_ez). Across all iterations, the p-value for the main effect of memory intention was <.01. The main effect of group had p-values of .17, .21 and .25 at the first, second and third quartiles, respectively, and the interaction effect had p-values of .36, .43 and .50. These findings demonstrate that the pattern of results was consistent across sampled datasets, revealing a robust main effect of memory intention, no significant main effect of group, and no significant interaction of memory instruction with group.
To further compare the Important–Not Important instructions of Experiment 3 against the typical R-F instructions of Experiment 1, we calculated directed forgetting effects by subtracting corrected TBF hit rates from corrected TBR hit rates on a subject-by-subject basis within each group. The cumulative distributions of directed forgetting effects are shown in Figure 4b, with the distribution for the full R-F group in the upper part of the plot and the distribution for sampled Important–Not Important data in the lower part of the plot. Suggesting similar overall shapes, a non-parametric Anderson–Darling k-sample test revealed no significant difference across these distributions (Version 1: AD = 0.60, T.AD = 0.53, p = .65; Version 2: AD = 0.58, T.AD = 0.56, p = .67). A Shapiro–Wilk test indicated that the distribution was approximately normal for participants who received R-F instructions (W = 0.96, p = .06) and was normal for those who received Important–Not Important instructions (W = 0.96, p < .02). Before proceeding to a Bayesian t-test of these data, we reviewed an outlier identified on a boxplot of directed forgetting scores. The directed forgetting effect for this participant in the Important–Not Important sample was 81%, compared to mean across the sample of 17% (SD = 20%). However, this participant was not identified as an outlier on either the corrected TBR hits or on the corrected TBF hits that were used to calculate the directed forgetting effect. Accordingly, we opted not to remove this participant’s data.
A Bayesian t-test was used to compare the directed forgetting effect obtained in the Important–Not Important sample of Experiment 3 data against that obtained in the full R-F group of Experiment 1. This analysis yielded a BF10 value of 0.277 and BF01 value of 3.613, indicating that the null hypothesis of no difference was more than 3 times more likely than the alternative. 8 This moderate evidence in favour of the null hypothesis suggests that Important–Not Important instructions produce a directed forgetting effect of comparable magnitude to that observed with more typical R-F instructions.
Discussion
As noted in the Introduction, framing a goal in terms of maximizing total points of items remembered leads to more remembering of high-value items than does framing a goal in terms of minimizing the total points of items forgotten (Murphy & Knowlton, 2022). This suggests that goal framing interacts with item importance to influence decision-making strategies aimed at maximizing rewards. But it does not clearly indicate whether deemed item importance is sufficient, on its own, to influence the commitment of items to memory. The results of Experiment 3 confirm that this is, indeed, the case.
Under the view that identifying a word as Important for a later memory test implies that the word is TBR and that identifying a word as Not Important implies that it is TBF, we used the difference in TBR and TBF recognition to calculate a directed forgetting effect. The magnitude of this effect was 18% in the full Experiment 3 dataset and 17% when down-sampled to match R-F group size. By comparison, the magnitude of this effect was 20% in both the full R-F dataset as well as when down-sampled to match group sizes within Experiment 1. A comparison of these groups’ results provided evidence in favour of the null hypothesis of no difference, suggesting that whether an instruction implied that an item was TBR or TBF or stated it explicitly, the outcome was indistinguishable. This conclusion was bolstered by a simulation-based power analysis that failed to reach 80% power even when simulating a sample size of 1,000 participants, indicating that any true difference due to instruction type – if it exists – is likely to be vanishingly small. Of course, this does not mean that Important and Not Important instructions necessarily produce these directed forgetting effects via the same mechanisms as Remember and Forget instructions. However, similar to an argument, we made in relation to Experiment 1: If encoding control genuinely explains item-method directed forgetting, its successful implementation should not be wholly dependent on presenting instructions that map explicitly onto the intended memory outcome for each trial.
General discussion
This study was motivated by the question of whether a directed forgetting effect depends on the intention to remember or forget or also on the words used to frame the trial-by-trial instructions or task. In real life, memory instructions are often framed using semantic equivalencies. These equivalencies sometimes guide memory intentions explicitly (e.g. ‘Don’t forget that we have dinner plans on Thursday’ to mean ‘Remember that we have dinner plans on Thursday’) and other times only implicitly, such as when we attempt to remember information that is important and to disregard information that is not. Yet, the ability to use such equivalencies to engage in active encoding control has not been demonstrated empirically. Moreover, the tendency for the field to frame memory instructions only with the words remember and forget risks studying a phenomenon that is, in fact, an artefact of informing participants of the intended memory outcome on each trial, and not reflective of how encoding control operates more generally. In other words, the robust directed forgetting effect observed with standard Remember and Forget instructions might depend critically on the unnatural explicitness of the instruction itself. To our awareness, our study is the first to explore whether the empirical pattern that defines a directed forgetting effect can even occur under conditions that do not rely on the standard Remember and Forget instructions. In doing so, we are laying a critical foundation for future work that can begin to ask whether similar effects arise from common causes – a question that is beyond the scope of our current manuscript.
With this caveat in mind, our three experiments demonstrated that a directed forgetting effect is robust across a variety of instructions and tasks. Indeed, there was a significant directed forgetting effect in all of our groups and conditions: When participants received instructions to Remember and Forget (R-F), to Remember and Don’t Remember (R-DR), and to Don’t Forget and Forget (DF-F); when they were given the default task of Remembering with interspersed instructions to Forget (R-default), as well as when they were given the default task of Forgetting with interspersed instructions to Remember (F-default); and, also when the memory intention was implied by instructing participants that some words were Important for a later test whereas others were Not Important. That said, there were differences in the magnitude of the directed forgetting effect based on how the task was framed, even if there was no compelling evidence for differences based on how trial-by-trial instructions were framed.
Of course, the fact that instructions may be interchangeable at the trial-by-trial level does not obviate the importance of other trial factors. As a case in point, Hourihan (2021, 2022) presented study items paired with one of two sources to show that source cue probability influences rehearsal strategies. Although both sources presented both TBR and TBF items, one source consistently provided twice as many TBR words as TBF, and the other source provided twice as many TBF words as TBR words. Recognition testing (on an equal number of TBR and TBF words from both sources) showed significant DF effects from both sources, but the specific pattern differed for the two sources. Unlike the current Experiment 2, it was recognition of the TBF words that varied depending on source: Participants rehearsed words presented by the mostly-Remember source earlier in the trial (as demonstrated using overt rehearsal), leading to higher hits for TBF words from this source, relative to TBF words from the mostly-Forget source. Recognition of TBR words generally did not vary with source cue probability, presumably due to cumulative rehearsal of TBR words across trials. Recognition of the TBF words benefitted from pre-instruction rehearsal that was preferentially afforded to words from the source from which participants expected to receive TBR items.
In light of our findings from Experiments 1 and 3, it would thus seem that even if researchers must be cautious around the selection of other trial-level variables (e.g. source probabilities), they do have some latitude with respect to how they choose to frame trial-by-trial instructions. This is particularly true when the primary concern is manipulating the memory outcome itself rather than the underlying mechanisms that give rise to it. Indeed, it remains possible that the words mapped onto our symbolic memory instructions in Experiments 1 and 3 led to similar directed forgetting effects via distinct underlying mechanisms. Alternatively, they may have produced similar effects by converging on a shared linguistic representation that belies differences in instruction wording. 9 To wit: despite variations in linguistic framing, participants may internally translate instructions into a common representation that guides memory control – one that might not even be explicitly verbalized but instead reflects a more abstract, goal-directed encoding process. If so, this would underscore the premise that directed forgetting is a general cognitive function that operates independently of the specific words used to engage it.
In contrast to the results of Experiments 1 and 3, the results of our Experiment 2 show that researchers have no such latitude in terms of choosing how to frame the memory task itself. When participants were presented with a default task of remembering, the magnitude of their directed forgetting effect was considerably smaller than when participants were presented with a default task of forgetting – despite finding a significant overall directed forgetting effect in both tasks. This suggests the need for care in deciding how to frame the default task for participants, especially where a researcher is interested in processes related to successful intentional remembering (i.e. because it was recognition of TBR items that seemed particularly affected). Indeed, our finding raises the possibility that caution may be needed any time a researcher needs to manipulate the way the task is framed.
Dunlosky and Tauber’s (2014) isomechanism framework addresses how different cues may be weighted differently when making memory predictions, depending on the context in which those predictions are made. Their framework was cited by England et al. (2017) in explaining why JOFs tend to be made differently than JOLs: Participants consider different knowledge about memory when the judgement is framed to ask about remembering than when it is framed to ask about forgetting. In the current Experiment 2, the task instructions differed from the usual directed forgetting instructions by virtue of setting a task default that differed between the R-default and F-default groups. In a typical item-method directed forgetting task, participants know that they will receive a memory instruction on each trial and so maintain each word in a shallow manner until this instruction is received (e.g. Gardiner et al., 1994), choosing to elaborate the item further only when the instruction is to Remember (e.g. Hsieh et al., 2009). On this basis, participants in the R-default group might have been expected to commence elaborative rehearsal immediately upon word presentation, without waiting for a memory instruction, since the default task was to remember and starting a deeper rehearsal right away would be conducive to that purpose. Conversely, one might have expected participants in the F-default group to choose a strategy much closer to that used in the standard task: To wait until the end of the trial to determine whether a Remember instruction would be received and, if so, to only then initiate elaborative rehearsal. The present results, however, are inconsistent with these suppositions. Had the R-default group elaborated each word immediately upon presentation, participants would have shown better memory than the F-default group for both the TBR items (which would have been rehearsed for a longer duration, starting at word onset) and the TBF items (which would have received elaborative rehearsal in the pre-instruction interval). Rather, just as it has been shown that beliefs about memory influence the predictions one makes about their future likelihood of remembering (i.e. memory monitoring; see Dunlosky & Tauber, 2014; Koriat, 1997), the current results suggest further evidence that beliefs about memory also influence the ways in which one strategizes about using their memory processes (i.e. memory control; e.g. Murphy & Knowlton, 2022), including how they engage monitoring and control (Nelson & Narens, 1990). Clearly, the way the default task is framed is one parameter that influences the magnitude of the directed forgetting effect; there likely are other task parameters that also matter.
Footnotes
Author contributions
Tracy L Taylor: conceptualization, methodology, writing – original draft (lead); writing – review and editing (equal). Kathleen L Hourihan: writing – original draft (supporting); writing – review and editing (equal).
Data availability statement
The data are not publicly available due to the terms of participant consent. However, they can be shared with qualified researchers for scholarly use upon request to the corresponding author.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by an NSERC Discovery grant to TLT.
Ethics approval
The experiments reported in this paper were reviewed and approved by the Dalhousie Social Sciences and Humanities Research Ethics Board.
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
Consent to use data for research purposes was obtained from all individual participants included in the study.