
Abstract
Research conducted on alphabetic languages has yielded findings suggesting that readers tend to allocate more time toward processing the final words of a sentence or clause, commonly referred to as the wrap-up effect. Several theoretical accounts of the wrap-up effect advocate causal mechanisms that are supposed to generalize over readers of all languages, yet they are based on a small selection of written languages and writing systems. Whether the wrap-up effect occurs in naturally unspaced, logographic languages such as Chinese remains unclear. We carried out an eye movement study focused on simplified Chinese reading, intending to discern whether the wrap-up effect at the end of the sentence is modulated by visual complexity. Native readers of Mandarin Chinese were tasked with reading sentences featuring target words manipulated in terms of visual complexity (high vs. low) and word position (final or medial) in the sentence. We found that words at the end of sentences were processed as quickly or even faster than those in the sentence-medial position, depending on the eye movement measure, and that the complexity of characters did not affect the wrap-up effect. This reversed or null wrap-up effect calls for a revision of proposed theoretical accounts grounded in the processing of alphabetic languages. The findings suggest that sentence processing in simplified Chinese is highly incremental, and the information-theoretical account is the one that does not contradict the observed direction of the wrap-up effect.
Keywords
Introduction
One of the most robust effects in eye movements during reading—named the “wrap-up” effect by Just and Carpenter (1980)—is the increase in reading times observed at the end of syntactic clauses or sentences compared to words within clauses. Originally reported nearly 50 years ago (Aaronson & Scarborough, 1976; Just & Carpenter, 1980; Rayner et al., 1989), the wrap-up effect has been playing a critical role in understanding the link between real-time visual processing of characters and words and comprehension of linguistic structure. While the wrap-up effect has been attributed to a variety of cognitive and perceptual causes (reviewed below), its traditional interpretation is as follows: Readers slow down at the boundaries of clauses and sentences because of the additional cognitive effort allocated to semantic integration of words within the clause and to connecting clauses into a coherent representation, as well as to updating prior discourse with new information (Just & Carpenter, 1980; Rayner et al., 1989, 2000). Importantly, with very few exceptions, the entire body of empirical evidence on the wrap-up effect has come so far from a handful of alphabetic languages. To our knowledge, this study is one of the first to experimentally study the wrap-up effect and its possible causes in the logographic writing system of Chinese. In the remainder of the introduction, we briefly review the evidence for and proposed explanations of the wrap-up effect in alphabetic languages; outline characteristics of written Chinese that may influence the magnitude and the very presence of this effect in Chinese; and provide the rationale for the present study.
Evidence of wrap-up effects across alphabetic languages
The wrap-up phenomenon of inflated reading times on sentence-final words has been robustly observed in multiple alphabetic languages, including English (Rayner et al., 2000; Warren et al., 2009), Dutch and German (Kuperman et al., 2010), Finnish (Hyönä et al., 2002) and French (Pynte & Kennedy, 2007). It is also observed, with different magnitudes, among children in elementary school (Tiffin-Richards & Schroeder, 2018) and adults varying in their age, reading proficiency and cognitive skills (Andrews & Veldre, 2021; Payne & Stine-Morrow, 2012). This effect is considered so standard that many eye-tracking studies of reading adopt the practice of removing from sentence-final words from data analysis to avoid the wrap-up as a confounding factor (see discussion in Kuperman & Van Dyke, 2011). Moreover, due to its robustness, attempts have been made to integrate this oculomotor pattern into models of oculomotor control during reading (Engelmann et al., 2013; Reichle et al., 2009).
As mentioned above, the classic interpretation of this effect is as a reflection of the integrative and updating effort that takes place at the end of a clause, over and above the regular effort of word recognition. Resolving all linguistic ambiguities at the end of the clause and committing the representation of the clause to long-term memory is argued to release resources in working memory that facilitate the processing of upcoming clauses (Rayner et al., 2000). This view converges with the once-dominant modular theoretical framework, which suggests that syntactic analysis of the sentence structure precedes its semantic interpretation and integration (Frazier, 1987; Frazier & Rayner, 1982).
Further developments in theories and empirical studies of sentence processing challenged the classical view. There is rich evidence (reviewed in MacDonald & Hsiao, 2018) that readers engage in highly incremental word-by-word building of the syntactic and semantic structure, responding to complexities and ambiguities as they arise (see Hale, 2006; Levy, 2008). In this framework, it is unclear why words at the clause boundaries would be any different from clause-medial words and elicit increased cognitive effort and, consequently, inflated reading times (Hirotani et al., 2006).
New explanations have been offered for the wrap-up effect as a result of this theoretical shift. One is of a perceptual nature. Clause boundaries are often marked by punctuation. These visual cues (commas, periods, colons, semicolons, exclamation, or question marks) lead to the low-level hesitation response of the oculomotor system and briefly delay saccadic planning (Hill & Murray, 2000; Warren et al., 2009). Another is that clause endings come with a specific contour of implicit prosody in silent reading. Since phonological processing is part and parcel of reading, the wrap-up effect may represent pauses (i.e., inflated reading times) at the end of intonational phrases, similar to the pauses speakers tend to make in these phonological environments (Hirotani et al., 2006). On this account, punctuation serves as the marker for the boundaries of intonational phrases. A range of self-paced reading and eye-tracking studies (Andrews & Veldre, 2021; Hill & Murray, 2000; Hirotani et al., 2006; Warren et al., 2009) manipulated punctuation at the clause boundaries and observed indeed that the clause endings marked with stronger punctuation cues (e.g., full stop) elicited stronger wrap-up effects than those marked with weaker punctuation cues (comma) or those unmarked with any punctuation: The magnitude of the effect also depends on syntactic complexity of the clause and individual skills and abilities of the reader. A highly relevant study by Luo et al. (2013) explored the applicability of these accounts of the wrap-up effect to reading in Chinese. In a series of three eye-tracking experiments, Luo et al. studied eye movements to the words and regions preceding and following a syntactic ambiguity in a sentence: Under one interpretation of the ambiguity, the target word ended the syntactic clause, and under another interpretation, the clause boundary was several words downstream. In Experiments 1 and 2, participants listened to the auditory cue in the form of a prosodic contour specifying the expected syntactic boundary; in Experiment 3, the boundary was marked by a comma as a visual cue. With both auditory and visual cues, resolution of syntactic ambiguity came with inflated reading times on target words, signaling that the cues may trigger the wrap-up effect. Whether the same behavior would be observed at the end of the sentence, or in the absence of syntactic ambiguity or overt auditory cues, is an open question.
Yet another explanation of the wrap-up effect takes the information-theoretic perspective, which links the processing effort of word recognition in connected texts with the amount of predictability (or surprisal) that a word is associated with in its context (Hale, 2001; Levy, 2008). Specifically, Meister et al. (2024) observe a stronger effect of information content on sentence- and clause-final positions relative to sentence- and clause-medial ones and propose two reasons for this finding. First, they suggest (though do not demonstrate) that the distribution of information in prior contexts may be different for words in the final versus medial positions, with contextual ambiguities being preferentially resolved at the clause endings. Second, they speculate without pointing to a specific psychological causal mechanism that the cognitive processes associated with sentence- and clause-final words are more sensitive to the information content of the preceding contexts than the sentence- and clause-medial words. On this account, punctuation as the visual cue and the intonational contour linked to punctuation are irrelevant for the occurrence and magnitude of the wrap-up effect.
In sum, after 50 years of consistent empirical findings in alphabetic languages, the theoretical consensus on the causes of the wrap-up effect has not been reached. We argue that additional insights into the causes of the wrap-up effect and valuable empirical data may come from consideration of the writing system and syntax that is radically different from the European alphabetic languages, namely, written Chinese.
Unique Chinese features and wrap-up effects
There are reasons to believe that the writing system and language structure can influence the presence and magnitude of the wrap-up effect. Chinese exhibits multiple relevant typological differences from alphabetic languages. Firstly, written Chinese employs logographic characters, which consist of strokes. These strokes are organized into radicals, which convey the meaning or pronunciation of the characters. Chinese words are constructed using one or more of these characters. It is estimated that approximately 70% of these words are composed of two characters, 20% of a single character, and the remaining percentage of three or four characters (Yu et al., 2018). Secondly, the words within a sentence are presented sequentially, without any intervening gaps between the individual characters, like spaces or lexical units. Although like English, Chinese uses periods, commas, and other common punctuation marks to indicate some boundaries between clauses or sentences, the placement and usage of some punctuation marks in Chinese differ from English. For instance, there are usually no spaces before and after these marks in Chinese, although the monospaced type of Chinese characters tends to leave ample white space around the marks. Commas can be used to combine clauses or sentences without any morphosyntactic markers. En dashes (–) for ranges and em dashes (—) for emphasis or breaks in English are not commonly used in Chinese. Thirdly, Mandarin Chinese, unlike English, does not have grammatical markers in sentences (Hickmann & Hendriks, 1999; Huang, 1984). Chinese sentence structure is rather flexible, relying less on strict word order to convey meaning compared to the subject-verb-object structure of English. The discourse-oriented characteristics of Chinese also permit the juxtaposition of clauses without the need for explicit connectives (Li & Thompson, 1981). Another relevant consideration is that perceived sentence completeness in Chinese is affected more strongly by semantic rather than syntactic information—the completion of an idea rather than a completion of the syntactic structure (Sun & Lu, 2022). 1 Thus, it is possible that the wrap-up effect is largely driven by semantic markers rather than the syntactic markers associated with the ending of a sentence. These distinctive characteristics inherent in Chinese—for example, the absence or weakness of syntactic, discourse-level or visual cues like spacing—imply that identification of word boundaries and, by implication, clause boundaries is much more laborious in written Chinese than in alphabetic languages. Unless a clause boundary is marked by punctuation, it is harder to detect as well. This poses an obvious question as to whether the hard-to-detect clause boundaries trigger the same additional cognitive effort in Chinese as the boundaries in other languages. Conversely, sentence boundaries are clearly demarcated by the period and a space in both Chinese and European alphabetic languages and thus may elicit cross-linguistically similar reading behavior. In sum, the wrap-up effect at the clause or sentence boundaries may be expressed in Chinese in a different way, and may have different causes than the current theories hold.
Another relevant cross-linguistic discrepancy is the much greater visual complexity of Chinese characters compared to letters in alphabets. The complexity of Chinese characters, measured by the number of strokes, has an effect on fixation durations and skipping rates, primarily through visual processing rather than lexical processing (Yu et al., 2018; Zang et al., 2016). A similar outcome was witnessed in Chinese incidental word learning (Liang et al., 2024). To elaborate, the two experiments in Liang et al.’s study respectively manipulated the number of strokes in two-character novel words and word length using two-character and three-character pseudowords as novel words. Both the number of strokes and word length influenced the “when” decision of eye movement control, with fewer strokes and shorter word lengths resulting in shorter fixations on novel words. The number of strokes affected saccade length into novel words, likely related to parafoveal processing, while word length affected saccade length, leaving novel words, related to foveal processing. These results support the visual constraint hypothesis (Inhoff et al., 2003), which holds the idea that visual information plays a significant role in shaping cognitive processes and behaviors.
Visual complexity is relevant for the wrap-up effect because it leads to much longer reading times per character in Chinese compared to alphabetic languages (see Liversedge et al., 2016 for comparison of Chinese, English, and Finnish text reading). This link between visual complexity and the wrap-up effect size was the core argument of the recent study (Kuperman & Schroeder, 2023) that investigated the wrap-up effect in eye-tracking text reading data from 15 languages (simplified and traditional Chinese plus 13 languages of the Multilingual Eye Movement Corpus, MECO, Siegelman et al., 2022). They divided each sentence in each language into 10 equal-sized bins based on word position (with each bin containing 2–4 words) and compared the average gaze duration in the penultimate and final bin (bins 9 and 10). In all written languages but three, gaze duration in the penultimate bin was significantly shorter (at the 5% level after Bonferroni correction) than in the final bin by 10 to 15 ms: This is a classic expression of the wrap-up effect. The three languages that did not reveal a significant difference between the pre-final and the final bin were the simplified and traditional Chinese and Korean. That is, the wrap-up effect was not observed in the two logographic languages and the alpha-syllabic Korean script. Kuperman and Schroeder (2023) hypothesized that the discrepancy between written languages lies in the visual complexity of their characters. Alphabetic languages and the abjad (Hebrew) incorporated in the MECO Wave 1 have relatively visually simple letters. For this reason, the visual decoding is relatively easy and allows the visual system to progress through the sentence rapidly. This rapid progression does not allow for the full real-time integration of the unfolding syntactic and semantic structure of the sentence, so some of this processing effort takes place at the very end of the sentence, which is in line with the previous studies (Rayner et al., 2000). Conversely, visually complex scripts like Chinese and Korean require more time to decode each character and to either segment unspaced character strings into words (in Chinese) or spaced syllabic characters into individual letters (in Korean Hangul). This processing delay allows the slower-paced integrative and updating processes to unfold while progressing through the sentence. In this case, less integration needs to be completed at the end of the sentence, and the wrap-up effect is either weaker than when reading alphabetic languages or not present.
That the wrap-up effect differs between visually complex nonalphabetic languages and alphabetic languages is confirmed by two more studies (Asahara, 2018; Wu, 2024). Wu (2024) analyzed sentence and passage reading in Chinese and observed the “reversed wrap-up” effect, that is, clause- and sentence-final words showed shorter reading times than the sentence- and clause-medial words. Similarly, the corpus-based study of Japanese by Asahara (2018) did not find the wrap-up effect at the end of sentences or clauses. In sum, there is accumulating evidence that the wrap-up effect is not universal across writing systems and that at least some of the causes proposed for its occurrence can be revisited.
The present study
Much of the prior evidence regarding the wrap-up effect in Chinese that we are aware of comes from corpus-based analyses (Kuperman & Schroeder, 2023; Wu, 2024). While they have the benefit of ecological validity of stimuli and tasks, corpus studies are not free of confounds. To our knowledge, there is only one experimental study in Chinese to directly address the wrap-up effect, Luo et al. (2013), explored syntactic, prosodic, and punctuation cues to the clause boundary; see the section “Introduction” for details.
The present study provides a tightly controlled experimental test of the wrap-up effect in a different syntactic and visual context, that is, at the end of the Chinese sentence and the end of the line on the screen. Two research questions were addressed.
(1) Is there a sentence-final wrap-up effect in simplified Chinese, defined as the inflated processing time at the end of a sentence?
(2) Is the magnitude of the sentence-final wrap-up effect modulated by the visual complexity of characters?
To investigate these research questions, experimental stimulus sentences implemented two manipulations. One was a classic wrap-up manipulation (Hirotani et al., 2006; Warren et al., 2009), where the same word occupies either the final position in the sentence, followed by the full stop, or a sentence-medial position unmarked by the punctuation. All the linguistic context preceding the word is kept identical (Hirotani et al., 2006). This manipulation is executed by placing target words at the end of one set of sentences, labeled the final condition. The second matched set of sentences, labeled the medial condition, is created by appending a modifier to the end of each sentence from the final condition, such that the target word is in the sentence- and clause-medial position and not followed by punctuation. For the final condition, we numbered words’ positions in the sentence starting from the end of the sentence. Thus, the position of the final target word in the sentence was 0, and that of the penultimate word −1, etc. We then aligned this information with the matched medial condition. The target word in this condition was again labeled as 0 and the word preceding the target as −1. Words following the target in the medial condition received positive values.
The second manipulation in our study was visual complexity of the target word and the immediately preceding word (positions 0 and −1) in the final condition and the matched words in the same positions in the medial condition. Both words contained exactly two characters, and both had either high or low visual complexity, operationalized through the number of strokes (see below). We kept two words consistent in terms of visual complexity to strengthen the potential effect by increasing the foveal load on word at position −1 and constraining the parafoveal preview benefit for the target word 0 in the high- versus low-complexity condition. This is expected to further increase the cognitive load of processing more rather than less complex characters of the target word. Table 1 provides examples of the two crossed conditions; sentence position × visual complexity.
Sentences across visual complexity and sentence position conditions.
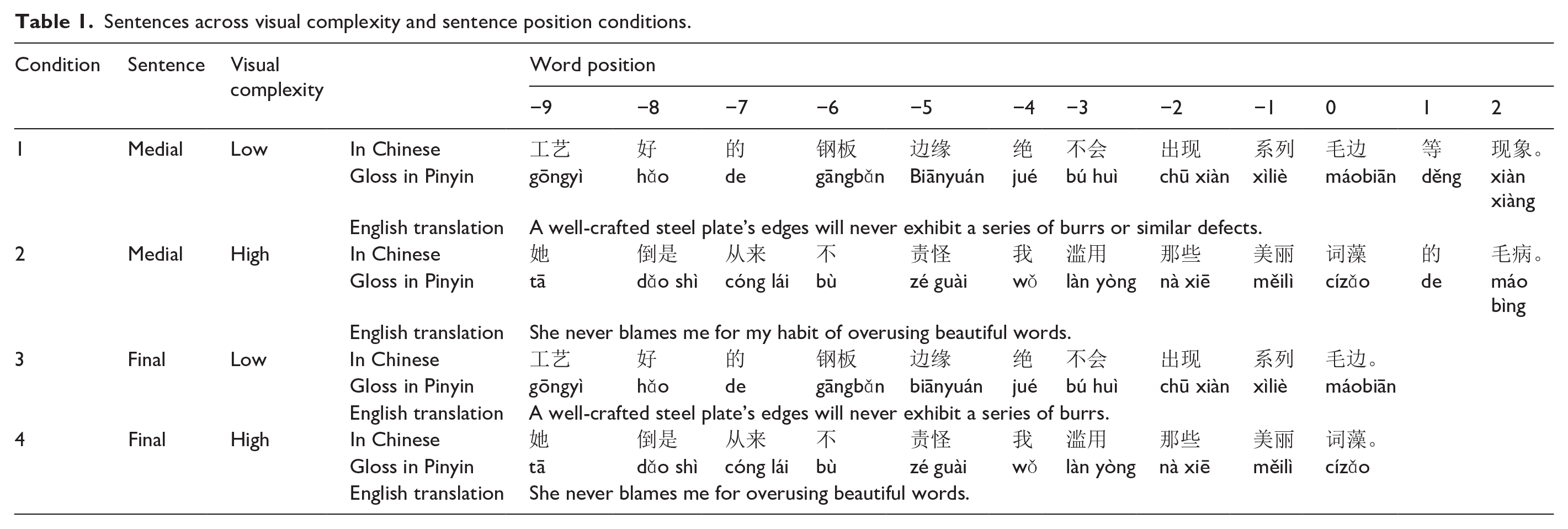
These manipulations enable us to test both the existence of the sentence-final wrap-up effect in Chinese reading and some of the proposed causes of the effect. If Chinese demonstrates this type of wrap-up effect, contra corpus-based observations of Kuperman and Schroeder (2023) and Wu (2024), the following must hold true. We should observe longer reading times at the target word at position 0 in the final condition compared to the medial condition. This sentence-final position next to the full stop is where the structural and lexical ambiguities are resolved (Rayner et al., 2000), the visual cue of the punctuation causes a low-level visual hesitation (Hill & Murray, 2000), and the contour of implicit prosody marks the end of the intonational phrase and elicits a pause (Hirotani et al., 2006). Furthermore, the wrap-up effect should also be observed in the sentence-final words of the medial condition: These words are expected to exhibit longer reading times compared to preceding words in the medial condition. If Chinese reading does not give rise to the sentence-final wrap-up effect, the reading times on the target words at position 0 (and all other words in positions up to 0) would not differ across the final and medial conditions. Moreover, the reading times on the sentence-final word in the medial condition (typically, position 3 or 4) would not differ from the reading times on immediately preceding words in the same condition.
Predictions regarding visual complexity are as follows. First, we expect less complex characters to be processed faster than more complex ones (see above for examples). If visual complexity is the reason that Chinese reading leads to a weaker wrap-up effect than reading of alphabetic languages, as hypothesized by Kuperman and Schroeder (2023), we can expect an interaction of sentence position by visual complexity. Namely, the difference between reading times for the target word (position 0) in the final versus medial condition will be stronger in the low-complexity condition (sentence 1 vs. sentence 3 in Table 1) than in the high-complexity condition (sentence 2 vs. sentence 4).
Since the consensus on what constitutes a word in Chinese is hard to reach even among proficient and educated native speakers (Liu et al., 2013), it is possible that the interest areas that we defined as words can be interpreted as phrases or other linguistic units. This does not change the logic of our comparisons outlined above: Since pairs of sentences in the final and medial conditions are identical up to and including the target unit, comparing identical units (words or phrases) would reveal the presence or absence of the wrap-up effect.
We acknowledge that our study concentrates on only one set of visual and syntactic conditions under which the wrap-up effect is expected to emerge, namely, at the end of the sentence, which is marked by the end of the line and the period, and the white space. We do not consider either the endings of sentence-internal clauses, the sentence endings in the middle of a visual line of text, or the sentence-internal punctuation in the wrap-up effect. In this sense, our current results may not generalize over all syntactic and visual conditions of the wrap-up effect and may not speak directly to all prior studies of the wrap-up effect in Chinese, including Luo et al. (2013). We view this paper as the first in the series of planned studies that will examine the effect across additional relevant conditions.
Methods
The study was conducted in accordance with the Declaration of Helsinki, and the materials and procedures used in this study have obtained approval from School of Foreign Studies at University of Science and Technology Beijing (USTB).
Participants
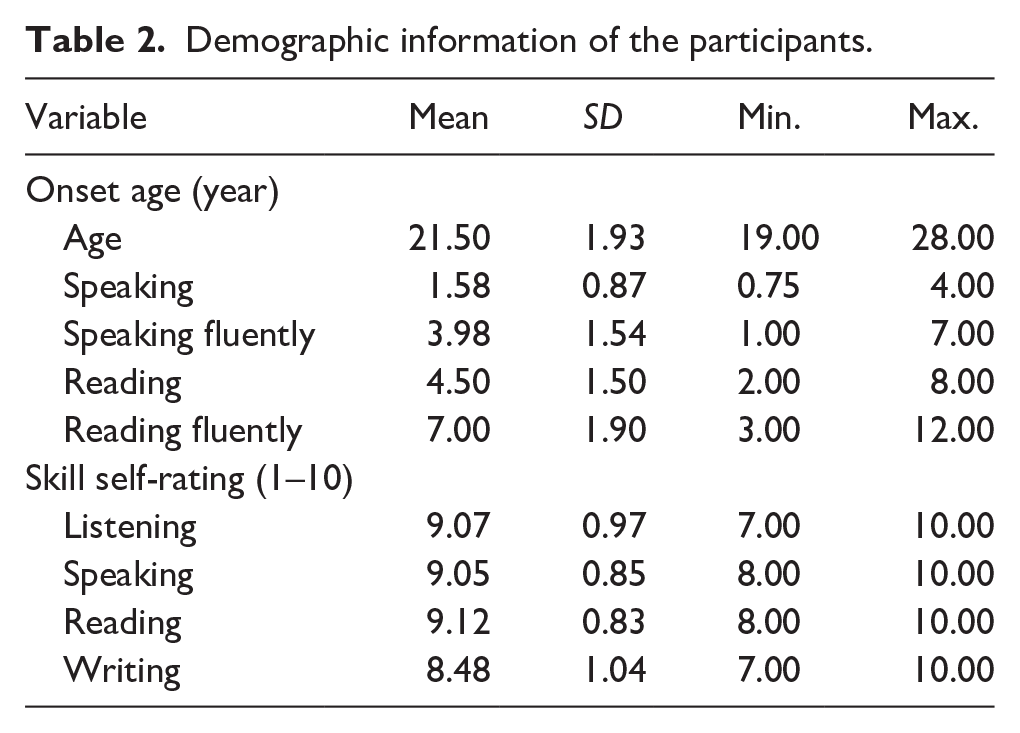
Forty-two adult Chinese natives (40 females, and 2 males; Mage = 21.5, SD = 1.93, range 19–28) participated in the study. All participants were recruited from a university in Beijing. They were native speakers of Mandarin enrolled in the undergraduate programs for English language and literature (N = 27), Engineering (N = 4) and Japanese (N = 3), or graduate programs such as Master of English language and literature (N = 1) and Master of Translation and Interpreting (N = 7). They were compensated by 100 RMB for their participants. The mean number of years of education was 14.6 years (SD = 1.2, range 11–17 years). Before the start of the study, all students signed an informed consent form. Table 2 summarizes the demographic information of the participants. Participants reported their onset age of speaking Chinese (M = 1.58, SD = 0.87), speaking fluently (M = 3.98, SD = 1.54), reading Chinese (M = 4.50, SD = 1.50), and reading fluently (M = 7.00, SD = 1.90), indicating they are early Chinese learners. Self-rating on the 10-point Likert Scale revealed they were skilled in listening comprehension (M = 9.07, SD = 0.97), speaking (M = 9.05, SD = 0.85), reading (M = 9.12, SD = 0.83), and writing (M = 8.48, SD = 1.04).
Demographic information of the participants.
Data acquisition
Eye movements were recorded using an Eyelink-1000 plus eye tracker, which is a desktop head-stabilized model manufactured by SR Research Ltd. (Kanata, ON, Canada), with a sampling rate of 1,000 Hz. The experimental procedure was implemented using the Experiment Builder software version 2.5.1 (SR Research Ltd.). A chin rest was utilized to minimize any potential head movements during the experiment. Calibration of the eye tracker involved the participant fixating on a series of nine fixed targets that were strategically positioned around the display. This was followed by a nine-point accuracy test to ensure the precise determination of eye position. Although the stimuli were viewed binocularly, only data from the participant’s right eye were analyzed. Prior to presenting the 14 practice sentences in the reading task, a dot appeared on the monitor screen, slightly offset to the left of the first word in the sentences. Once the participant had directed their gaze toward this dot, the trial would commence. This drift check occurred at the onset of each trial, and ongoing calibration was supervised by the experimenter throughout the task, being redone if deemed necessary. Following the completion of the trials, each of the 80 sentences was displayed on a separate screen in a random order across different participants. Participants were instructed to silently read the sentences for comprehension and to press the space bar upon finishing each sentence. The text was presented using a mono-spaced font (SimSun) with a font size of 20 pixels. The refresh rate of the Dale computer was set to 60 Hz. The distance between the eye tracker and the participant’s eyes was approximately 60 cm. Furthermore, the display resolution was fixed at 1,024 × 768, and the monitor’s luminance was appropriately adjusted to ensure a comfortable brightness level for each participant, which was maintained consistently throughout the experiment.
Materials
The experimental materials consisted of naturally unspaced sentences in simplified Chinese: Experimental manipulations are described above. The study incorporated a total of 14 practice sentences as well as 80 experimental sentences. Sentences in the medial condition appended words to the sentences in the final condition to make the target word appear within rather than at the end of a clause or a sentence: 5 sentences had 1 additional word, 53 sentences had 2 additional words, 20 sentences had 3 additional words and 1 sentence each for 4 and 5 additional words. To sound natural, some sentences had punctuation marks and clauses embedded in the sentences, but never near the target word position. Examples for the four conditions that crossed the word position and visual complexity manipulations in the 2 × 2 design (1–4) are shown in Table 2. The above four conditions each had 20 sentences. We defined boundaries for each word in the sentences and exported the eye movement measures at the word level.
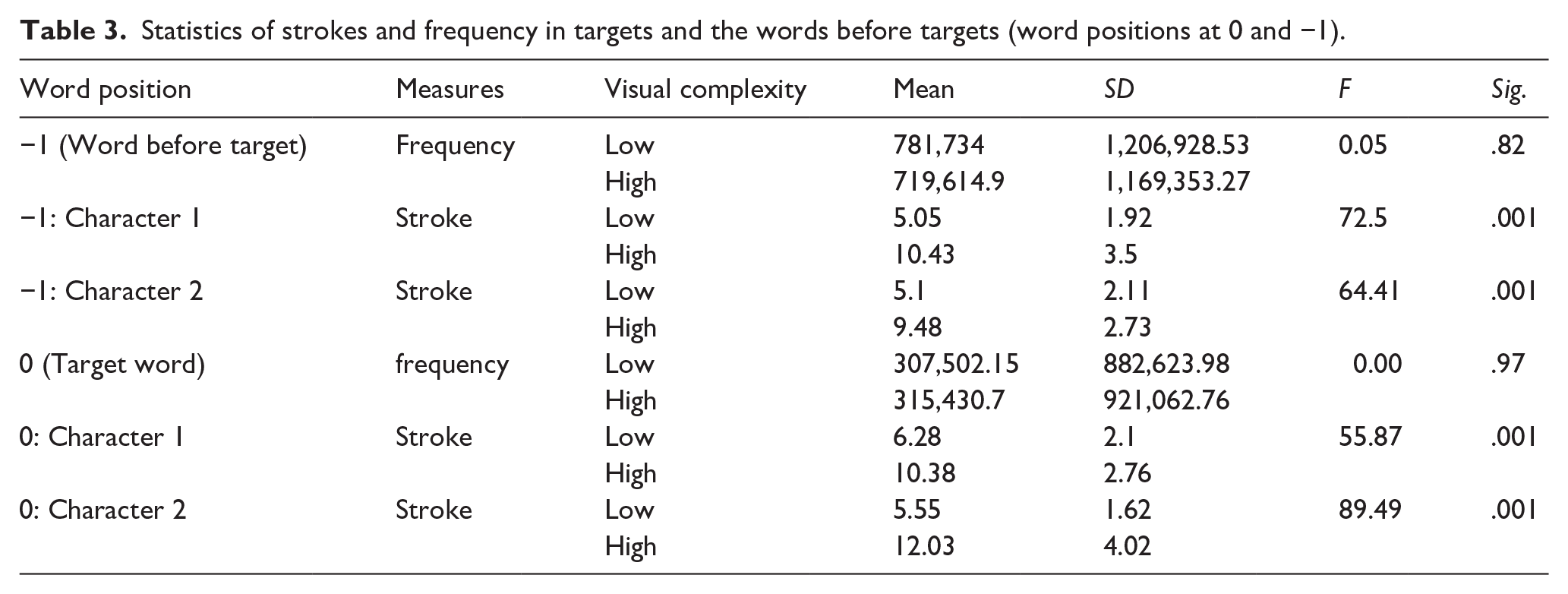
The visual complexity of words at positions −1 and 0 in each sentence was estimated as the stroke count of each character; see Table 2 for values per experimental condition. We further matched words at positions −1 and 0 on frequency across high and low visual complexity (see Table 2). Word frequency data utilized in the analysis were derived from the statistics obtained from Beijing Language and Culture University Corpus Center (BLCU Corpus Center; http://bcc.blcu.edu.cn). ANOVAs (reported in Table 3) indicated that the frequency of each of the two words was matched across the high- and low-visual complexity conditions (p = .97 for the target words; p = .82 for words preceding the targets). However, a significant statistical difference was observed in the stroke count of the characters constituting words at position 0 and −1 across the high- and low-complexity conditions, which is the expected outcome of our experimental manipulation (p < .001).
Statistics of strokes and frequency in targets and the words before targets (word positions at 0 and −1).
Variables
Dependent variables in this study were gaze duration (the summed duration of fixations on the word before the gaze leaves the word for the first time) and total fixation duration (the summed duration of all fixations on the word). Critical independent variables for the present research questions where sentence position of the target word (with levels final and medial) and visual complexity of the target word (with levels high and low). The focus of our analyses was on reading times to the target word (position 0). Yet, we extended our consideration to all words in experimental sentences. In all analyses, we took into account the relative position of the word in the sentence, its stroke count as a measure of visual complexity, and log-transformed word frequency.
Statistical analysis
Linear mixed-effects models were fitted to gaze duration and total fixation time using random intercepts for word and participant as well as random by-participant slopes for sentence position and visual complexity. If failure to converge occurred, the random effect structure was simplified until the convergence was achieved. We report the outcomes of the simplified models. Statistical software environment R version 4.4.1 (R Core Team, 2024) was used in all analyses. Library lme4 version 1.1-35.5 (Bates et al., 2015) was used for model fitting, and library ggplot2 version 3.5.1 (Wickham, 2016) for visualization.
Availability
The data and code used in this paper are available at the Open Science Framework repository at: https://osf.io/xf2q9/ (the view-only link is currently provided for peer-review purposes only; it will be replaced by the open-access link when the paper is accepted for publication)
Results
The full dataset representing all words across all experimental conditions consisted of 39,924 observations. One of the participants demonstrated comprehension accuracy below 70% and was removed. This reduced the dataset to 38,991 observations from 41 participants. Of these, 18,141 words were fixated at least once, and the remainder were skipped. We further removed words that elicited first fixations shorter than 80 ms, total fixation times longer than 1,500 ms, and six or more fixations. The cutoff of 80 ms is determined by the well-attested timeline of encoding visual information useful for reading (Rayner, 1998). Cutoffs for total fixation times and number of fixations were determined through the inspection of respective data distributions and roughly correspond to the top 1% of those distributions; for the best practices of data cleaning, see the study by Eskenazi (2024). The resulting dataset of fixated words contained 17,107 observations. Descriptive statistics of several eye movement measures are shown in Table 4.
Descriptive statistics of eye-tracking data across experimental conditions.
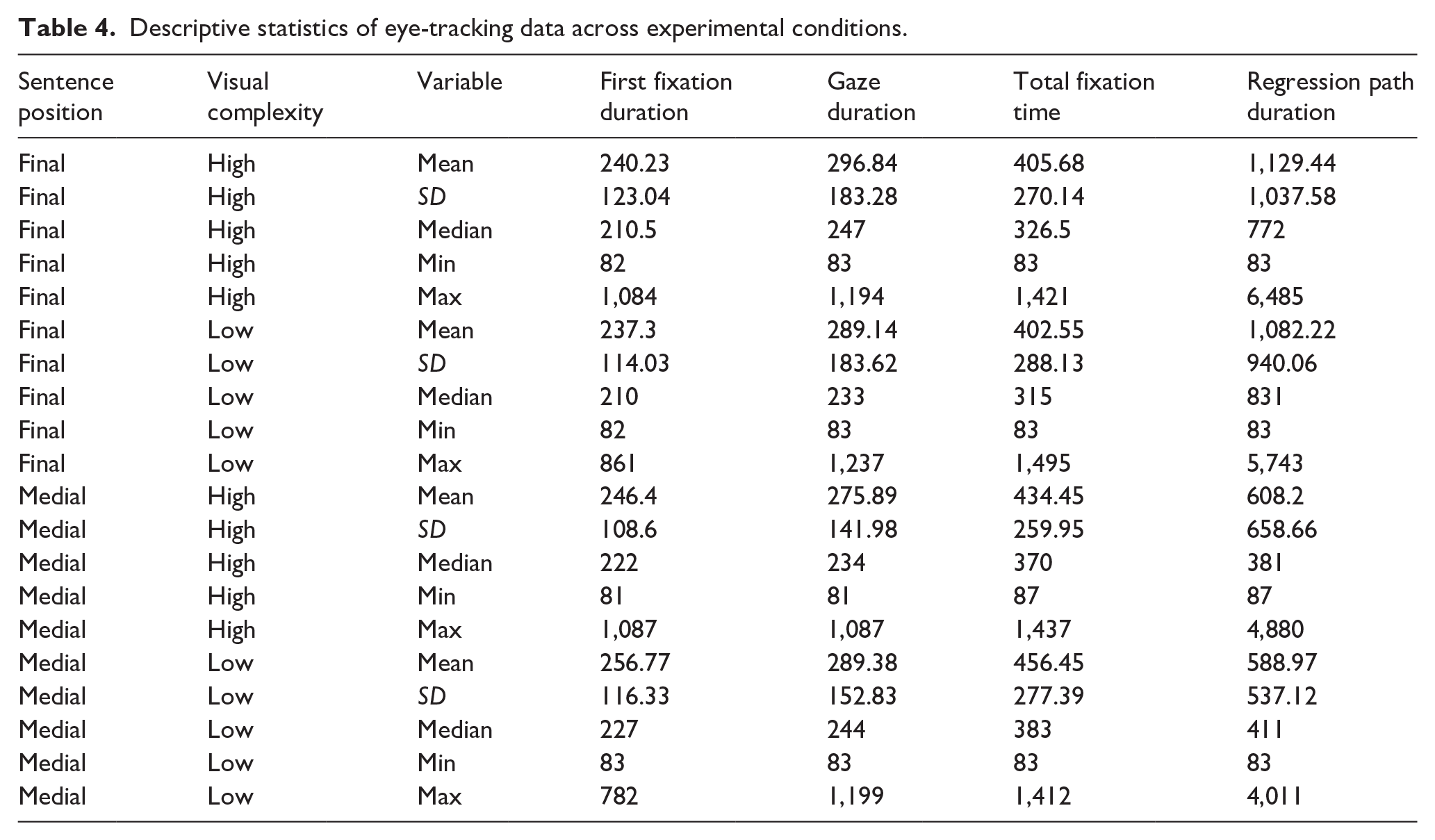
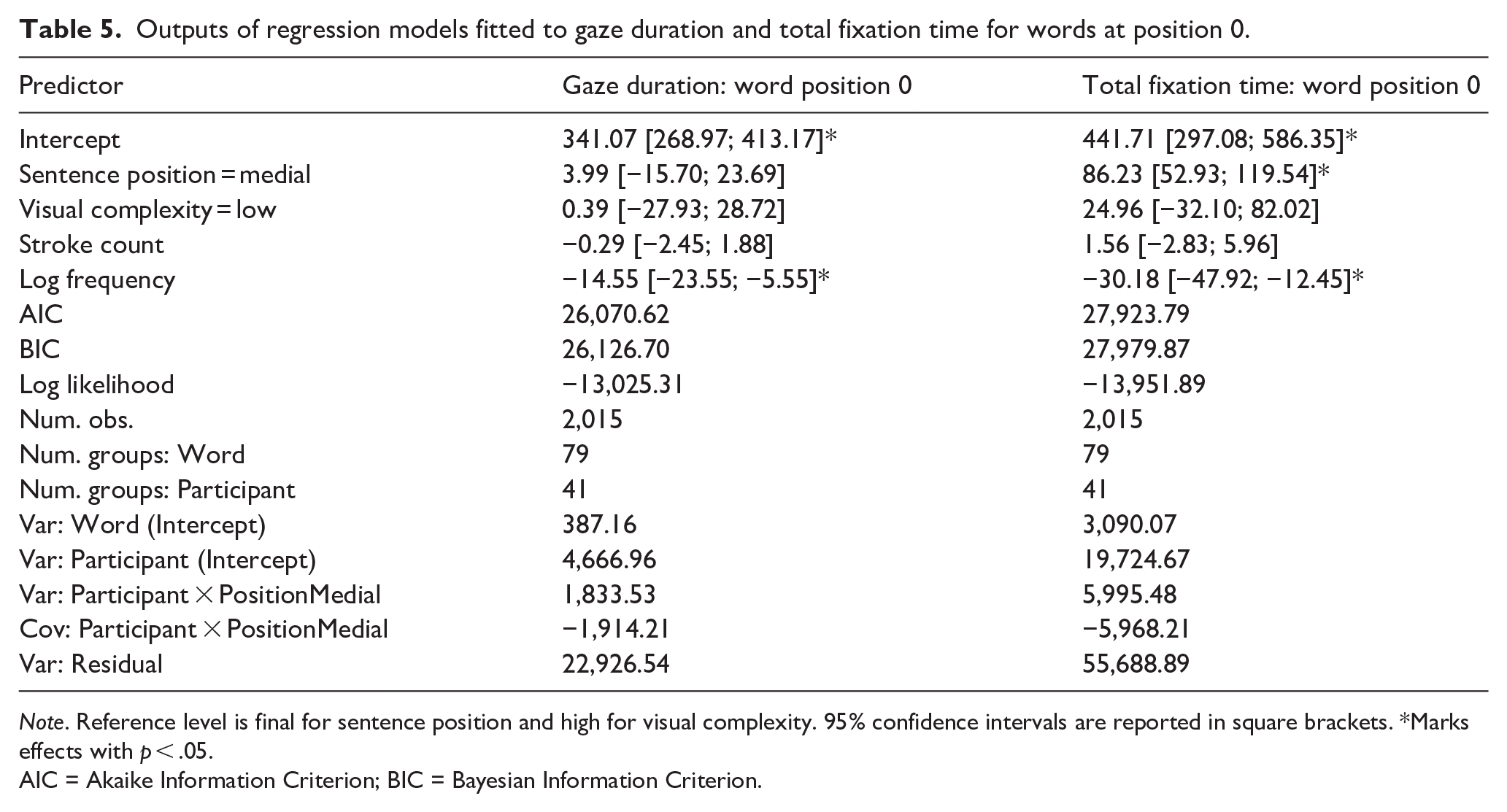
Figure 1 visualizes gaze duration and total fixation duration by word position for both the final and medial conditions, while Table 5 summarizes outputs of the linear mixed-effects models fitted to gaze duration and total fixation times for words at positions 0 and −1.
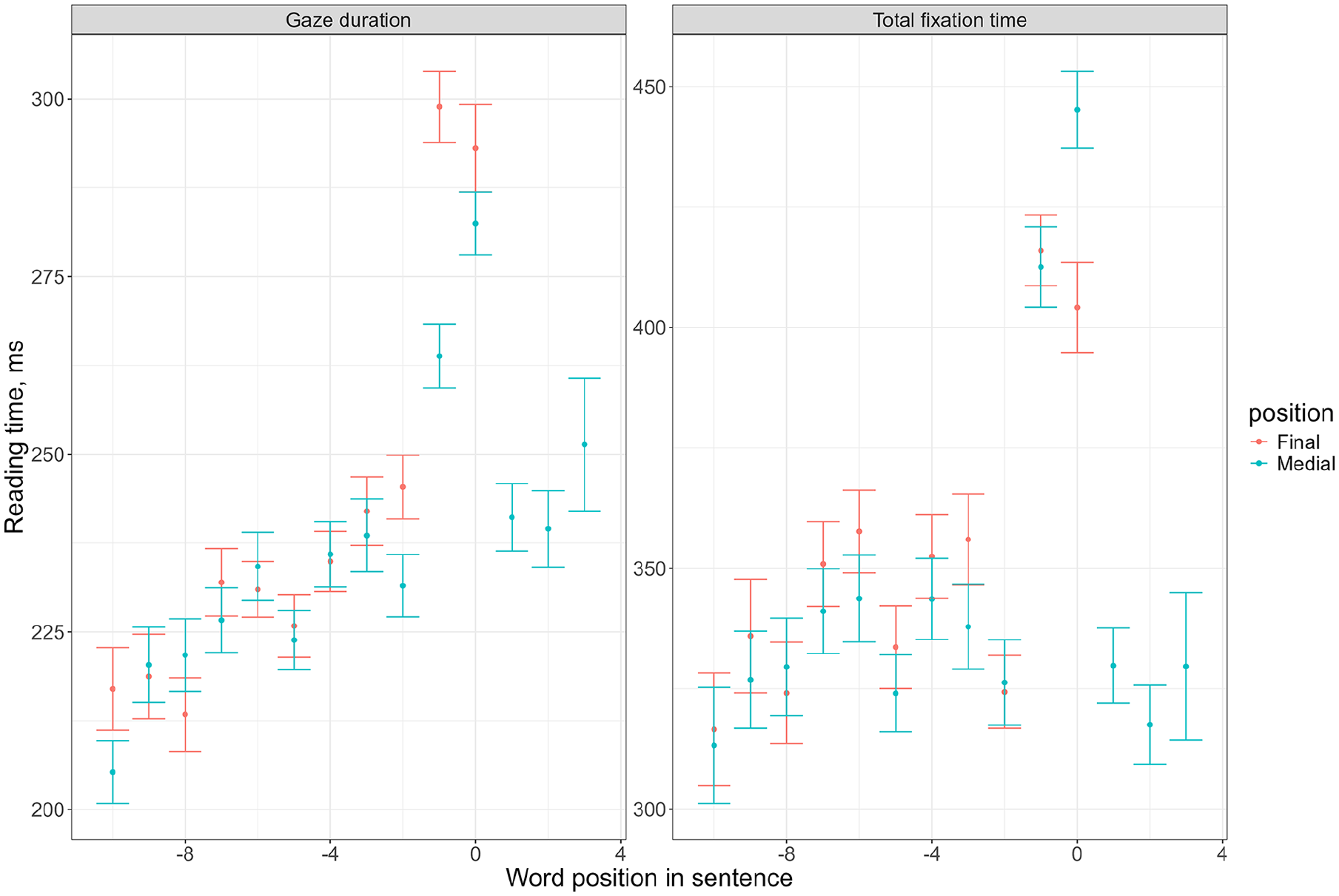
Mean gaze duration (left panel) and total fixation time (right panel) per word position in the sentence.
Outputs of regression models fitted to gaze duration and total fixation time for words at position 0.
Note. Reference level is final for sentence position and high for visual complexity. 95% confidence intervals are reported in square brackets. *Marks effects with p < .05.
AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion.
Is there a wrap-up effect in Chinese?
Eye movement patterns illustrated in Figure 1 provide an answer to our first research question: Whether the wrap-up effect exists in Chinese reading. The answer is negative. As we argued in the section “Introduction,” one critical comparison is between reading times on the word at position 0 (sentence-final or -medial in respective conditions). This comparison reveals no significant difference between the final versus medial condition in gaze duration (β = 3.99, SE = 10.05, t = 0.40), while controlling for visual complexity of characters, their stroke count, and word frequency. The difference in total fixation duration was in the direction opposite to the classic wrap-up effect, namely, words in the sentence-medial position were processed substantially and significantly slower than those in the sentence-final position, by 86 ms (β = 86.23, SE = 16.99, t = 5.08). This reversed wrap-up effect is consistent with the corpus-based finding by Wu (2024).
Visual inspection of the words that are identical across two matching conditions, that is, words with positions marked with the negative numbers and zero in Figure 1, is revealing as well. Gaze durations do not diverge across conditions, except for words −2 and −1. In these positions, the final condition elicits longer reading times than the medial conditions (see Table 5). It may be tempting to interpret these inflated reading times as evidence in favor of the wrap-up effect, which simply manifests itself slightly before the actual sentence ending and punctuation. Yet the patterns of total fixation times rule out this explanation. All matching words across final and medial conditions elicit the same total fixation times, except for the target word at position 0, as discussed above. Thus, the differences in gaze durations can be attributed to the trade-off between prolonging the first pass on the word or breaking it short but regressing back to the word: The sum total of word processing time, gauged by total fixation time, does not vary as a function of sentence-final versus medial word position.
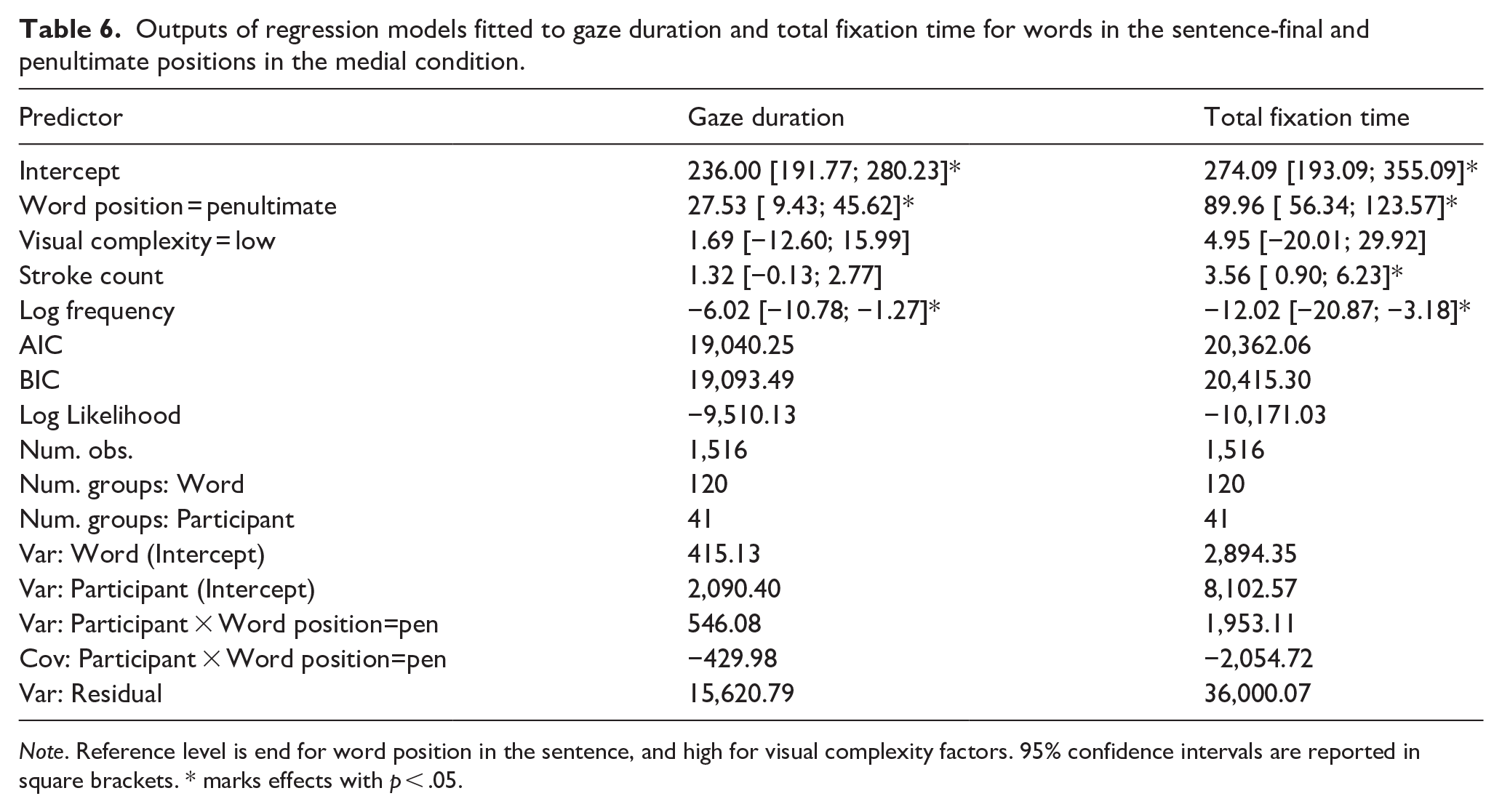
Our experimental manipulations create another possible locus for the wrap-up effect, that is, the sentence endings in the medial condition. If the wrap-up effect holds in Chinese, the words at the end of these sentences are expected to elicit longer fixation times compared to preceding words in those sentences. We drew the second critical comparison between words ending the sentences in the medial condition versus penultimate words in the same sentences (labeled as “end” vs. “penultimate”). As in analyses above, we accounted for visual complexity, stroke count, and log frequency, as well as random effects in regression models fitted to gaze duration and total fixation times to the words in the abovementioned positions. Table 6 summarizes the findings. Both in gaze duration and total fixation times, penultimate words took significantly longer to process (by 28 and 90 ms, respectively) than the sentence-final words. This reversed wrap-up effect converges with our first critical comparison, reported above in this section, and runs counter to the reports of the wrap-up effects in alphabetic languages.
Outputs of regression models fitted to gaze duration and total fixation time for words in the sentence-final and penultimate positions in the medial condition.
Note. Reference level is end for word position in the sentence, and high for visual complexity factors. 95% confidence intervals are reported in square brackets. * marks effects with p < .05.
Another noteworthy observation is that reading times—both gaze durations and total fixation times—are indeed the longest toward the end of the sentence in the final condition (words −1 and 0 compared to preceding words in the sentence). Without the experimental control, this pattern might appear to replicate the wrap-up effect found in alphabetic languages. Yet the same or even inflation in reading times toward words at positions −1 and 0 takes place in the medial condition, even in the absence of either syntactic or visual cues to the sentence ending. This is compatible with the notion that information content and surprisal increase as the sentence progresses, and readers respond to these increases in information content in the prior context during the incremental word-by-word processing of the sentence, irrespective of whether these words end the sentence or not.
Interestingly, reading times decrease sharply in the medial condition after the word at position 0, see positive word positions values on the x-axis in Figure 1. Indirectly, this pattern confirms that the contingency of the processing effort (and reading times) is on unfolding information content rather than on the sentence ending as the processing locus. The medial condition appended syntactically and semantically simple modifiers to the final condition sentences that do not present substantial structural or lexical ambiguity or long-distance dependencies to resolve. Thus, the drop in fixation times is indicative of that lower information content and processing effort, irrespective of the word position in the sentence.
What is the role of visual complexity?
This study tested a hypothesis that the absence of the wrap-up effect in Chinese and its presence in alphabetic languages is because of the high visual complexity of Chinese characters, which require a greater decoding effort and allow for additional time for incremental syntactic and semantic processing (Kuperman & Schroeder, 2023). Visual complexity manipulation of words at positions −1 and 0 sought to test this hypothesis. Yet the contrast between high- and low-visual complexity conditions did not elicit any main effect on reading times to word at position 0, nor did it enter into interaction with the sentence-final versus sentence-medial position of the word in predicting word reading times. In sum, contrary to our initial hypothesis and to Kuperman and Schroeder (2023), visual complexity was not an influential factor for the direction or magnitude of the observed null or reversed wrap-up effects.
General discussion
The present study revisits the wrap-up effect, that is, the inflation in reading times, at the end of a sentence (for early reports, see Aaronson & Scarborough, 1976; Just & Carpenter, 1980; Rayner et al., 1989). While being under scrutiny for nearly 50 years, the causes of the wrap-up effects are still debated. Proposed candidates include a hypothesis that boundaries of clauses and sentences are the loci where linguistic ambiguities within the clause are settled, the content of the just-finished clause is integrated with other clauses, and prior discourse is updated: These cognitive operations enable readers to free up memory resources for the processing of new clauses (Just & Carpenter, 1980; Rayner et al., 2000). Other accounts invoke the well-supported notion that sentence comprehension is highly incremental, and thus ambiguities tend to get resolved and integration executed during the word-by-word building of the semantic representation of the sentence. On this view, “it is unclear what unfinished semantic and discourse work remains to be done at the ends of clauses and sentences” (Hirotani et al., 2006, p. 426). The accounts that highlight incrementality explain the wrap-up effects by either the hesitation of the oculomotor system when it comes across punctuation cues often placed at the ends of clauses or sentences (Hill & Murray, 2000; Warren et al., 2009), or the influence of implicit prosody that readers make use of even when silently reading for comprehension (Hirotani et al., 2006). Yet another account (Meister et al., 2024) proposes that either words toward the clause or sentence endings have higher surprisal values than clause-internal words, or readers engage in different cognitive processes in clause- or sentence-final versus -medial words, or both.
The point of onset for the present study is an intriguing suggestion that the wrap-up effect may not be cross-linguistically universal. Wu’s (2024) analysis of the Hong Kong Corpus of sentences and passages in simplified Chinese reported the reversed wrap-up effect: Sentence- and clause-final words were read faster than clause-medial words. Kuperman and Schroeder’s (2023) analysis of text reading similarly observed a healthy sentence-final wrap-up effect in all alphabetic and abjad languages of the Multilingual Eye-Movement Corpus (Siegelman et al., 2022), but no differences between sentence-final and sentence-medial words in simplified and traditional logographic systems of Chinese writing, nor in Korean Hangul. No wrap-up effect was observed either in the corpus study of Japanese (Asahara, 2018). These discrepancies may emerge both from the structural properties of languages and the specifics of the writing systems which are briefly reviewed in the section “Introduction” and further discussed below.
The present study revisits both ubiquity of the wrap-up effect and its causal mechanisms through a study of sentence reading in simplified Chinese, removing confounds inherent in corpus studies through tight experimental control. The key manipulation was implemented through creating two pairwise matched sets of sentences: In one set, target words occupy the sentence-final position, and in its counterpart, created by appending modifiers to the sentence ending, they occupy the sentence-medial position. We focused on only one context in which the wrap-up effect may arise, that is, at the end of the sentence, which is marked by the end of the visual line on the screen, the period, and white space. The critical comparisons were between the fixation times on the target words in the final versus medial conditions, as well as between the final word and the penultimate word in the medial condition (see Table 1). Another manipulation aimed to address the visual complexity of characters as a source of potential discrepancy in the wrap-up effect between alphabetic and logographic languages. As a result, the target word and the preceding word were selected to have either a relatively low or a high number of strokes in each character.
The results were straightforward. Words in the sentence-final position were processed equally fast or faster than those in the sentence-medial position, with total fixation times shorter by 80 to 90 ms than in the respective counterparts. This direction of the effect, opposite to the classic wrap-up in alphabetic languages, was found both in the target words in the fully matched sentences and in the more flexible context where the sentence-final word in medial sentences was compared to the preceding word in the same sentences. Gaze durations showed weaker contrasts in the same direction. Thus, the findings confirmed the reversed wrap-up effect reported by Wu (2024). Visual complexity of characters did not influence the magnitude or direction of the reversed wrap-up effect. We also found—contra our initial assumptions—that visual complexity does not co-determine the wrap-up effect in simplified Chinese.
One implication of our findings is that the practice of removing sentence-final words before data analysis to avoid the wrap-up effect as a confound may be warranted in alphabetic languages, but it is unnecessary in Chinese.
What existing accounts are compatible with the findings in Chinese?
Our findings call for a reappraisal of one of the most robust effects in the eye-tracking literature on reading and enable us to adjudicate between some of the competing causal accounts. For instance, the account proposing that the end of the sentence is where ambiguities are resolved and semantic integration takes place, giving rise to an additional cognitive effort and processing slowdown (Rayner et al., 2000) does not find support in Chinese. Similarly, the account highlighting the end-of-sentence punctuation as the visual cue that delays the oculomotor processing (Warren et al., 2009) is not corroborated by evidence. Sentences in Chinese end with a punctuation mark signaling a full stop, yet it evidently does not cause the wrap-up inflation of reading times. By the same token, there is no reason to question the presence of pauses in spoken Chinese at the end of the sentences, as a prosodic device helping the listeners to detect the end of an utterance. Similarly, there is no reason to doubt that Chinese readers are at least as sensitive to the intonational contour of implicit prosody while reading sentences as are the readers of alphabetic languages. Since the sentence-final wrap-up effect is not found in Chinese sentences, the intonational contour is an unlikely causal factor both in Chinese and other languages (in contrast with Hirotani et al., 2006). We note that our findings and interpretation run counter to the argument by Luo et al. (2013) who found that punctuation (the presence of a comma) and overt prosodic contour presented auditorily do elicit wrap-up effects in Chinese sentence reading. We believe that this discrepancy derives both from the use of syntactic ambiguity in the study by Luo et al. versus unambiguous sentences in the present study, from the differences between clause boundaries explored by Luo et al. and sentence boundaries explored in this paper, and from the use of audio recordings and the gaze-contingent preview chance paradigm in Luo et al.’s study versus simple sentence reading in the present study. Examination of the conditions under which the wrap-up effect is possible to observe in Chinese is an important task for the future research.
The only account that is—in principle—compatible with the present findings is the information-theoretical one (Meister et al., 2024). One premise of Meister et al.’s account is that the processing effort and reading time of each word are proportional to the surprisal value of this word, which in turn is determined by the distribution of linguistic information in prior context. On this account, sentence processing is highly incremental, with little to no spillover of the cognitive effort to subsequent words or the sentence ending. Inflation of reading times takes place whenever surprisal is high. Analyzing data in English, Meister et al. conjecture that sentence endings tend to come with high surprisal, which causes the wrap-up effect. It is possible that the syntax of Chinese, and the related distribution of information over context, is such that the peak in surprisal does not necessarily coincide with the sentence ending, and thus the inflation of reading times is shifted away from sentence-final words.
Our data (visualized in Figure 1) are generally compatible with this possibility. The matched sentences in the final and medial conditions have identical prior contexts up to the target word, that is, word at position 0. The identical distribution of information in these prior contexts would account for the very minor and insignificant differences in gaze durations for virtually all words up to and including the target word. The drastic decrease in reading times on words downstream of position 0 in the medial condition may reflect the relative ease of processing the modifier at the end of the sentence, that is, the phrase without linguistic ambiguity or long-distance dependencies to resolve. Longer total fixation times in the medial versus final condition may reflect the fact that regressions into word 0 are only possible in the medial but not the final condition: When these regressions take place to revisit the prior context, inflation of reading times takes place. Similarly, it is plausible that the final word in the medial condition is more predictable (has lower surprisal) than the immediately preceding word, due to accumulating contextual constraint: This would account for shorter reading times on the final versus penultimate word in this comparison.
We note that the confirmation of Meister et al.’s (2024) account requires calculation of surprisal values for a large corpus of Chinese and, say, English sentences and examination of their distribution over the sentence length. Observing that the peak of surprisal is associated with the sentence ending in English but not in Chinese would help explain the discrepancies in the wrap-up effect from the information-theoretic point of view. It would also eliminate the need for the second premise of Meister et al. (2024), that is, that sentence-final words elicit different cognitive processes or command a reader’s greater sensitivity to surprisal than sentence-medial ones. While outside the scope of this paper, this makes a promising future avenue for investigation.
Why the cross-linguistic discrepancy?
We argue that the discrepancy between Chinese and alphabetic and abjad languages stems from profound typological differences in the language structures and scripts. As reviewed in the section “Introduction,” Chinese characters function as standalone units, with every character representing a word or a meaningful component of one. Reading Chinese characters involves a more holistic processing approach (Dehaene, 2010; Kao et al., 2010). This holistic processing is likely to result in a more evenly distributed cognitive load throughout reading. Moreover, written Chinese offers no visual cues as to the word boundaries and has a relatively free word order and few syntactic and discourse markers that signal the clause boundaries. Punctuation in Chinese also differs from English in terms of spacing and stylistic conventions. These typological features of Chinese complicate the definition and detection of some of the loci where the wrap-up effect takes place, that is, the clause endings. The logographic nature of Chinese characters is compounded by the topic-prominent structure and the flexibility in sentence construction, potentially reducing the need for anticipatory processing at sentence boundaries found in alphabetic languages. Consequently, the cognitive load is more evenly spread, and anticipation at sentence boundaries is diminished when reading simplified Chinese. Accordingly, the sentence-final wrap-up effect is attenuated in Chinese.
This study only tested one of the possible causes for the absent or reversed wrap-up effect, that is, visual complexity of the words at the sentence ending. The null effect of this manipulation indicates that it is an unlikely cause of the behavioral discrepancy between simplified Chinese and alphabetic languages. We note, however, that even in the characters belonging to the condition with low visual complexity, the average stroke count was between 5 and 6 strokes. This is roughly twice as high as the number of strokes required for capital letters in the Roman script (e.g., 3 strokes in K). Thus, it is possible that the Chinese characters, even the visually simplest ones, are still too complex to elicit the wrap-up effect.
Limitations and future directions
Evidently, disentangling linguistic and visual sources of the reversed or absent wrap-up effect in logographic scripts, and the reasons for its divergence from that in alphabetic scripts, may require a new line of research. We only tested whether the wrap-up effect is present at sentence endings in simplified Chinese (it is not) and whether the visual complexity of sentence-final characters is responsible for it (it is not). This investigation can be taken further in several ways. This paper has only investigated one of the configurations of visual, orthographic, and syntactic parameters that may elicit the wrap-up effect: The sentence ending marked by the period and the end of the line on the screen. Prior work on Chinese (Luo et al., 2013) suggests that other configurations (sentence-internal clauses with or without punctuation) may give rise to the traditional wrap-up effect, with inflated reading times at the clause ending. The systematic examination of the wrap-up compatible configurations is an issue for future research.
Another perspective may be pursued in experimental studies of other logographic scripts, like traditional Chinese and Japanese, and perhaps other visually complex scripts (Korean Hangul, Hindi Devanagari, unspaced Thai). They may indicate how prevalent the inter-script divide is for the direction of the wrap-up effect. Another possibility is to test whether the wrap-up effect emerges, and in what direction, in reading pinyin (the Roman-script spelling of written Chinese), which introduces spaces and visually simple letters to express the same phonology as the logographic Chinese script. Such a study would test whether the reversal of the wrap-up effect is due to the difficulty of identifying clause boundaries, because of the lack of spacing and visual complexity. A similar investigation can be conducted in simplified Chinese but with artificially introduced spaces at the word or clause boundaries.
We also note that the study was predicated upon manipulating visual complexity based on the stroke count within Chinese characters. While this is a conventional approach, it may not fully capture the multifaceted nature of visual complexity. Future studies could explore additional measures of visual complexity, such as character familiarity or structural complexity, to provide a more nuanced understanding of how visual factors influence reading processes.
Conclusion
This study promotes the burgeoning research framework that investigates features of reading behavior that are universal across written languages of the world or specific to individual writing systems or languages (see e.g., Liu et al., 2013; Liversedge et al., 2016; Siegelman et al., 2022). Our findings of the reversed wrap-up effect in reading simplified Chinese are novel and contribute to this framework in three ways. First, it serves as another demonstration that cross-linguistic consideration of even very robust behavioral effects may correct the received theories based on a handful of typologically similar languages and scripts. Second, the findings demonstrate the methodological life cycle of corpus studies and experimentation. While the former type of research is exploratory and aims at generating new hypotheses in more naturalistic tasks, the latter type offers a tighter experimental control and enables hypothesis confirmation. This study confirms findings from sentence- and text-reading corpora that either examine Chinese in comparison to other written languages (Kuperman & Schroeder, 2023) or on its own (Wu, 2024). Second, our study makes it possible to adjudicate between existing accounts of the wrap-up effect. The key point of this adjudication is whether the accounts rely on a mechanism that is expected to generalize across readers of all languages, who can be assumed to possess the same (neuro)physiological, visuo-perceptual, and motor machinery, but differ in linguistic knowledge and experience. As a result, we believe that the sole existing account with the potential to explain the counter-directed wrap-up effects across languages is the information-theoretical model, in which reading times reflect the distribution of word-level surprisal based on prior contexts (Meister et al., 2024). We also propose several ways in which the investigation of the wrap-up effect can fruitfully continue.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The second and last authors were supported by the Social Sciences and Humanities Research Council of Canada Partnered Research Training Grant (895-2016-1008; Libben PI), Insight Grant (435-2021-0657; Kuperman, PI) and the Canada Research Chair (Tier 2; Kuperman, PI).