
Abstract
In dual tasks, with a visual-manual choice reaction time task in Task 1 and a go/no-go task in Task 2, not responding to Task 2 can have adverse effects on Task 1 performance, as demonstrated by no-go backward crosstalk effects (no-go BCE). Here, the response inhibition required to not respond to Task 2 spills over and slows response execution in Task 1. Over three experiments, we investigated whether the prospect of reward, which is a potent cognitive control modulator, influences no-go BCE. In Experiment 1, reward for fast and accurate responses in both tasks was modulated as a within-subject factor, and in Experiments 2 and 3, as a between-subject factor. The results revealed three major insights. In all three experiments, reward led to faster Task 1 and Task 2 performance. Second, despite this speeding, the no-go BCE was not modulated by reward. Finally, the reward led to more errors in Task 2 no-go trials. These results reveal a reward-induced bias for action, suggesting better preparedness to respond and, consequently, larger commission errors in Task 2 no-go trials. The absence of a reward-based modulation of the no-go BCE indicates that the reward-induced bias for action does not necessarily translate into larger response inhibition. These findings point towards the complex interactions between reward and inhibitory control and shed light on the potentials and limitations of reward-based modulation of dual-task interference.
Introduction
It is not uncommon to see people talking or texting on their cell phones while walking. This becomes especially dangerous when one has to hold a steady conversation while crossing a busy road or halt as soon as the traffic signal turns red. For example, participants consider riskier crossing choices while engaged in a phone conversation, thus impairing their street-crossing abilities (Banducci et al., 2016). Pedestrian injuries and fatalities are increasing dramatically (National Highway Traffic Safety Administration, 2023), and performance costs due to multitasking are becoming a growing concern not only with pedestrian safety but also in other domains. Therefore, it is imperative to understand the underlying mechanisms of these limiting performance costs and whether these costs can be reduced by motivational factors. In particular, incentives such as prospective rewards are strong motivators for aligning behaviour with the current goal (Braver et al., 2014; Chiew, 2021; Chiew & Braver, 2011; Dreisbach & Fischer, 2012; Fröber & Dreisbach, 2016, 2021; Padmala & Pessoa, 2010; Yee & Braver, 2018). Therefore, understanding the source of dual-task performance costs as well as investigating how external factors such as reward modulate dual-tasking are crucial when aiming to optimise dual-task performance. In this study, we investigated the effects of prospective reward on performance costs arising from crosstalk between two tasks in a dual-task situation.
One popular approach to investigate dual-task performance and factors that contribute to dual-task costs is the psychological refractory period (PRP) paradigm (Pashler, 1994). In this paradigm, a stimulus for Task 1 (S1) appears on the screen, and after a short temporal delay, known as the stimulus onset asynchrony (SOA), the second stimulus (S2) appears for Task 2. Participants are instructed to respond to S1 first and then to S2. The crucial manipulation here is that the temporal overlap between the two tasks is varied; that is, at short SOAs (e.g., 40 ms), the temporal overlap between the two tasks is high compared to long SOAs (e.g., 1000 ms). As a result, large performance decrements are observed for shorter compared to longer SOAs for Task 2, while Task 1 performance is less affected by varying degrees of temporal overlap. The performance decrement in Task 2 for short compared to long SOAs is known as the PRP effect (Meyer & Kieras, 1996; Pashler, 1984; Welford, 1952). The Response Selection Bottleneck (RSB) model attributes these costs to capacity constraints, that is, a processing bottleneck at the central processing stage, which can only serve one task at a time (Pashler, 1994; Pashler & Johnston, 1989). Thus, at short SOAs, Task 2 central processing must wait until the central processing of Task 1 is completed, resulting in prolonged Task 2 responses (see Fischer & Janczyk, 2022 and Koch et al., 2018 for reviews).
Thus, the RSB model argues for independent processing of the two tasks. However, the processing of two tasks often leads to between-task interactions when performed simultaneously. Recent studies have shown that, under certain circumstances, Task 2 response-selection related processes can affect Task 1 response selection, thus challenging the view of discrete and independent task processing. This results in a dual-task cost due to crosstalk between the response-selection processes of both tasks, which is a powerful source of interference (Duncan, 1979; Lien & Proctor, 2002; Navon & Miller, 1987). Applied to the aforementioned street-crossing example, the secondary task of texting a message interferes with processing information related to the prioritised task of crossing the busy street. This kind of crosstalk where Task 2 processing influences Task 1 performance is termed backward crosstalk effects (BCE).
Two types of backward crosstalk as markers of between-task interference
Crosstalk typically occurs in a situation in which both tasks share a dimensional (e.g., response, spatial, or semantic) overlap (Lien & Proctor, 2002; Logan & Schulkind, 2000; Navon & Miller, 1987). Hommel (1998), for example, demonstrated the so-called compatibility-based BCE by recruiting coloured letters as stimuli for Task 1 and Task 2. Hommel instructed the participants to manually respond left or right to the colour of the letter (Task 1), followed by a verbal “left” or “right” utterance to the identity of the letter (Task 2). The compatibility was based on the response code overlap. A trial was termed compatible when the response codes for both tasks matched, for example, when the manual response left coincided with the verbal response “left.” When the response codes differed, for example, when the manual response left coincided with the verbal response “right,” the trial was termed incompatible. The important finding was that the reaction time to Task 1 (RT1) was longer in incompatible as compared to compatible conditions. These findings demonstrated that prior to the completion of Task 1 processing, central Task 2 processing must have been underway, thus influencing the Task 1 stimulus-response translation process. This backward crosstalk challenges the notion of strictly serial response selection of the RSB model. Thus, BCEs have prompted a re-evaluation of the RSB model, in which the response selection stage was subdivided into an automatic, parallel running response activation stage, followed by a strictly serial response selection stage (Hommel, 1998; Lien & Proctor, 2002; Schubert et al., 2008). Numerous studies have shown compatibility-based BCEs with different dual-task paradigms, with various feature and response overlaps (Brüning et al., 2022; Ellenbogen & Meiran, 2008, 2011; Fischer et al., 2007; Fischer & Liepelt, 2020; Hommel & Eglau, 2002; Janczyk, 2016; Janczyk et al., 2018; Koob et al., 2023, 2024; Lien et al., 2007; Logan & Schulkind, 2000; Lück et al., 2023; Mahesan et al., 2021; Scherbaum et al., 2015; Schonard et al., 2022; for a review, see Fischer & Janczyk, 2022), thus providing additional evidence for the parallel activation of stimulus-response translation processes. Importantly, the dimensional task codes overlap as the underlying mechanism is the defining feature of the compatibility-based BCE (see Fischer & Janczyk, 2022).
Backward crosstalk, however, can also occur when both tasks do not share dimensional overlap. One such BCE was reported by Miller and Alderton (2006), who demonstrated that the (task-irrelevant) force exerted to respond to Task 1 was influenced by the later required response force characteristics in Task 2 (soft vs. hard button press). These results show that crosstalk can have an impact at the motor execution stage without any task similarity. In a further setup, Miller (2006) employed a PRP paradigm, where the participants were instructed to respond to a choice task in Task 1, followed by a go/no-go task in Task 2. Here, participants responded faster to Task 1 when Task 2 required a response (go trial) as compared to withholding a response in Task 2 (no-go trial). This so-called no-go BCE occurred without any dimensional overlap and is typically explained via the inhibition hypothesis, according to which the inhibition required to not respond to Task 2 spills over to Task 1 motor execution stage and interferes with executing a response in Task 1 (Durst & Janczyk, 2018, 2019; Janczyk & Huestegge, 2017; Mahesan et al., 2021; Miller, 2006; Schonard et al., 2022, but see Röttger & Haider, 2017 for an alternate explanation). Confirming this argumentation, subsequent research demonstrated that, more the participants prepared to respond to Task 2, the larger was the no-go BCEs (Durst et al., 2019; Janczyk & Huestegge, 2017; Mahesan et al., 2021). Conditions with simple stimulus detection in Task 2 (compared to choice RT task) or a high proportion of go trials (compared to no-go trials) resulted in a stronger response tendency for Task 2 go trials but required more inhibitory control to not respond to Task 2 no-go trials. Consequently, larger no-go BCEs were observed in Task 1 (Janczyk & Huestegge, 2017).
Although both types of BCE, compatibility-based and no-go BCE arise due to the processing of Task 2 interfering with Task 1 performance, the underlying mechanisms of both BCEs have been claimed to be very different. Whereas the compatibility-based BCE rests on a dimensional overlap that allows the influence of Task 2 response activation on Task 1 response selection (Janczyk et al., 2018), the no-go BCE is due to the influence of response inhibition from Task 2 on the motor execution stage of Task 1 (Durst & Janczyk, 2018). Furthermore, recent studies also showed that conflict adaptation recruited by each of these BCEs is independent of each other, furthering the distinction between the two types of BCEs (Durst & Janczyk, 2019; Mahesan et al., 2021; Schonard et al., 2022). That is, both BCEs have different assumed sources in Task 2 processing and also different loci in Task 1.
Controlling for between-task interference
For compatibility-based BCE, many studies have investigated how cognitive control engagement varies from proactive control and increased task shielding to reactive control and relaxed task shielding in the presence of various regulators (for a review, see Fischer & Janczyk, 2022; Fischer & Plessow, 2015). That is, the size of the compatibility-based BCE has often been taken as a marker for effective shielding of prioritised Task 1 processing—the smaller the compatibility-based BCE, the stronger the assumed Task 1 shielding (Fischer & Plessow, 2015). It has been shown that, for example, specific instructions, negative mood, frequent conflict, or convergent thinking target the involvement of cognitive control and are capable of reducing, if not eliminating, crosstalk between tasks (e.g., Fischer et al., 2014; Fischer & Hommel, 2012; Lehle & Hübner, 2009; Plessow et al., 2017; Zwosta et al., 2013).
A powerful modulator of cognitive control involvement is the prospect of reward. It is a potent motivational trigger that has been argued to recruit proactive control. In general, the prospect of reward leads to faster responses and higher accuracy rates in cognitive control tasks (Botvinick & Braver, 2015; Fröber & Dreisbach, 2014; Janssens et al., 2016; Krebs et al., 2010; Locke & Braver, 2008; van den Berg et al., 2014; Yee & Braver, 2018). Furthermore, performance contingent reward has also been shown to increase proactive control (Fröber & Dreisbach, 2014, 2016) and conflict adaptation (Braem et al., 2012; Stürmer et al., 2011). Converging evidence shows that this enhancement in performance, especially under conflict, is facilitated by upregulating proactive control processes (Braem et al., 2014; Chiew & Braver, 2016; Dreisbach & Fischer, 2012; Goschke & Bolte, 2014). This could be realised by strengthening the goal-relevant information (Hefer & Dreisbach, 2017, 2020; Padmala & Pessoa, 2010), by appropriate inhibition of prepotent automatic responses (Boehler et al., 2012, 2014), or by ignoring the distracting stimuli efficiently (or all together). Interestingly, upregulation of cognitive control demands is also seen when the inherent valence-action compatibility, such as a match between reward and response execution, is violated (Asci et al., 2019). There seems to be an implicit compatibility between reward and response execution, leading to better performance in rewarded go trials (Guitart-Masip et al., 2011, 2012). On the other hand, when one has to suppress the response to rewarded no-go stimuli, the chances of commission errors increase (Asci et al., 2019). Overcoming such prepotent tendencies to correctly withhold the response indeed demands increased cognitive control, which is evident by the increased left dorsolateral prefrontal cortex activity—a region linked to cognitive control, in such situations (Asci et al., 2019).
Reward has recently been used in a dual-task scenario, where only Task 2 performance was rewarded (Langsdorf et al., 2022). Here, the perceived reward also impacted Task 1 processing, leading to smaller RT1s. These results show that reward may be applied to the entire dual-task representation, which includes both tasks. Such an integrated processing style under reward could have implications on between-task interference. Indeed, prospective reward was recruited to increase the level of proactive control with the purpose of reducing between-task interactions in the form of compatibility-based BCE. Fischer et al. (2018) showed that introducing a prospective reward for fast and accurate responses in both tasks not only decreased the BCE (Experiment 2) but also prevented the observed increase in between-task interference with increasing time on task in a non-rewarded control group (Experiment 3). More precisely, in their study, the prospect of reward was manipulated as a within-subject factor, where the reward was presented in alternating blocks (Experiment 2) and, as a between-subject factor (Experiment 3). In Experiment 2, the BCE was smaller in the reward blocks as compared to the no-reward blocks. In Experiment 3, the no-reward group showed a pattern of increasing BCE with time on task. For the reward group, however, the BCE did not increase but was stable across the experiment. This was interpreted as a constant high level of Task 1 shielding throughout the experiment. The authors concluded that prospective reward increases proactive task shielding, leading to reduced between-task interference, thus highlighting the importance of flexible regulation of proactive control to optimise multitasking. Such a result of increased task shielding might be expected if the level of proactive control is boosted by the prospect of reward in the compatibility-based BCE in a dual task. For the no-go BCE, however, predictions about how reward affects performance in both tasks appear less straightforward. Not only does the no-go BCE differ from the compatibility-based BCE with respect to the origin and locus of interference (Durst & Janczyk, 2019; Mahesan et al., 2021), but the no-go BCE also results from the interplay between response execution (Task 1) and the sudden response inhibition in no-go trials in Task 2. In fact, two opposing hypotheses are possible:
First, as reward is contingent on accurate and fast performance in both tasks, participants could integrate Task 1 and Task 2 into a single representation. In such a case, the reward would then be assigned to the whole representation of the combined dual task and not exclusively to individual tasks (Langsdorf et al., 2022). Consequently, the shift towards increased proactive control under reward would lead to faster performance in both Task 1 and Task 2. Since reward leads to a bias for action (Asci et al., 2019), resulting in increased preparedness and readiness to respond. While this may benefit response execution in go trials, it might become problematic in Task 2 no-go trials when a response needs to be withheld. With higher preparedness to respond, larger inhibitory control would be required, when a no-go trial requires not to respond. This would result in a larger no-go BCE seen in slowed Task 1 performance in conditions of reward compared to no reward. Furthermore, increased response preparedness may also impair Task 2 performance in no-go trials when participants fail to abort the prepared response in time.
Second, it is conceivable that the prospect of reward predominantly facilitates Task 1 performance because Task 1 is prioritised in task order and contains only go trials. The risk of commission errors in Task 2 (i.e., premature response execution in no-go trials) may lead to a more cautious processing strategy when discriminating between go and no-go trials. This, however, might reduce an automatic response tendency, requiring less inhibitory control to withhold a response. As a consequence, along with improvements in task performance, prospect of reward would also lead to a smaller no-go BCE in Task 1.
The present study
Therefore, in this study, we investigated the effects of reward on Task 1 performance when Task 2 was a go/no-go task. To investigate this question, we recruited a dual-task paradigm, where Task 1 was a two-alternative forced choice task and Task 2 was a simple go/no-go task. Participants were rewarded for fast and accurate responses to both Task 1 and Task 2. As by Fischer et al. (2018), prospective reward was manipulated as a within-subject factor (Experiment 1) or between-subject factor (Experiment 2). Accordingly, Experiment 1 and Experiment 2 were planned and conducted in parallel. Experiment 3 served as a replication of Experiment 2. Whereas in Experiment 1, reward and non-reward blocks alternated over the course of the experiment, in Experiment 2 (and Experiment 3) the prospect of reward (or no reward) remained constant in each group of participants. The effects of reward on no-go BCE were assessed in the two-way interaction Reward condition × Task 2 trial-type. Furthermore, the stable reward/no-reward manipulation in Experiments 2 and 3 afforded the opportunity to examine whether these modulations remained constant or changed over time, as assessed by the three-way interaction Reward condition × Task 2 trial-type × Block (Fischer et al., 2018).
Experiment 1
Experiment 1 tested whether a prospective reward could modulate the no-go BCE. In the current experiment, the prospect of reward was manipulated as a within-subject factor. Participants began the experiment with a baseline block, which was not rewarded. Subsequently, dual-task blocks with and without reward were alternated. Participants were instructed to respond fast and accurately to Task 1 and then to Task 2. In reward blocks, fast and accurate responses to both Task 1 and Task 2 were rewarded.
Methods
Participants
Thirty-two students of the University of Greifswald and non-students (25 female; Mage = 21.34 years, SD = 3.19 years) participated in the study. The sample size was adopted from a previous study that investigated the modulation of compatibility-based BCE with reward (Fischer et al., 2018). Students from the psychology department at the University received course credits for their participation. All participants had normal or corrected-to-normal vision, and two were left-handed. Participants provided written informed consent as per the Declaration of Helsinki and the ethical guidelines of the German Psychological Society before data collection.
Stimuli and apparatus
The stimuli for Task 1 (S1) were “X” and “O” and the stimuli for Task 2 (S2) were auditory stimuli—high (700 Hz) and low (450 Hz) tones. S1 was presented in Arial 18-point font in white on a black background on a 22-inch TFT monitor (1920 × 1080) with approximately 60 cm of viewing distance between the monitor and the participant. A fixation display with two horizontal dashes at the centre of the screen served as the fixation display. S1 appeared between the dashes. The response to Task 1 was provided by the left index or middle finger (A or S key of the QWERTZ keyboard). Participants responded to S2 using their right index finger (K key). E-prime 2.0 was used for stimulus presentation and data recording.
Procedure
The experimental procedure was adapted from Fischer et al. (2018) and modified for this study. In each trial, the fixation display appeared for 1500 ms, followed by the appearance of S1 between the two dashes. After a variable SOA of 40, 120, or 300 ms, auditory S2 was presented for 150 ms. After the onset of S2, S1 remained on the screen for 1000 ms and was subsequently replaced by a blank screen for 1500 ms. The trial terminated either when the execution of the response exceeded 2500 ms or when the response was executed. Feedback was provided by displaying the German words “Richtig” (correct), “Falsch” (wrong), or “Reihenfolge beachten” (mind the order). After feedback, a blank screen was displayed for a variable inter-trial interval of 100–1000 ms, randomly presented in increments of 100 ms, before the next trial began (Figure 1).
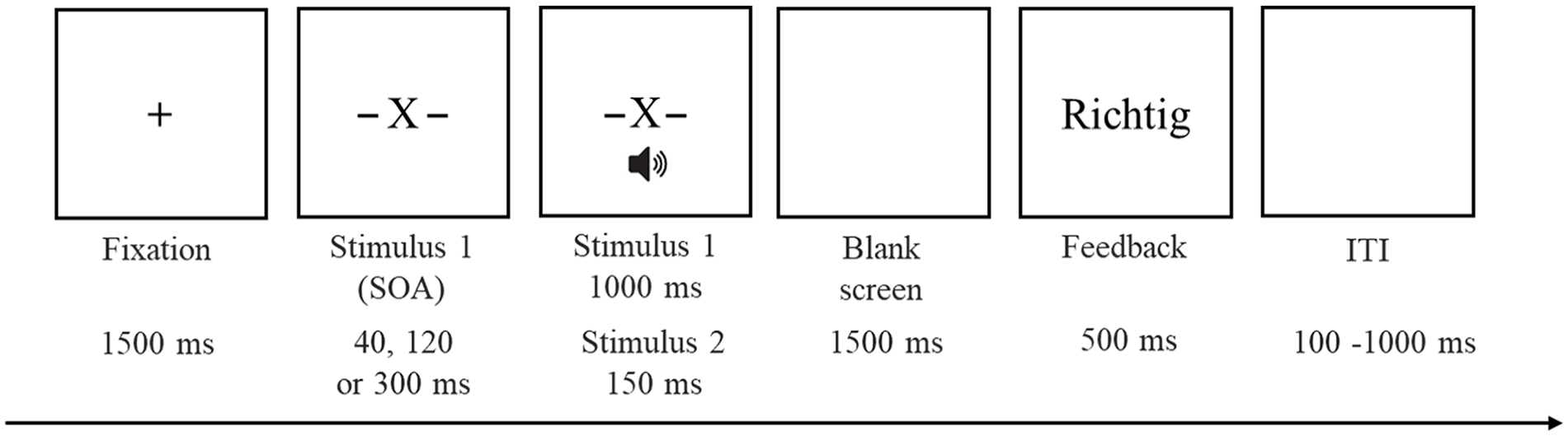
Trial structure of the go/no-go dual-task paradigm.
Participants were instructed to prioritise Task 1 and respond as quickly and accurately as possible, first to Task 1 and subsequently to Task 2. Half of the participants were instructed to respond to X using their left middle finger and to O using their left index finger. This assignment was reversed for the other half of the participants. Half of the participants withheld their response to the high tone (no-go trial) and responded to the low tone with their right index finger (go trial). The other half of the participants received the reversed assignment.
The experiment comprised a practice block (36 dual-task trials) and a baseline block that did not contain reward manipulation. The subsequent experimental block included alternating runs of reward and no-reward blocks. The ratio of the go and no-go trials was equal throughout the experiment in all blocks.
Baseline block
Participants performed two dual-task blocks with no reward, consisting of 72 trials each. In the first block, the median RT1 and RT2 were calculated for each SOA and Task 2 go trial combination and were later considered as a threshold in the reward condition. Separate thresholds as opposed to a global threshold ensured that not some conditions are favoured (e.g., long SOAs with longer RT1s) as compared to others (e.g., short SOAs with smaller RT1s) in the reward condition. If any cells remained empty due to a lack of correct responses from the participant, a message appeared at the end of the block informing the participant that they had committed too many errors and were to repeat the baseline block. Otherwise, the experiment proceeded to the second baseline block after a short break.
Reward manipulation block
The reward was manipulated within the participants, where the no-reward and reward conditions were switched after every 24 trials. In reward blocks, the symbol € appeared between the fixation dash at the start of every trial to indicate the possibility of receiving a reward. In no-reward blocks, the @ symbol appeared between the fixation dash at the start of every trial. A 2 (Task 2 trial-type: go vs. no-go) × 3 (SOA: 40 ms, 120 ms, 300 ms) combination occurred four times in random order within each of these blocks. A break was provided after 72 trials, and in total, the participants performed 144 trials of reward and 144 trials without reward.
In reward blocks, if the participants responded accurately to both tasks and their RTs were within the individual RT thresholds for both tasks, they could obtain 5 points per trial. Participants were informed of this reward structure. They could collect a maximum of 720 points. Participants were informed that they would participate in a competition with the points they earned: A €15 Amazon voucher (1st place), a €10 voucher (2nd place), and a €5 voucher (3rd place) would be given to the participant with the highest, second-highest, and third-highest scores, respectively. Furthermore, the feedback was adapted to reflect the reward earned by the participants. If the response was both correct and prompt, the feedback shown was “Richtig! + 5” (Correct! + 5). However, if the responses were correct but the RTs were above the individual RT threshold, the feedback displayed “Richtig! 0” (Correct! 0). For all other error feedback, “0” was added at the end, that is, “Reihenfolge beachten! 0” (Mind the task order! 0), “Falsch! 0” (Wrong! 0).
Design and analysis
Erroneous responses in Task 1 (5.3%) were removed prior to the analysis of Task 2 error rates (PE2). In addition to Task 1 errors, also trials with erroneous responses in Task 2 (3.8%) were excluded prior to RT analysis. Trials with RT1 or RT2 exceeding 2.5 standard deviations from the corresponding cell mean, calculated individually for each participant, were considered outliers (2.8%) and excluded from RT1 and RT2 analyses. The baseline block was not considered in the main analyses. Repeated measures analyses of variance (ANOVAs) with the factors Reward condition (no reward, reward) × Task 2 trial-type (go, no-go) × SOA (40 ms, 120 ms, 300 ms) were conducted on RT1, PE1, and PE2. A repeated measures ANOVA with the factors Reward condition (no reward, reward) and SOA (40 ms, 120 ms, 300 ms) was conducted on RT2 go trials. Greenhouse-Geisser corrections were applied when relevant.
Results
The results of Experiment 1 are visualised in Figure 2.
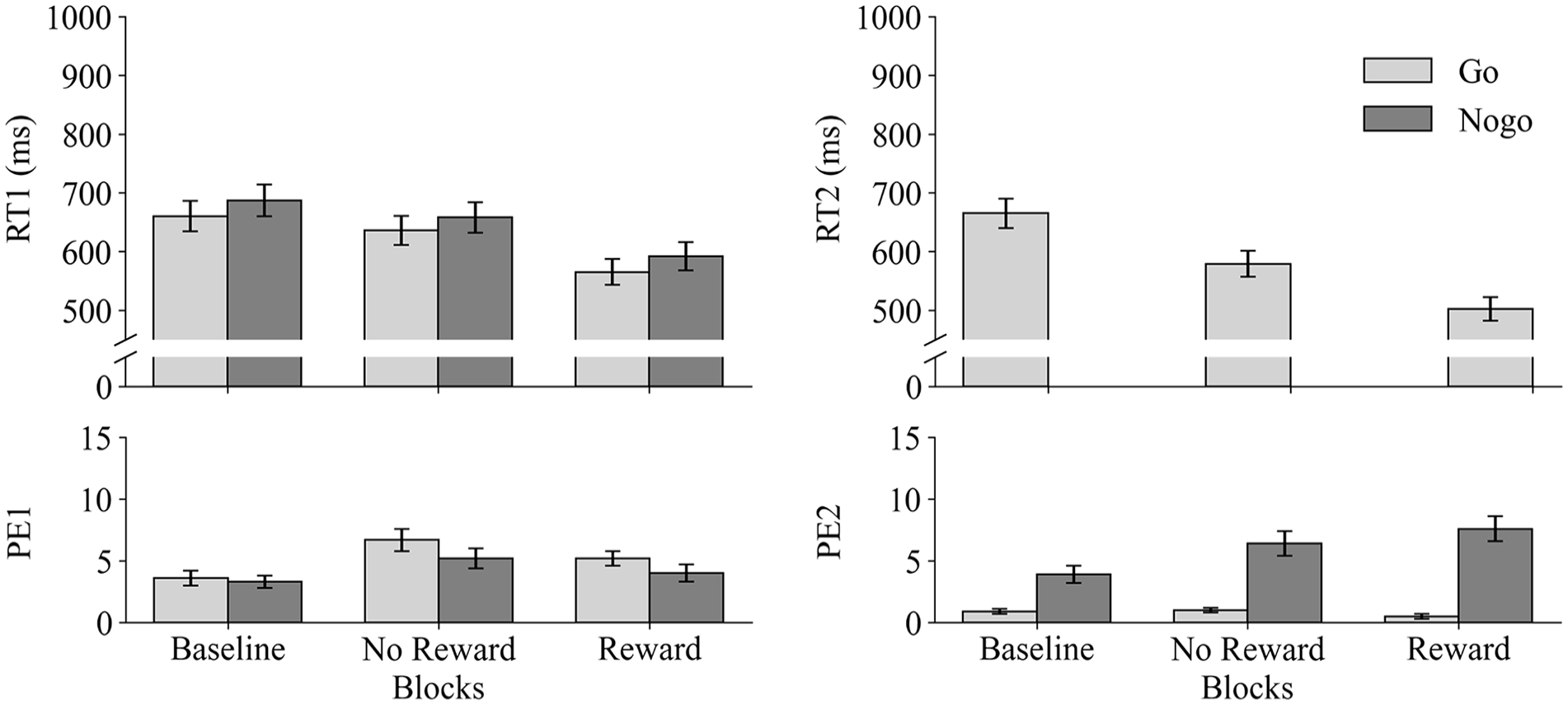
Response times (RT1 in ms) and percentage error rates (PE1) in Task 1 (left panel) and response times (RT2 in ms) and percentage error rates in Task 2 (PE2; right panel) as a function of Reward condition (baseline vs. no reward vs. reward) and Task 2 trial-type (go vs. no-go). Error bars represent standard errors of the mean.
Task 1
RT1
The ANOVA on RT1 revealed a significant main effect of Reward condition, F(1, 31) = 66.26, p < .001, ηp2 = .68. Participants were faster in the reward condition (578 ms) as compared to the no-reward condition (647 ms). Furthermore, participants were slower in responding to Task 1 when Task 2 was a no-go (625 ms) as compared to a go trial (600 ms), F(1, 31) = 28.20, p < .001, ηp2 = .48, thus revealing a no-go BCE. Furthermore, the main effect of SOA was also significant, F(1.45, 44.95) = 75.61, p < .001, ηp2 = .71, indicating an increase of RT1 with increasing SOA (i.e., 576 ms, 593 ms, and 669 ms for SOAs 40, 120, and 300 ms, respectively). This SOA dependency of RT1 was more pronounced for the reward condition (537 ms, 559 ms, and 639 ms, for SOAs 40, 120 and 300, respectively) than the no-reward condition (614 ms, 626 ms, and 700 ms, for SOAs 40, 120, and 300, respectively), F(1, 31) = 4.91, p = .034, ηp2 = .14 (linear contrast). The Reward condition did not modulate the no-go BCE as no two-way interaction, Reward condition × Task 2, was observed, F < 1. No other effects were significant, all Fs ≤ 2.68, all ps ≥ .076.
In addition, to verify that the Reward condition did not modulate the no-go BCE, a Bayesian repeated measures ANOVA with the factors Reward Condition (no reward, reward) and Task 2 trial-type (go, no-go) was conducted using JASP software (JASP Team, 2024) (see the Supplementary Material for a description of the analysis and complete results). Bayes Factors of the relevant interactions are reported here, which indicate how likely the data are under one model (e.g., model with interaction) over the other (e.g., model without interaction). The classification of the Bayes Factor (BF10) for interpretation follows the scheme proposed by Lee and Wagenmakers (2014).
The interaction of interest, Reward condition × Task 2 trial-type, yielded a BF10 = 0.337 which provides “anecdotal evidence” in favour of the null hypothesis. In other words, the data are 3 times (1/BF10 = BF01 = 2.9) more likely under the two main effects model than the interaction model.
PE1
The ANOVA on PE1 revealed a main effect of Reward condition, F(1, 31) = 6.23, p = .018, ηp2 = .17, where fewer errors were committed in the reward condition (4.6%) as compared to the no-reward condition (5.9%). Participants made more errors in Task 1 when Task 2 was a go (5.9%) as compared to a no-go (4.6%), F(1, 31) = 4.16, p = .050, ηp2 = .12. The main effect of SOA was significant, F(2, 62) = 12.39, p < .001, ηp2 = .29, indicating a decrease in PE1 with increasing SOA (i.e., 6.8%, 5.4%, 3.6% for SOAs 40, 120, and 300 ms, respectively). No other effects were significant, all Fs ≤ 2.77, all ps ≥ .071.
In addition, Bayesian analysis yielded BF10 = 0.273 for the interaction of interest Reward condition × Task 2 trial-type. That is, the data are about four times (1/BF10 = BF01 = 3.6) more likely to be under the two main effects model than the interaction model.
Task 2
RT2
The ANOVA on RT2 revealed a main effect of Reward condition, F(1, 31) = 65.89, p < .001, ηp2 = .68. Participants were faster in the reward condition (502 ms) as compared to the no-reward condition (579 ms). There was a main effect of SOA, F(1.65, 51.02) = 192.70, p < .001, ηp2 = .86. Participants were fastest at the longest SOA of 300 ms (472 ms), followed by SOA of 120 ms (546 ms), and slowest at the shortest SOA of 40 ms (603 ms). This PRP effect was modulated by Reward condition, F(1, 31) = 17.75, p < .001, ηp2 = .36 (linear contrast), and was much less pronounced for reward (550 ms, 511 ms, 445 ms for 40 ms, 120 ms and 300 ms, respectively) as compared to no-reward condition (656 ms, 581 ms, 500 ms for 40 ms, 120 ms and 300 ms, respectively).
PE2
The main effect of the Reward condition was not significant, F < 1. Participants made more errors in no-go (7.0%, commission errors) as compared to go (0.7%) trials, F(1, 31) = 43.65, p < .001, ηp2 = .59.
The factor Reward condition modulated the error rate depending on Task 2 trial-type, F(1, 31) = 5.12, p = .031, ηp2 = .14. In the reward group, participants committed 7.2% more errors in no-go as compared to go, t(31) = −7.45, p < .001. Whereas, only 5.5% more errors were committed in no-go as compared to go trials by the no-reward group, t(31) = −5.09, p < .001. The main effect of SOA was not significant, F(1.40, 43.54) = 2.80, p = .089, ηp2 = .08; however, SOA affected error rate differently for go and no-go trials, F(1.42, 43.99) = 3.86, p = .042, ηp2 = .11. Error rates in Task 2 no-go trials varied across SOA (6.4%, 5.8%, 8.8% at 40 ms, 120 ms and 300 ms), whereas the error rates in go trials remained stable (0.8%, 0.8%, 0.5% at 40 ms, 120 ms and 300 ms). SOA also affected error rates differently for the Reward conditions, F(2, 62) = 4.50, p = .015, ηp2 = .13. While there was no effect of SOA in the no-reward condition, F < 1, error rates were considerably elevated, especially at longest SOA for the reward condition, F(1.53, 47.28) = 5.27, p = .014, ηp2 = .15. This pattern of the reward condition, however, was restricted to no-go trial errors, as indicated by the three-way interaction between Reward condition × Task 2 trial-type × SOA, F(2, 62) = 4.73, p = .012, ηp2 = .13. While there were no differences in the error rates in go trials between Reward condition and SOA, F < 1, error rates in no-go trials were modulated by the reward conditions and SOA, F(1, 31) = 8.58, p = .006, ηp2 = .22 (linear contrast). Here, especially in the reward condition, participants committed the most errors at the longest SOA (10.7%), F(1, 31) = 8.26, p = .007, ηp2 = .21 (linear contrast).
Discussion
In Experiment 1, reward was manipulated in a within-subject design, where the experiment began with a baseline block followed by alternating no-reward and reward blocks. The current experiment provided three important results. First, the prospect of reward improved dual-task performance, with faster RTs in both tasks and fewer errors committed in Task 1 compared to the no-reward block. Second, despite this general performance improvement and in contrast to our prediction, prospect of reward did not modulate the no-go BCE. Third, prospect of reward, however, resulted in a somewhat smaller PRP effect in Task 2 go trials as compared to the PRP effect in no-reward blocks. This aligns with an observed steeper RT1 slope across SOA for the reward than the no-reward condition. 1 That is, particularly fast responses in Task 1 at short SOA may explain small PRP effects in Task 2. In addition, this response benefit of rewarded go trials came at the cost of increased error rates for Task 2 no-go trials. Thus, prospect of reward seemed to induce a bias for action, for example, in terms of increased response readiness that made it more difficult to stop responding in the case of a no-go trial. This was especially evident at the longest SOA. The longer the wait for the Task 2 stimulus to appear, the more difficult it is to stop responding.
Experiment 2
In Experiment 2, reward was manipulated as a between-subject factor as it allowed the examination of the effects of reward in isolation, without mixing with no-reward blocks. Experiment 2 was conducted to inspect the generalizability of the findings from Experiment 1. Similar to Fischer et al. (2018), both groups began the experiment with a baseline block that was not rewarded. After the baseline block, the no-reward group continued the experiment without a prospective reward, whereas the reward group received a prospective reward for their fast and accurate performance in both tasks. Here again, we investigated whether prospective reward modulates no-go BCE.
Methods
Participants
Forty-seven students from the University of Greifswald and non-students (26 female, 2 diverse; Mage = 21.43 years, SD = 3.91 years) participated in the study. The sample size was adopted from Experiment 3 of Fischer et al. (2018), which assessed the effects of reward on the compatibility-based BCE in a between-subject design. Students from the psychology department at the University received course credits for their participation. All participants had normal or corrected-to-normal vision, and six were left-handed. Participants provided written informed consent as per the Declaration of Helsinki and the ethical guidelines of the German Psychological Society before data collection. None of the participants took part in Experiment 1. Twenty-two participants took part in the no-reward group and 25 participants in the reward group.
Stimuli, apparatus, and procedure
Experiment 2 utilised the same apparatus and stimuli as in the previous experiment. In Experiment 2, reward was manipulated between the participants. The experiment began with a practice block of 36 trials for both groups.
Reward group
After the practice block, the participants performed a baseline block of 72 trials where the RT threshold for each category was calculated, similar to Experiment 1. After the baseline block, 6 blocks of 72 trials each followed, where a participant could earn 5 points in each trial by correctly and promptly (faster than the RT threshold) responding to both tasks. Feedback remained identical to the reward blocks of Experiment 1, with the only change being the absence of € symbol announcing a reward trial as all the trials were now rewarded. Participants could collect up to 2160 points. With the points, the participants entered a competition wherein the participants with the highest three scores were awarded a 15€, 10€, and 5€ Amazon gift cards, respectively.
No-reward group
Similar to the reward group, the no-reward group completed a baseline block of 72 trials after the practice block. The baseline block was followed by 6 blocks of 72 trials, in which the participants were not rewarded. Feedback remained the same as in the no-reward blocks of Experiment 1.
Design and analysis
Erroneous responses in Task 1 (4.9%) were removed prior to the analysis of Task 2 error rates (PE2). Trials with erroneous responses in Task 1 and Task 2 (3.9%) were excluded prior to all RT analyses. Trials with RT1 or RT2 exceeding 2.5 standard deviations from the corresponding cell mean, calculated individually for each participant, were considered outliers (3.0%) and excluded from RT1 and RT2 analyses. To increase statistical power, pairs of consecutive blocks were combined, thus reducing six experimental blocks to three blocks. Baseline blocks of both groups were removed prior to analyses. A mixed factors ANOVA with the factors Reward condition (No reward, Reward group) × Block (block 1, block 2, block 3) × Task 2 trial-type (go, no-go) × SOA (40 ms, 120 ms, 300 ms) was conducted on RT1, PE1, and PE2. A mixed factors ANOVA with the factors Reward condition (No-reward group, Reward group) × Block (block 1, block 2, block 3) × SOA (40 ms, 120 ms, 300 ms) was conducted on RT2 go trials. In all analyses, the Reward condition served as a between-subject factor.
Results
The results of Experiment 2 are visualised in Figure 3 (Task 1 results) and Figure 4 (Task 2 results).
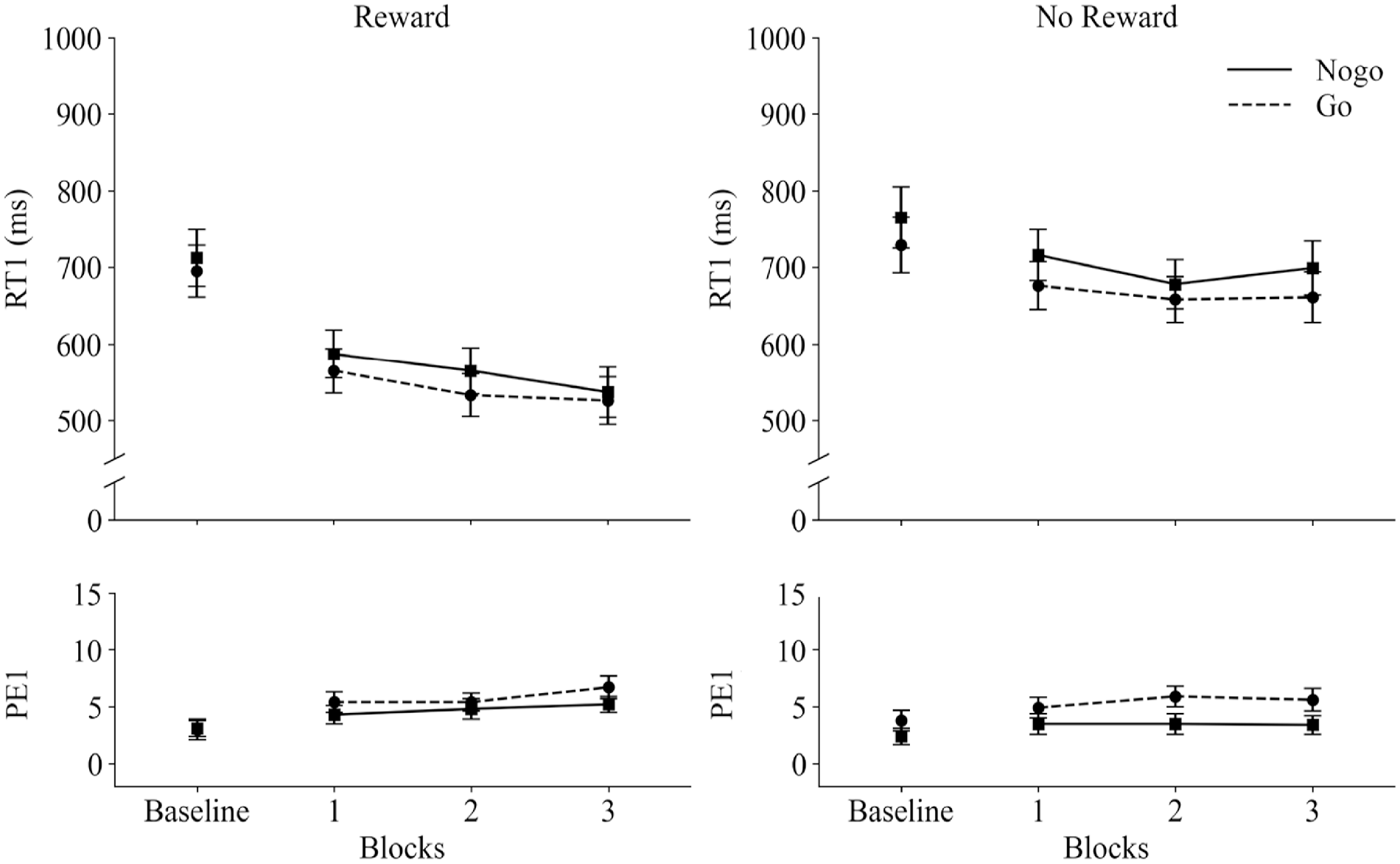
Response times (RT1 in ms) and percentage error rates (PE1) in Task 1 as a function of Blocks (Baseline vs. 1 vs. 2 vs. 3), Reward Group (Reward vs. No reward), and Task 2 trial-type (go vs. no-go). The baseline block of the Reward group was not rewarded. Error bars represent standard errors of the mean.
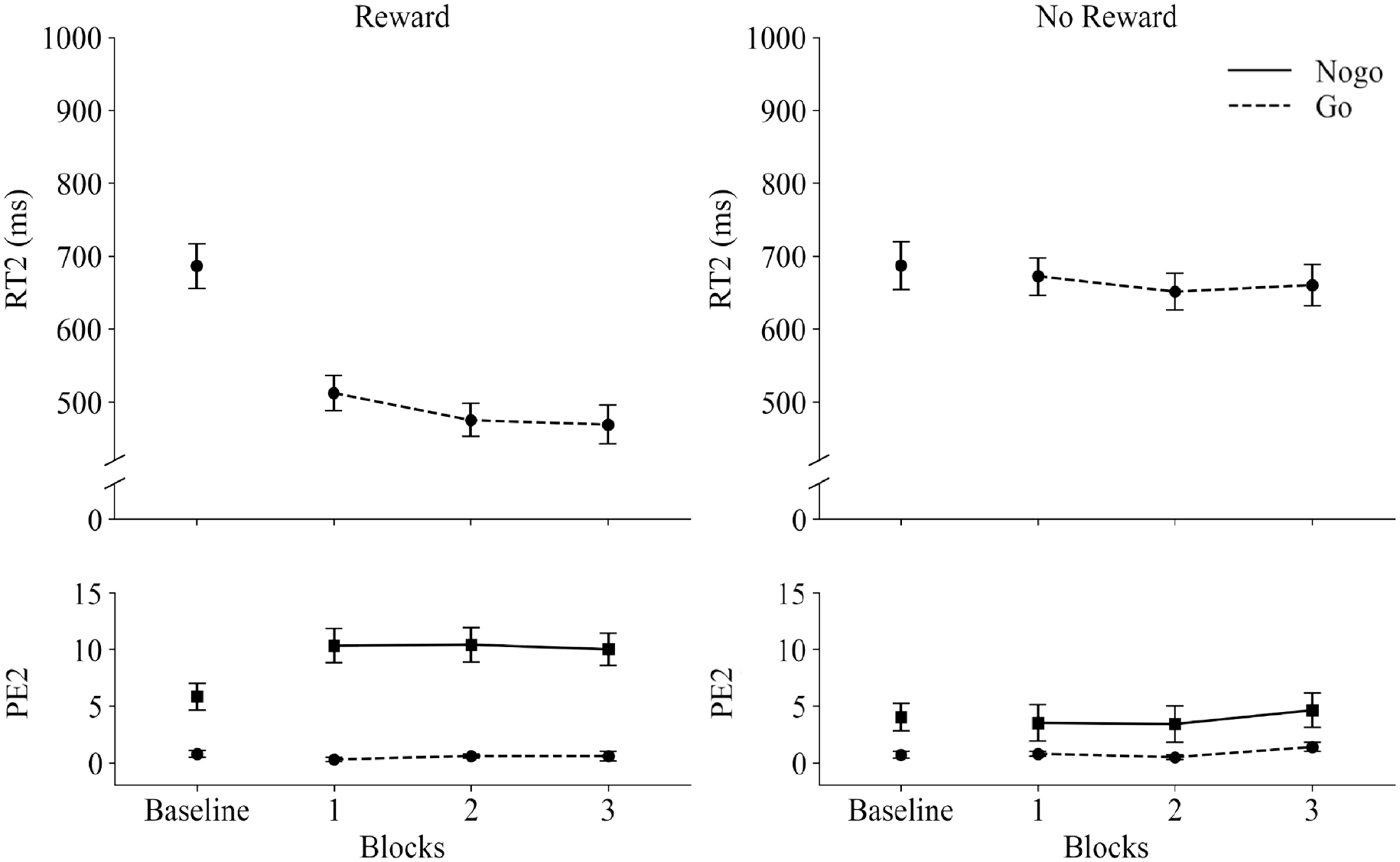
Response times (RT2 in ms) and percentage error rates (PE2) in Task 2 as a function of Blocks (Baseline vs. 1 vs. 2 vs. 3), Reward Group (Reward vs. No reward), and Task 2 trial-type (go vs. no-go). The baseline block of the Reward group was not rewarded. Error bars represent standard errors of the mean.
Task 1
RT1
The main effect of Block was significant, F(1, 45) = 8.60, p = .005, ηp2 = .16 (linear contrast), where a decreasing RT1 with increasing block number was observed (636 ms, 609 ms, 606 ms in blocks 1, 2 and 3, respectively). Participants were overall faster in the Reward (552 ms) as compared to the No-reward group (681 ms), F(1, 45) = 9.09, p = .004, ηp2 = .17. RT1 of both groups, however, did not differ in the baseline condition, t < 1 (see Figure 3).
Participants were generally faster in responding to Task 1 when Task 2 was a go (603 ms) as compared to a no-go trial (630 ms), F(1, 45) = 22.10, p < .001, ηp2 = .33. This no-go BCE was not modulated by Reward condition, F < 1. However, there was a three-way interaction between Block, Reward condition, and Task 2 trial-type, F(2, 90) = 7.13, p = .001, ηp2 = .14, suggesting that the no-go BCE varied for different blocks between both groups. This was especially evident in the final block 3, in which the no-go BCE was smaller for the Reward group (9 ms) as compared to the No-reward group (39 ms), F(1, 45) = 4.08, p = .049, ηp2 = .08. A numerical difference between Reward (17 ms) and No-reward group (36 ms), observed at the very first non-rewarded block (baseline), was not significant, F(1, 45) = 1.13, p = .293, ηp2 = .03 (see Figure 3). A Bayesian ANOVA was further conducted with the factors Reward condition (No reward, Reward group) × Block (block 1, block 2, block 3) × Task 2 trial-type (go, no-go). The two-way interaction Task 2 trial-type × Reward condition yielded a BF10 = 0.551 (1/BF10 = BF01 = 1.8), providing anecdotal evidence favouring the null hypothesis. On the other hand, BF10 for the three-way interaction was at 26.694, which suggests strong evidence for including the three-way interaction to explain the data.
Finally, RT1s was also affected by SOA (579 ms, 597 ms, 675 ms for 40 ms, 120 ms, and 300 ms, respectively), F(1.17, 52.53) = 114.71, p < .001, ηp2 = .72. No other effects were significant, all Fs ⩽ 2.11, all ps ⩾ .127.
PE1
Participants committed more errors in Task 1 when Task 2 was a go (5.7%) as compared to a no-go trial (4.1%), thus showing a slightly inverted no-go BCE, F(1, 45) = 22.98, p < .001, ηp2 = .34. PE1s decreased with increasing SOAs, F(1, 45) = 25.09, p < .001, ηp2 = .36 (linear contrast), which was further modulated by Reward condition, F(1, 45) = 11.12, p = .002, ηp2 = .20 (linear contrast). This decrease in PE1s with increasing SOA was stronger in the reward group (6.8%, 5.7%, 3.4% for SOA 40, 120, and 300 ms, respectively) as compared to the No-reward group, (4.8%, 4.5%, 4.1% for SOA 40, 120, and 300 ms, respectively). No other effects were significant, all Fs ⩽ 2.19, all ps ⩾ .146.
In addition, Bayesian analysis yielded BF10 = 0.506 for the interaction of interest Reward condition × Task 2 trial-type. That is, the data are two times (1/BF10 = BF01 = 1.9) more likely to be under the two main effects model than the interaction model. The three-way interaction, Block × Reward condition × Task 2 trial-type yielded BF10 of 0.215, thus data are five times more likely to be under the main effects model than the interaction model.
Task 2
RT2
RT2s decreased with time on task (592 ms, 563 ms, 564 ms for block 1, block 2, and block 3, respectively), F(1, 45) = 7.56, p = .009, ηp2 = .14 (linear contrast). Participants in the Reward group were overall much faster (485 ms) as compared to participants in the No-reward group (661 ms), as indicated by the main effect of Reward condition, F(1, 45) = 25.43, p < .001, ηp2 = .36. RT2 decreased with increasing SOA (641 ms, 577 ms, 501 ms for 40 ms, 120 ms, and 300 ms, respectively), thus reflecting a PRP effect F(1, 45) = 303.05, p < .001, ηp2 = .87 (linear contrast). Finally, there was a three-way interaction between Block, SOA, and Reward condition, F(1, 45) = 9.28, p = .004, ηp2 = .17 (linear contrast), suggesting that, especially in block 3, a smaller PRP effect was found for the Reward group as compared to the No-reward group, F(2, 90) = 8.56, p < .001, ηp2 = .16.
PE2
Participants made more errors in the Reward group (5.4%) as compared to the No-reward group (2.4%), F(1, 45) = 8.36, p = .006, ηp2 = .16. Overall, participants made more commission errors in no-go trials (7.0%) as compared to errors in go trials (0.7%), F(1, 45) = 39.97, p < .001, ηp2 = .47. The commission error rate for no-go trials was higher for the Reward group than the No-reward group, t(27.60) = –3.39, p = .002, while both groups did not differ with respect to the errors in go trials, t(34.87) = 1.31, p = .198, resulting in a significant two-way interaction between Reward condition and Task 2 trial-type, F(1, 45) = 11.73, p = .001, ηp2 = .21.
The main effect of SOA was significant, F(1, 45) = 8.76, p = .005, ηp2 = .16 (linear contrast). There was a general increase in error rates with increasing SOA (3.5%, 3.3%, and 4.8% for SOA 40 ms, SOA 120 ms, and SOA 300 ms, respectively). This increase in PE2 was further modulated by Reward condition, F(1, 45) = 18.72, p < .001, ηp2 = .29 (linear contrast), being larger in the reward (3.2%) than the no-reward group (–0.6%).
Furthermore, the interaction between Task 2 trial-type and SOA was also significant, F(1.53, 68.86) = 9.61, p < .001, ηp2 = .18, showing a larger variation in commission errors in the no-go trials across the SOAs (6.3%, 5.8%, 8.9% for SOAs 40 ms, 120 ms, and 300 ms, respectively) as compared to errors in go trials (0.7%, 0.7%, 0.8% for SOAs 40 ms, 120 ms, and 300 ms, respectively). Thus, the later the S2 no-go stimulus appeared, the higher the tendency to respond to it. This pattern, however, was specifically related to the Reward group, F(1.51, 36.17) = 20.29, p < .001, ηp2 = .46, but was not found in the No-reward group, F(2, 42) = 1.86, p = .168, ηp2 = .08, resulting in the three-way interaction between, Task 2 trial-type, SOA, and Reward condition, F(2, 90) = 19.12, p < .001, ηp2 = .30.
Discussion
In Experiment 2, the prospective reward was manipulated as a between-subject factor. After a non-rewarded baseline block, participants in the reward group performed the remaining blocks, receiving a reward for accurate and fast responses to the dual task. The no-reward group continued the same dual task without the prospect of reward.
First, similar to Experiment 1, participants in the reward group responded faster to Task 1 and Task 2. Second, a no-go BCE was found, that was not statistically different between both groups. However, only in the final block does the no-go BCE appear somewhat smaller in the reward than in the no-reward group. These results again show that we did not find the predicted pattern of an increased no-go BCE under the prospect of reward. If anything, the no-go BCE seemed to be even smaller when participants aimed for the receipt of a reward. However, visual inspection suggests that the reward group started out with at least a numerically smaller no-go BCE than the no-reward group already in the baseline block when no reward was provided. In addition, Bayesian analysis suggested that there is very little to no evidence that an included two-way interaction could explain the data. Thus, at this point, it remains to be determined to what extent the prospect of reward truly reduces the no-go BCE.
Similar to Experiment 1, at least in the final block, the PRP effect was smaller in the reward as compared to the no-reward group (we will discuss this pattern in more detail in the General Discussion section). At the same time, the reward group displayed overall more errors in Task 2 no-go trials as compared to go trials. Although both groups showed comparable error rates in Task 2 go trials, the reward group committed more Task 2 no-go errors, especially at long SOA, as compared to the no-reward group. This is further evidence for the assumption that the prospect of reward increases response readiness (bias for action), so that the later the stimulus onset of Task 2, the more difficult it is to inhibit the response. This pattern also accounts for the overall higher Task 2 error rates in the reward as compared to the no-reward group and speaks against a more cautious Task 2 processing in the reward group.
Experiment 3
Results from Experiments 1 and 2 demonstrate two critical points: Reward speeds up both Task 1 and Task 2 performance but comes at the cost of higher Task 2 no-go errors. At the same time, the question of whether the no-go BCE is modulated by reward could not be completely concluded from the previous two experiments. While the within-subject manipulation in Experiment 1 showed no evidence of reward modulation of the no-go BCE, the between-subject manipulation in Experiment 2 suggested, if anything, an even smaller no-go BCE, at least in the last block of the experiment.
Therefore, the goal of the current experiment was to replicate Experiment 2, and several changes were implemented. Because the high no-go errors at long SOA in the reward group might reflect premature responses, especially with increasing temporal delay, we first omitted the long SOAs and included a single short SOA of 100 ms only. Furthermore, the no-go BCE in Experiment 2 was of moderate size (27 ms), and as a result, the reduced no-go BCE was quite small towards the end of the experiment in the reward group. Therefore, we increased the proportion of go trials as compared to no-go trials (e.g., Mahesan et al., 2021). A higher preparedness to respond to Task 2 requires a larger inhibition not to respond to rare no-go trials in Task 2, resulting in a large no-go BCE. Experiment 3 was conducted online using two sets of digits as visual stimuli in both tasks. Participants performed a magnitude categorization in Task 1 (smaller and larger than 5). In Task 2, participants were instructed to respond to all digits (go) other than 5 (no-go). Similar to previous experiments, we expected the reward to speed up Task 1 and Task 2 performance. The question of interest was again, whether the prospect of reward modulates the size of the no-go BCE.
Methods
Participants
Fifty-one students from the University of Greifswald and non-students (26 female, 2 diverse; Mage = 21.43 years, SD = 3.91 years) participated in the study. Students from the psychology department at the University received course credits for their participation. All participants had normal or corrected-to-normal vision and were right-handed. Participants provided informed consent according to the Declaration of Helsinki and the ethical guidelines of the German Psychological Society before data collection. Twenty-five participants took part in the no-reward group and 26 participants were in the reward group. One participant in the reward group was removed prior to analysis because of high error rate (>60%).
Apparatus and stimuli
The experiment was conducted online. The demographic questionnaire was created using SoSci Survey (Leiner, 2019). The experiment was created using Psychopy Builder (2021.1.4) and hosted on Pavlovia (https://pavlovia.org/). The experiment was adopted from Mahesan et al. (2021). S1 were the digits 2, 3, 7, and 8 and S2 were the digits 1, 4, 6, 9, and 5, which were visually presented on the screen. A fixation display of four horizontal dashes, two dashes above the centre (10 pixels above) and two dashes below the centre (10 pixels below) served as the fixation display. S1 appeared between the upper dashes, and the response for Task 1 was provided by the left index or middle finger (A or S key of the QWERTZ keyboard). S2 appeared between the lower two dashes, and the response to Task 2 was provided using the right index or middle finger (K or L key of the QWERTZ keyboard)
Procedure
A trial began with the fixation displayed for 1500 ms. Following this, S1 was presented in between the two dashes above the centre of the screen. Along with the onset of S1, the dashes below the centre of the screen disappeared. After an SOA of 100 ms, the dashes below the screen centre reappeared together with S2, which remained on the screen for 1000 ms. This was followed by a blank screen for 1500 ms.
Participants were instructed to categorise S1 according to the magnitude and respond with the left middle finger if the digit is smaller than 5 and with the left index finger if the digit is larger than 5. Response mapping was held constant for Task 1. For Task 2, the participants were instructed to respond to all digits except 5. Half of the participants responded to S2 using the right index finger, whereas the other half responded using the right middle finger.
To increase the preparedness for Task 2, we introduced more go trials than no-go trials. Therefore, 66% of the trials were go and 34% of the trials were no-go, which means that the digit 5 was presented twice as often as each of the other digits serving as S2. The experiment began with a practice block (32 dual-task trials). The rest of the procedure remained the same as in Experiment 2.
Design and analysis
Erroneous responses in Task 1 (5.3%) were removed prior to the analysis of error rates in Task 2 (PE2). Trials with erroneous responses in Task 1 and Task 2 (5.6%) were excluded prior to all RT analyses. Trials with RT1 or RT2 exceeding 2.5 standard deviations from the corresponding cell mean, calculated individually for each participant, were considered outliers (3.2%) and excluded from RT1 and RT2 analyses. Baseline blocks of both groups were removed prior to analyses. A mixed-factors design with Reward condition (No reward, Reward group) × Block (block 1, block 2, block 3) × Task 2 trial-type (go, no-go) × SOA (40 ms, 120 ms, 300 ms) was conducted for RT1, PE1, and PE2. A mixed-factors design with the factors Reward condition (No reward, Reward group) × Block (block 1, block 2, block 3) × SOA (40 ms, 120 ms, 300 ms) was conducted on RT2 go trials. The factor Reward condition served as the between-subject factor.
Results
The results of Experiment 3 are visualised in Figure 5 (Task 1 results) and Figure 6 (Task 2 results).
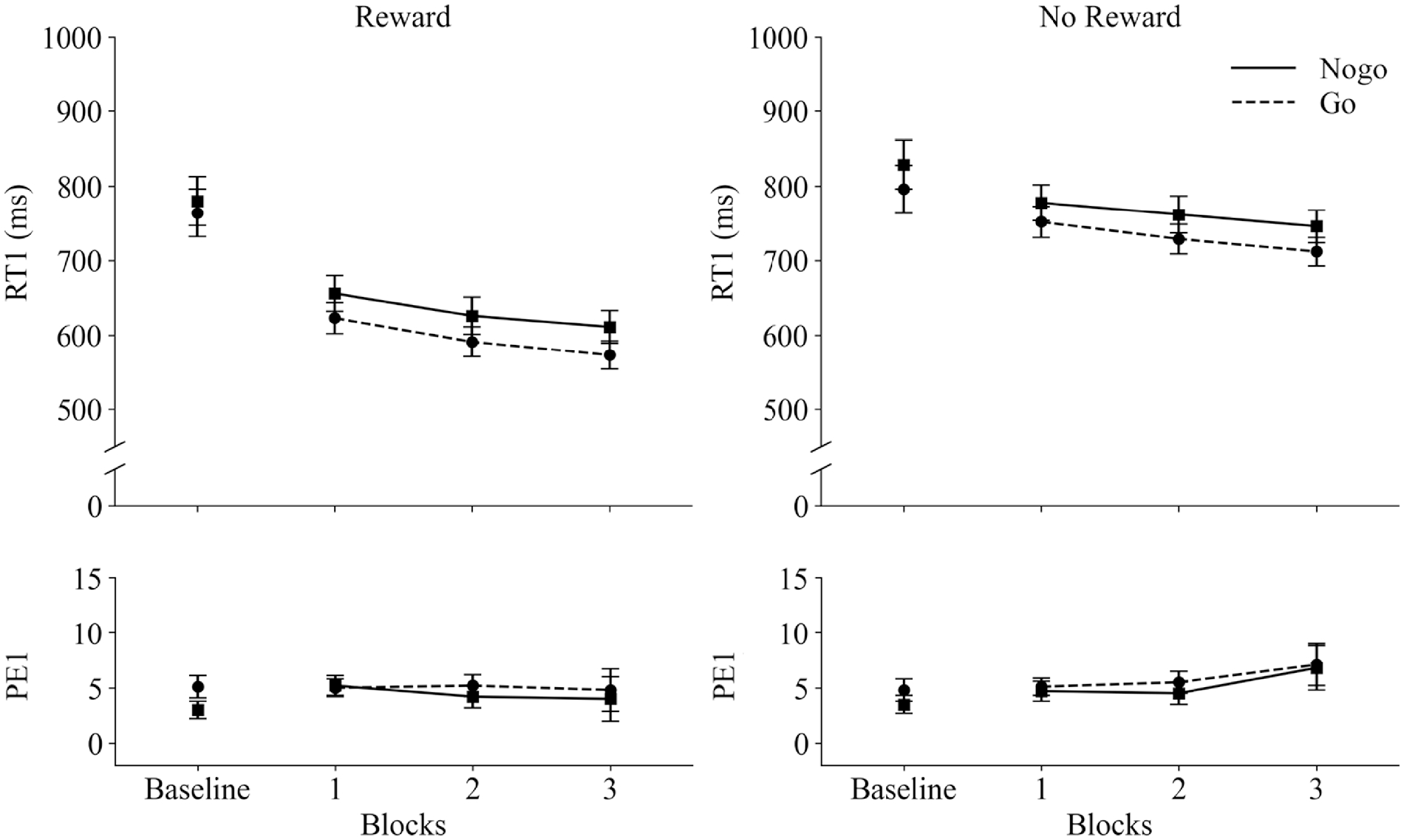
Response times (RT1 in ms) and percentage error rates (PE1) in Task 1 as a function of Blocks (Baseline vs. 1 vs. 2 vs. 3), Reward Group (Reward vs. No reward), and Task 2 trial-type (go vs. no-go). The baseline block of the Reward group was not rewarded. Error bars represent standard errors of the mean.
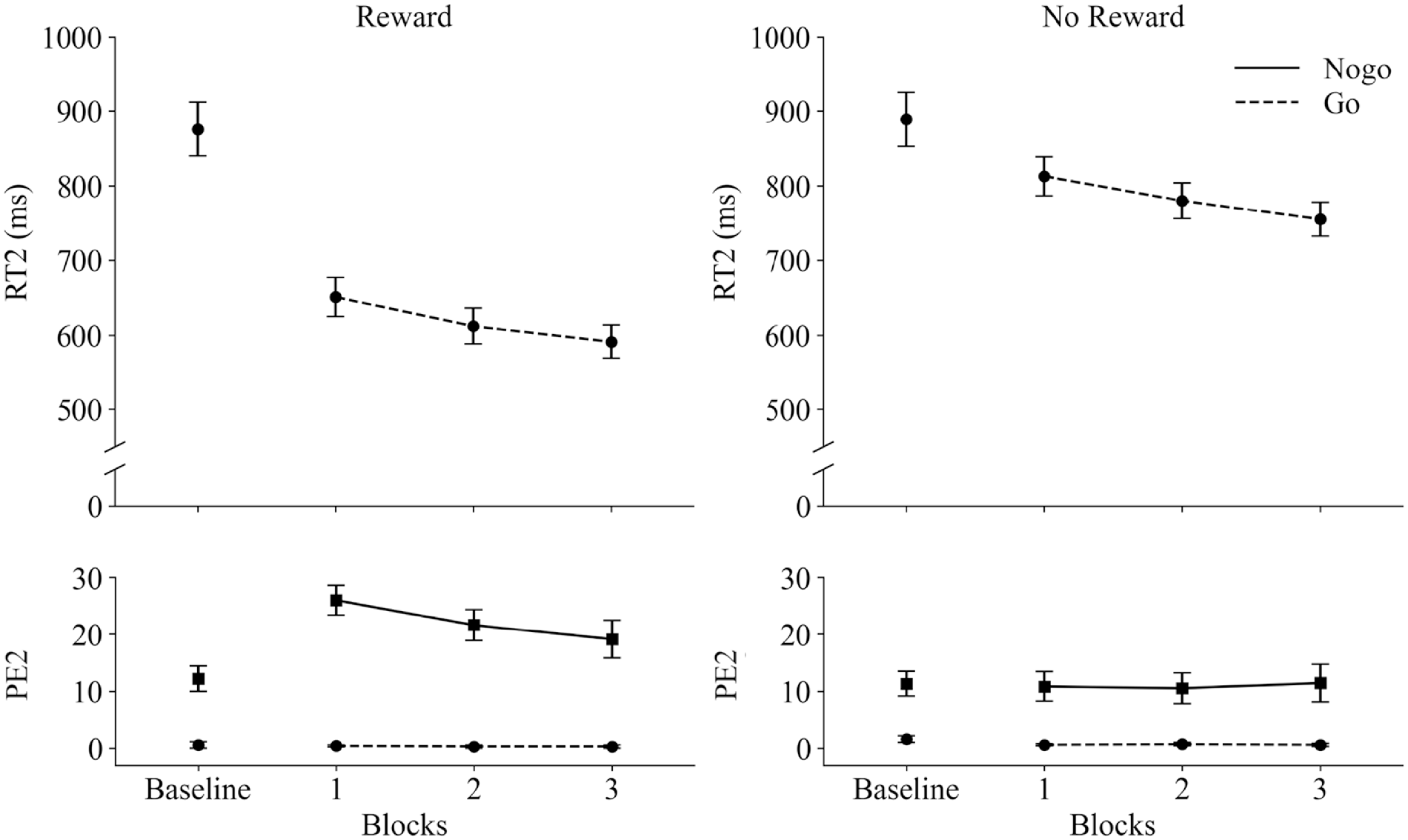
Response times (RT2 in ms) and percentage error rates (PE2) in Task 2 as a function of Blocks (Baseline vs. 1 vs. 2 vs. 3), Reward Group (Reward vs. No reward), and Task 2 trial-type (go vs. no-go). The baseline block of the Reward group was not rewarded. Error bars represent standard errors of the mean.
Task 1
RT1
Participants were faster in the Reward group (613 ms) as compared to the No-reward group (747 ms), F(1, 48) = 20.16, p < .001, ηp2 = .30. A no-go BCE was observed, F(1, 48) = 48.44, p < .001, ηp2 = .50, where participants responded faster to Task 1 when Task 2 was a go (663 ms) as compared to no-go (696 ms) trial. The main effect of Block was significant, F(1, 48) = 47.23, p < .001, ηp2 = .50 (linear contrast), where the RT1s decreased with increasing time on task (702 ms in block 1, 677 ms in block 2 and 661 ms in block 3). Most importantly, both groups did not display different-sized no-go BCEs, nor differences in the size of the no-go BCE over time, in addition, the no-go BCE did not change across blocks, all Fs ⩽ 0.82, all ps ⩾ .444. To further support these effects, a Bayesian ANOVA was conducted with the factors Reward condition (No reward, Reward group) × Block (block 1, block 2, block 3) × Task 2 trial-type (go, no-go). Of interest, the BF10 for the two-way interaction Reward condition × Task 2 trial type was 0.286, providing anecdotal evidence for the null hypothesis. The BF10 for the three-way interaction was 0.103, revealing that the evidence to not include the model containing the three-way interaction is around a factor of 10 (1/BF10 = BF01 = 9.7).
PE1
No effects were significant, all Fs ⩽ 3.40, all ps ⩾ .071.
A Bayesian ANOVA was further conducted with the factors Reward condition (No reward, Reward group) × Block (1, 2, 3) × Task 2 trial-type (go, no-go). The two-way interaction Task 2 trial-type × Reward condition yielded a BF10 = 0.186, providing moderate evidence favouring the null hypothesis. Similarly, BF10 for the three-way interaction was at 0.237, which suggests moderate evidence to not include the model with the three-way interaction to explain the data.
Task 2
RT2
The Reward group responded overall faster (618 ms) than the No-reward group (783 ms), F(1, 48) = 23.68, p < .001, ηp2 = .33. The main effect of Block was significant, F(1, 48) = 61.97, p < .001, ηp2 = .56 (linear contrast), with decreasing RT2 across increasing block numbers (732 ms in block 1, 696 ms in block 2 and 673 ms in block 3).
PE2
Participants of both groups produced considerably more commission errors in no-go trials (16.6%) as compared to errors in go trials (0.5%), F(1, 48) = 83.34, p < .001, ηp2 = .64. This effect was modulated by the factor Reward condition, F(1, 48) = 10.89, p = .002, ηp2 = .19. The Reward group committed more errors in no-go trials (22.2%) as compared to the No-reward group (10.5%), t(37.86) = –3.36, p = .002. However, the error rates in go trials did not vary between the No reward (0.6%) and the Reward (0.3%) group, t(33.83) = 1.08, p = .288. Together, this resulted in overall higher error rates for the Reward group (11.3%) compared to the No-reward group (5.8%), F(1, 48) = 8.40, p = .006, ηp2 = .15. No other effects were significant, all Fs ⩽ 3.06, all ps ⩾ .052.
Discussion
Experiment 3 aimed to further test for a reward modulation of the no-go BCE when only a single short SOA and a high number of Task 2 go trials were included. In line with the previous two experiments, Experiment 3 yielded three important findings: First, participants were again faster in responding to both Task 1 and Task 2 in the reward group as compared to the no-reward group. Second, a reliable no-go BCE was observed in RT1s, which, however, was rather similar in size to those observed in Experiments 1 and 2. While previous research had suggested that a high percentage of go trials usually yields larger no-go BCEs (e.g., on average 59 ms by Mahesan et al., 2021), the present no-go BCE did not exceed 33 ms. One crucial difference might be that the experiments by Mahesan et al. (2021) were conducted in the lab, whereas the present experiment was conducted online. Most importantly, however, the obtained no-go BCE was not at all modulated by reward.
In line with the previous experiments, participants committed more errors in Task 2 no-go trials as compared to Task 2 go trials, which was especially pronounced for the reward group. Yet, both groups did not differ in their error rates for go trials. Thus, this experiment revealed that high no-go trial errors are not related exclusively to long SOAs, but could be due to the rather higher preparedness in Task 2 responses in reward condition. Consequently, overall, the reward group committed more commission errors in Task 2 as compared to no-reward group.
General Discussion
This study aimed to investigate the effects of the prospect of reward on dual-task performance and its influence on between-task interference, that is, the extent to which secondary task processing influences the processing of the prioritised Task 1. Previous research has distinguished two types of between-task interference. One type of between-task interference requires dimensional overlap between both tasks (i.e., compatibility-based BCE), whereas the other occurs when both tasks are rather independent of each other (i.e., no-go BCE). Recently, the prospect of reward has been shown to reduce the size of compatibility-based BCE, presumably by increasing the levels of proactive control (Fischer et al., 2018). In this study, we tested the impact of reward on no-go BCE, that is, interference on Task 1 processing due to not responding in Task 2. Reward was either manipulated as a within-subject variable (Experiment 1) or as a between-subject variable (Experiments 2 and 3).
In the first hypothesis, we predicted that the prospect of reward would induce a bias towards action. This would speed up responses in both tasks when go-responses are required but would lead to increased demands on inhibition in Task 2 no-go trials. Stronger inhibition would lead to increased no-go BCE in Task 1. Alternatively, a strong bias towards action could also lead to increased levels of failed inhibition and thus, higher commission errors in Task 2 (i.e., erroneous responses to no-go trials). In the second hypothesis, we predicted that higher levels of proactive control in the reward condition may not bias for action but induce more cautious Task 2 processing, even reducing the no-go BCE in Task 1.
The current experiments revealed three key insights. First and in line with hypothesis 1, reward largely affected dual-task performance. The prospect of reward led to faster Task 1 and Task 2 responses than conditions without the prospect of reward, aligning also with the previous line of research showing better task performance with performance-contingent reward (Botvinick & Braver, 2015; Fröber & Dreisbach, 2014; Fröber & Lerche, 2023; Janssens et al., 2016; Jurczyk et al., 2021; Krebs et al., 2010; Locke & Braver, 2008; van den Berg et al., 2014; Yee & Braver, 2018). Second, this reward-induced bias for action, however, came at the cost of increased premature responding in Task 2 no-go trials, when no response was required. That is, more commission errors in Task 2 no-go trials were observed in the reward compared to the no-reward conditions, while the errors in go trials did not differ. This trade-off between quick responses and correct stopping of a prepared response in Task 2 (no-go trial) becomes especially apparent the longer participants have to wait for the appearance of the Task 2 stimulus. In Experiment 1 and Experiment 2, the highest rates of no-go commission errors were obtained the longer the waiting period, that is, especially at longer SOAs. Together, these findings suggest that the prospect of reward facilitates responding in both tasks, which is in line with an assumed bias for action (hypothesis 1) but not with an assumption of more cautious processing (Hypothesis 2). Finally, a third and quite surprising result, which was not predicted by either hypothesis, was that prospective reward did not modulate the no-go BCE. In Experiment 1, the no-go BCE did not vary at all between the reward and no-reward conditions. In Experiment 2, it seemed that a smaller no-go BCE was observed in the final block of the reward group. However, this result should be interpreted with caution, because the reward group started with a numerically smaller BCE compared to the no-reward group already in the non-rewarded baseline block. In a subsequent replication attempt, in Experiment 3, we obtained again faster responses in both tasks for the reward compared to the no-reward group. In line with Experiment 1, however, reward did not modulate the no-go BCE in the between-subject design of Experiment 3. Additional Bayes analyses further suggested that all three experiments seem to converge on the assumption that overall the no-go BCE remains quite constant across both the reward and no-reward groups/conditions, irrespective of the faster responses in the reward group/condition.
The consistently observed reward-induced bias for action in the present dual-task experiments suggest that the prospect of reward triggered a generally higher readiness to respond, resulting in faster responses in both tasks and higher rates of commission errors in Task 2 no-go trials. Indeed, this increase in no-go errors with reward aligns well with the idea of reward-action compatibility, according to which, abstract compatibility is formed between reward and response execution (Asci et al., 2019; Guitart-Masip et al., 2011, 2012). However, when reward is associated with inaction, as is the case in Task 2 no-go trials of the current experiments, this leads to an abstract incompatibility. This conflict may lead to increased Task 2 no-go errors if cognitive control is not upregulated to overcome the prepotent tendencies to respond. Contrary to our prediction, however, this prepotent tendency to respond did not translate into larger response inhibition when a no-go response was required. As aforementioned, the prospect of reward did not modulate the no-go BCE, assuming that the spilled-over inhibition from not responding in Task 2 onto Task 1 was similar in reward and no-reward conditions. Thus, the present findings are not in line with previous observations that increased response preparedness requires more inhibition in a Task 2 no-go trial (e.g., Janczyk & Huestegge, 2017; Mahesan et al., 2021).
At present, we can only speculate about this finding. If we assume that increased response preparedness comes with stronger inhibition in Task 2 no-go trials, as suggested by Janczyk and Huestegge (2017), it is unclear why more inhibition in Task 2 does not spill over onto Task 1 processing and does not slow Task 1 response execution. At least two possibilities are conceivable.
First, prospect of reward may not specifically act on response inhibition per se. Recent studies have shown that the effect of reward on inhibitory processes is not as straightforward. For example, in the context of the stop-signal paradigm, reward seems to improve only the attentional capture component, and the effects on response inhibition are only indirect via enhanced attentional processing (Wang et al., 2019). Similarly, it is possible that reward does not directly impact response inhibition in the current study. In fact, a comparable no-go BCE in both, reward and no-reward conditions in the case of successful not-responding to Task 2 no-go trials, suggests that response inhibition works just fine in most of the cases. However, it seems that the reward-induced bias towards action may reflect faster response initiation (or faster crossing of the response threshold) that, although beneficial in go trials, might simply escape slower response inhibition in no-go trials. In these cases, commission errors in Task 2 no-go trials reflect fast premature response execution, before higher demands for inhibition were even signalled. Importantly, in this view, the inhibitory process itself would be intact, yet too slow to act in all cases on time.
Second, reward can act directly on inhibitory processes, but inhibitory processes may already be maximised in the no-reward condition, preventing any further increase in the reward condition. 2 Both explanations, however, remain speculative at present and require further experimentation.
Finally, prospect of reward not only affected general response speed and increased Task 2 no-go errors but also yielded a shallower RT2 slope across SOA, indicating a slightly smaller PRP effect. This was found in the within-subjects design of Experiment 1 and at least for the final block of the between-subjects design of Experiment 2. A smaller PRP effect could indicate that under conditions of reward, some Task 2 processing might have bypassed the bottleneck. However, observations of bottleneck bypassing in a PRP paradigm have been rare and occur in rather specific conditions, such as eye-movement responses (e.g., Pashler et al., 1993) or conditions with Task 2 auditory-vocal stimulus response pairings, often including immense task practice (e.g., Maquestiaux et al., 2008; Ruthruff et al., 2006). Especially using dual tasks with manual responses in Task 1 and Task 2 produces strong output interference (De Jong, 1993), which may have prevented bottleneck bypassing even with large amounts of practice (Karlin & Kestenbaum, 1968). Alternatively, what appears to be a partial bottleneck bypass could be the result of the general RT benefit in Task 1 for reward relative to no-reward conditions. It has been argued that a central bottleneck may well explain small PRP effects when RT1 is sufficiently short (Lien et al., 2003, 2005), which may thus provide a more parsimonious explanation. 3 This is in line with previous findings, showing that the prospect of reward was not able to facilitate circumventing the processing limitation due to the bottleneck. This was evident when participants failed to process two tasks in parallel, despite parallel processing being financially rewarded (Han & Marois, 2013). Thus, it seems that the processing limitation of the RSB in dual tasks cannot be avoided by mere motivational incentives of the prospect of reward. Instead, the observation of a smaller PRP effect in the present conditions of reward seems most likely to be due to the reward-induced shortening of RT1.
To sum up, the current results show that the prospect of reward for fast and accurate performance in both tasks in a dual-task, where Task 2 is a go/no-go, leads to overall better performance in Task 1 and Task 2 go trials. Furthermore, reward does not influence the no-go BCE; however, the anticipation of reward leads to increased response readiness and premature responding in Task 2. This can be specifically observed in the higher error rates in no-go trials in the reward as compared to the no-reward condition. These results further our understanding of no-go BCE and highlight the need to study the complex interactions between control and motivation that drive adaptive behaviour.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218251322167 – Supplemental material for Prospective reward in dual task induces a bias towards action at the cost of less accurate Task 2 performance
Supplemental material, sj-docx-1-qjp-10.1177_17470218251322167 for Prospective reward in dual task induces a bias towards action at the cost of less accurate Task 2 performance by Devu Mahesan and Rico Fischer in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
The supplementary material is available at qjep.sagepub.com.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.