
Abstract
Visual-spatial contextual cueing learning underpins the daily lives of older adults, enabling them to navigate their surroundings, perform daily activities, and maintain cognitive function. While the contextual cueing effect has received increasing attention from researchers, the relationship between this cognitive ability and healthy ageing remains controversial. To investigate whether visual-spatial contextual cueing learning declines with age, we examined the contextual learning patterns of older (60–71 years old) and younger adults (18–26 years old) using a contextual-guided visual search paradigm and response variability measurements. We observed significant contextual learning effects in both age groups, impacting response speed and variability, with these effects persisting for at least 24 days. However, older adults required more repetitions and memorised fewer repeated stimuli during initial learning. Interestingly, their long-term memory maintenance appeared stronger, as their contextual facilitation persisted in both response speed and variability, while younger adults only persisted in response speed but not variability. Overall, our results suggest an age-related complex and diverse contextual cueing pattern, with older adults showing weaker learning but stronger long-term memory maintenance compared with younger adults.
Introduction
Adapting to a changing environment requires that humans continuously process diverse visual stimuli. To increase the effectiveness of visual information processing, humans have evolved sophisticated mechanisms for recognising and extracting environmental information (Aslin, 2017; Saffran et al., 1996; Turk-Browne et al., 2005). Imagine that when you move to a new city, you typically pay close attention to the spatial layout near your residence, carefully observing landmarks like parks, road signs, and bus stations. However, as you repeatedly experience these contexts, you may effortlessly hang out around the city without the fear of getting lost. What explanation is there for this cognitive phenomenon?
One theory that might be utilised to explain this phenomenon is the contextual cueing effect, which describes a reduced search time in repeatedly shown displays compared with novel non-repeated displays. This effect was originally examined by Chun and Jiang (1998, 2003) who instructed participants to search for a target item amid several distractor items. In half of the search displays, the spatial arrangements of the target and distractions were presented repeatedly during the experiment, while the arrangements in the other half of the displays were randomly regenerated for each presentation (i.e., non-repeated displays). The results revealed significantly faster response time (RT) in repeated displays than that in non-repeated ones. The researchers concluded that observers learned and used the consistent spatial target-distractor associations in the repeated displays to direct visual search when they encountered the same search display again (Chun & Jiang, 1998, 2003).
The contextual cueing effect has been extensively investigated in several follow-up studies that concentrated on different aspects of it, such as visual search, implicit learning, attention, and related evidence has been found to support the robustness of this cognitive effect (Goujon et al., 2015; Sisk et al., 2019). For example, researchers have found that (1) repeated display configurations could improve visual search performance and boost search speed (Geyer et al., 2010; Makovski & Jiang, 2010; Pollmann, 2019), (2) contextual cueing is (largely) an implicit cognitive ability and does not require the explicit awareness of the contextual repetition (Chun & Jiang, 1998, 2003; Colagiuri & Livesey, 2016; Rausei et al., 2007, but see Kroell et al., 2019), and (3) context memory leads individuals to prioritise attention to the location where the target stimulus is most likely to appear (Anderson, 2016; Jiang & Chun, 2001). As the contextual cueing effect has attracted increased attention from researchers, knowledge of this cognitive ability has grown. However, the relationship between the contextual cueing effect and healthy ageing remains controversial.
On one hand, a number of studies have reported that the contextual cueing effect could be observed in humans of different ages (Howard et al., 2004; Kojouharova et al., 2023; Lyon et al., 2014; Merrill et al., 2013; Preuschhof et al., 2019). For example, Howard et al. (2004) used the standard contextual cueing paradigm to explore the relationship between ageing and implicit spatial contextual learning. In their experiments, older and younger adults were required to search for the target item among the distractor items as quickly and accurately as possible. The results revealed a comparable magnitude of contextual cueing effects between the two groups (i.e., the search facilitation in repeated relative to novel displays, indexed by the RT difference between these two types of displays). Merrill et al. (2013) examined the cognitive-developmental trajectory of contextual cueing with a simplified version of the contextual cueing task, during which cartoon characters were used as search items (i.e., target and distractors). All the participants, including young children (6.3 years old), young adults (19.8 years old), and older adults (72.17 years old), exhibited significant contextual cueing effects, and the magnitude of contextual cueing effects was comparable across the three age groups. In addition, Preuschhof et al. (2019) found that older adults could develop a reliable contextual cueing effect, although more repetition was required, and that this effect was transferred even if the target was relocated in the display. A recent study found that both younger and older adults showed faster target identification in repeated displays compared with novel displays, indicating intact contextual cueing in ageing (Kojouharova et al., 2023). These studies consistently suggested that older adults, like younger ones, could also obtain contextual memory and facilitate their visual search. More importantly, the null difference in the magnitude of contextual cueing between older and younger groups implies that the contextual cueing effect could be constant across ages.
Other researchers, on the other hand, have found that the contextual cueing effect might be impaired with ageing (Goujon et al., 2015; Smyth & Shanks, 2011). With the aim to examine the relationship between contextual cueing and ageing, Smyth and Shanks (2011) employed the standard paradigm of contextual cueing but lowered the number of repetition times of repeated contexts (16 blocks) in their Experiment 1. As a result, reliable contextual cueing was observed in young people but not in older people, and young people’s mean search time was significantly faster than older people. To further investigate whether the response speed difference was a possible reason for observing the contextual cueing effect in young but not older adults, Experiments 2 and 3 manipulated the difficulty of the search task by changing the feature similarity between the distractor and the target items, or the luminance contrasts of item colour to the background colour. The results showed that young people still exhibited a contextual cueing effect when the search speed lowered due to the increased task difficulty. In contrast, the elderly still did not show a contextual cueing effect when the task became easier. Goujon and Fagot (2013) further investigated context learning ability in a non-human primate, the baboon. They found that older baboons exhibited a contextual cueing effect, but this cognitive ability was weakened compared with young adult baboons. These studies suggested that different contextual learning abilities may exist between old and young individuals.
Considering the inconsistency of the findings mentioned above, it was deemed necessary to replicate the validation process. In addition, previous studies suggested that the learned repeated contexts could be stored in long-term memory systems, lasting at least 7 days or even 10 days (Chun & Jiang, 1998, 2003; Jiang et al., 2005; van Asselen & Castelo-Branco, 2009). Furthermore, Goujon and Fagot (2013) observed that contextual cuing persisted after 6 weeks in non-human primates, providing additional evidence for the long-term persistence of this effect. As far as we know, no studies have yet examined whether contextual cueing could remain persistent over more extended periods (e.g., 1 month) in humans, especially in older adults. Notably, when assessing a learning effect, it is necessary to observe not only the process of acquiring information but also the quality of memory consolidation. However, previous studies on ageing and contextual cueing have paid little attention to how ageing affects the memory consolidation of contextual cueing. Thus, in addition to repeating and validating the previous studies on age-related contextual cueing, we also aimed to examine the long-term property of contextual memory.
In parallel to the response speed and accuracy, processing variability also detected information processing between groups of people (Li, Huxhold, & Schmiedek, 2004). According to Williams et al. (2005), the reaction time variability increased with age among 273 participants ranging in age from 6 to 81 years and could be portrayed by a “U”-shaped curve (larger for children and older adults, smaller for young adults, see also Williams et al., 2007). This result indicated that the RT variability could be used to detect and examine the developmental characteristic of cognitive abilities. Similarly, Li, Lindenberger, et al., (2004) explored intra-individual RT fluctuations in a lifespan (6–89 years old) and found that response variability predicted fluid intelligence beyond processing speed in older adults. Furthermore, Hultsch et al. (2000) also used RT variability to investigate cognition performance in three groups of older adults (healthy, with arthritis, and diagnosed with mild dementia), identifying that RT variability was associated with the level of performance and predicted neurological status uniquely. These studies confirmed that the intra-individual RT variability, reflecting the response fluctuation/stability, tracked down the properties of cognitive function in older people (Hultsch et al., 2000; Li, Huxhold, & Schmiedek, 2004; Williams et al., 2005).
The variability in reaction time reflects the stability of response, providing insights into cognitive features that are difficult to capture through reaction time alone. However, there is limited research on using reaction time variability to examine how ageing affects contextual cueing learning patterns. In a recent study, Kojouharova et al. (2023) observed differences in neural correlates when performing a contextual cueing task among older and younger adults. In younger adults, stronger cueing effects were associated with more distinct differences in N2pc (related to attentional allocation and stimulus categorisation) and P3 (related to decision-making confidence) amplitudes between new and repeated displays. But, in older adults, cueing was only linked to amplitude variations in the response-locked lateralized readiness potential(rLRP), which is related to response organization. This study indicates that older adults may develop a contextual learning pattern that enhances response organisation, differing from that of younger adults. Considering the potential feature of the variability in reaction time to detect subtle cognitive mechanisms, in the context of revealing possible differences in contextual cueing learning patterns between older and younger adults, reaction time variability could be regarded as an effective indicator.
Based on the above statements, we structured our investigation into two distinct segments, each focusing on a different age group: older adults and younger adults. The aim was to conduct a partial replicative study to examine and clarify the feature of contextual learning between older and younger adults, combining the analyses of the mean and variability of RT. Differing from previous studies, we also investigated how ageing affected the long-term memory properties of contextual cueing learning. Specifically, we examined the cueing effects in older and young adults after a prolonged interval of 3 weeks subsequent to the initial training. If contextual cueing effects are robust across the lifespan and contextual memory is consistent with time interference, we should observe comparable contextual cueing effects between old and young adults. By contrast, if human’s ability in contextual learning declines with ageing, we should observe weaker contextual cueing effects in older adults.
Experiment 1
Methods
Participants
To ensure a robust level of statistical power, we employed G*Power 3 (Faul et al., 2007) for estimating the requisite sample size with reference to previous research (Kojouharova et al., 2023). As a result, the total sample size was determined to be 17 per group. For our analyses, we applied the repeated measures within-between factors test family with specific parameters: effect size f, power, number of groups, and number of measurements. The effect size (f) was set at 0.25 (calculated by ηp2 = .06), representing a medium effect for both the main effect of CONTEXT and the CONTEXT × AGE GROUP interaction. A power level of 0.8 was chosen, indicating a probability of obtaining a false negative of approximately 20%. The number of groups was set to 2, representing the two age groups, and the number of measurements was set to 2, corresponding to the two levels of the context factor (novel and repeated).
We recruited 24 older adults to attend the experiment (female: 7; age: 60–71 years). All the participants had normal or corrected-to-normal vision and reported no neurological disorders. They signed informed consents before the start of the experiment and received monetary compensation after the experiment. The Ethics Committee of Hangzhou Normal University Affiliated Hospital approved the study.
Apparatus and stimuli
The experiments were conducted in a small, dimly illuminated cabin. The experimental stimuli were presented on a 27-inch, 60-Hz refresh rate computer screen. The viewing distance was set to 57 cm. Programmes were generated and run via MATLAB 2017a with PSYCHTOOLBOX 3.0 extension.
Figure 1 shows an example of the search display (see Figure 1a) and the possible item locations (see Figure 1b). The items were white and displayed on a dark grey background. The search context consists of 12 stimulus items (i.e., 1 “T”-shaped target item and 11 “L”-shaped distractor items) that are randomly presented within a 10 × 10 grid of invisible matrix (12.53° × 12.53° angle of view). The “T”-shaped target has two possible orientations, either to the left or to the right, while the “L”-shaped distractors have four possible directions (i.e., rotated by 0°, 90°, 180°, or 270°; see Figure 1a). The repeated and novel search displays in our experiment featured 12 distinct target locations, with consistency maintained across different blocks for both types of displays. Target items were evenly distributed across the quadrants, excluding the central four grid locations and the four corners (see Figure 1b). Distractor items were fully randomised.
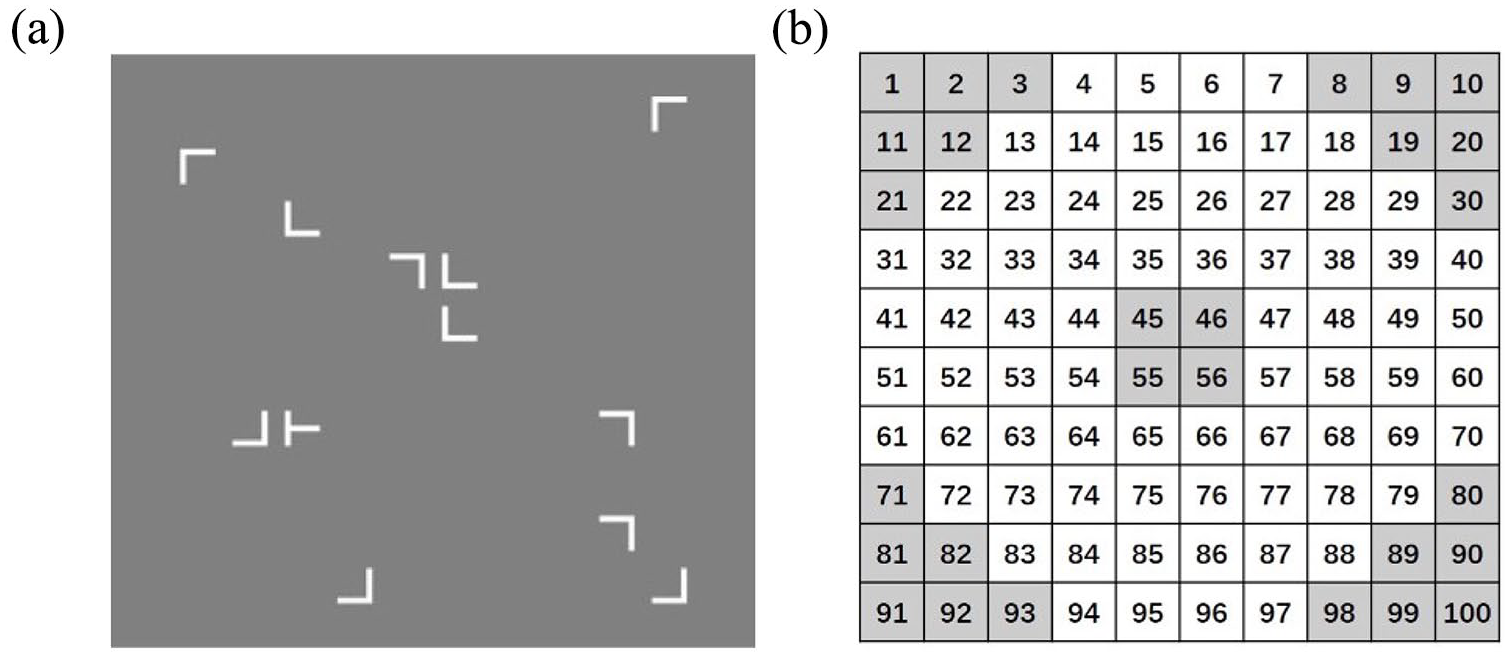
(a) An illustrative example of the experimental stimuli used in the study. (b) The location of the potential item locations. The target item would not appear in the darker cells. The distractors could appear in all the 10 × 10 cells.
Design and procedure
The experiment comprises three phases: practice (2 blocks), learning (40 blocks), and test (10 blocks). During each block, 24 trials were presented randomly, with half repeated contexts and half novel contexts. Each context included 1 “T”-shaped target item and 11 “L”-shaped distractor items. The current experiment adopted two types of contexts: repeated and novel contexts. For the repeated context, the locations and orientations of the distractors and the target location (but not orientation) were maintained constant and repeated once per experimental block. All aspects of the novel context, except for the target’s location, were randomly determined for each presentation. This includes the location and orientation of the distractors and the target orientation. Participants were instructed to respond as quickly and accurately as possible to the orientation of the target item by pressing a key on the keyboard. Two keys were used: The left arrow key represents a target oriented to the left, and the right arrow key represents a target oriented to the right. The correct rate was displayed on the screen at the end of each block. Between each block, participants were encouraged to have a break.
Before starting the formal experiment, participants completed two blocks of practice. Participants had to achieve a correct rate of 85% or higher to be allowed to proceed to the subsequent experiment (see also Chen et al., 2021). Otherwise, they need to repeat the practice procedure. This setting was to assist older participants in understanding tasks. Most participants achieve an 85% or higher correct rate within two blocks of practice. No participants did more than three times of the practice.
The formal experiment consists of a learning phase and a test phase. The test phase had the same design and procedure as the learning phase but was implemented 24–35 days after the initial learning phase to test whether the contextual memory could keep for a relatively long term. During the two phases, each participant performed the same repeated context configuration, and the target item location remained the same for the novel context. Furthermore, participants did not engage in experimental tasks related to contextual cueing paradigms during the time interval between the two phases.
Trial sequence
Each trial is initiated with a fixation cross presented for a random time within the range of 800–1,000 ms. After the fixation disappeared, the screen showed a visual search context with a maximum time of 5 s or until the participant’s response. Following this, a blank screen with a presentation time of 1,000 ms was used as the inter-trial interval (ITI) before the start of the subsequent trial. Figure 2 provides details of the trial sequence.
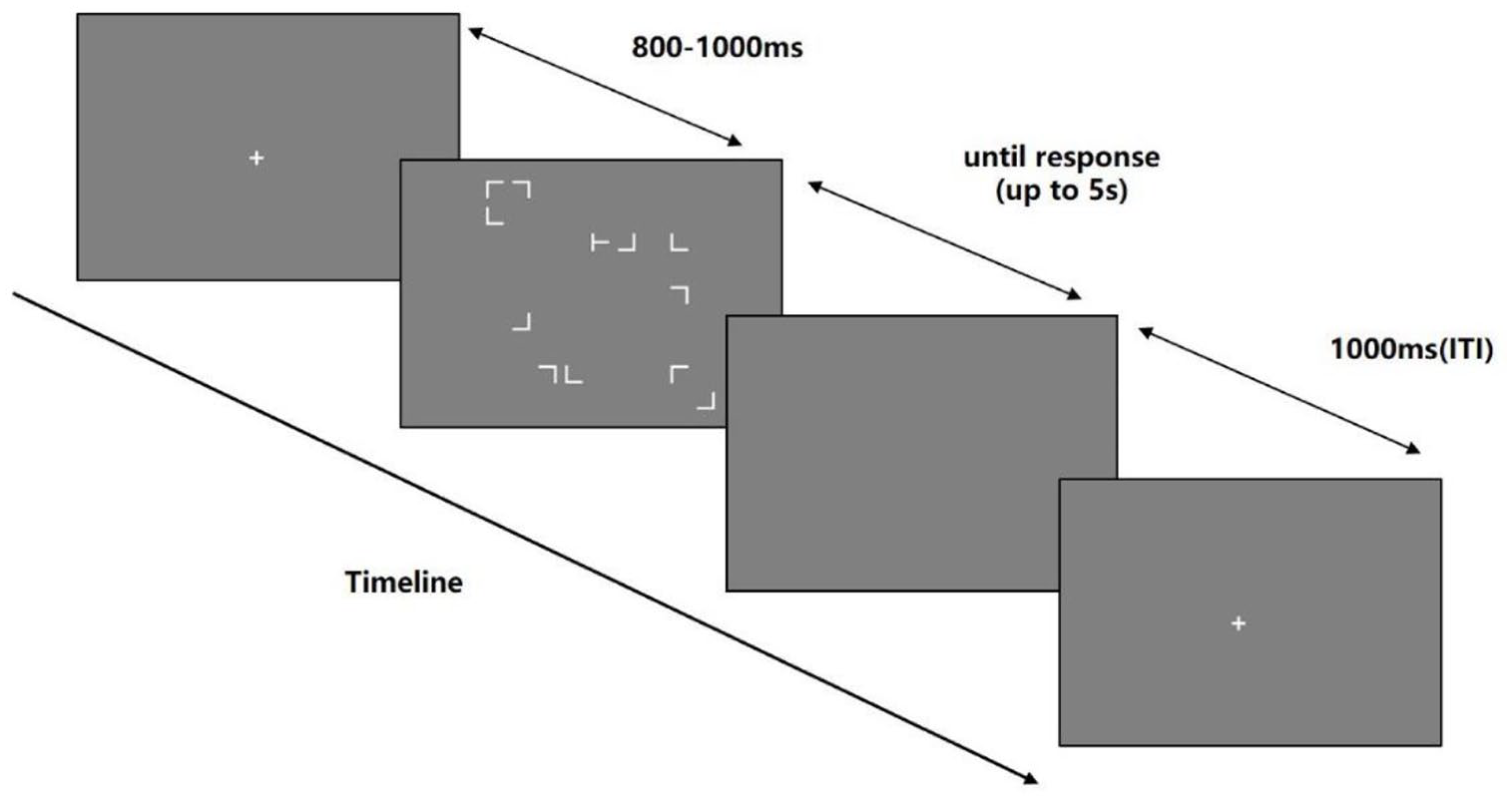
Schematic illustration of the experimental trial sequence.
Statistical analyses
For the mean RT and CVRT (abbr for the CV of the RT) of analysis, every five blocks were combined into one epoch to increase the power of the statistical analysis. To analyse the stability of the implicit spatial contextual learning process, we calculated the RT variability between the repeated contexts and the novel contexts, using the coefficient of variation (abbr: CV, standard deviation divided by the mean) as the index. It was calculated as follows: In each epoch, the target items in each of the 12 novel displays appear 5 times, consistently in the same location. We first calculate the CVRT for each of these 12 novel displays. Then, we compute the mean CVRT for novel displays in that epoch by averaging the 12 individual CVRT values. This approach provides a meaningful CVRT for novel displays in each epoch, despite each novel display only being presented once during the entire task. By comparing the mean CVRT for novel displays to the CVRT for repeated displays (the computational method is the same as novel displays), we can assess the contextual cueing effect in terms of response variability.
The Mauchly sphericity test was performed first before performing the repeated-measures analysis of variance (ANOVA). When the Mauchly sphericity test was not matched (p < .05), the Greenhouse-Geisser corrected values were adopted. Bonferroni correction was used for multiple comparisons. To further justify the non-significant and marginally significant results, we utilised JASP to compute Bayes Factors for Bayesian T-tests (BF10, with default Cauchy (0,1) priors) and Bayesian repeated-measures ANOVA (BFincl, using r scale JZS priors, compared to the null model, across matched models), thereby quantifying the relative evidence between the alternative hypothesis (H1) and the null hypothesis (H0). As suggested by Wagenmakers et al. (2018), the Bayes Factors greater than 3 indicate substantial evidence for H1 over H0, while the Bayes Factors less than 0.3 constitute good evidence for H0 over H1. By complementing the p values, the Bayes Factors provide more calibrated indices to help interpret the extent of evidence supporting or opposing the hypotheses.
Results
The overall mean error rate was 1.49%, with 1.53% for the learning phase and 1.31% for the test phase. No statistical analysis was performed on them due to the low error rate. Incorrect trials and trials with reaction times (RT) below 0.2 s and three standard deviations above the mean were excluded from further statistical analysis.
The learning phase
The mean RT and CVRT of the elderly participants with context and epoch as functions were shown in Figure 3. Repeated-measures ANOVA with Context (repeated vs novel) and Epochs (1–8) as factors were conducted, considering the mean RT and CVRT as the dependent variables, respectively.
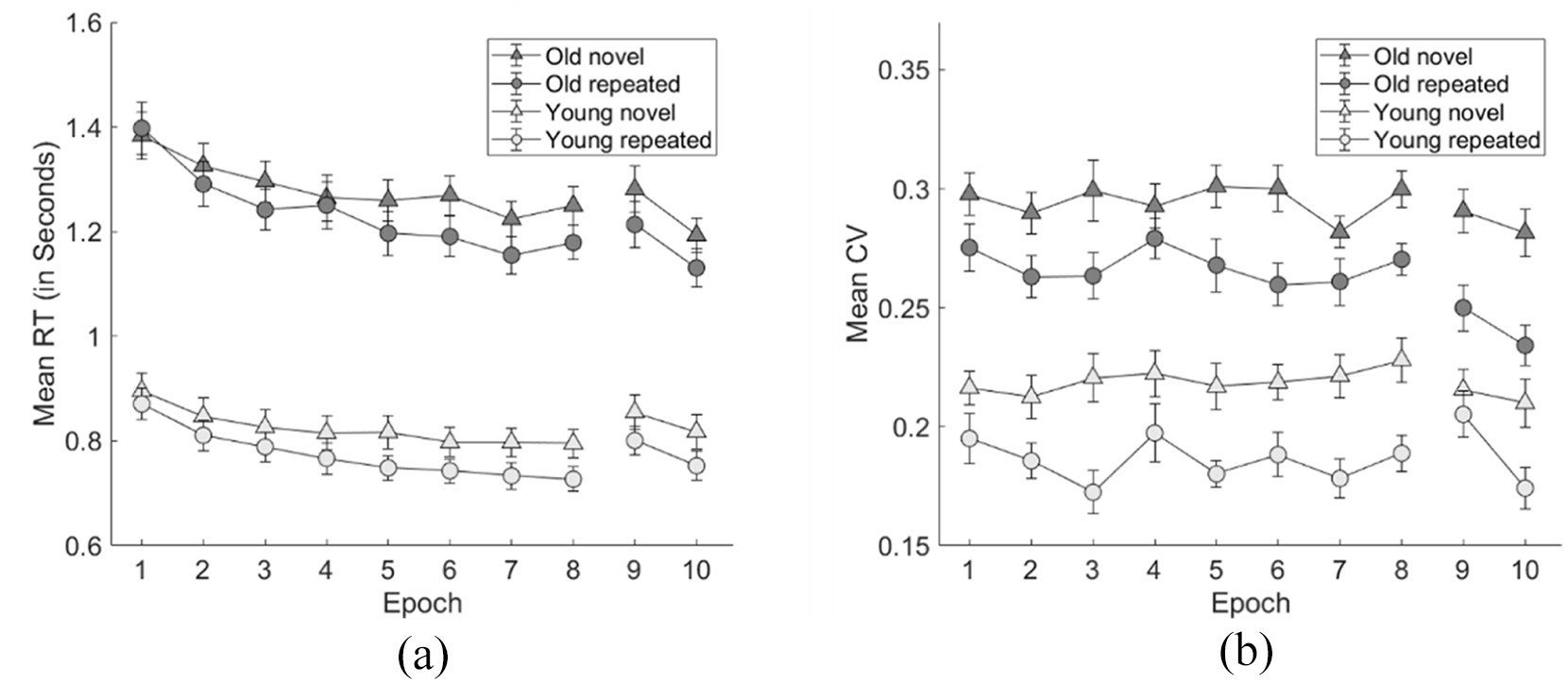
(a) The mean RT and (b) the mean CVRT as function of epoch for two distinct participant groups: Older adults (mean ages: 62.87) in Experiment 1, consisting of all 24 participants; younger adults (mean ages: 21.21) in Experiment 2, comprising all 20 participants. The learning phase consisted of Epochs 1–8, and the test phase consisted of Epochs 9 and 10. Each epoch consisted of 5 blocks, and each block consisted of 24 trials (12 repeated and 12 novel displays). The error bar indicates the standard error of the mean.
For mean RT, the statistical results revealed a significant main effect of Context, F (1, 23) = 5.466, p = .028, ηp2 = .192. Participants’ mean search time of the repeated display (1,238 ms) was significantly faster than that of the novel (1,283 ms) display, confirming the existence of the contextual cueing effect (abbr: CCRT). The main effect of Epoch was also significant, F (7,161) = 22.290, p < .001, ηp2 = .492, demonstrating an increased search speed as the experiment progressed (i.e., a significant procedural learning effect), the mean search time reduced linearly from 1,390 ms in Epoch 1 to 1,215 ms in Epoch 8, linear effect: t (161) = 11.276, p < .001. The Context × Epoch interaction also reached significance, F (7,161) = 3.467, p = .002, ηp2 = .131, suggesting a gradual development of the contextual cueing effect with the progress of the experiment: Contextual cueing effect first reached significance at Epoch 3, t (23) = 2.399, p = .025, but disappeared at Epoch 4, t (23) = 0.558, p = .582, BF10 = 0.247, and then reappeared from Epoch 5 onwards (all ps < .05).
For the mean CVRT, the results showed a significant main effect of Context, F (1,23) = 35.594, p < .001, ηp2 = .607, mean of 0.267 and 0.295 for the repeated and novel contexts, respectively, demonstrating contextual cueing facilitation in terms of response variability (abbr: CCcv), i.e., participants had less variability in response to the repeated contexts in comparison to the novel contexts. Both the main effects of Epoch, F (7, 161) = 1.037, p = .407, ηp2 = .043, BFincl = 0.035, and the Context × Epoch interaction did not reach significance, F (7, 161) < 1, p = .505, ηp2 = .038, BFincl = 0.051, suggesting an early onset of the CCcv: The contextual facilitation reached significance already in Epoch 1, 1 t (23) = 3.002, p = .006, mean effect = 0.024. Combined with the results that CCRT became stable from Epoch 5 onwards, we could conclude that the elderly improve response variability earlier than response speed through contextual learning.
Note that previous studies have found that around one-third of the young participants may fail to obtain contextual cueing effect in standard contextual-guided visual search tasks (Goujon et al., 2015; Von Mühlenen & Lleras, 2004; Zang et al., 2016), and we found that it is the same case for elderly participants: We found only 18 out of the 24 participants showed positive contextual cueing effects while the other 6 participants (i.e., participant number 5, 10–13 and 23, see Figure 4a) failed to obtain contextual facilitation in terms of response speed. Note the non-cueing learners were defined as follows: For each individual participant, we computed their CCRT and CCCV values in the second half of the learning phase (i.e., Epochs 4–8) during which we expected contextual cueing effects to have been established if present. If the participant showed negative CC values (mean CCRT and mean CCcv < 0), we thought them as a “non-CC learner.” Conversely, if they showed positive CC values (mean CCRT > 0 and mean CCcv > 0), we thought them as a “positive CC learner.”
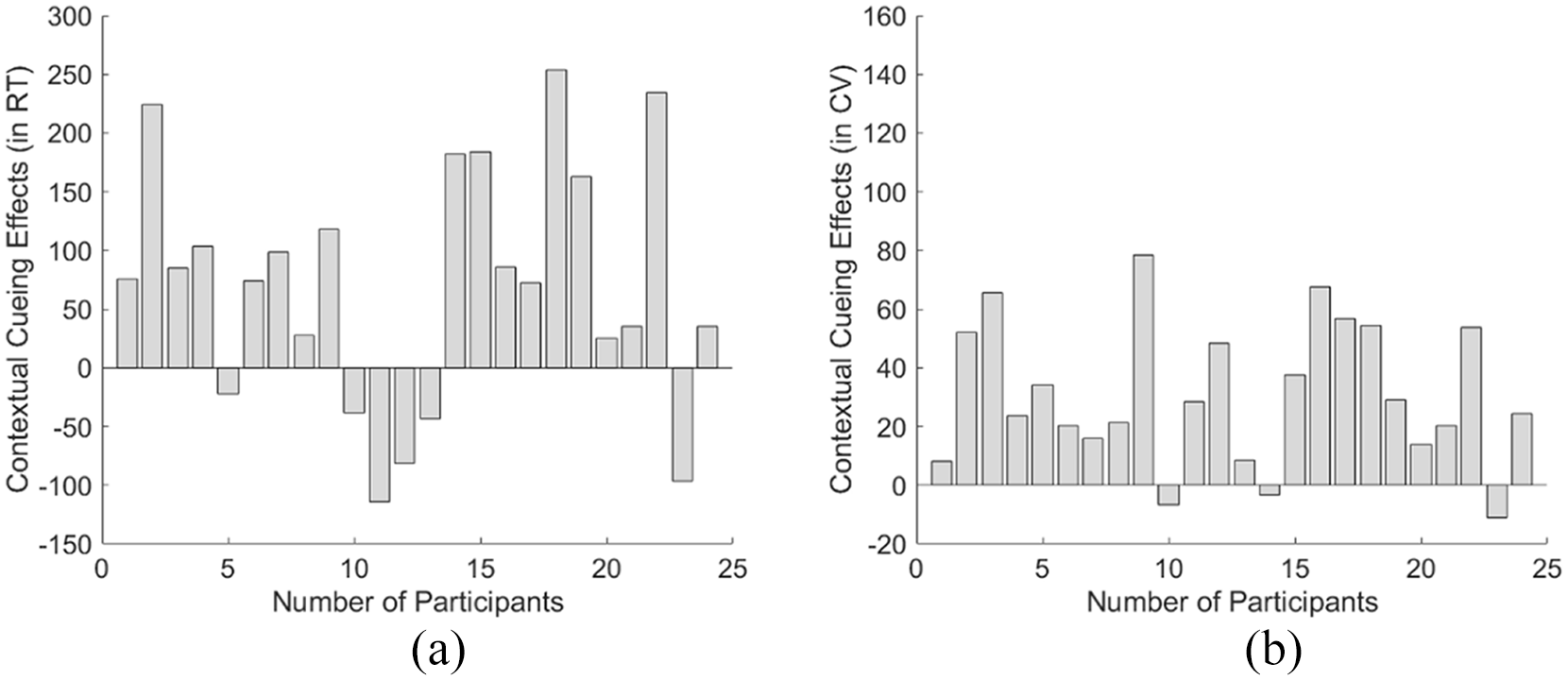
Contextual cueing effect (in the learning phase of Experiment 1) in terms of the mean RT (a) and the mean CVRT (b) for each individual participant. As shown in (a), participants 5, 10–13, and 23 showed a negative cueing effect in terms of mean RT, while all the other 18 participants revealed positive contextual cueing facilitation. Similarly, in (b), participants 10, 14, and 23 showed negative cueing effects in terms of mean CVRT.
When using CVRT as measurement, only 3 out of the 24 participants did not show positive contextual facilitation (see Figure 4b). These results suggested that CVRT could be a more sensitive index than the mean RT in detecting early contextual cueing facilitation. For instance, when a participant partly learned a repeated display, with the learning effect not strong/robust enough to be observed in RT but already observable in CVRT.
The test phase
This phase aimed to investigate the long-term properties of older adults’ contextual memory, i.e., whether the learned contextual memory could be maintained for as long as 4 weeks (24–35 days). Indeed, we analysed both only positive learners (17) and all participants (24), and the results were similar. To streamline the presentation, we report the results based on the inclusion of all participants in the next part.
A repeated-measures ANOVA for the mean RT with Context (repeated vs novel) and Epoch (Epochs 9 and 10) as factors showed main effects: Context, F (1, 23) = 8.376, p = .008, ηp2 = .267, CCRT = 65 ms; Epoch, F (1, 23) = 18.336, p < .001, ηp2 = .444, the mean RT of 1,247 ms and 1,162 ms in Epochs 9 and 10, respectively. The Context × Epoch interaction was not significant, F (1, 23) < 1, p = .801, ηp2 = .003, BFincl = 0.276. Post hoc tests showed a significant effect of Context at the first Epoch (Epoch 9) of the test phase, t (23) = 2.593, p = .019, CCRT = 68 ms, suggesting that the well-established contextual cueing effect (measured by mean RT) for the elderly could be maintained 24 days after the initial learning.
Repeated-measures ANOVA for the mean CVRT with Context (repeated vs novel) and Epoch (Epochs 9 and 10) as factors a showed main effect of Context, F (1, 23) = 38.403, p < .001, ηp2 = .625, CCCV = 44 ms. The effect of Epoch and Context × Epoch interaction, did not reach significance: Epoch, F (1, 23) = 4.071, p = .055, ηp2 = .150, BFincl = 1.082, the mean CV of 0.270 and 0.258 in Epochs 9 and 10, respectively; Context × Epoch interaction, F (1, 23) < 1, p = .516, ηp2 = .019, BFincl = 0.358. Post hoc tests showed a significant effect of Context at the first Epoch (Epoch 9) of the test phase, t (23) = 5.459, p < .001. These results suggested successful maintenance of contextual memory with a long break time of 24 days between the initial learning and the test phases.
Comparison between the learning and test phase
We are interested to know whether participants showed the same or different search pattern at the end of the learning phase (when the contextual cueing effect was well-established) and the beginning of the test phase, namely, to clarify whether any memory decay occurs during the very long-time gap (>24 days) between the two phases. As a result, repeated-measures ANOVA for the mean RT and CVRT with Context (repeated vs novel) and Epoch (Epochs 8 and 9) as factors were applied.
For the mean RT, the statistical analysis showed a significant main effect of Context, F (1,23) = 10.164, p = .004, ηp2 = .306, but not of Epoch and the Context × Epoch interaction (all ps > .05, Epoch: BFincl = 0.834; Context × Epoch: BFincl = 0.239, the mean RT were 1,215 and 1,247 ms for Epoch 8 and Epoch 9, respectively), confirming comparable mean RT and contextual cueing effect before and after the long-time gap. Note that the amount of contextual facilitation in the first test epoch (Epoch 9, CCRT = 68 ms) was also comparable to the last learning epoch (Epoch 8, CCRT = 71 ms), t (23) = 0.107, p = .915, BF10 = 0.216. In other words, we did not observe any significant search speed cost or cueing memory decay in terms of mean RT when re-testing the older participants 24 days later.
For the mean CVRT, the statistical analysis showed significant main effects of both Context and Epoch: Context, F (1, 23) = 46.150, p < .001, ηp2 = .667, mean of 0.260 and 0.295 for the repeated and novel displays, respectively; Epoch, F (1, 23) = 7.089, p = .014, ηp2 = .236, the response variability decreased significantly from 0.285 in the last epoch of the learning phase to 0.270 in the first epoch of the test phase. The Context × Epoch interaction did not reach significance, F (1, 23) < 1, p = .347, ηp2 = .038, BFincl = 0.491. The amount of contextual facilitation in the first test epoch (Epoch 9, CCcv = 0.041) was also comparable to that in the last learning epoch (Epoch 8, CCcv = 0.029), t (23) = 0.959, p = .347, BF10 = 0.325. These results suggested comparable contextual facilitation between the learning and the test phases. However, participants’ response variability even reduced in the test session, suggesting a better search performance (i.e., higher response stability) 24 days after the initial learning phase. This may be caused by a potential memory consolidation of the old participants during the long-time gap.
Discussion
Experiment 1 showed that older adults successfully develop contextual cueing effects with improved search speed and response stability in the repeated displays than that in the non-repeated displays. Interestingly, these contextual cueing effects could be well preserved for at least 24 days. Because we still do not know whether the same contextual learning pattern and a long-term preservation pattern exist in participants of different ages, we conducted a second experiment with younger college students as participants.
Experiment 2
Methods
The experiment was essentially the same as Experiment 1 except that 20 younger adults (college students, 12 female, and 8 males, age: 18–26 years) were recruited to attend the experiment. For comparison with Experiment 1, we need to recruit at least 17 participants who showed positive contextual cueing effects. This goal was not achieved until 20 younger adults were recruited in Experiment 2.
Results
The overall mean error rate was 0.88%, with 0.89% for the learning phase and 0.64% for the test phase. The error rate was low and not statistically analysed. Incorrect trials were excluded. RTs below 0.2 s and three standard deviations above the mean were excluded from further statistical analysis.
The learning phase
The mean RT and CVRT of the younger participants with context and epoch as functions are shown in Figure 3. Repeated-measures ANOVA was conducted with Context (repeated vs novel) and Epoch (Epochs 1–8) as factors, considering the mean RT and CVRT as the dependent variable, respectively.
For the mean RT, the data confirmed a significant main effect of Context, F (1, 19) = 26.921, p < .001, ηp2 = .586, mean of 824 and 774 ms of the novel and repeated contexts, respectively, and Epoch, F (3.313, 62.938) = 42.110, p < .001, ηp2 = .689; linear effect: t (133) = 15.791, p < .001, the mean RT reduced continuously from Epoch 1 (883 ms) to Epoch 8 (761 ms). The Context × Epoch interaction was also significant, F (7, 133) = 2.844, p = .009, ηp2 = .130. Further post hoc analysis showed that the contextual cueing effect reached significance from Epoch 2 onwards (all ps < 0.05, mean effect > 36 ms).
For the CVRT, the statistical analysis showed a significant main effect of Context but not of Epoch: Context, F (1,19) = 46.07, p < .001, ηp2 = .708, mean of 0.186 and 0.220 for the repeated and novel contexts, respectively, suggesting a significant contextual improvement in terms of response variability; Epoch, F (7,133) = 1.309, p = .251, ηp2 = .064, BFincl = 0.063. The Context × Epoch interaction was not significant, F (7, 133) = 1.384, p = .217, ηp2 = .068, BFincl = 0.218. The contextual facilitation reached significance already in Epoch 1, t (23) = 2.888, p = .009, mean effect = 0.021.
Further individual analysis showed that 2 of the 20 younger participants (Participants 5 and 6) failed to show a positive contextual cueing effect in terms of RT while Participants 3 and 6 did not show contextual facilitation in response variability (see Figure 5). The proportion of the younger participants who could not demonstrate the contextual cueing effect (10%) was less than the proportion of the elder group (around 30%) as well as the proportion reported in previous studies (Goujon et al., 2015; Von Mühlenen & Lleras, 2004; Zang et al., 2016).
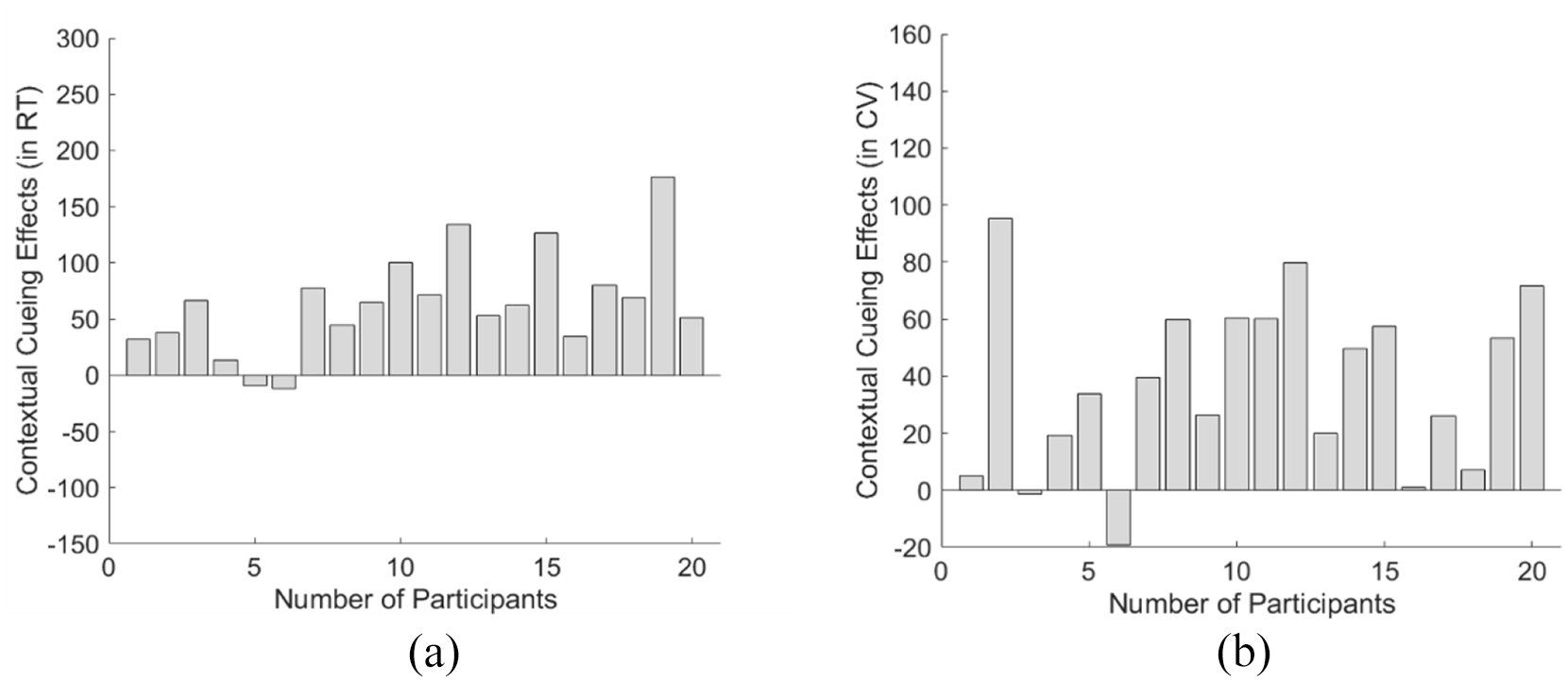
Contextual cueing effect (in the learning phase of Experiment 2) in terms of the mean RT (a) and the mean CVRT (b) for each individual participant. As shown in (a), participants 5 and 6 showed a negative cueing effect in terms of mean RT, while all the other 18 participants revealed positive contextual cueing facilitation. Similarly, participants 3 and 6 showed negative cueing effects in terms of mean CVRT (b).
The test phase
In Experiment 2, we analysed both only positive learners (n = 17) and all participants (n = 20), and the results were also similar. To avoid repetition, we will report the findings based on including all participants in the following section.
A repeated-measures ANOVA for the mean RT with Context (repeated vs novel) and Epoch (Epochs 9 and 10) as factors showed a main effect of Context, F (1, 19) = 35.119, p < .001, ηp2 = .649, CCRT = 59 ms; Epoch, F (1, 19) = 12.774, p = .002, ηp2 = .402, the mean RT of 828 and 785 ms in Epochs 9 and 10, respectively. The Context × Epoch interaction was not significant, F (1, 19) < 1, p = .471, ηp2 = .028, BFincl = 0.350. Post hoc tests showed a significant effect of Context at the first Epoch (Epoch 9) of the test phase, t (19) = 4.515, p < .001. These results altogether suggested that the well-established contextual cueing facilitation of younger participants could be preserved during the test phase.
Repeated-measures ANOVA for the meant CVRT with Context (repeated vs novel) and Epoch (Epochs 9 and 10) as factors showed main effects: Context, F (1, 19) = 10.819, p = .004, ηp2 = .335, CCCV = 23 ms; Epoch, F (1, 19) = 4.747, p = .042, ηp2 = 0.079, BFincl = 1.472, the mean CV of 0.210 and 0.192 in Epochs 9 and 10, respectively. The Context × Epoch interaction effect did not reach significance: F (1, 19) = 3.218, p = .089, ηp2 = .038, BFincl = 1.634. However, post hoc tests showed a significant effect of Context at the second test epoch (Epoch 10), t (19) = 3.668, p = .002, instead of at the first test epoch (Epoch 9), t (19) = 1.022, p = .320, BF10 = 0.368. This result demonstrated that younger participants initially exhibited significant reductions in contextual facilitation in terms of response variability 24 days after the initial learning phase. Subsequently, the rapid emergence of this facilitation may be attributed to the occurrence of relearning.
Comparison between the learning and test phases
To examine the change in mean RT and CVRT among younger adults between the learning phase and test phase, we conducted a repeated-measures ANOVA with Context (repeated vs novel) and Epoch (Epochs 8 and 9) as factors, considering the mean RT and CVRT as the dependent variable, respectively.
For the mean RT, the statistical analysis showed a significant main effect of both Context and Epoch: Context, F (1,19) = 67.180, p < .001, ηp2 = .780; Epoch, F (1,19) = 27.421, p < .001, ηp2 = .591, the mean RT were 761 and 828 ms for Epochs 8 and 9, respectively, suggesting the search speed decreased significantly from the learning phase to the test phase after at least 24 days. The Context × Epoch interaction was not significant, F (1,19) = 0.582, p = .455, ηp2 = .030, BFincl = 0.40, confirming comparable contextual cueing effect before and after the long-time gap. Note that the amount of contextual facilitation in the first test epoch (Epoch 9, CCRT = 68 ms) was also comparable to the last learning epoch (Epoch 8, CCRT = 54 ms), t (19) = 0.763, p = .455, BF10 = 0.31. These results confirmed again that there was no significant difference regarding contextual cueing effect (measured by CCRT) between these two phases.
For the mean CVRT, the statistical analysis showed significant main effects of both Context and Context × Epoch interaction: Context, F (1, 19) = 9.002, p < .001, ηp2 = .321, mean of 0.197 and 0.222 for the repeated and novel displays, respectively; Context × Epoch interaction: F (1, 19) = 5.895 1, p = .025, ηp2 = .237. But the effect of Epoch did not reach significance, F (1, 19) < 1, p = .779, ηp2 = .004, BFincl = 0.296. Post hoc tests showed a significant effect of context occurred at the last epoch of the learning phase, t (19) = 3.861, p < .001, instead of at the first epoch of the test phase, t (19) = 1.022, p = .320, BF10 = 0.239. The amount of contextual facilitation in the first test epoch (Epoch 9, CCcv = 0.010) was also significantly different to that in the last learning epoch (Epoch 8, CCcv = 0.039), t (19) = 2.428, p = .025, again confirming a significant contextual memory decay with the long-time gap of 24 days. In other words, younger participants exhibited a reduced contextual memory 24 days after the initial learning phase.
Discussion
Experiment 2 showed that younger adults could learn the repeated spatial context and exhibited contextual cueing facilitation in both response speed and variability. The contextual facilitation in RT but not CVRT could be maintained in the later test phase, and a search cost (i.e., slower RT) was observed in the first test epoch compared with the last learning epoch. These results suggested that younger participants exhibited a reduced contextual memory 24 days after the initial learning phase.
Recall that older adults in our Experiment 1 retained contextual memory in terms of both RT and variability in the post-test phase and no extra search costs were observed. Combined with younger adults’ behaviour, we could observe a different contextual learning and long-term retrieval pattern. To further elucidate these differences, we ran between-experiment analysis in the following part.
Omnibus between-experiment analysis
As a way to uncover the effects of ageing on contextual cueing learning, we will compare behavioural performance between younger and older adults. The factors that we will consider include the mean search speed and the mean variability, the contextual learning effect, and the long-term property of contextual memory.
The mean search speed and variability
Older participants responded significantly slower and more variably than the younger adults: Mean response speed of 1,260 and 799 ms of the elderly and younger participants, respectively, t (42) = 9.831, p < .001, Cohen’s d = 2.976; mean response variability of 0.281 and 0.203 of the elderly and younger participants, respectively, mean CVRT, t (42) = 8.712, p < .001, Cohen’s d = 2.638.
Contextual learning effect
Previous within-experiment analysis hints that younger participants may have stronger contextual learning abilities. This is because 30% of the older participants while only 10% of the younger participants failed to obtain positive contextual facilitation during the learning session. Furthermore, the contextual cueing effect in terms of RT became reliable from Epoch 2 (i.e., 10 repetitions of the repeated displays) for younger participants but from Epoch 5 (i.e., 25 repetitions) for the older participants.
To validate the above speculation, we conducted further between-experiments analysis. The first analysis is to compare normalised contextual cueing facilitation between the older and younger participants. The normalised contextual facilitation in terms of RT could be calculated as CCRT = (RTnovel − RTrepeated)/RTnovel, and the facilitation in terms of response variability as CCcv = (CVnovel − CVrepeated)/CVnovel. The normalised process was conducted to avoid potential influences from the different RTs and variability between the two groups of participants. A repeated-measures ANOVA was conducted on the normalised CCRT and CCcv, considering factors such as Age group and learning Epoch (Epochs 1–8). The results showed a significant increase in normalised CCRT from Epoch 1 to Epoch 8 (6–67 ms, representing the mean increase across both groups), F (7,294) = 6.243, p < .001, ηp2 = .129, while other factors did not reach statistical significance on both dependent variables (all ps > .05, BFincl < 0.3; see Figure 6). These results indicated no direct evidence for stronger contextual learning ability of the younger participants.
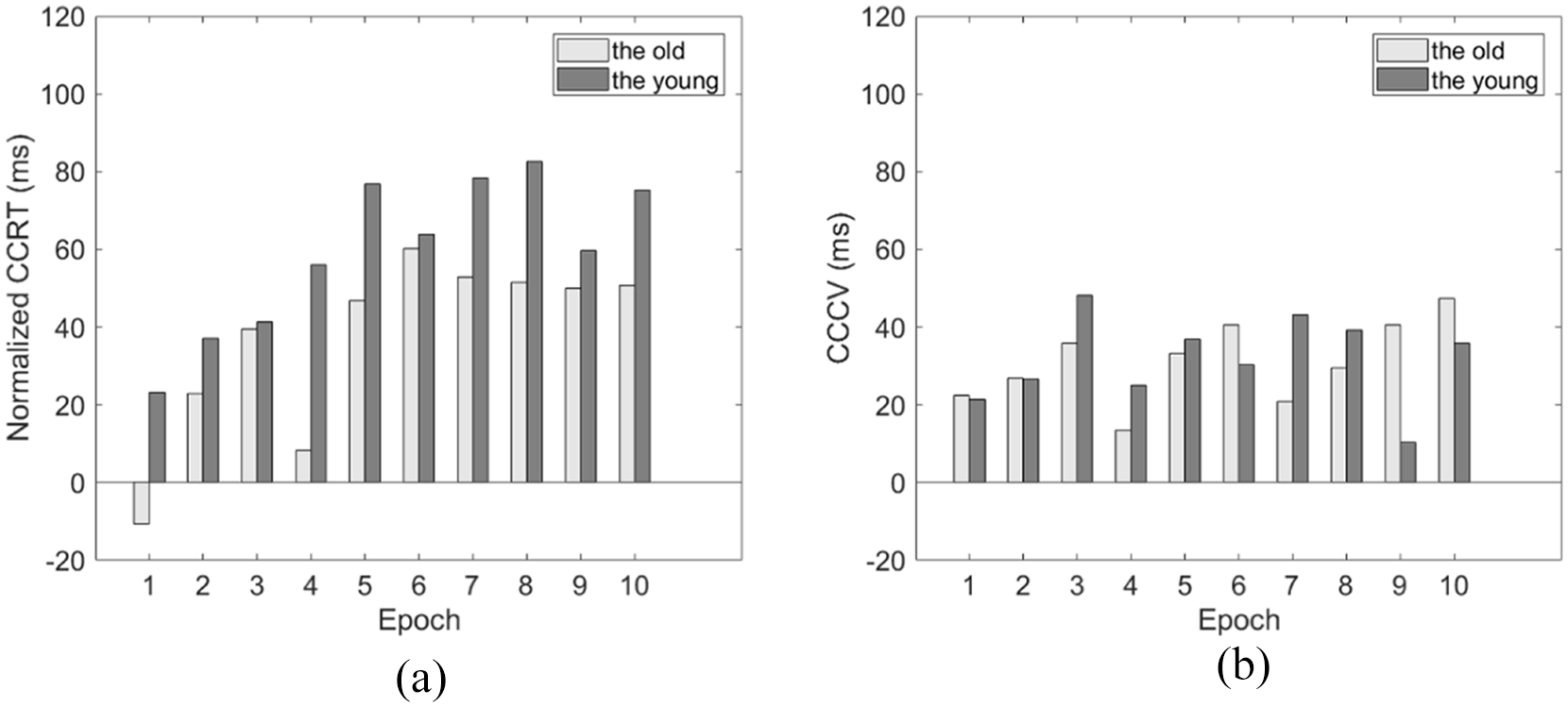
The comparison of the normalised CCRT (a) and CCcv (b) by Age group (the old and the young) and Epoch (epochs 1–8). CCRT = (RTnovel − RTrepeated)/RTnovel; CCcv = (CVnovel − CVrepeated)/CVnovel. The light-coloured bar and the dark-coloured bar represent contextual facilitation in the older and younger groups, as measured by normalised CCRT and CCcv, respectively.
However, when we further compared the number of learned repeated displays between the two groups, an intriguing difference was observed. This analysis was chosen because previous studies showed that not all but only a subset of the repeated displays were learned, in which the search speed was faster than that in the novel displays (Peterson & Kramer, 2001; Schlagbauer et al., 2012). Researchers deem that cueing facilitation is restricted to repeated and, more importantly, “recognised” displays (Peterson & Kramer, 2001; Schlagbauer et al., 2012). In our study, we defined a learned repeated display as one for which the mean RT and CV was shorter than the novel contexts in the last epoch of the learning phase (i.e., Epoch 8). This criterion was applied to assess learning based on the mean RT and CV difference between repeated and novel contexts.
When using RT as an indicator to assess the number of learned repeated displays, the results showed a difference between older adults and younger adults, t (42) = 1.97, p = .028, Cohen’s d = 0.596, with 7.37 and 8.45 (on average) out of the overall 12 repeated displays being learned in the old and young participants, respectively. This result confirmed the conclusion that contextual learning in terms of RT improvement exhibits greater efficacy among younger adults when compared with their older counterparts. Interestingly, the analysis using CVRT as an indicator showed no significant difference in repeated displays that these two age groups learned, t (42) = 1.273, p = .105, Cohen’s d = 0.385, BF10 = 0.570, with the number of learned displays being 9.5 in the old and 10.1 in the young. This suggests a similar degree of improvement in response variability between the two groups. The distinct patterns observed between RT and CVRT may be elucidated by the partial learning of certain configurations in the older group, which already demonstrated search facilitation in response variability. However, additional repetitions are necessary to consolidate this learning before facilitation in response speed is also evident. This suggested that CVRT could be a more sensitive indicator of contextual cueing than RT especially when a repeated context was partly learned.
The long-term property of contextual cueing memory
An additional contextual difference observed in the previous analysis is the maintaining of contextual cueing effect in terms of response variability, which occurs in older but not younger adults. This finding is further supported by our between-experiment analyses, given that the mean CCCV at the first test epoch was significantly larger for old adults than that for younger adults: CCCV at the first test phase epoch with age group as a factor revealed significant differences, t (42) = 2.445, p = .009, Cohen’s d = 0.740, with the mean CCCV of 0.040 and 0.010 for older and younger adults, respectively. This pattern of significant results also held when only positive learner participants were included, t (32) = 1.762, p = .044, Cohen’s d = 0.604, BF10 = 1.064, the mean CCCV of 0.034 and 0.009, respectively.
Note that a similar comparison on the normalised CCRT did not show any significant difference between older and younger adults, t (42) = 0.383, p = .704, Cohen’s d = 0.116, BF10 = 0.317, with mean of 50 and 59 ms for older and younger adults, respectively. In addition, no significant difference emerged when only positive learner participants were included, t (32) = 0.755, p = .456, Cohen’s d = 0.259, BF10 = 0.410, mean of 78 and 59 ms, respectively. This demonstrated that CV might be a sharper detector in recognising age-related contextual cueing features in contrast to RT.
It could be argued that the long-term memory of contextual cueing observed during the test session may contribute to the new learning effects that occurred during the test session, but we are more inclined to believe that the contextual memory measured in the test phase primarily reflects long-term memory effects. To support this assertion, we conducted an analysis with mean RT in the first epoch of the learning phase (Epoch 1) and the first epoch of the test phase (Epoch 9) between older and younger adults. The results showed a significant effect of Context × Epoch interaction in older adults, F (1, 23) = 9.778, p = .005, ηp2 = .298, and a marginal significant effect in younger adults, F (1, 23) = 3.307, p = .085, ηp2 = .148, BFincl = 1.119. These results suggested that the initial contextual effect in Epoch 1 is much weaker than the contextual cueing effect in Epoch 9. If the cueing effect observed in Epoch 9 were a result of relearning, we would expect to see a similar cueing effect compared with Epoch 1.
General discussion
Would spatial contextual learning decline with ageing? To answer this question, we examined the contextual learning patterns of older (60–71 years old) and younger (18–26 years old) adults using a contextual-guided visual search paradigm. We found significant contextual learning effects in both groups (affecting both response speed and variability), and these effects persisted for at least 24 days. In contrast, older adults required more repetitions and memorised fewer repeated stimuli during initial learning, but their long-term memory may be stronger given that their contextual facilitation persisted in both response speed and variability while younger adults only persisted in response speed but not variability. In short, older adults showed weaker learning but stronger long-term memory maintenance than younger adults, suggesting an age-related complex and diverse contextual cueing pattern (differing from a simple decline with ageing, Smyth & Shanks, 2011).
While contextual learning has been extensively examined for the facilitation of response speed, we are the first group to examine response stability in contextual cueing, with the coefficient of variance (CVRT = RT/SDRT) being analysed. We observed concrete evidence that contextual learning improved not only response speed but also response variability in both older and younger adults. And the contextual facilitation in response variability for young adults has also been replicated in another submitted manuscript from our group (in submission). This evidence suggested that response stability should also be considered as a contextual cueing indicator in future studies.
It is of great interest to note that response stability (calculated by CVRT) is a more sensitive detector of age-related contextual cueing features than mean RT (calculated by RT). For older participants, RT revealed robust contextual facilitation first from Epoch 5 (far later than the younger group, which revealed contextual facilitation from the Epoch 2), while CVRT already revealed significant facilitation in the first 5 blocks (for both older and younger participants). Remember that Smyth and Shanks (2011) conducted an experiment consisting of only 16 blocks to examine the contextual cueing effect in older adults. After discovering no improvement in contextual cueing in terms of RT, they came to the conclusion that contextual learning ability declined with age. However, Smyth and Shanks’s (2011) conclusion has been criticised by a number of subsequent studies that proposed comparable contextual learning ability between older and younger people with more number blocks (more repetition) in their experiment (Howard et al., 2004; Lyon et al., 2014; Merrill et al., 2013; Preuschhof et al., 2019). Here, we offer a new view with empirical evidence: Both older and younger people have contextual learning abilities (as proposed by Howard et al., 2004; Lyon et al., 2014; Merrill et al., 2013; Preuschhof et al., 2019), but older people are slower in obtaining contextual facilitation in terms of response speed, which is the reason that Smyth and Shanks (2011) failed to observe contextual facilitation for older people (i.e., too few repetitions was provided in their study). However, older people show response variability much earlier than speed in contextual learning, and this offers another solution for studies with shorter experiments as that was used in Smyth and Shanks (2011). In other words, if Smyth and Shanks (2011) reanalyzed their data with response variability, they may be able to observe contextual facilitation for old people even with only 16 blocks of repetition.
Another intriguing finding in the learning phase was the failure of 6 out of the 24 older participants (25%) to demonstrate contextual facilitation in terms of RT. This is in line with earlier research that suggested that one-third of the subjects did not exhibit a beneficial contextual cueing effect (Goujon & Fagot, 2013; Von Mühlenen & Lleras, 2004; Zang et al., 2016). Despite the fact that it is still unknown why certain people were unable to learn the context, four of these six “cueing failures” actually showed positive cueing facilitation in response stability. This suggested that certain participants, particularly older individuals, are not failures but slow learners who are not able to show positive contextual facilitation in terms of RT within the limited number of repetitions in a particular experiment. Note for the experiment with younger participants, only Participants 5 and 6 out of the total 20 participants (10%) failed to demonstrate positive RT facilitation, indicating a potentially better contextual learning ability than that of older people. Considering CVs, Participants 3 and 6 failed to show contextual cueing facilitation. This variety of contextual learning behaviour in the younger participants—Participant 6 failed to learn contextual cueing in both the RT and CV, while Participants 3 and 5 failed in only one of them—indicates the existence of some individual differences in contextual learning, such as failure to learn context.
Being a more sensitive measure, analysis of the response stability also shows advantages (over RT) in examining the long-term property of contextual memory in the post-test phase 24 days after the initial learning. In particular, the contextual facilitation in terms of RT was preserved for both older and younger participants in the first test session, indicating that the contextual memory could be preserved for at least 24 days. This is in line with earlier research that suggested young adults’ contextual memory might last for at least 2 weeks (Goujon et al., 2015; Von Mühlenen & Lleras, 2004). However, here we went a step further and offered fresh proof that both older and younger people can preserve their long-term contextual memory for at least 3 weeks. It is crucial to highlight that contextual facilitation in terms of response stability revealed different long-term properties across the two groups, despite the fact that significant facilitation was detected for older participants in the first test period but not for younger ones. This finding offered the possibility of reaffirming the previous conclusion on the long-term property of the contextual cueing effect. That is to say, contextual memory can be preserved for a considerable amount of time following initial learning; however, it may not be entirely preserved and may instead partially deteriorate. For instance, young adults preserved their contextual facilitation in terms of RT, but not in terms of response stability.
It is interesting to notice that older adults have better long-term memory than younger adults given that both contextual facilitation in terms of response speed and variability was maintained while younger adults only maintained response speed. A potential reason for this long-term memory difference could be a compensatory mechanism for old peoples’ memory systems (Reuter-Lorenz, 2002; Rieckmann & Bäckman, 2009). As common knowledge, ageing significantly impairs one’s explicit memory and capacity to learn new information (Lupien et al., 2005). For instance, researchers have repeatedly suggested that human memory, including episodic memory and working memory, declines with ageing (Hultsch et al., 1992; Nyberg et al., 2012; Park et al., 2002). In this sense, to adapt to this impaired learning ability and explicit memory, older people become more persistent and rely more on habit and past knowledge that has been obtained through learning (Edmonds et al., 2012; Park & Reuter-Lorenz, 2009). Therefore, it seems to make sense that older adults have a stronger long-term contextual memory than younger ones, especially when it comes to maintaining response stability (i.e., being less variable) than younger adults.
Returning to our initial findings in the learning phase, it was found that older adults could learn the repeated context, albeit with relatively slower and weaker learning performance in terms of response speed compared with their younger counterparts. This decreased ability for learning aligns with the neurological evidence that links contextual learning with the medial temporal lobe (e.g., Chun & Phelps, 1999), a region of the brain known to decline with age (Raz et al., 2004; Ward et al., 2015). To be more precise, Chun and Phelps (1999) concluded that the acquisition of contextual information is dependent on the medial temporal system, based on their observation that amnesic subjects with damage to the medial temporal system, including the hippocampus, showed impaired implicit contextual learning when compared with the control group. Moreover, extensive research employing neuroimaging techniques such as functional Magnetic Resonance Imaging (fMRI) has revealed that the hippocampus, parahippocampal gyrus, entorhinal olfactory cortex, and temporoparietal joint area would be activated in response to repeated context when compared with novel context (Geyer et al., 2012; Giesbrecht et al., 2013; Goldfarb et al., 2016; Kasper et al., 2015; Spaak & de Lange, 2020; Westerberg et al., 2011), further confirming the important role of the medial temporal lobe in contextual learning. Note that the structure of the human brain, especially the medial temporal lobe underwent age-related shrinking, is accompanied by a significant decline in hippocampal volume and minimal changes in entorhinal volume (Raz et al., 2004; Ward et al., 2015). Therefore, it is logical to expect a reduction in contextual learning among elderly individuals as the medial temporal lobe, which is a crucial brain area for contextual learning, deteriorates with age.
One might argue that the difference of long-term contextual memory between older adults and younger adults could have been due to their existing different baseline levels of performance for the two groups. In other words, although older and younger adults exhibited differing memory performance for repeated contexts after 24 days, this variance can be attributed to the challenge younger adults face in maintaining their high-performance levels—characterised by faster and less variable RTs—from the training phase to the test phase. In contrast, older adults, owing to lower performance at the end of training, seem more adept at maintaining their performance from the training phase to the test phase. To clarify this, we conducted additional analyses splitting the older adult group into high and low baseline RT subgroups—using the median of their mean RT at novel contexts during the learning phase as the cut-off point. As the subgroups did not differ at the beginning of the test phase, we are inclined to believe that this difference seems to reflect differential memory maintenance rather than baseline levels of performance. But, the small sample sizes of the subgroups reduced statistical power to detect potential differences. Further research with larger age-matched RT subgroups is needed to fully disentangle these factors.
In the studies by Chun and Jiang (2003) and van Asselen and Castelo-Branco (2009), they applied repeated presentations of novel contexts during the test phase as a means to control for the possibility of new learning occurring during that session. Given the effectiveness of this manipulation in ensuring examination of the long-term persistence of CC, future research should consider employing this paradigm more extensively. In the context of our study, we acknowledge the possibility of relearning effects, but we are inclined to believe that the contextual memory measured in the test phase primarily reflects long-term memory effects because the contextual cueing effect in the last learning epoch was significantly larger than that in the initial learning epoch.
To sum up, our study highlighted the potential of response variability, alongside the traditional response speed measure, as a reliable and sensitive indicator for detecting contextual cueing. The observation that both younger and older participants showed significant contextual learning effects in terms of response speed and variability suggests that the contextual cueing effect could be well preserved during healthy ageing. Notably, older participants exhibited enhanced long-term memory retention compared with young adults, as evidenced by the sustained contextual facilitation in both response speed and variability. These findings indicate that older individuals might exhibit a different contextual cueing pattern in contrast to their younger peers, which warrants further investigation through a study of brain mechanisms.
Footnotes
Acknowledgements
We would like to thank Professor Zang Yufeng for his invaluable inspiration on the idea of the current study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (NSFC 32071042) and the Starting Research Fund of the Affiliated Hospital of Hangzhou Normal University (2021YN2021107) to X.Z. The funding bodies had no involvement in the study design, data collection, analysis, decision to publish, or preparation of the manuscript.