
Abstract
Flexible, adaptive behaviour depends on the application of prior learning to novel contexts (transfer). Transfer can take many forms, but the focus of the present study was on “task schemas”—learning strategies that guide the earliest stages of engaging in a novel task. The central aim was to examine the architecture of task schemas and determine whether strategic task components can expedite learning novel tasks that share some structural components with the training tasks. Groups of participants across two experiments were exposed to different training regimes centred around multiple unique tasks that shared some/all/none of the structural task components (the kinds of stimuli, classifications, and/or responses) but none of the surface features (the specific stimuli, classifications, and/or responses) with the test task (a dot-pattern classification task). Initial test performance was improved (to a degree) in all groups relative to a control group whose training did not include any of the structural components relevant to the test task. The strongest evidence of transfer was found in the motoric, perceptual + categorization, and full schema training groups. This observation indicates that training with some (or all) strategic task components expedited learning of a novel task that shared those components. That is, task schemas were found to be componential and were able to expedite learning a novel task where similar (learning) strategies could be applied to specific elements of the test task.
Flexible, adaptive behaviour depends on the application of prior learning to novel contexts (transfer). Without the ability to transfer learned material beyond the learning context, any slight variation would require that a given task be learned “from scratch.” Despite its importance in flexible adaptive behaviour and the education sector, the mechanisms by which transfer takes place (especially in the early stages of learning) remain poorly understood. The aim of the present study was to develop our understanding of transfer by investigating how the early stages of learning a novel task are guided by recently used learning strategies.
According to Chein and Schneider’s (2012) “triarchic” theory of learning, there are three distinct stages of learning (formation of a learning strategy, controlled execution, automatic execution), each of which is localised in a distinct neural network/system (metacognitive system, cognitive control network, representation system). The early stages of learning are characterised by the formation of a learning strategy or “task schema,” by the metacognitive system, which is then applied to the current context by the cognitive control network. Eventually, it becomes possible for the representation system to perform the (now well-practised) task with little or no intervention from the other systems and performance is thought to be “automatic.”
Application of a “task-set” (a tuning of the cognitive control network towards completion of a specific task/goal; see, for example, Kiesel et al., 2010; Monsell, 2003; Vandierendonck et al., 2010) will eventually result in the phased transition to automatic execution of the task. Similarly, early application of a task schema will result in the formation of a task-set that can be used to guide performance until it is no longer needed, and the task can be completed from memory alone. A task schema can therefore be considered a set of broad strategic parameters that can be applied to multiple tasks with a common structure (e.g., stimulus → classification → response), whereas a task-set is a specific group of parameters that are applied to a relatively limited context (e.g., 3, 5, 7 → odd number → left index finger key press). Automatic execution is thought to be context-specific (e.g., Logan, 1988) and therefore relies on specific instances (e.g., 7 → left index finger key press). Although there is a wealth of research on the controlled execution and automatic execution stages of learning, there is little research that has focused specifically on the formation stage and the transfer of task schemas between tasks with a common structure.
Although we introduce the term “task schema” here, the notion that learning might not be limited to associations between representations but can also include the underlying structure of a set of related tasks is not novel (e.g., Ableson, 1981; Maslow, 1949; Thorndyke & Yekovich, 1980) and has even been the subject of more recent research (e.g., Braun et al., 2010; Cooper & Shallice 2006). Although there are a few contemporary examples of research that specifically investigate this kind of learning (see below), remarkably little is known about the details of how task schemas are represented, their architecture, or how they orchestrate learning a novel task. The central aim of the present study was to contribute to this literature by conducting a relatively large-scale, systematic investigation of these issues with an eye to develop our understanding of an important aspect of human learning and transfer that remains poorly understood.
Learning and transfer
Research on learning and automaticity has a long tradition of using tasks that rely on the formation of simple stimulus–response (S-R) associations (e.g., A → left-hand key press, B → right-hand key press). However, there is a recent recognition of the limits inherent in such a narrow view (e.g., Hazeltine & Schumacher, 2016; Schumacher & Hazletine, 2016). A growing body of research has been investigating learned associations between other kinds of representations such as categories of stimuli and/or responses (for a relevant review, see Henson et al., 2014). For example, Horner and Henson (2009, 2011) asked participants to classify pictures of everyday items in a study-test design. By manipulating repetitions of the stimulus (picture, word), the classification (e.g., larger than a shoebox, larger than a wheelie bin), the decision (yes, no), and the action (left/right key press) between study and test phases, they were able to demonstrate that stimuli and responses can be represented at different levels of abstraction. For example, a stimulus can be represented as a specific exemplar or a semantic/perceptual category of stimuli, whereas a response can be represented motorically or semantically (for some other examples of research consistent with this idea see, for example, Dennis & Perfect, 2013; Longman et al., 2018, 2019, 2020; Moutsopoulou & Waszak, 2012, 2013; Pashler & Baylis, 1991; Pfeuffer et al., 2017; Wills et al., 2006). The common conclusion from this body of research is that existing associations between the learned material and other instances from the same stimulus/response category can expedite learning when those instances are introduced during the controlled execution stage. For example, learning that the letters A, E, and I require a left-hand response might result in speeded responses to untrained instances from the same category (i.e., the vowels O and U) due to existing associations between these instances as part of a broader category structure.
However, learning need not be limited to the associations formed between (sets of) stimuli, categories, and/or responses. Learning can also be observed when practised task components are combined in novel ways. For example, Cole and colleagues (2011; see also Cole et al., 2010) developed a paradigm that allowed them to give participants training on a set of 12 task components (rules) that could be combined to make 64 unique tasks. On each run of trials, a unique task (a unique combination of the task components) was cued by instructing the participant in the semantic classification (e.g., “sweet”), the comparison (e.g., “same”), and the response (e.g., “left index finger”) which should be applied to the subsequent word pairs (e.g., “grape” and “apple”). Four of the possible tasks (unique combinations of the 12 components) were extensively practised prior to the experimental session. Cole et al. found that initial performance was better for the tasks introduced for the first time in the experimental session (which were made up of practised components combined in unique ways) relative to the tasks introduced for the first time during the training session (which were made up of unpractised components). That is, participants were able to transfer their prior experience with individual task components (e.g., the semantic classification “sweet”) to novel tasks that used the same components in unique combinations thereby expediting the early stages of learning (for a similar theory based on computational modelling, see Taatgen, 2013).
Finally, flexible behaviour need not necessarily rely on combining prelearned task components in novel ways. People can also learn about the task structure itself. For example, learning about the task has received some attention in the (hierarchical) reinforcement learning literature (as reviewed by Bhandari & Badre, 2018). In these studies, participants create a task schema, or internal task model, on the fly which can be adapted to fit novel tasks with a similar structure (for similar theories see, for example, Bhandari & Duncan, 2014; Braun et al., 2010; Collins & Frank, 2013; Schmidt et al., 2016; Verbruggen et al., 2014). For example, Bhandari and Badre found both positive and negative transfer of working memory (WM) gating policies (i.e., task strategies) across unique tasks where optimum performance relied on either efficiently updating the contents of WM or biasing attention towards particular items stored therein. That is, they found evidence that task strategies readily transferred to novel tasks that used unique stimuli, even if the strategies were not appropriate to the current context. More recently, Pereg et al. (2021) observed a systematic improvement in performance through a session consisting of multiple unique simple two-choice S-R learning tasks. Such an improvement in performance cannot easily be explained by transfer of learned associations, or compositionality, but can easily be explained by participants learning about the structure of the tasks themselves and applying the relevant (learning) strategy to other tasks with a common structure.
To summarise, learning can include structural information about groups of tasks where performance can be optimised by using a common (learning) strategy (e.g., Bhandari & Badre, 2018). Such information can be readily applied to unique tasks that share a common structure, thereby expediting learning (e.g., Pereg et al., 2021). Learning novel tasks can also be expedited by recombining the elements of practised task-sets into unique combinations (e.g., Cole et al., 2011). However, it is still not known whether structural representations can also be broken down into their constituent components, and whether these components can be recombined in novel ways to expedite learning novel tasks that share some common structural elements with the training tasks (e.g., the same kinds of stimuli, classifications, and/or responses), but none of the surface features (e.g., the specific stimuli, classifications, and/or responses). That is, the core aim of the present study was to determine whether strategic elements of practised tasks with a common structure could be combined in novel ways to expedite the early stages of learning a unique task via the rapid formation of a novel task schema based on components of an existing schema. And if so, which specific strategic elements (or combinations of elements) are most likely to transfer between tasks to expedite learning.
Experiment 1
Experiment 1 was an exploratory study designed as a first attempt to systematically investigate the architecture of a task schema by dividing a class of dot-pattern classification tasks (first introduced by Longman et al., 2018) into perceptual, categorization, and motoric components and providing groups of participants with training on all/some/none of those components before comparing their performance in equivalent dot-pattern classification tasks at test.
In the full schema training condition, participants performed three distinct dot-pattern classification tasks (each task used completely novel stimuli, categories, and responses) before completing a fourth dot-pattern classification task in the final test block. In a control training condition, participants had to indicate whether some simple mathematical formulae were true or false by making a left/right key press response (i.e., none of the test task elements could be practised during the training phase). Two other groups were able to gain experience with the motoric, and perceptual + motoric components of the test task. A final group (categorization + motoric) were given the opportunity to perform a different set of classification tasks but use the same kinds of motor responses as the test task. By comparing performance from the start (and end) of the test block (using response time [RT] and accuracy measures from the first/last 3 repetitions of each stimulus in a block) across the training groups we could determine which task elements directly contributed to subsequent performance/learning in a novel task, and whether any benefits observed in the early stages of learning were maintained after a short spell of practice.
Note that the control training tasks were designed to control for extraneous variables such as fatigue, and time engaged in a broadly similar experimental task prior to the test block. However, it could be argued that participants in this group might have benefitted from performing any task for a comparable duration to the participants from the other groups prior to the test phase (e.g., they might have become accustomed to being in the laboratory, concentrating on a simple task, or engaging with the same experimental context). For this reason, we also compared performance from Block 1 for the full schema training group (who performed a unique dot-pattern classification task without any prior experience of the experimental context) to test performance from each training group in each experiment. These alternative control performance data are plotted in the relevant figures, but their analysis is reported in the Supplementary Materials. The findings from the analyses suggest that the control training regime was, if anything, a conservative estimate of baseline performance given that performance was significantly worse in the alternative control relative to the control group in all experiments.
We predicted that the full schema training group would outperform the control training group in the early stages of the test task. Such a finding would provide direct evidence that experience with tasks that share a common structure with the test task can expedite learning via the application of an existing task schema (cf. Bhandari & Badre, 2018; Pereg et al., 2021).
The purpose of a task schema (learning strategy) is to aid in the formation of a useful task-set that can be applied to the current context. That is, task schemas are only active in Chein and Schneider’s (2012) formation stage of learning that has a duration in the order of seconds. We therefore predicted that any performance benefits associated with task schema transfer would be relatively short-lived (i.e., only detectable within the first few trials/stimulus repetitions of learning a novel task—the formation stage). If any performance differences remained reliable at the end of the test block (during the controlled execution stage), then the benefits might not be explained by transfer of task schemas alone.
Critically, we also predicted that the motoric, perceptual + motoric, and/or the categorization + motoric training groups would outperform the control training group in the early stages of the test block. Such a finding would indicate that a task schema can be divided into distinct components, each of which might expedite learning in a task that shares some structural elements with the training tasks (i.e., something akin to compositionality of structural task components; cf. Cole et al., 2011).
Method
Participants
The final sample included a total of 200 individuals (40 per training group) who were recruited via the University of Exeter participant pool. Demographic data for each group can be found in Table 1. Each participant was paid £4 or was awarded partial course credit for participating in a session that lasted around 30 min. N was set prior to testing (and was selected based on the design of Longman et al., 2018). A power analysis using G*Power (Faul et al., 2007) determined that, when N = 40 in each group, it was possible to detect medium-large sized differences (Cohen’s d = .78) with 80% power with an alpha of .005 (.05 Bonferroni corrected for 10 one-tailed comparisons). This experiment was approved by the local research ethics committee at the School of Psychology, University of Exeter. Written informed consent was obtained after the nature and possible consequences of the study were explained.
Demographic data for each training group in Experiment 1.
Apparatus, stimuli, and responses
Stimuli were presented on a 21.5-in. iMac using Psychtoolbox (Brainard, 1997). As shown in Figure 1 the stimuli used in the dot-pattern classification tasks of the full schema training condition and the test phases consisted of patterns of five black dots (diameter = 0.5 cm) presented at a pseudo-random location in a larger array (18 × 18) of small grey dots (diameter = 0.25 cm, distance between adjacent dots = 0.75 cm), which was itself surrounded by a black square (side = 15 cm, thickness = 2 ptu). Three of the black dots were positioned at locations within the category template and the remaining two were positioned at locations directly adjacent to the template. Thus, category membership of a given stimulus (eight per block, four per category) was determined by its overall similarity to the category templates (two per block, pseudo-randomly selected from a set of five pairs).
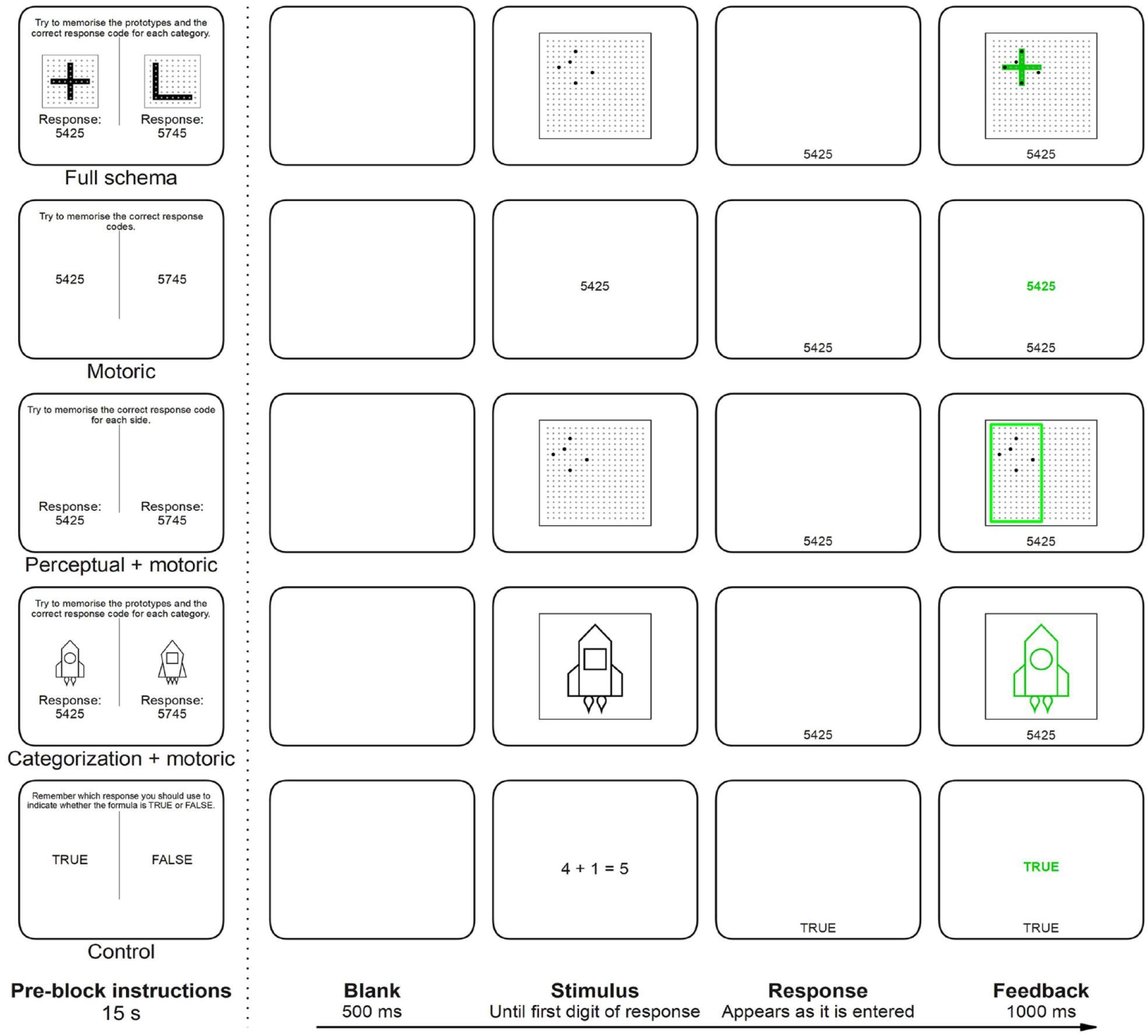
Pre-block instructions screen (left) and timeline of a single trial (right) for each training condition in Experiment 1.
The stimuli for the motoric training were the relevant response code (two per block, order randomised) presented centrally in black Arial font (size 30). The perceptual + motoric training tasks used the same stimuli as the dot-pattern classification tasks, but they were presented either to the far left or far right of the grid (pseudorandomised, with each stimulus appearing on either side of the grid equiprobably; vertical position was randomised).
The stimuli for the categorization + motoric training tasks were drawings of spaceships, aliens, or flowers (one category per block, order randomised) that could differ on four binary dimensions (Spaceship: shape of ship, shape of window, shape of wings, number of rockets; Alien: shape of antennae, number of eyes, number of fingers, shape/number of teeth; Flower: shape of head, diameter of centre, shape of leaves, shape of pot). All individual stimuli from these picture-classification tasks are deposited on the Open Science Framework data repository: https://osf.io/t9whg/. The two category templates used in each experimental block differed on all four dimensions and therefore had no critical features in common with each other. Each stimulus (eight in total, four per category) differed from the relevant template on one dimension (a different dimension for each stimulus, no single dimension was 100% predictive of category membership; for a similar category structure, see Medin et al., 1987) and was presented surrounded by a black square identical to the square surrounding the grid in the dot-pattern classification blocks. Like in the dot-pattern classification tasks, category membership of each stimulus in the picture-classification tasks was determined by overall similarity to the templates.
The stimuli for the control training condition were simple mathematical formulae (eight per block, four true, four false) presented centrally in a randomised order, in black Arial font (size 30).
On each trial in all conditions except for the control training blocks, the participant responded by entering a four-digit response code (two codes per block) with their right index finger (participants were asked to use their preferred hand, all chose to respond with their right hand) using the numeric keypad part of a standard keyboard. The response codes all started and ended with “5” and the intervening digits were always on adjacent keys to equate the difficulty of entering each code (e.g., 5235, 5425). The codes used to respond in each block were selected pseudo-randomly (from a set of eight pairs) to equate the difficulty of each task. In the control training blocks, the participant responded by pressing either the “F” or “J” keys on a standard keyboard with their left and right index fingers, respectively.
Procedure
The procedure for a single trial in each condition is presented in Figure 1. Each trial started with a blank screen displayed for 500 ms, after which the stimulus appeared. In all tasks that used four-digit responses, the stimulus remained visible until the participant entered the first digit in the response code. The response code then appeared at the bottom of the screen as it was typed in (black Arial font size 30). In the control training condition, which used single left/right key press responses, the stimulus remained visible until any response was made, and the given response (“TRUE” or “FALSE”) was displayed at the bottom of the screen for 200 ms (black Arial font size 30). In all conditions, immediate feedback was provided on every trial and was visible for 1,000 ms (see Figure 1).
The experiment consisted of four experimental blocks of 128 trials each divided into two mini-blocks of 64 trials, with a short break between mini-blocks. At the start of the session, participants were informed that the first three experimental blocks were an extended training phase and that the fourth and final experimental block was the test phase in which they would have to perform a dot-pattern classification task. All groups completed three unique tasks in the training phase (one task per block). For example, the full schema training group completed three dot-pattern classification tasks with unique stimuli, categories, and responses where the task was to indicate which of the two categories the displayed stimulus belonged by entering the relevant response code, whereas the motoric training group simply had to enter three unique pairs of response codes (see Figure 1). The test task was equivalent for all groups. Participants had to indicate which of two perceptual categories the displayed dot-pattern belonged to by entering the relevant response code. The stimuli, categories, and responses used in the test task were always unique. In all conditions, participants first received identical instructions regarding the dot-pattern classification task before receiving (condition-specific) instructions regarding the training phase. A reminder about the procedure of the dot-pattern classification task (printed in text, visible for 30 s) immediately preceded the pre-block instructions for the test phase. Prior to the start of each mini-block, an instruction screen displayed all relevant information necessary to perform the current task (see Figure 1). Each mini-block ended with a feedback screen displaying the mean RT and proportion of errors for that mini-block. The pre mini-block instructions and the feedback screen were both visible for 15 s.
Dependent variables and analyses
All data processing and analyses were performed using R (R Core Team, 2022). Bayes factors (BFs) were calculated using the BayesFactor package (Morey et al., 2022) and plots were drawn using ggplot2 (Wickham, 2022). All raw data files, R scripts, and the experiment scripts used for data collection from all experiments are deposited on the Open Science Framework data repository (https://osf.io/t9whg/).
In each training condition, trials with RT (first digit) < 100 ms (full schema = 0.08%, motoric = 0.08%, perceptual + motoric = 0.02%, categorization + motoric = 0.07%, control = 0.02%), and trials with RT (last digit) > 5,000 ms (full schema = 0.98%, motoric = 0.48%, perceptual + motoric = 0.49%, categorization + motoric = 2.35%, control = 0.57%) were omitted from all analyses. Error trials were also omitted from RT analyses. Any participants who had < 50% of the maximum possible observations in at least one mini-block following the above data cleaning procedures were replaced (full schema = 5; motoric = 3; perceptual + motoric = 2; categorization + motoric = 9; control = 2). The latency of the final digit in the response code (i.e., the time at which the full response had been entered) was used for all response latency analyses 1 (Longman et al., 2018). Performance from all stimuli in each block were pooled.
Two critical measures were used to compare test 2 performance between the five (training) groups. As noted above, we were especially interested in performance during the earliest stages of learning a new task. Our first measure, initial performance, therefore took the average performance during the first three repetitions of each stimulus in the test block. 3 Our second measure, final performance, took the average performance during the final three repetitions of each stimulus in the test block. This measure was used to determine the extent to which any differences between groups observed in initial performance were still observable at the end of the test block.
Because this was an exploratory experiment, the performance from each training group was compared with all other training groups. This strategy allowed us to systematically investigate the benefits of each training condition relative to the others. Thus, for each measure and dependent variable (RT and error rate), we performed a separate set of independent-samples t-tests. We applied separate Holm–Bonferroni corrections 4 for each set of comparisons. We also performed equivalent Bayesian analyses (using the default JZS prior of .707) and calculated effect sizes (Hedges’s g; Lakens, 2013). For all Bayesian analyses only the BF10 is reported (i.e., the BF for evidence in favour of the alternative hypothesis). BFs are interpreted according to the protocol outlined by Schönbrodt and Wagenmakers (2017): BF > 100 = extreme evidence for H1, BF 30–100 = very strong evidence for H1, BF 10–30 = strong evidence for H1, BF 3–10 = moderate evidence for H1, BF 1–3 = anecdotal evidence for H1, BF 1 = no evidence, BF 0.333–1 = anecdotal evidence for H0, BF 0.01–0.333 = moderate evidence for H0, BF 0.033–0.1 = strong evidence for H0, BF 0.001–0.033 = very strong evidence for H0, BF < 0.001 = extreme evidence for H0.
Results and discussion
Mean RTs and proportion of errors from the test block are plotted as a function of training group and stimulus repetition in Figure 2. Note that rolling means were used to visualise the data, but all analyses used only the data from the first and last points on the curves. For brevity, the results from all planned contrasts comparing test performance across the training groups are reported in the Supplementary Materials and only the main findings of interest are summarised here.
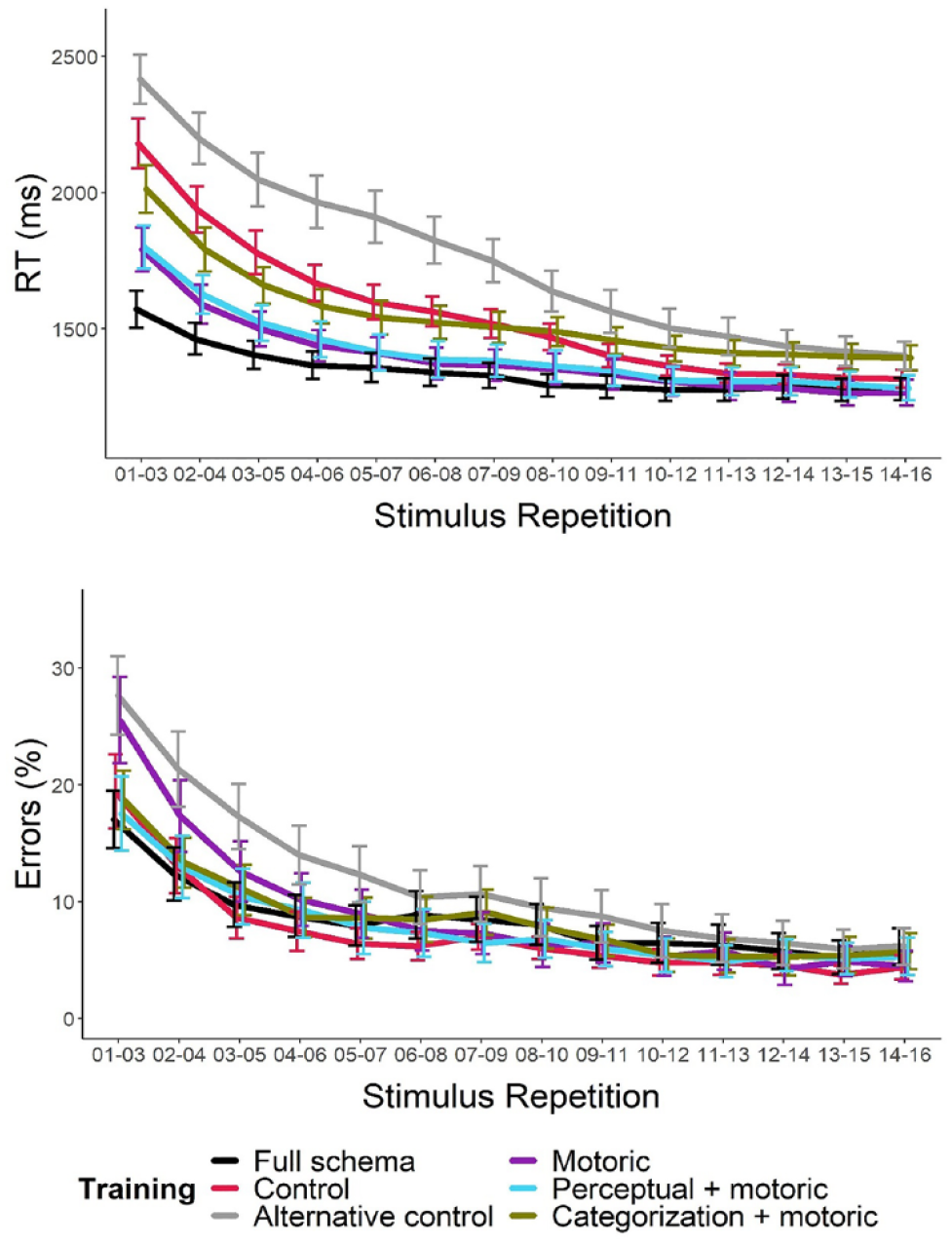
Mean RTs (left) and proportion of errors (right) from the test blocks of Experiment 1 plotted as a function of training condition and stimulus repetition.
Initial test RTs were significantly faster in the full schema group relative to all the other groups (ps ⩽ .012, BFs > 3.8) indicating that training with multiple dot-pattern classification tasks resulted in improved initial test performance relative to the other training conditions. Note that the t-test comparing initial test performance in the full schema and motoric training groups did not survive correction for multiple comparisons, but the Bayesian analysis (for which the Holm–Bonferroni procedure does not apply) found moderate evidence that initial RTs were faster in the full schema training group than in the motoric training group.
Initial RTs were significantly slower in the control training group relative to all other groups (ps < .001, BFs > 120) with the exception of the categorization + motoric group (p = .105, BF = 0.740), indicating that training with some/all task components improved test performance relative to a condition where the training was (largely) irrelevant to the test task. None of the remaining comparisons of initial RTs survived correction for multiple comparisons suggesting that practice with any subset of strategic task components relevant to the test task was broadly equivalent. That is, training with any of the strategic task components relevant to the test task improved initial RTs relative to the control but training with the full schema provided an additional benefit.
Note that all training groups gained experience with the motoric component of the test task. Importantly, the motoric training group, which only gained experience with this component, had similar initial test performance as the other groups which gained experience with a subset of the strategic task components relevant to the test task. This finding suggests that training with the motoric component of the test task was an important contributor to initial test performance in the present paradigm. However, training with the full schema still gave participants some advantage in initial test performance (note that the Bayesian analysis found moderate evidence that the full schema group outperformed the motoric group), suggesting that experience with other components also contributed to the improvement in initial test RTs for this training group.
None of the planned comparisons performed on the initial proportion of errors from the test block survived correction for multiple comparisons (ps ⩾ .020), indicating that response accuracy was largely unaffected by the differences in training between groups. Finally, none of the planned comparisons on the final performance measures survived correction for multiple comparisons for either RTs (ps ⩾ .019) or errors (ps ⩾ .246) indicating that any differences in the initial performance across the groups had largely been resolved by the end of the test blocks.
In summary, the results from Experiment 1 are consistent with the theory that transfer of task schemas can expedite the early stages of learning a new task that shares a common structure with the training tasks. Importantly, the present findings also support the notion that a task schema can be divided into distinct strategic task components, some of which can offer benefits to subsequent learning in a task that shares a subset of the structural task components practised in the training tasks. Although training with the full schema was associated with the largest benefits to subsequent performance, training with the motoric component was also an important contributor to initial RTs in the test task. However, the benefits of motoric training might be especially prevalent in the present design where the required response was a 4-digit code (we return to this issue in the “General discussion” section). Nonetheless, any performance benefits observed during the early stages of the test block were largely eliminated by the end of the block, suggesting that the benefits were rather short-lived. The latter conclusion is consistent with the notion that the early benefits to performance observed in the present experiment were due to task schema transfer, which expedited the formation of a stable task-set. Once the relevant task-set had been formed/implemented, the performance benefits of task schema transfer were largely eliminated.
Experiment 2
Experiment 1 was an initial exploratory investigation into the architecture of task schemas. Although the outcomes were informative to a degree, there remain several unanswered questions and possible optimisations of the design. The primary aim of Experiment 2 was to address these issues.
For example, some training conditions were not included in the design of Experiment 1. Although one group was able to gain experience of the motoric element of the test task (independently of the remaining structural components), no groups were given training with the perceptual or categorization elements independently of the remaining elements of the test task. An additional group in Experiment 1 gained experience with the perceptual and motoric elements of the test task, but no groups were trained with the perceptual and categorization elements, or with the same kinds of categorization task and responses used in the test task. Finally, the categorization + motoric training in Experiment 1 used a different kind of categorization task that did not allow participants to gain experience with classifying stimuli by comparison to a geometric perceptual category template like those used in the test task. Experiment 2 was designed primarily to address these omissions in the training groups included in Experiment 1. To this end, Experiment 2 included a total of eight training groups—perceptual, categorization, motoric, perceptual + categorization, perceptual + motoric, categorization + motoric, full schema, and control (see below for full details on each of these). The inclusion of the additional training groups allowed a fuller analysis of the benefits of training with single structural task components and all combinations of two-component training regimes relative to the full schema and control conditions (see “Analyses” section). The design also allowed for a full factorial analysis of the performance data from the test block as a function of whether the training included perceptual, categorization, and/or motoric components and a direct analysis of test performance as a function of the number of relevant components included in the training tasks.
The rationale for the duration of the training phase in Experiment 1 (three 128-trial blocks) was based on the observation that most of the performance benefits to be gained by transfer of task schemas observed by Longman et al. (2018) were found across the first three training blocks. However, theories of learning and automaticity (e.g., Chein & Schneider, 2012; Logan, 1988) suggest that, as new skills become more automatic, performance relies less on algorithmic processes (rules) and more on memory-based processes (associations)—that is, that expertise is context-specific, or that novice performance is more likely to transfer between tasks. Thus, one might suppose that a longer training phase with a broader range of training tasks, but a shorter training block for each task might enhance the effects of transfer. For this reason, the training phase in Experiment 2 was extended to include five 48-trial 5 blocks, each of which was associated with a unique task. It was predicted that this manipulation to the design would enhance the differences in test performance between groups, thereby allowing for more subtle differences to be measured.
Experiment 2 was run online because of restrictions associated with the COVID-19 pandemic. However, a benefit of doing so was that the population was not limited to the student population from a particular university and the sample was instead drawn from a much more diverse pool thereby improving the generalisability of the results.
Method
Participants
The final sample included a total of 640 individuals (80 per training group) who were recruited via “Prolific” (an online participant pool) and paid £3.15 for a 25-min session. The only criteria used to filter participants at this stage was that they identified as being fluent in English and were using a desktop or laptop computer with a numeric keypad on the right-hand side of the keyboard. Demographic data for each group can be found in Table 2. N was set prior to testing and was selected based on a compromise between increasing power relative to Experiment 1, and access to fair payment for participants. G*Power determined that, when N = 80 in each group, it was possible to detect medium-large sized differences (Cohen’s d = .56) with 80% power with an alpha of .004 (.05 Bonferroni corrected for the 13 one-tailed comparisons we chose a priori, see below). This experiment was approved by the local research ethics committee at the University of the West of Scotland. Participants indicated their informed consent by ticking a box on-screen after the nature and possible consequences of the study had been explained. All participants were debriefed on-screen at the end of the session.
Demographic data for each training group in Experiment 2.
Materials, design, and procedure
Experiment 2 was run online, so it was not possible to determine the precise hardware used by each participant. However, individuals could only participate by using a laptop or desktop computer with a numeric keypad on the right-hand side of the keyboard (not a smartphone or a tablet) connected to the internet. All tasks were coded using JavaScript (jsPsych; De Leeuw, 2015) and were hosted by Pavlovia.org. The stimuli, responses, and general structure of the session were based on those used in Experiment 1, but there were several important differences. The session consisted of six blocks of 48 trials each (4 stimuli from each category were presented 6 times each per block). Participants were informed that the first five blocks were the training phase, and the final block was the test phase. Participants from all conditions first received identical instructions regarding the test task before receiving (condition-specific) instructions regarding the training phase. A reminder about the procedure of the dot-pattern classification task (printed in text, visible for 60 s) immediately preceded the pre-block instructions for the test phase. A unique task was performed in each block throughout the entire session. The nature of the tasks performed during the training phase depended on the group, but all participants performed a unique dot-pattern classification task at test similar to those performed in the full schema training blocks (see Figure 3).
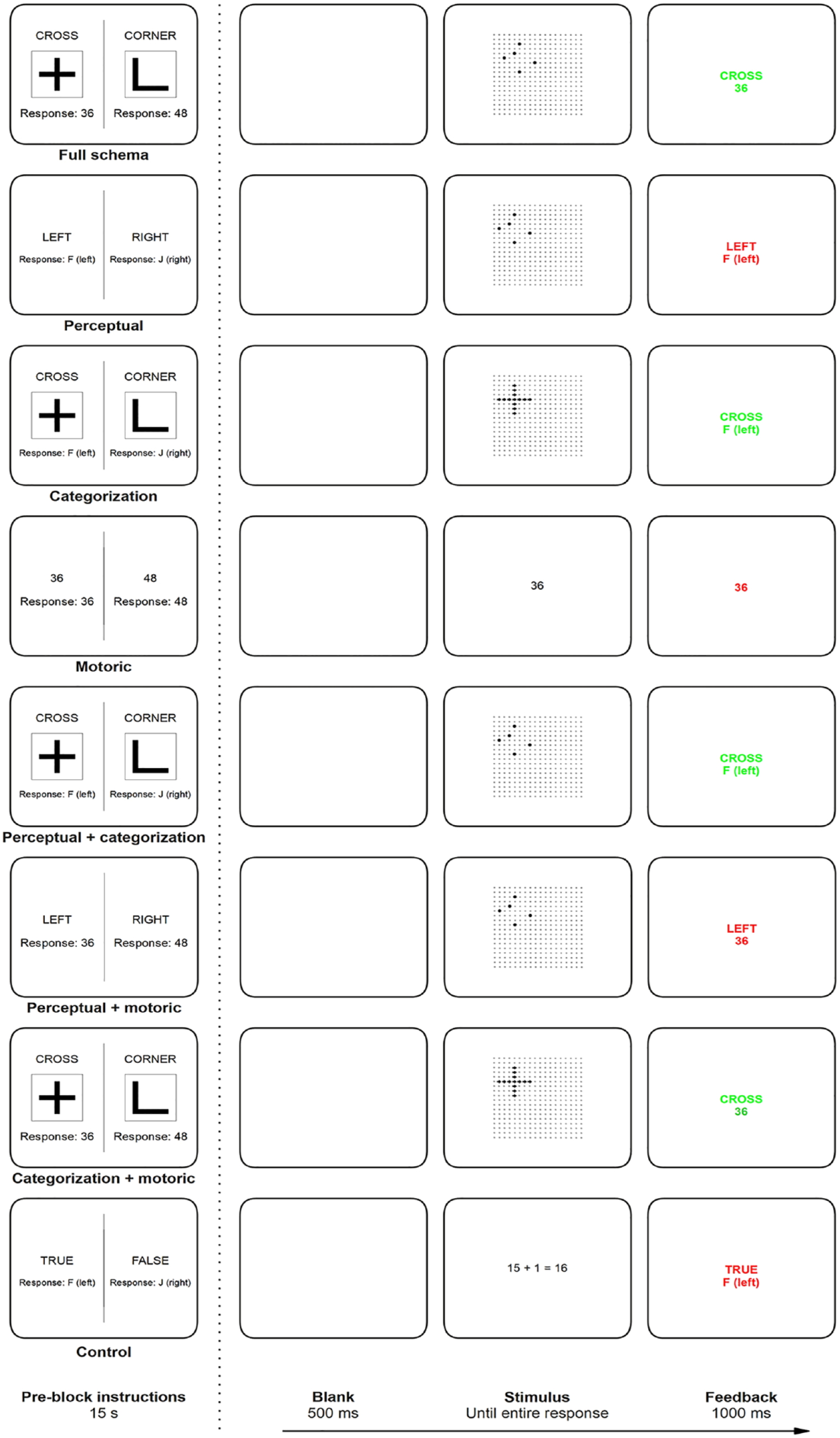
Pre-block instructions screen (left) and timeline of a single trial (right) for each training condition in Experiment 2.
As shown in Figure 3, the stimuli used in the dot-pattern classification tasks of the full schema and the perceptual + categorization training tasks as well as the test phase for each group were identical to those used in the test phase of Experiment 1. As in Experiment 1, the perceptual + motoric training tasks used the same stimuli as the dot-pattern classification tasks, but they were presented to the far left or far right of the grid (pseudorandomised, with each stimulus appearing on either side of the grid equiprobably; vertical position was randomised). The same stimuli were also used in the present perceptual training tasks. The stimuli for the categorization and categorization + motoric training tasks were the relevant category templates drawn at a random location in the grid using arrows pointing up, down, left, or right (equivalent size to the black dots used in the dot-pattern classification tasks). In these conditions, the participants could therefore learn to identify the relevant category by comparing the stimulus with an internal representation of the category template but could not gain experience of comparing the templates to the dot-pattern stimuli used in the test task. That is, they could learn about the kinds of categories, but not the kinds of stimuli used in the test task. The use of arrows instead of dots for these stimuli meant that each category could include four unique exemplars, but the differences between them would be minimal, thereby encouraging participants to simply identify the category template, rather than having to identify the category to which the distorted stimulus belonged. As in Experiment 1, the stimuli for the motoric training tasks were the relevant response code (two per block), and the stimuli for the control training tasks were simple mathematical formulae (eight per block, four true, four false). Both of the latter were presented centrally in a randomised order in black Arial font.
On each trial in the motoric, perceptual + motoric, categorization + motoric, and full schema training blocks as well as in the test tasks for all groups, participants were asked to respond by entering a two-digit response code equivalent to the four-digit response codes used in Experiment 1 with the first and last digits (5) omitted from the code. Participants were asked to respond using only one finger from their right hand (the instructions suggested the index finger but emphasised the importance of using only one finger to make each response) using the numeric keypad part of a standard keyboard. Although none of the codes included the number 5, participants were encouraged to start each trial with their finger in this central position on the numeric keypad. The codes used to respond in each block were selected pseudo-randomly (from a set of 8 pairs) to equate the difficulty of each task. Note that the coding of the experiment meant that it was not possible for participants to respond using the number keys along the top of the keyboard. This precaution was introduced to ensure that all participants used the numeric keypad to enter the response codes. In the remaining training blocks, the participant responded by pressing either the “F” or “J” keys on a standard keyboard with their left and right index fingers, respectively.
Otherwise, the procedure for Experiment 2 was identical to that for Experiment 1 with two additional exceptions. First, the response code did not appear on the screen as it was typed in by the participants. Instead, the stimulus remained visible until the entire response code was entered. As in Experiment 1, immediate feedback was then displayed for 1,000 ms. Second, on trials where the stimulus was presented within a grid of small grey dots, this grid was not surrounded by a black square.
Analyses
In each training condition, trials with RT (first digit) < 100 ms (full schema < 0.01%, perceptual = 0.02%, categorization < 0.01%, motoric = 0.02%, perceptual + categorization < 0.01%, perceptual + motoric = 0.01%, categorization + motoric = 0.00%, control < 0.01%) and trials with RT (last digit) > 3,000 ms (full schema = 2.05%, perceptual = 0.63%, categorization = 0.72%, motoric = 0.55%, perceptual + categorization = 0.79%, perceptual + motoric = 1.00%, categorization + motoric = 1.25%, control = 1.33%) were omitted from all analyses. Error trials were also omitted from RT analyses. Any participants who had < 50% of the maximum possible observations in at least one block following the above data cleaning procedures were replaced (full schema = 9, perceptual = 8, categorization = 2, motoric = 3, perceptual + categorization = 5, perceptual + motoric = 5, categorization + motoric = 5, control = 10). (Note that participants were informed that they would not be eligible for payment if they achieved less than 75% accuracy in any single block, and that responses slower than 3,000 ms would be counted as errors in this calculation).
The same two critical measures used in Experiment 1 were used again in Experiment 2. However, because Experiment 2 had a full factorial design, it was possible to conduct several analyses in addition to the planned contrasts comparing test performance between training conditions. First, to determine whether training with the perceptual, categorization, and/or motoric components of the test task independently contributed to test performance, we ran a separate Perceptual (component was present/absent from training) by Categorization (component was present/absent from training) by Motoric (component was present/absent from training) between-subjects ANOVA on each dependent variable for each measure. BFs and effect sizes (generalised eta squared) were also calculated for all relevant effects/interactions. BFs were calculated with the BayesFactor package, using the default JZS prior (.707; Morey et al., 2022). To reduce the number of model comparisons, a subtraction approach was used (see Morey et al., 2022). That is, the full model including all effects and interactions was compared with the full model minus the effect or interaction of interest. When this approach is used, BFs < 1 indicate that removing the effect/interaction reduces the fit of the model (i.e., it is a contributor to the fit of the full model). Conversely, when the BF remains > 1, removing the effect/interaction did not affect the fit of the model (i.e., it is not a contributor to the fit of the model). As in Experiment 1, for all Bayesian analyses, only the BF10 is reported (i.e., the BF in favour of the alternative hypothesis), and they are interpreted using the classification introduced by Schönbrodt and Wagenmakers (2017).
Second, to determine whether test performance improved as a function of the number of trained components, we ran a separate linear regression for each measure and dependent variable with Number of Components (0–3) as the predictor variable. BFs were calculated for these analyses with the BayesFactor package using the default JZS prior. Significant regression models would therefore indicate that increasing the number of strategic task components relevant to the test task included in the training tasks systematically affected test performance.
For the planned comparisons, instead of comparing performance from each training condition with all other conditions (as in Experiment 1), to reduce the number of comparisons, we limited analyses to comparisons between the full schema and control training groups to all other groups. Comparison of test performance in the control training group to the other groups made it possible to determine the extent to which training with any of the components relevant to the test task improved test performance relative to a condition in which the training was theoretically irrelevant to performing the test task. Comparison of test performance in the full schema training group to the other groups made it possible to determine the extent to which training with a subset of components relevant to the test task improved test performance relative to training with all components relevant to the test task.
Finally, to partition the cognitive processes involved in test performance into separable components, we fit the RT data from the test block to a Drift Diffusion Model 6 (DDM; Ratcliff, 1978) using the DstarM R package (van den Bergh et al., 2019). DDMs assume that participants performing binary decision tasks accumulate evidence until a response threshold is reached and can distinguish between four distinct parameters. Non-decision time (t0) reflects the time taken to complete low-level perceptual and/or motoric processes that are not involved in selecting an appropriate response. Boundary separation (a) can be considered a measure of the amount of information required to make a decision and is akin to a measure of participant cautiousness with regard to the task. A larger value in this parameter can be interpreted as indicating a more cautious approach to response selection (i.e., one resulting from the acquisition of more evidence before a decision is made). The starting point (z) is usually halfway between the upper and lower boundaries (in the present study, these represent a correct or incorrect response, respectively), but can also vary reflecting a degree of bias towards one response over the other. A larger value in this parameter would suggest some initial bias towards a correct response over an incorrect response. Finally, the drift rate (v) indicates the rate at which evidence is gathered and can be interpreted as reflecting processing efficiency. A larger value in this parameter indicates more efficient evidence accumulation towards a response decision.
We fit the RT data from all valid test block trials (see data cleaning procedure above) to a DDM separately for each participant. Note that RTs from trials where a correct or an incorrect response was made were included in the DDM analysis. This strategy provides an overview of performance that is not limited to one measure or the other and instead looks at the balance between speed versus accuracy—an essential element of learning a novel task. In an attempt to reduce noise, we included all of the data from each test block rather than having distinct initial and final performance measures. There were no constraints set on any of the parameters. DstarM generated a value for each parameter based on test performance for every participant. The resulting data were submitted to equivalent ANOVAs and regressions to those performed on the RT and error data using the same methods reported above.
Results and discussion
Mean RTs and proportion of errors from the test block are plotted as a function of training group and stimulus repetition in Figure 4.
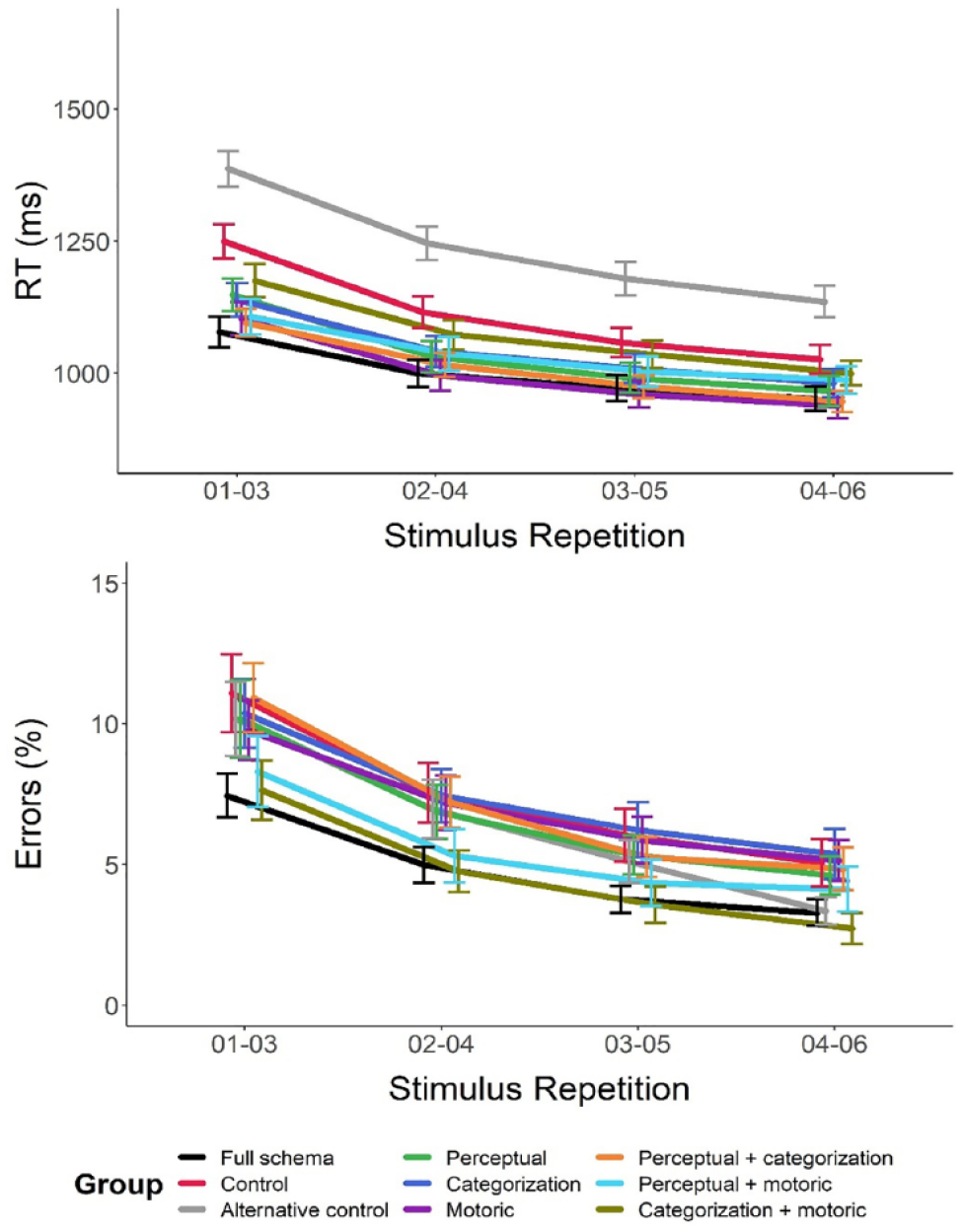
Mean RTs (top) and proportion of errors (bottom) from the test block of Experiment 2 plotted as a function of training group and stimulus repetition.
Omnibus analyses
The results from the between-subjects ANOVAs are reported in Table 3.
ANOVA results from Experiment 2. Equivalent Bayes factors are also reported.
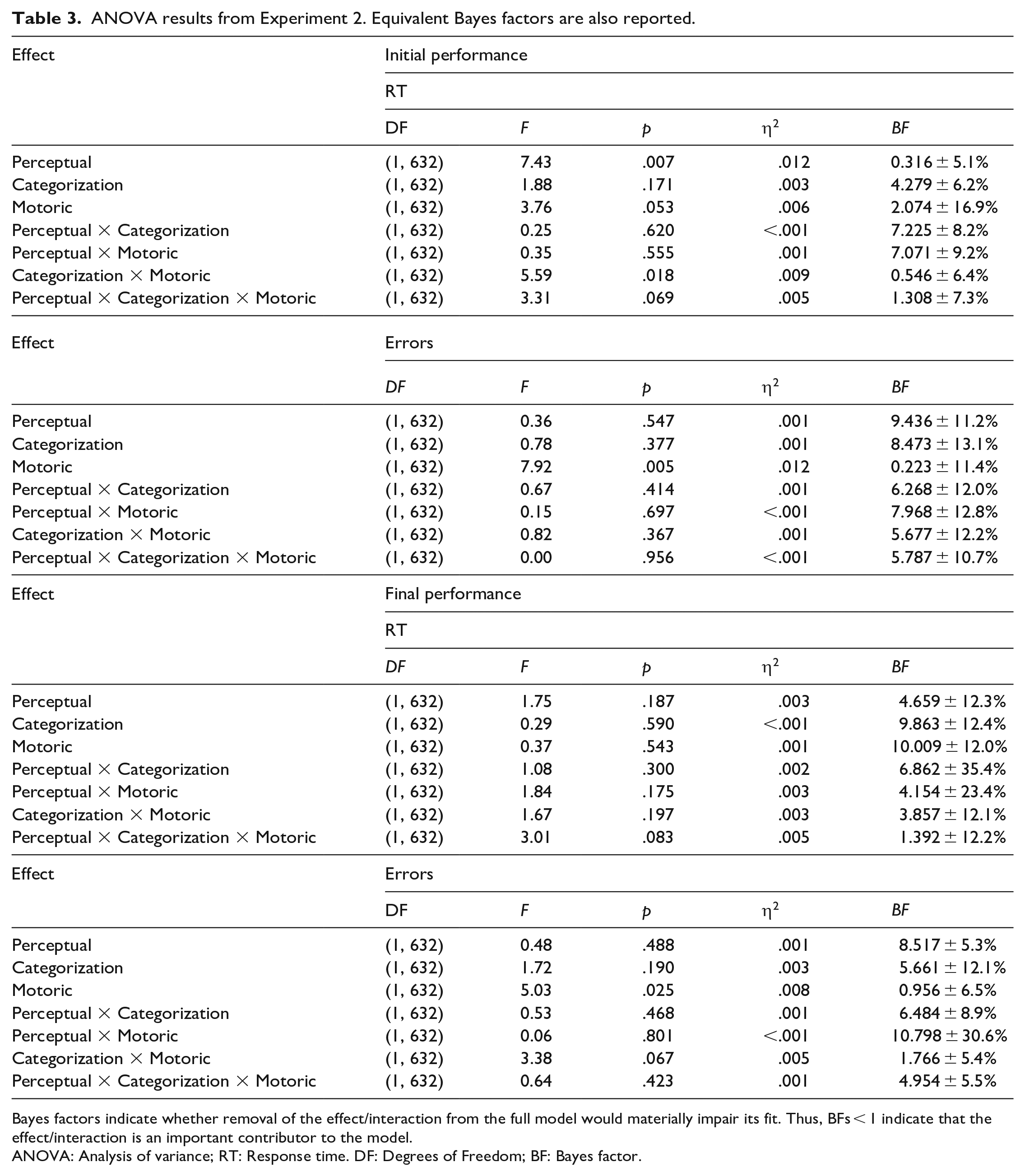
Bayes factors indicate whether removal of the effect/interaction from the full model would materially impair its fit. Thus, BFs < 1 indicate that the effect/interaction is an important contributor to the model.
ANOVA: Analysis of variance; RT: Response time. DF: Degrees of Freedom; BF: Bayes factor.
The ANOVA on initial RTs found that participants responded faster to the first three repetitions of each stimulus in the test block when the training included the same kinds of stimuli as the test task (mean RT = 1,107 ± 15 ms) relative to when the training did not (mean RT = 1,166 ± 16; main effect of Perceptual component: p = .007, BF = 0.316 ± 5.1%). Although there was a small benefit to initial RTs resulting from training with the kinds of category templates (mean RT when the training included the same kinds of category templates = 1,122 ± 15 ms; different category templates = 1,152 ± 16 ms) and the kinds of responses (mean RT when the training included the same kinds of responses = 1,116 ± 16 ms; different responses = 1,158 ± 15 ms) used in the test task, neither of these differences reached significance (main effect of Categorization: p = .171, BF = 4.279 ± 6.2%; main effect of Motoric component: p = .053, BF = 2.074 ± 16.9%). However, the Categorization by Motoric components interaction was significant (p = .018, BF = 0.564 ± 6.4%), indicating that including the motoric component in the training regime was beneficial to test RTs when the training did not include the categorization component (mean difference = 144 ms). Whereas, when the training did include the categorization component, the benefit of including the motoric component was eliminated (mean difference = −9 ms).
None of the other effects or interactions from the ANOVA on initial RTs were significant (all ps > .06, all BFs > 1.3). None of the effects or interactions from the ANOVA on final RTs were significant (all ps > .08, all BFs > 1.3), indicating that any RT benefits of training were quite short-lived and had been resolved by the end of the test block.
The ANOVA on the initial proportion of errors found that participants made fewer errors during the first three repetitions of each stimulus in the test block when the training included the same kinds of responses used in the test block (mean errors = 8.3 ± 0.5%) relative to when the training did not (mean errors = 10.6 ± 0.7%; main effect of Motoric component: p = .005, BF = 0.223 ± 11.4%). 7 The ANOVA on the final proportion of errors found that this difference remained significant at the end of the test block (mean errors when the training included the same motoric component as the test task = 3.8 ± 0.3%; when the motoric component was different = 5.0 ± 0.4%; p = .025, BF = 0.956 ± 6.5%), indicating that the benefits of training with the motoric component of the test task had a degree of longevity. None of the other effects or interactions was significant in either ANOVA on response accuracy (initial errors: all ps > .3, all BFs > 5.6, final errors: all ps > .06, all BFs > 1.7).
The results from the regressions investigating the effect of number of relevant strategic task components included in the training tasks on test performance are reported in Table 4.
Regression results from Experiment 2. Equivalent Bayes factors are also reported.
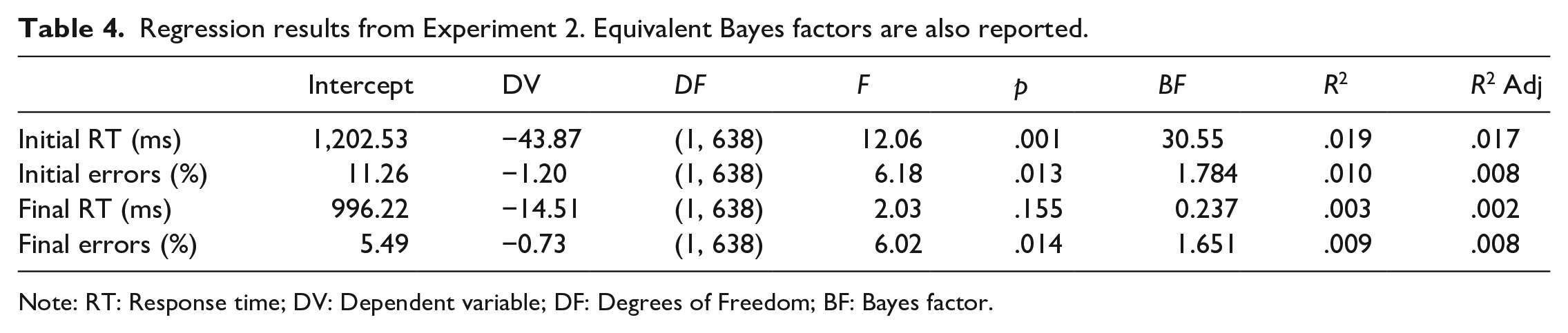
Note: RT: Response time; DV: Dependent variable; DF: Degrees of Freedom; BF: Bayes factor.
A significant regression equation was found for initial RTs (p = .001, BF = 30.55), indicating that participants’ initial test RTs were 44 ms faster for each additional component included in the training. The regression on the final RTs was not significant, suggesting that any benefits found at the start of the test block had been resolved by the end of the block.
A significant regression equation was found for initial errors and final errors (initial errors: p = .013, final errors: p = .014), suggesting some improvement in test response accuracy with each additional component included in the training. However, the Bayesian analyses found only anecdotal evidence in support of both models (initial errors: BF = 1.8, final errors BF = 1.7), suggesting that any effect of number of components on test accuracy was inconsistent at best.
Planned contrasts
The results from all planned contrasts comparing test performance across the training groups are reported in Table 5. For brevity, only the main findings of interest are summarised here.
T-test results comparing test performance between training groups from Experiment 2. Equivalent Bayes factors are also reported.
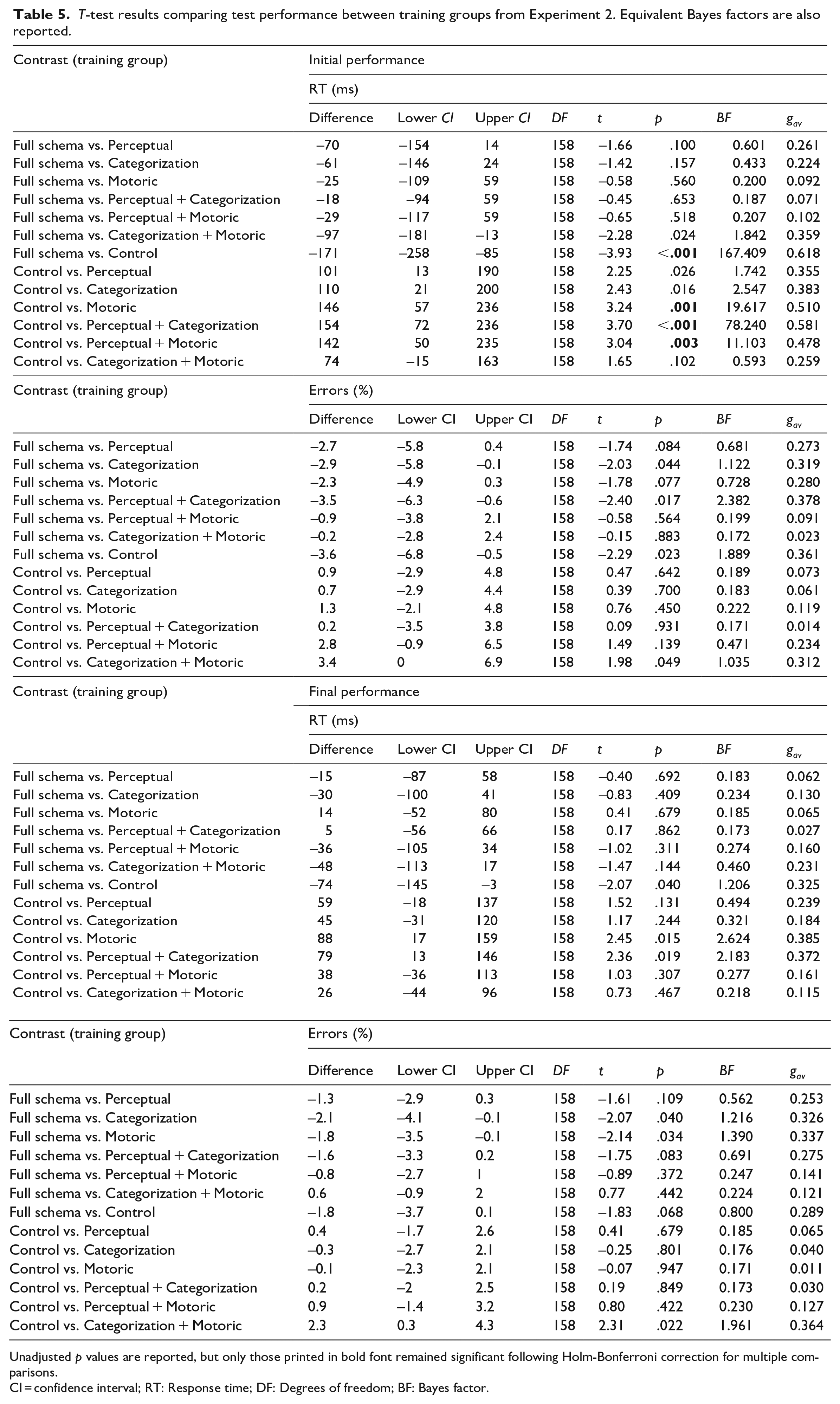
Unadjusted p values are reported, but only those printed in bold font remained significant following Holm-Bonferroni correction for multiple comparisons.
CI = confidence interval; RT: Response time; DF: Degrees of freedom; BF: Bayes factor.
Initial test RTs were significantly faster in the full schema group relative to the control group (p < .001, BF = 167.409), indicating that training with all structural components relevant to the test task resulted in improved initial test performance relative to training with none of the relevant structural components of the test task. None of the other comparisons to the full schema group’s initial RTs reached significance or survived correction for multiple comparisons. Taken together, these results suggest that, although training with the full schema expedited learning of the test task relative to the control, training with any of the structural task components relevant to the test task appeared to result in broadly equivalent benefits to initial test RTs. Nonetheless, it is important to compare performance from the active training groups with performance from the control group before drawing any strong conclusions regarding the benefits of training with a subset of strategic task components.
Initial RTs were significantly slower in the control condition relative to the motoric, perceptual + categorization, and perceptual + motoric groups (ps < .004, BFs > 11). Thus, in the present experiment, the training associated with the clearest RT benefits in the test task were the full schema, motoric, perceptual + categorization, and perceptual + motoric groups. That is, the greatest benefits to initial test RTs relative to the control condition were found when the training included practice with the full schema, only the kinds of responses, the kinds of stimuli and responses (presumably in part due to the benefits associated with practicing the motoric component), or the kinds of stimuli and categories used in the test task. The latter finding is especially noteworthy given that it suggests a benefit to test performance associated with performing the same kinds of dot-pattern classification tasks independently of training with the kinds of responses used at test.
None of the planned comparisons performed on the initial proportion of errors from the test block survived correction for multiple comparisons. Nor did any of the planned comparisons on the final performance measure for either RTs or errors. The latter findings indicate that any performance differences between groups at the start of the test block had largely been resolved by the end of the test block, suggesting that the benefits to initial test performance could be explained by task schema transfer and the benefits did not continue to expedite learning once the relevant task-set had been implemented.
DDM
The results from the ANOVAs on each of the parameters from the DDM are reported in Table 6.
ANOVA results for drift diffusion model parameters from Experiment 2. Equivalent Bayes factors are also reported.
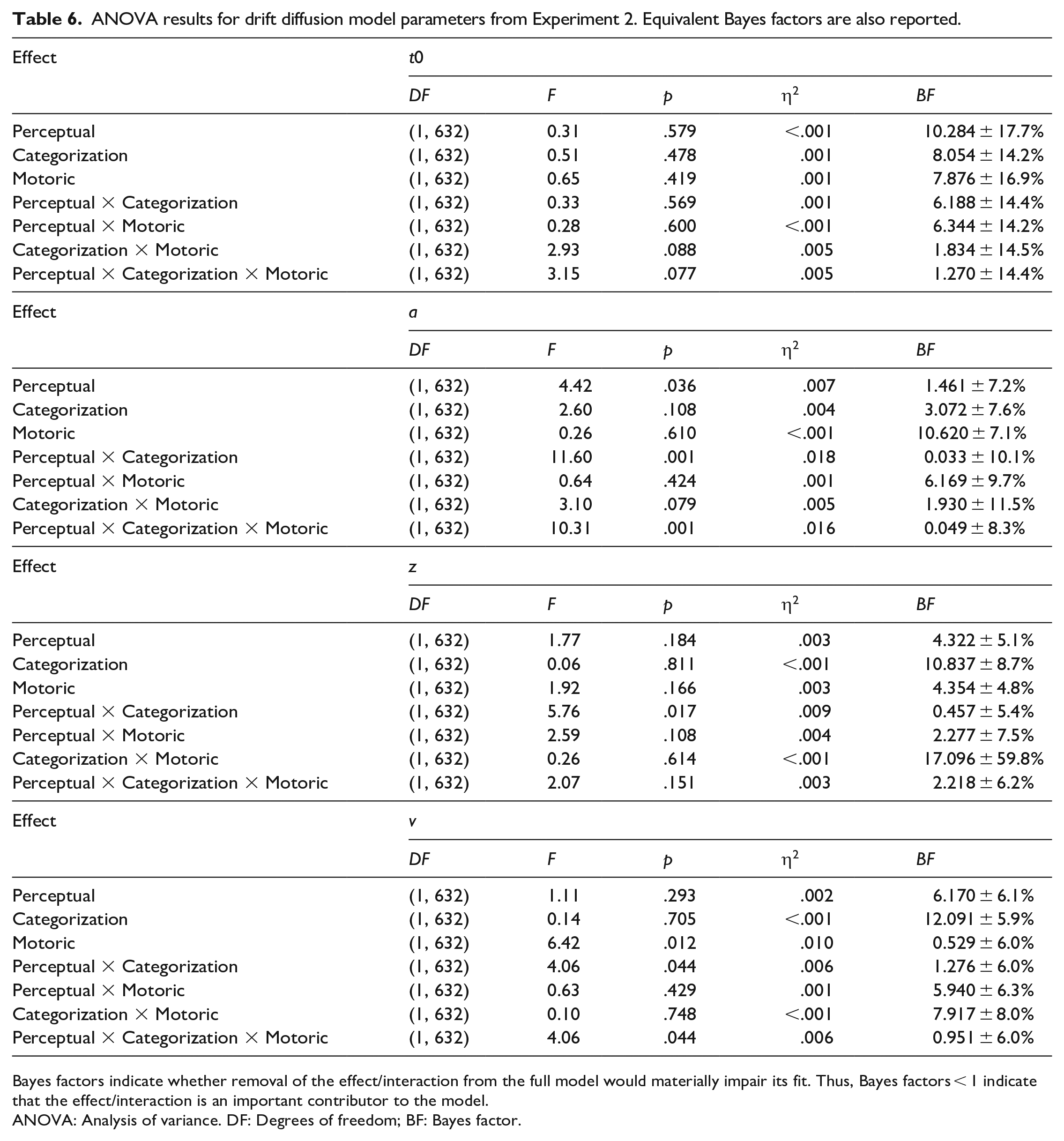
Bayes factors indicate whether removal of the effect/interaction from the full model would materially impair its fit. Thus, Bayes factors < 1 indicate that the effect/interaction is an important contributor to the model.
ANOVA: Analysis of variance. DF: Degrees of freedom; BF: Bayes factor.
None of the effects or interactions from the ANOVA on the t0 parameter reached significance (all ps > .07, BFs > 1.2) indicating that non-decision processes in the test task were broadly equivalent across all training groups.
The ANOVA on parameter a found a main effect of Perceptual training (p = .036) suggesting that those groups who gained some experience with the perceptual component during training (M = 1.68) were less cautious than those who did not (M = 1.73). However, the Bayesian analysis found anecdotal evidence that removal of this effect from the model would not materially impair its fit (BF = 1.461 ± 7.2%) suggesting that this effect should be interpreted with caution. Nonetheless, those participants who experienced training with both the perceptual and categorization components (M = 1.62) were less cautious than participants who experienced neither the perceptual not categorization components (M = 1.71), only the perceptual but not the categorization component (M = 1.74), or only the categorization but not the perceptual component (M = 1.75; Perceptual by Categorization interaction: p = .001, BF = 0.033 ± 10.1%). The three-way interaction was also significant for parameter a (p = .001, BF = 0.049 ± 8.3%) indicating that the Perceptual by Categorization interaction was largely limited to those groups who also experienced training with the motoric component (mean values from smallest to largest: Full schema = 1.62, Motoric = 1.65, Perceptual + Motoric = 1.77, Categorization + Motoric = 1.80). Such an interaction was not present for the groups who did not experience training with the motoric component (mean values from smallest to largest: Perceptual + Categorisation = 1.62, Categorization = 1.70, Perceptual = 1.71, Control = 1.77).
The ANOVA on parameter z also found a significant Perceptual by Categorization interaction (p = .017, BF = 0.457 ± 5.4%). Specifically, those participants who experienced training with both the perceptual and categorization components (M = 0.63) started the trials with a larger bias towards a correct response than participants who experienced neither the perceptual not categorization components (M = 0.60), only the perceptual but not the categorization component (M = 0.58), or only the categorization but not the perceptual component (M = 0.54). Taken together with the results from the ANOVA on parameter a, this would suggest that training with both the perceptual and categorization components together produced the optimum conditions for rapidly learning the test tasks.
Finally, the ANOVA on parameter v found that participants processed the information more efficiently when their training did not include the motoric component (M = 0.59) relative to when it did (M = −0.09; main effect of Motoric training: p = .012, BF = 0.529 ± 6.0%). The Perceptual by Categorization interaction was also significant for this component (p = .044) indicating the most efficient processing of information in groups where the training included both perceptual and categorization components (M = 0.72) relative to when the training included neither component (M = 0.33), only the perceptual but not the categorization component (M = 0.07), or only the categorization but not the perceptual component (M = −0.11), However, the Bayesian analysis found anecdotal evidence that removal of the interaction would not materially impair the fit of the model (BF = 1.276 ± 6.0%) suggesting some degree of caution when interpreting this result .
To summarise, the findings from the ANOVA on the DDM parameters suggest that non-decision time was largely unaffected by the differences in training between groups. This is especially noteworthy given that non-decision time is typically thought to represent low-level perceptual/motoric processes (van den Bergh et al., 2019), so one might expect to see some effect of perceptual and/or motoric training on this parameter. Nonetheless, as in the other analyses reported above, there was some evidence that training that included both the perceptual and categorization components, or just the motoric component alone was especially effective in reducing cautiousness (parameter a) and the speed at which information was accumulated (parameter v). This pattern of results seems to suggest that training with the motoric component of the test task did not reduce non-decision time but did improve the two processes associated with cautiousness (parameter a) and efficiency in decision-making (parameter v). We return to this point in the “General discussion” section.
The results from the regressions investigating the effect of number of relevant training components on each of the parameters from the DDM are reported in Table 7. None of the parameters from the DDM was significantly affected by the number of components included in the training suggesting no systematic effect of increasing the number of trained components on any of the DDM parameters.
Regression results for drift diffusion model parameters from Experiment 2. Equivalent Bayes factors are also reported.
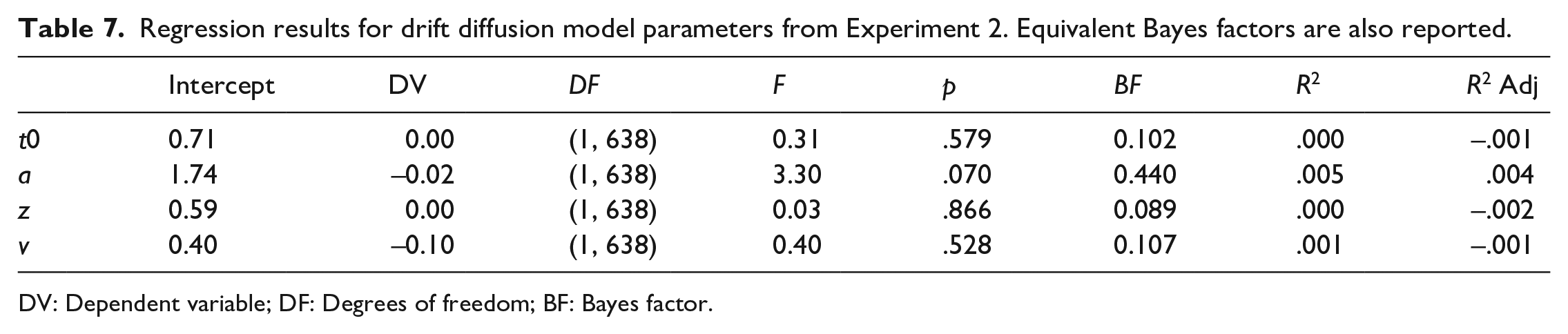
DV: Dependent variable; DF: Degrees of freedom; BF: Bayes factor.
General discussion
The central aim of the present study was to further investigate the architecture of task schemas—learning strategies that can be applied to the early stages of engaging with a novel task. Two learning experiments were conducted to determine whether task schemas can be divided into separable components, each of which can be used to expedite learning a novel task that shares some of the structural components with the training task(s). To this end, different groups of participants received training with several unique tasks that included some/all/none of the structural components (the same kinds of stimuli, categories and/or responses), but none of the surface features (the specific stimuli, categories and/or responses) found in the test task (a dot-pattern classification task). The results from both experiments indicated that task schema transfer was observable to a degree in all training conditions relative to the control group and that initial test performance improved as a function of the number of relevant components included in the training tasks. However, it was also clear that some components made a larger contribution to initial test performance than others (e.g., the motoric component alone, and the combination of perceptual and categorization components together). That is, the reported experiments found evidence that task schemas are componential and that practised strategic task components can expedite learning novel tasks that share some of the structural elements represented in the schema.
Training with the motoric component of the schema was especially effective in the present experiments. One possible explanation for this could be in the extent to which the participants had made similar responses before. It is not clear whether the same pattern of results would have been observed with a more practised (or simpler) motoric component such as a single key press. For example, the motoric aspects of driving a car are complex, but once they have been learned they can likely be applied to other similar contexts such as driving a bus, thereby expediting learning. Nonetheless, it is noteworthy that a substantial portion of the benefits to be gained by task schema transfer in the present experiments can be explained by a single (motoric) component of the schema. Future research would benefit from establishing the extent to which this was a specific feature of the present paradigm. However, the findings from Bhandari and Badre (2018), and Pereg et al. (2021), suggest that the benefits associated with task schema transfer are not limited to only the motoric component of the schema but can also be found in other components (e.g., the combination of perceptual and categorization training was also an important contributor to test performance in the present study; see below). Note that the required response in their experiments was a single key press that presumably did not require any additional practice, but they still found evidence of transfer of relevant strategies across unique tasks with a common structure. Nonetheless, as with the present study, it is possible that a subset of the task schema components relevant to their tasks were especially important in improving performance, and that more directed training on those components alone would have also resulted in a similar pattern of results.
Similarly, in the present Experiment 2, there was evidence that learning about the perceptual and categorization components together (without the motoric component) readily transferred to the test task. A useful strategy in the present experiments might be to generate an internal representation of the category template from the pre-block instructions, and then superimpose that representation over the dot-patterns presented on each trial to determine their category membership. Such a strategy would be useful in the test task whatever action was required to indicate the relevant category. Note that training with a different kind of categorization task in the present Experiment 1 did not appear to improve participants’ ability to perform the dot-pattern classification task at test (if anything, it seemed to hinder test performance). The latter observation is also consistent with the notion that training with task-specific strategic components can readily be applied to novel tasks with a common structure, but training with an irrelevant (or detrimental) strategy cannot (cf. Bhandari & Badre, 2018). As with the motoric component, further research would benefit from determining the extent to which this pattern of results was due to the features of the present test task where optimal performance relied on the ability to identify the category to which a dot-pattern stimulus belonged. Different test tasks might benefit from different training regimes depending on which components of the task schema were most useful in guiding performance.
The results from the DDM analyses seem to suggest that training with the perceptual and motoric components of the test task did not affect non-decision time (typically thought to reflect low-level perceptual/motoric processes), but did affect participant cautiousness and the rate at which information relevant to the decision was accumulated. This would imply that, at least in the current experiments, training of low-level processes did not affect the efficiency of these processes directly. Rather, training that included the perceptual and/or motoric strategic components of the test task appeared to affect task performance. This is consistent with the notion that participants were learning about the structure of the tasks and were able to apply that knowledge by rapidly developing novel learning strategies based on their prior experience. After all, the training did not include the specific stimuli/actions used in the test task but included only the kinds of stimuli/actions used at test. It is possible that training with specific stimuli and/or responses would have affected non-decision time if those same stimuli/responses were used at test by allowing participants to practice the specific perceptual and/or motor processes used in the test task, thereby reducing non-decision time. Because novel tasks (with novel stimuli, categories, and responses) were introduced at test, non-decision time was not reduced by the training that was only able to support the learning of a new action rather than the application of a practised action.
Training was effective to a degree in all groups at least in terms of response speed, despite the introduction of a task with altogether novel surface features at test. (Response accuracy at test was largely comparable across all groups and was typically quite high making it a less sensitive measure of the differences in performance between groups.) There was also evidence that training with multiple strategic task components was more effective than training with fewer components, suggesting an additive effect. The performance benefits associated with each training regime cannot be explained by familiarity with specific stimuli, categories, responses, or combinations of these. Conversely, this pattern of results can easily be explained by the transfer of a task schema representing some/all of the critical strategic task elements (e.g., motoric, perceptual, and/or cognitive control routines that are not bound to specific actions, percepts, or S-R bindings). Note that this view is also mirrored by the broad consensus in the transfer literature that (more abstract) conceptual relations readily transfer to contexts that share an underlying structure (schema), but which differ on their surface features (e.g., Day & Goldstone, 2012).
These observations suggest that generating a task schema can accelerate acquisition of a novel task with a similar structure to the tasks practised during training. Presumably, during the initial stages of the test phase, participants create a new task schema based on the instructions that they can use to formulate a new task-set over the course of the first few trials of the test block. This process may require a few trials of practice to stabilise (cf. Bhandari & Duncan, 2014; Brass et al., 2017), or transition from relying on the task (the formulation of a learning strategy) to relying on a more stable task-set (i.e., transitioning from Chein & Schneider, 2012, formation stage to their controlled execution stage). However, the evidence presented here is consistent with the notion that this process can be expedited by reusing parts of a recent task schema that shares some/all strategic components with the current task, even if the surface features of the task are novel and unique. The present work therefore extends Cole et al.’s (2010, 2011) theory of compositionality to include the recombining of strategic task components as well as specific task components. As noted above, the specific components that are most effective in improving test performance for a given task are likely determined by the features of the particular paradigm or test task.
For example, Pereg et al. (2021) observed transfer akin to that reported in the present work across multiple relatively simple two-choice reaction time tasks. Whereas Bhandari and Badre (2018) demonstrated the learning and transfer of relatively sophisticated control routines (WM input and output gating policies). In the present study, we examined control routines involved in relatively low-level (motoric/perceptual) mechanisms as well as more sophisticated (categorization) mechanisms and found evidence of both. Critically, the present experiments extend the findings of Pereg et al., and Bhandari and Badre by formalising the componential nature of task schema architecture and also confirms what some theorists have postulated in recent theories of learning and adaptive human behaviour—that components of individual learned routines at various levels of abstraction can be adapted to the current context, thereby expediting learning (e.g., Cole et al., 2011; Taatgen, 2013; Verbruggen et al., 2014).
The present results are also consistent with recent theories of cognitive control (including computational models) which acknowledge that learning can include more abstract representations than specific S-R rules (e.g., Collins & Frank, 2013; Schmidt et al., 2016). For example, Collins and Frank (2013) have demonstrated that task-set structure can also be learned and applied to novel tasks that share a common structure. Their results even suggest that inferring a task-set structure is the norm and that these structures readily transfer between contexts even when they are detrimental to performance (see also Dreisbach, 2012). The construction of task-sets (either via instruction or performance) has also received some attention recently in the instruction-learning literatures (for reviews see, for example, Brass et al., 2017; Meiran et al., 2017). Although the details regarding this process and the mechanisms involved in the transfer of task schemas and their relationship with task-set construction remain murky, there is a growing recognition of the importance of such schemas in learning and adaptive human behaviour.
In the present experiments, the benefits of task schema transfer were relatively short-lived—they were largely limited to the first few trials of the test block and were no longer observable by the end of the block. That is, the benefits of task schema transfer were largely limited to Chein and Schneider’s (2012) formation stage of learning and had largely been eliminated by the time learning had transitioned to their controlled execution stage. This observation is consistent with the notion that task schema transfer was the source of the effect. As the new task becomes more practised (and learning can rely more on the newly formed task-set), the benefits of task schema transfer dissipate. Apparently, the main benefit to be gained by reusing components of recently formulated task schemas in the construction of novel schemas is in accelerating the formation of a novel task-set. Once that task-set has been created and has been applied to the current task a few times, the task schema itself is less active in controlling behaviour. Although apparently it is not altogether discarded because it can be used to expedite subsequent learning where appropriate.
It should be noted that this particular pattern of results is likely linked to the paradigm used here, which was specifically designed to investigate transfer of task schemas. 8 Other forms of transfer certainly have longer-lasting effects on performance and are not limited to the first few attempts at learning a novel task. For example, individuals with more experience in reading experimental psychology journal articles will be able to decipher the content of the present article more quickly than readers with less experience in this skill, and that benefit is likely to last beyond the first few words/sentences of the article. However, that class of transfer is more akin to Cole and colleagues’ (2010, 2011) compositionality of learned instances—the recombining of existing representations/information in novel ways. Another example from a different domain of transfer would be that the transfer of category–response associations to novel stimuli from the same category (e.g., Longman et al., 2018) is likely to benefit performance for as long as the newly formed stimulus–category association remains intact. As discussed in the introduction, transfer can take many forms, but the focus of the present study was on the transfer of (components of) learning strategies that can be used to accelerate the formation of novel task-sets. Nonetheless, it is possible that the rapid deterioration of transfer effects reported in the present experiments might be a feature of the paradigm used rather than our preferred interpretation.
In the spirit of full disclosure, a third experiment was run using a similar paradigm to Experiment 2, but the results were largely inconclusive (i.e., almost all BFs from the planned contrasts comparing test performance from the full schema and control groups to the other groups were in the range 0.2–2.0). However, there was some evidence that the motoric component was also an especially important contributor to test performance in Experiment 3. This third experiment is described in more detail and the results are reported in the Supplementary Materials where we also report additional analyses that collapsed the data from Experiments 2 and 3 together. To summarise, the outcomes from the between-experiment analyses provided additional evidence that motoric training was especially important in directing test performance, and that test performance improved as a function of the number of relevant components included in the training tasks. The planned contrasts also added to the evidence that training with the perceptual and motoric components together or with the perceptual and categorization components together expedited the early stages of learning the test task.
There were some procedural differences between Experiments 2 and 3 (e.g., Experiment 3 had a longer practice phase), but it would be difficult to argue that any of these could explain the difference in outcomes between experiments. Although there were some qualitative differences in the patterns of results from Experiment 3, the most salient difference between the two experiments was in the variability of RTs and accuracy. Specifically, there was considerably more variability in the data from Experiment 3 than the data from Experiments 1 and 2. This might have reflected some differences in experience with participating in psychology experiments between the pools. For example, the participants from Experiments 1 (University of Exeter students) and 2 (recruited via Prolific) might have had more experience with participating in similar computer-based psychology experiments than the participants from Experiment 3 (students from the University of the West of Scotland where participation in experiments is rare). However, we acknowledge that this is merely conjecture and that the source of the differences in variability of RTs/accuracy within the groups from each experiment remains unclear.
Another limitation of the present study is that learning difficulty was not matched across strategic task components in the present experiments. 9 It is possible that the performance benefits associated with training on components which were especially easy to learn might not be observable in test performance because asymptotic performance was reached almost immediately. Inspection of the learning data from the training phase of all three experiments (found in the Supplementary Materials) suggests that the perceptual, categorization, and motoric components (i.e., single-component training conditions) were the easiest to learn—performance reached asymptote before the end of the first training block and there was little additional improvement in performance throughout the remainder of the training phase. However, training with the motoric component was consistently associated with improved test performance in the present experiments, suggesting that the ease by which this component was learned did not hide the transfer effect. Conversely, training with the full schema continued to improve performance throughout the practice phase, suggesting that it was a difficult combination of components to learn. Nonetheless, full schema training was also one of the most reliably associated with improved test performance. Task/component difficulty was not explicitly controlled in the present experiments, and it would be difficult to equate the difficulty of learning a single component versus learning three. Nonetheless, the data seem to suggest that the relevance of each component to the test task was a better predictor of transfer than the speed at which each component was learned.
To conclude, the current report makes a unique contribution by systematically examining the architecture and transfer of task schemas in a series of dot-pattern classification tasks. Specifically, by determining the kinds of information that can be represented therein, and how that information can be adapted to novel contexts. The findings suggest that task schemas can be divided into distinct components that can be reused to expedite the earliest stages of learning a novel task that shares some/all of the structural task components with the training task(s) and that this effect is additive. The particular components (or combinations of components) that are especially effective in optimising performance are likely to be determined by the format of the task and the prior experience of the learner. Nonetheless, the present study contributes to the growing literature investigating learning and transfer of task schemas by demonstrating that they can be divided into separable components which can individually be used to optimise learning a novel task.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218231221046 – Supplemental material for Transfer of strategic task components across unique tasks that share some common structures
Supplemental material, sj-docx-1-qjp-10.1177_17470218231221046 for Transfer of strategic task components across unique tasks that share some common structures by Cai S Longman, Fraser Milton and Andy J Wills in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
The authors thank Rosamund McLaren, Ruichong Shuai, and Sara Asanai for their help in data acquisition and Marius Golubickis for his help with the drift diffusion model analyses.
Author contributions
C.S.L., F.M., and A.J.W. contributed to the conception and design; C.S.L. contributed to acquisition of data; C.S.L., F.M., and A.J.W. contributed to analysis and interpretation of data; C.S.L., F.M., and A.J.W. drafted and/or revised the article; C.S.L., F.M., and A.J.W. approved the submitted version for publication. The authors also thank Frederick Verbruggen who made valuable contributions to the early stages of developing this work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the European Research Council (Grant No. 312445 awarded to Frederick Verbruggen), the Carnegie Trust for the Universities of Scotland (Grant No.RIG008617 awarded to C.S.L.), and the Experimental Psychology Society (Small Research Grant awarded to C.S.L.)
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.