
Abstract
Category variability or diversity is an important factor influencing generalisation. However, expectations of category variability may not only depend on the variability of encountered category members, but may also be shaped by prior experiences with similar categories. In this study, we investigated whether we could influence category generalisation by inducing different category representations in an A/Non-A categorisation task: Participants either learned about a homogeneous category Non-A or a diverse category Non-A during a priming phase. To better understand the transfer process, we varied the nature of the learning phase from implicit transfer to explicit instructions that actively requested participants to use their prior experiences. We found that while with a homogeneous Non-A representation, generalisation of the A and Non-A categories was equal, the generalisation of category Non-A widened after a priming phase with a diverse representation. In a second experiment, we found that the widening of generalisation of category Non-A occurred when the exemplars in this category were themselves diverse (feature-diverse condition) but not when the category contained distinct exemplars (exemplar-diverse condition). These results suggests that categorisation is influenced by previous categorisation experiences possibly altering the representation of a category. Furthermore, the study gives a hint what kind of heterogeneity is needed to observe the commonly reported broader generalisation of diverse categories. The finding has implications not only to understand the influence of prior experiences on category learning, but any cognitive process that hinges on generalisation.
Introduction
Categories are a fundamental building block of human cognition enabling us to meaningfully organise our complex world. An important part of categorisation is the process of generalising from known to yet-unknown instances of a category. For example, imagine a person deciding whether the new kind of tea she tasted is a black or a green tea to accordingly integrate the new experience into her representation of these categories. Category representations such as the ones of black and green tea sorts are defined by the variability of their members and dimensions. The perceived variability or diversity of a category, in turn, influences the accuracy with which category members are recognised as well as the likelihood of generalisation such that high variability categories are learned more slowly but are more likely to be generalised to novel instances (Cohen et al., 2001; Gonzalez & Madhavan, 2011; Hahn et al., 2005; Raviv et al., 2022).
People usually form a representation of a category such as the one of green tea by gaining experiences with members of the category. Furthermore, prior knowledge influences categorisation and is updated and revised in the learning process (Carmichael & Hayes, 2001). One way how prior knowledge may play a role is experience with a general or abstract entity (Rehder & Ross, 2001) that is related to a subsequently learned category. For example, people may hold certain stereotypes about tea, such as “green teas have many different flavors while black teas always taste the same.” These preconception they hold about the relatively abstract categories “green tea” or “black tea” may influence their decisions when classifying a concrete new tea as green or black. Furthermore, being able to apply knowledge by understanding relations between categories is powerful (Hummel & Holyoak, 2003). Understanding that green teas possess a different diversity of flavours than black teas gives one a head start when learning about the actual blends. Although many studies have shown that directly experiencing diversity in a category yields a wider generalisation, it has not yet been investigated whether the previous experience of diversity plays a role in generalisation.
To research this question, we chose a single category or A/Non-A categorisation task (cf. Posner & Keele, 1968): In A/Non-A tasks, participants are not asked to categorise objects into two categories (e.g., categories A and B), but have to decide whether an object is a member of category A or not. Preconceived notions about Non-A are likely weak. Taking advantage of this natural indefiniteness, we investigated whether we can induce differing representations of the Non-A category’s variability. To this goal, we employed a priming phase, in which participants encountered an abstract Non-A category that was either diverse or homogeneous before the actual categorisation task. More specifically, the diversity in a category could originate from experiencing several differing exemplars, for example because they belong to different subcategories, or from experiencing exemplars that are themselves diverse, e.g., because they possess several different features. Following the priming phase, we then tested whether the experience in the priming task shaped how the Non-A category was generalised. In the following paragraphs, we outline how variability is supposed to influence generalisation in categorisation tasks and how the prior experience with a category’s variability may be transferred and continues to influence future categorisation behaviour.
Category variability and generalisation
Generalisation is a basic ability that allows humans to deal with novel situations: When people are confronted with a new situation, they rely on similar previous experiences to infer their response. Research on human generalisation often investigates how people generalise from one training stimulus to a range of test stimuli (J. C. Lee et al., 2018). The generalisation gradients that are observed in these studies are empirical observations of Shepard’s universal law of generalisation (Shepard, 1987). Shepard states that the probability of generalising to an instance decays with greater distance in psychological space from the original stimulus. In a generalisation task that studied associative learning—and thus a form of prior experiences on later prediction—J. C. Lee et al. (2019) showed that when participants saw non-diverse or diverse pictures that predicted a hypothetic shock outcome or no shock outcome, experienced diversity during training increased generalisation for the test stimuli.
Generalisation and categorisation are tightly linked, insofar as the process of categorising involves generalising from known exemplars of categories to novel objects. Indeed, Shepard’s exponential generalisation function is part of a number of theories of categorisation and concept learning, e.g., ALCOVE (Attention Learning COVEring map model; Kruschke, 1992) or the GCM (Generalised Context Model; Nosofsky, 1984).
Variability is crucial for categorisation because it impacts the generalisation process, as is evident from research showing that high variability in the feature dimensions increases generalisation width (Carvalho et al., 2021; Hahn et al., 2005; Rips, 1989). For instance, a famous study by Rips (1989) showed that participants were more likely to categorise an object with a 3-inch diameter as a pizza than a quarter, suggesting that knowledge about the high variability of a pizza’s diameter facilitated their generalisation of this category and thus the inclusion of the new object (see also Smith and Sloman, 1994). Similarly, Cohen et al. (2001) showed that participants were more likely to categorise novel objects into a high- than a low-variant category and Hahn et al. (2005) found that the diversity of categories, manipulated as variability in the range of their feature dimensions not only made learning more difficult, but also increased generalisation to novel items outside the range of training exemplars.
Indeed, variability may also explain why different distributions of training items affect category generalisation. Carvalho et al. (2021) found that skewed and uniform input distributions resulted in broader generalisation than normal input distributions, suggesting that the greater perceptual variability experienced in the skewed and uniform distributions has an effect on the generalisation width.
Similar effects of training variability on generalisation have also been shown in more realistic categorisation tasks. For instance, Gonzalez and Madhavan (2011) reported that participants training to detect dangerous items with low variability training instances learned faster and were more accurate at the end of training. However, in the test phase, participants who had been training with high variability training instances were more likely to detect novel dangerous objects.
Although most research has focused on categorisation tasks in which participants are asked to categorise an object in one of two categories (A vs B), manipulating variability in an A/Non-A task could lead to different results. Casale and Ashby (2008) compared an A/B and an A/Non-A task and showed that contrasting a category A with a category B resulted in high accuracy categorisations of the training items regardless of the manipulated variability of the categories. In contrast, when participants had to discriminate a category A from a category Non-A, larger variability of category A decreased accuracy during training. This may have been due to the more diverse perceptual experience that participants already made with stimuli from category Non-A. Stimuli of Non-A came from a uniform distribution, while stimuli from category A (and category B) came from a normal distribution and were thus biased towards a central stimulus and less diverse in their experience. In sum, a host of studies suggests that experiencing categories with a higher variability or diversity impedes learning but increases generalisation, i.e., the likelihood that novel instances are assigned to a category.
Influencing expected category variability
As outlined above, the experienced variability of categories influences their generalisation. But there are also prior experiences and assumptions that one holds for categories and their (expected) variability.
Prior knowledge influences category learning in many ways. For example, Kim & Rehder (2011) showed in an eye-tracking study that previous knowledge guides our attention to certain category features. Furthermore, the effects of prior knowledge have been implemented in a number of category-learning models. For example, a modified ALCOVE model that includes prior biases as weights, fits data successfully in rule-learning situations (Choi et al., 1993). Heit (1994) modified an exemplar model to include prior knowledge. Finally, Rehder and Murphy (2003) integrated prior knowledge within their knowledge-resonance model.
In many cases, people may draw upon prior experiences or knowledge regarding the variability that can be expected in a type of category structure. They may hold preconceptions about a rather abstract category or may have received information about general structures, before interacting with concrete exemplars. This transfer of prior experiences is enabled by a relationship between both categories. In this research, we aim to investigate this question using a general A/Non-A category structure (abstract) that is transferred to a later X/Non X categorisation task (concrete). Although categories are in general expected to be normally distributed around a central, most frequent exemplar (Duffy et al., 2010), Non A categories are likely not linked to a certain expectation. Manipulating the variability of Non-A should thus provide us with a conclusive result whether an experience of a category structure can be transferred to a subsequent categorisation task.
Evidence that experiences and, in particular, assumptions about environmental structures can transfer across tasks comes from several lines of research. For one, Hills et al. (2008) showed that the distribution of resources in an external search task influenced subsequent internal search. Similarly—and more directly related to our task—a study by Flannagan et al. (1986) examined the effect of a transfer of distributions in category learning. In their third experiment, participants first performed a category learning phase with a normal or U-shaped distribution followed by a second category learning task that also had a normal or U-shaped distribution. Participants were faster in learning a U-shaped distribution in the second task when it followed the U-shaped training phase. But learning was impaired in the second phase when the U-shaped distribution followed a normal distribution. In experiment 4, they found that learning a U-shaped distribution in the second phase was also facilitated by being first exposed to a skewed distribution, even though the skewed distribution bore no obvious resemblance to the U-shaped distribution. These results show that prior expectations people hold about categories can be influenced by current experiences from a first experimental learning phase and suggest that a transfer of structure may take place even if there is no perceptual similarity (Flannagan et al., 1986). Conceivably, this may mean that the internal representation of a category is influenced by prior experiences, which, in turn, is reflected in the following categorisation decisions.
An open question is how important explicit knowledge is for this transfer to take place. Priming studies such as the study by Hills et al. (2008) assume an implicit transfer and do not even instruct participants to rely on the experiences in the previous tasks (see also Flannagan et al., 1986). This suggests that transfer processes take place without participants being explicitly aware of their internal category representation. However, if knowledge and rules (Rips, 1989; Smith and Sloman, 1994) can impact categorisation, an explicit representation of the categories’ variability may be necessary or at least more reliable to enable a transfer and induce effects of experienced variability.
This research
Taken together, these findings suggest that experiences with categorising objects of category A from a homogeneous or a diverse category Non-A may influence later categorisation in a task with similarly labelled categories. Specifically, we expect that experiences with a diverse Non-A category compared with a homogeneous Non-A category will lead to a wider generalisation of this category.
To investigate the questions outlined, we conducted two experiments consisting of three phases, a priming phase, a category learning phase, and a category generalisation or transfer phase. The priming phase consisted of learning a generic A/Non-A categorisation task. During the priming phase, we manipulated the experienced variability of the Non-A category by training participants either with a set of diverse category members for the Non-A category or by showing the same stimulus repeatedly. Afterwards, participants performed a second category learning phase, in which they learned about a novel A/Non-A categorisation task using stimuli that were perceptually unrelated to the first categorisation task and replacing the abstract with more concrete labels. In the third phase, we tested participants’ generalisation of the category exemplars from Phase 2 by asking them to indicate to which category a novel object of the second categorisation task was more likely to belong.
We chose to relate the categories by giving them the analogue labels “A”/“Non-A” and “Flox”/“Not-Flox” to enable a transfer.
To test whether explicit representations of the category variability were necessary for transfer, we varied the instruction mode in two levels: We either explained the category structure to participants or just requested a transfer of experience between the phases (Experiment 1). In Experiment 2, we tested whether exposure without any instruction suffices. We either requested a transfer between the phases or did not request a transfer (implicit condition). If explicit knowledge is necessary, we expect that participants will only show an effect on categorisation behaviour, when the training mode was explicit. However, if the exposure to a diverse Non-A category is enough to transfer to the second task, we expect diversity to influence generalisation in all instruction conditions.
Experiment 1
Methods
The study was programmed in jsPsych (de Leeuw, 2015) and conducted as an online study. We employed a 2 (priming of the Non-A category representation: homogeneous vs diverse) × 2 (instruction mode: implicit vs explicit) between-subjects design.
Participants
A total of 127 participants were recruited at the University of Bremen via a mailing list of the psychology department. All participants gave informed consent on the first page of the experiment. Participants were randomly assigned to one of the four conditions. Based on previously defined criteria, we excluded five participants due to an accuracy below 80% in one of the categorisation tasks (Phases 1 and 2), two participants because they indicated limited colour vision, and three participants based on self-exclusion (participants were asked whether they completed the task diligently and wanted their data included in the analysis). None of the remaining participants indicated that he or she worked through the experiment very or moderately unfocused. This resulted in a total of 117 participants for our main data analysis (29 males, 87 females, 1 diverse;
Procedure and materials
The experiment consisted of three phases: a priming phase, a category learning phase and a category generalisation phase. In the priming phase, participants completed a categorisation task, in which they were asked to categorise stimuli as “A” or “Non-A.” Participants were introduced to the task by an instructional picture that showed only blue stimuli for category A and either only green stimuli for category Non-A (homogeneous category representation) or six different coloured stimuli (diverse category representation). Participants then categorised monochrome stimuli (six blue A stimuli, and six other coloured stimuli) in 12 trials into A and Not-A to learn about the category representation. See Figure 1 for a representation of the stimulus materials used in the different phases of the experiment.
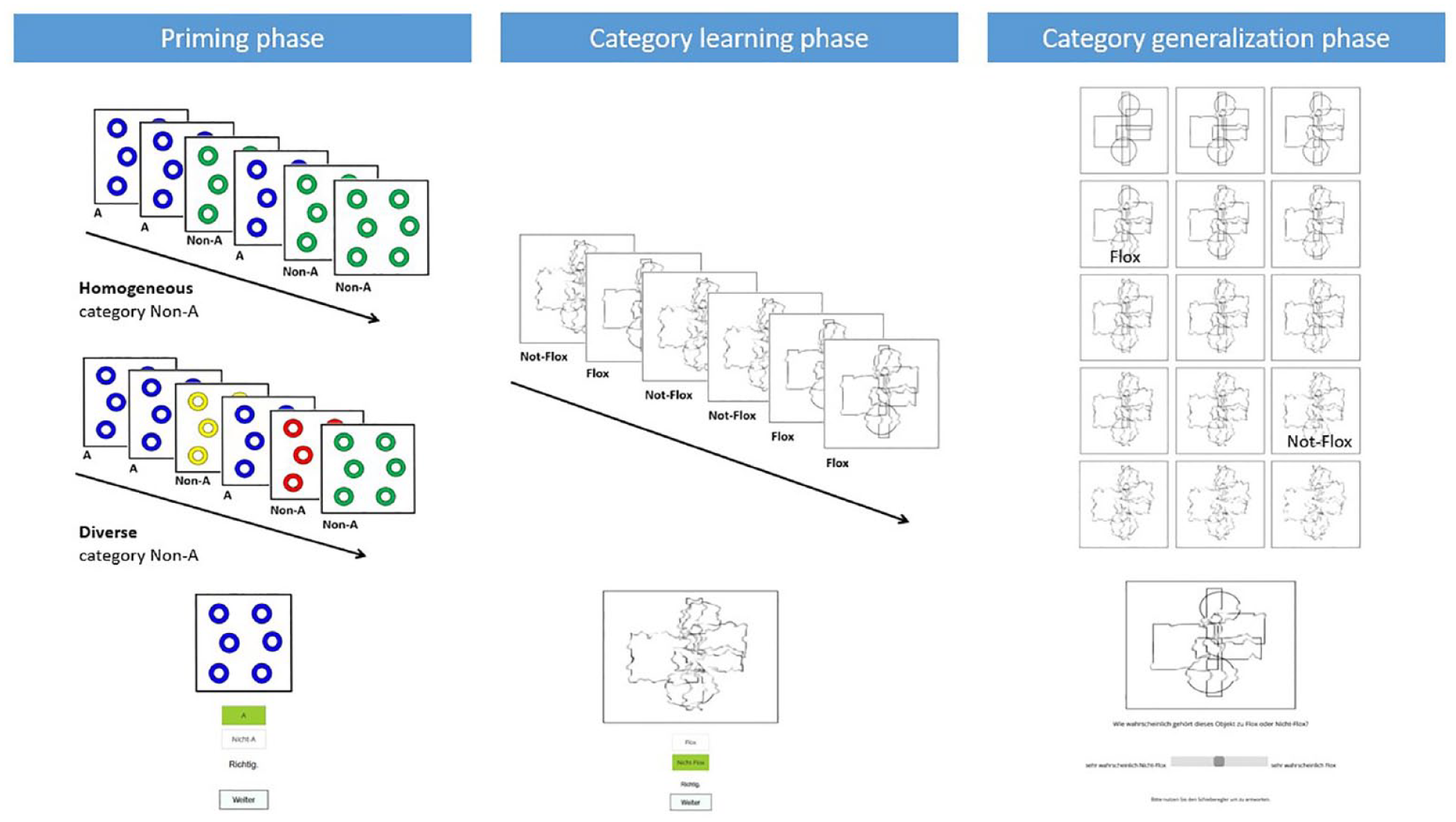
Illustration of the experiment phases.
In the category learning phase, participants learned a second A/Non-A categorisation task using perceptually different stimuli from the stimuli of the priming phase and concrete labels. The stimuli used for the second categorisation task and the generalisation task consisted of several black-lined rectangles on a white background. To obtain stimuli that differed only on one dimension, we distorted the original stimulus 1 (clear, sharp edged lines) by increasingly blurring the lines in 15 levels. The stimuli shown in the category learning phase were distortion levels 4 and 12, which participants learned to categorise as “Flox” or “Not-Flox,” respectively. Thus, three stimuli lay between the ends of the one-dimensional continuum and the training stimuli, and three stimuli lay between the training stimuli and the ambiguous stimulus in the centre (which had a distortion level of 8). Because the dimension was not assumed to be perfectly linear, we did not counterbalance whether the Level 4 or Level 12 stimulus was shown with the “Flox” label. This decision also ruled out that participants could find it counter-intuitive to associate the Non-A label and the less distorted stimulus. In the following 16 training trials, participants had to categorise objects (8 stimuli of Level 4 and 8 stimuli of Level 12) into “Flox” and “Not-Flox.”
Categorisation decisions were made throughout the experiment by pressing one of two response buttons. Answering induced a colour change in the response button: the button turned green with correct answers and red in case of an incorrect answer. In addition, a verbal feedback (“Correct” or “Not correct”) was displayed underneath the response buttons. The order of the response buttons (i.e., the labels “Flox” and “Not-Flox” as well as “A” and “Not-A”) was counterbalanced between participants.
The third phase was the “transfer phase” or generalisation phase, in which we asked participants twice for each of the 15 stimuli from the continuum whether they thought that this object belonged to the Flox or Not-Flox category. The order was randomised such that each stimulus was shown once before being shown again. Participants answered by adjusting a slider from “very likely Not-Flox” (1) to “very likely Flox” (100). They did not receive any feedback in the generalisation phase. Participants were told that there were no correct or incorrect answers, but that we were interested in the decisions they made. Figure 1 illustrates the flow of experimental phases.
Before starting the transfer phase, we varied the instructions with respect to the instruction condition. In the explicit condition, participants were asked to use the experiences in the priming task to make the categorisation decisions in the transfer phase. In the full explicit condition, they were additionally informed that the Non-A category in the priming phase consisted of six categories and that they should assume the same structure for the “Not-Flox” category when making their categorisation decisions.
We announced the two training phases and the later transfer phase before the training started. Instead of using “attention checks” to screen for inattentive participants, we added an “honesty check” to the debriefing, where participants could self-declare whether they should not be considered for the data analysis, for example, because they were distracted. We made it clear that their honesty would not affect whether they received course credit.
Upon completion of the test phase, participants filled in a question on category Non-A perception. The exact wording of the question was: “At the beginning of the experiment and in interim instructions it was explained to you how you should imagine Non-A/Not-Flox. How many categories did you imagine for Not-Flox in the later test phase (phase with slider responses)? (Please enter a number.)”
Results
Data cleansing
We assessed reliability of test phase responses by calculating the correlation between participants’ responses in the two blocks of the transfer phase
Final distribution of the participants to the experimental conditions was as follows: diverse Non-A category implicit learning condition
You may find a table indicating the number of participants per condition before and after exclusion in Supplemental Appendix H.
Descriptive analyses
As expected, participants showed a high accuracy of 97% (SD = 0.04) for the priming learning phase. Participants also showed a high accuracy of 96% (SD = 0.05) for the category learning phase.
As illustrated in Figure 2, the test phase responses revealed that participants tended to categorise Stimuli 4 and lower as “Flox” and Stimuli 12 and higher as “Not-Flox” with the response strength reaching its extreme values at Stimulus Level 2
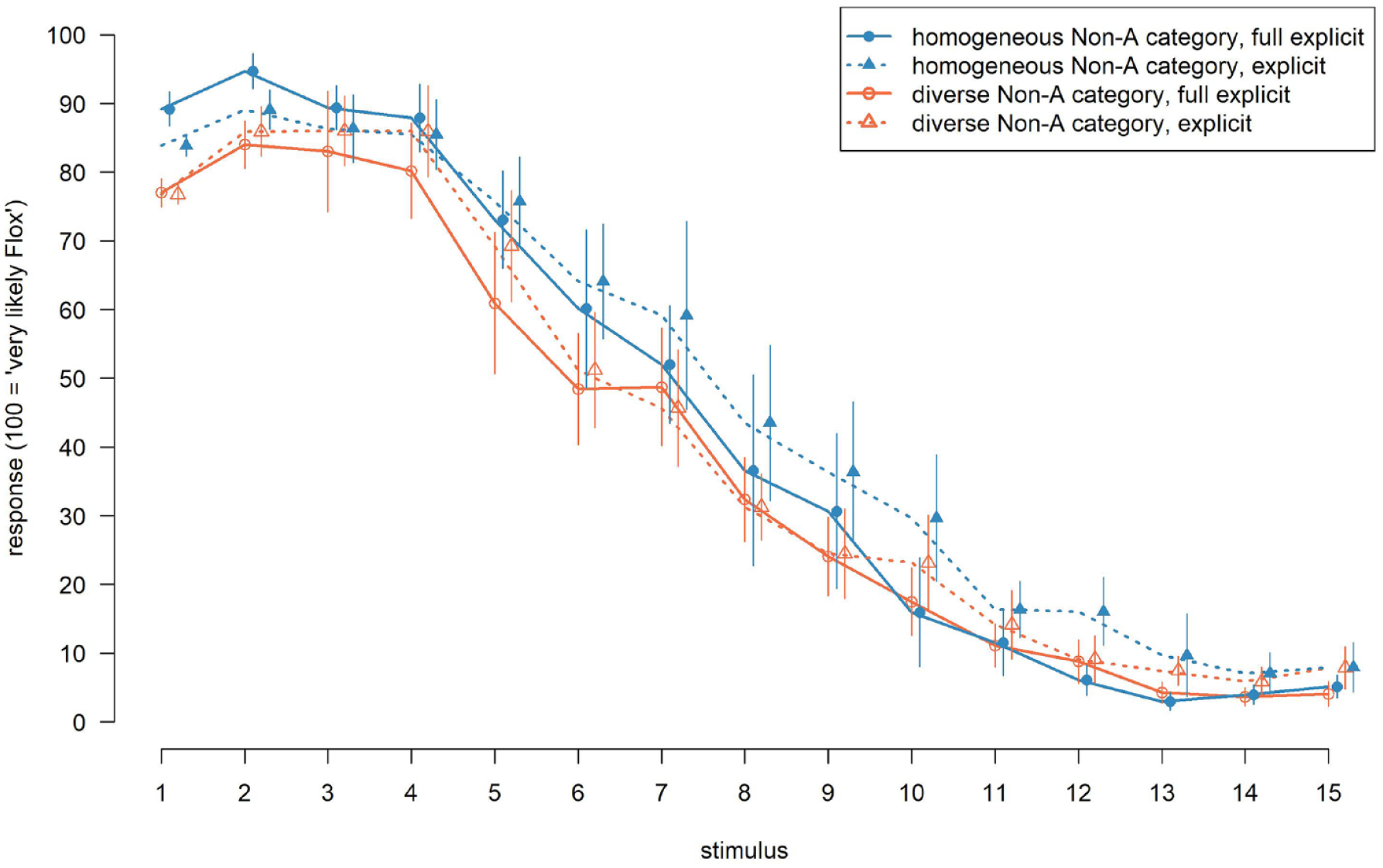
Response strength by Non-A category representation and learning mode.
Data analysis plan
First, we analysed influences of our manipulations on responses in the transfer phase with a generalised linear mixed model. As this analysis shows that there are interactions of the Non-A category representation with the stimulus, we conducted a post hoc analysis of stimulus regions. In a second part of the analysis, we aimed to corroborate the main analysis with an additional analysis that specifically targeted the generalisation width, which can be inferred as boundary from the intercept of a logistic regression. For this analysis, we fitted a hierarchical Bayesian model of a logistic function and examined boundary values with respect to condition. The analyses were conducted in the statistical software R 4.1.2 (2021-11-01; R Core Team, 2021).
Analysis with a generalised linear mixed model
We calculated a generalised linear mixed model assuming a binomial distribution of residuals of the dependent variable and a logit-link function with the package brms (Bürkner, 2017) with the formula:

The stimulus variable was centred and scaled. We defined sum contrasts for both factors scaled to –0.5 and +0.5.
1
Estimates correspond to main effects on the log-odds scale. We employed weakly informative priors,
We evaluated model fit to the data by a model comparison with leave-one-out cross-validation. The full model including both predictors, category Non-A representation and instruction mode and the interaction (Model 1) provided a better fit for the data than a reduced model without the interaction (Model 2: response
Across all stimuli on the continuum, we could not find an effect of category Non-A condition,
The reported three-way interaction suggested an interaction between Non-A representation and instruction mode that depended on stimulus. We examined this further by looking at marginal means and calculating pairwise comparisons for the interaction of these predictors averaging over stimulus.
Post hoc comparisons with the package emmeans (Lenth et al., 2018) showed that responses differed credibly between the homogeneous and the diverse category Non-A representation only in the explicit instruction mode,
Post hoc analysis of stimulus interactions
The found two-way interactions of category Non-A representation and stimulus and instruction mode and stimulus were further examined in a post hoc analysis. For the analysis, we divided the stimulus continuum into four regions: Region “Category Flox” included Stimuli 1 to 4, region “Category Flox-Boundary” included Stimuli 5 to 8, region “Category Not-Flox-Boundary” included Stimuli 8 to 11 and finally, region “Category Not-Flox” included Stimuli 12 to 15. Comparisons between the category Non-A representations for each stimulus region are reported in Table 1. In the comparison between the homogeneous and diverse condition, we see credible estimates of the difference for the regions “category Flox” and “category Flox-Boundary” such that we observe a lower response strength in the diverse compared with the homogeneous condition. Our region of interest, “Category Non-A-Boundary” in which we would expect the widening of category Non-A, shows however no credible estimate of the difference. For the comparison between the full explicit and the explicit condition, the region analysis reveals a difference for the regions “Category Not-Flox-Boundary” and “Category Not-Flox,” meaning that response strength was lower for the full explicit than the explicit condition.
Estimates for post hoc comparisons for stimulus regions in interaction with category Non-A representation and instruction mode.
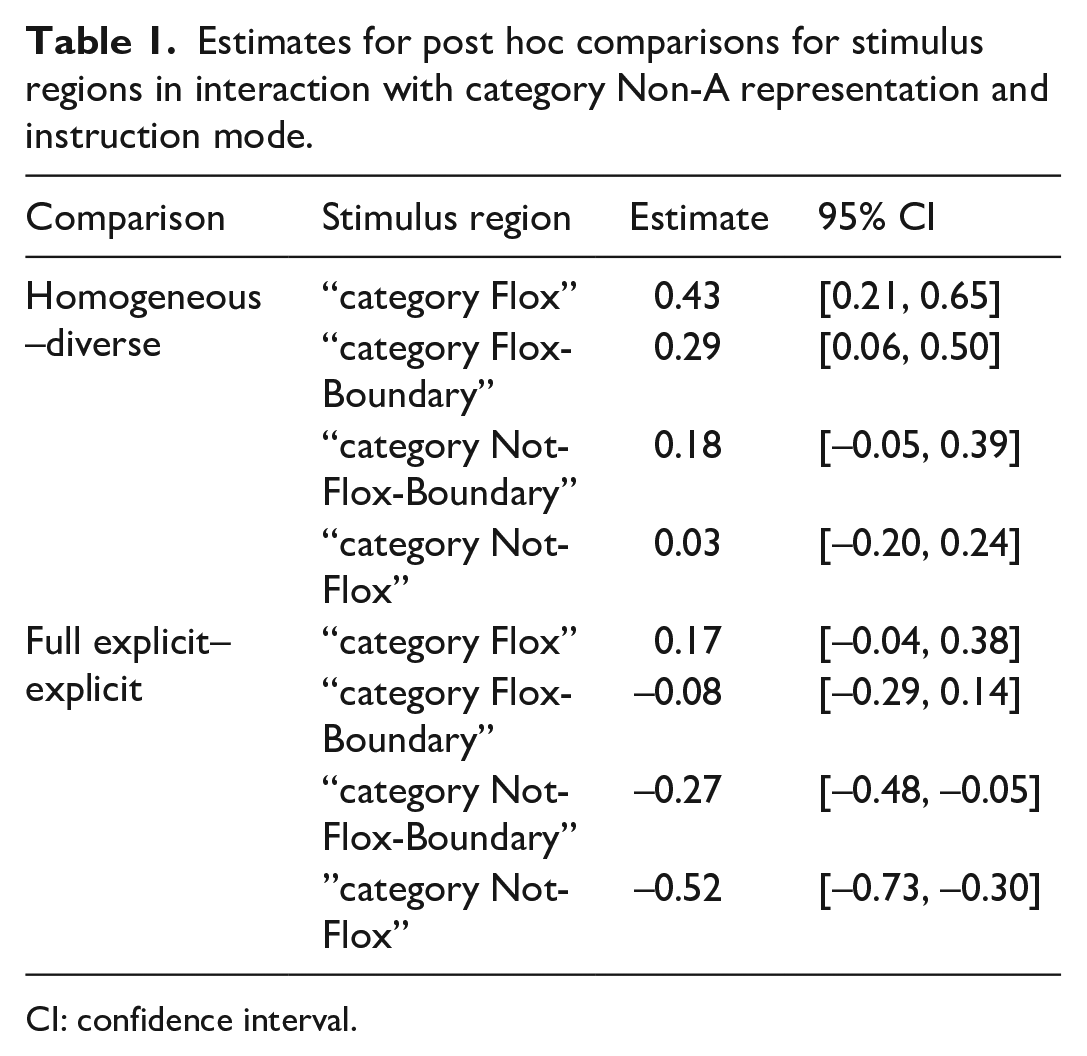
CI: confidence interval.
Hierarchical Bayesian logistic regression fit: Boundary parameter
One way to characterise generalisation via a logistic function is to determine the boundary position, i.e., the turning point in which participants are indecisive how to categorise an object, with objects left to this turning point being more likely to be categorised into category “Flox” and objects right to this point being more likely categorised into category “Not-Flox.”
To determine shifts of the boundary and thus the width of generalisation, we fit a logistic regression to participants’ responses. The parameter

indicates the x-value of the turning point (i.e. the boundary).
We decided to fit this logistic function in a hierarchical Bayesian way to accommodate for individual differences while estimating precise boundary parameters on the group level per condition (M. D. Lee, 2011). To implement this model structure, we used the model displayed in Figure A1 in Supplemental Appendix B.
We fitted the model with four chains and 10,000 iterations. We assumed model convergence after visually inspecting traceplots and evaluating
Estimated boundary parameters for the homogeneous conditions were higher,
Figure A2 in Supplemental Appendix C shows the distribution of the boundary values by condition and Table A2 shows all estimated values in Supplemental Appendix D.
Question on category Non-A perception
Finally, we analysed answers to our additional question on the perception of category Non-A. Participants in the diverse Non-A condition indicated a somewhat higher number of categories for Not-Flox than participants in the homogeneous Non-A condition (M diverse = 4.21, SD diverse = 3.32, M homogeneous = 3.88, M homogeneous = 3.06), and in the full explicit than the explicit instruction condition (M fullexplicit = 4.16, SD fullexplicit = 2.66, M explicit = 3.94, M explicit = 3.57), but neither difference was significant (category Non-A representation: F (1,108) = 0.43, p = .514; instruction mode: F (1,108) = 0.19, p = .660) nor the interaction (F (1,108) = 0.52, p = .473) . Furthermore, even in the full explicit instruction condition, only a minority of participants (14% and 37%) indicated the correct number of categories (1 vs 6) suggesting that participants struggled understanding the question and probably misinterpreted it.
Discussion
Experiment 1 provided us with first evidence that prior experiences with a category’s structure can shape later categorisation decisions. Evident from the boundary shift in the explicit condition and visual depiction in the descriptive plot, we found the hypothesised widening of category Non-A when it was preceded by a diverse experience. A widening of a diverse category is a well-established finding. However, we show that not only direct experience but fairly subtle experiences with a previous categorisation task can affect the width of generalisation. This suggests that generalisation is sensitive to fairly small changes in peoples’ preconceptions about variability. To highlight the relation between the two tasks and facilitate transfer, we had framed the transfer as learning about an abstract category structure that then can be transferred to a specific, concrete case. Interestingly, we only found the effect when instructions about the transfer were explicit, but not when full explicit. One potential explanation could be that the transfer is a more implicit process that is not based on a deliberate transfer of an abstract structure to a concrete example and thus is more likely to be disrupted by a deliberate process as instructed in the full explicit condition. However, it could also be that participants were confused by the instructions and our manipulation of the diverse category, which could have reduced the effect of the previous experience in the priming phase. Thus, we conducted a second experiment to replicate the findings from Experiment 1 and to improve on our instruction and manipulation.
Experiment 2
In Experiment 2, we extended the first experiment to sharpen our manipulation of diversity, to improve the instructions and to test whether transfer would also occur with a completely implicit instruction and to generalise to new stimulus materials. For one, we adapted the manipulation to disentangle diversity that arises in a situation in which people are presented with several different exemplars all belonging into one category (exemplar diversity) and a diversity that stems from diverse exemplars, e.g., because they possess diverse features (feature diversity). A similar distinction was made by Bowman and Zeithamova (2020) who separately manipulated set size (i.e., number of exemplars shown per category) and set coherence (i.e., similarity of exemplars to the average). They showed that high-set coherence sped up learning and enhanced a prototype representation. A differentiation of variability types has also been made by Raviv et al. (2022), who distinguishes between numerosity (i.e., the number of exemplars, set size) and heterogeneity of exemplars. Improving on the manipulation of our first experiment by making this distinction will yield valuable insights in the nature of diversity that creates effects of wider generalisation. The stimuli of Experiment 1 showed several same-coloured rings in one exemplar. In the diverse condition, these same-coloured rings had different colours between exemplars. However, participants could still interpret the different rings as different features that possibly could take on a colour by themselves, that is theoretically creating multi-coloured exemplars. For Experiment 2, we again hypothesised a broader generalisation for Non-A in the diverse compared with the homogeneous Non-A representation. Specifically, we expected a boundary shift such that the boundary is shifted towards the A stimulus in the diverse conditions while no such shift occurs in the homogeneous condition. We expected this shift for both, an exemplar-diverse and a feature-diverse representation. However, we expected a greater shift for the exemplar-diverse than the feature-diverse condition given that it manipulates the variability between exemplars more directly. In addition, we simplified our instructions and made our manipulation of the instructions more straightforward: Either, we instructed participants to transfer their experience from the priming learning phase to the following learning phase, or we did not instruct them to do so. Finally, we constructed new stimulus material to ensure that effects are not limited to stimulus materials used in Experiment 1.
Methods
We preregistered the experiment at https://osf.io/5brfn.
Participants
We recruited 240 participants from local university students via list e-mails and online and offline advertisement. We excluded 14 participants from all analyses: 1 because of self-exclusion, 6 because of low accuracy in the training phase (< 0.80), 3 because they indicated to have impaired colour vision, and 4 because they had a low correlation between their answers of block 1 and 2
Procedure and materials
The experiment consisted again of three phases. We applied changes to the stimulus material of the priming phase to realise the newly introduced condition: In the homogeneous condition, participants categorised purple-coloured squares (category A) from green-coloured squares (category Non-A). In the exemplar-diverse condition, participants categorised purple-coloured squares (category A) from either turquoise-, red-, yellow- or blue-coloured squares (category Non-A), while in the feature-diverse category, participants categorised purple-coloured squares (category A) and rainbow-coloured squares (category Non-A). In the priming phase, participants completed 24 trials (12 stimuli for category A and 12 stimuli for category Non-A). The stimuli for the training and test phase were replaced with similar material because we wanted to generate the material systematically and avoid a stimulus without any distortion. Again, we blurred an image of rectangles in 15 levels. The stimulus material is shown in Figure 3. Procedure of the training and transfer phase stayed otherwise the same as in Experiment 1.
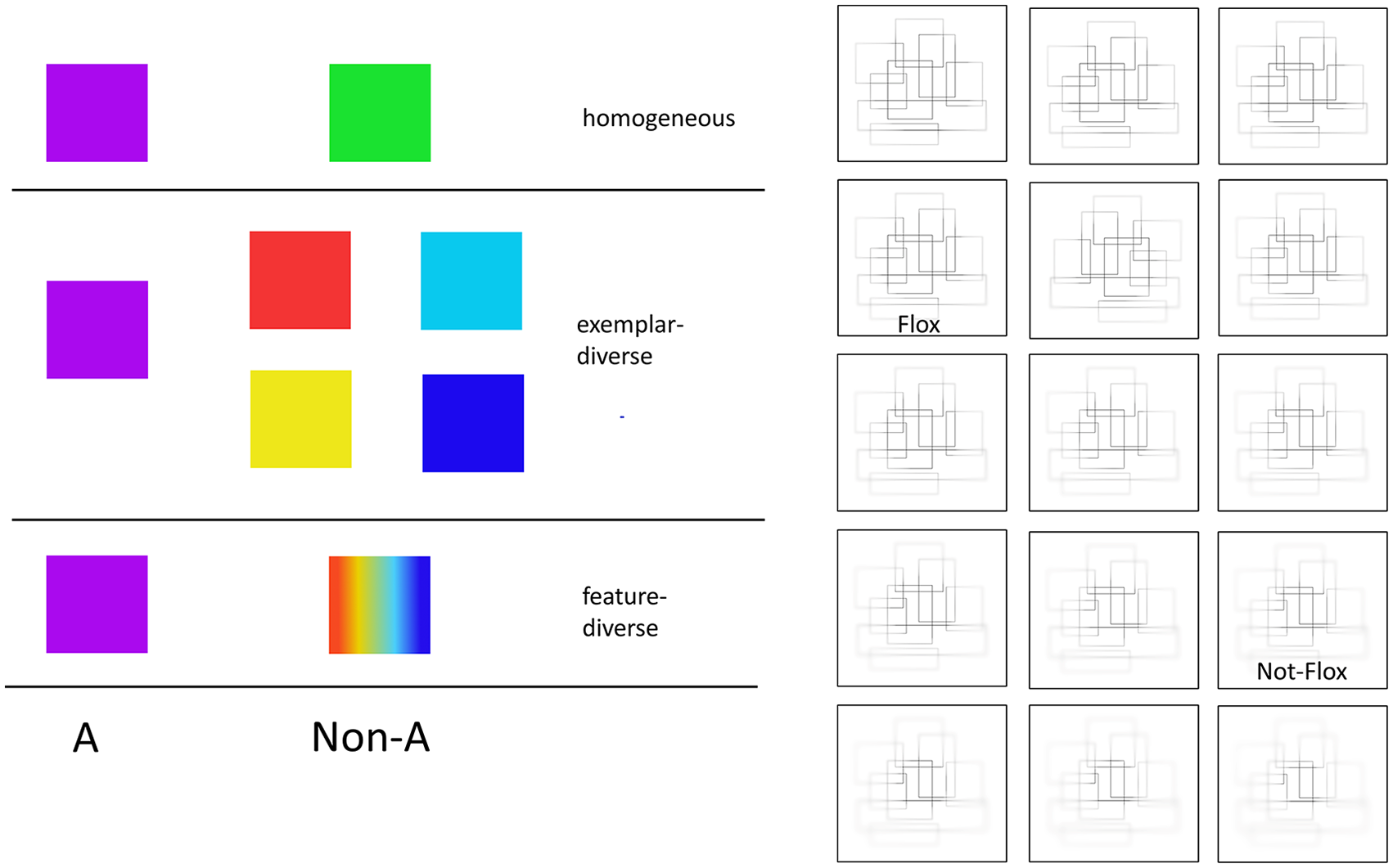
Stimulus material from Experiment 2.
Before starting the priming and the transfer phase, we varied the instructions with respect to the instruction condition. In the explicit condition, participants were asked to use the experiences in the priming task to make the categorisation decisions in the transfer phase. In the implicit condition, they were not told anything about a transfer or relation between the tasks.
Upon completion of the test phase, participants filled in a question on category A and Non-A perception. The exact wording of the question was: “Please remember the first training phase in which you got to know category A and Non-A. How do you estimate the variance of category A? How do you estimate the variance of category Non-A?” Participants could answer both questions separately on a Likert-type scale from 1 (“very low”) to 7 (“very high”).
Results
We followed the same analysis as in Experiment 1, first assessing effects of our manipulation on responses in the transfer phase with a generalised linear mixed model and second, a model analysis of a logistic function in a Bayesian hierarchical framework.
Descriptive analyses
The majority of participants indicated to have worked through the experiment focused
As illustrated in Figure A3 in Supplemental Appendix E, we observed generalisation from the training Stimuli 4 and 12. Participants categorised Stimuli 4 and lower as “Flox” and Stimuli 12 and higher as “Not-Flox.” Stimuli 5 to 9 were increasingly likely categorised as “Not-Flox,” with most participants indicating again that the middle Stimulus 8 belonged somewhat more likely to the “Not-Flox” category than the “Flox” category.
The following analysis is structured as in Experiment 1.
Analysis with a generalised linear mixed model
We again calculated a generalised linear mixed model assuming a binomial distribution of residuals of the dependent variable and a logit-link function with the package brms package (Bürkner, 2017). We employed weakly informative priors,

The stimulus variable was centered and scaled. We defined sum contrasts for both factors summing to 1. 4 Estimates correspond to effects on the log-odds scale. Detailed results of the generalised linear mixed model are reported in Supplemental Appendix F in Table A3.
We could not show an effect of category Non-A representation across all stimuli on the continuum,
Post hoc analysis
The interactions of category Non-A representation and stimulus and instruction mode and stimulus were further examined in a post hoc analysis. For the analysis, we divided the stimulus continuum into four regions: Region “Category Flox” included Stimuli 1 to 4, region “Category Flox-Boundary” included Stimuli 5 to 8, region “Category Not-Flox-Boundary” included Stimuli 8 to 11 and finally, region “Category Not-Flox” included Stimuli 12 to 15. Comparisons between the category Non-A representations for each stimulus region are reported in Table 2. In the comparison between the homogeneous and the exemplar-diverse condition, we see non-credible estimates of the difference. Our region of interest, “Category Not-Flox-Boundary” in which we would expect the widening of category Non-A shows, however, an almost credible estimate of the difference. When looking at this region, we do see credible differences for the comparison homogeneous and feature-diverse category Non-A representation that are robust in statistical analysis due to a high number of observations that show distinct response patterns for these conditions and stimulus region, i.e., when taking the stimuli of this region into a combined analysis. In Figure 4, you may compare the homogeneous and feature-diverse line carefully and integrate over the adjacent stimuli (specifically, Stimuli 8 to 12), to get a grasp of the difference between both conditions. This result can be described as a widening of category Non-A for the feature-diverse and also—but less pronounced—the exemplar-diverse condition between the Stimuli 8 and 12 (i.e., there is a lower response strength for “Flox” in these conditions).
Estimates for post hoc comparisons for stimulus regions in interaction with category Non-A representation and instruction mode.
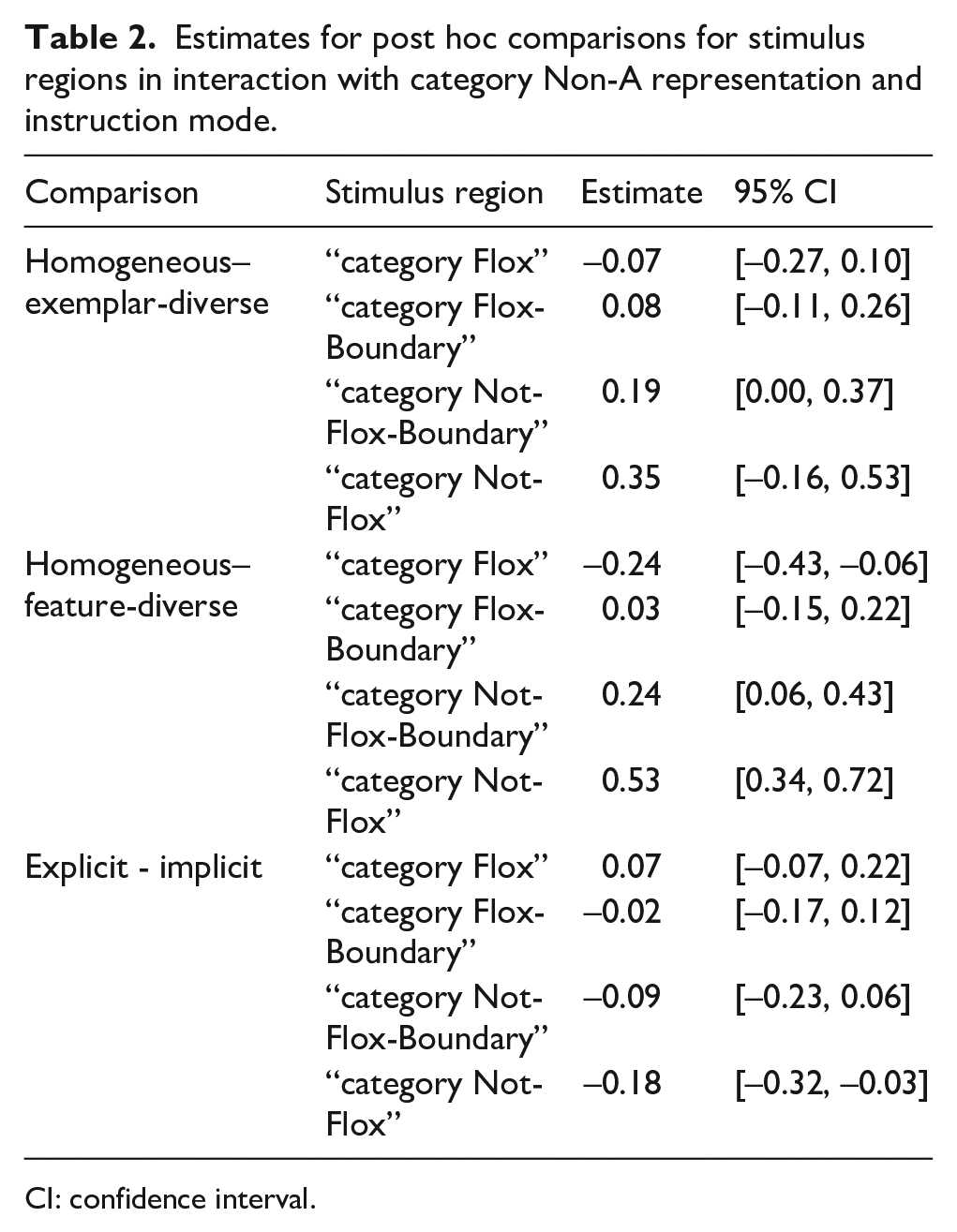
CI: confidence interval.
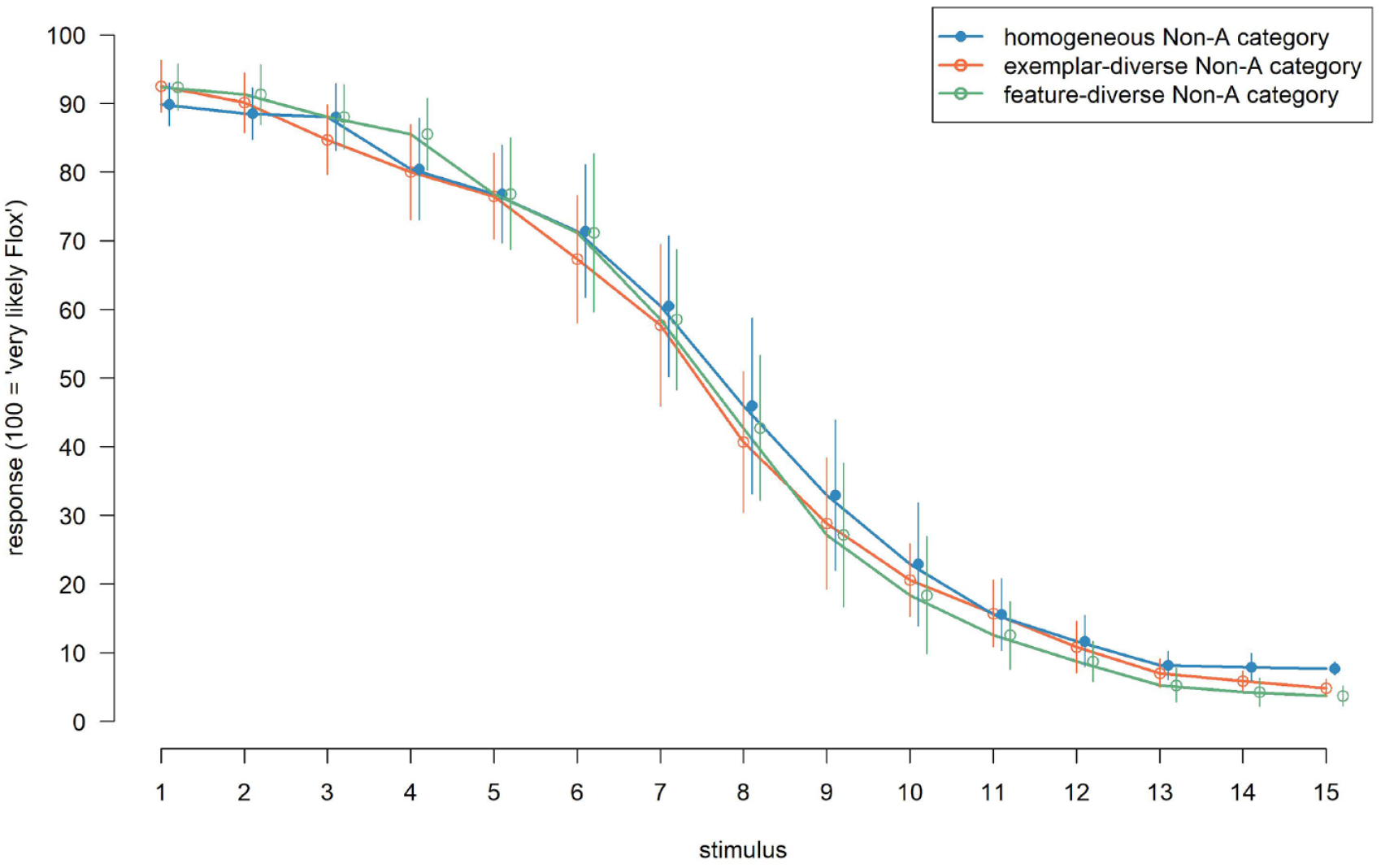
Experiment 2: Response strength by Non-A category representation.
Moreover, while we find an effect for the region “Category Not-Flox”, we further find a reversed effect for the region “Category Flox”. Thus, we see a lower response strength for “Not-Flox” and a higher response strength for “Flox” in the feature-diverse compared with the homogeneous category. This could be interpreted as a stronger discrimination between the two categories, i.e. between “Flox” and “Not-Flox” in the feature-diverse compared with the homogeneous condition. For the comparison between the implicit and the explicit condition, the region analysis reveals a difference only for the region “Category Not-Flox,” meaning that response strength was lower for the implicit than the explicit condition.
Boundary parameter in a logistic function
As in Experiment 1, we fit a model with a logistic function that allows to interpret the parameter of our interest, the boundary directly. The model details can be found in Supplemental Appendix B in Figure A1. We ran 10,000 iterations with four chains. Individual and group-level parameters for the boundary all converged with values below
Table A5 in Supplemental Appendix G provides the values for the boundary parameters for each condition. In the explicit condition, the estimated boundary of the homogeneous condition was
Question on Non-A perception
Perception of category A was on average
Discussion
In Experiment 2, we extended the design from Experiment 1 by differentiating between two ways in which diversity could influence categorisation: Either, the category exists of several diverging exemplars that are shown in succession (exemplar-diverse category Non-A) or the category exemplars themselves are diverse (feature-diverse category Non-A). Our findings replicate the effect of diversity by showing that the experienced diversity in the features of category exemplars yields a widened generalisation, in particular, between the middle stimulus and the stimuli belonging to category Non-A. Similar to our findings from Experiment 1, participants assign more stimuli to the feature-diverse Non-A category than the homogeneous category Non-A. However, we have to acknowledge that our observed effect was too small to be able to find evidence in the form of a boundary shift.
Unexpectedly, we did not find an effect in the exemplar-diverse category in Experiment 2. In Experiment 2, we used single coloured squares with a homogeneous surface as exemplars, while in Experiment 1 exemplars consisted of several objects with the same colour. These results suggest that the effect is more likely to occur with more complex and diverse stimulus material and that the perceived heterogeneity may depend less on differences in exemplars than the diversity of the exemplars themselves.
Taken together, the results show that generalisation processes are susceptible to subtle manipulations of previous experiences, while at the same time highlighting the limits of changing representation of variability via a transfer from another task and the subtle nature of the effect. Nevertheless, we think these results are important given the large literature on generalisation gradients (Ghirlanda & Enquist, 2003; J. C. Lee et al., 2018, 2019; Lovibond et al., 2020) and the importance of generalisation for processes such as categorisation.
In regard to the instruction mode, we could show that whether participants were not told anything about a dependency of the priming phase and the subsequent category learning phase or whether they were told to keep their experiences from the priming phase in mind played a role for the certainty with which participants categorised, but did not interact with the Non-A representations. Thus, we could show the effect of category widening in the explicit condition in both experiments. However, the relation of the two categories (recognisable through the analogue abstract and concrete labels) seems too suffice to make a connection regarding category diversity, as it is evident from the results of the implicit condition.
General discussion
In this study, participants generalised objects after learning about a diverse or homogeneous category Non-A. Participants assigned more stimuli to category Non-A when they had experienced a diverse Non-A representation before the categorisation. In other words, in the condition with the diverse Non-A representation, the found effects suggest a widening of the category representation, compared with the homogeneous condition. This widened generalisation is in line with findings of several previous studies reporting stronger generalisation with higher category variability (Carvalho et al., 2021; Hahn et al., 2005; Rips, 1989). Our results extend these finding by showing that category generalisation is not only widened after experiencing a highly variant category but that a previous experience with a category having a similar structure but no perceptual similarity is enough to influence generalisation width.
Although in Experiment 2, we show this effect by post hoc comparisons, in Experiment 1, this finding is further corroborated by a boundary shift: although the boundary was close to the centre of the standardised continuum in the homogeneous condition, it was lower and thus shifted towards the learned “Flox” stimulus in the diverse category Non-A condition. Experiment 2 aimed to clarify the nature of the diversity that caused wider generalisation and thus contrasted a prior experience that involved category Non-A being comprised of several different exemplars (exemplar-diverse condition) or diverse exemplars, possessing different features (feature-diverse condition). We found that only the feature-diverse condition showed a wider generalisation. Thus, the perception of diverse exemplars is relevant in the process of generalisation. One may guess that many distinct exemplars that are however alike in their homogeneous appearance are represented in an overlapping manner within the same category, yielding no category widening. Then, it is not numerosity of distinct exemplars, but the perceived heterogeneity within each exemplar that fuels the greater generalisation.
The findings occurred not by direct experience with category exemplars but after previous experience with a similar category. These results are in line with the study by Flannagan et al. (1986) who had participants experience several different distributions of category exemplars and found that categorisation was influenced by prior experiences. Similar to these findings, we showed that participants changed their generalisation with respect to their previous experience on category variability and widening their generalisation in the diverse condition—in line with the effects reported for category diversity in tasks without a transfer. An explanation for this behaviour may be that the initial experience with the categories altered the participants’ internal category representation, which then manifested in their categorisation decisions. The results show that not only direct experiences with a task but also experiences of tasks with a similar structure need to be considered when trying to understand how categories are represented and generalised and highlight how susceptible generalisation processes are to manipulations of category representations.
For this transfer, in Experiment 1, an explicit instruction mode unexpectedly fared better than a full explicit instruction about the category structure. A potential explanation could be that the explicit instruction may have confused participants, as indicated by their inability to correctly answer our follow-up question about the manipulation and thus did not increase their ability to transfer the primed category structure to the second task. The clearer instruction about the category’s diversity in Experiment 2 showed that the explicit mode again yielded less assignments to category Non-A, but instruction mode did not interact with category representation. We can thus conclude that a purely implicit previous experience suffices to elicit the observed effect. This observation is in line with the idea that category generalisation may rely less on rules and more on implicit processes such as similarity-based generalisation (Nosofsky, 1986). Even without any instruction, participants are influenced by their prior experience as it was the case in the studies of Flannagan et al. (1986) and Hills et al. (2008).
In future research, the employed manipulation of the category Non-A representation can still be refined, for example, by finding out more about the moderating factors of category generalisation exemplar frequency and range (cf. generalisation from multiple examples in Bayesian inference; Tenenbaum and Griffiths, 2001). Elaborating on the manipulation of the Non-A category representation could also target the relational structure and investigate how abstract knowledge is applied in categorisation tasks. So far, our results are limited to a single (A/Non-A) category task. Future research should investigate whether the results of a wider generalisation after experiencing a diverse category replicate if both categories have defining labels, as it is the case in a traditional A/B categorisation task.
Still, our results have important implications for research on category learning: Prior experiences, possibly made in a relational framework, are rarely subject to the category learning and human generalisation literature. We provide a first account how a common generalisation task is influenced by previous experiences. As has been started with models such as KRES (Rehder & Murphy, 2003) or LISA (Hummel & Holyoak, 2003), a comprehensive view on category learning should take into account prior and possibly relational knowledge. With respect to variability, the generalisation process in these models could be adjusted by these previous experiences.
Our distinction between two kinds of diversity in Experiment 2 further yields important insights for the well-established notion that diversity leads to wider generalisation. We could show that this is especially true when exemplars themselves are heterogeneous, while simply presenting distinct exemplars within a category does not result in this widening.
Taking a broader view, we could adapt a Bayesian perspective on our findings, as it has been suggested for many cognitive domains, including categorisation (Chater et al., 2010). A Bayesian view on categorisation acknowledges that categorisations can be influenced by prior assumptions through background theories—in our case, by experiences with a similar category. Thus, this would allow formalising the intuitive beliefs that people rely on previous experiences within a theoretical Bayesian model, which is then updated based on the experiences people make. This model would also take into account the uncertainty people encounter when, for instance, categorising yet unseen stimuli.
Conclusion
In this study, we could show that prior experience with a diverse or homogeneous category influences categorisation decisions in a subsequent task: A high variant category yielded a widened generalisation, while with homogeneous representations of both categories, equal generalisation was observed. This widened generalisation only became evident when the diversity of Non-A was manipulated by heterogeneous exemplars, not by showing several distinct exemplars in this category. Thus, we could show that category generalisation, an important cognitive ability of inference, is influenced by certain prior experiences. This finding has implications not only for a better understanding of category learning, but any cognitive process that hinges on generalisation.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218231210491 – Supplemental material for Prior experience of variability influences generalisation of unspecified categories
Supplemental material, sj-docx-1-qjp-10.1177_17470218231210491 for Prior experience of variability influences generalisation of unspecified categories by Ann-Katrin Hosch, Philipp Wirtz and Bettina von Helversen in Quarterly Journal of Experimental Psychology
Footnotes
Correction (January 2024):
This article has been updated with minor grammatical or style corrections since its original publication.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
The supplementary material is available at qjep.sagepub.com.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.