
Abstract
It is unclear to what extent natural differences between reading and listening result in differences in the syntactic representations formed in each modality. The present study investigated the occurrence of syntactic priming bidirectionally from reading to listening, and vice versa to examine whether reading and listening share the same syntactic representations in both first language (L1) and second language (L2). Participants performed a lexical decision task in which the experimental words were embedded in sentences with either an ambiguous or a familiar structure. These structures were alternated to produce a priming effect. The modality was manipulated whereby participants (a) first read part of the sentence list and then listened to the rest of the list (reading-listening group), or (b) listened and then read (listening-reading group). In addition, the study involved two within-modality lists in which participants either read or listened to the whole list. The L1 group showed within-modal priming in both listening and reading as well as a cross-modal priming effect. Although L2 speakers showed priming in reading, the effect was absent in listening and weak in the listening-reading condition. The absence of priming in L2 listening was attributed to difficulties in L2 listening rather than to an inability to produce abstract priming.
Introduction
Syntactic priming
Syntactic priming in comprehension refers to facilitation in the processing of a sentence (target sentence) following the processing of a preceding unrelated sentence(s) (prime sentence) that shares the same syntactic structure (for reviews, see Pickering & Ferreira, 2008; Tooley & Traxler, 2010). For example, language users process an ambiguous modifier prepositional phrase (PP) as in “The girl hit the boy
Syntactic priming effect has been detected cross-modally across production modalities (i.e., from speaking to writing and from writing to speaking) (Cleland & Pickering, 2006). In comprehension, syntactic priming was found from reading to listening in L1 in studies that employed a visual world paradigm to examine priming in dative constructions (Arai et al., 2007; Carminati et al., 2008; Scheepers & Crocker, 2004; Thothathiri & Snedeker, 2008). For example, Arai et al. (2007) conducted a study in which participants first read a prime sentence, and then listened to a target sentence in either a prepositional object dative structure as in “the pirate will send the necklace to the princess” or a double object dative structure as in “the pirate will send the princess the necklace.” Target sentences were presented with pictures that depict the three referents in the sentence (e.g., a picture of a pirate, a princess, and a necklace). The participants’ eye movements were recorded upon hearing the verb in the target (i.e., “will send”). Results showed that participants were more likely to gaze anticipatorily at the princess after having read a double object prime aloud, but more likely to gaze at the necklace after having read a prepositional object prime. Findings from the visual world paradigm, therefore, showed the occurrence of a priming effect that transferred from reading to listening. Nevertheless, the opposite direction (i.e., from listening to reading) has not yet been investigated. Furthermore, cross-modal priming has yet to be investigated in L2 speakers.
A mode of syntactic priming that has been studied within-modally is the cumulative priming paradigm (Fine et al., 2013; Fine & Jaeger, 2013; Fine & Jaeger, 2016; Kaschak & Glenberg, 2004; Wells et al., 2009) in which participants gradually adapt to an unfamiliar structure after repeated exposure to several instances of that structure. This syntactic adaptation is backed by a statistical learning account in which the language user stores information about the probability of occurrence of the encountered syntactic features (Kleinschmidt et al., 2012; Kleinschmidt & Jaeger, 2015). When exposed to a new context with different probabilities, language users dynamically employ statistical learning mechanisms to update their knowledge, preferences, and predictions according to the probabilities of the new context. Syntactic structures that are more frequently encountered are assigned a higher probability and subsequently become more predicted and preferred. For example, repeated exposure led readers to adapt to syntactic structures that were initially judged as ungrammatical to the extent that they became more easily processed (Luka & Barsalou, 2005) and even produced (Kaschak & Glenberg, 2004).
Studies employing the artificial grammar learning paradigm demonstrated that the ability to extract probabilistic information from the environment is modality-specific (Conway & Christiansen, 2005; Conway & Christiansen, 2006; Li et al., 2018; Redington & Chater, 1996). Learning a grammatical structure in one modality cannot, therefore, be transferred to a different modality. For example, Conway and Christiansen (2006) exposed participants to a visual colour sequence generated from one grammar and an auditory tone sequence generated from another grammar. While both modalities were presented simultaneously in the training phase, only one modality was employed in the testing phase. Participants could not generalise the grammar learnt through one modality in the training phase to a different modality in the test phase. Thus, results showed that statistical learning is modality-specific. Given that the cumulative priming paradigm depends on statistical learning of the syntactic probabilities in the linguistic environment, it can be predicted that the cumulative priming effect cannot transfer across different comprehension modalities. Nevertheless, Tunney and Altmann (2001) argued that the modality-specific episodic repeated fragments employed in artificial grammar paradigm studies differ from the modality-independent transitional probability that characterises statistical learning in language. This lack of consensus necessitates a further investigation of the cross-modal transfer.
Differences between reading and listening
The dissociation in syntactic processing between listening and reading is supported by neuropsychological studies in which aphasic patients maintain their visual orthographic ability in the presence of a dysfunctional oral phonological system, and vice versa. Tyler et al. (1995) found deficits in verbal, but not oral, production of abstract words among deep dyslexic patients. In addition, Endo et al. (1996) observed deficits in performing visual naming tasks as compared with auditory naming tasks in aphasia. At the level of syntax, Caramazza and Hillis (1991) examined the production of nouns versus verbs in two neurologically impaired patients, H.W. and S.J.D. H.W. made more errors on verbs than on nouns in oral but not in written output, whereas S.J.D. showed the same verb production deficit in writing, but not in speech. In a subsequent study, Hillis and Caramazza (1995) found that a neurologically impaired patient, E.B.A., showed more impairment in noun production in oral than in written output but more impairment in recognising and comprehending written verbs than oral verbs. These results indicate a dissociation between the oral and written modalities regarding the production and processing of word grammatical categories (i.e., nouns vs verbs).
At the sentence level, comprehension involves integrating the incoming words into the sentence context by combining semantic, syntactic, and pragmatic sources of information in both bottom-up and top-down manner. One can expect sentence integration to be similar in both listening and reading due to the same semantic, syntactic, and pragmatic roles being employed in both modalities. For example, language users who show high proficiency in reading comprehension are more likely to be highly proficient in listening comprehension (Protopapas et al., 2012; Tilstra et al., 2009; Townsend et al., 1987). Nevertheless, there are some modality-specific characteristics that might result in differences in the representation resulting in each modality. For example, the entire discourse is simultaneously present in reading, meaning that the reader might retreat at any point to the beginning of the sentence, whereas listening disappears instantaneously, so listeners cannot backtrack. Accordingly, there is evidence that monolingual listeners tend to perform shallow and partial syntactic processing to be able to keep up with the rapidly incoming linguistic input in listening as opposed to reading (Christianson et al., 2001; Ferreira et al., 2001).
Syntactic priming in L2
Although several studies investigated comprehension cumulative priming in L1 (Fine et al., 2013; Fine & Jaeger, 2013; Fine & Jaeger, 2016; Kaschak & Glenberg, 2004; Wells et al., 2009), the phenomenon was examined in L2 by only one study (Kaan et al., 2018). Kaan et al. (2018) employed a self-paced reading task to examine cumulative adaptation to two types of syntactic ambiguity by both native and non-native English speakers. The two ambiguous structures tested were filler-gap constructions in wh-clauses as in “the builder wondered what the worker repaired the leak with before going home,” and coordination ambiguity as in “the servant cleaned the table and the floor was cleaned by the maid.” Only native speakers showed cumulative adaptation. It can, therefore, be inferred that L2 processing is not sensitive to the statistical learning mechanisms underlying cumulative priming in reading; however, previous evidence is very limited. No L2 cumulative priming research has been conducted in the listening modality. Therefore, further studies are needed to gain robust relevant conclusions.
Nevertheless, studies that used modes of syntactic priming that differ from the cumulative paradigm showed that syntactic priming is stronger in L2 than in L1 in both listening (Nitschke et al., 2010; Nitschke et al., 2014) and reading (Wei et al., 2017, 2019). L2 advantage was accounted for by Pickering and Branigan (1999) who suggested that priming is a function of limited resources. L2 speakers who naturally possess limited cognitive resources are more likely to be susceptible to priming than L1 speakers who are more experienced with the language, and therefore store alternatives of the appropriate structure. These alternatives may suppress the effect of the prime sentence. The greater magnitude of priming in L2 can also be accounted for by the inverse frequency effect (Ledoux et al., 2007; Scheepers & Crocker, 2004; Sturt et al., 2010; Traxler, 2008; Traxler et al., 2014). The inverse frequency effect refers to the common finding that syntactic structures occurring relatively infrequently tend to produce greater priming than more frequent structures. Generally, L2 speakers have limited experience with linguistic regularities due to their less frequent encounter with L2 syntactic structures, which might be the reason for the greater syntactic priming effect in L2.
However, it can be predicted that L2 speakers might face more difficulty in listening than in reading due to the time constraint imposed in listening. In real life, the speech stream flows spontaneously at the talker’s pace. In contrast, reading is self-paced. The speed of the aural input might cause the mental resources to barely suffice the processing of the bottom-up signal at the expense of the syntactic integration process. Previous evidence showed shallow syntactic processing among L2 speakers when performing temporally constrained online tasks (Clahsen & Felser, 2006). This shallow processing causes over-reliance on semantic, rather than syntactic, representation in sentence online processing (Felser et al., 2003; Guo et al., 2008; Papadopoulou & Clahsen, 2003). Accordingly, the time constraints involved in the listening condition in the current study, as well as in the real life, might lead L2 listeners to rely on semantic features in the sentence and subsequently become more resistant to syntactic priming.
The present study
In this study, we investigate whether the syntactic priming effect produced in each of the listening or reading modalities can transfer to the other modality in both L1 and L2. To achieve this, the present study employed a cumulative priming paradigm in which the first 80% of the experimental sentences acted as primes, whereas the last 20% of the sentences acted as targets on which the priming effect was assessed. In the cross-modal priming from reading to listening condition, the prime sentences were read, and the targets were listened to, whereas in the opposite listening to reading condition, the prime sentences were listened to and the target sentences were read.
Although cumulative priming has been shown to occur within-modally in both listening and reading, there is evidence that the statistical learning mechanism underlying the cumulative priming effect is modality-specific. As for L2 speakers, difficulties associated with listening might hinder the occurrence of syntactic adaptation in listening, and subsequently from listening to reading. Another possibility is that L2 speakers might tend to exploit the grammatical knowledge resulting from syntactic priming to mediate listening difficulties. Syntactic priming in this case would disambiguate the speech signal and guide the processor’s analysis to match the syntactic probabilities of the context, leading to the occurrence of priming in listening and from listening to reading in L2. The absence of priming in both reading and listening would indicate that L2 speakers are less able to adapt to the syntactic probabilities of the context irrespective of the modality.
Experiment 1: cross-modal priming in L1
The aim of Experiment 1 is to examine whether the processing of an ambiguous structure in one modality (reading or listening) facilitates the processing of the same structure in the other modality in L1. To achieve this, the processing of target sentences such as (1a, see below) will be assessed after exposure to multiple sentences of the same structure.
1a. The man fixed the box with a hole (low-attachment [LA] structure)
1b. The apprentice fixed the mirror with a tape (high-attachment [HA] structure)
In this type of structure, the PP can either be a modifier of the preceding noun as in (1a) “with a hole” or an instrument of the verb as in (1b) “with a tape.” Being less familiar, the LA structure as in (1a) causes processing difficulty when the perceivers incorrectly analyse the PP as an instrument of the verb (Rayner et al., 1983). Previous research demonstrated that this ambiguous LA structure produces a syntactic priming effect that facilitates target sentence comprehension both in listening (Branigan et al., 2005) and reading (Boudewyn et al., 2014; Traxler, 2008). The HA as in (1b) was used as a control (baseline) to produce a no-priming condition to which the processing of the ambiguous LA structure can be compared.
In the present study, all low-attached PPs carry an attribute semantic role “with a hole,” whereas the high-attached PPs carry an instrument semantic role “with a tape.” The semantic role was unified across the experimental sentences for each structure because previous evidence suggests that the semantic role of the PP biases the parsing of the pp attachment structure (Taraban & McClelland, 1988).
Method
Participants
The study included 80 participants who were between 18 and 23 (M = 19.2) years of age from the student cohort at the University of Leeds. All reported normal vision and hearing, and no neurological impairment. They were all native English speakers and formed the L1 group. Participants provided written informed consent. The experiment was reviewed and approved by the University of Leeds Research Ethics Committee (no.17-0098).
Materials
Participants were assigned to one of four lists: (a) two within-modality lists and (b) two cross-modality lists.
The two
The two
In addition to the experimental sentences, 10 word and 40 non-word filler sentences intervened between the prime and target sentences. The filler sentences are of randomly chosen structures and occupy different positions in the list for each participant. For the purpose of the lexical decision task, some of the filler sentences ended with a non-word. Non-words were generated using a stimulus generation programme created by the English lexicon project (Balota et al., 2007). Non-words were matched with real words for mean word length and mean bigram frequency. Six practice items were presented at the start of the experimental session to allow participants to practice the task and ask questions about the procedure. Each experimental or filler sentence was followed by a yes/no comprehension question. Comprehension questions were inserted to prevent the participants from directing their attention solely to the sentence’s final critical word instead of the whole sentence, which would have hardened the cumulation of the syntactic priming effect across the sentence list. For most of the questions, the correct answer did not require the participants to resolve the syntactic ambiguity. This was done to obscure the main aim of the study so that any resulting facilitation in processing can be attributed to the implicit priming effect rather than the participants’ explicit memory of the experimental stimuli. See Appendix S1 in the online Supplementary Material for a full set of experimental and filler items.
The predictability of the final word in the sentence was controlled for by a Cloze test. The Cloze test was a sentence completion task in which all the experimental sentences were presented with the final critical words replaced with a gap. Twenty participants (who were all L1 speakers) were asked to fill in the gap with the first word that comes to mind. The experimental words produced an average cloze probability of 2.3% (range: 0%–5%), indicating none of the words were particularly predictable. To control for the lexical characteristics of the target words, the two groups of words embedded in each of the HA and LA structure sentences were matched for response time latency values that were extracted from the British Lexicon Project (Keuleers et al., 2012).
Procedure
The stimuli in this experiment were presented using DMDX (Forster & Forster, 2003). A female speaker with a standard British English accent recorded the listening stimuli using Audacity software. Both LA and HA sentences were recorded using a neutral intonation such that a stop before the preposition phrase was avoided to prevent bias to the HA structure. Each participant was tested individually in a silent room. Participants were instructed to listen to or read the sentences and to state whether the last word was a real word or a non-word by pressing one of two keys. In the reading trials, a fixation point first appeared for 500 ms on the screen at the same place where the first letter of the sentence appeared. Participants were instructed to always keep their fingers on the buttons to encourage quick responses. The “yes” response key was always pressed with the dominant hand, and the “no” response with the non-dominant hand. After that, sentence context up to the word preceding the final word appeared for 3,000 ms with the position of the final target word marked with dashes. The 3-s presentation time was identified through a pilot study in which 10 native English speakers were asked to read for comprehension all the experimental sentences up till the final word. The reading times were calculated and averaged across sentences for each reader and across readers. Immediately after the sentence context disappeared from the screen, the final target word was displayed for 1,000 ms. In the listening trials, a fixation point appeared on the screen for 500 ms before the sentence was presented via headphones. The speech rate was 140 wpm. In both listening and reading trials, participants were given 2,500 ms to give a response. Response time was measured by DMDX from the onset of the target word. Following both reading and listening trials, the probe “Question” was displayed for 500 ms, then the comprehension question was presented visually in the reading trials and orally in the listening trials. Participants were allowed 2,500 ms to answer the comprehension question.
Results
Erroneous responses, reaction times less than 100 ms and greater than 2,000 ms, and data from sentences after which participants responded incorrectly to the comprehension question were all excluded from the analysis, resulting in the overall elimination of 12.6%, 18.3%, 13.5%, 17.5% of the data for the reading, reading to listening, listening, and listening to reading groups, respectively.
Within-modal priming
Repeated exposure to the ambiguous LA structure throughout the list was expected to lead to a cumulative priming effect that would eliminate the processing difficulty towards the end of the list. As a result, words in sentences in the final block are expected to be more easily processed than in sentences occurring earlier in the list. The effect is predicted to be observed with the ambiguous LA structure rather than with its familiar HA counterpart. To assess the occurrence of such within-modal cumulative priming effect, error rates and RTs were analysed using logit/linear mixed-effects models calculated in R (R Development Core Team, 2008) using the lme4 package with random intercepts and slopes (Baayen et al., 2008). Both dependent measures were regressed onto the main effects and interactions of sentence structure (HA vs LA), and block order (from 1 to 5). To control for task adaptation, log-transformed stimulus order was also included as a predictor representing item position among other experimental, filler, and practice items (Fine et al., 2013). The difference between block order and stimulus order is that block order is a predictor of the occurrence of syntactic priming. This is because the exposure to more experimental items throughout the list is predicted to produce the priming effect in late blocks compared with early blocks, whereas stimulus order is a predictor of the increased speed of processing resulting from increased adaptation to the task throughout the list (i.e., learning/training effect). Maximal random-effects structure justified by the design was included. The best-fitting random-effect structure was determined by beginning with the maximal version of the model. If the maximal model would not show convergence, random effects were eliminated based on their variance such that random effects causing the least variance were removed first until the model reached convergence. 1
Although accurate responses to the comprehension questions are not used as a dependent variable in the current experiments, comprehension question response accuracy was analysed to give insight into the participants’ overall performance and the task level of difficulty. Accuracy scores are provided in Table S1 (Appendix S2 in Supplementary Materials). Comprehension question accuracy data showed a main effect of block order in listening (β = 0.34, SE = 0.1454, z = 2.39, p = .016). Questions in the last block were answered more accurately than in the first block (p < .05). No main effects or interaction was found in reading.
Mixed-effects model estimates for reaction times in within-modal listening and reading, first language speakers.
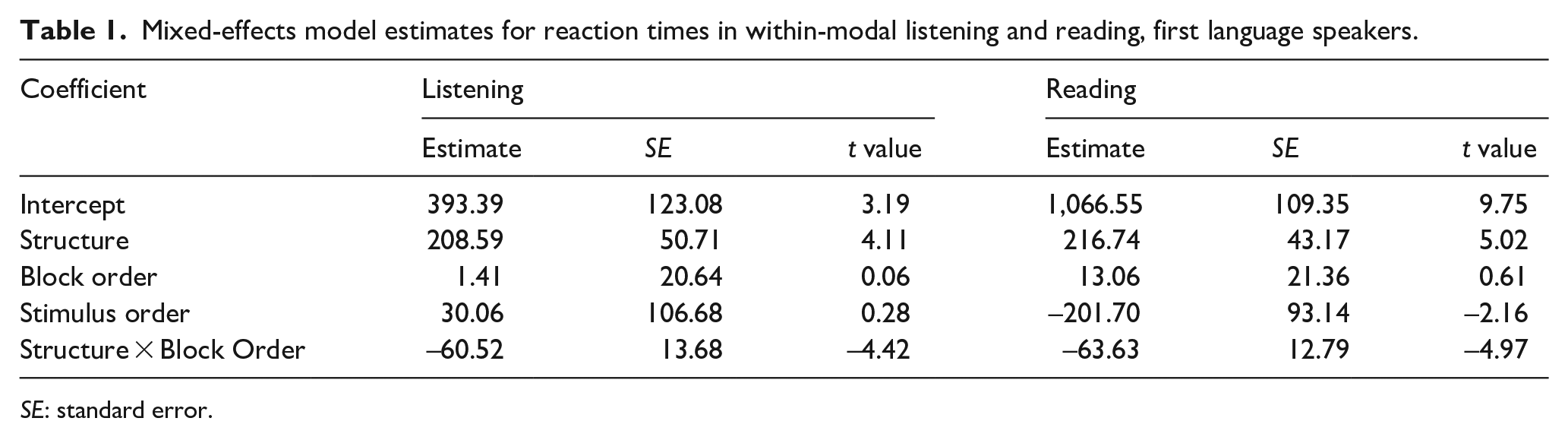
SE: standard error.
Error rate results of the reading condition revealed a main effect of stimulus order (β = 2.99, SE = 1.43, z = 2.08, p < .05). Crucially, error rates revealed no interaction between structure and block order in both reading (β = 0.06, SE = 0.31, z = 0.2, p = .8) and listening (β = 0.02, SE = 0.37, z = 0.07, p = .9). All items were responded to with equal accuracy throughout the whole list, indicating the absence of within-modal priming effect in both reading and listening.
As for RT data analysis, the reading condition revealed a main effect of structure (β = 216.74, SE = 43.17, t = 5.02, p < .001) and stimulus order (β = –201.70, SE = 93.14, t = –2.1, p < .05). Crucially, there was an interaction between structure and block order (β = –63.63, SE = 12.79, t = –4.9, p < .001), whereby LA items in the first block elicited longer reaction times than LA items in the third (p < .05), fourth (p < .001), and fifth (p < .001) blocks. In listening, there was a main effect of structure (β = 208.59, SE = 50.71, t = 4.1, p < .001). In addition, there was an interaction of structure and block order (β = –60.52, SE = 13.6, t = –4.4, p < .001), with post hoc comparisons revealing that LA sentences in the first block elicited slower response times than sentences occurring in the third block (p < .01), fourth block (p < .05), and fifth block (p < .001). This indicates the occurrence of within-modal cumulative priming in both reading and listening. Model estimates are presented in Table 1.
Cross-modal priming
Given that syntactic priming in the within-modal list was not evident by error rates data, this dependent measure is excluded from the analysis conducted to examine cross-modal priming. To examine the transfer of the syntactic priming effect across different modalities (i.e., from listening to reading, and vice versa), we compared RTs in the last blocks for the within-modal versus the cross-modal lists. If the critical words in the sentences included in the fifth block are processed at equal speeds in both lists, this would indicate that a syntactic priming effect was transferred from the modality of the first four blocks to the different modality of the fifth block in the cross-modal list.
Fixed effects in the structure of the regression model included group (cross-modal vs within-modal), structure (LA vs HA) and the interaction between group and structure. The model included maximal random-effects structure justified by the design. 2 To examine the occurrence of priming from listening to reading, reaction times in the last block were compared between the within- and the cross-modal groups. Results revealed no Group × Structure interaction (β = –80.23, SE = 82.39, t = –0.9, p = .3) as LA items in the fifth blocks of both the listening-reading list (i.e., reading block) and the reading list elicited equal reaction times, indicating the occurrence of cross-modal priming from listening to reading (see Figure 1). Similarly, comparing reaction times of the last (listening) block between the listening and the reading to listening groups revealed no group by structure interaction (β = –38.66, SE = 64.47, t = –0.60, p = .5), indicating the occurrence of cross-modal priming from reading to listening (see Figure 2).
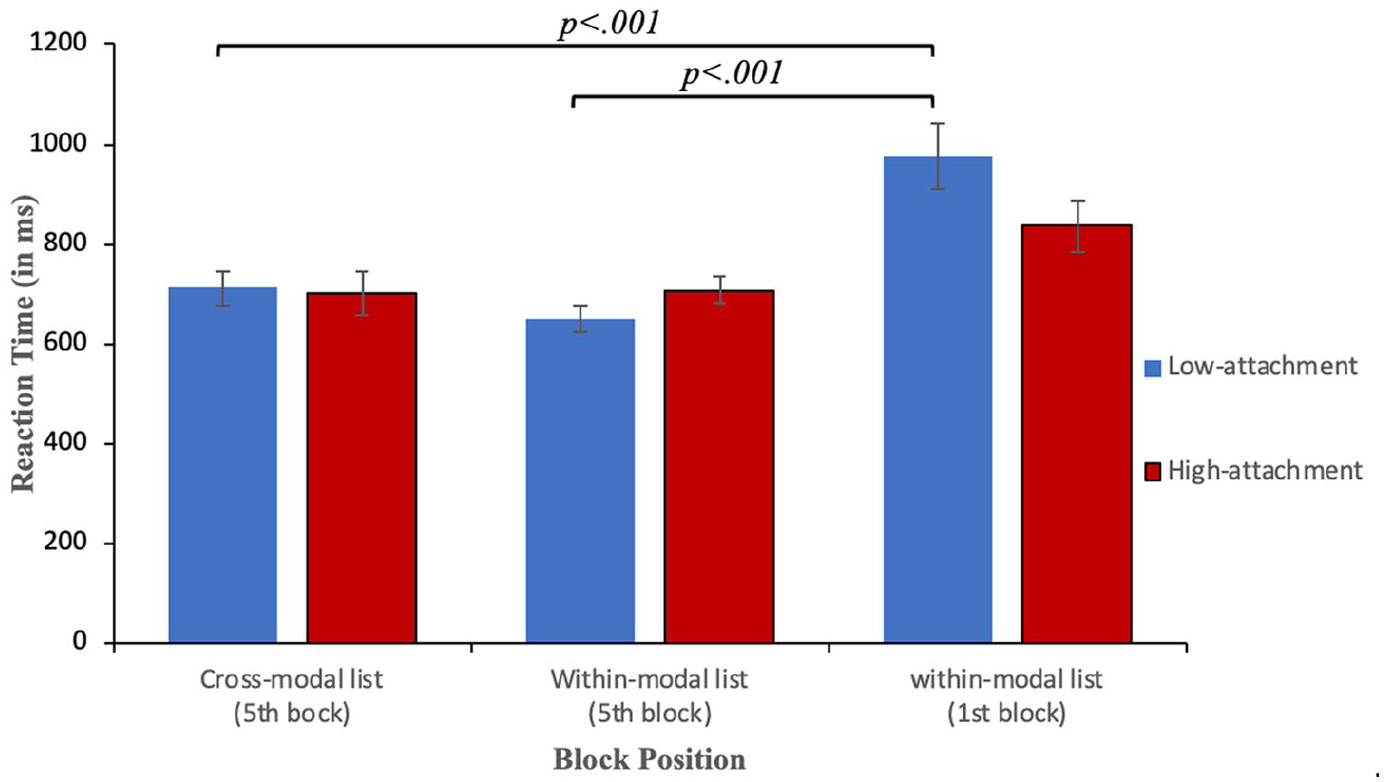
Reaction times (in ms) in reading split by structure and block position for first language speakers. Low-attachment target words are shown as blue bars and high-attachment target words as red bars. The error bars indicate SEM.
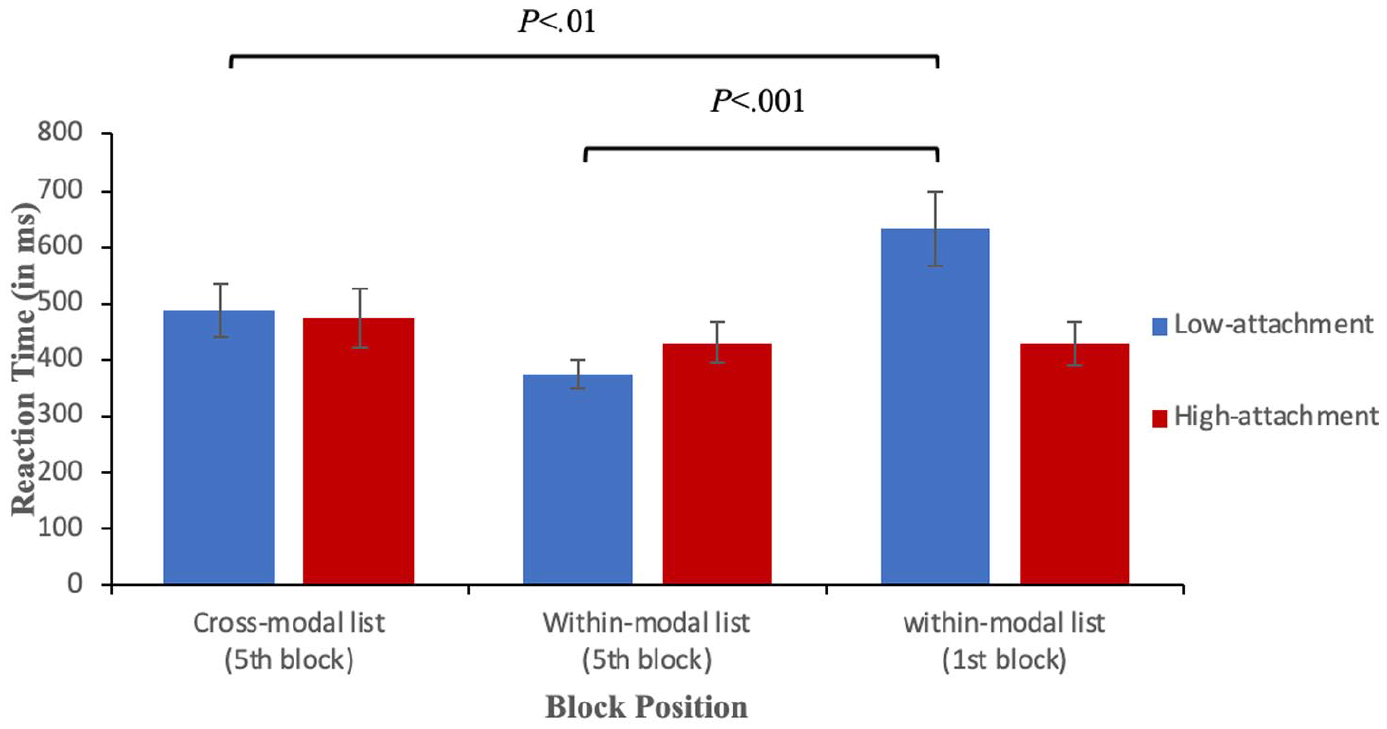
Response times (in ms) in listening split by structure and block position for first language speakers. Low-attachment target words are shown as blue bars and high-attachment target words as red bars. The error bars indicate SEM.
Cross-modal priming was additionally examined by comparing the fifth block of the cross-modal list with the first block of the within-modal list. A significant difference in processing between the two blocks would indicate that a priming effect cumulated throughout the cross-modal list leading sentences in the last block to be more easily processed than those in the first block of the within-modal list. Another model was fitted and included the main effects and interaction of sentence structure (LA vs HA) and group (fifth block of cross-modal list vs first block of within-modal list). To examine the occurrence of priming from listening to reading, reaction times in the last (reading) block of the listening-reading list were compared with reaction times in the first block of the reading list. There was a main effect of structure, (β = 138.45, SE = 50.40, t = 2.74, p < .01). In addition, there was a main effect of group (β = –127.03, SE = 56.50, t = –2.24, p < .05), whereby sentences appearing in the first block processed less rapidly (i.e., with higher reaction times) than items appearing in the final block. In addition, there was an interaction (β = –188.23, SE = 72.03, t = –2.6, p < .001). LA items in the final reading block of the listening-to-reading list were processed more rapidly than items of the same structure in the first block of the reading list, which strengthens the evidence supporting the occurrence of cross-modal priming from listening to reading (see Figure 1).
To examine cross-modal priming from reading to listening, reaction times were compared for the fifth block (listening block) of the cross-modal reading-to-listening list and the first block of the within-modal listening list, which revealed an interaction (β = 208.08, SE = 77.21, t = 2.69, p < .01). LA sentences in the fifth block (listening block) of the cross-modal list were processed more easily than LA sentences in the first block of the within-modal listening list. This indicates the occurrence of cross-modal priming from reading to listening (see Figure 2).
To ensure that the cross-modal results can be attributed to the priming effect and not to the general differences in lexical decision between the tested groups, separate analyses were conducted for each cross-modal condition using reaction times to filler items and their error rates as dependent variables. Although error rates could not act as a dependent variable in the main analysis, it was used in this filler complementary analysis to give extra insight into any potential group differences that did not stem from the priming effect. Linear/logit mixed-effects models were fitted. Both models included (group) as a fixed variable (last block of the cross-modal list group vs last block of the within modal list group) or (first block of the within-modal list group vs last block of the cross-modal list group). The model had the maximal random-effects structure justified by the design. Separate analyses were conducted for word and non-word items.
Word filler item data revealed no differences between the last blocks of the within-modal versus cross-modal lists in reading reaction time (β = –76.96, SE = 93.22, t = –0.82), listening reaction time (β = –24.41, SE = 76.45, t = –0.319), reading error rates (β = 0.265, SE = 0.731, z = 0.363), and listening error rates (β = 0.164, SE = 0.573, z = 0.286). In addition, no differences were revealed between the first block in the within-modal versus the last block in the cross-modal condition in reading reaction time (β = –199.9, SE = 128.0, t = –1.56), listening reaction time (β = 27.11, SE = 61.96, t = 0.43), reading error rates (β = 0.47, SE = 0.69, z = 0.67) and listening error rates (β = 0.64, SE = 0.67, z = –0.96).
Similarly, non-word filler item data revealed no differences between the last blocks of the within-modal versus cross-modal lists in reading reaction time (β = 60.92, SE = 43.37, t = 1.40), listening reaction time (β = 96.06, SE = 58.89, t = 0.78), reading error rates (β = 0.43, SE = 0.47, z = 0.91), and listening error rates (β = 0.48, SE = 0.63, z = 0.75). No differences in reading reaction time were revealed between the first block of the within-modal list versus the last block of the cross-modal list (β = –119.39, SE = 66.27, t = –1.80), listening reaction time (β = 31.44, SE = 44.65, t = 0.70), reading error rates (β = 0.23, SE = 0.48, z = 0.48), and listening error rates (β = 0.55, SE = 0.47, z = 1.15).
Experiment 2: cross-modal priming in L2
The aim of Experiment 2 is to examine whether syntactic priming can transfer cross-modally in L2. The answer to this question can indicate whether L2 syntactic priming is a shared mechanism between reading and listening.
Method
Participants
Eighty native Arabic speakers with English as a second language participated in Experiment 2 and formed the L2 group of the study. Participant ages ranged from 17 to 33 years (M = 21.6 years). All participants reported normal to corrected hearing and vision, and no neurological impairments. Participants responded to a language history questionnaire before participation. All participants started to learn English between the ages of 8 and 12 years and were exposed to English in media and textbooks daily. Fifty-two participants (65%) lived in a L1-dominant environment. All participants were either undergraduate or postgraduate students and had the minimum English proficiency required for enrolment at the University of Leeds with an IELTS (International English Language Testing System) total score of 6 out of 8 and a TOEFL (Test of English as a Foreign Language) score of 87 out of 120. Five students were enrolled in English language courses at the University of Leeds to further improve their language ability. Table 2 presents self-rated proficiency in English for the L2 group. Participants provided written informed consent. The experiment was reviewed and approved by the University of Leeds Research Ethics Committee (no.17-0098).
Mean self-reported ratings (7-point Likert-type scale) of proficiency in English as a second language for Experiment 4.
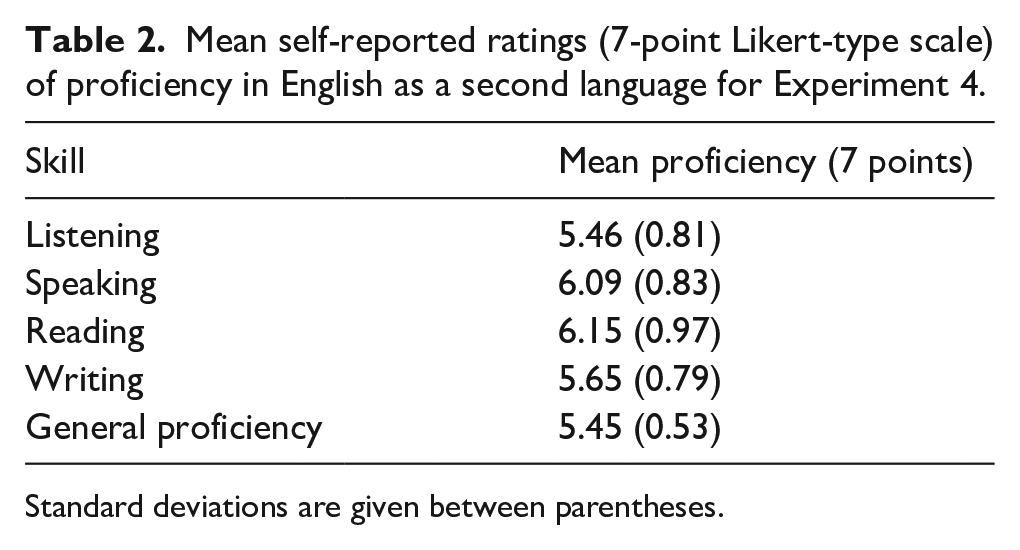
Standard deviations are given between parentheses.
Material and procedure
Stimulus, materials, and procedures were the same as in Experiment 1.
Results
Erroneous responses, reaction times less than 100 ms and greater than 2,000 ms, and data from sentences after which participants responded incorrectly to the comprehension question were all excluded from the analysis, resulting in the overall elimination of 18.16%, 15.8%, and 25.8% of the data for the reading, the fifth block (reading block) of the listening-reading, and listening conditions, respectively. The same logit/linear models as in Experiment 1 were fitted for the examination of within- and cross-modal priming. 3
Within-modal priming
Comprehension question response accuracy in reading showed a main effect of structure (β = 1.93, SE = 0.61, z = 3.13, p < .01). Questions following HA structure were answered more accurately than those following the LA structure (p < .01). There was also a main effect of block order (β = 0.30, SE = 0.13, z = 2.21, p < .001), as questions in the fifth block were answered more accurately than in the first block (p < .05). Furthermore, there was a Structure × Block Order interaction (β = –0.38, SE = 0.17, z = –2.20, p < .05) as LA sentences in the fifth block were answered more accurately than those in the first (p < .01) and second blocks (p < .05). There were no main effects or interaction in listening.
Error rate data for reading showed no interaction between structure and block order (β = –0.34, SE = 0.30, z = –1.15, p = .2). Similarly, in listening, there was no interaction between structure and block order (β = –0.36, SE = 0.25, z = –1.4, p = .1). Participants responded with equal accuracy to both structures throughout the whole lists in reading and listening. Given that error data of both the reading and listening lists showed no priming effect, it is not possible to use it as a measure in an analysis that uses a within-modal list as a control for the occurrence of cross-modal priming. Hence, error rates analysis of cross-modal priming from listening to reading and from reading to listening could not be conducted.
For the within-modal conditions, model estimates for reaction time data of the reading condition (Table 3) showed a main effect of structure (β = 346.3, SE = 52.12, t = 6.6, p < .001). A significant interaction between block order and structure (β = –71.8, SE = 15.32, t = –4.6, p < .001) was also present, supporting the occurrence of cumulative priming within the reading modality for second language (L2) speaker participants. Post hoc comparisons revealed that LA sentences in the first block elicited slower response times than sentences occurring in the second and third blocks (ps < .01) as well as the fourth and fifth blocks (ps < .001). Listening data revealed a main effect of structure (β = 210.8, SE = 85.8, t = 2.4, p < .01) with LA structure eliciting longer reaction times than HA structure. Unlike reading, RT data for listening showed no interaction (β = –20.6, SE = 24.3, t = –0.8, p = .3). Items throughout the within-modal listening list were processed at equal speed, suggesting the absence of cumulative priming in listening.
Mixed-effects model estimates for response times in within-modal listening and reading, second language speakers.
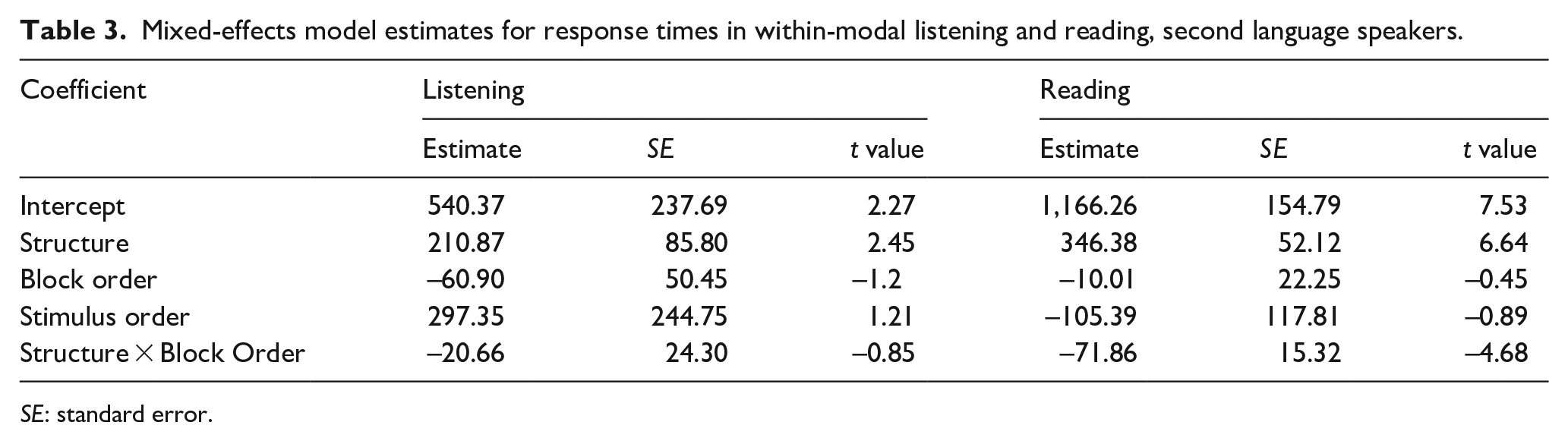
SE: standard error.
Cross-modal priming
Cross-modal priming from reading to listening cannot be conducted because of the absence of the control condition (i.e., within-modal priming in listening). To examine cross-modal priming from listening to reading, reaction times were regressed onto the main effects and interaction of sentence structure (HA vs LA) and block position (fifth block of the cross-modal list vs fifth block of the within-modal list). Comparing the fifth block (i.e., reading block) of the listening-reading list and the fifth block of the reading list revealed no interaction (β = –88.2, SE = 64.1, t = –1.3, p = .1). In addition, a second model was fitted whereby reaction times were regressed onto the main effects and interactions of sentence structure (HA vs LA) and block position (fifth block of the cross-modal list vs first block of the within-modal list). Results revealed no interaction (β = 129.1, SE = 72.9, t = 1.7, p = .07), hence items in the fifth block of the listening-reading list were processed at equal speed as items in the first block of the reading list. This indicates the occurrence of weak cross-modal syntactic priming from listening to reading among L2 speakers (see Figure 3).
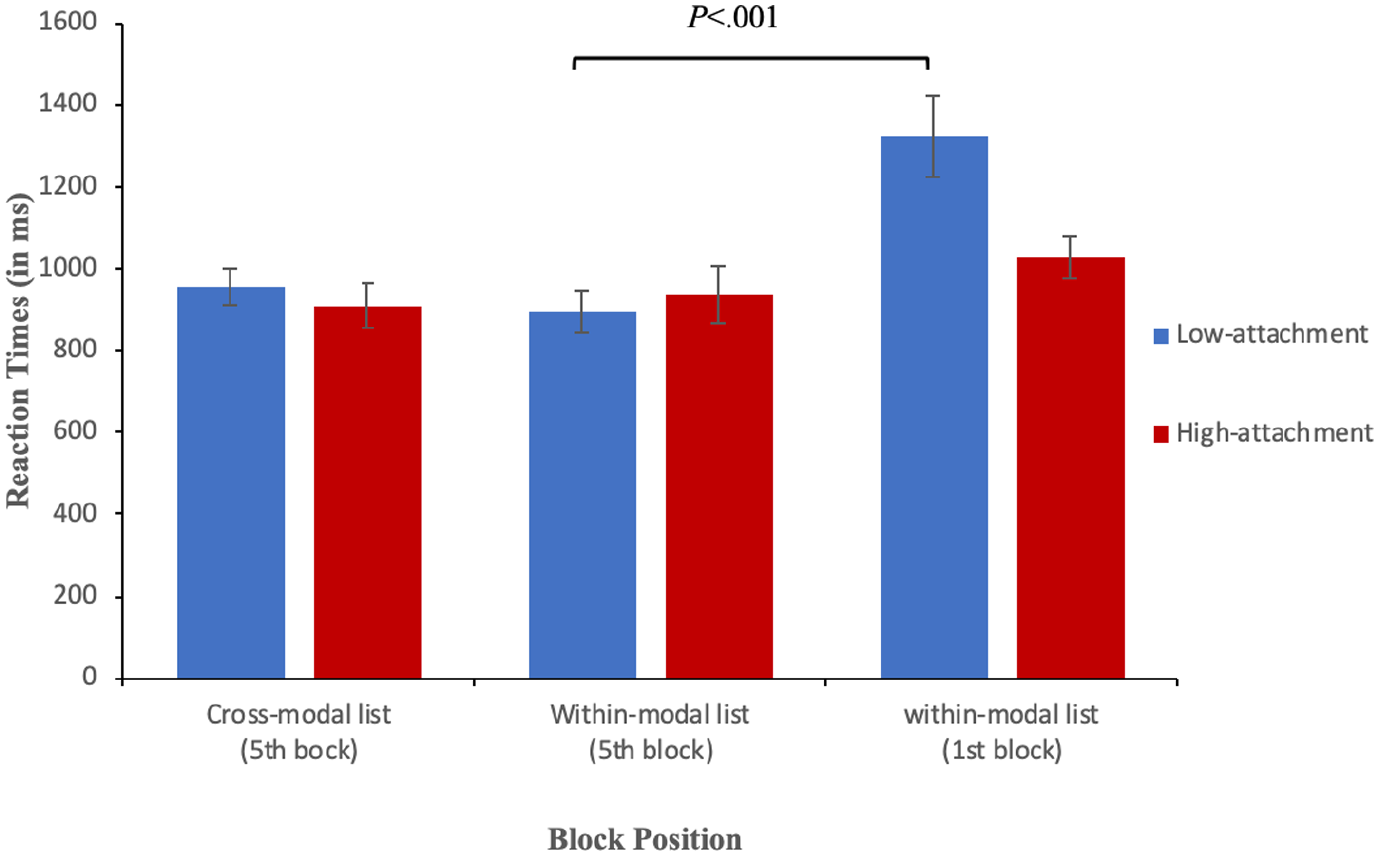
Response times (in ms) in reading split by structure and block position for second language speakers. Low-attachment target words are shown as blue bars and high-attachment target words as red bars. The error bars indicate SEM.
To make sure that the tested groups are comparable with regard to their general proficiency, self-reported general proficiency was compared between the group pairs. Independent-samples t test showed no differences in self-rated general language proficiency across all group pairs (all ps > .05).
Like Experiment 1, reaction times and error rate responses to filler items were compared across conditions to ensure that the tested groups are comparable with regard to lexical decision. Word filler item data showed no differences between the last blocks of the within-modal versus cross-modal lists in reading reaction time (β = 24.26, SE = 59.35, t = 0.40) and reading error rates (β = –0.50, SE = 0.82, z = –0.60). Non-word filler items similarly showed no differences in reading reaction time (β = –9.06, SE = 55.74, t = –0.16) and reading error rates (β = –0.28, SE = 0.37, z = –0.75). The comparison between the first block of the within-modal condition versus the last block of the cross-modal condition showed no between-group differences in word items reading reaction time (β = –100.54, SE = 63.59, t = –1.58), word item reading error rates (β = –0.88, SE = 0.96, z = –0.91), non-word items reaction time (β = –86.53, SE = 49.73, t = –1.74), and non-word items error rates (β = –0.28, SE = 0.38, z = –0.75).
Discussion
Current results demonstrate the modality independence of syntactic priming in L1, supporting an account of shared syntactic representations between listening and reading comprehension. Previous research employing the artificial grammar paradigm showed that the ability to extract regularities from a grammatical sequence is dependent on the modality of exposure (Conway & Christiansen, 2006; Li et al., 2018). Learning a grammatical structure in one modality cannot, therefore, be transferred to a different modality. However, current results contrast this view. The occurrence of cross-modal cumulative syntactic priming indicates that the underlying statistical learning mechanism can transfer across modalities. Subsequently, the syntactic priming effect produced in each modality can transfer to the other causing facilitation in the processing of the target sentences. However, L2 speakers were found to perform differently from L1 group in the listening modality. Although cumulative priming occurred in L2 reading, no priming was observed in listening.
The discrepancy between current results and the previous evidence provided by the artificial grammar paradigm can be accounted for by distinguishing between the episodic fragmented repetition involved in artificial grammar and the transitional probability mechanism underlying language processing (Tunney & Altmann, 2001). In language, statistical learning is probabilistic, meaning that there is a probability associated with the likelihood of occurrence for each syntactic attachment. Given the repeated exposure in the current study, the likelihood that a given PP be attached to the preceding noun rather than the verb (i.e., LA) increased and was therefore attributed a higher probability whereas the HA structure acquired a lower probability. In artificial grammar, what transfers is the repetitive sequential structure, whereas in priming, it is the probability associated with each syntactic attachment that transfers cross-modally. Our study, to the best of our knowledge, is the first to examine the question of modal transfer using a paradigm that differs from the artificial grammar paradigm (i.e., cumulative priming).
The absence of priming in L2 listening can be attributed to the time constraints associated with listening both in the current study as well as in real life. While reading is a self-paced process, listening depends on the speed of the incoming speech stream that is out of the listener’s control. In the present study, despite the reading task was not self-paced for methodological reasons, sentence context in the reading modality appeared for 3 s on the screen before the critical word was presented for 1,000 ms, which allowed the visual input a prolonged presentation time in the reading condition. Conversely, the whole sentence flew at the natural speed in the listening condition. This might have hindered the occurrence of priming in listening for two reasons. First, building a syntactic structure is one step that follows other non-syntactic processes that are essential for efficiency. Among these processes is lexical access (Hopp, 2016). While L1 speakers can rapidly accomplish this process, research indicates that L2 speakers’ lexical bottom-up processing occurs less efficiently (Roberts, 2013). In the present study, the lexical decision task contains a non-word option that delays the lexical retrieval of the final critical word. Time constraints in listening might have not allowed L2 participants, whose mental resources are already overly consumed in the L2 lexical retrieval process, the sufficient time required for the sentence integration process that is necessary for syntactic adaptation (i.e., cumulative priming). This is supported by previous evidence that showed L2 difficulties in integrating multiple sources of information when performing time-constrained online tasks (Rah & Adone, 2008). Second, the interpretation of the LA ambiguity in the current study requires identifying the verb argument structure, assigning a correct thematic role to the final PP, and accordingly, ascertaining the PP attachment. Time constraints imposed in listening might have prevented L2 speakers from effectively performing these parallel processes, forcing them to resort to a shallow processing strategy (Clahsen & Felser, 2006) which subsequently hinders the occurrence of the syntactic priming effect. According to the shallow structure hypothesis (Clahsen & Felser, 2006), L2 speakers rely solely on lexical-semantic representation to interpret syntactic ambiguities instead of performing structurally detailed syntactic representation. The occurrence of shared syntactic representation in reading, and not in listening, in the present study suggests that L2 speakers do not engage in shallow processing all the time. Instead, factors affecting the speed of processing such as task demands and modality of presentation contribute to the occurrence of shallow processing. This goes in line with previous evidence suggesting that insufficient processing speed could result in processing difficulties in L2 (Ellis, 2005; López Prego & Gabriele, 2014).
Current results indicate that cross-modal priming is of an equal magnitude to within-modal priming in L1. This was confirmed by the additional comparison conducted between the fifth block of the cross-modal list and the first block of the within-modal list. The difference in processing between these two blocks indicated that a priming effect was accumulated throughout the cross-modal list leading sentences in the last block to be more easily processed than those in the first block of the within-modal list. Accordingly, the absence of a difference in processing between those two blocks in L2 indicated a weak cross-modal priming effect from listening to reading. This result was predictable given the fact that no priming was produced in L2 listening. This evidence supports the current suggestion that the differences between L1 and L2 speakers did not result from L2 participants’ inability to produce a cumulative priming effect but were rather linked to L2 less efficiency in listening.
Current L2 results interestingly showed the occurrence of priming, albeit a weak effect, from listening to reading, but not from listening to listening. A facilitation effect caused by the listening primes in L2 transferred to reading, but not to listening. The transfer of the priming effect, therefore, is modulated by the modality of the target. We can, therefore, assume that it is the modality of the target, not the prime, trials that hindered the priming effect among L2 participants in the current study. Although the facilitating priming effect can build up throughout the listening prime trials, it will not show up in the target trials unless the time constraints and task demands are eased for L2 speakers.
Syntactic priming across the two production modalities (i.e., speaking and writing) has been demonstrated in previous research (Cleland & Pickering, 2006). In addition, the present findings provide evidence for priming across the two comprehension modalities (i.e., listening and reading). These findings form a good foundation for a next step in which priming is examined from comprehension to production and vice versa across the four underlying modalities (i.e., from listening to speaking and vice versa, from listening to writing and vice versa, from writing to reading and vice versa, and from speaking to reading and vice versa). The resulting findings would give insight into shared mechanisms and representations underlying comprehension and production. Multiple contradictory views are related to the connection between comprehension and production. First, some views support the existence of separate modular instantiation of the processes underlying production and comprehension (Chomsky, 1965). Second, Dell and Chang (2014) proposed the P-Chan model in which production is linked to comprehension through predictive processing. The production of linguistic content provides top-down effects that are needed for the comprehension process of generating predictions about the upcoming input. Therefore, the model predicts the occurrence of facilitation in processing from production to comprehension, but not vice versa. Finally, the interactive alignment model by Pickering and Garrod (2013) relies on the alignment of produced and comprehended utterances within dialogues to account for the connection between comprehension and production. A future examination of bidirectional priming effects across comprehension and production would reconcile the existing contradictory views. A recent study has indeed supported bi-directional effects across production and comprehension through trial-to-trial priming (Litcofsky & van Hell, 2019); however, it is still to be seen whether these effects persist across the four underlying sensory modalities (reading, listening, speaking, and writing), and whether these bidirectional effects can be found in cumulative priming rather than in trial-to-trial priming which tends to be a short-lasting effect (Pickering & Branigan, 1999).
Conclusion
Current results revealed bidirectional syntactic priming across the two comprehension modalities in L1. Although L2 speakers showed priming in reading, no priming effect was found in listening. In addition, a weak effect was demonstrated in the listening-reading condition. Given that a priming effect was observed in L2 reading, the lack of priming in L2 listening can be attributed to listening difficulties among L2 speakers rather than to an inability to produce a priming effect. We propose that L2 speakers are not less susceptible to syntactic priming, but rather need more time when listening to efficiently comprehend and process sentences.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplementary material
The supplementary material is available at qjep.sagepub.com.