
Abstract
As communication with non-native speakers becomes increasingly common, it is important to understand how foreign-accented speech might influence language processing. Non-native speech can require the listener to process errors, such as grammatical violations or unexpected word choices. The present study examines how listeners process different types of errors across native and non-native speakers. Using a self-paced listening task measuring reaction times to target words, 30 participants listened to sentences that contained either no-error, a grammatical error (e.g., “Do you
Introduction
As travel has become more affordable and businesses have globalised, communication with non-native speakers has become more common. This has introduced us to a range of accents from all over the world (Barner-Rasmussen & Aarnio, 2011; Bloch, 1995). Still, learning a second language is not easy, and while all speakers may fall victim to committing linguistic errors from time to time, non-native speakers can struggle more with this (Corder, 1971; Schepens et al., 2020). Various components of language can differ between native and non-native speech, including accent (e.g., Abrahamsson & Hyltenstam, 2009), vocabulary or lexical diversity (e.g., Dewaele & Pavlenko, 2003), grammar (e.g., Clahsen & Felser, 2006), and discourse (e.g., Fuller, 2003). Despite deviations from native speech patterns 1 often being noticeable, native speakers only correct non-native speakers around 10% of the time (Chun et al., 1982). Studies of error detection suggest that listeners process these linguistic errors, in particular grammatical errors, differently when they are produced by non-native speakers as compared with native speakers (e.g., Fairchild & Papafragou, 2018; Grey & van Hell, 2017; Hanulíková et al., 2012). However, less is known about how errors influence the actual speed of language processing. Furthermore, much of the previous research addressing the difference between native and non-native error detection focussed on grammatical errors and/or salient semantic violations (e.g., Fairchild & Papafragou, 2018; Hanulíková et al., 2012). Non-native speakers, however, often also show more subtle differences from native speech, such as incorrect use of words that mismatch the context (Danesi, 2008; Romero-Rivas et al., 2016). Because of this, the present study examined how non-native speech influences processing of both grammatical and word-choice errors.
Behavioural effects of errors produced by native or non-native speakers
Behavioural research assessing processing of errors made by a native or non-native speaker has mainly focussed on offline measures asking listeners to evaluate or respond to sentences. For example, Gibson et al. (2017) asked listeners to interpret implausible sentences (e.g., “the mother gave the candle the daughter”) produced in a native or non-native accent. Listeners were asked a question after each sentence (e.g., “Did the daughter receive something?”) and were asked to answer according to what they thought the speaker intended to say. If participants answered “no” to this type of questions, their response was interpreted as listeners using the literal meaning. However, if participants answered “yes,” this was interpreted as listeners using a more plausible, non-literal interpretation. Listeners were more likely to follow a plausible (non-literal) interpretation for implausible sentences when the sentence was produced by a non-native speaker. Fairchild and Papafragou (2018) obtained similar findings when asking listeners to rate under-informative sentences (e.g., “Some people have noses with two nostrils”). While written sentences were used to remove any potential differences in processing difficulty as a consequence of listening to non-native speech, participants were told that the sentences came from either native or non-native speakers. They then had to judge how good (i.e., making perfect sense) or bad (i.e., making no sense) a sentence was. Reading about the writer’s background (native or non-native) influenced the ratings, with non-native under-informative sentences being rated more positively than native sentences. Fairchild and Papafragou interpret these findings by contrasting an intelligibility account (understanding non-native speech comes with additional processing demands) and an expectation-based account (arguing that listeners have different expectations for non-native vs native speech, with the former expected to be more variable and error prone). The expectation-based account furthermore predicts that listeners might rely more on top-down information (such as background knowledge and context) when processing non-native speech. Given that Fairchild and Papafragou used written sentences (which were identical for native and non-native speakers and thus did not differ in processing difficulty), they suggest that the findings are best explained by an expectation-based account. Based on the description of the speaker, listeners might have used a more lenient approach when accepting sentences produced by a non-native speaker.
These findings and interpretations are in line with the argument made by Lev-Ari (2015a, 2015b), positing that when processing language produced by non-native speakers, listeners might alter their expectations. As a consequence, listeners might filter out some of the linguistic information and might end up with a less precise linguistic representation. To compensate, they might rely more on context than when listening to native speech. One example given is that when a non-native speaker refers to a “cake” instead of a “pie,” listeners might overlook this unexpected word choice and assume that they are talking about the pie present in the room. This is compatible with the “good enough” approach listeners might use (e.g., Ferreira et al., 2002). Listeners might not always fully process the language input they are given. Instead, they might only partially process the input, up to the level needed for the purpose (e.g., understanding what they speaker intends to say). This good enough approach might be used even more strongly with non-native speech, which might be processed less precisely.
Following this line of reasoning, listeners would be expected to show a smaller processing cost when hearing errors produced by a non-native speaker than when the same error is produced by a native speaker. In contrast, an intelligibility-based account would expect a larger processing cost as a consequence of increased processing demands associated with non-native speech. Behavioural research (e.g., Fairchild & Papafragou, 2018) supports the former explanation (differences in expectations and less precise processing of non-native speech leading to smaller error costs). Most of this research, however, has focussed on offline tasks that ask participants to make judgements about sentences they hear or see (e.g., Fairchild & Papafragou, 2018), to respond to these sentences (e.g., Gibson et al., 2017), or to make judgements about similarities between utterances with and without errors (e.g., Pelzl et al., 2021 show that tone errors were less likely to be rejected when made by a non-native speaker of Mandarin). While this suggests that listeners might be more lenient in response to non-native language, these studies do not necessarily show us how native versus non-native error detection operates online (i.e., while processing speech). In other words, does processing of errors incur larger processing demands when the error is made by a non-native speaker (larger error cost) or, conversely, are listeners more lenient and “overlooking” errors made by a non-native speaker (smaller error cost)? Although we focus on behavioural processing of errors in our study, most research looking at online processing (as opposed to offline evaluations) has used electroencephalography (EEG). We will therefore briefly discuss this literature too.
Grammatical error detection in ERP studies
Focussing on grammatical errors first, Hanulíková et al. (2012) investigated grammatical error detection (gender disagreement between the definite determiner and noun, such as “de huis” [“the house”] instead of “het huis”) in native and non-native (Turkish) speakers of Dutch. Grammatical violations produced different event-related potentials (ERPs) in participants when listening to the native and non-native speakers. Grammatical violations elicited a larger P600 effect than control sentences in the native speech condition while no such difference between grammatical and control sentences was observed in the non-native speech condition. The authors interpret these findings in line with the P600 reflecting repair of grammatical errors. In line with the behavioural interpretation discussed above, listeners might modify their expectations when listening to non-native speech and might take a more tolerant approach overlooking grammatical errors. As a result, they may not attempt to repair grammatical errors in non-native speech. In a comparison between common and less common grammatical errors, Caffarra and Martin (2019) also showed that the P600 was absent when listening to common grammatical errors (gender violations, such as “la color” instead of “el color”) in non-native speech, suggesting that listeners might not attempt to repair errors in non-native speech when they are expected. However, uncommon grammatical errors (number violations, such as “los color”) did elicit a P600 in non-native speech too, suggesting listeners do attempt to make repairs when errors are not predictable.
Grey and van Hell (2017) also examined sentences containing a grammatical error, such as “Thomas was planning to attend the meeting but
EEG studies thus suggest that grammatical error processing differs between native and non-native speech, with listeners showing no difference between errors and control sentences in non-native speech (potentially depending on familiarity with accent and errors). These findings could be and have been interpreted in line with the “good enough” approach suggesting that listeners are more likely to overlook errors and rely on top-down knowledge when processing non-native speech. However, multiple interpretations are possible, including the interpretation that listeners unfamiliar with an accent might require too many resources to understand the speech and might therefore have insufficient resources left to repair or reanalyse any errors (Grey & van Hell, 2017). Furthermore, from these ERP studies, it is less clear how differences between native and non-native speech might influence behavioural outcomes. While comprehension accuracy was high in the studies discussed above, we do not know how accent might influence speed when processing errors, an important aspect of communication. Does accent influence how quickly listeners can process sentences with grammatical errors? The current study will therefore investigate how grammatical error processing, across native and non-native speakers, influences measures of behavioural processing.
Semantic error detection
While grammatical errors studied in the research described above often resemble the type of errors non-native speakers might make, this is often not the case for materials used when studying semantic or pragmatic violations. The behavioural studies described at the beginning often present participants with implausible or under-informative sentences. Similarly, ERP studies assessing semantic errors typically use words that are impossible in the context and that violate world knowledge (e.g., “Kaitlyn travelled across the ocean in a
The type of semantic violations studied, however, are very unlikely to occur in either native or non-native speech. The semantic errors used in studies are very salient. For example, in the sentence “Kaitlyn travelled across the ocean in a
In recent research, Gosselin et al. (2021) created semantic errors that non-native speakers make in daily life as a consequence of mispronunciations. In the study, native Spanish listeners heard both native and non-native (Chinese-accented) speakers read correct sentences and incorrect sentences with typical and atypical phoneme substitutions (e.g., substitution of /r/ to /l/, which is often made by Chinese speakers, or /n/ to /s/, which is less common). Sentences with phonemic substitutions led to semantic anomalies but, in the case of typical substitutions, represented errors non-native speakers could make in natural speech. While EEG data showed that there was no difference between well-formed and semantically incorrect sentences in an early time window (300–600 ms), the later time window (600–900 ms) showed a larger negativity for incorrect versus correct sentences in non-native speech than in speech with a native accent. This was found when listening to both common and uncommon semantic errors. This could suggest that while semantic errors may initially seem “overlooked” (cf. Hanulíková et al., 2012), error detection may be present in later processing, potentially because listeners have a harder time integrating semantic errors when listening to non-native speakers.
Contextual error detection
While Gosselin et al. (2021) created semantic violations that can occur in daily life, the semantic violations might still have been stronger than what would be expected in natural speech, where mispronounced phonemes do not always lead to strong anomalies. Rather than focussing on semantic anomalies we therefore studied a different type of semantic inconsistencies in our study, namely, contextually inappropriate language use. Acquiring a new language does not just requiring learning new vocabulary and grammar rules but also learning how to use this language in different contexts. Non-native speech has been found to show violations of pragmatics or discourse. For example, Fuller (2003) investigated native and non-native speech in more formal contexts (interviews) and informal contexts (conversations). Native speakers used their discourse markers (such as “well” or “like”) in different ways depending on the type of interaction and familiarity with the interlocutor. Non-native speakers, despite having a very high proficiency, did not adapt their use of discourse markers to the interaction they were in to the same extent as the native speakers. This suggests that non-native speech might show less adaptation to the context it is used in and might be less sensitive to register differences (Gilquin & Paquot, 2008). Non-native speakers might struggle to acquire and correctly use the more colloquial language that is often used in informal contexts (e.g., Frumuselu et al., 2015), especially when they learn their second language in a classroom setting. At the same time, non-native speakers also struggle with formal contexts and often use less “polite” language when in contexts requiring more formal use (e.g., overly colloquial use when emailing a teacher, Biesenbach-Lucas, 2007; Economidou-Kogetsidis, 2011, or in academic settings, Gilquin & Paquot, 2008).
Earlier research has utilised contextual errors to examine what effect these violations have on linguistic processing in native speakers. Van Berkum (2009) used contextual errors to examine how “referential pragmatism” (the process of building semantic meaning from sentences) can influence linguistic processing. Across multiple studies, participants showed to be sensitive to violations when sentences are not expected given the speaker or context (e.g., “Every evening I drink some wine before I go to sleep” spoken by a child). This shows that listeners are not just sensitive to implausible words that violate world knowledge but also to contextually inappropriate word choices when building semantic meaning from sentence content (e.g., Van Berkum et al., 1999, 2003, 2008). However, this was only investigated within native speakers, leaving open the question of how contextual violations can influence processing of non-native speech. The current study therefore examined how, in addition to grammatical errors, listeners process contextual “word-choice” errors (i.e., overly formal words in an informal setting or overly informal words in a formal setting) in native and non-native speech.
The current study
The literature thus suggests that listeners might show different patterns in response to errors in native speech than in non-native speech, suggesting that listeners might be more tolerant when listening to non-native speech and follow a “good enough” approach in which they do not repair errors (Lev-Ari, 2015a, 2015b). Studies assessing semantic or pragmatic violations, however, show more mixed results (e.g., Hanulíková et al., 2012; Romero-Rivas et al., 2015) but also often use errors that do not typically occur in either native or non-native speech. Hence, the current study’s aims are twofold. First, we aimed to examine behavioural outcomes when listeners hear native and non-native speakers commit linguistic errors. Most previous work has focussed on ERP effects or on offline behavioural processing (e.g., ratings or response to sentences), but little is known about how errors might influence the speed of language processing in different types of speakers. Second, we aimed to examine whether error processing differs between grammatical and contextual errors, when those contextual errors represent word-choice errors non-native speakers make in daily life as opposed to salient violations of world knowledge.
To answer these questions, native English speakers listened to a set of sentences (spoken by a native speaker or a non-native speaker of English) which were divided between two contexts (either a “friend” or a “teacher” speaking to them) and three error variants (no-error, grammatical error, or a contextual word-choice error). The task measured reaction times (RTs) while listening to the sentences in a self-paced listening task. This acted as a measure of behavioural processing; the more processing needed, the longer we expected the RTs to be. Previous research has shown that these self-paced listening tasks are sensitive to effects detected in other language paradigms (e.g., Waters & Caplan, 2004).
Considering previous research (e.g., Fairchild & Papafragou, 2018; Gibson et al., 2017; Grey & van Hell, 2017; Hanulíková et al., 2012), we expect that processing will differ when listening to native and non-native speakers commit errors, signifying that error processing varies across native and non-native speech. If listeners are indeed more tolerant of errors in non-native speech and follow a “good enough” approach more strongly for non-native than native speech (Lev-Ari, 2015a, 2015b), we expect the RT error cost to be smaller when listening to non-native speech as compared with native speech. The comparison between grammatical and contextual word-choice errors will allow us to examine whether processing differences between native and non-native speech depend on the type of errors made.
Methods
The study was pre-registered on the Open Science Framework (https://osf.io/tyu94). The data are available at https://osf.io/u367c/. The study received ethical approval from the ethics committee in the Department of Psychology at the University of York (number 20216).
Participants
According to power calculations based on medium-sized effects using G*Power, 28 participants were needed to satisfy 80% statistical power, thus the sample size aim was 30 (Faul et al., 2007). The final sample included 30 participants. An additional four participants were recruited but three were omitted due to not meeting eligibility requirements (indicating that they were born outside of the United Kingdom and had an “American” accent, while the native speaker in our study had a British accent), while another participant was removed due to showing abnormally fast responses (2 standard deviations [SDs] below the group mean). It should be noted that our pre-registered exclusion criteria focussed on low accuracy on the comprehension questions and not fast RTs in the listening task as a reason for exclusion. Given, however, that these RTs were faster than the duration of the audio they were asked to listen to, it was unlikely that this participant paid sufficient attention to the sentences. Participants were recruited through word-of-mouth and social media platforms using a link to the online experiment. Eligibility criteria required participants to be 18 years or older, monolingual native English speakers, and currently residing in the United Kingdom. Gender and age of participants were not recorded. There was no incentive for participation.
Design
This study included two within-subject variables: type of speaker (either native or non-native) and type of error (no-error, grammatical error, or a contextual formal/informal word-choice error, which will be referred to as a word-choice error). The dependent variable was RTs in response to the target cluster, which was measured in milliseconds. RT was calculated as the time participants needed (relative to onset of the audio) to indicate (by pressing the spacebar) that they were ready to move onto the next word cluster.
Materials/stimuli
Stimuli consisted of 20 sentence triplets, half of which were assigned to a “friend” context, meaning they were common things a friend would say, and half to a “teacher” context, meaning they were common things a teacher would say. A teacher and friend context were used to create a formal and informal environment, respectively. Participants were told about the context they were in, with associated images provided to enhance context salience. For the friend context, the image supplied was of two male cartoon boys standing with their arms around each other, and for the teacher context, a similar style image was provided of an elderly male with a notepad and a pencil (see Figure 1 and the online Supplementary Material C).
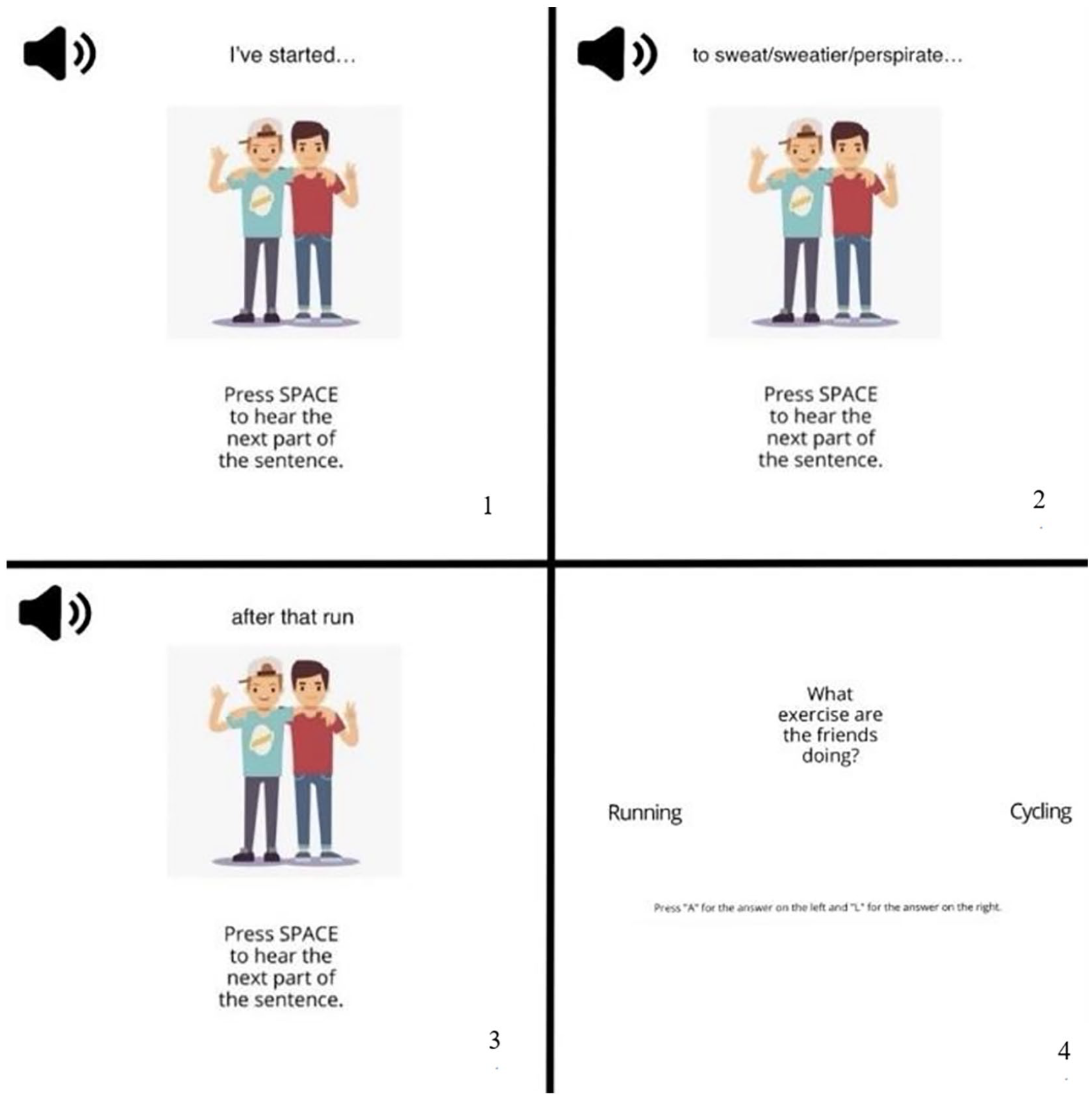
Example of what participants saw during the “Friend” context block, while they were hearing the audio-clips and pressing the spacebar to progress. On the second slide (top right), the errors played in the three conditions are presented as examples: no-error/grammatical error/word-choice error. After this, participants saw a comprehension question probing the content of the sentence heard or they saw a screen telling them to get ready for the next sentence.
Each sentence triplet was created to have three versions of the target-word cluster: a no-error, a grammatical error, or a formal/informal contextual word-choice error on a specific target word (e.g., see the online Supplementary Material A and Table 1). Grammatical error conditions contained a range or errors (see the online Supplementary Material A for all sentences). This included, for example, incorrect use of verbs (e.g., “do you wanting” or “did you gone”), plural instead of singular nouns (e.g., “an emails”), and incorrect use of nouns or adjectives (e.g., using “danger” instead of “dangerous”).
Examples of stimuli used in the different contexts.

Note. As seen in the “word-choice control” column, word-choice sentences were also included in the other context to control for word frequency, ensuring any effects found in word-choice error conditions are due to contextual processing. Target words can be seen in bold.
The word-choice errors were designed, so that the target cluster contained either a formal word, which would be unusual if heard from a friend, or an informal word that would be unusual if heard from a teacher (Krashen, 1976). In neither the grammatical errors nor the word-choice errors, did we specifically consider the type of errors Spanish native speakers might make. In both conditions, errors reflected grammatical and choice mistakes that could be made by English non-native speakers more generally. Considering that we did not know how familiar participants would be with Spanish speakers specifically, we aimed to include errors that would be salient regardless of familiarity with the specific accent. Furthermore, considering that our word-choice error condition included a range of word classes (including nouns, adjectives, and verbs), we did not pick one type of grammatical errors (e.g., number agreement) but used a range of errors.
Apart from the target word/words, sentences were identical. This ensured that any effects of error were not due to differences in the sentence context used. Sentences did differ between the friend and teacher context (to create sentences that are likely to be produced by either a teacher or friend), but a comparison between these two contexts was not part of this study and the analysis collapsed across these two parts. Nevertheless, we ensured sentence length was similar for the two contexts.
Target words in the “word-choice error” condition differed from target words in the no-error and grammatical error condition. Due to the nature of these words, there was a difference in frequency between the word-choice and control/grammatical target words. Formal or informal words (e.g., “perspire” instead of “sweat” or “lads” instead of “males”) are unavoidably less frequent (M log frequency = 0.95, SD = 0.62; Davis et al., 2005) than their more common control equivalents (M log frequency = 2.00, SD = 0.70). In addition, the control words were slightly shorter (M syllables = 1.45, SD = 0.60; M phonemes = 4.25, SD = 1.45) than the word-choice condition (M syllables = 2.05, SD = 0.85; M phonemes = 5.47, SD = 1.71). As an additional control condition, we therefore also presented participants with these target words in the more appropriate context (i.e., the more formal words, such as “perspire” in the teacher context and the more informal words, such as “lads” in the friend context).
Sentences were recorded in English by a native speaker (who had what could be described as a British “received pronunciation” accent) and a non-native speaker (with a Chilean Spanish accent). Both speakers were male and around the same age. Audio from the speakers was processed using “Praat” software (Boersma & Weenink, 2021). Sentences were divided into clusters of words that were deemed to “naturally flow” on from one another (see the online Supplementary Material A). The word cluster containing the target word was referred to as the “target-cluster”; each target cluster ended with the target word and target clusters were never at the end of sentences, to accurately measure RT of participants when indicating that they were ready to move on to the next part of the sentence.
For the experiment, non-target clusters were taken from the same reading of a sentence (usually the no-error condition), the target cluster from each condition was inserted, and volume was standardised to 70 db. Each of the clusters was cut to ensure they had around 50 ms of silence between the start and end of the clip. Finally, the non-native speaker clusters were increased in speed by 20%, to match speaking rate between the native and non-native audio.
As an attention check and to ensure sentences were comprehendible in both the native and non-native speaker conditions, we also generated a set of forced-choice comprehension questions asking about the content of the sentences. Each sentence had its own comprehension question (see the online Supplementary Material B). These were distributed across participants so that each participant saw a question on 12.5% of trials, distributed across speaker and error condition.
Procedure
The study was run using Gorilla.sc (Anwyl-Irvine et al., 2020).
Participants accessed the experiment through their own computer device and we ensured that the study could only be completed on a desktop or laptop and not on a phone or tablet.
Participants first read and completed their information and consent forms, confirmed they were 18 years or older, and confirmed they met the necessary eligibility criteria (monolingual native speaker of English, where they were born, and what accent they had). Next, participants completed a sound check, prompting participants to move to a quiet area where they would not be distracted. This sound check allowed participants to adjust their volume if necessary and made sure that sound clips could be played automatically on the participant’s device.
The programme then randomly allocated which half of participants heard the friend sentences first and which half heard the teacher sentences first. The order of trials in the experiment was also pseudo-randomised, so that no more than three consecutive trials had the same speaker or error condition. Instructions stated that participants would hear a range of sentences spoken to them and they should imagine the speaker as their friend or teacher, dependent upon which context they were completing. Each sentence was split into clusters of words and they had to indicate, by pressing the spacebar, when they were ready to move onto the next cluster (see Figure 1). In addition, after each trial, they saw a “Start Next Sentence” screen or a forced-choice comprehension question, which they had to answer through keys on their keyboard (see Figure 1).
Participants first heard a practise sentence (produced by the researcher) with a comprehension question. Once participants either worked through the friend or teacher sentences, instructions were shown again (this time with the alternative context) and the practise question was repeated (again, with the alternative icon), familiarising them to the change of context, before completing the alternative block. The experiment included 120 experimental trials, 60 per context (friend/teacher). This included 40 no-error, 40 grammatical, and 40 word-choice trials (20 per speaker).
In addition, to control for differences in frequency between the word-choice targets and control/grammatical targets, participants also saw “word-choice” controls in their corresponding context. This meant that in the “friend” context block, participants also heard the informal word-choice sentences and in the “teacher” block participants heard the formal word-choice sentences (see Table 1). This was done to investigate if processing of the inappropriate word choices (formal in friend context and informal in teacher context) were indeed affected due to the use of contextually incorrect words or confounded by the frequency of these words, as uncommon words are harder to process than common ones (“The Word Frequency Effect”; Brysbaert et al., 2011).
After completing the self-paced listening task, participants completed post-study questions which asked where they believed both of the speakers to be from, what the native languages of the speakers were, and if they believed themselves to be familiar with the non-native accent heard. Participants then read through a short debrief.
Data analysis
Participants’ data were taken from Gorilla.sc and responses to questionnaires were examined to ensure participants met the study’s inclusion requirements. Next, comprehension questions (used as an attention check) were assessed to make sure participants reached the 70% accuracy threshold for inclusion. The main analysis focussed on RTs from the self-paced listening task. The RT data file was run through a script on RStudio to remove non-target word clusters from the data, as only target clusters were considered in analysis, as well as individual RTs 2.5 SD above or below the participant’s mean per speaker and error condition (trimr, Grange, 2015).
Means were computed per condition, which was then inserted into SPSS (Version 26.0) to perform the main analysis comparing main effects of “speaker” (native and non-native) and “error condition” (no-error, grammatical error, and word-choice error), as well as the interaction between these variables, on RT.
It should be noted here that while a 2 × 3 repeated measures analysis of variance (ANOVA) was used, two conditions failed Shapiro–Wilks’s normality checks: non-native control targets (p = .045) and non-native word-choice targets (p = .037). However, after inspection of Q–Q plots, the ANOVA was still considered to be viable; the other conditions furthermore met the normality checks. In addition, we log-transformed RTs to improve normality of distribution. ANOVAs using these log-transformed RTs showed the same outcomes as the results reported below with untransformed RTs.
After the main analysis (and pairwise comparisons between error conditions) was run, a post hoc analysis was conducted to examine specifics of the interaction found in the main 2 × 3 ANOVA and to compare the two error types. For each participant, we computed their “error cost” for grammar errors as the RT difference between the grammar and no-error condition, and for word-choice errors as the RT difference between word-choice and no-error conditions. This was done for the native and non-native conditions separately. These error costs were then analysed using a 2 × 2 repeated measures ANOVA, including the factors error type (grammatical or word choice) and speaker (native and non-native). A paired t-test was also run between the RTs from the native and non-native no-error conditions to assess whether there were any processing differences between native and non-native speakers in sentences without errors.
Finally, we examined whether any effects related to word-choice errors were related to contextually inappropriate use or rather to differences in frequency between word-choice and no-error/grammatical targets. We therefore ran another repeated measures ANOVA, including speaker and word-choice condition (word-choice error and word-choice control). In this analysis, we examined responses to the same target words, presented either in the wrong context (word-choice error) or in the appropriate context (word-choice control).
In addition to the ANOVAs, we also conducted Bayesian ANOVAs (not pre-registered) to formulate how much evidence there was for or against the crucial interactions between error and speaker (the effect of interest in this study). We therefore compared a model with the main effects + the interaction of interest with a model with the main effects but no interaction (using JASP version 13.1, with 1 million iterations). We will report these results in the form “BF10,” showing the evidence for the alternative hypothesis (significant interaction) over the null hypothesis (no interaction). Values below 1 indicate evidence against an interaction; values above 1 indicate evidence for an interaction.
Results
Sentence comprehension and post-study questions
In the comprehension questions used to measure attention levels, all participants superseded the required 70% accuracy levels, showing that participants paid sufficient attention to the content of the sentences (Maccuracy = 96%, SD = 4.7, range = 85%–100%)
When answering the post-study questions, none of the 30 participants correctly guessed the accent or place of birth of the non-native speaker. Despite this, seven participants still indicated that they believed themselves to be “familiar” with the accent (another 13 indicated they were not familiar and the remaining 10 chose to say they were “unsure”). It is worth noting that seven participants guessed that the non-native speaker had a “Mediterranean” accent, which, while perceptually close to a Chilean Spanish accent, is not strictly correct. However, there was no relationship between these close guesses, and confidence in “familiarity,” suggesting that even the participants who guessed a Mediterranean accent were not certain of that guess.
Main analysis
A 2 × 3 repeated measures ANOVA was carried out on participants’ mean RTs, comparing the main effects of “speaker” and “error condition,” as well as the interaction effect between these two variables, on RT (see Figure 2 and Table 2).
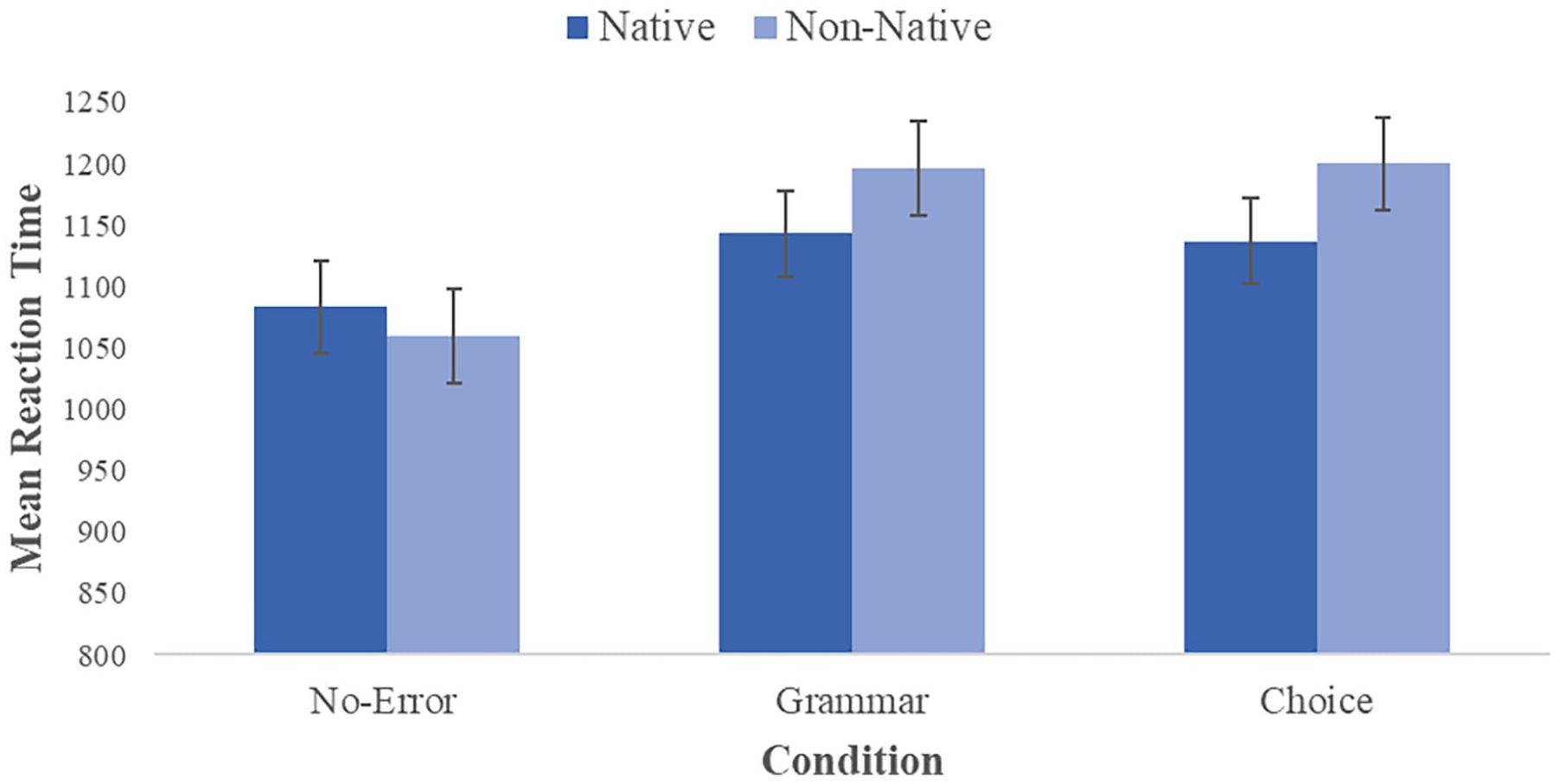
Graph showing mean RTs for each condition. Dark blue shows native speaker conditions, while light blue represents non-native conditions. The y-axis represents mean reaction time (ms) and the x-axis represents error type (no-error, grammatical, and word choice).
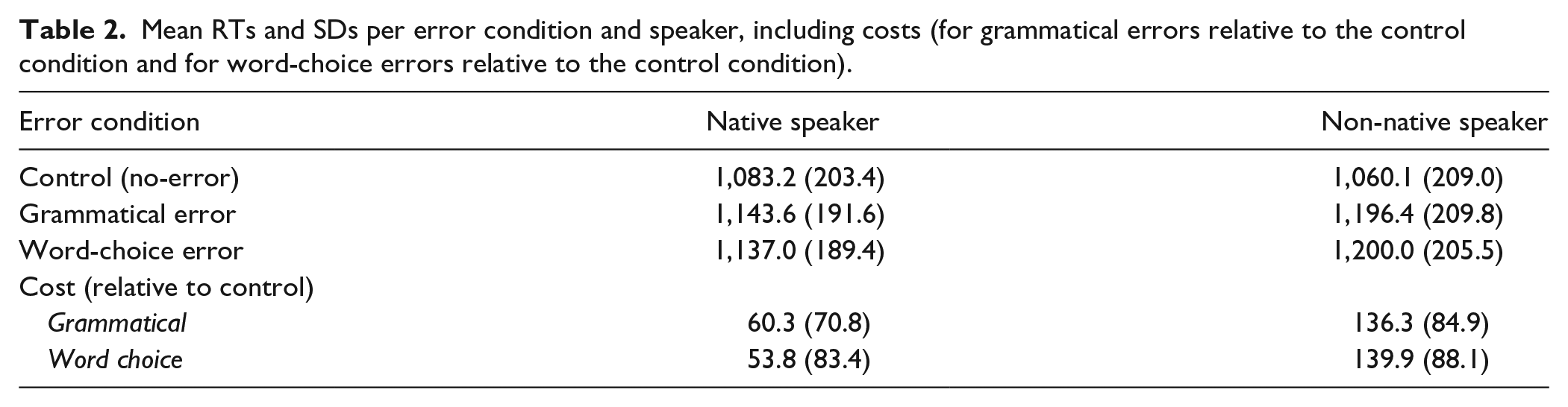
Mean RTs and SDs per error condition and speaker, including costs (for grammatical errors relative to the control condition and for word-choice errors relative to the control condition).
The ANOVA revealed that the type of speaker had a significant effect on RT, F(1, 29) = 8.73, p = .006,
The main effect of error condition on RT was also significant, F(2, 58) = 47.17, p < .001,
There was a significant interaction between speaker and error condition, F(2, 58) = 12.71, p < .001,
Cost analysis
After computing error costs relative to no-error sentences for each participant and speaker for the grammatical error and word-choice conditions, a 2 × 2 repeated measures ANOVA on RT cost was carried out.
There was a significant main effect of speaker on RT, F(1, 29) = 32.79, p < .001,
However, the ANOVA also revealed that there was no significant main effect of type of error, F(1, 29) = 0.20, p = .890,
Word-choice control analysis
Finally, another 2 × 2 repeated measures ANOVA was run to check the validity of the word-choice error condition by comparing the word-choice error and word-choice control conditions (i.e., two conditions using the same target words but in either correct or in “incorrect” contexts). As the main ANOVA shows that processing word-choice errors was significantly slower than well-formed speech, this test was run to ensure contextual error detection was not confounded by frequency differences between stimuli used in the word-choice condition and in the no-error/grammatical error conditions (Brysbaert et al., 2011).
Once again, a significant main effect of the speaker was found, F(1, 29) = 9.63, p = .004,
The interaction between these two variables (speaker and word-choice errors vs word-choice controls) was not significant, F(1, 29) = 3.63, p = .067,
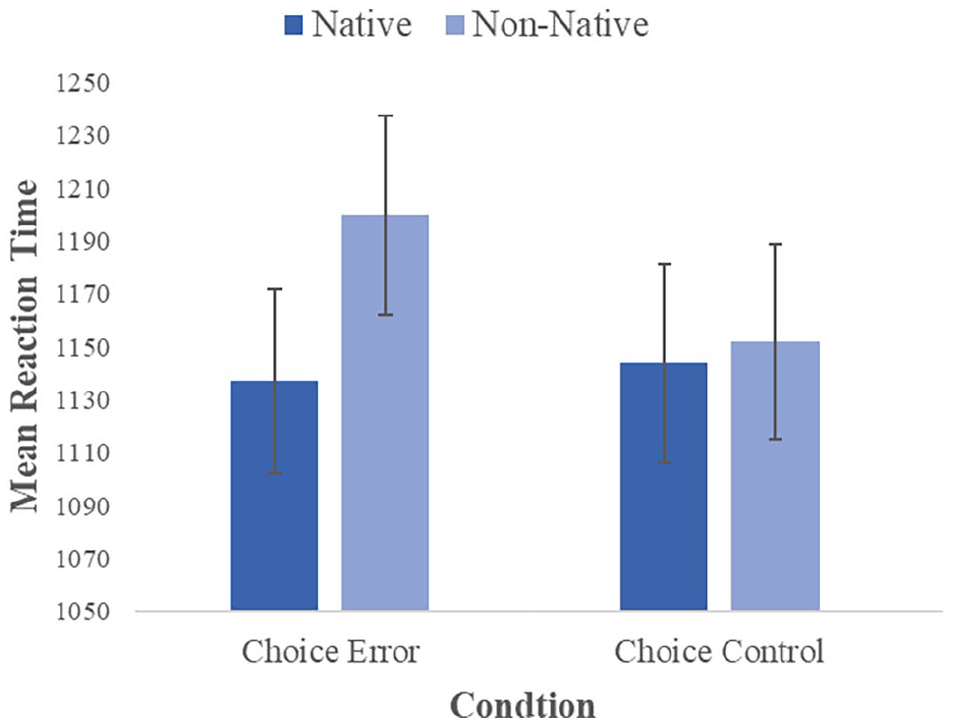
Graph showing average reaction time across word-choice conditions. Dark blue shows native speaker conditions, while light blue represents non-native conditions. The y-axis represents mean reaction time (ms) and the x-axis represents word-choice error and word-choice control conditions.
Discussion
This experiment investigated behavioural processing of linguistic errors across native and non-native accents. The study aimed to examine whether error processing varies when listening to native and non-native speakers, as well as to compare processing across error type, utilising frequently studied (grammatical) and novel (contextual) errors. The results showed that RTs when listening to the non-native speaker were longer than when listening to the native speaker. This was due to the differences in RT when listening to the speakers commit grammatical/word-choice errors, while no speaker difference was found during no-error speech. As RT was used as a proxy for linguistic processing, this suggests that more processing is needed when listening to a non-native speaker commit linguistic errors, over a native speaker. Moreover, there was no difference in RT across grammatical or contextual errors, suggesting that error processing was more demanding when listening to non-native speakers during both grammatical and word-choice errors.
Error processing across accents
The overall finding that errors are processed differently when listening to native or non-native speech is in line with many previous studies, including those showing differences in how people respond to implausible sentences with errors (e.g., Gibson et al., 2017), how people rate under-informative sentences (e.g., Fairchild & Papafragou, 2018), as well as EEG studies showing different ERP effects in response to errors made in native versus non-native speech (e.g., Grey & van Hell, 2017; Hanulíková et al., 2012).
Listeners might follow a “good enough approach” (e.g., Ferreira et al., 2002), in which linguistic input might not be processed fully. It has been proposed that this might apply even more strongly when listening to non-native speech, where listeners might expect errors and might therefore process the linguistic input less precisely or fully. They might be more tolerant to errors and instead rely on context to facilitate their understanding (Lev-Ari, 2015a, 2015b). Indeed, several ERP results suggest that errors committed by non-native speakers may be “overlooked” in processing (Hanulíková et al., 2012), perhaps especially so when errors are expected (Caffarra & Martin, 2019).
However, the current study shows that responses are slower when listening to errors spoken in a non-native accent than when listening to these errors in native speech. This suggests that listeners are not more tolerant but rather that these errors produced by non-native speakers are even more difficult to process. This suggests that more cognitive recruitment is needed (e.g., Gagné et al., 2017). Listening to non-native speech might pose additional demands (e.g., processing slight mispronunciations, different intonation patterns) and this has been found to make speech comprehension more difficult (e.g., Braun et al., 2011; Floccia et al., 2009; Van Engen & Peelle, 2014). In line with the intelligibility account proposed by Fairchild and Papafragou (2018), as a consequence, listening to non-native speech might reduce cognitive resources available for error processing, resulting in longer response times. While there was no difference between listening to native and non-native control sentences, listeners might apply additional resources to quickly process non-native speech (without errors), which reduces the resources needed to quickly manage errors when they are encountered. This interpretation would be in line with dual-tasking effects that have shown, for example, that listeners show larger costs on a secondary task when speech is presented in (more) noise (cf. Gagné et al., 2017). Similar to speech in noise, non-native speech could require additional cognitive resources that make the “secondary task” (processing errors) more difficult.
It could be precisely because of the absence of early repair of errors in non-native speech (e.g., Caffarra & Martin, 2019; Hanulíková et al., 2012) that later stages of processing are more demanding (e.g., Gosselin et al., 2021; Romero-Rivas et al., 2015). When looking at behavioural processing (as done here), this can lead to longer processing times to ensure comprehension is still achieved. It is possible that this cost of processing errors made by non-native speakers could be especially effortful when the listener is not familiar with the accent, as was the case in this study, or when grammatical errors are not entirely predictable (e.g., when a range of errors is used, as in the current study). This is in line with Grey and Van Hell’s (2017) suggestion that listeners unfamiliar with the non-native accent might not have sufficient cognitive resources available to quickly re-analyse the sentence. When processing a familiar accent, the processing demands might be reduced. Similarly, these demands might be smaller when using written instead of spoken language (e.g., Fairchild & Papafragou, 2018), when stimuli are related and provide context (e.g., Lev-Ari, 2015a), or when listeners are given more time to respond (e.g., in studies using offline ratings, e.g., Gibson et al., 2017). A “good enough” approach might be more successfully applied by listeners in those types of situations. In contrast, when overall demands are higher (i.e., when having to respond quickly to an unfamiliar speaker without any other contextual factors facilitating understanding, as was the case in this study), this approach might be less successful and non-native speech might increase processing costs associated with errors.
Processing of different error types
RTs in the current study did not vary as a result of error type (grammatical or word choice). This suggests that contextual word-choice errors are processed in a similar fashion to grammatical errors. Previous studies assessing “word-choice” errors have focussed on semantic violations that are incompatible with our world knowledge (e.g., sentences referring to flying on a cactus). These implausible sentences might be evaluated differently in native and non-native speech (e.g., Gibson et al., 2017). However, ERP studies focussing on online processing provide more mixed results. Some conclude that semantic violations, contrary to grammatical errors, might elicit similar effects in native and non-native speech (e.g., Hanulíková et al., 2012), while others have shown different patterns for native and non-native speech (e.g., Romero-Rivas et al., 2015). Crucially, however, these errors might be so salient, and so uncommon in daily-life speech, that they stand out and need to be re-analysed in both native and non-native speech. Our study suggests that listeners are not just sensitive to these salient violations of world knowledge, but also to more subtle word choices that mismatch the context, in particular when these violations are presented in a non-native accent. These are errors that occur in non-native speech but that typically receive less attention in classroom settings (especially when compared with e.g., grammatical errors). Our study, however, shows that these errors can influence processing speed as much as grammatical errors.
Our word-choice errors, however, differed from the no-error controls and grammatical errors in frequency (and to a lesser extent in length). Comparisons with “word-choice” control conditions in which the same “word-choice” target words were presented in their corresponding context (e.g., formal words in a formal context) suggested that effects of word-choice errors were indeed due to violation of context and not frequency of usage. Nevertheless, considering that this interaction did not reach significance and only showed weak support from Bayesian analyses, future research is needed to examine the role of context violation as opposed to frequency effects.
Conclusion
In conclusion, this study suggests linguistic error processing varies as a function of accent, both when listeners encounter unexpected word choices as well as when they hear grammatical errors. Our results suggest that more processing time is needed to handle linguistic errors when spoken in a non-native accent. In addition, it may be that effects are comparable across different error categories, or at least the two examples (grammatical and contextual word-choice violations) used here. When listening to non-native speech, listeners might recruit additional resources and might consequently not have sufficient resources left to quickly process and repair errors. This has consequences for our everyday conversations and our perceptions of non-native speech. For example, non-native speech can be judged as being less credible, and this could be a consequence of increased processing difficulty (e.g., Lev-Ari & Keysar, 2010). Slower processing when encountering non-native errors might thus not only influence the ease with which but also how we engage with millions of non-native speakers.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218221135543 – Supplemental material for Examining the difference in error detection when listening to native and non-native speakers
Supplemental material, sj-docx-1-qjp-10.1177_17470218221135543 for Examining the difference in error detection when listening to native and non-native speakers by Grace Sanders and Angela de Bruin in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.