
Abstract
The last decade has seen a rise in big data approaches, including in the humanities, whereby large quantities of data are collected and analysed. In this paper, we discuss long-form audio recordings that result from individuals wearing a recording device for many hours. Linguists, psychologists and anthropologists can use them, for example, to study infants’ or adults’ linguistic behaviour. In the past, recorded individuals and communities have resided in high-income countries (HICs) almost exclusively. Recognising the need for better representation of all cultures and linguistic experiences, researchers have more recently started to collect long-form audio recordings in low- and middle-income countries (LMICs). We aim to help researchers to collect, analyse and use these recordings ethically. To do so, we identify four main ethical challenges linked to research that relies on long-form recordings in LMICs. We provide recommendations to overcome these challenges. These considerations should be useful to researchers employing other big data techniques collected via wearables.
Introduction
Long-form audio recordings result from individuals wearing a recording device for many hours at a time (VanDam et al., 2017). They pose unusual ethical challenges and guidance has been developed for researchers using this technique (Cychosz et al., 2020). More recently Cychosz and Cristia (2022), discussed some additional ethical considerations. This paper builds on that foundation with consideration of long-form, child-centred recordings to help researchers working with big data approaches to collect data in LMICs ethically. Thus, it adds a novel perspective to the existing discourse in the discussion of researcher biases, the solutions proposed and the provision of new advice, specifically for appropriate benefits. Moreover, having an exclusive focus on LMICs encourages reflection upon power asymmetries and related issues. It will be most beneficial to researchers who are unfamiliar with the use of long-form recordings in LMICs.
After describing long-form recordings, we outline the ethical considerations of research with long-form recordings in LMICs. We then present four main ethical challenges researchers could face while collecting, analysing and using long-form recordings in LMICs: the researchers’ own biases, culturally inappropriate informed consent, algorithm biases and the lack of fair benefit distribution. We discuss what may be the most impactful decisions researchers can take to guide ethical behaviour in their work and overcome each challenge. These considerations should be useful to researchers employing other big data techniques collected via wearables.
What are long-form recordings?
Detailed guidelines exist for long-form recording collection, analysis, storage and sharing (Casillas and Cristia, 2019; Pisani et al., 2022), and an extensive introduction to the technique is beyond the scope of the present paper. We thus provide a very brief introduction to the technique and its use.
Long-form recordings, also called long-format or daylong recordings, are audio recordings that can last 12 hours or more. These recordings are gathered with small devices like USB audio recorders or wireless microphones worn by an individual in a cloth pocket. These devices typically record the voice of the person wearing them, that of anyone who speaks near them (with sensitivity depending on the equipment), and even those who are further away, provided they speak loudly enough. Sometimes, the audio recording is combined with other data types like videos or heart rates to study phenomena like neurological states or wellbeing (de Barbaro, 2019).
Very few devices that are currently in use to collect long-form recordings have on-device encryption. Given the considerable quantity of data gained through long-form recordings, it is not typically synchronised to the cloud. Instead, a physical transfer must take place to extract it. Researchers then usually store the data in a secure location. Some of them also archive a copy of their data in specialised scientific archives providing a range of access options (e.g. public, restricted to members, etc.; including Carnegie Mellon University’s homebank.talkbank.org and New York University’s databrary.org) from where others can download a copy for reuse.
This technology allows researchers to collect large quantities of raw audio data. Indeed, multiple individuals, sometimes up to hundreds, are recorded in any given study. As a result, it is too expensive and impossible from a practical point of view for researchers to manually analyse and annotate all recordings. Thus, they use algorithms to do so. These algorithms perform tasks like talker diarization (Casillas and Cristia, 2019), whereby they identify who produced the vocalisations. Often, they identify demographics rather than specific individuals. For example, they identify whether a male adult, a female adult, the child wearing the device, or other children are producing the vocalisations. Currently, they do not analyse the content of the speech captured by long-form recordings. However, the field is advancing fast enough to imagine them being able to perform these analyses in the foreseeable future, yielding new ethical challenges.
The technology has been available for many decades (Wells, 1981). However, it became popular in the last decade in the field of children’s language acquisition due to the work of the Language ENvironment Analysis (LENA) Foundation. The Foundation developed a combination of hardware devices to record the infant and proprietary algorithms, trained with data collected from North American, English-learning infants, to analyse the recordings (Gilkerson et al., 2017). The LENA pipeline is the most widely used, but its cost results in inequality of access. Each recording device costs about 300 US$ and, although no prices are available on the LENA Foundation website, the most inexpensive quote for the software was about 7700 US$ in 2022, with costs increasing as a function of the number of recordings analysed (Coulter, 2022, personal communication). This analysis programme also requires a reasonable internet connection and data transfer over the web to the LENA servers located in the USA. 1
The last 5 years have seen the emergence of a cheaper set of alternatives. With international funding, the ACLEW collaborative project developed multilingually trained algorithms. They are open-source and free to use (Lavechin et al., 2020; Räsänen et al., 2020). Others have started exploring the use of mass-produced and, therefore, cheap devices like USB audio recorders, which can cost as little as 20 US$ (e.g. Scaff, 2019). Despite the low price, they have an audio quality comparable to LENA’s. This second type of pipeline should be more accessible to researchers based in LMICs, although it is still relatively unknown.
Long-form recordings can be used in disciplines, such as psychology and speech-language sciences, by researchers interested in the language metrics of infants and adults. For example, Oller et al. (2021) found that new born babies produce more speech-like vocalisations than cry vocalisations, contrary to what some parents may believe by using these recordings. Some long-form recording research projects aim to improve the lives of individuals and societal conditions. For instance, measurement of depression in adults (e.g. Mehl et al., 2010). Cychosz and Cristia (2022) mention three such uses of child-centred recordings: (1) the detection of language disorders and potential treatment evaluations, (2) large-scale real-life interventions aimed at improving children’s language and cognitive outcomes and (3) documenting under-documented languages.
Over the last few decades, researchers have, almost exclusively, collected audio data by recording individuals living in HICs. Indeed, a systematic review of LENA papers (Ganek and Eriks-Brophy, 2018a) reveals that 97.6% of participant samples were from residents in HICs (Canada, South Korea, the USA and the UK), with the remaining 2.4% based in an upper MIC (China). This is problematic as there is a need for better representation of all cultures and linguistic experiences for greater equity and diversity in research. Motivated by these considerations, researchers have more recently started to collect long-form audio recordings in LMICs, namely Bolivia (Cychosz, 2022; Scaff, 2019), China (Ma et al., 2021), India (Fibla Reixachs, 2021; Meera et al., 2023; Swaminathan et al., 2022), Mexico (Casillas et al., 2020; Nee, 2021), Papua New Guinea (Casillas et al., 2021), Senegal (Weber et al., 2017), Solomon Islands (Cassar et al., 2022), Vanuatu (Cristia et al., 2023) and Vietnam (Ganek and Eriks-Brophy, 2018b). 2 Although this work increases the diversity of participant samples, it is far from representative of live births, which in 2021 happened primarily in LMICs with 19% in low-income countries, 72% in middle-income countries and 9% in high-income countries (based on data from Our World in Data, 2022). Arguably, the best way to increase participant diversity is to increase researcher diversity (see Singh et al., 2023, for arguments). However, the diversity of authors is even more skewed (see Figure 1), with nearly 99% of first authors residing in HICs. The latter fact led us to write this article with authors residing in HICs as primary readers, although we hope that ongoing changes empower researchers residing in LMICs to increase their representation.
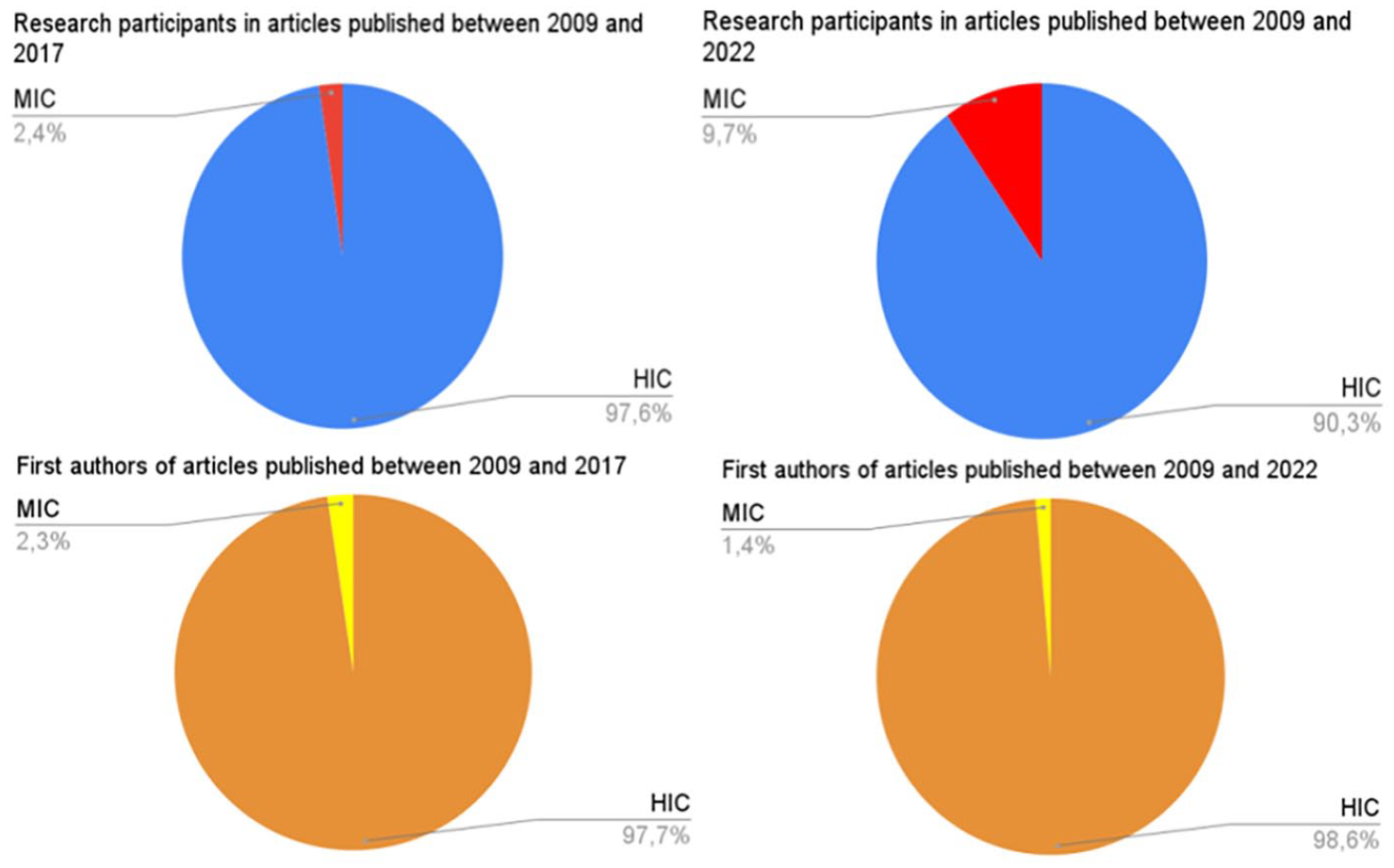
Sampling bias in long-form recordings research (source: Ganek and Eriks-Brophy, 2018a; Pubmed, 2022). Country of residence of research participants and first authors of long-form recordings research published between 2009 and 2017 (first and third pie charts) and 2009 and 2022 (second and fourth pie charts). We analyse countries of residence because countries of origin are typically not available for participants and researchers.
The need for ethics guidance regarding long-form recordings in LMICs
Researchers need to be extra careful while doing research in LMICs as there is a history of ethics dumping: the exportation of unethical research practices from HICs to LMICs (see Schroeder et al., 2018 for examples). 3 Moreover, some participants and communities in LMICs are vulnerable to research exploitation due to social, economic and political factors such as illiteracy, poverty, cultural differences with researchers, limited understanding of the nature of Western scientific research or political powerlessness. 4
Legislation also varies in ways that partially correlate with the country’s income. Members of the Language Acquisition Across Countries (LAAC) Team 5 reviewed legislation relevant to long-form recordings. They focused on data protection in the following countries: Argentina, Australia, Bolivia, Brazil, China, Costa Rica, Denmark, Finland, France, Ghana, India, Israel, South Korea, Malawi, Mexico, Netherlands, Norway, Papua New Guinea, Solomon Islands, South Africa, Sweden, Tanzania, Timor Leste, United Kingdom, Uruguay, Vanuatu and Vietnam. In general terms, the legislation was most protective of individuals in European and Latin American countries and resembled the General Data Protection Regulation (GDPR). Asian countries that are part of the Asia-Pacific Economic Cooperation also have some considerations for data protection. There was less or no legislation in the studied African countries. There was no legislation in Oceanian countries except for Australia. Few of these regulations consider the full extent of issues raised, including, for instance, algorithm bias (considered in Uruguay). In the absence of such regulations, it is particularly important to consider the individuals’ and communities’ welfare from an ethical perspective. That said, the members of the LAAC Team have not thoroughly studied regulations concerning research in particular, nor regulations beyond national or international entities as they apply to long-form recordings.
This is not to say that no guidance exists for lower-income countries. Beyond legally binding regulations, codes of ethics and other relevant resources about ethical and culturally sensitive research are starting to emerge. See, for example, the TRUST Code (TRUST, 2018) that aims to support all relevant stakeholders in the identification of ethical pitfalls in international research in resource-poor settings, and the code for Ethical Research Involving Children for guidance on cross-cultural research involving children (Powell et al., 2013). A growing number of Indigenous Populations have written their codes of ethics for research too (Assembly of First Nations, 2009; Hudson, 2010; South African San Institute, 2017). Moreover, institutional review boards or research ethics committees, with a quasi-legal status, protect vulnerable populations in most high-income countries.
Ethical challenges for research relying on long-form recordings in LMICs
In this section, we focus on four ethical challenges for research relying on long-form recordings in LMICs: the biases researchers could have while analysing the recordings, culturally inappropriate informed consent, algorithm biases and the lack of sufficient benefits for host communities. We discuss how researchers can overcome each challenge.
Researcher bias
Challenge
Researchers tend to be more familiar with the language development and experiences of infants from Western, educated and rich populations in HICs due to the sampling bias in developmental sciences (Singh et al., 2023). As a result, they might, consciously or unconsciously, take these behaviours and experiences as the norm and interpret infants from other communities’ linguistic development, and their caregivers’ role in that process, as being inferior to that norm. This could lead to the stigmatisation of communities, deter them from participating in other research projects, and impair researchers’ collaborations with these communities (Broesch et al., 2023). We cannot expand this due to space constraints but invite interested readers to look at the ongoing debate regarding the ‘30 million word gap’ for an example that touches on this issue and builds on research using LENA (e.g. Avineri et al., 2015; Golinkoff et al., 2019). Moreover, metrics used by researchers are influenced by their beliefs, such as the quantification of children’s input via Adult Word Count, which only considers adults and not other children as potential sources of relevant linguistic experiences (Cristia et al., 2023). It also means that any benefit arising from that research is more likely to bypass them (see also the Lack of sufficient benefits to host communities section below).
Proposed solutions
Researchers should keep in mind that socio-cultural factors influence developmental processes and assume that supposed ‘universal’ phenomena often differ between communities (Broesch et al., 2023; Singh et al., 2023). In addition to engaging in practices whereby they can acknowledge their own potential biases (e.g. positionality statements, Roberts et al., 2020), researchers can also collaborate with local researchers who may be less influenced by embedded assumptions fostered in HICs, particularly if they have worked long-term with, or come from, local communities. Local researchers and community representatives may more readily spot issues such as metrics that ignore local customs (for instance, a focus on adults as conversational partners), and provide insight into relevant cultural norms and guidelines to show respect for the community. When in doubt, it is better to use descriptive (e.g. ‘larger adult word count’) instead of normative language (e.g. ‘better language input’) while presenting research results. When working in such collaborative environments, it is imperative to consider power differentials (see Bruno et al., 2022
Culturally inappropriate informed consent
Challenge
Researchers traditionally obtain informed consent before collecting long-form recordings in a written format in HICs. The consent form includes an information sheet that covers the following items: a general description of long-form recordings, their length and scope; a description of the research project and how long-form recordings fit in; their plan for data sharing and participants’ rights to refuse data sharing; the risks of participation, such as confidentiality and privacy risks; and the rights of participants, which usually include (but are not limited to) the right to withdraw and ask questions at any given time (see Cychosz et al., 2020 for a complete list). Such procedures and forms may be culturally inappropriate in some communities from LMICs. Although culturally inappropriate ethical procedures have been discussed (e.g. Cross et al., 2015; Wynn, 2011), we believe the problem is heightened in the case of long-form recordings. We posted a question about this in a specialist mailing list (darcle.org), and several colleagues who use both long-form recordings and other types of research agreed that navigating ethical challenges through a consent form is particularly challenging for long-form recordings. The issues raised included the more extensive scope of personal and private information that can be accidentally recorded and of which individuals (both participants and researchers) may not have an intuitive understanding (VanDam et al., 2016), as well as the fact that consent forms for long-form recordings tend to be longer, leading families to miss details or sign without reading.
Proposed solutions
Changes researchers can make to render consent culturally appropriate have been discussed in other work (e.g. Wynn and Israel, 2018), and typically build on knowledge from local researchers and communities. Briefly, researchers can consider oral consent when there is a strong oral culture and/or high illiteracy. If a record is needed, researchers can audio-record the consent process in a separate recording to the long-form recording so that the identity of the person is not so easily linked to their long-form recording. Another option is to get a witness to sign a document to attest that the participant gave oral consent. Either way, the mode of consent should not prevent participants from exercising their rights, such as withdrawing their participation whenever they want.
Particularly for quickly changing technologies, such as those used in long-form recordings research, dynamic consent, where participants are invited to ‘alter their consent choices in real time’ (Kaye et al., 2015) may be preferable to one-shot informed consent. Dynamic consent may also be more relevant in communities that value reciprocal social relationships over one-time agreements (Broesch et al., 2020). For communities with good network access, this can be facilitated via a digital interface (Kaye et al., 2015), but even in other cases, such a solution should be sought to render the archiving of long-form recordings compatible with state-of-the-art data protection legislation like GDPR.
To ensure they comply with local ethics requirements, researchers should also seek approval from a local research ethics committee if there is one. One of the authors of the manuscript serves on an ethics committee with a long history. According to members of this committee, local ethics approval is recommended by most ethics committees in France and Canada, even though it may result in significant delays in the research project (see e.g. Chatfield et al., 2022). It is also recommended by the previously mentioned TRUST Code (TRUST, 2018).
Algorithm biases
Challenge
Algorithms are often used to analyse long-form recordings via software like LENA and the Voice Type Classifier (VTC). VTC is an open-source alternative to LENA trained with a more diverse corpus (Lavechin et al., 2020). Both segment the recordings into the following classes: children wearing the recording device, other children, male adults and female adults. These tools can be biased against some demographics from the recorded community. Indeed, speech processing algorithms trained with non-representative samples enact bias towards the under-represented demographic groups. In other words, their accuracy will be lower for these under-represented groups.
While algorithm bias is a methodological issue, it has ethical consequences, some of which have been discussed in fields like legal and political theory (see Angwin et al., 2016; Smith and Rustagi, 2016). We provide three consequences, appealing to key moral values.
First, algorithm bias can create a form of disrespect to the recorded communities or individual participants and thus be perceived as an affront to their honour.
Second, biases can effect inequality by preventing linguistic diversity and inclusiveness in research. Since algorithms are mainly trained on data from English speakers in HICs, and they can perform poorly in other languages and research in other languages may not be publishable, this perpetuating the aforementioned bias in the literature.
Third, they can have real-life negative consequences for the recorded communities. For instance, they could motivate misguided interventions or policies because they create an incomplete or inaccurate understanding of the language environment in which the child is evolving. For example, if a biased algorithm misclassified male caregivers as females, researchers may draw incorrect conclusions about the role of men in child language development. This could lead to policies or interventions that exclude or marginalise male caregivers.
Proposed solutions
Although algorithm bias has not yet captured researchers’ attention in the field that uses long-form recordings, it is important to consider it, particularly when relying on automated or partially automated analyses. The majority of researchers will not have a great deal of technical training. For them, our first advice is to measure these potential biases by extracting sections of the audio and annotating them manually (Pisani et al., 2022, chapter 15), and take steps to assess the accuracy of algorithms (see Cristia et al., 2020 for a meta-analysis). Ideally, researchers will obtain consent from the community to archive these data in a place where it can inform further algorithm development, including scientific archives like Homebank and Databrary (see Pisani et al., 2022, chapter 18 for more information). Usually, bias effects will be smaller when the algorithm has been trained with speakers with similar properties. Thus, we recommend ACLEW algorithms for LMIC applications as they have LMIC data in their training set.
Researchers with a technical background can consider fine-tuning or retraining the ACLEW algorithms. This is possible because their code is open and the LAAC Team is involved in such work. Indeed, LAAC is trying to increase the algorithm’s performance on vocalisations of other children (i.e. children other than the one wearing the recording device), which tended to be rarer in the original training set than vocalisations from the target child or female adults. LAAC’s current strategy is to oversample the under-represented group by screening sections of long-form recordings to find examples of other children’s voices and adding those sections to the training set. Given the goal of documenting children’s early vocal development, LAAC decided against two other strategies that may lead to reductions in accuracy in the key child class, namely, down-sampling of the over-represented group and changing the algorithm (Fletcher et al., 2020). The former involves removing examples of the key child from the training data set so that there are as many examples of the key child as other children’s voices. The latter involves changing how the parameters are optimised rather than trying to get the best performance overall (which means that parameters will tend to perform best for the most frequent class). The aim is to get a similar level of performance across each class.
Lack of sufficient benefit sharing
Challenge
Unlike a standardised test, which can be interpreted at the individual level, results from individual-level analyses of long-form recordings cannot readily be informative to individual participants. Moreover, learning about these phenomena might not be their priority, directly improve individuals’ life or even match the priorities of their community (Bird, 2020; Bruno et al., 2022). When communities are interested in these phenomena, it is important to bear in mind that scientific publications may be inaccessible to them. Community members might be illiterate, not fluent in English or other languages used, or unable to understand the results because of scientific jargon.
Proposed solutions
First and foremost, we stress that benefits need to be determined in collaboration with (representatives of the) participants and the community (see Leonard and Haynes, 2010, for advice). Otherwise, well-intentioned attempts to give back to the community could be perceived as instances of disrespect by research participants (see Davis and Krupa, 2022). Similarly, language documentation by an outsider may be an affront to community members who view language as their intellectual property, transmitted by their ancestors, and think it is their people’s prerogative to safeguard their cultural heritage.
One example of potential benefits related to long-form recordings is that the recordings can constitute a database to document under-represented languages or create other language resources based on how language is used in everyday activities and contexts (Cychosz and Cristia, 2022). Moreover, as with other types of language data, researchers with appropriate training and links to the software industry can use long-form recordings to build and train speech and language technology that the community considers useful. For example, they can build tools to convert spoken language into written text or provide translation tools (but see Bird, 2020, for the failed promises of speech and language technology).
Additionally, all usual forms of benefit sharing are open for long-form recordings, such as prioritising research directed to the community’s needs, social recognition, etc. In some cases, community members will ask for something unrelated to long-form recordings, such as medical and school supplies, in addition to or instead of monetary or in-kind compensation for the time and effort individuals and communities put into the project. We think researchers should honour these requests if possible (see Bowern, 2008, for advice about how to remunerate participants this way).
Conclusion
We outlined what we consider the most pressing challenges of research relying on long-form recordings in LMICs and proposed solutions for best practices that researchers can adopt to avoid falling into these ethical pitfalls. In summary, we have first argued that researchers can misinterpret and stigmatise the vocal inputs of individuals from LMICs. To avoid this, we suggest they stay open-minded, transparent and collaborate with local researchers and communities. Second, the consent forms and procedures used by researchers could be culturally inappropriate if they are similar to the ones from HICs. To avoid this, researchers should be sensitive to the local context. They might have to capture consent in an oral format. If possible, they should facilitate dynamic consent in preference to single-timed consent. Third, we have pointed out that algorithms could have lower accuracy for certain speaker types (e.g. for male speakers, and thus misrepresent the input of children reared primarily by fathers). To prevent this, researchers should test for biases and try to use algorithms trained on a more diverse training set. Those with technical training can re-train the algorithms and over-sample the underrepresented groups. Fourth, participants might not directly benefit from the research and its results. To avoid this, researchers should determine equitable benefits in collaboration with the host community.
Footnotes
Acknowledgements
We would like to thank members of the Language Acquisition Across Culture team (LAAC) and the Daylong Audio Recordings of Children’s Linguistic Environments group (DARCLE) for their comments and insights on early versions of the paper.
Anonymised content
In the spirit of reflexivity, we disclose the following aspects of ourselves, which we believe impact our perspective in the present article. One of the authors identifies as having a mixed Latin and White background, growing up in a comparatively wealthy family in a highly unequal, upper-middle income country, and later living in high-income countries while increasingly researching participants in low- and middle-income countries. These experiences sensitised her to inequalities in power and access that are hard to redress. She attempts to employ a mixed moral approach combining key values (including respect for autonomy and diversity, as well as scientific transparency) with consideration of consequences for participants’ and non-participants’ welfare.
Funding
All articles in Research Ethics are published as open access. There are no submission charges and no Article Processing Charges as these are fully funded by institutions through Knowledge Unlatched, resulting in no direct charge to authors. For more information about Knowledge Unlatched please see here: ![]() The research for this paper was funded by the J. S. McDonnell Foundation Understanding Human Cognition Scholar Award and the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (ExELang, Grant agreement No. 101001095).
The research for this paper was funded by the J. S. McDonnell Foundation Understanding Human Cognition Scholar Award and the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (ExELang, Grant agreement No. 101001095).
Ethics approval
Not applicable.