
Abstract
Twitter is an increasingly common source of rich, personalized qualitative data, as millions of people daily share their thoughts on myriad topics. However, questions remain unclear concerning if and how to quote publicly available social media data ethically. In this study, focusing on 136 education manuscripts quoting 2667 Tweets, we look to investigate the ways in which Tweets are quoted, the ethical discussions forwarded and actions taken, and the extent to which quoted Tweets are “discoverable.” A concerning result is that in almost all manuscripts, and for around half of all quoted Tweets, the original author could be identified. Drawing on our findings we share some ethical dilemmas, including those that arise from an apparent lack of understanding of the technical aspects of the platform, and offer suggestions for promoting ethically-informed practice.
Introduction
At the end of 2020, 192 million people were active daily users of the social media platform Twitter (Statista, 2021). On any given day, millions of “Tweets,” messages of up to 280 (previously 140) characters, are posted by individuals and groups sharing insights from the mundane to the existential. The sheer volume of data and its free availability make Twitter a fertile ground for collation of rich textual datasets that provide glimpses into the lives and minds of people from across the globe and over time. In this way, researchers may overcome some of the time, cost, and distance challenges often associated with qualitative data collection. Using Tweets, researchers have investigated topics as varied as the stigma surrounding homelessness (Kim et al., 2021), the experiences of first year university students (Liu et al., 2018), and the misuse of prescription opioids (Chary et al., 2017). At the time of writing, the COVID-19 pandemic is impacting every corner of the globe, and Twitter has proved a powerful resource for gaining insights related to topical issues including vaccine hesitancy (Griffith et al., 2021), attitudes to mask wearing (He et al., 2021), and the impact of the pandemic on the discrimination of Asian people (Jia et al., 2021).
As public Tweets are available freely, and have been posted voluntarily, the line between “public” and “private” is blurred (Gerrard, 2021), and debates have arisen about how and if to quote Tweets in the media (Nesbitt Golden, 2015; Nolan, 2014) and in research (Ahmed et al., 2018; Williams et al., 2018). Twitter’s terms of service allow public Tweets to be used in various ways by third parties and encourage users to “only provide content that [they] are comfortable sharing with others” (Twitter, 2021a, para 4). However, terms of service relating to social media usage are notoriously complicated (Fiesler et al., 2016) and many users lack understanding of how their online content can and may be used (Fiesler and Proferes, 2018). In any case, ethical research is “not easily wrapped in a term of service agreement” (Power, 2019: 196).
While quotes are more traditionally seen in qualitative papers, technological advances and the sheer volume of social media data now available has opened up a range of “big qualitative data” approaches that “blur the boundaries of qualitative and quantitative research” (Davidson et al., 2019: 365). In this changing landscape, researchers are dealing with new questions about how to engage in ethical research. For example, is informed consent possible when dealing with big data? (Froomkin, 2019). To what extent is anonymity possible if users’ personal information is publicly available? (Townsend and Wallace, 2020). Is it possible or practical to ensure participant confidentiality if the content has been posted voluntarily in the public domain? (British Psychological Society, 2021; Gerrard, 2021). What implications does this have for the current push toward increased data transparency and sharing, which can help build trust in the research, including enabling study replication? (Tromble, 2021). Leonelli et al. (2021) raise the important issue of equity in social media research, as data mining processes and algorithms privilege certain people and perspectives, introducing biases in the data. The growth of social media data has complicated the discussions, but “the process of evaluating the research ethics cannot be ignored simply because the data are seemingly public” (Boyd and Crawford, 2012: 672).
One of the issues that must be considered when quoting data from social media is that of discoverability. Discoverability, in the information science context, concerns the extent to which online content, in light of an abundance of choice, can attract or be found by target audiences (McKelvey and Hunt, 2019). While most content developers are concerned with making their content more discoverable, the issue of discoverability in research is inversely related to issues of privacy. Thus, if online content quoted in a study can be found online, that is, if it is discoverable, it can lead to the original source. This is particularly true of platforms such as Twitter that make their content freely available and easily searchable. Indeed, Twitter recently announced that it was expanding its services to enable researchers to “access the entire history of the public conversation on Twitter’s platform” (Perez, 2021, para 1). This means that not only is Twitter likely to be used increasingly as a source of research data, but it will also make that data more easily discoverable, with implications for ethical research practice. Also of importance within this debate is the “right to be forgotten,” a complex but not absolute legal right enacted in a number of jurisdictions including the European Union (Information Commissioner’s Office, n.d.), where in some certain circumstances individuals can request personal data to be removed from a platform, often used in relation to child protection (Carter, 2016). Beyond any legal rights that may apply, if a Tweet is published in a manuscript, it is set in concrete, and so users will lose the ability to delete it if they so choose in the future. Sarikakis and Winter (2017) found in their study that participants were only vaguely, if at all familiar with the concept of privacy, with understanding limited to issues of personal control of one’s own data.
Ethical considerations are not always present in social science manuscripts. For example, a recent analysis of 500 manuscripts found that more than half did not include any discussion of ethical considerations (Coates, 2021). In this study, we focus on the social science field of education, as one of the major domains of society alongside health and politics, in which social media wields considerable influence (Burgess et al., 2018). Education is a broad and interdisciplinary field that intersects with all other disciplines, one that impacts all individuals directly, if not through formal education then through informal and non-formal concepts of learning and teaching (Dib, 1988). Due to the nature of the field, research conducted in education may have a higher tendency toward qualitative, participant-centered research designs where addressing ethical issues is of paramount importance, particularly when it regularly involves students and children (Felzmann, 2009). Thus, it is an ideal field in which to serve as an initial case study.
In this study, we look to answer questions related to the practical and ethical approaches to reporting Tweets in published manuscripts, within our specific context but with implications for broader research discourse. Our research questions are as follows:
To what extent do manuscripts seek ethics approval and report ethical issues?
How are Tweets quoted, what is included and excluded from reporting?
To what extent are quoted Tweets discoverable?
What factors are related to the discovery of Tweets?
The study
We sought original studies published in peer-reviewed journals related to all sectors of education. No geographic or language constraints were imposed, and the time period under analysis ran from 2006, when Twitter was founded, to the end of 2020, with data collection conducted in early 2021. Studies were included in the corpus if they (a) included Tweets as a source of data, and (b) included quotes or excerpts from this data in the manuscript. Searches were conducted of ERIC (Educational Resources Information Center) and Scopus databases. The former was chosen as the oldest and largest database dedicated to education literature (Bell, 2015), while the latter was selected for its extensive coverage of social science journals (Mongeon and Paul-Hus, 2016). Searches were conducted using the following keyword search string, where + denotes a required term, and * returns all keywords containing the root: (+tweet OR +twitter) AND (education OR teach* OR learn* OR university OR college OR school).
Initial searches resulted in more than 2200 returns, just over 2000 when removing duplicates (Figure 1). Manuscripts were reviewed at deepening levels in order to remove ineligible cases. Manuscripts removed included those that utilized surveys, interviews, or other methods to elicit participants’ reported usage or perceptions of Twitter, a common research design observed, but one that sees the platform as a focus of inquiry and not (also) as a source of data. Other excluded studies focused purely on quantitative elements of Twitter, including user networks or hashtags. Six cases were unable to be included as the full text could not be sourced using the resources available to the researchers. At the end of these vetting procedures, 136 manuscripts were identified for inclusion.
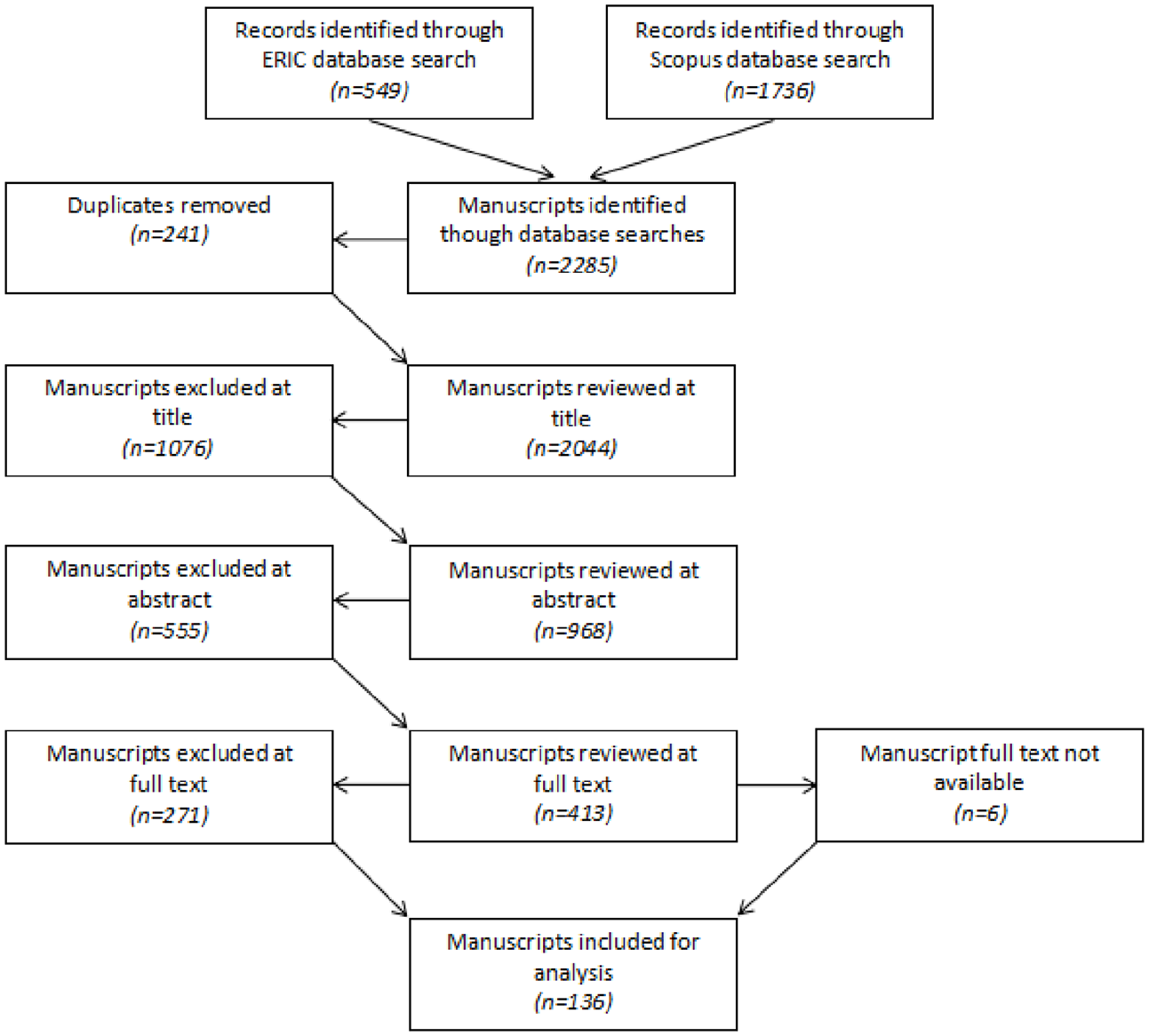
Identification and selection of manuscripts.
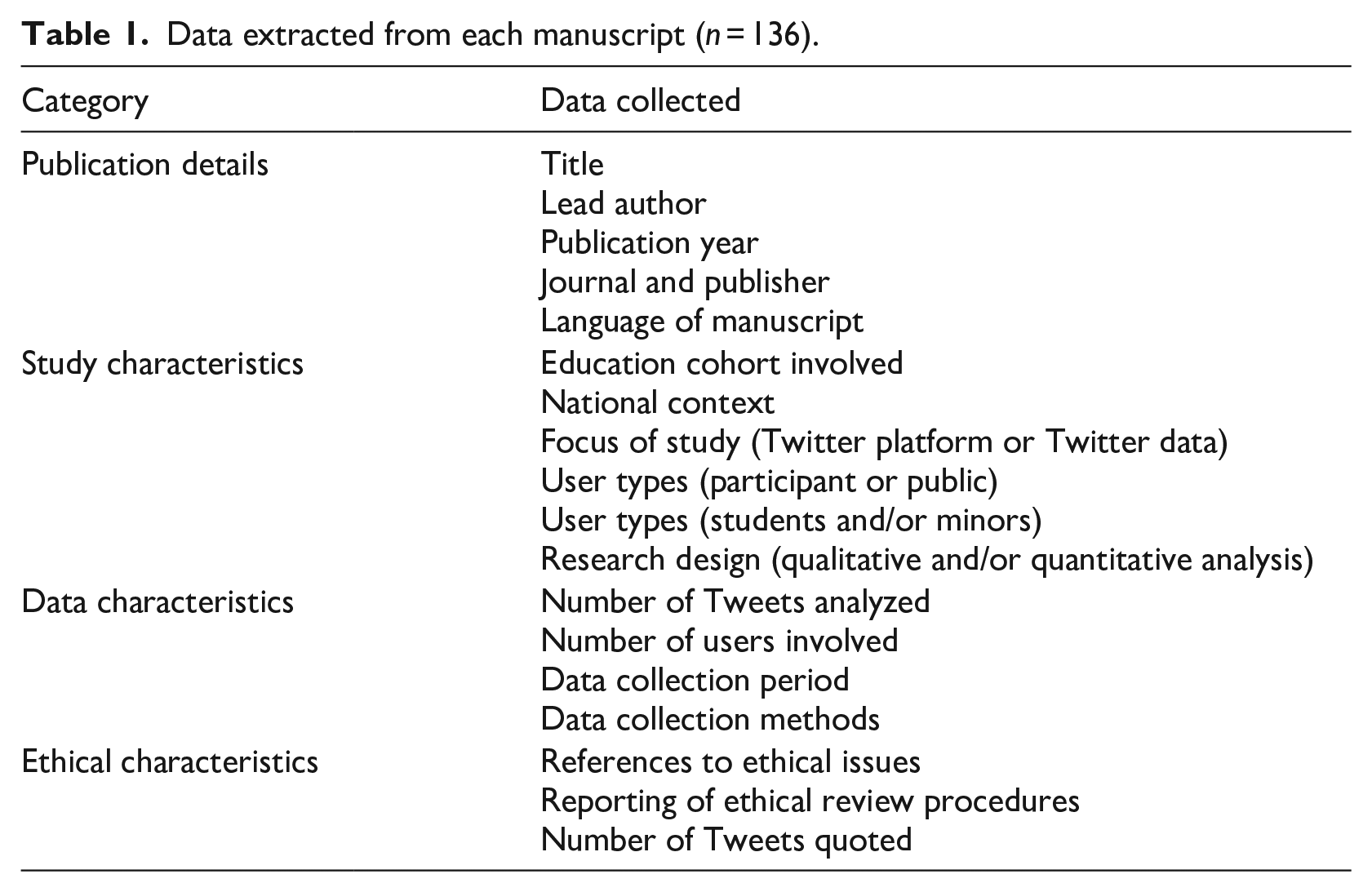
Manuscripts were analyzed using a Content Analysis approach, an umbrella term for a broad range of approaches that aim to describe and make sense of complex qualitative datasets through a systematic process of coding (Schreier, 2012). In particular, we focus on the manifest content, that which is “easily observable both to researchers and the coders who assist in their analyses, without the need to discern intent or identify deeper meaning” (Kleinheksel et al., 2020: 128). After determining the publication details, we coded each manuscript according to a range of information related to its study, data, and ethical characteristics (Table 1). These characteristics were chosen as they constitute the various methodological decisions made by researchers in designing, conducting and reporting their studies.
Data extracted from each manuscript (n = 136).
Coding was conducted equally by the two authors using a shared online spreadsheet. To strengthen reliability across the two coders, we initially coded a small number of manuscripts together to ensure mutual understanding of the meaning of each code. Further, while the information we sought was manifest and thus relatively objective, we engaged in regular discussions to discuss any unclear cases, and in all cases, agreement could be reached.
While most of the data fields presented in Table 1 are self-explanatory, several require further explanation. In this study, a distinction was made between studies where the focus is the Twitter platform, and those where the focus is purely on the content. Manuscripts were considered the former when the use of the platform itself was an integral part of the inquiry. In other studies the content of the Tweets is central to the inquiry, and the platform itself serves only as a tool through which to access the relevant data. We also distinguish between two types of Twitter users. “Participants” are those who are involved in a specific study, through which their relevant Tweets become part of the data collected for the study. On the other hand, users that are referred to as “public” are those whose Twitter posts may be used for a study but are not technically participants in a traditional sense, the data is collected without a direct relationship with the researcher, and they may or may not be aware that their Tweets are part of a study. Whether classified as participants or users, these groups may also include students and/or minors, which we also included in our coding procedures.
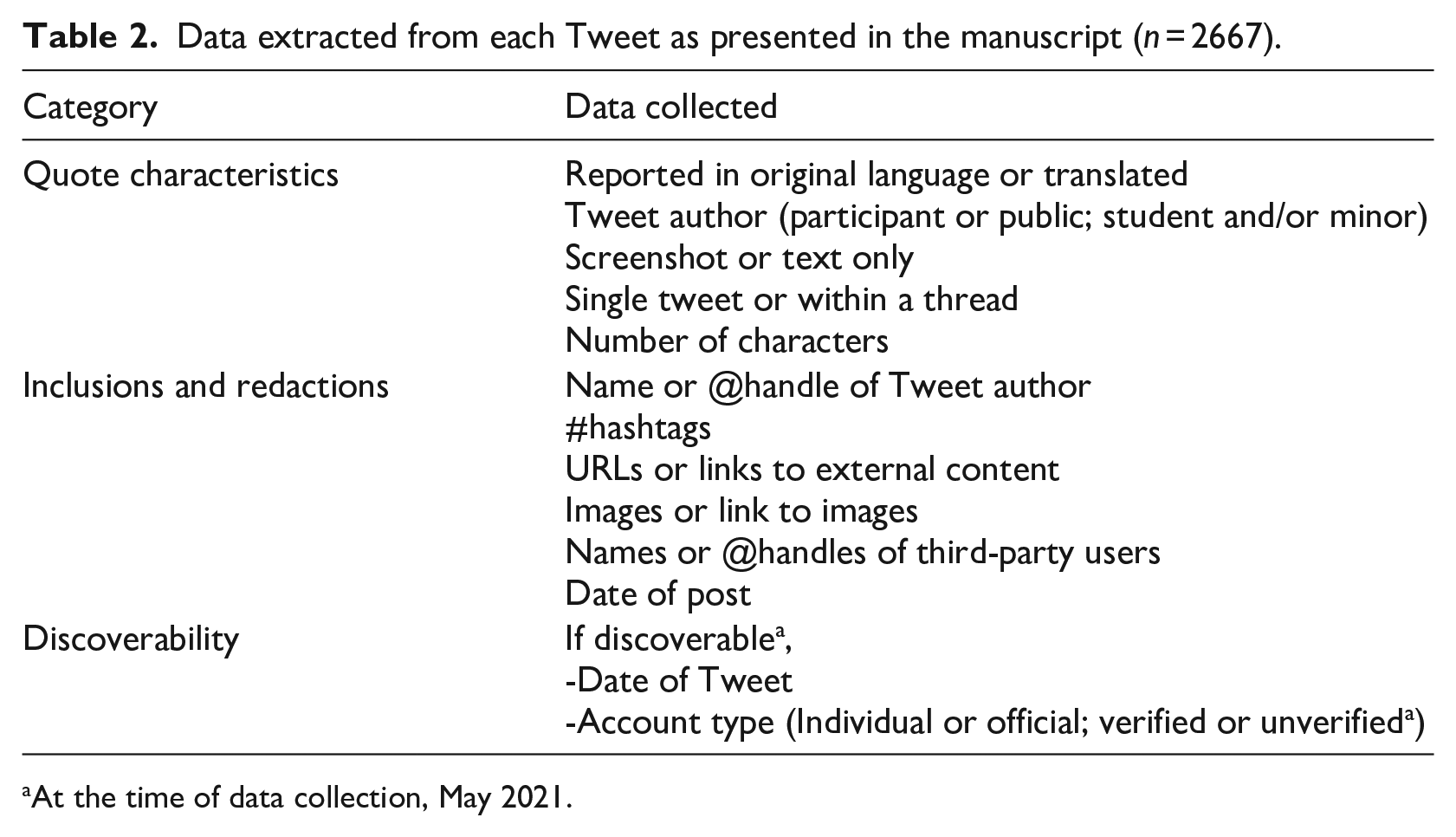
Once each manuscript was coded, we extracted the content of all Tweets that were included in each manuscript and added them to a separate spreadsheet. Each of these 2667 Tweets were coded according to the criteria in Table 2, again selected as characteristics that cover the variety of ways in which researchers may opt to report Twitter data in their manuscripts.
Data extracted from each Tweet as presented in the manuscript (n = 2667).
At the time of data collection, May 2021.
Regarding the “Inclusions and redactions” category, we looked to see what was reported in the manuscript within or alongside the Tweet. Using “URL” as an example, a Tweet would be given a “Yes” or “No” code depending on whether a URL was included or not. A “no” code does not necessarily mean that there was no URL in the original Tweet, merely that it was not reported in the manuscript. In cases where a URL was mentioned but not included, a “redacted” code was applied. This information might be redacted through covering, explicitly removing, or replacing the relevant details. The distinction from a “No” code is that readers are made aware that this element was present in the original post, even if it was not included in the manuscript.
To determine the discoverability of each Tweet, we conducted manual searches using the Twitter search tool, known as an Application Programming Interface (API), which has both a standard and advanced function. To illustrate, we posted a Tweet on the first author’s public Twitter account. Figure 2 shows examples of three ways in which the content of this Tweet might be reported in a manuscript, with different levels of deviation from the original post. Part A shows a screenshot of the original Tweet with identifying details redacted. However, including a simple text search the Tweet can easily be found and the hidden information revealed. This is the same when searching only particular keywords when Tweets are excerpted as in Part B. In the case of paraphrased Tweets, as in Part C, the original post might not in itself be discoverable through a text search alone, but may be discoverable when paired with other details that may be included (such as the date of posting), or that may become apparent (e.g. another Tweet in the same paper may reveal a redacted hashtag). We invite readers to try to locate our original Tweet and let us know in the comments on Twitter if they are successful.

Example Tweet posted by the authors with three different ways of reporting.
If a Tweet was discovered, we recorded the year of initial posting, as well as details about the user account by reviewing the account’s bio, username, and profile image. An account that appeared to be owned by an individual person (including anonymous accounts) was coded as “individual,” while those used by institutions, organizations, corporations, or other collectives were coded as “official.” This is different from a “verified” account, those that the Twitter platform has deemed to be active, authentic, and notable, typically individuals and organizations with some influence and public profile, marked with a blue checkmark (Twitter, 2021b).
For all levels of coding, the same procedures were followed regardless of language. Where the linguistic expertise of the authors was not sufficient, we requested the assistance of learned colleagues proficient in the target languages. To ensure consistency, we provided step-by-step guidance on how to conduct the analyses, which included identifying particular characteristics of a manuscript, or attempting to locate translated Tweets.
The data analysis began with descriptive statistics to summarize the data according to measures of frequency, central tendency, and dispersion. This allowed us to determine the various and common practices adopted by researchers when reporting quoted Twitter data. Then, we ran a series of non-parametric tests (Chi square tests of independence with effect sizes, Point-biserial correlations, and Spearman’s correlations depending on the data assumptions as recommended by Mat Roni et al., 2020) in order to identify any relationship to discoverability of each variable, at both the manuscript and Tweet levels.
Results
In this section we provide an overview of the current practices, with the left part of Tables 3 and 4 providing specific counts where appropriate.
Characteristics of manuscripts (n = 136), and their relationship to discoverability.
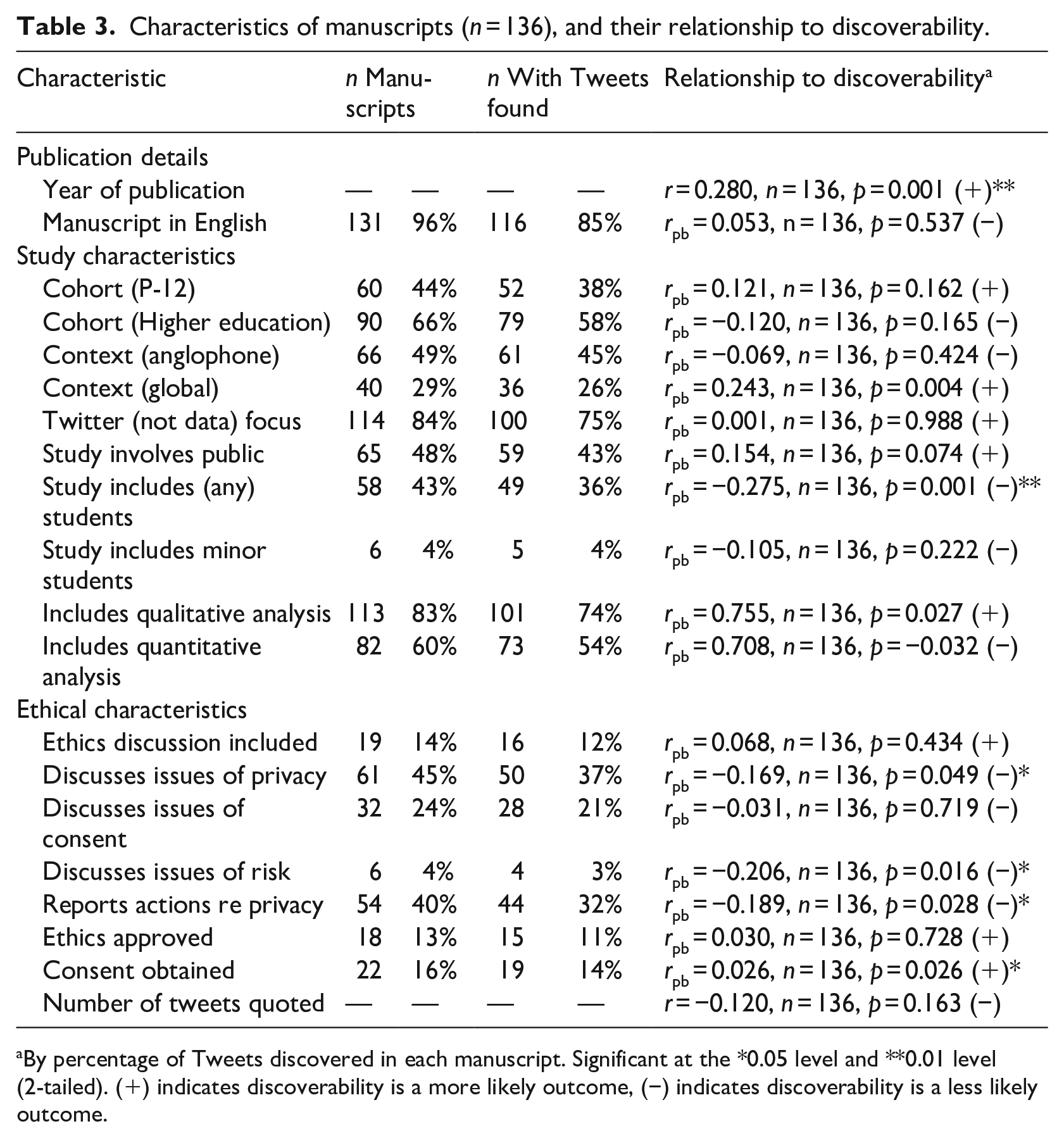
By percentage of Tweets discovered in each manuscript. Significant at the *0.05 level and **0.01 level (2-tailed). (+) indicates discoverability is a more likely outcome, (−) indicates discoverability is a less likely outcome.
Characteristics of Tweets (n = 2667), and their relationship to discoverability.
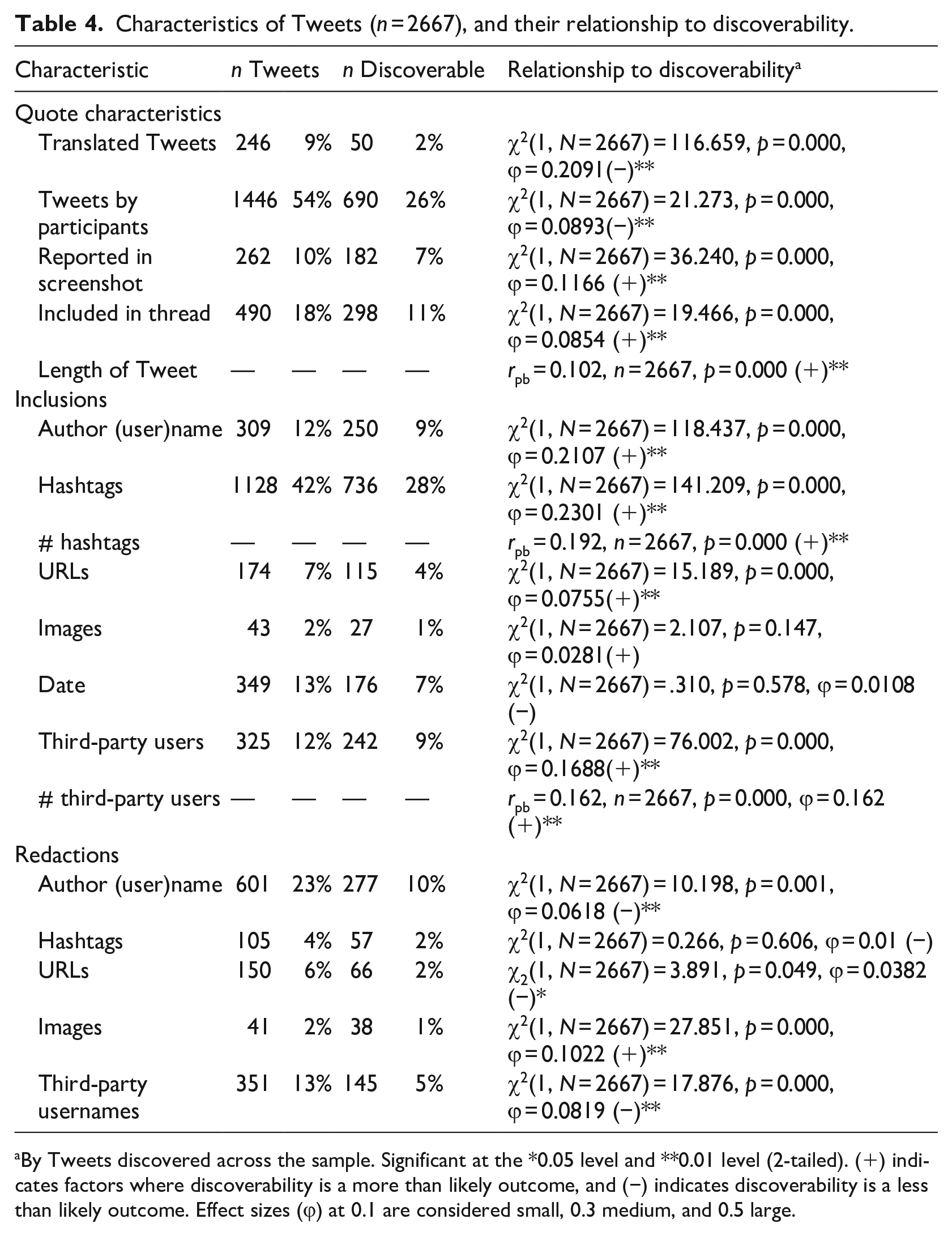
By Tweets discovered across the sample. Significant at the *0.05 level and **0.01 level (2-tailed). (+) indicates factors where discoverability is a more than likely outcome, and (−) indicates discoverability is a less than likely outcome. Effect sizes (ϕ) at 0.1 are considered small, 0.3 medium, and 0.5 large.
Manuscript-level analysis
Publication details
Within our sample of 136 manuscripts, the earliest was published in 2010, with the majority published in the past 5 years (Figure 3). Manuscripts were published in 107 different journals by 56 publishers. 123 different lead authors were identified, with 10 authors leading two or more papers. The majority of articles were written in English (96%, n = 131), with five in other languages.
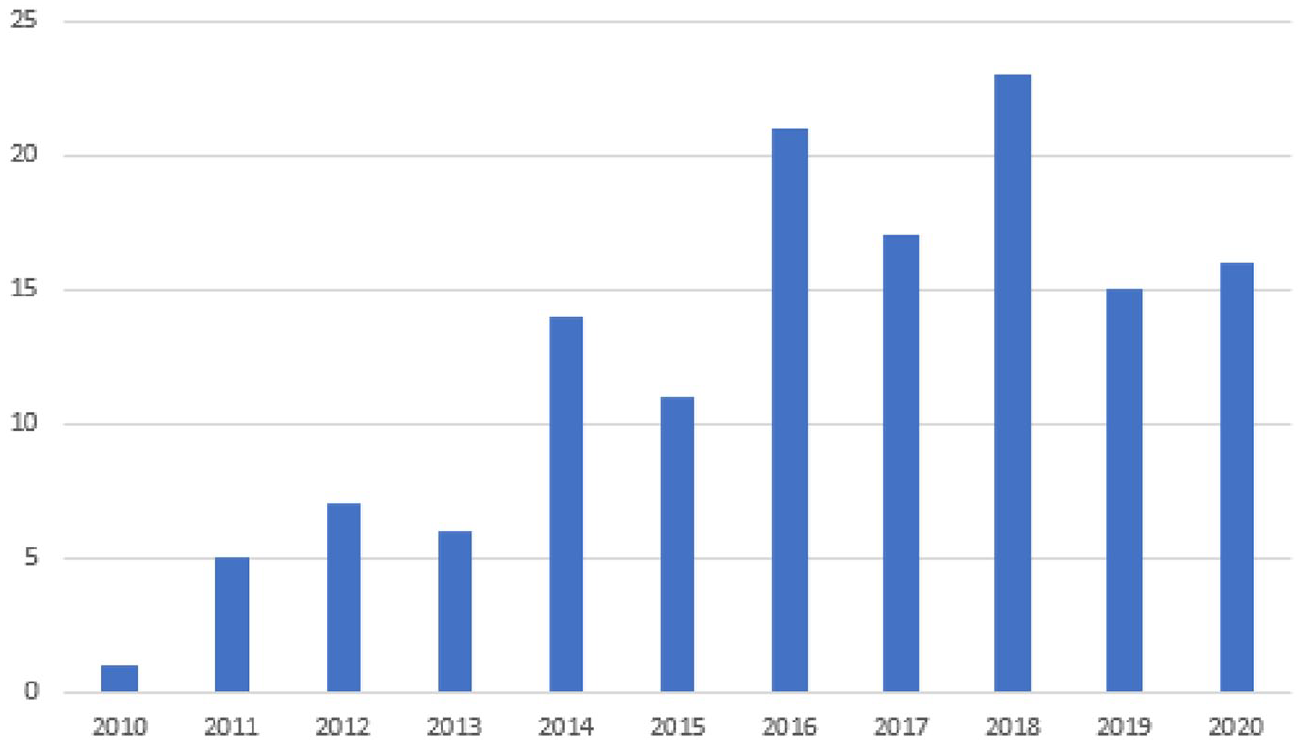
Manuscripts included in the corpus, by year (N = 136).
Study characteristics
Just over half of the studies (n = 76, 56%) were focused on the higher education sector, while around one third were focused on the P-12 sector (n = 46, 34%), with the remaining studies more broadly defined. Because of the global nature of Twitter, some studies were not (overtly) bound by a geographic scope although a majority (n = 96, 71%) were limited to a specific national context with 20 countries represented, most commonly the United States (n = 47), Spain (n = 8), Canada (n = 6), and the United Kingdom (n = 6). As shown in Table 3, the majority of studies involved participants in the traditional sense, with Twitter as a central focus. Tweets represented various perspectives, including school teachers, school students, university educators and scholars, and undergraduate and postgraduate students, as well as individuals and groups with a vested interest in, or opinions related to, various educational issues. The studies involved qualitative (n = 113, 83%) and quantitative approaches (n = 82, 60%) to data collection, with just under half (n = 59, 43%) involving both in a mixed methods design.
Data characteristics
The total number of Tweets included in a study ranged from 63 up to 15.9 million, with an average of around 324,000. We note that only some studies provided this information (n = 103) and even then it was not always clear what the number given indicated (e.g. some study designs involve a large corpus of Tweets, but analysis of the actual content is conducted only on a subset of the sample). Similarly, the data provided about the number of users involved in a study was not regularly discussed. From 98 studies with data reported, user numbers ranged from one to more than 70,000, with an average of around 2200, although the majority (n = 66) involved less than 100 users. We observed several starting points for data collection, including participant accounts, public accounts of relevance, keywords, and/or hashtags. The duration of data collection ran from several hours to several years, sometimes related to the duration of a course or event. Because of the lack of consistent reporting, these data characteristics are not included in our statistical procedures.
Ethical characteristics
We found that only 19 manuscripts included a dedicated research ethics section, although 75 made some mention of the following ethical concerns: privacy (n = 61), consent (n = 32), and risk to participants (n = 5) (Table 3). A majority of manuscripts (n = 110, 81%) made no mention of a formal ethical review process, while 15% (n = 21) reported that they had undergone a formal review process. Of these, 18 received ethics approval, and three received a formal waiver. Five additional studies made reference to a lack of need for ethical clearance due to the public nature of the data.
Discoverability
In terms of discoverability, at least one quoted Tweet was discovered from a majority of articles (n = 121, 89%), with an average of 55% of Tweets per manuscript located. At each extreme, no quoted Tweets were discoverable in 15 manuscripts (total 308 Tweets), and all quoted Tweets were discoverable in 20 manuscripts (total 226 Tweets). The right side of Table 3 shows the number of manuscripts which include at least one discovered Tweet in each category, and the results of the statistical analyses. As shown, six of the variables were correlated either positively (+) or negatively (−) to discoverability, as indicated by ** or *. Specifically, manuscripts where more Tweets were discoverable were those published more recently, and those where consent was obtained. Tweets less likely to be discovered were found in manuscripts that include students, that discuss issues of risk and privacy, and that report taking actions to promote privacy.
Tweet-level analysis
Quote characteristics
Tweets quoted in full or in part across all manuscripts totaled 2667, ranging from 1 to 81, with an average of 20 Tweets per manuscript. Most Tweets were reported solely in English (n = 2468), with other Tweets reported (sometimes with an English translation) in Spanish (n = 91), German (n = 30), Dutch (n = 27), Indonesian (n = 15), French (n = 14), Portuguese (n = 10), Chinese (n = 3), and Danish (n = 1). This totaled 191 Tweets written in a language other than English within manuscripts. However, of all the original Tweets, 437 Tweets were originally posted in languages other than English, with 246 Tweets, or around 10% of the total corpus, being translated into English. As shown in Table 4, most Tweets were reported as text only, and were presented as a single Tweet. For those included in a thread of related Tweets, most common were threads of two or three Tweets, with the longest being a conversation involving 25 tweets.
Inclusions and redactions
Table 4 provides an overview of the inclusions and redactions within Tweets across the sample, showing that hashtags are the most common element included, while redactions were commonly attributed to usernames, both of the original poster and of third parties. Not shown in the Table are observations beyond our original coding protocol, including direct links to 17 Tweets across two manuscripts, and bibliographic citations of 13 Tweets across three manuscripts.
Discoverability
More than half of all Tweets across the corpus (n = 1382, 52%) were found to be discoverable. Table 4 shows that a majority of the characteristics analyzed had a strong association to discoverability, again indicated by ** or *. Tweets that were more likely to be discoverable include those with hashtags and usernames, as well as those reported as screenshots. Less likely to be discoverable were Tweets that were translated before reporting, those that were authored by participants, and those with usernames redacted.
Our final analyses focused on the account characteristics of the discovered Tweets, which date back as early as 2009 (n = 33), with half of all discovered Tweets posted prior to 2015. As seen in Table 5, neither of these account-level variables were significantly related to discoverability.
Account characteristics of discovered Tweets (n = 1384), and their relationship to discoverability.

(+) indicates factors where discoverability is a more than likely outcome, and (−) indicates discoverability is a less than likely outcome. Effect sizes (ϕ) at 0.1 are considered small, 0.3 medium, and 0.5 large.
Discussion
In response to our first research question regarding ethical procedures and discussions, we note that these issues are often not included, mirroring previous social media research (Dawson, 2014; Hokke et al., 2018; Stommel and Rijk, 2021). Only a small number of studies were approved for ethical review, indicating that in some cases it may not be considered necessary. This is certainly evident in instances where ethical clearance was sought but waived. In itself, the lack of ethical clearance may not be a concern; there are acknowledged problems with formal ethical processes that may be more about administrative “box ticking” than promoting “a proper conversation about research ethics in the community of researchers” (Whelan, 2018: 1). Further, formal review boards are not available to all researchers, particularly those outside of well-resourced institutions (Giraud et al., 2019). However, there is a need to consider ethics not only as procedure but, perhaps more importantly, as practice (Guillemin and Gillam, 2004).
The issue most commonly addressed in manuscripts was privacy, in some cases to report actions taken to promote anonymity and/or confidentiality, and in some cases to provide a justification for not doing so, generally limited to the public nature of the data. Efforts to promote privacy are concentrated in studies involving participants, particularly students. This is important because students are often vulnerable in research designs involving educators in positions of authority, and researchers likely have a legal if not a moral duty of care to their student participants (Sherwood and Parsons, 2021). However, the right to privacy is often not afforded to members of the public, and particularly those in the public eye. The extent to which we should afford privacy to those whose data we quote is highly dependent on the nature of the study and its participants. For example, it may not be necessary when quoting Tweets from official accounts of political figures. However, many cases are not usually so clear cut. Even though technology has allowed researchers to collect personal data without direct interaction, it does not negate a researchers’ obligation to consider the fundamental ethical issue of privacy and its appropriateness for each study.
Informed consent was gained from participants in some cases, although it is generally unclear what was being consented to, and how informed a participant was. A fundamental role of informed consent is ensuring that participants are fully informed about their involvement at all levels of the research process (including publication), and understand the potential implications of consenting, such as the limits to anonymization of online data (Dawson, 2014) and the risks of having Tweets elevated beyond their intended audience (Dym and Fiesler, 2020). In only two cases is it explicitly stated that participants have provided their consent specifically to have their Tweets quoted in a manuscript. In other cases, it is unclear whether consent extends beyond general consent to participate in the study. While most studies make no mention of consent at all, some cite the public nature of Tweets as a form of implied consent. While again, this may be legally appropriate, this clashes with user expectations that they would be asked to give their consent before their data were published in research papers (Beninger et al., 2014).
Gaining consent may not be appropriate in all cases, as in our previous example of political leaders. In other cases, such as research that involves vulnerable populations, direct quoting may be unacceptable. A recent study that received ethical clearance, and where authors followed published guidelines on the use of social media data, “sparked debate and some objections on social media” (Morant et al., 2021: 1). Subsequently, the researchers released a comment about their procedures revealing that they did not involve gaining explicit consent from “participants” in vulnerable positions. The decisions taken by researchers about whether or not to quote a Tweet, and whether or not to obtain consent to do so, are highly consequential. They depend upon a complex interplay of factors, such as the social position of the Twitter user, the “publicness” of the tweet, the relationship between the researcher and the researched, the vulnerability of the users, and the sensitivity of the content. At present, the justifications offered in many studies (if provided at all) are generally not grounded in ethical discussions, such as the public nature of the data, or the large size of the sample. On this final point, we note that manuscripts generally include quotes from a small subset of their sample, and so consent to quote remains a simple way to give users some agency over how (or if) their words are quoted. As Beninger et al. (2014) found, there are a range of opinions among users regarding the use of their online content, and while some may be unwilling to consent, others are happy to see their work published in research.
The only other ethical issue noted involved “risk to participants.” In one case risk was deemed to be absent. In another, risk was stated as being no more than that assumed when agreeing to the Twitter terms of service. In the other three instances, risk was related to the risk of unwanted comments from other users, and the potential of Tweets to impact future careers. No other ethical concerns were raised. Notably, no study included acknowledgment of the methodological limitations of collecting data using algorithmic data collection methods, nor of the biases introduced when limiting data collection to a single source.
Our second research question is about how Tweets are reported in manuscripts. In some manuscripts a small number of Tweets were quoted, for example to illustrate a coding schema, while in others multiple Tweets were quoted as an integral component of the manuscript. Some Tweets are quoted verbatim with a range of identifying details, some being a screenshot of and/or link to the Tweet itself. Others were included verbatim but with identifying features removed, and others were included in paraphrased or excerpted form. Quotes are not just limited to qualitative and mixed-methods studies, but also appear in quantitative studies, including those that focus largely on aggregate data. Manuscripts in this study were selected expressly because a decision had been made by the author/s to include at least one Tweet in reporting or discussing the findings. This constitutes personal, qualitative data that is linked intimately and directly to real individuals, or at the very least to their online persona. Regardless of the analytical approach, the inclusion of quotes impels researchers to provide justifications for these decisions, but this is largely missing from manuscripts.
One question we should ask ourselves is what purpose do the Tweets serve? According to Corden and Sainsbury (2006), quotes may be used as evidence, to explain, to illustrate, to enhance readability, to deepen understanding, to give voice to participants, and in some cases quotes themselves are the matter of inquiry. Through our reading, we noted that it was common for Tweets to be included to explain coding schemes, even quoting examples of irrelevant Tweets that were exluded from a study. It is unclear whether direct quoting is necessary in such cases where an explanation might suffice. Further, if giving voice to participants is a goal for the inclusion of quotes, then surely not giving the author an opportunity to consent is in contradiction to that goal. If the goal is to explain a concept, then paraphrasing and mixing details of several Tweets that deal with the concept may allow researchers to retain the desired balance between preserving meaning and ensuring privacy (Saunders et al., 2015).
Research questions three and four deal with the discovery of Tweets. Tweets quoted in education manuscripts were regularly discovered. In our efforts to locate Tweets, we did not go to any extraordinary lengths, we did not use specialized tools, nor did we spend excessive time searching. So, we can assume that our ability to locate half of all Tweets would also be possible for the average curious manuscript reader. While it is not correct to say that all of these discoveries represent breaches of privacy, among the discovered Tweets are those quoted in studies where authors aimed to keep participants’ identities confidential, evidenced through explicit reporting and/or implicit action such as redacting identifying details. They also include Tweets authored by students and minors, as well as those that address issues that may be sensitive or place Twitter users in a vulnerable position, such as teachers criticizing government education policy. Even with the best of intentions, deductive disclosure is a possibility (Dawson, 2014; Zimmer, 2010). While the only way to guarantee confidentiality is to not include quotations from Tweets at all, or to edit them to such an extent that they are no longer recognizable, this may take away from the integrity and value of the data, which is often enhanced by retaining the original words of the authors (Saunders et al., 2015). It is incumbent upon the researcher to consider the benefits and risks of including quotes in different formats.
We note that discoverability is not decreasing over time, despite Twitter now being 15 years old and regularly featured in scholarship across a range of disciplines. As Sloan et al. (2020) surmise, researchers’ engagement with Twitter data has “outpaced our technical understandings of how the data are constituted” (Sloan et al., 2020: 63). Indeed, we found some cases of deductive disclosures that appear to stem from a lack of understanding of the technical aspects of the platform. One aspect of Twitter requiring more understanding is hashtags, whose very function is to make content easier to find. It was interesting to see that at times, in the same paper, and sometimes even within a single Tweet, effort was made to redact one hashtag (e.g. one used for a course), while at the same time others were retained. In other cases, efforts were made to redact URLs, images, and/or usernames, but hashtags were kept intact. The redactions suggest efforts to promote privacy, but the inclusion of (some) hashtags likely countered those efforts, as in our study the strongest association with discovery was the inclusion of hashtags, and the more hashtags included the more likely a Tweet was discoverable. We thus advise caution when including hashtags in quoted Tweets, particularly if confidentiality is a goal.
Another technical aspect of Twitter in need of consideration is the search tool. The freely available advanced feature allows users to search for text, but also to filter for other details, including language, dates, and related accounts. While excerpting might be effective in some cases, and we found shorter Tweets to be less discoverable, it is possible to locate a Tweet even of a relatively short length; we found 26 Tweets that were less than 20 characters, the shortest simply replying “hi.” This is also why we (or our volunteer experts) were able to locate some Tweets that were originally posted in other languages. While translated Tweets were in fact more difficult to find, translation is not a guarantee of confidentiality. A few well-chosen keywords is often all that is needed. The strength of the Twitter search is a blessing for researchers who wish to collate Tweets on a particular issue, but at the same time it makes them more discoverable than some authors appear to presume. We recommend that researchers undertake their own “discovery” exercises to determine the extent to which quoted Tweets can be found and make their reporting decisions accordingly.
We noted some additional ethical dilemmas that can arise when researchers are part of a study with their students, common in higher education research. For example, we observed that in some studies where both students and educators were quoted, student identities were redacted but educators were not. However, when one Tweet is identified it may lead to the further identification of others, particularly if they are reported within a thread. Further, it is difficult to anonymize a researcher who may be both an active participant and a manuscript author, as their name and institution will be listed in the manuscript byline. With this knowledge, we were able to find redacted course hashtags on one researcher’s Twitter profile page. In another case a Twitter search revealed a redacted hashtag that was included in a post by a researcher announcing the publication of the very study in which the hashtag had been very carefully redacted. We also pondered the issue of peer-review, which in education usually follows a double-blind model. If a researcher can be identified through Twitter searches during the peer review process, this may compromise impartiality in the review process. While it seems that education researchers are rightly concerned about the privacy of their student participants, it is equally important that they also consider how their own identities are positioned, as threats to confidentiality of one participant generally means threats to others.
Final remarks
It is easy to get caught up in debates about what is public and what is private with regards to social media data, but focusing on this single and simplistic dichotomy draws our attention away from the real complexity and nuances of what it means to engage with this relatively new form of data. Consideration of ethical issues must play a more prominent role in social media research design, and as such the inclusion of “public” data should not be used as justification for avoidance of ethical clearance procedures. At the same time, researchers should not rely exclusively on guidelines or ethics boards/committees to inform their decisions, as they may be absent or lacking in appropriate skills and knowledge. Ethical review procedures and guidelines need to be updated regularly to reflect current trends in data collection and reporting.
Decisions about whether and how to quote Tweets in manuscripts require a number of considerations. An understanding of the unique social context of each study is necessary; gaining consent and ensuring confidentiality may not be essential when analyzing the Tweets of public figures like political leaders, but is of paramount importance in research involving Tweets from members of vulnerable groups. Even without direct interaction, it must be acknowledged that Tweets are posted by individuals with different needs, vulnerabilities, and relationships to the research/er. Further, a critical appraisal is needed to determine the purpose of Tweets and what is gained by their inclusion (and what is missed by their omission) in both a study and a manuscript. If the inclusion of Tweets is deemed to bring value, appraisal must then extend to a consideration of any potential harmful consequences or risks to participants, and unless these can be circumvented, priority must be given to the welfare of the participants. Finally, there is a need for researchers to understand the platforms they employ; our ability to engage ethically in social media research is limited by our knowledge of the platforms we use. In this study we have highlighted a number of common practices in reporting Tweets that may hinder attempts to promote privacy, indicating a limited understanding of the technical aspects of the platform and how easy it can be to breach confidentiality, even with the best of intentions.
Taking the time to consider these issues is vital for ethical research, but it is also important that the ultimate decisions are explained and justified within manuscripts. Within our sample, evidence of engagement with questions of ethics is limited in most cases. Justifications that the data are public, or the dataset is large, are not indicative of a robust reflection of ethics. Communicating practices and decisions clearly will serve to build transparency, to contribute to the broader ethical discourse within social media research, and to model good practice. It is incumbent upon researchers to base their methodological decisions on a sound ethical foundation, but it is also something that ethics review boards, journal editors, and peer reviewers should encourage. With constant changes in the social media data landscape, researchers need to be constantly and critically reflecting on their practices because it must be researchers, and not social media platforms, who lead the way in promoting ethical research (Pagoto and Nebeker, 2019).
Footnotes
Acknowledgements
The authors wish to thank the generous support from the following people who gave their time and language expertise which enabled us to include in our study manuscripts and data in languages other than English: Matt Absalom, Isabelle Heyerick, Anabela Malpique, Pascal Matzler, Lafi Munira, Alireza Valanezhad, and Michiko Weinmann.
Funding
All articles in Research Ethics are published as open access. There are no submission charges and no Article Processing Charges as these are fully funded by institutions through Knowledge Unlatched, resulting in no direct charge to authors. For more information about Knowledge Unlatched please see here: ![]()