
Abstract
Background:
Menstrual literacy is crucial for safeguarding the health, dignity, and rights of women. However, in low- and middle-income countries (LMICs), such as Bangladesh, it remains an overlooked issue. Female university students, positioned at a pivotal developmental stage, require accurate and comprehensive knowledge about menstruation. Despite overall improvements in education, significant gaps persist in menstrual knowledge and hygiene practices among this group.
Objectives:
This study aimed to predict menstrual literacy levels among female university students in Bangladesh using tree-based machine learning models. It also sought to identify the most influential predictors shaping menstrual knowledge.
Design:
A cross-sectional analytical design was employed to assess menstrual literacy and apply predictive modeling.
Methods:
A total of 576 female students from a public university in Bangladesh participated in a structured survey. Data were collected on sociodemographic and menstrual characteristics. Five tree-based machine learning models—Random Forest, Decision Tree, Extra Trees, LightGBM, and XGBoost—were trained to classify participants based on their level of menstrual knowledge. Model performance was evaluated using accuracy, F1-score, and receiver operating characteristic (ROC)- Area Under the Curve metrics.
Results:
Overall, 76% of participants demonstrated good menstrual knowledge, while 24% had poor knowledge. The Random Forest model outperformed others with an accuracy of 81%, followed closely by Extra Trees, LightGBM, and XGBoost (each at 80%). Key predictors identified across models included menstrual duration, type of hygiene materials used, permanent residence, and whether participants received early menstrual education. All models performed better in predicting participants with good knowledge, revealing a class imbalance.
Conclusion:
Tree-based machine learning approaches effectively predict menstrual literacy and uncover critical influencing factors. These findings can guide targeted educational interventions and public health strategies to improve menstrual literacy, particularly in LMIC settings such as Bangladesh.
Keywords
Introduction
Menstrual literacy is a critical component of women’s well-being, encompassing the knowledge and understanding necessary to manage menstruation effectively and with dignity.1,2 In low- and middle-income countries (LMICs) such as Bangladesh, menstrual literacy remains a significant public health concern, especially among adolescents and young women in higher education settings.3–5 Despite increased enrollment of women in tertiary institutions, widespread misinformation, stigma, and sociocultural taboos surrounding menstruation continue to pose barriers to menstrual education and self-care practices.6–8 University-aged women, who are often in the transitional phase between adolescence and adulthood, represent a key demographic for understanding menstrual health literacy.9,10 They are expected to possess a foundational level of knowledge regarding reproductive health, yet many still lack accurate information, proper menstrual hygiene practices, and access to supportive infrastructure.11–13 This gap not only affects their physical and mental health but also influences academic performance, social participation, and long-term reproductive choices.14–16
Previously conducted studies from both global and national contexts have depicted a mixed situation regarding the status of menstrual literacy among reproductive-age women. Studies conducted in New Zealand found that the overall menstrual knowledge score among active females aged 16–40 was 51.8% of the available score; specifically, 80.5%,79.8%, and 20.4% about symptoms, menses, and health outcomes, suggesting an underperforming result compared to the socioeconomic status of the country. 17 Similarly, in Malaysia, 60% of young women (aged 18–25) had poor knowledge of dysmenorrhea, and 61.88% had poor practices related to menstrual health. 18 In addition, a systematic review and meta-analysis from Ethiopia found the pooled prevalence of poor menstrual hygiene practice was 48.98%. 19 Furthermore, studies across South Asia and East Africa reveal substantial gaps in menstrual literacy and hygiene practices: in southern Ethiopia, 68.3% of adolescent girls had poor knowledge and 60.3% practiced poor hygiene; in northeast Ethiopia, 64.9% reported good knowledge and 62.4% demonstrated good practices; while in India, over half of adolescent girls were unaware of menstruation before menarche and 71.5% did not know its cause.16,20–22 A similar pattern is observed in Bangladesh, where basic physiological knowledge is moderate (around 63%–67%), and significant gaps remain in understanding menstrual disorders and self-care practices. 23
Traditional approaches to assessing menstrual literacy have primarily relied on descriptive or inferential statistics. 24 While valuable, these methods may fall short in capturing complex, nonlinear interactions among the wide range of sociodemographic, behavioral, and cultural factors that influence menstrual knowledge and practices.25,26 The growing availability of digital survey data and the advancement of computational tools present new opportunities for more nuanced analysis and prediction.27,28 The recent advancements in the field of artificial intelligence (AI) have provided us with the scope of utilization of these technologies in various sectors, including the social and medical sectors.29–31 Evidence suggests that large language models possess significant knowledge regarding medicine and other humanistic approaches, which has increased their ability to be used as predictive and interventional tools. 32 Machine learning, particularly tree-based algorithms such as Random Forest, Gradient Boosting Machines, and Extreme Gradient Boosting (XGBoost), has shown promise in the field of public health for predicting outcomes based on multifactorial inputs.33,34 These models are not only capable of handling complex relationships but also provide interpretable outputs, such as feature importance, which can be instrumental for targeted interventions. Despite their potential, machine learning applications in the domain of menstrual health remain scarce, particularly in LMIC contexts.35–37
This study aims to fill this gap by leveraging tree-based machine learning algorithms to predict menstrual literacy among female university students in Bangladesh. By identifying the most influential factors associated with menstrual knowledge and practices, this study seeks to contribute both to the evidence base for menstrual health interventions and to the growing intersection of AI and women’s health. In addition, the application of predictive modeling allows for more personalized and efficient targeting of health education strategies in resource-limited settings.
Methods
Study design, setting, and population
A nationwide cross-sectional study was carried out between January and February 2024, targeting female university students across Bangladesh using a nationally representative sample. The study was conducted at four major public universities—University of Dhaka, University of Rajshahi, University of Chittagong, and University of Khulna—each located in a different administrative division. Eligible participants were female students enrolled in any Bangladeshi university who had experienced menarche at least 2 years before the study and reported either regular or irregular menstrual cycles. Students who had not yet experienced menarche and individuals unwilling to provide informed consent were excluded from the study. In addition, participants who reported serious medical conditions affecting menstruation (e.g., hysterectomy and hormonal disorders) were not considered eligible.
Sample size and technique
The required sample size was calculated using the following Cochran’s formula for sample size estimation in a cross-sectional study.9,38
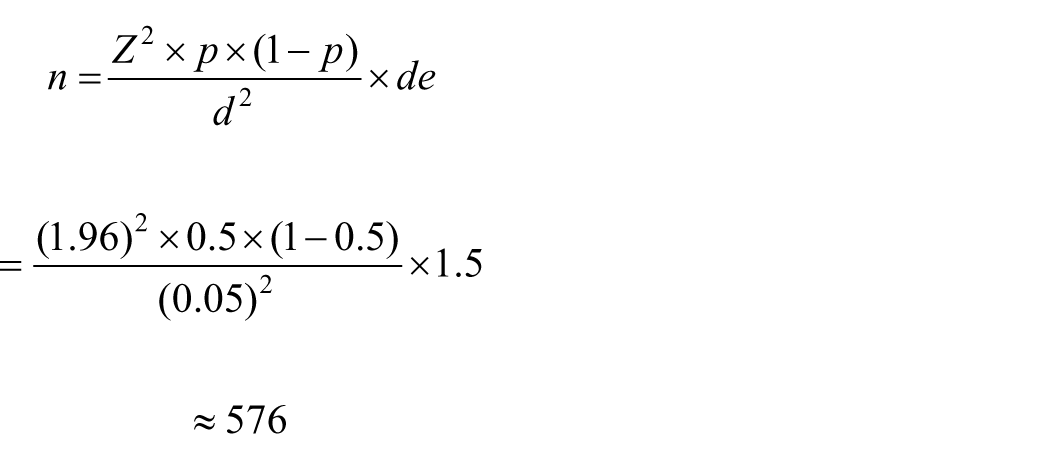
A conservative prevalence estimate of 0.50 was adopted in the sample size calculation to maximize variability, as is standard practice in this context. For multistage sampling designs, a margin of error of 5% and a design effect of 1.5 are typically applied. 39 Based on these parameters, the initial estimated sample size required for this study was 576 participants.
A multistage cluster random sampling technique was employed to select participants for this study. In this approach, the eight administrative divisions of Bangladesh were treated as primary clusters, and the universities within these divisions were considered secondary clusters. In the first stage, four divisions—Dhaka, Rajshahi, Chittagong, and Khulna—were randomly selected. In the second stage, one university from each selected division was chosen at random, resulting in the inclusion of the University of Dhaka, University of Rajshahi, University of Chittagong, and University of Khulna. In the final stage, an equal number of participants (n = 144) were randomly selected from each of the four universities using simple random sampling, ensuring balanced representation across the chosen institutions. Participants were approached sequentially, and recruitment continued until the target sample size (n = 576) was achieved. Individuals who declined participation or withdrew before completing the survey were replaced by newly approached participants from the same university. As a result, the final dataset comprised 576 complete responses, and the withdrawal/non-response rate was effectively accounted for during recruitment.
Survey instrument
Data from the participants were collected using a structured and interviewer-administered questionnaire for this study. The questionnaire was divided into three sections: “Demographics,” “Menstrual Characteristics,” and “Menstrual Knowledge.” The first two sections contained questions regarding the social, demographic, and menstrual characteristics of the study participants, which were adapted from previously published studies of similar interest and setting.4,19,20,40 In addition, participants’ knowledge about menstruation was evaluated using a pre-validated scale developed by Belayneh and Mekuriaw 16 that contained a total of 19 questions answerable in a Likert scale (Strongly disagree, Disagree, Agree, Strongly agree). To ensure semantic and conceptual equivalence, a standard forward–backward translation procedure was followed. Two bilingual experts initially translated the original questionnaire into Bengali. A separate bilingual translator, blinded to the original version, then back-translated the Bengali version into English. The research team compared the back-translated version with the original questionnaire and resolved any discrepancies through consensus. This rigorous process ensured the linguistic accuracy and cultural appropriateness of the Bengali version before its pilot testing. The scale was translated into Bengali, the native language of the participants. To ensure linguistic and cultural appropriateness, the translated version underwent a pilot test with 50 students at Jahangirnagar University. The Bengali version demonstrated good internal consistency, with a Cronbach’s alpha of 0.73, which is considered acceptable for establishing reliability and validity. Based on the statements, the score ranged from 0 to 3. So, the total possible score was 60, and individuals with a mean score of equal to or greater than 30 were categorized as having “Good” knowledge, and others were identified with “Poor” knowledge level.
Data collection
The interviewers conducted face-to-face interviews for the collection of data from the participants. The questionnaire was translated from English to Bengali before data collection. In addition, the interviews were conducted in the local language of the participants to avoid communication barriers and reduce information bias. Their responses were later translated into English for further analysis by the research team. The STROBE guideline was followed while reporting results. 41
Statistical analysis
All collected data were securely stored in an encrypted file with limited access. For analysis, we used Python (version 3.13.1) within the Jupyter Notebook interface manufactured by non-profit “Project Jupyter”. Several widely used Python libraries supported different steps of the analysis. The “pandas” and “numpy” libraries were used to organize, clean, and preprocess the dataset. The “scikit-learn” library was employed to divide the data into training and testing subsets, standardize variables, and apply machine learning algorithms for model training and evaluation. Model performance was assessed using standard metrics such as accuracy, F1-score, and receiver operating characteristic (ROC)-area under the curve (AUC), all calculated with “scikit-learn.” Finally, the “matplotlib” library was used to create visualizations, including plots and graphs, to present the results in an interpretable manner.
Models
Decision Tree
A Decision Tree is a supervised learning algorithm that partitions data into subsets based on feature values using a tree-like structure. It splits the dataset recursively according to the feature that provides the highest information gain or Gini impurity reduction, allowing for interpretable decision rules. 42
Random Forest
Random Forest is an ensemble learning method that constructs multiple decision trees during training and outputs the mode (classification) or mean (regression) of their predictions. It enhances accuracy and reduces overfitting by introducing randomness through bootstrap sampling and feature selection at each split. 43
Extra Trees
Extra Trees is an ensemble learning algorithm similar to Random Forest, but it differs in its use of fully randomized thresholds for splitting nodes. By increasing variance through this additional randomness, it often improves generalization and computational efficiency. 44
XGBoost
XGBoost is a gradient boosting framework that builds additive models in a forward, stage-wise fashion. It optimizes model performance using a regularized objective function and advanced techniques such as tree pruning, parallel processing, and handling missing values effectively. 45
LightGBM
LightGBM is a gradient boosting framework designed for high efficiency and scalability. It uses histogram-based decision tree learning and a leaf-wise growth strategy, allowing it to handle large datasets with faster training speeds and lower memory usage compared to traditional boosting methods. 46
Ethics statement
This study was conducted in accordance with the principles outlined in the Declaration of Helsinki and received ethical approval from the Biosafety, Biosecurity, and Ethical Committee of Jahangirnagar University (Ref No: BBEC,JU/M 2023/12 (77)). The universities where samples were collected didn’t require any additional ethical clearance apart from this certificate. Therefore, we did not seek ethical clearance from each of the different universities visited in the study. Before participation, written informed consent was obtained from all participants. For those requiring assistance, the consent form was read aloud by trained data enumerators. Participation was entirely voluntary, and individuals retained the right to withdraw from the study at any time without penalty or loss of benefits. To maintain confidentiality, all participants were assigned unique identification codes, and no personally identifiable information was collected. The dataset was securely stored in encrypted, password-protected files accessible only to the research team. These procedures reflect a strong commitment to safeguarding participants’ privacy and adhering to the highest ethical standards in data management. Throughout the study, anonymity and confidentiality were rigorously maintained, and no identifying details were included in any resulting publications.
Results
Socio-demographics of the participants
Participants’ socio-demographics are described in Table 1. Among the 576 participants, the majority were aged between 18 and 22 years (62%) and identified as Muslim (88%). Most were undergraduate students (95%) and lived in university halls (57%). A larger proportion reported their permanent residence as urban (43%). Parental education levels were notably high, with 98% of fathers and 93% of mothers being educated. Most fathers were employed (82%), while the majority of mothers were housewives (75%). In addition, a significant portion of participants came from nuclear families (83%) and reported a monthly family income between BDT 30,000 and 70,000 (58%).
Sociodemographic characteristics of the study participants (N = 576).

Distribution of the participants’ menstrual characteristics
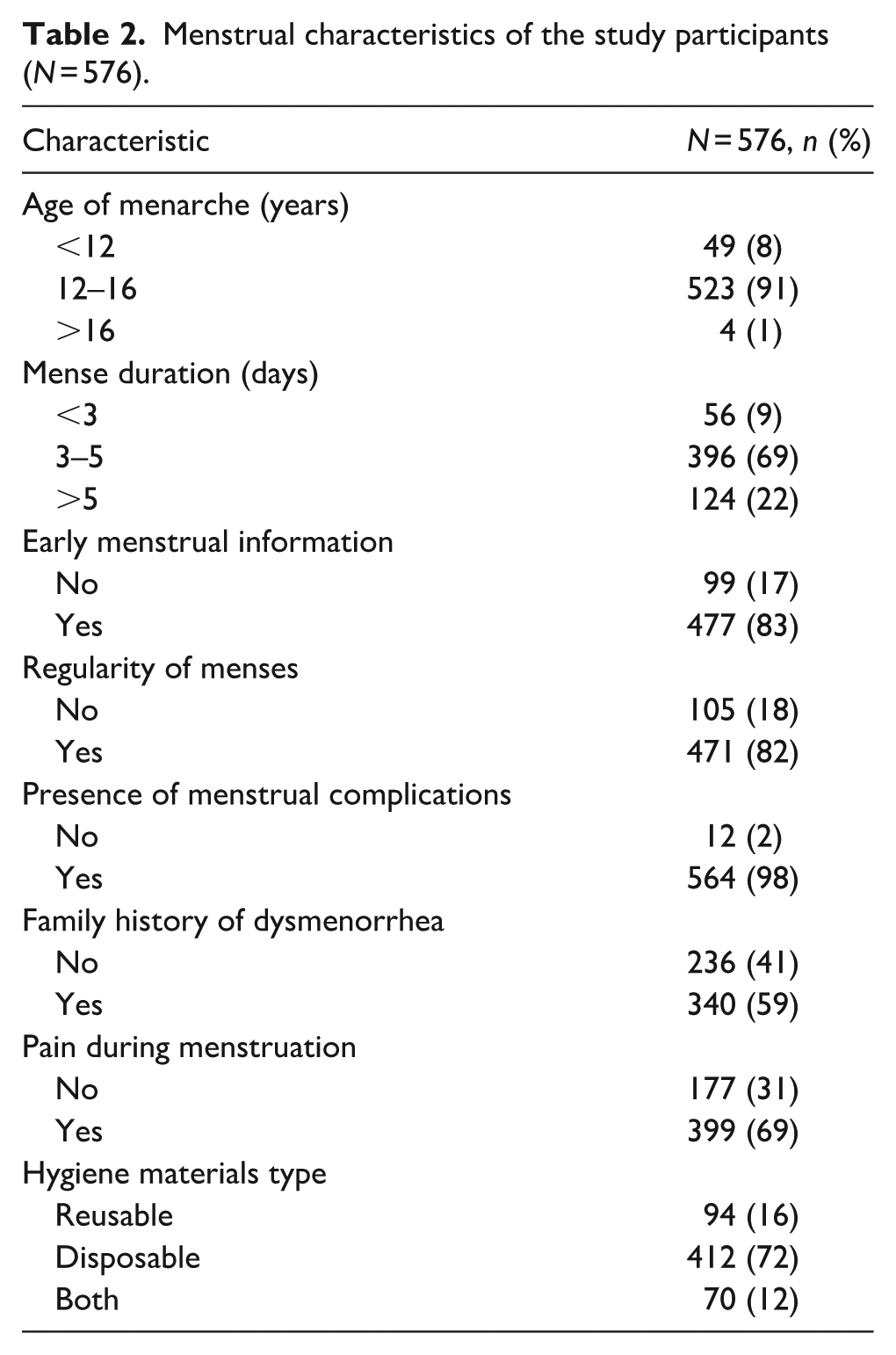
Table 2 reports the menstrual characteristics of our study participants. The majority experienced menarche between the ages of 12 and 16 years (91%) and had menstrual durations of 3–5 days (69%). Most had received early menstrual information (83%) and reported having regular menstrual cycles (82%). A striking majority (98%) experienced menstrual complications, and 59% had a family history of dysmenorrhea. Additionally, 69% reported experiencing pain during menstruation. In terms of hygiene practices, most participants used disposable menstrual materials (72%).
Menstrual characteristics of the study participants (N = 576).
Participants’ knowledge level regarding menstruation
In our study, 436 participants (76%) showed a good knowledge level regarding menstruation out of 576 participants. On the other hand, only 140 participants (24%) possessed poor menstrual knowledge. Figure 1 illustrates participants’ responses to various menstruation-related knowledge statements, grouped into agreement and disagreement. The visualization helps distinguish accurate knowledge from misconceptions based on whether participants endorsed or rejected each statement.

Participants’ responses to the questions on menstrual knowledge.
Overall, a considerable proportion of participants showed correct knowledge regarding menstruation. For example, over 90% of respondents agreed that “Menstruation is a normal phenomenon” and that “Menstruation is unique to females.” A similar pattern was observed for the statement “Menstruation will be stopped after the initiation of sexual intercourse,” where the majority correctly disagreed, and for “Curses are causes of menstruation,” which saw 90% disagreement, indicating rejection of superstitions. However, several responses revealed significant misconceptions. For instance, a majority agreed with the inaccurate statement “Vagina is the source of menstrual bleeding.” In contrast, the correct anatomical source—the uterus—was acknowledged by most through disagreement with the false statement “Uterus is the source of menstrual bleeding,” showing confusion in basic reproductive knowledge. Furthermore, nearly 70% agreed that “Menstrual discharge has a foul smell,” and over half endorsed the misconception that “Menstruation is pathological,” reflecting persistent stigmatizing beliefs.
Participants largely rejected cultural taboos related to menstruation. High disagreement rates were observed for statements such as “Not allowed to go to kitchens during menses” (78%), “Not allowed to touch others during menstruation” (71%), and “Activities done by a menstruating woman are not blessed” (78%). In addition, around 70% disagreed with the fatalistic view that “Being free from menses is a fate.” These findings indicate that while foundational knowledge about menstruation is relatively strong among participants, notable misconceptions persist, particularly concerning anatomy, hygiene, and stigma, highlighting the need for comprehensive menstrual education interventions.
Prediction of participants’ knowledge level using classification algorithms
Random Forest
The classification report of the trained Random Forest (RF) model is given in Table 3. Based on the accuracy parameter, the RF model is the highest performing model with an accuracy of 81% in predicting the knowledge level of the participants.
Classification report: Random Forest.

Figure 2 depicts the confusion matrix of the RF model, which displays the cross-tabulation results for categories of the target variable. The RF model predicted the poor knowledge accurately (TN) in 10 instances and falsely (FN) in 14 instances. On the other hand, 84 instances of good knowledge (TP) were accurately predicted by it, while in eight cases it predicted the good knowledge as poor (FP).

Confusion matrix—Random Forest.
The ROC curve for the RF model is presented in Figure 3, which plots the probability of being identified as TP against FP of the instances. The area under the curve (AUC = 0.80) confirms the reliability of the model’s prediction, as an informed prediction rather than random guesses (AUC > 0.50).

Receiver Operating Characteristic-AUC curve—Random Forest.
Decision Tree
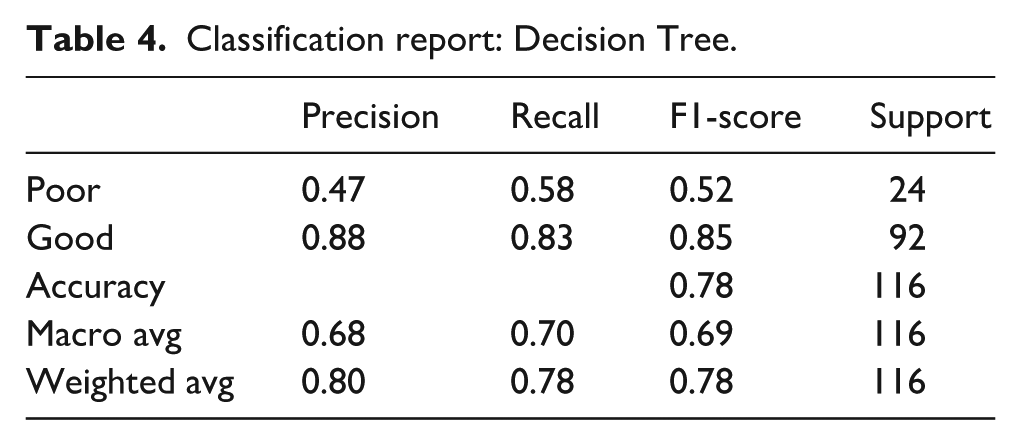
The classification report summarizes the Decision Tree (DT) model’s performance in predicting menstrual knowledge levels. The model achieved an overall accuracy of 78%, correctly classifying 78% of the 116 participants (Table 4). For the “Poor” knowledge group (label 0), the model showed a precision of 0.47, a recall of 0.58, and an F1-score of 0.52, indicating moderate performance in detecting students with poor knowledge. In contrast, for the “Good” knowledge group (label 1), the model performed considerably better, with a precision of 0.88, a recall of 0.83, and an F1-score of 0.85. The macro average F1-score was 0.69, which treats both classes equally, while the weighted average F1-score was 0.78, reflecting the performance while considering the class distribution.
Classification report: Decision Tree.
The confusion matrix for the DT model provides insights into the classification performance for menstrual knowledge levels (Figure 4). Among the 24 students with poor knowledge (label 0), the model correctly classified 14 (TN) and misclassified 10 as having good knowledge (FP). For the 92 students with good knowledge (label 1), the model correctly identified 76 (TP) and misclassified 16 as having poor knowledge (FN). This indicates that while the model performs reasonably well in detecting good knowledge, it is less accurate in identifying students with poor knowledge, which may be attributed to class imbalance or limited distinguishing features in the “poor” class.

Confusion matrix—Decision Tree.
The ROC curve was used to evaluate the classification performance of the model in distinguishing between students with good and poor menstrual knowledge (Figure 5). For the DT model, the AUC was found to be 0.72, indicating a moderate level of classification ability, meaning that the model can correctly differentiate between a randomly selected student with good knowledge and one with poor knowledge approximately 72% of the time. Although not highly accurate, this performance suggests that the model has a reasonable ability to classify students’ knowledge levels, with potential for improvement through further model tuning or feature enhancement.
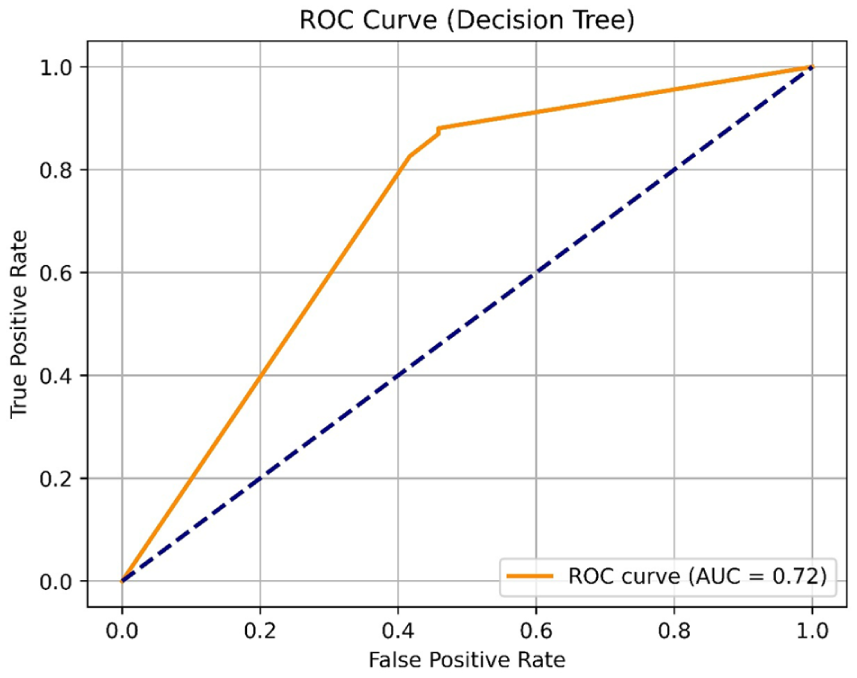
Receiver Operating Characteristic-AUC curve—Decision Tree.
Extra Trees
Table 5 presents the classification report of the Extra Trees (ET) models’ overall performance regarding menstrual knowledge level predic3.4tion. Model accuracy was 80% with a precision of 0.52 and 0.86 for the “Poor” and “Good” knowledge levels, respectively. The higher precision in the prediction of “Good” knowledge level indicates the model’s superior performance in predicting compared to “Poor” knowledge level. It performed slightly less compared to RF but better than the DT model.
Classification report: Extra Trees.

From the confusion matrix of ET, the classification performance of the model is visible (Figure 6). The ET model correctly identified 11 students (TN) having poor knowledge and falsely identified 13 students (FP) with good knowledge among the 24 students who had poor menstrual knowledge. In addition, among the 92 students with a good knowledge level, the model accurately predicted 82 of them (TP) and mistakenly classified 10 (FN) as with a poor knowledge level. This shows the model is more reliable in predicting university students who have a good level of knowledge than those with poor knowledge.

Confusion matrix—Extra Trees.
The ROC curve was utilized to assess how effectively the model distinguishes between students with good and poor menstrual knowledge (Figure 7). For the ET model, the AUC was 0.79, reflecting a moderate classification performance. This suggests that the model can accurately differentiate between a randomly chosen student with good knowledge and one with poor knowledge in about 79% of cases. However, this does not represent high accuracy; it indicates a fair level of predictive capability, with room for enhancement through further model optimization or feature refinement.

Receiver Operating Chracteristic-AUC Extra Trees.
LightGBM
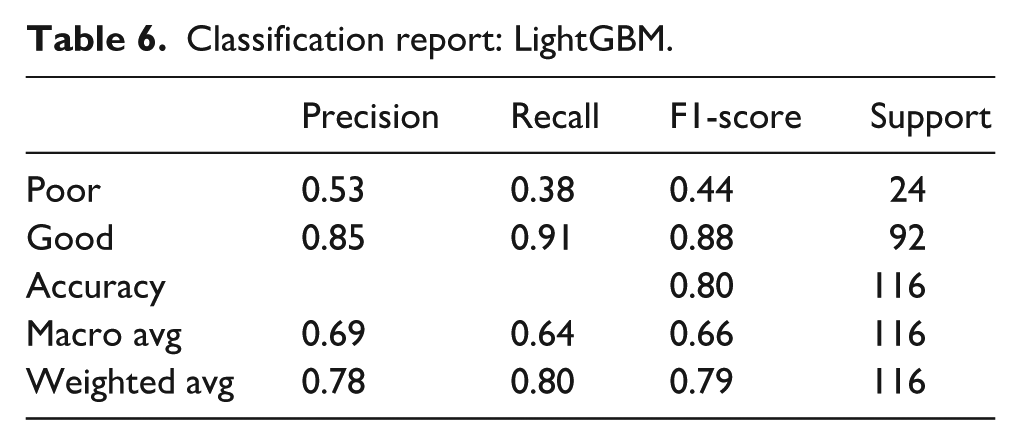
The classification performance of the LightGBM model in predicting menstrual knowledge levels is summarized in Table 6. The model achieved an overall accuracy of 80%, indicating a strong ability to correctly classify the knowledge levels of students. For the “Poor” knowledge group, the model recorded a precision of 0.53, a recall of 0.38, and an F1-score of 0.44. In contrast, the model performed significantly better for the “Good” knowledge group, achieving a precision of 0.85, a recall of 0.91, and an F1-score of 0.88, indicating robust predictive capability for this class. The macro average F1-score was 0.66, reflecting the overall performance across both classes equally, while the weighted average F1-score was 0.79, accounting for the class distribution. These results imply that although the model is highly effective at identifying students with good knowledge, its performance for the minority “Poor” class is comparatively weaker, similar to the other models in the study.
Classification report: LightGBM.
The confusion matrix of the LightGBM model illustrates the classification performance in predicting menstrual knowledge levels (Figure 8). Among the 24 students with poor knowledge, the model correctly identified 9 as having poor knowledge (TN) and incorrectly classified 15 as having good knowledge (FP). For the 92 students with good knowledge, the model accurately predicted 84 (TP) and misclassified 8 as having poor knowledge (FN).

Confusion matrix—LightGBM.
The ROC curve for the LightGBM model is presented in Figure 9, illustrating the trade-off between the true positive rate and false positive rate across various threshold settings. The AUC was 0.75, indicating that the model has a good level of discriminative ability. This value reflects the model’s capacity to make informed predictions rather than random guesses, as an AUC greater than 0.50 suggests meaningful classification performance.

Receiver Operating Characteristic-AUC curve LightGBM.
XGBoost
Table 7 outlines the performance metrics of the XGBoost model in classifying students’ menstrual knowledge levels. The model attained an accuracy of 80%, correctly predicting the knowledge category for the majority of students. For the group with poor knowledge, the model achieved a precision of 0.53, a recall of 0.42, and an F1-score of 0.47, reflecting limited sensitivity and moderate precision in identifying this category. On the other hand, the model demonstrated strong performance for the good knowledge group, with a precision of 0.86, a recall of 0.90, and an F1-score of 0.88, indicating consistent and reliable classification for this majority class. The macro average F1-score, which treats both classes equally regardless of size, was 0.67, while the weighted average F1-score, which accounts for class imbalance, was 0.79.
Classification report: XGBoost.

The confusion matrix of the XGBoost model provides a detailed illustration of its classification performance (Figure 10). Out of the 24 students identified as having poor menstrual knowledge, the model accurately classified 10 cases as TNs, while incorrectly labeling 14 students as having good knowledge (FP). Conversely, among the 92 students with good knowledge, the model correctly identified 83 instances as TPs and misclassified 9 students as having poor knowledge (FN). These results suggest that the XGBoost model demonstrates greater reliability in identifying students with good menstrual knowledge compared to those with poor knowledge, highlighting a disparity in performance across the two classes.

Confusion matrix—XGBoost.
Figure 11 presents the ROC curve for the XGBoost model, which depicts the relationship between the true positive rate and the false positive rate across a range of classification thresholds. The model achieved an AUC of 0.80, reflecting a satisfactory level of discriminatory power in distinguishing between students with good and poor menstrual knowledge. This AUC value signifies the model’s ability to generate informed and reliable predictions, as values significantly above 0.50 indicate performance that surpasses random chance and demonstrate meaningful classification capability.
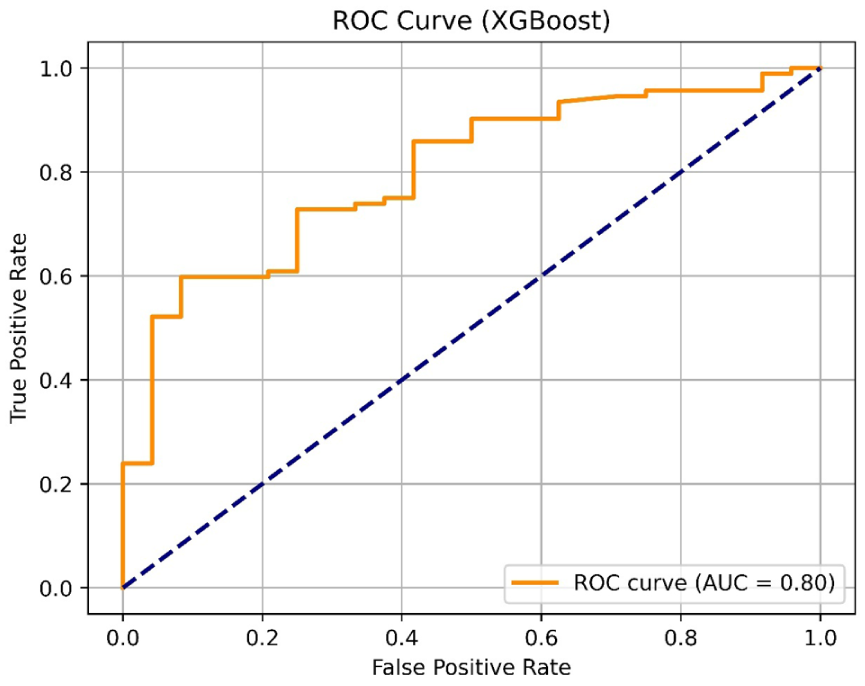
Receiver Operating Characteristic-AUC curve—XGBoost.
Feature importances of the classification models
Figure 12 presents the top 10 most important features identified by each of the five tree-based machine learning models—Random Forest, Decision Tree, Extra Trees, LightGBM, and XGBoost—in classifying menstrual knowledge levels among female university students. Several features consistently emerged as highly important across all models. Notably, Mense Duration, Hygiene Materials Type, Permanent Residence, Residency, and Monthly Family Income were among the most influential predictors in four out of five models. These variables reflect key sociodemographic and menstrual factors that influence menstrual knowledge. The LightGBM model emphasized Permanent Residence and Residency with the highest importance scores, while Random Forest and Decision Tree ranked Mense Duration as the top predictor. Interestingly, the XGBoost model highlighted more cognitive and structural factors, such as Educational Level, Early Menstrual Information, and Family Structure, pointing to a slightly different prioritization compared to other models. In addition, Mother’s Occupation, Pain During Menstruation, Age, and Regularity of Menses frequently appeared in the top 10 across multiple models, further underscoring the multifactorial nature of menstrual knowledge. Overall, the convergence of key features across diverse model architectures reinforces their relevance and reliability as predictors, suggesting areas where targeted educational and health interventions may be most effective.

Feature importance (top 10) for the models.
Discussion
University students comprise a significant portion of the total population in Bangladesh. In addition, due to the increased women’s participation and societal reforms, a substantial number of female students are now studying at different universities in Bangladesh. Information regarding their menstrual literacy can identify the current status of menstrual literacy, which can be used as baseline information, providing valuable insights and direction in developing policies and determining actions. To our knowledge, this is one of the first studies conducted in this context in Bangladesh. In addition, the probability of the incorporation of machine learning algorithms has added a different dimensional aspect in this regard.
Our study found that a significant majority of the students (76%) possessed a good level of knowledge regarding menstruation. This finding is similar to the studies conducted in Bangladesh by Ahmed et al. 14 and Huda et al., 47 where more than half of the participants (69% and 59.4%, respectively) demonstrated good menstrual knowledge level. However, this contrasts with the findings from other countries such as Ethiopia, Nigeria, and India. The prevalence of poor menstrual knowledge in Ethiopia and Southern Ethiopia was found to be 68.3% and 60.1% by Belayneh and Mekuriaw 16 and Tangchai et al., 48 respectively. Similar findings were reported in India and Nigeria, where most participants did not have good knowledge of menstruation.49,50
Recent studies conducted in South Asia and beyond continue to reveal wide variations in menstrual literacy levels, underscoring the contextual nature of knowledge and practices. For instance, Ganguly et al. in India found that more than half of adolescent girls demonstrated poor knowledge regarding menstruation and continued to adhere to restrictive practices, highlighting persistent cultural barriers despite policy-level interventions.24,51 Similarly, a nationwide study in Bangladesh by Ahmed et al. reported that only 69% of schoolgirls demonstrated adequate menstrual knowledge, 14 which is slightly lower than the 76% observed among university students in our study, possibly reflecting differences in age, educational exposure, and access to resources. In Malaysia, Mohamad Bakro et al. also reported poor knowledge of dysmenorrhea among 60% of young women, 18 further illustrating that gaps remain even in middle-income countries. These findings collectively suggest that while knowledge levels among Bangladeshi university students appear relatively encouraging, substantial room for improvement remains when viewed in the broader regional and global context.
In terms of predictive modeling, the Random Forest demonstrated the highest predictive accuracy (81%), closely followed by Extra Trees, LightGBM, and XGBoost (each at 80%), while the Decision Tree trailed slightly at 78%. This hierarchy of model performance is consistent with previous comparative studies in public health and behavioral prediction tasks. For instance, studies by Imani et al. and Anggraini et al. found that Random Forest consistently outperformed single decision trees and boosting algorithms in predicting health behaviors and disease risk due to its ensemble learning nature and resistance to overfitting.33,52 The superior performance of Random Forest and Extra Trees is likely due to their ensemble architecture and capability to manage feature interactions and nonlinear relationships, which are common in social and health data. Moreover, LightGBM and XGBoost, known for their efficiency in handling large datasets and offering robust gradient boosting frameworks, also exhibited high F1-scores for the majority of the “Good” knowledge class. These findings are corroborated by Weng et al., who highlighted the efficiency of boosting models in clinical prediction tasks involving imbalanced datasets. 53 Despite overall strong performance, all models demonstrated lower sensitivity in detecting the “Poor” menstrual knowledge group, as seen in the lower recall values (ranging from 0.38 to 0.58 for the minority class). This discrepancy is likely due to the class imbalance (76% versus 24%), a well-documented limitation in machine learning applications to health classification, as discussed by Haixiang et al. 54 While resampling techniques or cost-sensitive learning were not employed in this study, such strategies could be explored in future work to mitigate this imbalance and improve recall for underrepresented groups.
Consistently across models, Menstrual Duration, Type of Hygiene Materials, Permanent Residence, and Early Menstrual Information emerged as the most significant predictors. This aligns with existing public health literature. For example, studies by Belayneh et al. in Ethiopia and Alam and colleagues in Bangladesh emphasized the critical role of access to information and urban residency in promoting better menstrual literacy.16,55 Our results also emphasize structural and socioeconomic determinants of menstrual literacy, such as residence, family income, and maternal occupation, which align with recent research in Bangladesh and South Asia. Oyshi et al. reported significant associations between sociodemographic factors and menstrual hygiene practices in rural Bangladesh, while Talukdar et al. highlighted that indigenous adolescents face greater barriers during seasonal resource constraints.15,26 These parallels reinforce the idea that menstrual health is not only a matter of individual knowledge but also a reflection of broader social inequities. The strong role of early menstrual information in shaping knowledge further supports earlier findings by Alam and colleagues and recent cross-country reviews that call for structured menstrual education programs within schools and universities. 55 Interestingly, XGBoost placed greater importance on cognitive and structural variables such as Educational Level, Family Structure, and Early Menstrual Information, suggesting that boosting models may better capture subtler patterns in knowledge acquisition. This divergence illustrates how different models emphasize different feature types based on their internal learning mechanisms, a point discussed in model explainability studies by Lundberg and Lee. 56
From a methodological standpoint, the integration of machine learning in our study is consistent with recent global advancements. For example, Adhikary et al. developed a specialized large language model (MenstLLaMA) for menstrual health education in India, demonstrating the feasibility of AI-driven educational tools. 36 Similarly, Malde et al. applied machine learning to predict maternal health risks in LMICs with promising results. 37 Our findings complement these works by showing that tree-based algorithms can effectively predict menstrual knowledge, highlighting the potential of AI not only for risk stratification but also for educational and policy applications. This convergence of evidence signals an emerging frontier where predictive analytics and AI-powered interventions can substantially advance menstrual and reproductive health research.
Strengths and limitations
A key strength of this study lies in its integration of AI-driven predictive modeling with public health research, allowing for personalized, scalable, and data-driven interventions. The use of multiple machine learning algorithms also enabled robust comparison and validation of model performance. However, the study has several limitations. The primary challenge lies in class imbalance, which affects the models’ ability to accurately classify individuals with poor menstrual knowledge. Moreover, although models such as Random Forest offer interpretability through feature importance, more advanced interpretability tools (e.g., SHAP and LIME) were not applied, which could provide deeper insights into individual-level predictions. Furthermore, the data are cross-sectional and self-reported, introducing potential recall and social desirability biases.
Recommendations
Future research should focus on several areas. First, longitudinal studies are needed to capture how menstrual literacy evolves over time and to examine causal relationships between early education, sociodemographic factors, and knowledge outcomes. Second, future studies should employ larger, nationally representative samples that include both public and private universities to better capture the diversity of menstrual experiences in Bangladesh. Third, methodological improvements such as resampling strategies, cost-sensitive algorithms, or hybrid models should be tested to address class imbalance and improve predictions for underrepresented groups with poor knowledge. Fourth, comparative studies across South Asian and LMIC contexts could provide valuable insights into how cultural and structural determinants shape menstrual literacy. Finally, as emerging AI-based interventions such as MenstLLaMA 36 gain traction, experimental trials integrating predictive modeling with digital menstrual education tools should be undertaken to evaluate their effectiveness and scalability in real-world public health programs.
Conclusion
This study confirms the utility of tree-based machine learning algorithms in predicting menstrual knowledge levels among university-aged women in Bangladesh. The high overall performance of models like Random Forest and XGBoost demonstrates the potential of AI tools to support health education initiatives. Key sociodemographic and behavioral factors—such as menstrual duration, hygiene material usage, early information access, and residency—play a central role in shaping menstrual literacy. Despite encouraging levels of overall knowledge, the persistence of specific misconceptions underscores the need for targeted educational interventions. Integrating menstrual health into formal education and public health campaigns, especially in resource-limited settings, could address these gaps effectively. Moreover, predictive models like those used in this study offer scalable solutions for identifying at-risk groups and tailoring interventions accordingly. The study contributes to the growing body of research at the intersection of AI and public health, demonstrating how data-driven approaches can enhance understanding and address critical gaps in menstrual health literacy.
Supplemental Material
sj-pdf-1-whe-10.1177_17455057251407850 – Supplemental material for Prediction of menstrual literacy among female university students using tree-based machine learning algorithms: A cross-sectional study in Bangladesh
Supplemental material, sj-pdf-1-whe-10.1177_17455057251407850 for Prediction of menstrual literacy among female university students using tree-based machine learning algorithms: A cross-sectional study in Bangladesh by Md. Mahadi Hassan, Noushin Nohor and Anika Bushra Boitchi in Women's Health
Footnotes
Acknowledgements
We would like to express our gratitude to Md. Shahidul Hassan and Marium Hassan for their unwavering support throughout the journey.
Ethical Considerations
This study received ethical approval from the Biosafety, Biosecurity, and Ethical Committee of Jahangirnagar University (Ref No: BBEC,JU/M 2023/12 (77)) before the data collection.
Consent to Participate
Informed consent and voluntary participation were ensured.
Consent for publication
All participants in this study provided written informed consent for the publication of their data in anonymized form. They were assured that no identifying personal information would be published. Participants were informed of their right to withdraw consent at any time, without affecting their involvement in the study.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The dataset and codes used and analyzed during the study are available from the author upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.