
Abstract
Background:
Stepped wedge designs are a specific type of cluster randomised trial design that requires all clusters to start and end the study at the same time. Batched stepped wedge designs are a variant that allows clusters to commence the study in batches instead of all at once. Since different batches of clusters may have different characteristics, it is possible that the treatment effect differs across batches. Here, we explore different approaches for accommodating this treatment effect heterogeneity when analysing data from a batched stepped wedge design where each participant provides a single outcome measurement: linear mixed models with a random coefficient for the intervention for each batch of clusters with estimation via restricted maximum likelihood; and meta-analysis approaches that pool the batch-specific treatment effect estimates using fixed- or random-effects meta-analysis approaches. In many batched stepped wedge designs, the number of batches will be low (e.g. 2); it is unclear what impact the small number of batches may have on bias and confidence interval coverage of these approaches.
Methods:
We simulated continuous outcome data from a range of batched stepped wedge designs with two and five batches, different within-cluster correlation structures (exchangeable, block-exchangeable), with and without period effects shared across batches, and with and without treatment effect heterogeneity across batches. Using the ‘lme4’ and ‘meta’ packages in R 4.4.1, we analysed each simulated data set using both linear mixed effects models (with and without treatment effect heterogeneity) and a range of meta-analysis approaches. We assessed the relative performance of all methods to estimate the true treatment effect using rates of convergence, bias, confidence interval coverage, and empirical standard error.
Results:
Treatment effect estimates from all meta-analysis approaches were unbiased. When period effects were incorrectly specified, treatment effects from linear mixed effects models were biased; when correctly specified, treatment effect estimates from these models were unbiased. Confidence interval coverage was similar for all random-effects meta-analysis approaches and close to the nominal level. For fixed-effect meta-analysis and linear mixed models, coverage depended on whether treatment effect heterogeneity was present.
Conclusion:
When batched stepped wedge trials include a small number of batches (two and five batches), linear mixed models provide unbiased estimates of treatment effects when correctly specified, but exhibit under-coverage of confidence intervals when treatment effect heterogeneity is present. Random-effects meta-analysis approaches provide unbiased estimates and nominal confidence interval coverage whether or not period or treatment effects vary across batches, but can yield excessively wide confidence intervals. When batched stepped wedge trials include small numbers of batches, we recommend the use of random-effects meta-analysis approaches for the analysis of continuous outcomes.
Keywords
Background
Cluster randomised trials randomise groups (clusters) of individuals (e.g. hospitals, schools, and villages) rather than individual participants. 1 Stepped wedge trials are particular variants of cluster randomised trials, where all clusters start implementing the control condition, and at pre-specified times clusters switch to the intervention condition, in a randomised order, until all clusters have crossed over to the intervention (see Figure 1). 2 Stepped wedge designs can reduce the number of clusters required to assess interventions compared with the standard cluster randomised design: the treatment effect estimator combines between-cluster and within-cluster comparisons. 3 However, stepped wedge designs require that all clusters start and end the study at the same time. Consequently, all clusters must be recruited with ethics approvals and data collection procedures in place before the trial can start.2,4,5
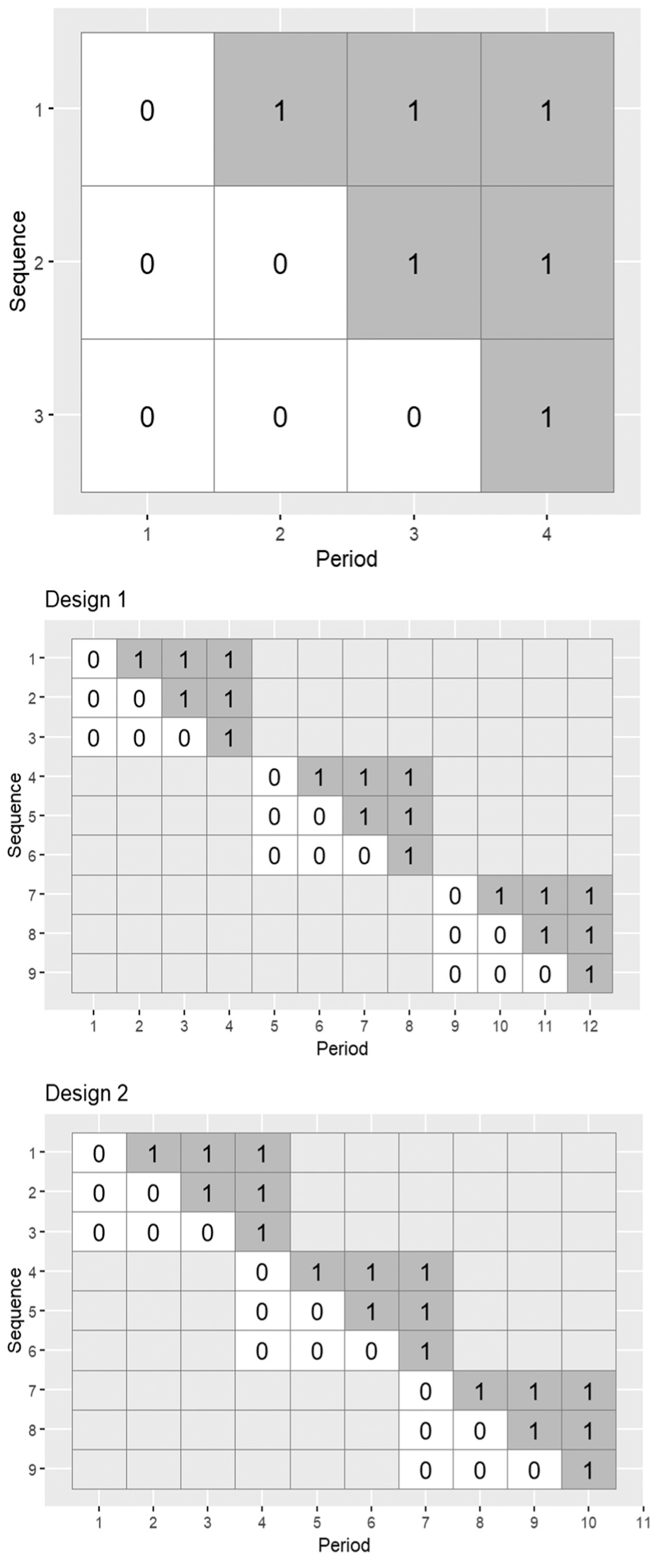
Top row: an example of a stepped wedge trial design with four periods and three sequences of treatment allocation (0 indicates control period; 1 indicates intervention period); multiple clusters can be randomised to each sequence. Middle and bottom rows: examples of batched stepped wedge trial designs with three batches, four periods, three sequences, and differing degrees of period overlap. Design 1 has no overlap between batches; Design 2 has one period of overlap between batches.
The batched stepped wedge design allows clusters to commence the study in batches, allowing for staggered cluster recruitment (examples in Figure 1). 5 If one batch starts before the previous batch has finished, it is said that there is ‘overlap between batches’ (e.g. there is one period of overlap between successive batches in the bottom row of Figure 1). Kasza et al 5 showed that when a linear mixed model (LMM) is assumed for the outcome, batched stepped wedge design power remains unaffected by delays in batch commencement, provided separate period effects are included for each batch in the outcome regression model. However, this assumes a constant treatment effect across all batches – which may not hold depending on the context. For example, if different batches correspond to different geographical locations, or if there are characteristics that may influence the ability of a cluster to fully implement the intervention, it may be expected that the treatment effect differs across batches. Treatment effect heterogeneity could be incorporated by including a random effect of treatment for each batch (other models are possible). 6 However, when the number of batches is small, it is unclear whether the restricted maximum likelihood estimator for the treatment effect will yield nominal levels of coverage, even if the number of clusters is large.
An alternative approach to analyse the results from a batched stepped wedge trial (targeting the same parameters) is to use meta-analysis, which combines the results of multiple studies into summary measures. 7 A two-stage meta-analytic approach for batched stepped wedge trial analysis would first analyse the data from each batch separately and then combine these results using standard meta-analytic techniques. An example of a batched stepped wedge study adopting this approach is the EAGLE trial, which assessed if a standardised quality improvement intervention could reduce anastomotic leak in patients undergoing right colectomy. 8 The EAGLE trial randomised 355 hospitals from 64 countries to the three sequences of an incomplete variant of a stepped wedge design in 16 batches. 8 To estimate the treatment effect, the EAGLE trial applied a meta-analytic approach: fitting models to the data from each batch, and then combining these estimates using random-effects meta-analysis.8,9
In situations where the assumption of a constant treatment effect across all batches may be questionable, meta-analysis may yield less biased estimates of the treatment effect (defined below) than standard LMMs; however, it is unclear in which circumstances meta-analysis may be beneficial. In this article, we conduct a simulation study to investigate when a meta-analysis approach may yield less biased and more efficient estimation of the treatment effect than the LMM approach when considering a continuous outcome from a batched stepped wedge design. We generated continuous outcomes from a range of batched stepped wedge designs assuming a range of within-cluster correlation structures and scenarios (when period effects do and do not differ across batches, and when the treatment effect does and does not randomly vary across batches). Data sets were analysed using LMMs and meta-analysis procedures. We also apply the various methods to analyse a specific trial.
Methods
Models
We assume that each participant provides a single continuous outcome measurement, represented by
We consider two within-cluster correlation structures: exchangeable and block-exchangeable. These two structures encode the within-period intracluster correlations (ICCs; the correlation between two observations in the same cluster in the same period) and cluster autocorrelations (CACs; the ratio of the correlation between two observations in the same cluster in adjacent periods to the ICC; these are equal to 1 for the exchangeable model) assumed in the model. Table 1 provides the ICCs and CACs for the models we consider.
Model 1: Exchangeable within-cluster correlation structure
Model 1 is given by 10
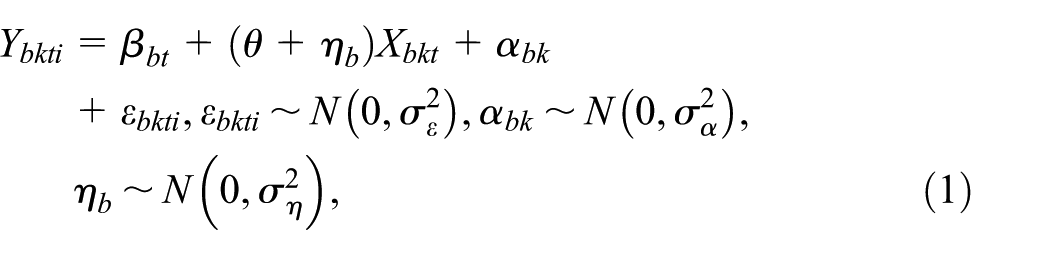
where
Intracluster correlations (ICC) and cluster autocorrelations (CAC) for Models 1 and 2. In the presence of treatment effect heterogeneity (

The cluster random effect,
We assume separate period effects for each batch. However, when generating and analysing data sets, if there is overlap between batches, we will also consider variants where period effects are shared across batches.
Model 2: Block-exchangeable within-cluster correlation structure
Model 2 is given by
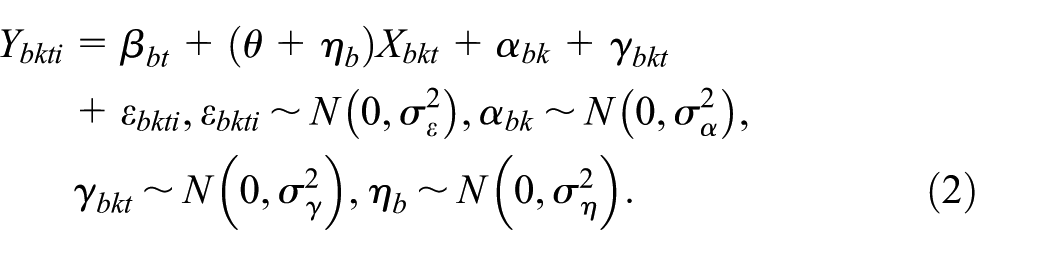
This extends Model 1, by including the cluster-period random effect,
Later, we also consider LMMs with a discrete-time decay within-cluster correlation structure (in the Disinvestment example section). Details about the discrete-time decay within-cluster correlation structure are provided in Section S4 of the Supplemental Material.
Meta-analysis approaches
Meta-analysis combines the results of the analysis of multiple studies into summary measures. There are two common meta-analysis models: fixed-effect and random-effects. 7 These should not be confused with fixed and random effects (i.e. mixed effects) models (e.g. Models 1 and 2) commonly used to analyse cluster randomised trials. In the context of batched stepped wedge designs, each batch constitutes a separate study, with treatment effects estimated separately for each batch and then combined. The target parameters in these approaches parallel those from LMMs in the previous section.
The fixed-effect meta-analysis model assumes there is one true treatment effect shared across batches,
The random-effects meta-analysis model instead assumes there is a distribution of true treatment effects across batches with mean
To analyse batched stepped wedge data using meta-analysis, the LMMs applied to each batch would be as in Models 1 and 2, with the exclusion of
Simulation study design
We aimed to compare the bias and statistical efficiency of LMM and meta-analysis approaches in estimating the treatment effect
Data generation
We set the total variance equal to 1. Setting
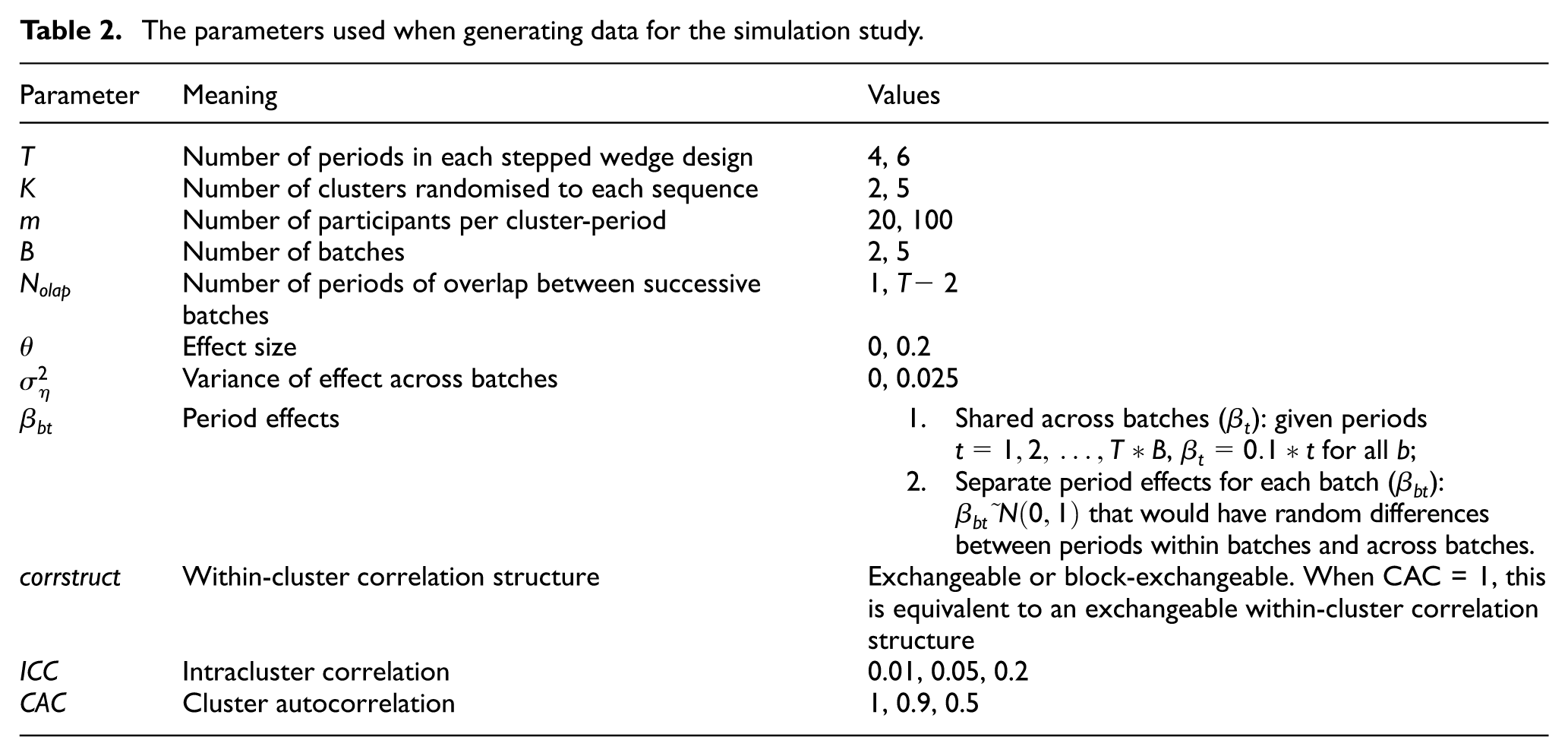
We conducted a factorial simulation study, and for every combination of parameters in Table 2 (2,304 combinations), we generated 500 data sets. With 500 data sets for each combination, the simulation study could be completed in a timely fashion, and the Monte Carlo standard error on an estimated coverage of 95% is <1%.
The parameters used when generating data for the simulation study.
Estimand and analysis methods
The estimand was the average treatment effect across the population of batches, represented by the parameter
Each simulated data set was analysed by fitting LMMs via restricted maximum likelihood estimation (REML) and using meta-analysis approaches. For each of these approaches, only models with the within-cluster correlation structure matching the data-generating model were fit.
For each simulated data set, four LMMs were fit:
1. Model A: Shared period effects; no treatment effect heterogeneity across batches (
2. Model B: Separate period effects; no treatment effect heterogeneity across batches (
3. Model C: Shared period effects; treatment effect heterogeneity across batches (
4. Model D: Separate period effects; treatment effect heterogeneity across batches (
When applying the meta-analysis methods, LMMs were fitted to data from each batch separately, and the results pooled using the fixed-effect or random-effects meta-analysis. To observe the behaviour of multiple specifications for random-effects meta-analysis, we applied every possible combination of methods available in the R ‘meta’ package:15–19
• Between study variance estimation: REML estimator; Sidik–Jonkman (SJ) estimator.
• 95% confidence interval (CI) construction: Wald-type CI; Hartung and Knapp and Sidik–Jonkman (HK) method; Kenward–Roger (KR) method.
• For the HK 95% CI method, we also considered variations of ad hoc adjustments available in the meta package, referred to in the package as: no ad hoc adjustment; HK ad hoc adjustment; IQWiG ad hoc adjustment. The details of the ad hoc approaches are provided in Section 1 of the Supplemental Material.
Analyses were conducted in R 4.4.1, 20 with LMMs fit using the ‘lme4’ package 21 and meta-analysis via the ‘meta’ package. 19 Results are displayed using nested loop plots constructed with the ‘looplot’ package. 22 For the Disinvestment example, the LMMs with discrete-time decay within-cluster correlation structure were fit using the ‘glmmTMB’ package. 23 Code to replicate our simulation study is available at https://github.com/DixonOrlando/BatchSW-MA.git.
Performance measures
To compare method performance, we calculated: bias of the estimate of the treatment effect, 95% CI coverage, empirical standard error, and rates of convergence. 24 Monte Carlo standard errors were calculated for each performance measure. 24 Non-convergence was identified by convergence warnings or errors printed by the lme4 command, with non-convergence indicated by warnings or errors indicating non-convergence. For the meta-analysis approaches, we defined non-convergence as occurring if none of the LMMs fitted for each batch converged. Some random-effects meta-analysis CI approaches have been found to yield very wide CIs.25–28 To give some indication of when CIs obtained for meta-analysis approaches were very wide, we also calculated the percentage of simulations for which the selected random-effects meta-analysis (described below) produced a CI wider than the extremes of the confidence intervals for the estimates obtained from each individual batch. Schulz et al. 28 stated such estimates should be considered ‘noninformative’.
Results
None of the considered performance measures depended on the effect size
Meta-analysis results
To maintain simplicity when reporting results, we present results for the fixed-effect meta-analysis and one random-effects meta-analysis approach in the main article, with results for all other random-effects meta-analysis approaches in Section S1 of the Supplemental Material. Across all random-effects meta-analysis approaches, bias and empirical standard error results were indistinguishable (bias: Supplemental Figures S1–S2 and S7–S8; empirical standard error: Supplemental Figures S5–S6 and S11–S12). Coverage depended on CI construction method, but for each CI construction method, both between-study variance estimation methods (REML and SJ) produced similar results (Supplemental Figures S3–S4 and S9–S10). Among all CI construction methods, HK with no ad hoc adjustment produced the best results across all performance metrics. Hence, this specification was chosen to represent the random-effects meta-analysis, with REML between-study variance estimation.
Non-convergence
Supplemental Figures S13–S14 display the rates of non-convergence for LMMs, indicating relatively high rates of non-convergence of the LMM approaches (up to 40%). Non-convergence rates were generally highest when more complex models were fit. While for some meta-analysis approaches one or more individual linear mixed models failed to converge, we only consider instances where none of the models fit to each batch converged as instances of non-convergence. This means that in some rare situations, where only an estimate from a single batch was available, no meta-analysis was undertaken. Using this definition, the meta-analysis approaches had no instances of non-convergence. Additional discussion of the rates of convergence is in Section S2 of the Supplemental material.
All results below are based on replicates with model convergence.
Bias
Figures 2 and Supplemental Figures S15 and S16 show bias for all models when the data-generating models assumed separate and shared period effects, respectively. Meta-analysis approaches were always unbiased, and the LMM approach produced unbiased estimates when period effects were correctly parameterised: in Figure 2, where data-generating models included separate period effects per batch, LMMs A and C incorrectly parameterised the period effects, and only these models showed biased results across most scenarios. Omitting true treatment effect heterogeneity did not impact bias.
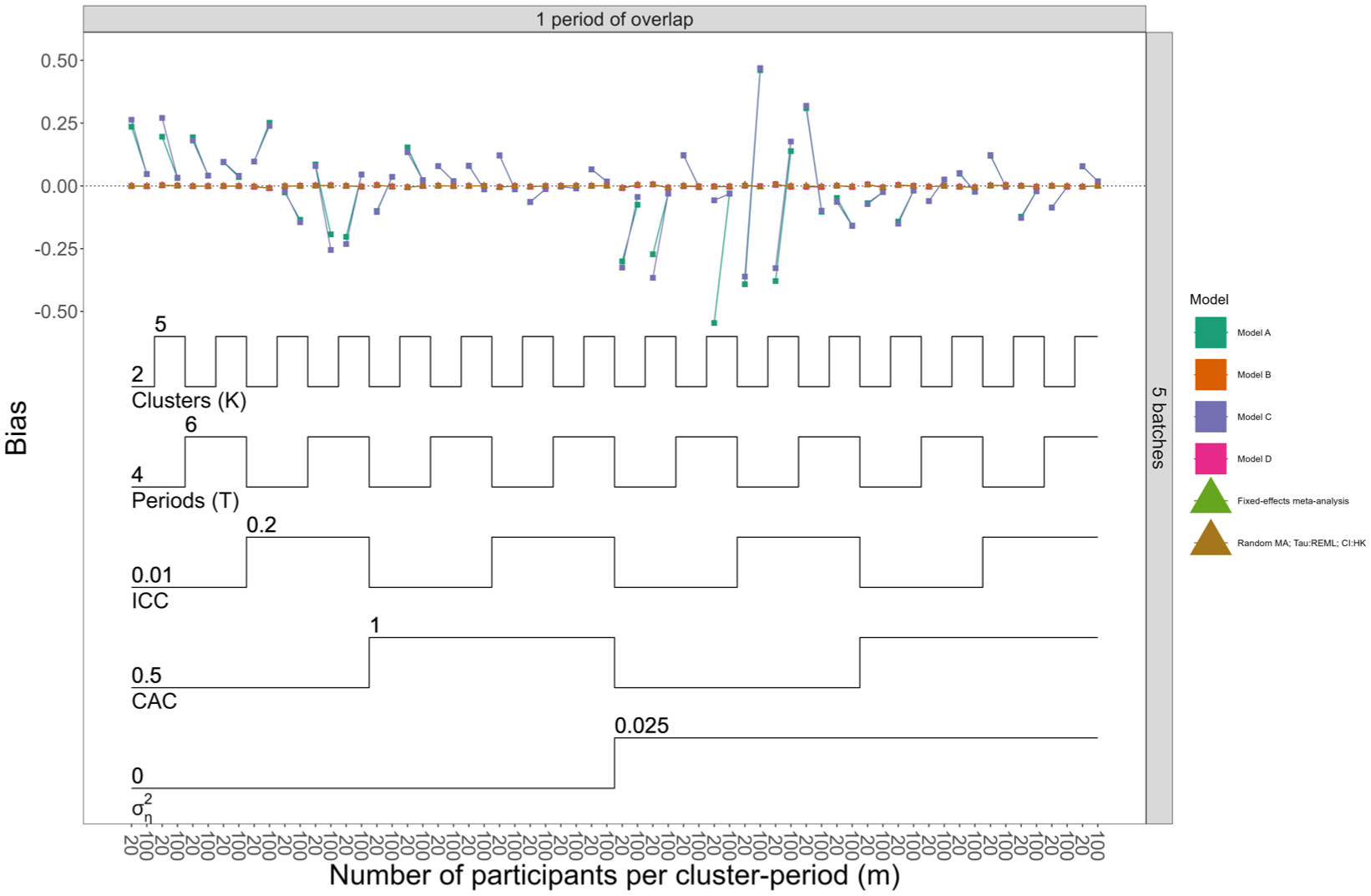
Nested loop plot displaying bias for Models A–D, the fixed-effect and random-effects meta-analysis approaches, when data were generated with separate period effects and null effect size. The simulation results are arranged based on the order of the loops. Loops in a nested loop plot represent the simulation parameters. The loops are ordered from the bottom to the top of the plot: the order of the loops starts from observations per cluster period, then treatment effect heterogeneity, CAC, ICC, periods (T), and finally clusters (K). Models A and B assume no treatment effect heterogeneity across batches; Models C and D allow for treatment effect heterogeneity across batches. Models A and C assume shared period effects across batches; Models B and D allow for separate period effects across batches. The overall pattern repeats across all possible combinations of the number of batches (horizontal grid) and number of overlaps (vertical grid); to simplify the results displayed in the figure, the scenarios are restricted to only one combination of number of batches and overlap. For more details about other scenarios, refer to Supplemental Figure S16.
Coverage
Figure 3 and Supplemental Figures S18 and S19 show coverage when data-generating models assumed separate and shared period effects, respectively. Figure 3 does not include coverage results for Models A and C (models with shared period effects), since these were shown to be biased for these scenarios. Overall, only the selected random-effects meta-analysis method achieved nominal coverage rates in almost all scenarios. When there was no treatment effect heterogeneity, all models had close to nominal coverage. When treatment effect heterogeneity was present, only Model D (and Model C when data were generated with shared period effects across batches) achieved coverage closest to 95%, although neither reached nominal levels. For Models D and C, coverage improved when the number of batches was higher (5 vs 2 batches), but nominal levels were still not attained. Not using small-sample corrections to account for a small number of clusters may have contributed to the under-coverage, but the number of batches had a much greater influence: increasing the number of clusters did not improve coverage, whereas increasing the number of batches did. This suggests that, for LMMs, correct specification of treatment effect heterogeneity is not enough to achieve nominal coverage; an adequate number of batches are also required, suggesting potential small-sample issues. Overparameterisation of period effects did not appear to impact the coverage of the LMMs.
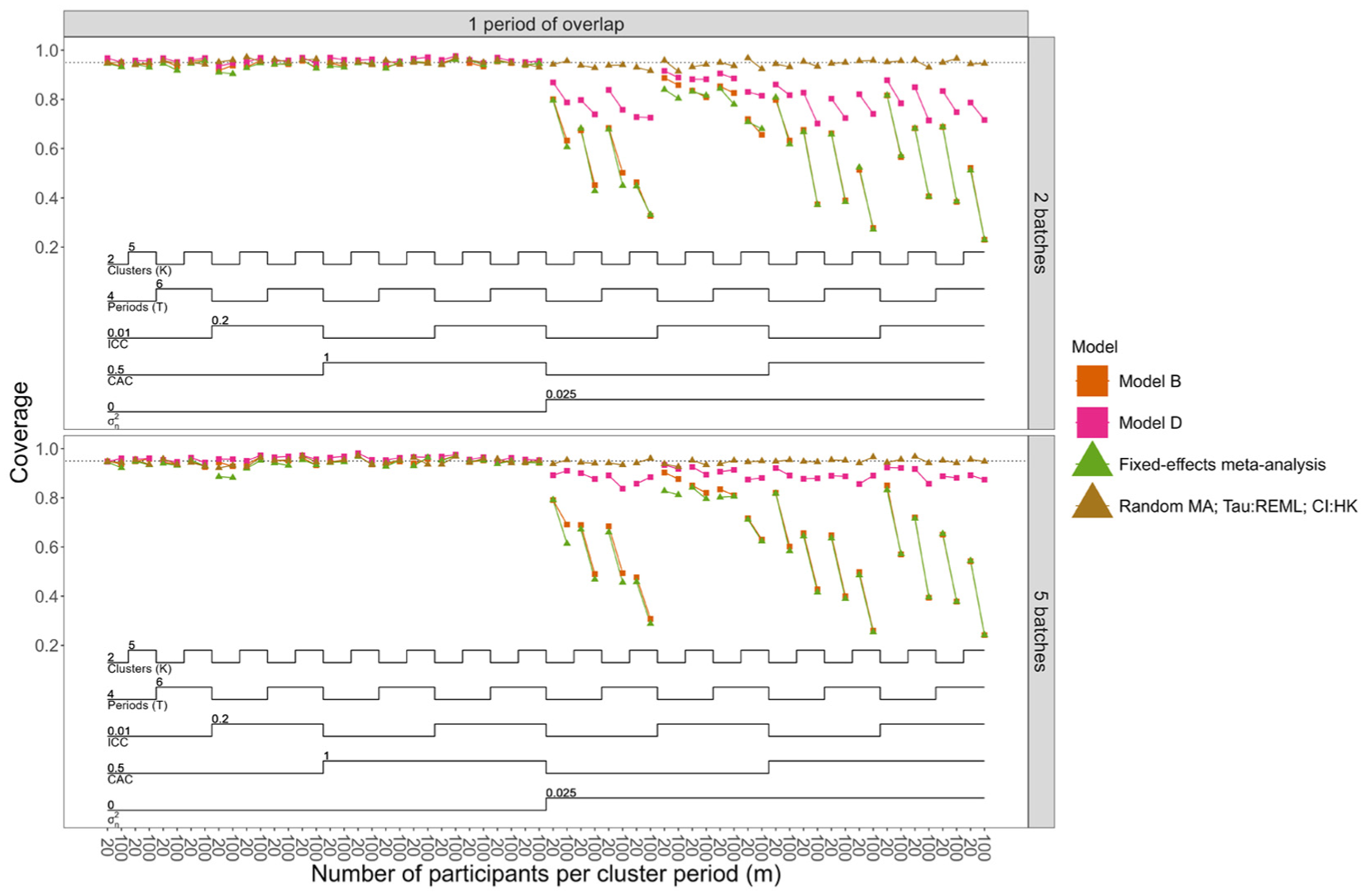
Nested loop plot displaying coverage of 95% confidence intervals for models with unbiased treatment effect estimates, when data were generated with separate period effects, null effect size, and number of overlapping periods equal to one. The simulation results are arranged based on the order of the loops. Loops in a nested loop plot represent the simulation parameters. The loops are ordered from the bottom to the top of the plot: the order of the loops starts from observations per cluster period, then treatment effect heterogeneity, CAC, ICC, periods (T), and finally clusters (K). Model B assumes no treatment effect heterogeneity across batches; Model D allows for treatment effect heterogeneity across batches. Models B and D allow for separate period effects across batches. The restriction for number of overlaps was performed because the results for coverage were similar across different numbers of overlaps. For complete results for all the scenarios, refer to Supplemental Figure S18.
The selected random-effects meta-analysis method tended to produce very wide confidence intervals when the number of batches was small (two batches), and this issue was exacerbated by the presence of treatment effect heterogeneity (Supplemental Figures S22–S25).
Empirical standard error
Empirical standard error results are in Supplemental Figures S20 and S21. Empirical standard errors reduce as the sample size increases and when treatment effect heterogeneity was not present. All methods were similar when data were generated with separate period effects across batches. When data were generated with shared period effects across batches, Models A and C (with shared period effects) had the lowest empirical standard error. The ICC affected empirical standard errors, but the effect depended on CAC: when CAC was low, higher ICCs increased empirical standard errors; as CAC rose, the ICC had less impact.
Disinvestment trial example
We consider data from a stepped wedge trial conducted in Dandenong and Footscray Hospitals in Australia. 29 This trial assessed whether ceasing routinely provided health services on weekends (i.e. ‘disinvestment’ from services) led to inferior outcomes for patients. Although not labelled a batched stepped wedge trial, each hospital can be considered a separate batch: randomisation of wards to sequences was stratified by hospital, with Footscray starting after Dandenong. Figure S26 displays the trial schematic with the number of participants in each ward in each period of the study (14,834 observations in total: Dandenong, 8,120 and Footscray, 6,714).
Here, we analyse patient length of stay using the LMMs and meta-analysis procedures with three within-cluster correlation structures. Supplemental Tables S2 and S3 provide the estimates of the ICCs and CACs obtained when applying Models B and D. Figure S27 displays the results of the application of each method, indicating the similarity of the estimated treatment effect across approaches, with much wider confidence intervals associated with random-effects meta-analysis. Table 3 presents Model D (separate period effects; treatment effect heterogeneity) results: estimates for each batch separately and their combination using random-effects meta-analysis with REML between-study variance estimation and confidence intervals constructed using HK with no ad hoc adjustment.
Individual hospital results before combining using the meta-analysis approach, results from Model D, and random-effects meta-analysis with ‘REML’ between-study variance estimation method and HK with no ad hoc adjustment CI construction.
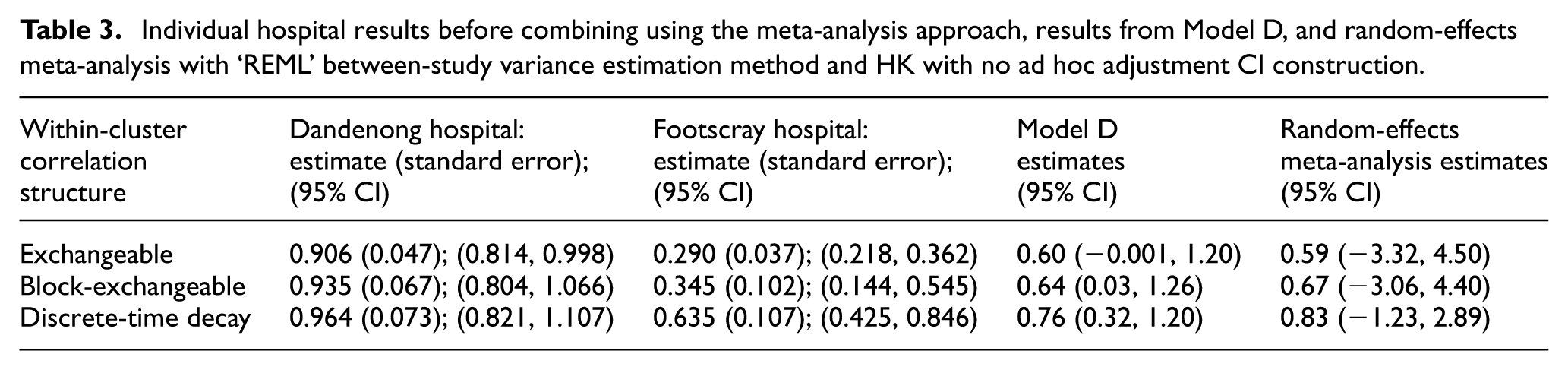
Model D results indicate that disinvestment from weekend services led to an increase in mean length of stay of around 0.7 days, and the data support a mean difference from around −0.001 to 1.26 days; however, only one correlation structure has a confidence interval including 0. The meta-analysis results have wider confidence intervals for the difference in length of stay than those for Model D. This exemplifies the simulation study results where the width of confidence intervals associated with fitting a standard LMM will likely be narrower in settings such as this, while the random-effects meta-analysis approach is likely to yield wider confidence intervals. Hence, the possibility of an important increase, decrease, or no important changes in mean length of stay after disinvestment from weekend services cannot be excluded.
Conclusion
The batched stepped wedge design was only recently described, and the most appropriate statistical analysis methods for this design are not yet well-understood. Previous recommendations for analysis of batched stepped wedge trials did not consider the possibility of differing treatment effects across batches.
We have provided an initial investigation into the application of meta-analysis techniques when treatment effects vary by batch. Through a simulation study, we compared the bias and confidence interval coverage of various meta-analysis approaches to those of the LMMs. We found that the random-effects meta-analysis with either ‘REML’ or ‘SJ’ between-study variance estimation methods and confidence intervals constructed using the Hartung–Knapp–SJ approach with no ad hoc adjustment performed best among all considered approaches. For all considered scenarios, this method produced unbiased estimates and nominal coverage rates. Other meta-analysis approaches did not perform as well. For the LMMs considered, bias and empirical standard error were similar to the meta-analysis approach when models were correctly specified, but coverage depended on correctly specifying treatment effect heterogeneity and the number of batches. ‘Correctly specified’ here includes allowing for differing period effects across batches: we, therefore, recommend always allowing period effects to vary across batches when analysing batched stepped wedge trials with LMMs. Furthermore, LMM approaches had high non-convergence rate, especially as the fitted model became more complex (more period effects and/or more complex within-cluster correlation structure).
Random-effects meta-analysis approaches are designed to combine results from (relatively) small numbers of studies with varied treatment effects. 7 Hence, we may expect random-effects meta-analysis approaches to perform well when there are ≥5 batches; however, as shown, CIs can be excessively wide when there are two batches (as has been pointed out). 27 Poor performance of LMMs is likely due to the small number of batches in our simulations (2 or 5). A small number of batches are not unusual: of the six trials that have cited the batched stepped wedge paper to date, all but EAGLE included≤4 batches.30–35 It is well-known that LMMs exhibit poor performance in the analysis of data from stepped wedge designs when the number of clusters is small, and small-sample corrections are recommended.36–40 Here, we have shown that issues associated with the use of LMMs with treatment effect heterogeneity across batches may also be subject to small-sample issues, where small sample here means a small number of batches. Additional simulations with 30 batches confirmed this finding, with coverage rates much closer to 95%. Given the higher rates of non-convergence for Models C and D (including treatment effect heterogeneity), and when a higher number of period effects were fitted, we recommend some caution in interpreting results associated with those models.
Our study has limitations. First, we did not consider data generated from the model with a discrete-time decay within-cluster correlation structure: primarily due to computational limitations. Given that our focus was on correct specification of the within-cluster correlation structure, we expect that the discrete-time decay model would yield similar results to the two correlation structure models examined in this study; we may observe higher rates of non-convergence. The trial designs we considered included scenarios with total clusters <50, and we did not apply any small-sample corrections when fitting LMMs – doing so may have improved coverage for scenarios with smaller number of clusters. 38 Nor did we consider the small number of batches issue: further research is required to understand adjustment of standard errors and CI widths. Our measure for identifying ‘excessively wide’ confidence intervals provided an indicator of this, but this measure is somewhat crude: wide confidence intervals may be necessary to capture variability across batches. Alternative models that include random intercepts for batches, in addition to random intervention coefficients, or models with separate fixed treatment effects for each batch, could be considered. Another limitation of this work is that we have not considered the implications of these approaches in designing batched stepped wedge trials: what are the implications for sample size and statistical power? Finally, we only considered continuous outcomes: binary or count outcomes are common in stepped wedge designs. 41 These are possible directions for future research.
Here, we have focused on treatment effects varying across the batches of batched stepped wedge designs, with an average treatment effect that does not vary with time or exposure duration. However, the important issue of time-varying treatment effects in stepped wedge designs has been the subject of much recent work. For example, Kenny et al. 42 highlighted the vulnerabilities of stepped wedge designs to the assumption of a constant treatment effect, with alternative models and treatment effects that accommodate time-varying effects presented by Maleyeff et al. 43 and Lee et al. 44 The impact of time-varying treatment effects on the analysis of batched stepped wedge designs requires further investigation.
We found that random-effects meta-analysis with either the ‘REML’ or ‘SJ’ estimation method for between-study variability, and HK confidence interval construction with no ad hoc adjustment performed the best among all approaches when analysing continuous outcomes from batched stepped wedge designs. Hence, we recommend using random-effects meta-analysis with these specifications; particularly when batch characteristics may be related to the outcome and treatment effects. Even in the absence of treatment effect heterogeneity, this approach performs well. However, caution is required when combining results of only two batches, as confidence intervals may be very wide. We have not considered correlation structure misspecification, but we would not expect meta-analysis to exacerbate the known issues of such misspecification, 45 and recommend pre-specification of sensitivity analyses under different assumptions. While LMMs with separate period effects for each batch and treatment effect heterogeneity across batches can perform similarly to random-effects meta-analysis, given the greater risk of non-convergence, we recommend pre-specifying back-up analysis methods when this model is to be fit.
Supplemental Material
sj-docx-1-ctj-10.1177_17407745261429957 – Supplemental material for Comparing meta-analysis and linear mixed model-based approaches for the analysis of continuous outcomes from batched stepped wedge trials
Supplemental material, sj-docx-1-ctj-10.1177_17407745261429957 for Comparing meta-analysis and linear mixed model-based approaches for the analysis of continuous outcomes from batched stepped wedge trials by Dixon Orlando, Rhys Bowden, Kelsey L Grantham, Joanne E McKenzie, Andrew B Forbes and Jessica Kasza in Clinical Trials
Footnotes
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: J.K. is an associate editor of Clinical Trials.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a National Health and Medical Research Council (NHMRC) Investigator Grant (GNT2033380) awarded to J.K. J.E.M. is supported by a National Health and Medical Research Council (NHMRC) Investigator Grant (GNT2009612).
ORCID iDs
Supplemental material
Supplemental material for this article is available online.