
Abstract
In precision oncology, integrating multiple cancer patient subgroups into a single master protocol allows for the simultaneous assessment of treatment effects in these subgroups and promotes the sharing of information between them, ultimately reducing sample sizes and costs and enhancing scientific validity. However, the safety and efficacy of these therapies may vary across different subgroups, resulting in heterogeneous outcomes. Therefore, identifying subgroup-specific optimal doses in early-phase clinical trials is crucial for the development of future trials. In this article, we review various innovative Bayesian information-borrowing strategies that aim to determine and optimize subgroup-specific doses. Specifically, we discuss Bayesian hierarchical modeling, Bayesian clustering, Bayesian model averaging or selection, pairwise borrowing, and other relevant approaches. By employing these Bayesian information-borrowing methods, investigators can gain a better understanding of the intricate relationships between dose, toxicity, and efficacy in each subgroup. This increased understanding significantly improves the chances of identifying an optimal dose tailored to each specific subgroup. Furthermore, we present several practical recommendations to guide the design of future early-phase oncology trials involving multiple subgroups when using the Bayesian information-borrowing methods.
Keywords
Introduction
In recent years, there has been a significant shift in anti-tumor therapies, moving away from traditional treatments like surgery, radiotherapy, and chemotherapy toward targeted therapy and immunotherapy. Unlike conventional approaches that focus on histological tumor types, these new therapies specifically target proteins or genetic mutations involved in cancer cell proliferation to impede their growth.1,2 Clinical studies and real-world evidence have demonstrated that these novel targeted therapies can effectively reduce treatment side effects, improve tumor responses, and prolong overall survival. Importantly, due to their unique mechanisms, these novel precision therapies have the potential to treat patients with similar genetic and immune phenotypic characteristics, regardless of their cancer types. Consequently, targeted therapy and immunotherapy offer treatment options for a broader range of cancer patients. 3
Traditional early-phase oncology trials have typically aimed to provide preliminary safety and efficacy evaluations of investigational treatments within a relatively heterogeneous patient population, often consisting of heavily pretreated individuals. 4 The primary objective of early-phase dose-finding or dose-optimization trials is to identify a suitable recommended phase II dose (RP2D), such as the maximum tolerated dose (MTD) or optimal biological dose (OBD). In recent years, many innovative early-phase trial designs have been developed, such as the continual reassessment method (CRM), 5 the method of escalation with overdose control (EWOC), 6 the Bayesian logistic regression method (BLRM), 7 the Bayesian optimal interval (BOIN) design, 8 the nonparametric overdose control design, 9 the BOIN phase I/II (BOIN12) design, 10 among others.
Conventional trial designs often rely on the pooled analysis strategy, which combines outcomes from all participants and assumes homogeneity by disregarding patient heterogeneity. As a result of this approach, a single “one-size-fits-all” dose is typically selected for different subgroups. However, such a uniform strategy is not practical nor optimal for precision oncology agents. For example, targeted therapy and immunotherapy are specifically designed to target particular proteins or genetic mutations in order to inhibit the growth of cancer cells. As a result, they can be used to treat a wide range of cancers. Due to the anti-tumor mechanism, the response or toxicity levels of targeted therapy or immunotherapy may vary among different populations defined by risk factors such as cancer subtype, disease stage, age, biomarker expression level, mutation type, and prognostic status. By combining all subgroups regardless of their similarity or heterogeneity, the pooled analysis leads to strong information sharing across subgroups and diminishes the distinct characteristics of each subgroup. As a result, when there is heterogeneity in toxicity or response between subgroups, it is possible that the single dose selected based on the pooled analysis strategy could be excessively toxic or ineffective for certain specific subgroups.
In order to account for potential heterogeneity between subgroups, a straightforward strategy, as opposed to the pooled analysis, is to investigate subgroup-specific optimal doses through parallel clinical studies for each subgroup of interest. However, conducting independent analyses for each subgroup prohibits information sharing between subgroups that likely exhibit homogeneous or similar dose-toxicity and dose-efficacy relationships. As a result, this independent analysis strategy necessitates a larger sample size to ensure a reliable dose selection for each patient subgroup. In turn, to maintain a relatively homogeneous patient population within each subgroup, stricter eligibility criteria are always necessary. Consequently, this independent approach can be associated with higher costs and longer trial durations due to slower and more expensive subject recruitment as well as increased retention expenses. 11 On the other hand, results collected based on a relatively smaller patient population from an individual trial may also weaken the evidence for the benefit of experimental treatments in real-world patient populations.12–15 Furthermore, when dealing with ordered subgroups, performing independent dose-optimization studies within these structured subgroups fails to consider the already-known order among multiple subgroups. Consequently, the optimal dose recommendations from these separate studies may inadvertently violate the established subgroup order. 16 For example, the MTD recommended for a more vulnerable population might end up being higher than the MTD estimated for a less vulnerable population.
Both independent analysis and pooled analysis are two simplistic approaches to address multiple subgroups, each with its own merits and significant deficiencies. To ensure operational convenience and unbiased inference, sponsors may opt to conduct parallel trials for each subgroup and independently determine the MTD or OBD based solely on the observed data within each subgroup. Conversely, the pooling strategy serves the purpose of collecting preliminary information on the experimental drug, facilitating faster patient accrual and trial duration when clinicians possess a strong prior belief in the similar toxicity or efficacy profiles among the subgroups. However, both independent and pooled analysis strategies have their own specific drawbacks and require significant efforts or strong assumptions to be truly effective. To strike a balance between the two extreme approaches, a more efficient and innovative strategy is to integrate multiple subgroups within one master trial and utilize adaptive information borrowing to leverage evidence collected across different subgroups. 17 Such a trial strategy is widely known as basket trials, which are typically used for phase II trials. Several well-known methods for phase II trials can be found in the literature, such as Thall et al., 18 Cunanan et al., 19 Neuenschwander et al., 20 Hobbs and Landin, 21 Chu and Yuan, 22 Jiang et al., 23 among others.
Recently, research efforts have been devoted to developing novel Bayesian statistical methods to concurrently evaluate multiple subgroups in early-phase studies, including phase I or phase I/II trials. Some of these methods can incorporate similar ideas developed in existing phase II basket trial designs. Due to the limited data observed in early-phase clinical trials, Bayesian approaches are often preferred because of their capacity to incorporate prior information and their flexibility in modeling multi-level data.24,25 In this article, we present a survey of representative innovative Bayesian methods that enable the adaptive borrowing of information across different subgroups in early-phase dose-finding or dose-optimization trials. To classify existing methods for information borrowing in early-phase trials with multiple subgroups, we employ the concept of “exchangeability.” which, in statistics, refers to a specific notion in which quantities treated as random variables in a probability specification are considered to be similar or interchangeable. 26 More precisely, exchangeability assumes that the joint probability distribution of the random variables of interest remains invariant regardless of the order or permutation of the sequences of variables. 27 As an illustration, when immunotherapy and targeted agents target a shared genetic characteristic across various cancer types, they hold the potential to effectively manage the tumor. In such scenarios, it is reasonable to consider the response rates of the defined subgroups based on cancer types as exchangeable given the uncertainty surrounding which specific cancer type might be more responsive to the investigational agent.
In the context of dose-finding or dose-optimization trials with multiple subgroups, exchangeability refers to the scenarios when the distributions of subgroup-specific parameters, such as subgroup-specific toxicity rates or response rates at different dose levels, are symmetric. This implies that the subgroup-specific parameters can be considered as random samples drawn from a common population. From a clinical perspective, exchangeability suggests that the subgroups are homogeneous, and any variation between subgroups arises primarily from the common distribution variance and sampling error. The exchangeability assumption facilitates the estimation of shared parameters that describe the underlying data distribution across all subgroups, enabling the exchange of information between subgroups to enhance the precision of parameter estimates.
We use the term “full exchangeability” to denote the concept of complete homogeneity among all the considered subgroups. Conversely, “partial exchangeability” is a more flexible and relaxed assumption that allows for homogeneity among certain subgroups while acknowledging heterogeneity within others. This assumption can accommodate the presence of potentially diverse subgroups, signifying that either a subset of the testing subgroups are exchangeable or that the considered subgroups are similar to some degree but not entirely homogeneous.
As depicted in Figure 1, Bayesian information-borrowing methods for early-phase oncology trials can be broadly categorized into two major classes based on their assumptions regarding exchangeability among the trial subgroups: those that assume full exchangeability and those that assume partial exchangeability. Under the assumption of full exchangeability, the Bayesian hierarchical modeling (BHM) approach provides a useful and simple tool to adaptively model the homogeneity or heterogeneity among the investigational subgroups. To address the limitations of the full exchangeability assumption, several adaptive methods have been developed to incorporate the concept of partial exchangeability. These adaptive methods allow for more flexible modeling and borrowing of information, accommodating the potential partial similarities or differences among subgroups. Figure 2 showcases the schematic illustration of the methods discussed in this article.
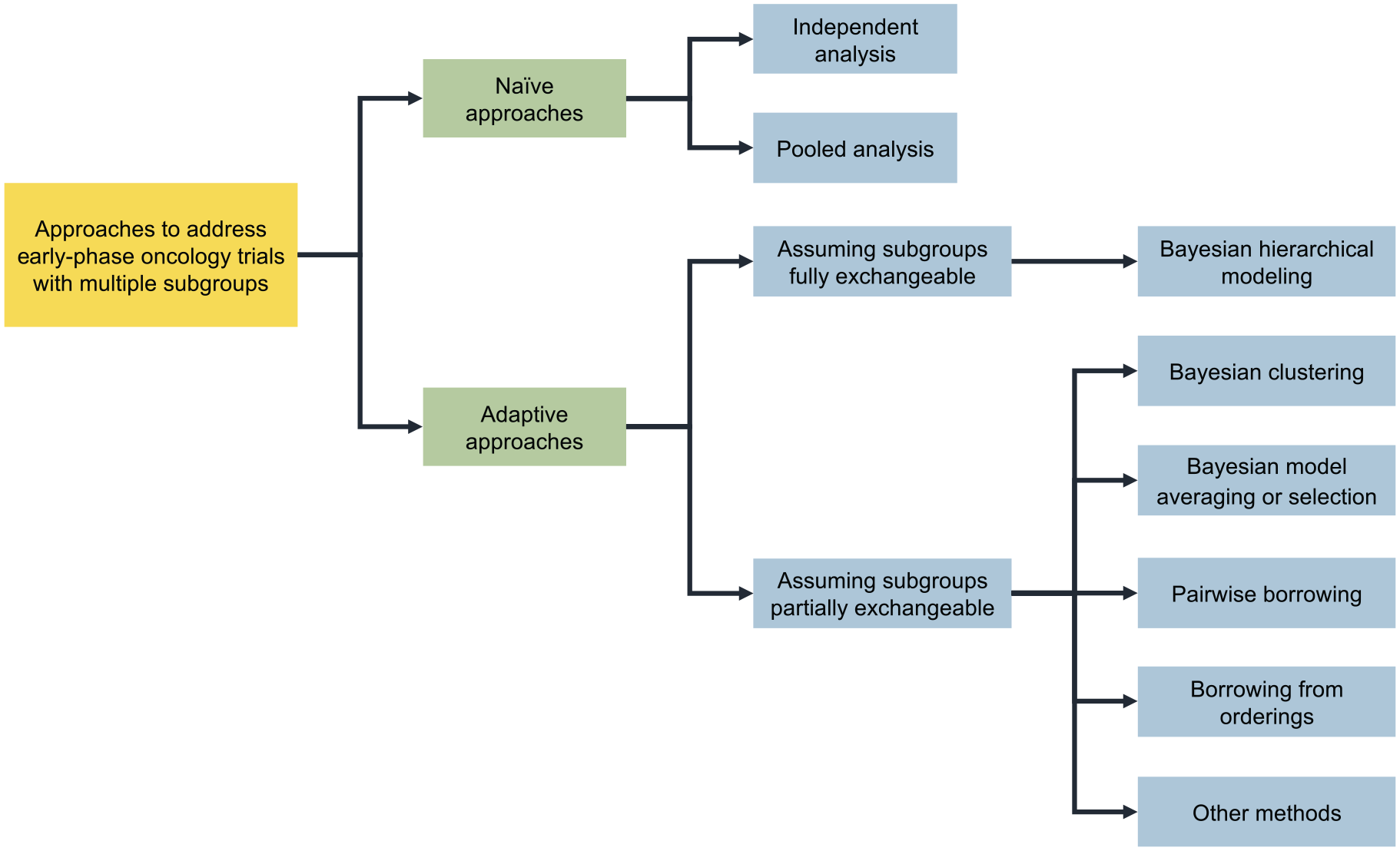
Classification of Bayesian information-borrowing methods for early-phase dose-finding and dose-optimization trials concurrently evaluating multiple subgroups.
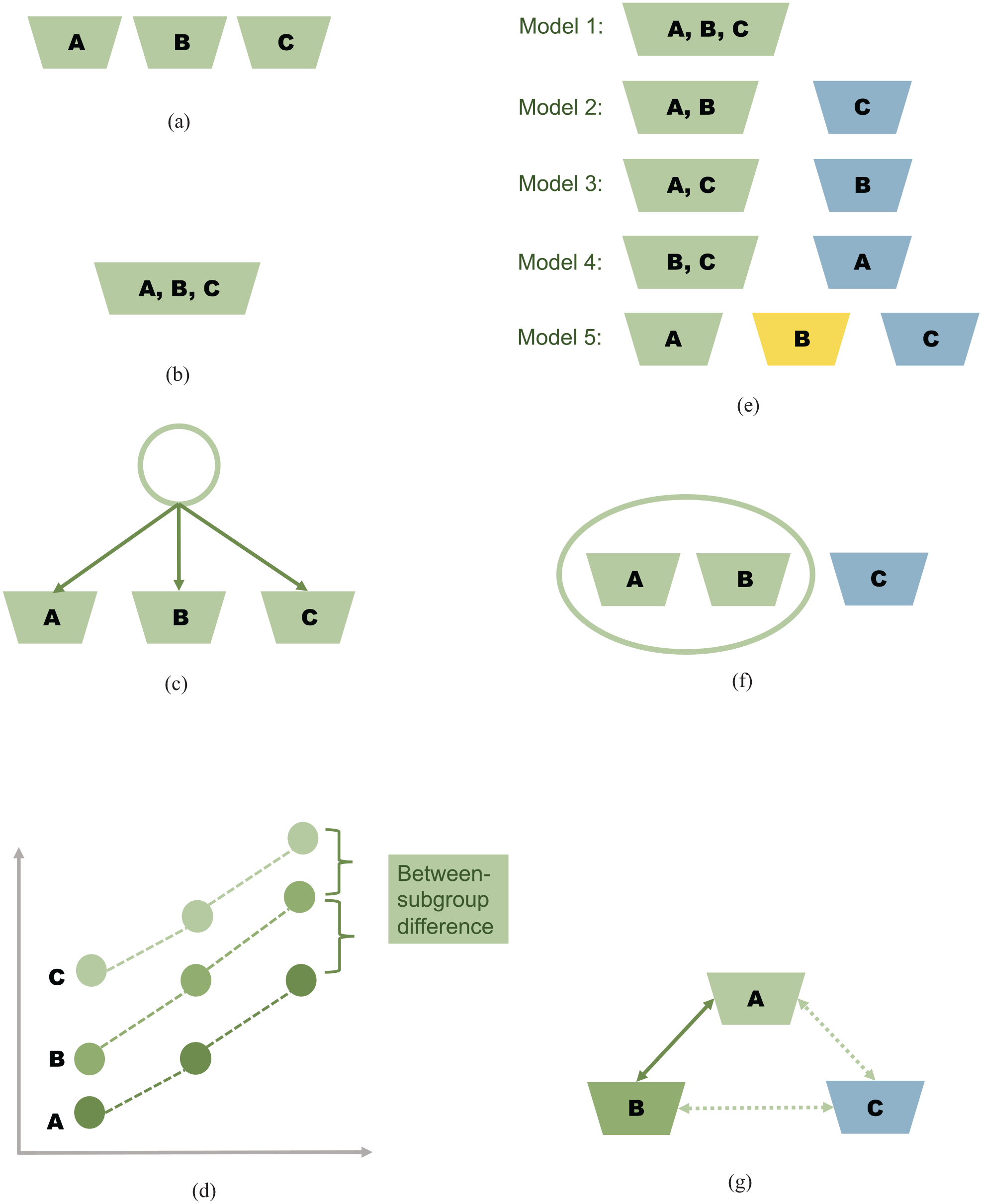
Illustration of the methods discussed in the article for addressing early-phase dose-finding and dose-optimization trials concurrently evaluating multiple subgroups. (a) Independent analysis, (b) pooled analysis, (c) Bayesian hierarchical modeling, (d) borrowing from orderings, (e) Bayesian model selection or averaging, (f) Bayesian clustering, and (g) Pairwise borrowing.
The remainder of the article is structured as follows. The section Bayesian methods assuming full exchangeability overviews the BHM approach, which addresses full exchangeability. The section Bayesian methods assuming partial exchangeability describes several methods that incorporate the notion of partial exchangeability. These methods encompass the Bayesian clustering approach, Bayesian model averaging (BMA) or Bayesian model selection (BMS), Bayesian pairwise borrowing, borrowing from orderings, and other approaches. Finally, the section Practical considerations concludes the review article by providing some practical considerations and remarks.
Bayesian methods assuming full exchangeability
Bayesian hierarchical modeling
Under the assumption of full exchangeability, the BHM approach is a flexible method for borrowing information across multiple subgroups.18,28,29 BHM constructs a multilevel model to draw posterior inference about the parameters of interest. In dose-finding or dose-optimization trials involving multiple dose levels, these parameters can refer to the toxicity (or response) rate at each dose level or the entire dose-toxicity (or dose-response) curve. Typically, a two-level hierarchical model is employed to integrate information across subgroups, as shown in Figure 2(c). At the lower observation level, patient outcomes are modeled separately for each subgroup with some unknown subgroup-specific parameters. At the upper population level, the subgroup-specific parameters are modeled using a common distributional assumption. Essentially, the subgroup-specific parameters are considered independent and identically distributed random samples drawn from a common population distribution, resulting in their shrinkage toward a common mean. In a more complex trial setting, such as involving multiple endpoints or multi-layered subgroups, the construction of a more comprehensive hierarchical model, encompassing multiple levels beyond the conventional two, becomes essential to accommodate the complexity of the situation.
For illustration of the typical two-level hierarchical model, consider a dose-finding trial that investigates
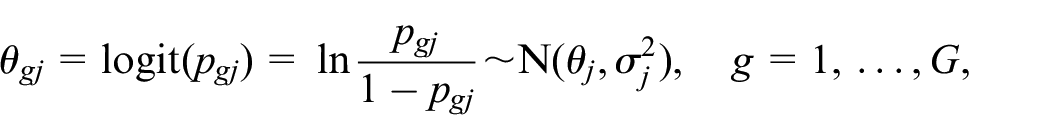
where
As a second example, we consider the integration of the entire dose-toxicity (or dose-response) curve across subgroups. In this case, a hierarchical parametric model based on a two-parameter logistic regression function can be constructed:
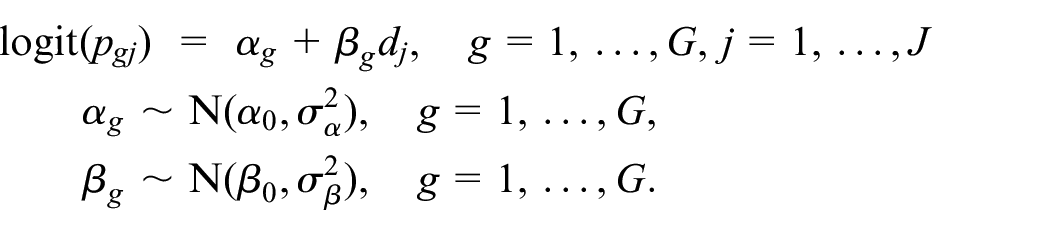
In this model,
The degree to which the subgroup-specific parameters shrink to the common mean is determined by the amount of inter-subgroup variance or the variance of this common distribution (i.e.
Technically speaking, BHM serves as a moderate approach for exchanging information across subgroups, offering a balanced alternative between independent analysis and pooled analysis strategies. The behavior of BHM depends on the inter-subgroup variance, which governs the extent of information sharing. When the inter-subgroup variance approaches zero, the BHM approach closely resembles the pooled analysis strategy, where information is combined across subgroups, leading to more homogeneous results. Conversely, as the inter-subgroup variance tends toward infinity, the BHM approach yields outcomes akin to the independent analysis strategy. The key characteristic of BHM lies in its adaptability. By leveraging observed data, BHM dynamically determines whether the inference should lean toward an independent analysis or a pooled analysis. This data-driven approach enables BHM to strike a balance, harnessing the benefits of both strategies based on the available evidence.
In BHM, prior distributions are specified for the common parameters, which are
In both these examples, the prior on the inter-subgroup variance (e.g.
The common parameters are then estimated by integrating the information contained in the prior distributions and the observed data. As a result, the BHM approach for dose finding and dose optimization involves a multilevel integration of information. First, there is integration between the prior distributions and the observed data, combining prior information with empirical evidence. Second, there is information integration across subgroups, where data from different subgroups are shared, allowing for borrowing strength and improving estimation. Third, there is information integration across different doses, enabling the sharing of information between dose levels. If multiple endpoints are considered, such as co-primary binary toxicity and efficacy outcomes, there can be additional integration of information between different endpoints, further enhancing the analysis.
Application of BHM in dose finding and optimization
Once a hierarchical model is estimated using a Bayesian approach, the posterior distributions of the parameters of interest become available. These posterior distributions provide valuable information for making dose-selection decisions at different stages of the trial. More specifically, during the middle course of the trial, the standard dose-selection criteria of the some commonly used dose-finding or dose-optimization designs such as CRM, EWOC, and BLRM can be applied based on the most up-to-date posterior distributions. For example, to determine the subgroup-specific MTD, the next patient of each subgroup can be assigned to the dose that yields the closest posterior mean estimate of the subgroup-specific toxicity rate to the target rate, as per the CRM criteria. Such a subgroup-specific dose-finding strategy has been investigated in the study by Morita et al. 31 They found that the BHM approach is effective when the dose-toxicity curves of patient subgroups are exchangeable, meaning they are similar or not significantly different. However, the BHM method may not be suitable when the subgroups are not exchangeable.
As a second example, Cunanan et al. and Cunanan and Koopmeiners used the BHM strategy to exchange information across subgroups in phase I dose-finding and phase I/II dose-optimization designs, respectively.19,32 In their investigation, both parametric and nonparametric multilevel hierarchical models were examined in detail. Subsequently, subgroup-specific decisions, such as identifying subgroup-specific admissible doses and estimating the subgroup-specific optimal doses, were made by utilizing the posterior distributions of toxicity or efficacy. The simulation studies show that the BHM approach has the capacity to allocate a greater number of patients to the optimal dose and enhance the probability of correctly identifying the appropriate dose when the dose-response profiles of the subgroups are fully exchangeable.
In another approach aimed at optimizing dose-schedule regimes in phase I/II trials, Lin et al. developed a three-level hierarchical model to characterize the relationship between the dose-schedule regime, disease subgroups, and the co-primary endpoints of toxicity and efficacy. 33 Based on the posterior distributions of the toxicity and efficacy rates, they were able to derive the posterior distribution of the mean utility, which serves as a measure to balance the tradeoff between toxicity and efficacy. The posterior utility distribution was then utilized to determine the regime allocation probability through an adaptive randomization scheme within each subgroup. Furthermore, it facilitated the identification of the optimal subgroup-specific dose-schedule regime that achieved the most favorable toxicity-efficiency tradeoff. Through simulation studies, Lin et al. discovered that the BHM approach is adept at identifying the presence of response homogeneity or heterogeneity among subgroups using the available data. Consequently, this enables the determination of an appropriate level of information sharing across subgroups. 33
Moreover, during the final analysis of a trial that involves multiple subgroups or in the integrative analysis of multiple subgroup-specific trials, the posterior distributions derived from the BHM approach can be employed to estimate the subgroup-specific probabilities associated with various dose-related outcomes, facilitating informed selection of the optimal dose specific to each subgroup under consideration. For instance, the Bayesian hierarchical random-effects models investigated in both the work of Ursino et al. 34 and Lin et al. 35 can be utilized to determine the MTD through combining multiple subgroup-specific phase I trials. In this scenario, where each trial corresponds to a unique subgroup, the inter-subgroup variability can be characterized by the between-trial heterogeneity parameter. The BHM approach can then adaptively estimate the heterogeneity parameter by leveraging the data from multiple trials.
Limitations of BHM
In the realm of the design and analysis of early-phase trials, the BHM approach stands out as a natural and straightforward method for addressing between-subgroup heterogeneity. As evidenced in the Application of BHM in dose finding and optimization section, the application of the BHM strategy has been extensively utilized and proven beneficial in numerous existing methods for early-phase trials. However, it is crucial to acknowledge several important considerations and potential limitations when implementing the BHM approach in early-phase trials.
First of all, in BHM, whether subgroups are homogeneous or heterogeneous in terms of the dose-response relationship is fully characterized by the inter-subgroup variance (or the heterogeneity parameter) of the common distribution. In statistical theory, reliable estimation of this variance parameter using a fully Bayesian way requires a large number of subgroups. However, the number of subgroups under investigation in real early-phase trials is often limited, leading to inadequate information available to reliably estimate this inter-subgroup variance. Therefore, caution must be exercised when eliciting the prior distribution for the inter-subgroup variance. If an informative prior is chosen, it implies a strong prior belief regarding the extent of heterogeneity among subgroups. However, the response homogeneity or heterogeneity of subgroups is usually unknown a priori in practice, making it necessary to specify a non-informative or weakly informative prior. For BHM, Gelman demonstrated that the conjugate inverse-gamma distribution might exhibit subpar performance and suggested the use of
Second, due to the sparsity of data observed in early-phase trials, the performance of BHM can be sensitive to the priors, particularly those related to the inter-subgroup variance. 36 To ensure a relatively robust performance of BHM, extensive simulation studies are often required to validate the specified priors, which may be computationally intensive. Several modifications have been proposed to enhance the robustness of BHM. Neuenschwander et al. 20 augmented the prior distributions of subgroup-specific parameters with an independent and non-informative component. Jin et al. 37 introduced a correlation structure in the prior distribution to facilitate adaptive information sharing among similar subgroups while avoiding excessive borrowing among heterogeneous subgroups. Since the inter-subgroup variance plays a crucial role in controlling the robustness of BHM, an alternative approach involves adopting a hybrid method to determine its value. For instance, Chu and Yuan proposed the calibrated BHM approach by treating the variance parameter as a function of the degree of similarity between subgroups, which can be quantified by the chi-square statistic in the context of dose finding and optimization. 22 Consequently, the inter-subgroup variance is not determined in a fully Bayesian manner but is instead computed deterministically based on the chi-square statistic. Other recent advancements aimed at enhancing the robustness of BHM when dealing with limited sample sizes and a small number of subgroups can be found in Cunanan et al., 38 Jiang et al., 39 Röver et al., 40 and Broglio et al. 41
Last but not the least, the BHM approach relies on the assumption of full exchangeability. This means that BHM can only handle scenarios where all subgroups share similar dose-response profiles at the same time, allowing for complete information sharing or no information sharing. This can be too restrictive for trials involving more than two subgroups: When some subgroups are similar while others are not, BHM cannot handle situations where both homogeneity and heterogeneity exist across subgroups. In these mixed scenarios, BHM may result in over-borrowing or under-borrowing of information, depending on the estimated level of heterogeneity. Over-borrowing can lead to biased estimates for subgroups that are dissimilar to the majority, potentially recommending overly toxic or futile doses for these subgroups. On the other hand, under-borrowing leads to inference from BHM resembling that of the independent analysis strategy, resulting efficiency loss. Therefore, when examining multiple subgroups, it becomes crucial to justify the feasibility of the full exchangeability assumption.
Bayesian methods assuming partial exchangeability
As the full exchangeability assumption underlying the BHM approach is often too stringent and difficult to verify in practical scenarios, alternative Bayesian methods have been devised to account for potential partial similarities or differences among subgroups. In the following section, we present several strategies based on the more flexible partial exchangeability assumption.
Bayesian clustering
Under the assumption of partial exchangeability, Bayesian clustering has emerged as a popular approach for partitioning the sample space.42,43 A typical example of applying Bayesian clustering methods in early-phase clinical trials is the implementation of the spike-and-slab prior.44–46 This approach enables adaptive collapsing or splitting of subgroup-specific dose-response curves.
To illustrate the application of the spike-and-slab prior, we refer to the work of Chapple and Thall for finding the MTD in phase I trials.
44
Define
We consider the logistic regression model as an example, where
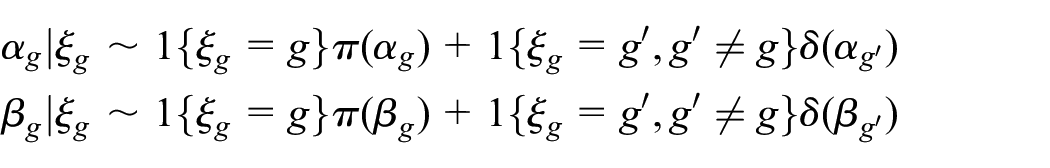
where
Within the Bayesian framework, the spike-and-slab prior approach allows for collapsing homogeneous subgroups and splitting heterogeneous subgroups at each posterior iteration. This leads to iterative changes in the model dimension. To address the issue of repeatedly changing model dimension, the reversible jump Markov chain Monte Carlo (MCMC) approach can be implemented to adaptively identify the latent cluster indicators based on the observed data.
The incorporation of the spike-and-slab prior and latent cluster membership enables effective identification of subgroup-specific optimal doses. By integrating this approach within the framework of CRM, Chapple and Thall discovered that the subgroup-specific CRM design outperforms both the independent analysis approach and the pooled analysis approach. 44 Furthermore, in the presence of partial exchangeability, the subgroup-specific CRM exhibits a higher probability of correctly selecting the optimal dose compared to the independent analysis approach. These findings align with the results observed in other early phase I/II designs, as explored by McGovern et al. 45 and Curtis et al. 46
An alternative example of Bayesian clustering method application in early-phase dose finding and optimization is the use of nonparametric Dirichlet processes, as demonstrated in the work of Li et al. 47 Apart from the aforementioned two approaches, there is a range of other available Bayesian clustering methodologies that have the potential to benefit early-phase dose finding and optimization.43,48,49 Nevertheless, it is worth noting that the application of these methodologies in early-phase trial designs has been relatively limited and should be approached with certain caveats in mind. One significant challenge is that Bayesian clustering methods often require a larger sample size to achieve sufficient flexibility. Unfortunately, early-phase clinical trials typically have small sample sizes. In addition, many Bayesian clustering methods involve sophisticated MCMC sampling techniques, which can significantly increase computational intensity.
Bayesian model selection or averaging
When the number of subgroups being studied is small or moderate (e.g.
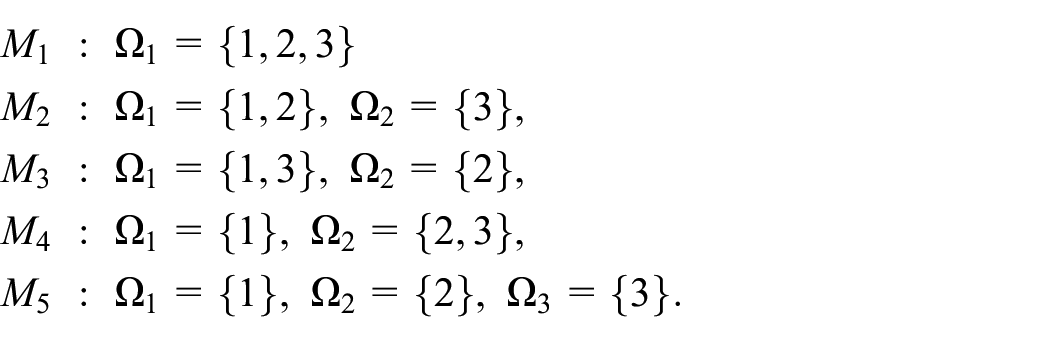
Here, each model
Under each model
In contrast, the BMA approach averages the estimates of all candidate models based on the posterior model probability. For instance, let
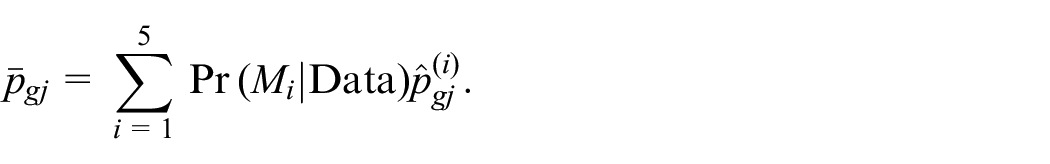
Compared to BMS, the BMA approach generally can reduce bias and enhance robustness in decision-making. 51
However, when the number of subgroups being examined is large, it becomes impractical or even infeasible to list all possible partitions for the entire subgroup space. For instance, when dealing with six subgroups
Pairwise borrowing
To circumvent the complexity of enumerating all possible subgroup partitions, an alternative and commonly used approach to address partial exchangeability is pairwise borrowing. In the pairwise borrowing approach, information from other subgroups is incorporated one-by-one for a specific subgroup of interest. The borrowing strength is then determined based on the pairwise homogeneity between the subgroups. To address phase II basket trials, several methods have been developed based on the concept of pairwise borrowing. Notable examples include the works of Fujikawa et al., 55 Zheng and Wason, 56 and Ouma et al. 57
Albeit being different in the specific details, the general idea of pairwise borrowing can be described as follows. Let
The strength borrowing from subgroup
Borrowing from orderings
The strategies discussed in the previous sections are designed to simultaneously evaluate multiple subgroups based solely on outcome data, without exploiting the information contained in subgroup characteristics. However, there are instances where the testing subgroups may have an inherent ordering, such as when the subgroups are defined by age, disease stage, metastatic status, or other risk factors. For example, it is often observed that younger patients tend to have a higher tolerance than older patients, while patients in later stages of the disease may exhibit a lower response rate. The genotype can directly influence the tolerability of drugs, as seen in the case of irinotecan treatment. For example, patients with the UGT1A1*28 genotype are known to have a higher risk of experiencing neutropenia after receiving irinotecan treatment. 60
By incorporating the information on orderings into the model-development process, it is possible to shrink the parameter support and enhance estimation efficiency. For instance, consider the scenario where subgroup
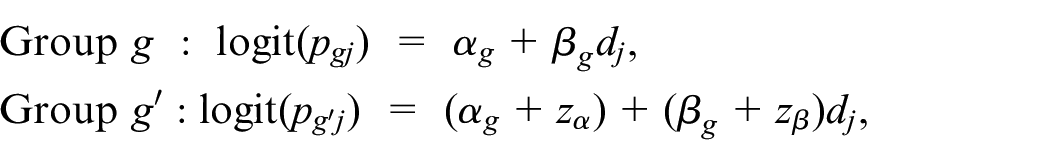
for
In general, methods that incorporate additional ordering information tend to be more efficient and robust than those that assume no orderings. However, it is important to note that specifying ordered subgroups requires expert input, and the validity of the assumed ordering should be biologically and clinically justified.
Other methods
Several other methodologies have been devised in the literature to optimize subgroup-specific dosing in early-phase clinical studies, especially in more complex trial settings. Lee et al. 69 explored a clinical trial focused on optimizing the dosage of natural killer cells for the treatment of severe hematologic malignancies. Unlike traditional early-phase clinical trials that typically rely on binary toxicity and efficacy endpoints, this particular trial aimed to incorporate different time-to-event endpoints. To address the ordered nature of patient subgroups based on disease severity, as well as the non-ordered nature based on disease type, Lee et al. 69 employed a comprehensive parametric hierarchical approach for the marginal hazard function for each event. In a different trial scenario where subgroups are predetermined based on prognostic risks, Lee et al. 70 utilized additional information derived from the ordinality of risk subgroups. They implemented a Bayesian clustering approach but with a reduced set of potential subgroup partitions. To address early-phase immunotherapy trials with three endpoints including the immune response, toxicity, and efficacy, Guo and Zang used the shift modeling strategies by adding the subgroup indicator as a covariate to the probability model for each endpoint.71,72 In another trial setting where the subgroups are predefined based on prognostic risks, Lee et al. 70 borrowed additional information from the risk subgroup ordinality and implemented the Bayesian clustering approach but based on a reduced number of possible subgroup partitions.
Practical considerations
In this article, we have presented a comprehensive overview of innovative Bayesian information-borrowing methods for optimizing subgroup-specific doses in early-phase dose-finding or dose-optimization trials. Although there are various Bayesian information-borrowing approaches and practical guidelines available for designing such trials,73,74 it is essential to address the following unique considerations associated with trials involving multiple subgroups. These considerations should be thoroughly discussed among biostatisticians, clinical investigators, and sponsors.
Predefining patient subgroups
First and foremost, it is crucial that the subgroups being investigated are well-defined prior to the trial and grounded in both clinical and biological rationale. Although it is feasible to identify patient subgroups based on the richness of the available data in late-phase trials, it is generally not advisable to perform such subgroup identification in early-phase trials. This is primarily due to the limited sample size typically associated with early-phase trials, which can result in low reliability and validity of the identified subgroups. In cases where certain subgroups cannot be distinctly defined, a practical approach is to first specify a large set of subgroups and then utilize Bayesian clustering or the BMS/BMA method to adaptively collapse subgroups with high levels of uncertainty based on the observed data.
The number of subgroups should also be strategically determined, as a small number may yield unstable estimation of the heterogeneity parameter in BHM, while a large number increases trial complexity and costs. It is also important to take the prevalence rate into consideration when defining subgroups. Subgroups with low prevalence may have a smaller impact on the model fitting, and their estimates may be diluted by the data from subgroups with higher prevalence rates. In addition, a small prevalence rate leads to a slower accrual rate, which, in turn, delays the timing for making interim subgroup-specific dose-selection decisions.
Finally, as mentioned earlier, it is crucial to ascertain whether the predefined patient subgroups exhibit any ordering. Incorporating the ordering information can enhance trial efficiency, thereby reducing the required sample size.
Enough sample size for each subgroup
Although early-phase trials typically have small sample sizes, it is crucial to make sure that each subgroup has a sufficient sample size to gather the necessary data for establishing specific dose-response relationships within each subgroup. This is because when the sample size is too small for certain subgroups, the amount of information borrowed from other subgroups becomes less data adaptive and relies heavily on the prior distribution of the inter-subgroup variance. If the prior distribution encourages information borrowing, then again, the estimate of the subgroups with a small sample size may be dominated by data from subgroups with larger sample sizes.
Consistent definition of decision-making endpoints
When employing Bayesian information-borrowing approaches in early-phase dose-finding and dose-optimization trials, it is crucial to ensure that the endpoints used in decision-making are consistently defined across subgroups. Even if the response rates between two subgroups are identical, it does not imply that information can be shared between them if they have different response assessment criteria. Furthermore, it is critical to have similar response assessment periods for all the considered subgroups. Otherwise, information borrowing between subgroups with significantly different response assessment periods should be discouraged.
Clinically and biologically justified model assumptions
To address the issue of data sparsity in early-phase clinical trials, a well-accepted strategy is to utilize parsimonious models to quantify dose-toxicity or dose-response relationships. These models are favored because they can enhance estimation efficiency and stability. However, it is important to note that parsimonious models also entail stronger assumptions. Since subgroup-specific dose-finding and dose-optimization trials involve multiple subgroups and dose levels, most existing designs rely on parametric model-based approaches. Some of these designs make strong assumptions about dose-toxicity relationships. For example, in a study by Lin et al., 33 it was assumed that the considered subgroups share the same dose-toxicity model, implying complete homogeneity with regards to toxicity. While the assumption of shared dose-toxicity models among subgroups is fully supported by the biological knowledge in this particular trial setting, it should be carefully assessed and considered when considering other trial settings.
In addition, other model assumptions may include whether to assume full exchangeability or partial exchangeability, and whether the concept of homogeneity pertains to the entire dose-response curves or solely to the response rates at specific doses across subgroups, among others. To ensure meaningful information borrowing and effective decision-making, it is crucial that all model assumptions underlying the trial designs are clinically and biologically justified. These assumptions should be thoroughly discussed with the clinical investigators.
After a full assessment of the aforementioned practical issues, the utilization of an adaptive Bayesian information-borrowing method that is both statistically and clinically sound in early-phase trials with multiple subgroups holds the potential to provide a more reliable estimate of the subgroup-specific optimal dose. Compared to conducting independent parallel trials among different subgroups, an early-phase trial with multiple subgroups and information borrowing across subgroups can offer greater efficiency and cost-effectiveness. However, it is essential to consider other operational factors when deciding whether to initiate such trials. Early-phase trials with multiple groups inherently introduce greater operational complexity and potentially require higher logistical costs. For instance, if the subgroups are defined by biomarkers, careful consideration must be given to factors such as the accuracy and cost of biomarker tests, as well as the feasibility and timing of collecting biospecimens. These operational factors play a crucial role in the success of early-phase dose-finding and dose-optimization trials.
Therefore, it is imperative to conduct a comprehensive and thorough evaluation of the statistical design, as well as the practical and operational issues, involving all stakeholders. Such an evaluation ensures that all aspects are carefully assessed, leading to a well-informed decision-making and guaranteeing the success of the trial.
Footnotes
Acknowledgements
The authors would like to thank the guest editors of the special issue, the associate editor, and the reviewers for their valuable comments and suggestions, which greatly contributed to enhancing the quality of the article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Dr. Lin is partially supported by grants from the National Cancer Institute (5P30CA016672, 5P50CA221703, and 1R01CA261978).