
Abstract
Terrain segmentation is of great significance to robot navigation, cognition, and map building. However, the existing vision-based methods are challenging to meet the high-accuracy and real-time performance. A terrain segmentation method with a novel lightweight pyramid scene parsing mobile network is proposed for terrain segmentation in robot navigation. It combines the feature extraction structure of MobileNet and the encoding path of pyramid scene parsing network. The depthwise separable convolution, the spatial pyramid pooling, and the feature fusion are employed to reduce the onboard computing time of pyramid scene parsing mobile network. A unique data set called Hangzhou Dianzi University Terrain Dataset is constructed for terrain segmentation, which contains more than 4000 images from 10 different scenes. The data set was collected from a robot’s perspective to make it more suitable for robotic applications. Experimental results show that the proposed method has high-accuracy and real-time performance on the onboard computer. Moreover, its real-time performance is better than most state-of-the-art methods for terrain segmentation.
Introduction
The identification of feasible regions is crucial for robot navigation and path planning. Sensors such as laser, vision, and sonar are often used to perceive feasible regions, based on which various maps are constructed. Most existing methods can only divide regions into areas whether robots can travel through or not. However, when robots move across different terrains, as shown in Figure 1, their speeds and energy consumption vary dramatically. In addition, weather can also have some impact. For example, rainfalls will cause puddles on the road and increase passing risks, as shown in Figure 1(a). Humans and most mammals are more strategic in identifying specific terrains, such as grass, sand, and pebbles. Although recent studies have begun to shed light on identifying some outlined feasible areas, such as highways, concrete, and asphalt roads, they are still far from satisfactory. Terrain segmentation and recognition are crucial for mobile robots to optimize navigation and path planning, especially for robots working in unstructured environments, such as agricultural robots, search, and rescue robots.

(a) to (f) Different feasible terrains for mobile robots.
We have been worked on the identification and segmentation of outdoor terrains since 2015. As shown in Figure 2, we attempt to make a more detailed division of the terrains and provide support for the multiterrain map building and multiterrain-based navigation for outdoor robots. In 2020, a low-risk terrain recognition strategy was proposed to classify the outdoor terrains in Zhang et al. 1 to make up for the deficiency of manual feature extraction and high misjudgment rate in risky terrains. In Wang et al., 2 a visual terrain classification method based on a convolutional neural network (CNN) and support vector machine was designed, focusing on terrain segmentation and its application to autonomous navigation of an outdoor robot.

In the navigation based on multiple terrains, a robot needs to automatically segment different terrains, including cement ground, grass, and puddles, to know its current surroundings quickly, plan appropriate paths, or make reasonable decisions. 3 –5 Yet, many challenges exist in terrain segmentation, as the outdoor environment is usually unstructured, uncertain, and sometimes interfered with by light, weather, pedestrians, vehicles, and other disturbances. 6,7 Therefore, it is crucial to improve the accuracy and real-time performance of terrain segmentation.
Vision sensors are often used to collect information of terrains. 8 Color space and geometric shape conversion methods are widely used in scenes with fewer changes and sharper contrasts. 9 –12 However, in complex outdoor environments, images collected by vision sensors often contain multiple types of terrains with similar characteristics. The segmentation of complex scenes usually requires pixel-level classification and has attracted the attention of many researchers. In Zhang et al., 13 the proposed approach extracted color features in multiple color spaces and combined texture features and geometric features to describe terrains. Then, feature selection and training based on the random forest algorithm are employed for terrain classification. In Liu et al., 14 the method combined the watershed algorithm and graph segmentation to solve the over-segmentation problem of images and obtained more precise boundaries of several terrains. By fusing the color histogram and local binary pattern features, the extreme learning machine was used to classify different regions. The feature extraction and screening process of most traditional terrain segmentation methods are cumbersome, with the representation of features limiting their performance, being unsuitable for the segmentation of complex geomorphic scenes.
Deep learning-based methods have developed rapidly in recent years and are widely used in semantic segmentation. In Long et al., 15 the proposed method applied 1 × 1 convolution kernel to replace the fully connected layer of CNN and then introduced the (fully convolutional network (FCN), by which realized the end-to-end semantic segmentation. Based on FCN, the SegNet was proposed in Badrinarayanan et al., 16 in which the pixel-level classification was made, and the characteristic is that the decoder performs a nonlinear upsampling of the input feature map according to the max-pooling index transmitted from the corresponding encoder. In Li et al., 17 the U-Net was applied to the terrain segmentation of aerial photography, and the cascaded dilated convolution module was used at the bottom layer to collect multiscale features. It could reduce the influence of interference and improve accuracy. In recent years, deep learning has been widely used in the field of robotics and autonomous driving. Researchers have proposed many novel methods for the detection and segmentation of driveable areas of vehicles and obstacles detection. In Frickenstein et al., 18 binary binarized driveable area detection network was proposed based on structured urban environments. It used binary weights and activations on encoders, bottlenecks, and decoders to reduce the amount of calculation and the storage space of the model. In addition, binary dilated convolution was used to strengthen the ability to extract features and improve segmentation accuracy.
Although vision-based deep learning methods can simplify the process of terrain segmentation, there are still some problems, for instance, Most previous segmentation networks have complex structures and lack particular optimization for outdoor robots. A high-precision segmentation network will involve a tremendous amount of calculation and slow down the speed of robots. How to balance the segmentation accuracy and speed is challenging. In terrain segmentation, only a few public data sets are available. A segmentation network with high accuracy relies on a data set with various terrains.
19
It is very tedious and challenging to construct a diverse and influential terrain data set for terrain segmentation.
In this article, a terrain segmentation method based on pyramid scene parsing mobile network (Psp-MobileNet) is presented for outdoor robots. The main contributions of this article can be summarized as follows: A terrain segmentation network, Psp-MobileNet, was designed and applied to terrain segmentation in unstructured environments. The network structure is optimized to reduce the onboard computing time of segmentation based on depthwise separable convolution, spatial pyramid pooling, feature fusion, and so on. Experimental results show that the proposed Psp-MobileNet provides a good balance between segmentation accuracy and real-time performance. A practical and annotated terrain segmentation data set was built in this study. To make samples consistent with the real scene of robot navigation, more than 4000 terrain images are collected by a mobile robot and then the unstructured terrain data set called Hangzhou Dianzi University Terrain Data set is generated after artificial screening and image annotation.
A terrain segmentation method based on Psp-MobileNet
Pyramid scene parsing network (PspNet), proposed in 2017, is good at mining global context information. It can generate a set of feature maps of different sizes through a pyramid pooling module. 20 It strengthens the network detection of the relationship between the global and the local area of the picture. ResNet is used to extract features for PspNet, which introduces a large number of parameters into the network. Therefore, for feature extraction, this study chose MobileNetV1, a lightweight neural network proposed by Google in 2017. 21 It replaces the standard convolutional layer in VGG (Visual Geometry Group) with depthwise separable convolution, significantly reducing the number of parameters.
The network structure of Psp-MobileNet
The proposed Psp-MobileNet inherits the structure of PspNet, including encoding and decoding paths, as shown in Figure 3. Some adjustments are made to the network structure to align with the terrain segmentation requirements of outdoor robots. The specific network parameters are presented in Table 1.
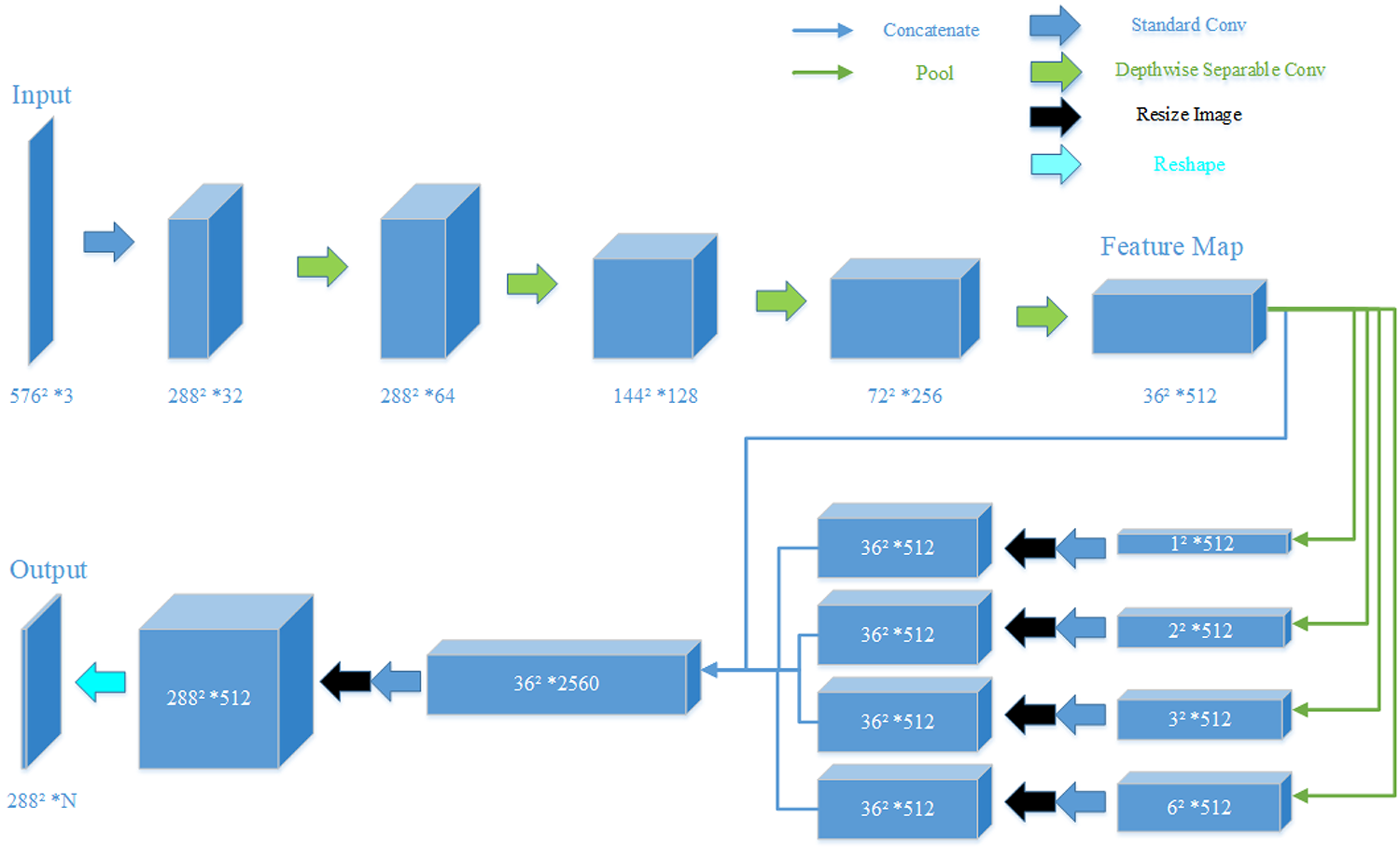
The overview of the proposed Psp-MobileNet. Psp-MobileNet: pyramid scene parsing-mobile network.
The outline of the proposed architecture.

c: the number of channels output by the convolution; n: the number of repetitions; s: the convolution strides; N: the number of categories classified.
Encoding path
Considering the computational cost and the limited capabilities of onboard computers of outdoor mobile robots, the lightweight network MobileNetV1 is chosen for feature extraction. Although MobileNetV2 is relatively newer, it performed poorly in our tests (detailed test results of Psp-MobileNetV2 are shown in the “Settings for training and testing” section). The depthwise separable convolution used by the MobileNetV1 divides the convolution process into two steps.
Depthwise convolution
Each convolution kernel of depthwise convolution is responsible for one input channel. That is, one of them is convolved with only one convolution kernel. Therefore, depthwise convolution is usually applied to two-dimensional structures, and the number of its outputs is the same as the inputs. As shown in Figure 4, where the size of inputs is


The process of depthwise convolution.
Pointwise convolution
The depthwise convolution cannot extract features between channels. Therefore, it is necessary to extract the depth information of the input layer and adjust the number of channels through pointwise convolution. The operation of pointwise convolution is the same as traditional convolution, except that its convolution kernel size is
As shown in Figure 5, when the feature map output by the depthwise convolution is


The process of pointwise convolution.
By the above convolutions, the total parameters of the depthwise separable convolution are

whereas the total parameters of traditional convolution with the same situation are 12k 2 as shown in the following equation

In the case of
Decoding path
The characteristic of the decoding path is pooling the generated feature map with four different sizes. It can improve the segmentation effect of targets of various sizes in samples and avoid losing context relationships. The
HDU-terrain data set
To make the network more adaptable to workspaces for outdoor mobile robots, we constructed the HDU-Terrain Dataset. As shown in Figure 6, a Scout MINI robot equipped with a monocular camera was used to collect samples with a resolution of 640 × 480 at 0.5 s/frame from 10 different scenes. Four thousand and seven original terrain images were retained after manual elimination of repetitive ones. Afterward, the Labelme semantic annotation software was employed to conduct semantic annotation. Samples were divided into 12 semantic categories: grass, concrete, masonry, mud, woodland, bumpy road, tree, obstacle, person, ditch, water, and background.
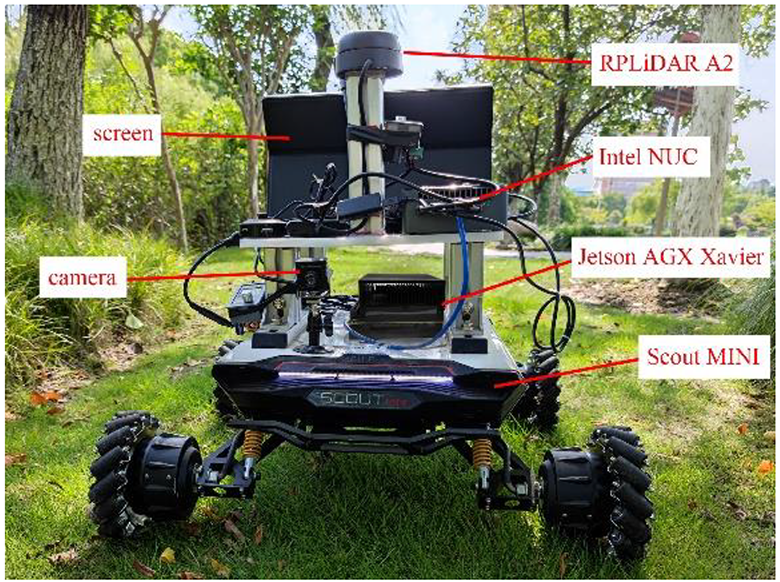
The Scout MINI robot equipped with a monocular camera.
As shown in Figure 7, we have made a more detailed division of outdoor terrains compared with Zhang et al. 1 and Wang et al.. 2 Based on the characteristics of common working spaces for outdoor robots, in HDU-Terrain Dataset, the feasible terrains were divided into grass, woodland, mud, cement, masonry, and bumpy road. Bumpy road includes gravel roads and uneven hard roads, which have a high traffic cost for wheeled robots. Unfeasible terrains are divided into trees, obstacles, persons, ditches, and water, where obstacles include rocks, railings, vehicles, street lamps, and other objects. The HDU-Terrain Dataset is publicly available at https://hduraslab.github.io/pages/research.html.

Example frames of ground truth annotation in HDU-Terrain Dataset.
Figure 8 shows the overall percentage of semantic categories of the entire data set. It can be seen from Figure 8 that there is always a tree in almost every picture. Mud, person, and ditch occupy relatively small percentages. This proportion provides a helpful reference for the comparison in the “Ablation Study for MobileNet” section.

The overall distribution of semantic categories in HDU-Terrain Dataset.
HDU-Terrain Dataset contains 10 sub-data sets. Figure 9 shows its specific composition and semantic categories distribution. The building12_trail sub-data set was gathered in sunny weather, and images were suffered from strong light interference. During the photographing of the yueya_trail sub-data set, the robot moved quickly, resulting in many blurred frames. In addition, many images in the data set contain small and irregular targets, such as various obstacles and persons.
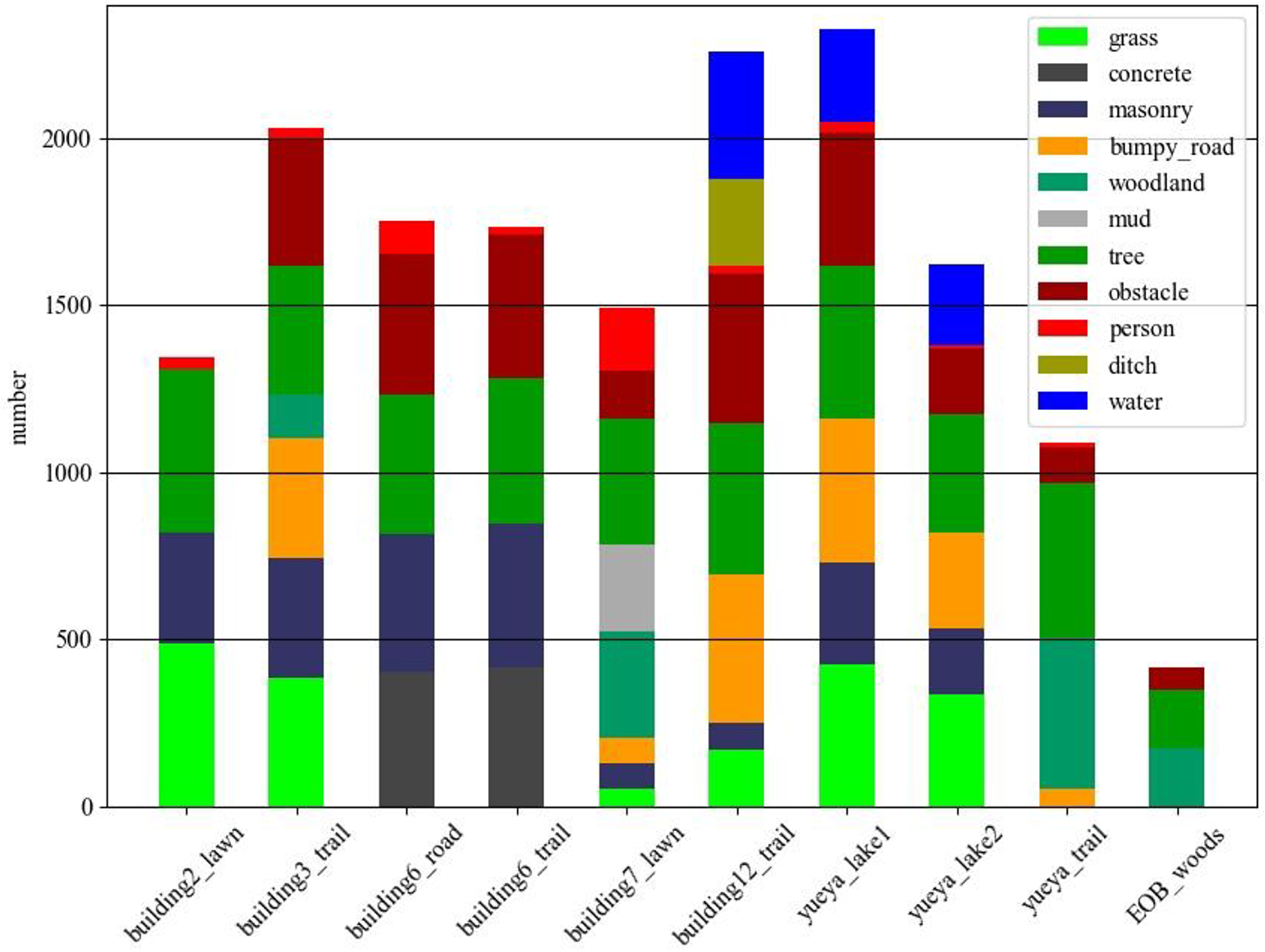
Ten sub-data sets in HDU-Terrain Dataset.
Experiments of terrain segmentation
Settings for training and testing
The HDU-Terrain Dataset is randomly divided into a training set, a validation set, and a test set. The images accounted for 81%, 9%, and 10% of the total data set, respectively. All models are trained through the training set on a PC with NVIDIA RTX2070 (Santa Clara, CA, USA) Super GPU (Graphic Processing Unit). We used the “poly” learning rate policy. 22 The current learning rate during the training process is shown in the following equation
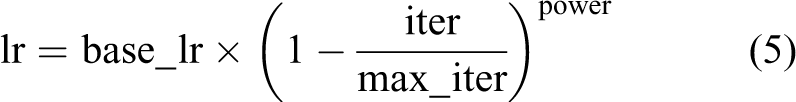
where base_lr is the initial learning rate, iter represents the current number of iterations, and max_iter represents the number of iterations. We set base_lr to 0.01 and power to 0.9. Due to the limited video memory of the GPU, the batch size is set to 4. A total of 50 epochs are trained, and 812 steps are trained in each epoch, which is equivalent to 40 K iterations. Using the Adam optimizer, the weight decay is set as 0.001. Considering the time cost of training, transfer learning is introduced into the network.
Five semantic segmentation metrics are used to evaluate the models: the number of model parameters, segmentation speed (frame/s), mean intersection over union (MIoU), mean pixel accuracy (MPA), and pixel accuracy (PA). PA and intersection over union (IoU) are derived from the confusion matrix and they are generally accepted metrics for semantic segmentation. 15 The computation of PA is shown in the following equation

where n represents the number of categories to be divided. In this article, 0–11 represents 12 semantic categories in Figure 7, respectively.


The model test is divided into two parts. The test set in HDU-Terrain Dataset is employed to test the accuracy, and the Jetson AGX Xavier (Santa Clara, CA, USA) is used to test the real-time performance. Jetson is an embedded system designed by NVIDIA. It has strong image processing ability. Therefore, we apply it to the terrain segmentation for robots.
Ablation study for MobileNet
MobileNet is used to build encoding paths because of its lightweight characteristic, but there are some differences in the features extracted by different MobileNets. The performance of several terrain segmentation networks composed of varying encoding paths is tested in this section. Psp-MobileNet: The proposed and recommended network. Psp-MobileNet-F5: Compared with Psp-MobileNet, we carry out one more depthwise separable convolution in the encoding path and extract a total of five layers of feature maps. The structure of the decoding path is PspNet. This test aims to verify that more feature extraction layers do not improve the algorithm’s performance. Psp-MobileNet-F3: Compared with Psp-MobileNet, we carry out a less depthwise separable convolution in the encoding path and extract a total of three layers of feature maps. The structure of the decoding path is also PspNet. The purpose of this test is to verify that fewer feature extraction layers can reduce the accuracy. Psp-MobileNetV2: MobileNetV2
24
is employed to extract features on the encoding path, and the structure of the decoding path is also PspNet. This comparative test is to verify whether MobileNetV2 or MobileNetV1 is more suitable to combine with PspNet.
As presented in Table 2, Psp-MobileNet has the highest segmentation accuracy. Although there are differences among the parameters of the four networks, the memory occupied by the corresponding model does not affect the regular operation of the mobile robots. In addition, the four networks have the same segmentation speed. We believe that the MobileNet with four feature extraction layers is the most suitable for the proposed Psp-MobileNet.
The comparison of several encoding paths.

Psp-MobileNet: pyramid scene parsing-mobile network; MIoU: mean intersection over union; MPA: mean pixel accuracy; PA: pixel accuracy.
Comparison of terrain segmentation
To evaluate the performance of the proposed network, several segmentation methods are designed and compared as follows. Seg-MobileNet: The semantic segmentation network SegNet
16
and MobileNet are used to design this segmentation network. U-MobileNet: The semantic segmentation network U-Net
25
and MobileNet are used to design this segmentation network. Deep-MobileNet: The semantic segmentation network DeepLabV3+
26
and MobileNet are used to design this segmentation network. Psp-MobileNet: The proposed network.
To ensure the reliability of the comparison, the training settings of the four networks are the same.
As presented in Table 3, compared with the other three methods, the proposed Psp-MobileNet has the highest segmentation accuracy. Its MIoU and MPA are 4.8% and 3.0% higher. Psp-MobileNet also maintains the fastest segmentation speed, which is twice as fast as others.
The comparison of the Psp-MobileNet, the Seg-MobileNet, the U-MobileNet, and the Deep-MobileNet.

Psp-MobileNet: pyramid scene parsing-mobile network; MIoU: mean intersection over union; MPA: mean pixel accuracy; PA: pixel accuracy.
It can be seen from Figures 10 and 11 that all the methods perform well on large areas of grass, masonry, bumpy road, woodland, and tree. There is no significant difference in the accuracy for these categories. But for concrete, ditch, mud, obstacle, and person, Psp-MobileNet has apparent advantages, especially for the person. As presented in Tables 4 and 5, IoU and PA of Psp-MobileNet for the person are 1.5 times and 1.3 times that of other methods, respectively. It proves that Psp-MobileNet has an excellent adaptive ability for small targets or low proportion targets. In addition, the segmentation accuracy of Psp-MobileNet for each category is almost the highest among all these methods. It shows that Psp-MobileNet has no significant weakness in the terrain segmentation of HDU-Terrain Dataset in segmentation accuracy. However, it is about twice as fast as the other methods, as presented in Table 3. The real-time performance for segmentation is critical for a mobile robot. That is why we believed that Psp-MobileNet is more suitable for landscape segmentation.

The bar chart of IoU. IoU: intersection over union.

The bar chart of PA. PA: pixel accuracy.
The IoU of all categories in the Psp-MobileNet, the Seg-MobileNet, the U-MobileNet, and the Deep-MobileNet.

Psp-MobileNet: pyrsamid scene parsing-mobile network; IoU: intersection over union.
The PA of all categories in the Psp-MobileNet, the Seg-MobileNet, the U-MobileNet, and the Deep-MobileNet.

Psp-MobileNet: pyramid scene parsing-mobile network; PA: pixel accuracy.
Figure 12 shows the segmentation results of the above four methods. There are many unstructured terrains in outdoor environments, which is very challenging. Seg-MobileNet and U-MobileNet are prone to segment terrains mistakenly in the corner areas of images. Psp-MobileNet could not only segment complex small targets such as persons and obstacles but also accurately describe the edges of large-area terrains. Its false positives and false negatives areas are significantly smaller than other methods.

The segmentation results of the Psp-MobileNet, the Seg-MobileNet, the U-MobileNet and the Deep-MobileNet. (a) Image, (b) Ground truth, (c) Seg-MobileNet, (d) U-MobileNet, (e) Deep-MobileNet, and (f) Psp-MobileNet. Psp-MobileNet: pyramid scene parsing-mobile network.
Conclusions
This article presented a terrain segmentation method for field robots based on Psp-MobileNet by combining PspNet and MobileNet. Compared with several state-of-the-art methods, it has a good balance between accuracy and real-time performance. We also established a more realistic and annotated terrain segmentation data set by sampling terrains from a robot’s perspective. This study contributes to a more detailed division of the terrains and can support the multiterrain map building and multiterrain-based navigation for mobile robots. Experimental results show that the proposed terrain segmentation method based on Psp-MobileNet has excellent real-time performance and maintains acceptable accuracy on an onboard computer often used by robots.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Key Research and Development Project of Zhejiang Province (Grant No. 2019C04018) and the Science and Technology Project of Zhejiang Province (Grant No. 2019C01043).