
Abstract
Multiagent reinforcement learning holds considerable promise to deal with cooperative multiagent tasks. Unfortunately, the only global reward shared by all agents in the cooperative tasks may lead to the lazy agent problem. To cope with such a problem, we propose a generating individual intrinsic reward algorithm, which introduces an intrinsic reward encoder to generate an individual intrinsic reward for each agent and utilizes the hypernetworks as the decoder to help to estimate the individual action values of the decomposition methods based on the generated individual intrinsic reward. Experimental results in the StarCraft II micromanagement benchmark prove that the proposed algorithm can increase learning efficiency and improve policy performance.
Keywords
Introduction
Many real-world tasks are cooperative multiagent problems, in which all agents work together to achieve a common goal, such as distributed logistics, 1 crewless aerial vehicles, 2 autonomous driving, 3 and network packet routing. 4 Multiagent reinforcement learning (MARL) holds considerable promise to deal with such tasks.
However, the sparse reward is a long-standing problem in the reinforcement learning (RL) field. Worse still, this problem will be more server in the cooperative MARL tasks, in which all agents usually share a global reward. Specifically, the sparse global reward not only reduces the learning efficiency but also may lead to the lazy agent problem in the multiagent field, 5,6 which means that it is difficult for each agent to confirm its contribution to the team’s success (i.e. the shared global reward). As a consequence, if an agent learns the decentralized policy based on the global reward directly, it will take the global reward originated from its teammates’ behavior as its contribution, thus encouraging its current meaningless action.
To address the lazy agent problem, decomposition methods 5,7,8 first learn a joint action value (JAV) for all agents based on the global reward and the joint experiences of all agents (i.e. joint observations and the joint actions). Then, each agent learns the individual action value (IAV) implicitly from the JAV decomposition rather than from the global reward directly. Finally, the per-agent decentralized policy can be determined based on its IAVs. To this end, value-decomposition networks (VDN) 5 additively decomposes the JAV into IAVs across agents, QMIX 7 replace the additivity with the monotonicity, and QTRAN 8 is free from the additivity/monotonicity structural constraints to make the decomposition method more general. Thereby, the IAVs are trained end-to-end with the optimization of the JAV.
Another approach to address the lazy agent problem is assigning each agent an individual reward. Reward shaping 9 aims to manually design individual reward functions for each agent. However, it needs heavy and careful manual work, which is hard to ensure that the optimal policy will not be changed even in the single-agent field. 10,11 Thus, a group of recent single-agent RL methods aims to learn parametrized intrinsic reward functions to replace the manually designed reward functions. 12 –14 Inspired by the concept, learning individual intrinsic reward (LIIR) 15 learns each agent an intrinsic reward function and then combines the intrinsic reward and the global reward to optimize the policy via the actor-critic 16,17 algorithm.
In this article, we propose a generating individual intrinsic reward (GIIR) algorithm in MARL, which constructs a connection between the learned individual intrinsic reward (IIR) and the decomposition methods. We assume that there exists an individual reward function for each agent, thus introducing an intrinsic reward encoder to generate the IIR
Related work
The naive MARL method to address the cooperative multiagent tasks is joint action learning (JAL), 20 which takes all agents as an agent and learns a JAV based on the joint experience of all agents. However, the number of actions increases exponentially with the number of agents, which makes it intractable. Thus, individual learning views other agents as parts of the environment and learns an IAV based on per-agent local experience. Then, each agent performs the decentralized policy without considering other agents. However, because of ignoring the strategy changes of other agents, it fails to coordinate with other agents efficiently. Besides, all agents often share a global reward in cooperative multiagent tasks. Under such circumstances, it is hard for each agent to confirm its contribution to the team’s success. Thus, each agent may view the rewards that originated from its teammates’ behavior as its contribution, which may lead to the lazy agent problem. 5,6
One approach to cope with the lazy agent problem is the decomposition method, 5,7,8 which aims to learn IAV implicitly from the JAV decomposition rather than from the global reward directly. Another approach is providing each agent an individual reward. Reward shaping 9 manually designs the individual reward for each agent, but it requires heavy handwork to accurately assign rewards to each agent and is difficult to handle in practice. LIIR 15 adopts the actor-critic algorithm 17,16 to address the MARL tasks and learns each agent an IIR, then the actor uses the IIR to learn each agent’s policy. Th emergence of individuality (EOI) 21 gives each agent an intrinsic reward, but it aims to learn the individuality based on the intrinsic reward to drive agents to behave differently. Thus, the intrinsic reward is outputted from a classifier in EOI and the role is to distinguish different agents. Our work is closely related to the decomposition methods and LIIR. We learn a parameterized intrinsic reward and introduce it into the decomposition methods to help to improve the learning efficiency.
Our work is also related to the single-agent works about the intrinsic reward. Most works take curiosity as the intrinsic reward either to encourage the agent to explore novel states 22,23 or to encourage the agent to reduce the uncertainty in predicting the consequence of its actions. 24,25 Besides, Zheng et al. 12,14 and Bahdanau et al. 13 learn parameterized intrinsic reward to help achieve learning goals.
Background
In this work, we focus on the setting of Decentralized Partial Observation Markov Decision Process (Dec-POMDP).
26
It models the fully cooperative MARL task as a tuple
To handle the partial observability, there is a technique
27
in MARL that applying the recurrent neural network
28
to estimate the IAV
Individual Q-learning
Individual Q-learning (IQL) views other agents as part of the environment, in which each agent uses the global reward to learn an IAV

where
Note that the global reward may originate from its teammates’ behavior, but each agent uses the global reward rt to update its IAV in Equation (1), which may lead to the lazy agent problem. Besides, because the dynamics of the environment will change as its teammate changes its behavior strategy, the learning process of IQL may be a nonstationary problem.
Decomposition method
Decomposition methods
5,7,8
apply the global reward to learn a JAV based on the joint experience (i.e. joint observations and joint actions), which is similar to the JAL.
20
Then, they decompose the JAV into per-agent IAV
The key condition of decomposition methods is individual–global–max (IGM), 8 which can make true that the optimal joint actions based on the JAV are equivalent to the collection of individual optimal actions of each agent based on the IAVs by ensuring that the global argmax operation on the JAV is the same with a collection of simple individual argmax operations of each IAV

Thus, we can determine decentralized policies based on the optimal IAVs of each agent while the goal of the training is optimizing the JAV.
To satisfy IGM, VDN 5 decomposes the JAV based on the additivity
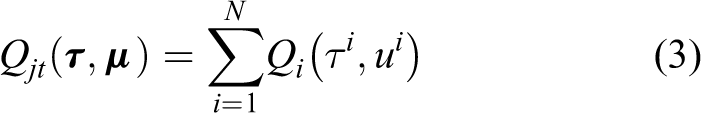
where
QMIX 7 decomposes the JAV based on the monotonicity

where
QTRAN 8 transforms the JAV into the sum of the IAVs and a state value, which can be free from the additivity/monotonicity structural constrains
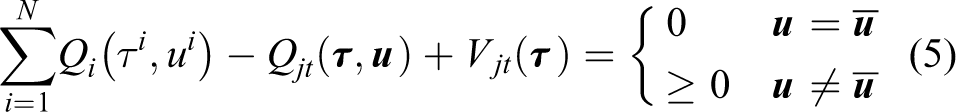
with

where
Thereby, the IAVs
Learning individual intrinsic reward
LIIR
15
learns each agent an IIR

where
Next, the proxy value function is used to optimize the policy of each actor (i.e. each agent)

where
Method
In this section, we propose a GIIR algorithm, which constructs a connection between the IIR and the decomposition methods in the cooperative MARL field.
The main idea is that through optimizing by maximizing the expected global reward, the learned IIR can guide each agent to perform the action that can obtain a greater global reward by participating in the estimation of the IAV.
We assume that there exits an IIR function

where

(a) Architecture of GIIR. The intrinsic reward encoder generates M IIR distributions, and a M-dimensional IIR is sampled from the generated distributions. The intrinsic reward decoder (i.e. hypernetworks) generates the parameters for the agent network. Then the agent network will output IAV
Similar to LIIR,
15
the generated IIR
Next, the IAVs of all agents will be mixed into a JAV

which can be abbreviated as
Then, we can use the global reward rt to optimize the JAV

with

where
Since the IAV of the decomposition methods can reflect each agent’s contribution to the global reward to some extent,
5
we can apply the IAV to train each agent’s IIR

where
Finally, the gradient of the overall loss function is as follows

Experiment
In this section, we conduct the experiments on a benchmark named SMAC 19 to show the performance improvement of the proposed GIIR.
Environmental setup
SMAC provides a set of fully cooperative multiagent scenarios, which focus on the decentralized micromanagement of the real-time strategy game StarCraft II. Namely, all units (ally units) are controlled by MARL agents to defeat another group of units (enemy units). The enemy units are controlled by the built-in game AI with difficulty from very easy to cheat insane, and we set the difficulty as very difficult in this work. Besides, SMAC considers the partial observability setting by introducing the sight range, in which each unit can only access the local observation with the field of the view.
To evaluate the policy performance of the proposed GIIR, we conduct the comparison experiments in three homogeneous scenarios (5m_vs_6 m, 8m_vs_9 m, and 10m_vs_11 m) and three heterogeneous scenarios (1c3s5z, MMM, and MMM2). The list of scenarios considered in our experiment is presented in Table 1, and the screenshots of the six scenarios are shown in the Online Appendix. We evaluate the proposed method and the comparison method across 10 independent runs with different seeds and run 20 independent test episodes every 20,000 timesteps training to calculate the percentage of winning episodes as the win rates, in which the winning episodes are those that all enemy units are defeated within a time limit. All methods are evaluated after 10 million training timesteps, and the exception is the MMM, which is an easy scenario and only be evaluated after 6 million training timesteps. More experimental details are presented in the Online Appendix.
SMAC scenarios.

SMAC: StarCraft multiagent challenge.
Comparison results
We compare the proposed GIIR with decomposition methods (i.e. VDN, QMIX, and QTRAN) and LIIR. Besides, we also compare it with the IQL, which learns the IAV based on the global reward directly.
The learning curves are shown in Figure 2 and the experimental statistic results are shown in Table 2. Because ignoring the coordination among agents and employing the global reward directly as the individual reward to learn per-agent IAV, the performance of IQL is almost the worst in all scenarios. Decomposition methods learn IAV implicitly through end-to-end training from the JAV decomposition, the performance has gain a great improvement, in which the performance of QMIX is slightly better than that of VDN, and QTRAN indeed performs poorly in most SMAC scenarios according to Wen et al.
32
The experiments of Du et al.
15
have shown that LIIR can outperform decomposition methods in many easy scenarios, which are similar to the Figure 2(d) and (e). This proves that learning each agent an IIR can help to improve performance. However, when the scenarios become more difficult, the performance of LIIR is poor, and even is worse than that of the decomposition methods, which are shown in Figure 2(a) to (c). Compared with that, GIIR combines the advantages of the decomposition methods and LIIR, which introduces the IIR into decomposition methods. The experimental results show that it can almost obtain better performance than all comparison methods, in which the performance of GIIR (

Test win rates of IQL, VDN, QMIX, QTRAN, and GIIR on six scenarios. (a) 5m_vs_6 m, (b) 8m_vs_9 m, (c) 10m_vs_11 m, (d) 1c3s5z, (e) MMM, and (f) MMM2. IQL: individual Q-learning; VDN: value-decomposition network.
Mean, SD, and median of test win rates in six SMAC scenarios.

SD: standard deviation; SMAC: StarCraft multiagent challenge; IQL: individual Q-learning; VDN: value-decomposition network; LIIR: learning individual intrinsic reward; GIIR: generating individual intrinsic reward.
Conclusion
In this article, we propose GIIR algorithm, which constructs a connection between the decomposition and the learned IIR to address the lazy agent problem. The proposed GIIR generates an IIR for each agent to help to confirm per-agent contribution to the global success. Besides, the generated IIR is optimized by maximizing the expected global reward, thus it can help to obtain greater teamwork success. Our experimental results in SMAC prove that GIIR improves the final performance over both the decomposition methods and LIIR in cooperative tasks.
In future work, we will focus on studying other methods to better utilize the generated intrinsic reward to estimate the IAVs. Furthermore, we will conduct additional experiments on other SMAC scenarios with a larger number and greater diversity of units. Moreover, we will apply the proposed method to actual multiagent system scenarios, such as the logistics robot task, and conflict resolution in the air traffic control task.
Supplemental material
Supplemental Material, sj-pdf-1-arx-10.1177_17298814211044946 - Generating individual intrinsic reward for cooperative multiagent reinforcement learning
Supplemental Material, sj-pdf-1-arx-10.1177_17298814211044946 for Generating individual intrinsic reward for cooperative multiagent reinforcement learning by Haolin Wu, Hui Li, Jianwei Zhang, Zhuang Wang and Jianeng Zhang in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.