
Abstract
Complicated underwater environments, such as occlusion by foreign objects and dim light, causes serious loss of underwater targets feature. Furthermore, underwater ripples cause target deformation, which greatly increases the difficulty of feature extraction. Then, existing image reconstruction models cannot effectively achieve target reconstruction due to insufficient underwater target features, and there is a blurred texture in the reconstructed area. To solve the above problems, a fine reconstruction of underwater images with the target feature missing from the environment feature was proposed. Firstly, the salient features of underwater images are obtained in terms of positive and negative sample learning. Secondly, a layered environmental attention mechanism is proposed to retrieve the relevant local and global features in the context. Finally, a coarse-to-fine image reconstruction model, with gradient penalty constraints, is constructed to obtain the fine restoration results. Contrast experiment between the proposed algorithm and the existing image reconstruction methods has been done in stereo quantitative underwater image data set, real-world underwater image enhancement data set, and underwater image data set, clearly proving that the proposed one is more effective and superior.
Introduction
Underwater environment surveys and intelligent operations are mainly relying on underwater autonomous underwater vehicle (AUV). 1 AUV perceives the information of surrounding environment via the visual perception system, providing important guarantee for the realization of autonomous navigation capabilities, target recognition and tracking, autonomous route planning, and coordinated control. 2,3 However, there are a large number of algae, plankton, and impurities in the ocean. And the water body has a strong attenuation effect on natural light. These factors seriously affect the underwater imaging effect, resulting in occlusion of underwater images and dim light, and a large amount of target information in underwater images is missing. At the same time, the features of underwater images are difficult to extract because of the complex background information. These factors seriously affect the effect of underwater imaging by covering targets or attenuating light, so a large amount of target information in underwater images has been missed. Therefore, with accurate reconstruction of the images mentioned above, AUV will perform well underwater. 4,5
Image reconstruction is realized by using the adjacent feature information of the missing part or the overall structure information of the image and by adopting a certain reconstruction technology to reconstruct the missing area of the image. 6 The core technology of image reconstruction is that the global semantic structure should be maintained and vivid texture details should be generated as well in the image reconstruction area. 7 –9 Most of the traditional reconstruction methods are based on texture synthesis and structure-based reconstruction methods to achieve image reconstruction. The reconstruction methods based on texture synthesis all use low-level features or patches to reconstruct the missing areas of the image. 10 –14 The structure-based reconstruction method is based on the structure of the image and reconstructs the missing area through the method of gradual diffusion. 15 –17 The traditional reconstruction methods are only fit for the scenes with single background or small missing area, exposing significant deficiency for the underwater images in complex scenes, or with a large amount of missing information. This type of image requires a high degree of understanding of information to achieve underwater image reconstruction.

The reconstruction results of reconstruction model in this article. The top two images are the input underwater images with occlusion phenomenon. The lower two images are the results of the reconstruction obtained by our reconstruction model.
The rapid development of deep learning methods has provided a new avenue for image reconstruction. 18 –20 The image reconstruction method based on deep learning heavily trains the data of the database in a deep learning network, enabling the reconstruction model to learn more deep-level feature information of the image. As generative adversarial networks (GANs), which are regarded as an unsupervised deep learning model, are applied in the field of image reconstruction, 21 –23 the image reconstruction has got further development. The image reconstruction is accomplished by the structure of encoder and evaluated the authenticity of the restored image by a discriminator, so it can ensure the quality of the reconstructed image.
There are a large number of algae, plankton, and impurities in the ocean. Moreover, the visibility is very low poor in deep water for a strong attenuation of light from the water body. Complicated underwater environments, such as occlusion by foreign objects and dim light, can cause serious loss of underwater targets feature. Many factors cause the lack of underwater image feature information, so that the existing image reconstruction model cannot achieve effective reconstruction of these images. To solve the above problems, this article proposes a fine reconstruction algorithm of the underwater image with the target feature missing from the environment feature. Firstly, the environmental attention mechanism is proposed to retrieve relevant local and global environmental features in the context. The model makes greater use of environmental information to solve the problem of insufficient target information. Secondly, it constructs the image reconstruction network from rough to fine. This article embeds the environmental feature attention mechanism layer into the coarse reconstruction network. At the same time, the relevant feature coherent layer is embedded in the fine-grained reconstructed network to obtain more ideal reconstruction results. Finally, through the learning of positive and negative samples in image reconstruction model training, the reconstruction model pays more attention to salient features in the process of extracting features. This can improve the efficiency of training and solve the problem that the target is difficult to extract. The reconstruction results of the model in this paper are shown in Figure 1. The principle is shown in Figure 2. Successful reconstruction of underwater images in the presence of occlusions will not only facilitate autonomous control and collaborative mission planning of AUVs but also have a significant impact on ocean exploration, underwater research, and underwater operations. The contribution of this article can be summarized in three points: Construct an image reconstruction network from rough to fine. And embedding relevant feature coherence layers in the fine reconstruction network for further refinement and perfection of the rough reconstruction results. This image reconstruction model is applied to the field of underwater incomplete images. It will be helpful for underwater environment survey and underwater intelligent operation. Proposes a hierarchical environmental attention mechanism, which can make greater use of background information. Solving the problem of ineffective image reconstruction due to insufficient data. For the first time, the idea of positive and negative sample learning is applied to the field of underwater images. It can improve the efficiency of training and solve the problem of difficult target extraction. The learning and reconstruction capabilities of the image reconstruction model have been improved.

Fine reconstruction of underwater images with environmental feature fusion algorithm network model.
The rest of this article is shown as follows: the second section introduces related work. The third section introduces the principle of underwater image reconstruction algorithm proposed in this article. The fourth section introduces the design simulation based on the proposed algorithm and analyzes the experimental results. The fifth section draws conclusions and points out future research work.
Related work
Image reconstruction
The current image reconstruction methods are mainly divided into two categories. One is a nonlearning image reconstruction method and the other is an image reconstruction method based on learning. Nonlearning image reconstruction methods mainly achieve image reconstruction of missing area by diffusing neighboring information or copying information from the most relevant area of the background. 10,15 This approach produces smooth and realistic results; however, its computational cost and memory usage are very large. To solve this problem, Barnes et al. proposed a fast nearest-neighbor calculation method for image reconstruction, 24 which greatly improved the calculation speed and can obtain a high-quality reconstruction effect. Nonlearning methods are very effective for surface texture synthesis. But they cannot generate semantically meaningful content. So the nonlearning image reconstruction method is not suitable for processing large missing areas.
As for learning-based image reconstruction methods, incomplete image reconstruction is usually realized by making use of deep learning and GAN strategies. Pathak et al. 25 proposed an image reconstruction method based on upper and lower feature prediction, which extracts the depth features of the entire image through a context encoder (CE) and makes reasonable assumptions about the generation of missing parts. At the same time, the pixel loss function is used to make the generated result clearer. However, it does not work well in fine texture generation. To solve this problem, Chao et al. proposed a multiscale image reconstruction model based on the combination of image features and texture constraints. 26 This method synthesizes lifelike high-frequency details through the encoder–decoder structure in the convolutional neural network model and the generated patches, so as to obtain a clearer and more coherent reconstruction effect. Jiahui et al. proposed a repair model based on unified prefeedback. 27 The model includes a context attention layer. Its principle is that to use the feature information of the known patch is used as a convolution processor. The patch generated by the convolutional design is matched with the known contextual patch, and the patch features are weighted by softmax and deconvolved to reconstruct the generated patch using the known contextual patch to obtain a fine texture reconstruction effect. However, this method ignores the semantic relevance and feature continuity of the incomplete region. To solve this problem, Liu et al. proposed an image reconstruction model based on refined deep learning. 28 This method proposes to adopt a new coherent semantic layer and retain the upper and lower semantic context structure through the coherent semantic layer, and the inferred part is more reasonable.
Contextual attention
The attention mechanism can retrieve image background feature information, which improves image processing capability, so it has been widely used in the field of vision. 29 To improve the classification ability of images, Mnih et al. introduced the attention mechanism into the CNN, which greatly improved the learning ability of the model. 30 Xu et al. divided the attention mechanism into two types, namely soft attention and hard attention. The relevant global features are extracted via soft attention. Extract the relevant features of small areas via hard attention. 31 Similarly, the attention mechanism is introduced into the field of image reconstruction. More potential feature information is obtained by means of the contextual attention (CA) mechanism to improve the effect of image reconstruction. 23 –26
Contrastive learning
Contrastive learning, a self-supervised learning method, principle is that the model is able to note the salient features of the samples by positive and negative sample learning, thus greatly reducing the computational effort of model training. Bo and Lin improved the overall quality of the subtitles by comparing and learning the correlation between the image and the subtitles. 32 Through the model’s learning of “similar” data points and “negative samples,” the weight of the representation of similar data is gradually increased, thereby reducing the workload of sample labeling. 33 He et al. used comparative learning to build a large dynamic dictionary and proposed comparative unsupervised learning to improve the detection ability of the model. 34
In view of the lack of information in the occlusion of underwater images, the existing image reconstruction technology cannot achieve image reconstruction. This article proposes fine reconstruction of underwater images with environmental feature fusion. In the construction of a fine reconstruction model, the attention mechanism will be embedded in the reconstruction model. At the same time, via positive sample and negative sample learning, the reconstruction model can pay attention to the salient features of the sample. The orthomorphic structure of the repair model in this article is shown in Figure 2. And the detailed principles will be elaborated in the third section.
Proposed approach
Feature extraction
Underwater objects tend to be obscured by foreign objects in complex underwater environments. In this article, the occluded underwater objects are defined as underwater targets. At the same time, the occluded area is defined as the missing area.
The underwater light is dim, and the movement of underwater plankton causes slight deformation of the underwater target. These factors undoubtedly increase the difficulty of underwater image feature extraction. At the same time, underwater images are difficult to obtain, which cannot meet the needs of deep learning models that require a large number of samples for training. To solve this problem, positive and negative sample learning is introduced to extract the features of underwater targets.
VGGNet, a network model proposed by Kamalyan and Simonyan, 35 has the following characteristics of deep network, small convolution kernel, and small pooling kernel. Increasing the depth of the model can improve its feature extraction capability. At the same time, the model also has generalization capability to adapt to different data sets. Therefore, extract the features of underwater targets, using the visual geometry group (VGG)-16 model network. The class of the sample should be clarified. As shown in Figure 3, the underwater images with occlusion phenomenon are positive samples. The obscured underwater objects are defined as real values and the images irrelevant to the underwater target are defined as negative samples. The principle is shown in the following equation

where

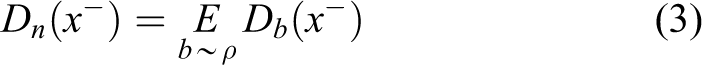
where distribution Dz
represents data similar to the target, distribution Dn
represents data not related to the target, and

Comparison of the principle diagram of feature extraction by learning.
The complex underwater environment results in underwater objects to be obscured. These factors that block objects are closely related to underwater objects. Such usage of the background information will contribute to the reconstruction of underwater images. This article proposes extracting relevant environmental information in the background by using hierarchical environmental feature attention mechanism. The environmental feature attention mechanism will retrieve and copy feature information patches from the known background to reconstruct the patch of the missing area. When selecting patches, the most concerned issue of this article is how to match the missing target features with the surrounding environment.
The paramount consideration is the local environmental characteristics, matching the missing pixel characteristics of the target with the surrounding environmental information. Extract the patch from the background and shape it into a convolution filter. To further verify the matching degree between the extracted background patch

where

To make better use of background information, this article proposes to aggregate global-level environmental feature information based on the overall characteristics of the input image. And the derived attention feature information is called global environmental attention feature information. The same as the above principle, the global-level environmental attention mechanism is expressed as follows

Through the above, the background features of local environment attention and the background features of global environment attention can be obtained. In this article, the environment feature information of these two parts is fused by convolutional layer. Thereby a layered environmental attention mechanism is obtained. The degree of attention between the background patch

where
Refactoring model construction
The model designed in this article is mainly divided into two parts: the rough reconstruction part and the fine reconstruction part. Its structure is shown in Figure 4. Input the occluded image

Design of reconstruction model from coarse to fine. The image reconstruction model is divided into two parts, coarse reconstruction and fine reconstruction, and the environment feature attention layer is embedded in the coarse reconstruction network. The relevant feature coherence layer is embedded in the fine reconstruction network.
The rough repair network designed in this article is a repair model based on GAN strategy. It associates each layer of the encoder with the characteristics of the corresponding layer of the decoder. The encoder obtains the depth feature representation of the image to be reconstructed. And the decoder predicts and generates missing area information based on the feature. This article embeds the hierarchical environmental feature attention mechanism into the rough reconstruction network. In the image reconstruction model, Wasserstein Generative Adversarial Network Gradient Penalty (WGAN-GP) loss is better than the existing GAN loss, and it will produce a better effect when combined with the reconstruction loss function. The Wasserstein-1 distance in WGAN is expressed as follows

where Pr
represents the distribution of the generation feature
WGAN-GP uses Wasserstein-1 distance to compare the generated data distribution with the original data distribution. The principle is shown in the following equation

where
The WGAN-GP reconstruction model uses gradient penalty constraints to train and optimize the generator of the original WGAN-GP network. The generated data distribution is compared with the original data distribution by distance

where L represents the set of 1-Lipschitz functions.
The image

Schematic diagram of feature correlation.
Feature correlation is divided into two stages: search stage and generation stage. Generate each patch


where

The patch generation process is an iterative process, so

where D represents the discriminator.
Image reconstruction and loss function
The extraction of underwater image features is difficult. Also underwater images are difficult to obtain, which cannot meet the requirements of deep learning models that require a large number of samples for training. The VGG-16 model pretrained in the stereo quantitative underwater image data set (SQUID) database. The reconstruction model extracts feature information of the image to be reconstructed by learning positive and negative samples. And the feature representation of the sample data is learned using the data itself as supervised information. Then the objective function is shown in the following equation

Thus, the relationship between M samples from

Through the above analysis, the objective function based on unsupervised learning can be expressed as follows

Image reconstruction often used perceptual loss to improve the reconstruction ability of image reconstruction networks. Since the reconstructed model in this article contains the relevant feature coherent layer. The past perceptual loss methods cannot be directly used to optimize the repair model based on convolution. Otherwise, it will affect the training of the reconstructed model and the reconstructed results. To solve this problem, this article adjusts the form of perceptual loss and proposes a solution to consistency loss. Set the encoder and the decoder feature spaces corresponding to the area to be reconstructed as the target. And the distance Lc is calculated according to this theory. The resulting consistency loss is shown in the following equation

where
To make the rough repair image Ir and the fine reconstructed image Im closer to the real image, we will use the distance L 1 as our image reconstruction loss. The loss function is shown in the following equation

Taking into account the consistency loss, edge loss function, contrastive loss, and reconstruction loss, the overall goal of the reconstruction model in this article is defined as follows
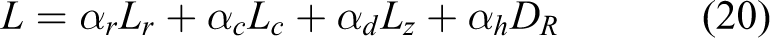
where
Experiment
In this section, a large number of experiments are designed to verify the performance of our proposed image reconstruction model. And comparative experiment is conducted between the current article and the existing methods in SQUID, 36 Real-world Underwater Image Enhancement (RUIE) data set, 37 and underwater image data set.
Experimental setup
The experiment designed in this article is based on three data sets: SQUI data set, RUIE data set, and underwater image data set. The learning rate is set to
Qualitative experimental comparison
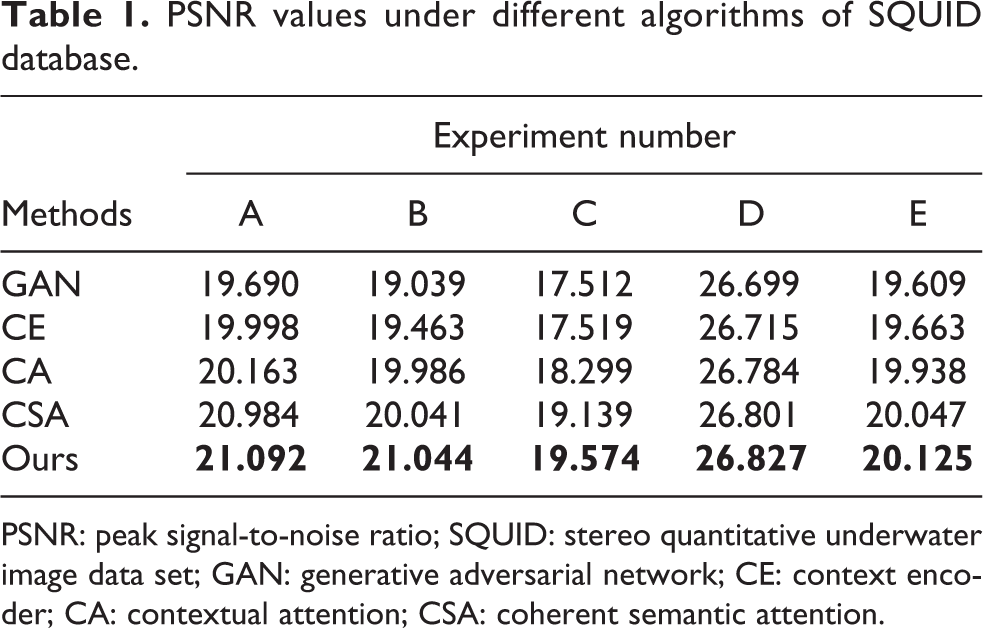
SQUID is a data set mainly aiming at the reconstruction of various underwater targets and underwater scenes. It is widely used in the field of underwater image research. It is mainly used in research fields such as underwater image enhancement, underwater image defogging, and underwater image three-dimensional (3D) reconstruction. This article selects a large number of underwater figures from the SQUID. The input image is occluded by the splash of the target feature, and the occluded part is reconstructed by the algorithm proposed in this article. In the experiment, the proposed algorithm is compared with GAN, CE, CA, and CSA image reconstruction models, with the simulation result shown in Figure 6.

Repair results of each model in the SQUID. The goal of the experimental reconstruction is to reconstruct the area where the person is obscured by the water splash. The leftmost row of the figure is the input image, and the others are the reconstruction results of GAN, CE, CA, CSA, and ours image reconstruction models in order. SQUID: stereo quantitative underwater image data set; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
The simulation results are shown in Figure 6. The input in the leftmost column is the underwater image where the target feature is lost due to splashes or water ripples. Others are the reconstruction results of GAN, CE, CA, CSA, and ours image reconstruction models in order. Experiment (A), experiment (B), experiment (D), and experiment (E) are experiments in which target features are lost due to water spray. Experiment (C) is an experiment of target deformation caused by water ripples. It can be obtained from the experimental results that GAN, CE, CA, and CSA cannot effectively reconstruct underwater images. For example, in experiment (A), experiment (C), and experiment (D), the results of GAN and CE model reconstruction lose a lot of target features. For example, in experiment (A) and experiment (D), although the CA and CSA models can be important the occluded part of the structure target, there is a fuzzy texture. The algorithm proposed in this article outperforms other algorithms in most cases. The model reconstruction results in this article are relatively clear and can effectively reconstruct the occlusion information. For example, experiment (C) and experiment (E) can reconstruct the information of human occlusion area well. And there is no loss of target features. Since the underwater target obscures too much area, there may be not enough learning of the scene to learn more features about the human body. Therefore, the image reconstruction is not so satisfactory. However, the restoration of the proposed algorithm is superior to other algorithms to some extent.
Quantitative experimental analysis
Due to individual differences, personal preferences, and other subjective factors, the evaluation of experimental results will be one-sided to a certain extent. To obtain a more accurate quality evaluation of the repair results, this article introduces peak signal-to-noise ratio (PSNR) 38 and structural similarity index (SSIM) 39 to analyze the repair results from the data to get more accurate evaluation results. The signal-to-noise ratio evaluates the quality of the image through the error of the pixels corresponding to the two images. The larger the value, the better the repair result of the image
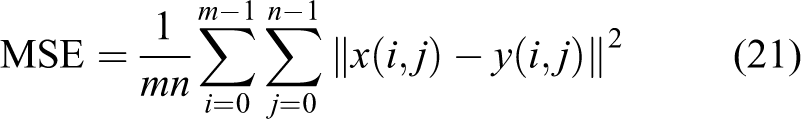
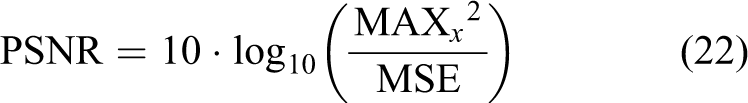
where m and n represent the size of the image, and MSE represents the mean square error between the images.
Structural similarity is important to measure the structural similarity of the image from the brightness, contrast, and structural information of the image, thereby evaluating the degree of distortion of the image. The larger the value, the smaller the distortion. The closer the repaired image is to the original image, the principle is shown in the following equation

where
When evaluating the quality of image reconstruction, people often use PSNR and SSIM for evaluation. The PSNR value of Figure 6 is shown in Table 1. It can be seen from the table that the repair result of this model is better than other models. The PSNR value of experiment (A) and experiment (B) is significantly higher than that of experiment (C), experiment (D), and experiment (E). The SSIM value of Figure 6 is shown in Table 2. It can be seen from the table that the SSIM value of the repair result of the model in this article is higher than that of other models. The PSNR value is significantly higher than that of other groups of experiments, thus explaining the underwater scene. It has a great influence on underwater image reconstruction.
PSNR values under different algorithms of SQUID database.
PSNR: peak signal-to-noise ratio; SQUID: stereo quantitative underwater image data set; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
SSIM values under different algorithms of SQUID database.

SQUID: stereo quantitative underwater image data set; SSIM: structural similarity index; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
RUIE data set is a data set for underwater image research proposed by Dhirubhai Ambani Institute of Information and Communication Soft International Institute. RUIE data set has several features: rich underwater images, large data volume of its main feature image, image scenes, various colors, rich detection targets, etc. It is mainly used for detection and recognition of underwater targets, and enhancement and recovery of underwater images. This article selects a large number of frogman images from the RUIE database. The local features of these frogmen are obscured by fish and then the target reconstruction for the obscured part is achieved by the proposed algorithm. In the experiments, the algorithm of this article is compared with GAN, CE, CA, and CSA image reconstruction models. The simulation results are shown in Figure 7 and their PSNR values and SSIM values are presented in Tables 3 and 4, respectively.
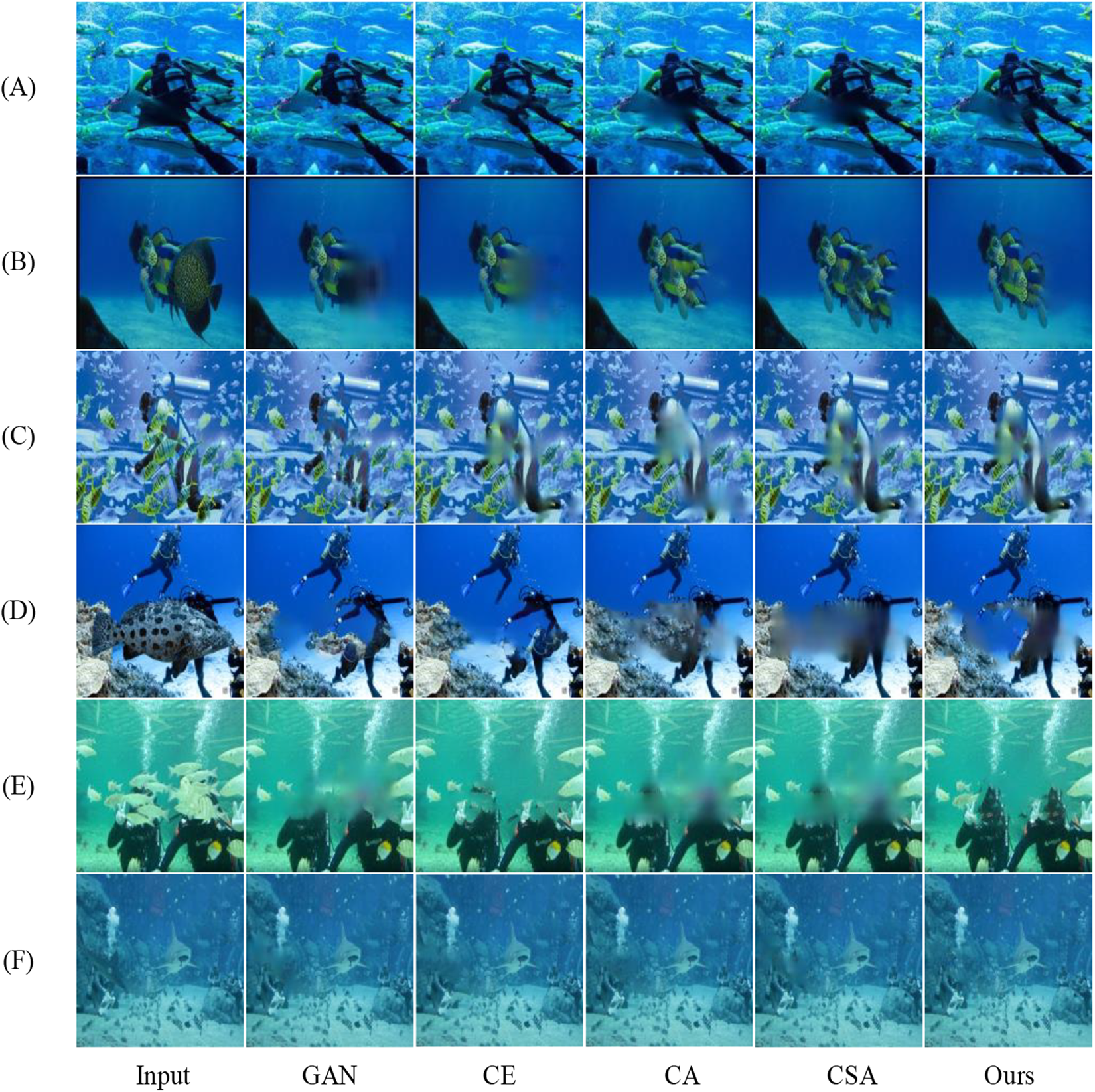
Repair results of each model in the RUIE database. The experiment is aimed at a scenario where the frogmen are obscured by fish, and the experiment aims to reconstruct the features of the frogmen in the obscured area. The leftmost row of the figure is the input image, and the others are the reconstruction results of GAN, CE, CA, CSA, and ours image reconstruction models in order. RUIE: real-world underwater image enhancement; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
PSNR value of each repair result of RUIE database.

PSNR: peak signal-to-noise ratio; RUIE: real-world underwater image enhancement; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
PSNR value of each repair result of RUIE database.

PSNR: peak signal-to-noise ratio; RUIE: real-world underwater image enhancement; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
The simulation result is shown in Figure 6. The input in the leftmost column is the underwater image where the target feature is lost due to the occlusion of fish. Others are the reconstruction results of GAN, CE, CA, CSA, and ours image reconstruction models in order. It can be obtained from the experimental results that GAN, CE, CA, and CSA cannot effectively reconstruct underwater images. For example, in experiment (A), experiment (D), and experiment (E), the results of GAN and CE model reconstruction lose a lot of target features. As in experiments (D) and (E), although the CA and CSA models are able to reconstruction the obscured part of the target, there are blurred textures and the reconstruction area is blurred. The results of the model reconstruction in this article are relatively clear and can effectively reconstruct the occlusion information. As in experiment (D) and experiment (E), the algorithm proposed in this article can over effectively reconstruct the features of the human body, while other reconstructive models cannot. The experimental results verify that the image reconstruction model proposed in this article has certain advantages in the underwater field.
The PSNR values of the experimental results are presented in Table 5. From the data, it can be seen that the reconstruction results of this model are better than other models, and the PSNR values of experiments (E) and (F) are significantly higher than those of other experimental groups. It can be seen from the table that the SSIM value of the reconstruction result of the model in this article is significantly higher than that of other models, and the SSIM value is significantly higher than that of other groups of experiments. This shows that the proposed reconstruction model has certain advantages in underwater image reconstruction. To further demonstrate the superiority of the proposed algorithm, the PSNR and SSIM values corresponding to the experimental results of Figure 7 are represented by the line graphs as shown in Figures 8 and 9, respectively.
PSNR value of each repair result in the underwater target data set.

PSNR: peak signal-to-noise ratio; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
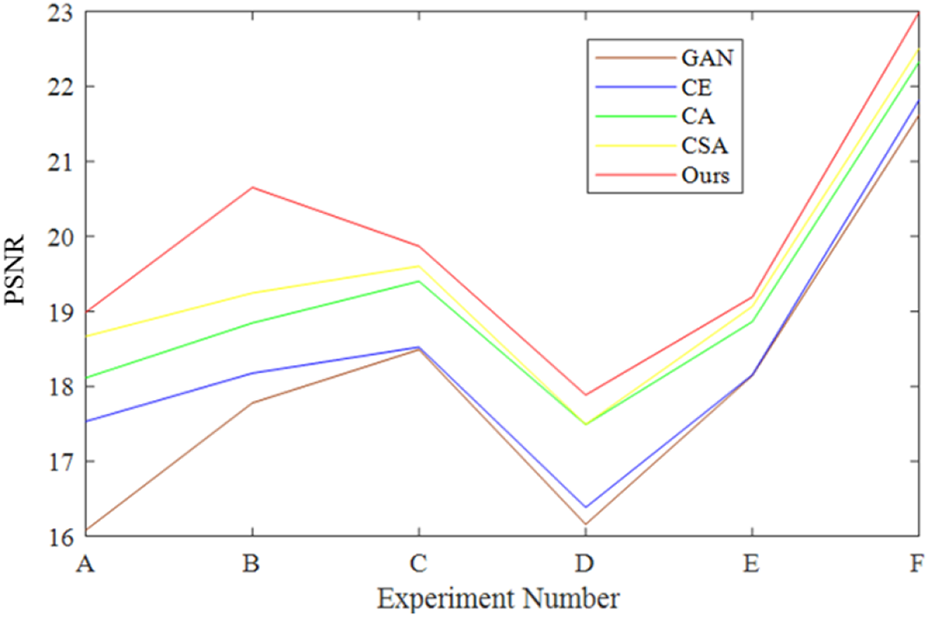
PSNR value line chart of each repair result of RUIE database. PSNR: peak signal-to-noise ratio; RUIE: real-world underwater image enhancement.
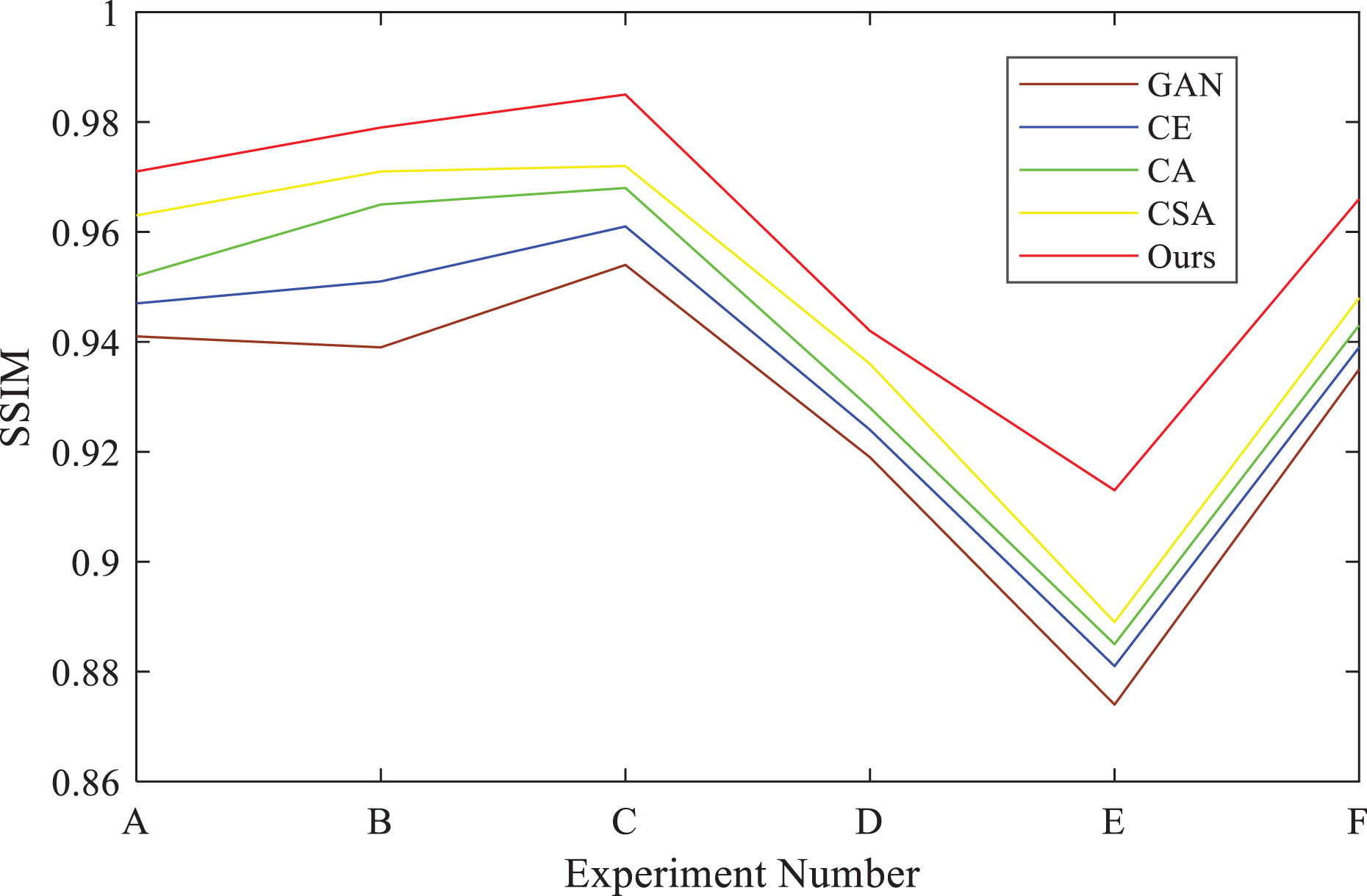
SSIM value line chart of each repair result of RUIE database. SSIM: structural similarity index; RUIE: real-world underwater image enhancement.
Algorithm verification
This article will further verify the repair model proposed in this article on the underwater target data set. The underwater target data set is a data set established by our team’s laboratory mainly for underwater images. It is of great significance in the research of underwater image processing. These include torpedoes, submarines, frogmen, AUVs, and other categories. It is currently under further construction and improvement. This article selects a large number of occluded or blurred torpedo, submarine, and AUV images from the underwater target data set for experiments and compares them with GAN, CE, CA, and CSA image reconstruction models. The simulation results are shown in Figure 10.

Repair results of each model in the underwater target data set. The experiment is aimed at the occlusion and blur phenomenon of underwater AUV and other targets and reconstructs the occlusion and blur area. The leftmost row of the figure is the input image, and the others are the reconstruction results of GAN, CE, CA, CSA, and ours image reconstruction models in order. AUV: autonomous underwater vehicle; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.
The simulation result is shown in Figure 10. The input in the leftmost column is the underwater image where the target feature is lost due to the occlusion of fish. The results of GAN and CE image reconstruction model reconstruction have the phenomenon of target loss. For example, the reconstruction results of experiment (A) and experiment (C) are not ideal. In experiment (C), although the reconstruction results of CA and CSA can reconstruct part of the contour, the result is not very satisfactory. The reconstruction algorithm proposed in this article can effectively reconstruct underwater targets.
The PSNR value of Figure 10 is shown in Table 5. It can be seen from the table that the reconstruction results of this model are better than other models. The PSNR values of experiment (D) and experiment (E) are significantly higher than those of experiment (A), experiment (B), and experiment (C). The SSIM values of Figure 10 are presented in Table 6. It can be seen from the table that the SSIM and PSNR values of the reconstruction results of this model are higher than those of other models, which show that underwater scenes have a great influence on underwater image reconstruction. Experimental data are displayed more intuitively with 3D histograms in this article. As shown in Figures 11 and 12, it can be seen from the simulation results that the reconstruction results of the proposed model are better than other models for comparison. No matter it is a qualitative comparison or a quantitative comparison, the proposed algorithm is superior than other comparative models, as for the underwater image reconstruction with missing target information.
SSIM values of the repair results in the underwater target data set.

SSIM: structural similarity index; GAN: generative adversarial network; CE: context encoder; CA: contextual attention; CSA: coherent semantic attention.

PSNR value of each repair result in the underwater target data set. PSNR: peak signal-to-noise ratio.

SSIM value of each repair result in the underwater target data set. SSIM: structural similarity index.
Conclusion
This article proposes an underwater image reconstruction algorithm based on environment feature fusion. Firstly, the significant features of the image are extracted by positive and negative sample learning. Secondly, the relevant information in the background is retrieved by the environmental attention mechanism. Finally, a coarse-to-fine underwater image restoration model is constructed to obtain fine restoration results. The test results show that the proposed algorithm has certain advantages in both qualitative and quantitative comparisons. However, proposed the algorithm has obvious shortcomings for the heavily obscured underwater objects. The performance of the algorithm will be further improved in future research work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is supported by the National Key Research and Development Project [2019YFB1311000], the Science and Technology Project of Henan Province [202102210302] and [182102210302], the Key Scientific Research Projects of the Institutions of Higher Education in Henan Province [21A520013], and the National Defense Science and Technology Innovation Special Zone.