
Abstract
Underwater robot plays an important role in underwater perception and manipulation tasks. Vision information processing is essential for the intelligent perception of an underwater robot, in which image matching is a fundamental topic. Feature-based image matching is suitable for the underwater environment. However, current underwater image matching usually directly applies those methods with a general purpose or designed for images obtained from the land to underwater images. The problem is that the blurring appearance caused feature descriptor ambiguity, which may greatly deteriorate the performance of these methods on underwater images. Aiming at problem, this article provides an underwater image matching framework by incorporating structural constraints. By integrating the appearance descriptor and structural information by a graph model, the feature correspondence-based image matching is formulated and solved by a graph matching method. Particularly, to solve the outlier feature problem, the graph matching method is applicable to the case where outlier features exist in both underwater images. Experiments on both synthetic points and real-world underwater images validate the effectiveness of the proposed method.
Introduction
It is widely accepted that underwater robots, for example, remotely operated underwater vehicle (ROV) and autonomous underwater vehicle, would play a more important role in underwater perception and manipulation tasks. 1 –3 For instance, one of our current projects is to study the potential of using underwater robots to grasp cultured creatures from the offshore seabed, under the background of increasing human labour cost and occupational disease risk. One key factor to realize this type of replacement of human by underwater robots is about its intelligent perception ability on the surrounding environment.
Similar to human, vision is also considered to be the most important part for an underwater robot to perceive the surrounding environment and to enhance its intelligent level because of the plenty information provided by visual data, for example, image sequences. This article focuses on the matching problem between underwater images. Image matching itself is a popular research topic in computer vision and pattern recognition communities, which aims to get the similarity between images or the similarity between objects of interests in different images. It lays the foundations for many high-level visual understanding tasks, such as image classification and retrieval, and it also plays an important role in underwater robot operations, such as underwater object recognition and robot hand–eye cooperation.
Earlier image matching methods usually took use of the image intensity by pixel wise operations. A typical instance is the famous correlation method, which treated the matching with the highest intensity correlation parameter as the final result by exhaust rotation and scale search. The main advantage of these methods is that the intuitive idea is easy to implement and test, but the disadvantages are also obvious. For instance, these methods are usually sensitive to illumination changes, object occlusions, geometric transformations and distortions and so on. And some of them are computationally expensive, especially when the high matching precision is needed or the images size becomes larger. Recent image matching methods usually resort to the visual features extracted from the images, especially the point features. In this context, image matching is realized by feature correspondence. With specific design, the feature extractor and descriptor could be robust to the changing factors, such as rotation, scale changes, illumination changes and so on. 4,5 Besides, since these features usually correspond to specific positions of the object, their number is to some extent robust to the image resolution, which is closely related to the image size. Based on these advantages, the feature correspondence-based image matching is successfully applied to natural images with artificial and inartificial objects and backgrounds, especially the images taken on the land. And a few researchers also apply it to underwater images. 6 –9
However, different from the common natural images, 10,11 the operations on the underwater images suffer from the inevitable blurring appearance, because that the limited light refracted into the water would further be scattered or absorbed by water molecules, plankton or sands. The blurring appearance leads to the ambiguity of feature descriptor, whose discriminant ability is decayed. And this phenomenon becomes the main obstacle for the feature correspondence between underwater images. For instance, some feature correspondence methods, for example, the scale-invariant feature transform (SIFT) feature, may totally fail when matching only the appearance descriptors.
To reduce the influence of feature descriptor ambiguity, it is intuitive to introduce additional information or incorporate additional constraints into the matching process. The structural information provides an effective tool to improve the descriptor matching, which can be treated as constraints to avoid abnormal feature assignments. Taking feature point matching for instance, if the distance between points, which is the most common type of structural information, is used to constrain the point matching, then two points close to each other in one feature set are less likely to be assigned to two points far away from each other in another feature set. From this perspective, incorporating structural constraints provides a feasible scheme for the feature-based underwater image matching problem.
Therefore, aiming to solve the blurring appearance caused descriptor ambiguity problem, in this article, we try to provide an underwater image matching framework by incorporating structural constraints. The key step in the framework is to integrate the appearance descriptor and structural information by a graph model, and then, the feature correspondence-based image matching is formulated and solved by a graph matching method. In the underwater environment, some tasks, for example, object recognition, can be solved by subgraph matching, where the input image contains certain outlier features, while the template images contain no outlier features. The outlier feature refers to a feature without a ground truth assignment in another feature set. However, in some other tasks, for example, hand–eye cooperation, both images may be obtained from the robot cameras, and therefore, outlier features may exist in both images. Therefore, the graph matching algorithm in the proposed framework should have the ability to match only the inlier features, which problem is a generalization of subgraph matching.
The remaining manuscript is organized as follows. The related works are discussed in ‘Related works’ section. The proposed underwater image matching framework is introduced in ‘Underwater image matching’ section. The experimental evaluation of the framework efficacy is given in ‘Experiments’ section, and finally, ‘Conclusion and future works’ section concludes this article.
Related works
The related works are discussed from three aspects, which are the methods based on direct appearance descriptor matching, the methods associated with structural cues and some similar applications.
Matching appearance descriptors
Many image matching algorithms directly match the appearance descriptors, which are built around each extracted key point. Some of them have even become the standard methods, or say the initial choice, for many image matching tasks.
The famous Harris corner point detector is one earliest type of local feature point extractor. It does not consider the descriptor construction, or the point coordinates are directly treated as the descriptor. The extracted points by the Harris detector are rotation invariant. The SIFT proposed by Lowe 4 beyond rotation invariance is further invariant to scale changes by carefully designing a complex descriptor around each extracted point. It is considered to be a milestone in the field of local features and becomes the initial choice of many computer vision engineers when using point extractor or descriptor in many fields, such as image registration and reconstruction. The main drawback of SIFT is its high computational expense, and quite a number of methods try to improve it by simplifying its complex extractor and descriptor, such as the principal component analysis-SIFT, 12 gradient location orientation histogram 13 and the well-known speeded up robust feature (SURF). 14 Particularly, SURF even achieve comparable performance with SIFT besides its considerable reduction of running time, which may be attributed to its more distinctive descriptor. Therefore, researchers further propose many variants based on SURF. Shape context descriptor proposed by Belongie and Malik 5 forms another type of feature point descriptor. Unlike the above descriptors, which construct a complex descriptor based on the appearance information, for example, pixel gray level, in the small region around each point, the shape context descriptor is constructed based on the distribution of the remaining points around each point. This descriptor is simple and effective, which is successfully used in, for instance, object recognition and retrieval.
Incorporating structure cues
It is explained in ‘Introduction’ section that incorporating structural constraints may be useful for the underwater image matching problem, and actually, only the structural information without the above point descriptor is sometimes adequate for the matching. From this view, some recently related works are introduced.
One recent important algorithm integrating point descriptors and structural cues is proposed by Berg et al., 15 which formulates feature point correspondence by integer quadratic programming. Its objective function consists of two terms, with the unary term measuring the difference between the so-called geometric blur point descriptors and the pairwise term measuring the geometric distortion between feature point pairs. The objective function is optimized by the gradient descent-based method. Later, aiming at a similar objective function, Leordeanu and Hebert 16 proposed a famous spectral decomposition method, where the original objective function is relaxed to be a Rayleigh quotient maximization problem, 17,18 which further improved this idea from different aspects. On the other way, Torresani et al. 19 extended 15 by introducing new pairwise terms in the objective function besides the term measuring geometric distortions. For instance, a coherence term is added inspired by the prior knowledge that matched feature points should spatially coherently locate in the image pair, which implies that they may be both in the object part or in the background part. Then, the extended objective function is approximately solved by a dual decomposition scheme. Similar objective function is adopted by Yarkony et al. 20 and Yang et al. 21
The above methods take both appearance information and structural cues into consideration. However, they usually resort to continuous quadratic programming techniques to approximately optimize the objective function, and then push the continuous solution to the discrete domain by a final hard-cut projection. Such a scheme does not always result in a better performance than using only feature point descriptor, 22 which is because that the correspondence between points is essentially a combinatorial optimization problem. Inspired by this observation, in the past decade, researchers have tried to incorporate the discrete property in the optimization process, which significantly improves the matching performance. The idea is to some extent similar to the famous graduated assignment algorithm. 23 Two recent leading algorithms are the integer projection fixed point 24 and the path following algorithm. 25 Furthermore, this idea has attracted much attention, and some representative algorithms include the factorized graph matching algorithm, 26 the reweighted random walk matching algorithm 27 and the graduated nonconvexity and concavity procedure (GNCCP). 28 However, these algorithms are limited to the form of the assignment matrix which is used to mathematically represent the correspondence between points and could not deal with case where outlier points exist in both images. To address this problem, we previously proposed a method 29,30 which could match the most similar subgraphs with specified size, which is generalized in this article.
Similar applications
There have been some progress on the research of underwater image matching problem. Leone et al. 6 used an improved variant of Harris corner point detector to extract the interest points, that is, the feature points on the underwater images, and then computed the correspondence between points by matching texture-based feature descriptors. Elibol et al. 7 used the SIFT as the initial feature point matching result of the underwater images, followed by the widely used random sample consensus (RANSAC) technique to reject outlier assignments. Ferreira et al. 8 matched two types of features in the ROV real-time mosaicing task. The first one is the binary robust independent elementary features (BRIEFs) used to estimate the real-time motion of ROV, and the second one is SURF used in the mosaicing problem. Garcia-Fidalgo et al. 9 in the mosaicing task used a type of binary feature called oriented fast and rotated BRIEF based on the bags of words (BoWs) scheme.
These methods only match the feature point descriptors, and usually suffer from the blurring appearance of underwater images, especially those shot in the offshore underwater environment. As far as we know, the method proposed in this article is the first one to incorporate structural information into underwater image matching.
Underwater image matching
In this section, the proposed underwater image matching framework is introduced, in which the key step is to integrate the appearance descriptor and structural information by a graph model. From this perspective, the framework consists of four parts, that is, the preprocessing step, graph construction, graph matching model and optimization and the postprocessing step, as illustrated in Figure 1.

Underwater image matching framework. The key step is the graph matching model and optimization, which is shown in gray.
Preprocessing
In the preprocessing step, the underwater image is first processed by certain low-level computer vision operations for easier subsequent processing. Compared with images on the land, the underwater image generally has low quality with many noisy pixels because of the bad illumination environment and moving robot mounted camera. We apply two main low-level operations to these images. The first operation is image de-noising to reduce the influence of noisy pixels, which is followed by the image enhancement operation to make these images more distinctive. Considering the computational power and time available on the underwater robot, only basic methods for these two operations are used, which are both based on the basic spatial convolution. 31
After the above operations, the image is then represented by a type of feature point. There are many choices for the feature point, such as SIFT, SUFR, BoWand so on. However, as explained in ‘Introduction’ section, their complex appearance extractors and descriptors are not suitable for the underwater images. Thanks to the incorporation of structural constraints, the design of the feature extractor and descriptor is no longer the determinant factor for the matching result, which offers an opportunity to use some simple but efficient extractors and descriptors, such as the Harris corner point detector and shape context descriptor. After obtaining the feature points, underwater image matching is transformed to the feature point correspondence problem, which aims to find an optimal set of assignments between feature points in two images. In this article, the point correspondence is modelled and optimized by graph matching, before which we would introduce how to represent a feature set by a graph below.
Graph construction
Graph has a powerful representation ability, especially for structural data. When a feature set
Graph matching model
By representing the two feature point sets G and

If the above case is generalized to that outliers exist in at most one graph, which implies that the two graphs have different sizes, for example, M < N, then the assignment matrix becomes the so-called partial permutation matrix defined by

However, as mentioned in ‘Introduction’ section, there may be outlier feature points in both images to be matched or, in other words, outlier vertices in both graphs. To tackle this case, we previously 29 proposed a type of assignment matrix by generalizing the above partial permutation matrix, which takes the following form
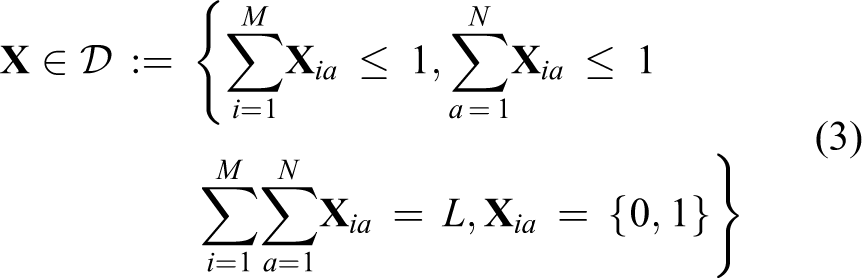
In this matrix, the integer constant L indicates the number of assignments. It is usually pre-specified according to the prior knowledge or the approximate estimation of the inlier feature points.
The correspondence between the inlier vertices can be explained by finding the most similar subgraphs in two given graphs. Based on the above assignment matrix form, the problem can be formulated by maximizing the following objective function

where

and

The operator ∥ ⋅ ∥ denotes the L2 norm of a vector. The constants σV and σE are the kernel width parameters.
When

because
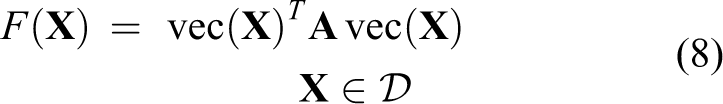
The similarity matrix

Thus, the feature point correspondence problem can be solved by maximizing the objective function (equation (8)). However, because of its quadratic combinatorial form, the optimization problem is NP-complete. Therefore, approximations are necessary in the optimization process to get a local optimum in reasonable time, which will be introduced below.
Graph matching optimization
We generalize the GNCCP-based optimization technique 28,30 to approximately maximize the objective function (equation (8)). The GNCCP belongs to a type of continuous methods. Most of the current continuous methods first relax the original combinatorial optimization problem to be a continuous one, and then directly project the continuous solution to be a discrete one. However, the ‘hard-cut’ projection introduces significant additional error, because the continuous solution and discrete solution by the ‘hard cut’ projection are not closely related, or in other words, a good continuous solution does not necessarily result in a good discrete solution. Different from these continuous methods, the GNCCP gradually projects the continuous solution back to the discrete domain under the supervision of the objective function and achieves significant performance improvements on graph matching problems. 28 –30
Specifically, the GNCCP first relaxes the discrete domain to its convex hull and requires that the discrete domain is exactly the extreme point set of its convex hull. Fortunately, the convex hull exists for the discrete domain

In the continuous domain, that is, the above convex hull, the GNCCP optimizes the following objective function (equation (11)) instead of the original objective function (equation (8))


This objective function has the same optimum as equation (8) in the discrete domain

and its matrix form can be obtained by an inverse vectorization operation.
The optimization process is summarized in Algorithm 1. For more theoretical analysis and implementation details, please refer to the works of Liu and Qiao 28 and Yang et al. 29,30

graph matching optimization.
Postprocessing
A specified number of assignments between vertices are obtained when the graph matching optimization process terminates. Although most outlier vertices are abandoned by the above graph matching scheme, it is inevitable that certain outlier vertices are left in the coarse matching result, because the specified number L is only an estimation of inlier number. To get a robust matching result, in the postprocessing step, the RANSAC technique is used to refine the assignments. Note that, in some tasks, it is often needed to obtain a small set of robust inlier assignments rather than a complete set of inlier assignments. For instance, when feature point correspondence is applied to the robot localization task, the relative position could be figured out by only four accurate assignments. In these tasks, the assignment refinement is effective. Despite the usage of the RANSAC technique, the above graph matching algorithm for the case when outlier points exist in both graphs still makes sense. Because when the number of outlier vertices is large, without the removal of outlier vertices by the graph matching algorithm, the inlier assignments would be submerged by the outlier assignments, which may invalidate the final outlier assignment refinement.
Experiments
The proposed method is experimentally evaluated by comparing it with some state-of-the-art methods. Not all the recent graph matching algorithms are applicable to the case when outliers exist in both graphs; therefore, the graph matching algorithms included for comparison in this article all involve a soft (continuous) matching solution before a final projection to the discrete domain. Although they are not directly applicable to the above case, the generalization is straightforward by selecting L assignments with the largest assignment confidence, which usually refers to the continuous value associated with an assignment. Specifically, these algorithms include spectral matching (SM), 16 graduated assignment (GA), 23 and probabilistic graph matching (PGM). 18 The proposed method is denoted by OUR. The experiments are carried out on both synthetic points and real-world underwater images.
Synthetic points
Two point sets with ground truth assignments are generated in a way similar to the works of Egozi et al.
18
and Yang et al.
30
First, the point sets

where η denotes the additive Gaussian noise. The vertex is not labelled in order to fairly evaluate the effectiveness of structural constraints. The graph structures are built by random connection with the edge density of 0.1. It is also disturbed by randomly adding and removing some edges σ ∥ EG ∥ following the way proposed by Zaslavskiy et al., 25 where ∥ EG ∥ denotes the edge number. The distance between key points is used as the edge weight. In this experiment, L is set to be equal to the number of ground truth assignments, which is 20. Therefore, the outlier assignment refinement in the postprocessing step is not needed. Besides, it is set that M = L + #outliers and M = L + 2#outliers, where #outlier denotes the outlier point number. The kernel width parameters are set to be σV = 0.15 and σE = 0.15.
Two groups of simulations are performed. The first group evaluates the performance with respect to the noise level σ which is increased from 0 to 0.1 by a step size of 0.01, and it is set that #outliers = 5. The second group evaluates the performance with respect to #outliers which is increased from 0 to 10 by a step size of 1, and it is set that σ = 0.1.
The matching accuracy is compared in Figure 2, where accuracy refers to the ratio between the number of correct assignments and the number of the selected assignments. Generally, it can be observed that the performances of all the algorithms decrease when the noise level σ increases and also when the outlier number increases. The proposed method achieves the best performance for the most time in both groups of simulations. An interesting observation is the superiority of OUR when #outliers is larger than 2, which validates the effectiveness of the proposed algorithm against outlier points.

Experimental results on synthetic points.
Underwater images
The proposed method is also applied to a real-world underwater image sequence, which is sampled from a video clip shot by a handheld camera at the Valldemossa harbour seabed (Mallorca, Spain). 9 There are nine image pairs selected from the sequence, which are then manually labeled with 20 ground truth key points and 10 outlier key points, as illustrated in Figure 3. The shape context descriptor 5 is used as the feature point descriptor, that is, the vertex label, and the weight parameter is set to be α = 0.5. The graph structure is built by the Delaunay triangulation technique. The length and orientation of edge are used as its weight. The parameters are set as follows: L = 25, M = N = 30, σV = 0.15 and σE = 0.15. Note that, in this experiment, L is not equal to the number of ground truth assignments. And the outlier assignment refinement by the RANSAC is used.

Underwater image pair samples. The ground truth key points are in red, the outlier key points are in blue and the graph structures are in yellow.
The average matching accuracy of the nine image pairs is compared in Table 1, from which we can observe the superior performance of the proposed method. Some typical matching instances are given in Figure 4. Note that, the number of assignments, which is 17 in Figure 4, is smaller than L, which is caused by the outlier assignment refinement operation.
Average matching accuracy (%) on real-world underwater images.

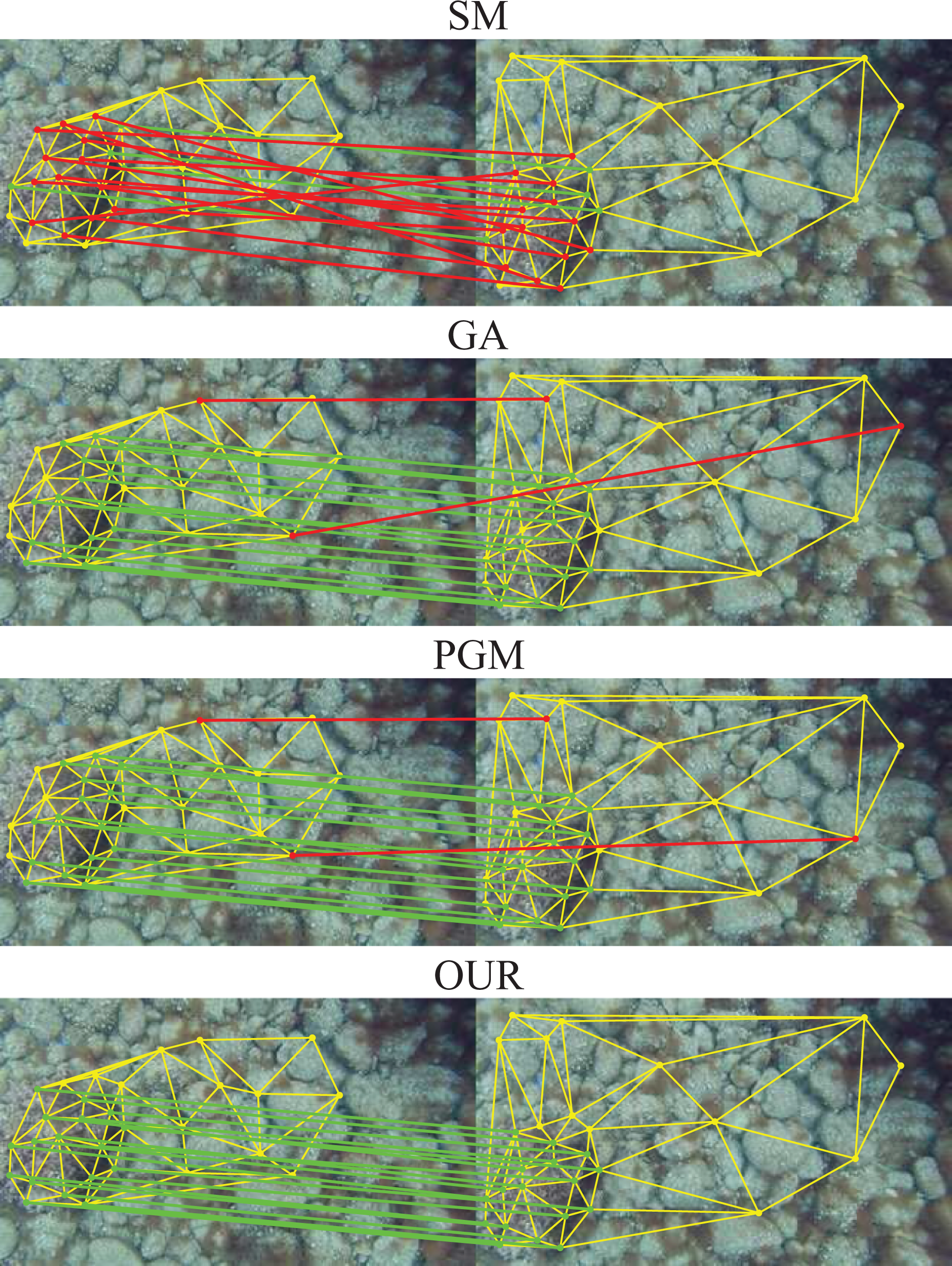
Typical underwater image matching instances by different algorithms. The correct assignments are shown in green, the incorrect ones are shown in red and the graph structures are shown in yellow.
Conclusion and future works
This article proposes an underwater image matching framework by incorporating structural constraints. The major advantage of the proposed scheme lies in its resistent to the feature descriptor ambiguity problem caused by the blurring appearance of the underwater images. One of our future works is to generalize the proposed image matching framework to some typical underwater image processing tasks, such as image stitching, or underwater robot operations, such as vision-based object grasping.
Footnotes
Acknowledgement
The authors would like to thank the graduate student Feng-Yi Zhang for his help in the experiment data set preparation.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported partly by the National Natural Science Foundation of China (grant nos 61503383, 61633009, U1613213, 61375005, 61210009 and 61773047), partly by the National Key Research and Development Plan of China (grant no. 2016YFC0300801), partly by the Beijing Municipal Science and Technology (grant nos D16110400140000 and D161100001416001) and the Guangdong Science and Technology Department (grant no. 2016B090910001).