
Abstract
Simultaneous localization and mapping (SLAM) problem has been extensively studied by researchers in the field of robotics, however, conventional approaches in mapping assume a static environment. The static assumption is valid only in a small region, and it limits the application of visual SLAM in dynamic environments. The recently proposed state-of-the-art SLAM solutions for dynamic environments use different semantic segmentation methods such as mask R-CNN and SegNet; however, these frameworks are based on a sparse mapping framework (ORBSLAM). In addition, segmentation process increases the computational power, which makes these SLAM algorithms unsuitable for real-time mapping. Therefore, there is no effective dense RGB-D SLAM method for real-world unstructured and dynamic environments. In this study, we propose a novel real-time dense SLAM method for dynamic environments, where 3D reconstruction error is manipulated for identification of static and dynamic classes having generalized Gaussian distribution. Our proposed approach requires neither explicit object tracking nor object classifier, which makes it robust to any type of moving object and suitable for real-time mapping. Our method eliminates the repeated views and uses consistent data that enhance the performance of volumetric fusion. For completeness, we compare our proposed method using different types of high dynamic dataset, which are publicly available, to demonstrate the versatility and robustness of our approach. Experiments show that its tracking performance is better than other dense and dynamic SLAM approaches.
Introduction
Simultaneous localization and mapping (SLAM) is to produce a consistent map of environment and to estimate the pose in the map using noisy range sensor measurements. SLAM problem has been extensively studied by researchers in the field of robotics. After the appearance of Kinect, there are many solutions, which fuse the color image and depth map. Visual SLAM produces a sparse solution by relying on points matching, whereas direct methods can produce a dense reconstruction by minimization of the photometric error. However, none of the above methods addresses the problem of dynamic objects in the environment.
Conventional approaches in mapping assume that the environment is static. Although the static assumptions are valid in a small region, change is inevitable when dynamic elements exist or large-scale mapping is necessary. By classifying dynamic content as outliers, a small fraction can be managed. However, SLAM problem in highly dynamic scenes is still not solved completely because there is no suggested framework found in the literature.
Another biggest difficulty in robot navigation is unstructured environment. In unstructured environments, it is not easy to find discrete geometries because of noisy edge or plane. Significant research has been carried out for unstructured environments, especially in the field of autonomous navigation, and a number of effective approaches have been developed using laser range finder. However, there is no effective RGB-D SLAM method for real-world unstructured and dynamic environments.
In this study, we propose DUDMap (see https://www.dropbox.com/s/lsexrz82ewdzo0w/DUDMAP_sample.mp4?dl=0): dense, unstructured, and dynamic mapping. Our approach requires neither explicit object tracking and object classifier nor purely geometric method in contrast to recent approaches discussed by Yu et al. 1 and Taneja et al., 2 which makes it robust to any type of moving object. Furthermore, we assume a dynamic environment consisting of static and dynamic classes having generalized Gaussian distribution to detect dynamics. We reconstruct scene geometry using signed distance function (SDF) instead of surfels. This makes our method to easily create a dense final mesh and such representation is useful in robotic applications because it defines the distance to surface.
The main contribution of this article is a novel and an effective SDF-based SLAM algorithm that is resistant to dynamics and also the following: We identify the dynamics using image registration residual combining with Gaussian mixture model. The number of dynamic objects does not limit our approach because we do not employ any type of moving object detection and tracking. Our method generates a final intense 3D mesh without using semantic information or object classifier. We eliminate repeated views and use only consistent data for decreasing the required computational power. We compare our method with other state-of-the-art systems using TUM dataset,
3
together with other high dynamic datasets including Bonn,
4
VolumeDeform,
5
and CVSSP RGB-D dataset
41
(used with permission), which are publicly available, showing the superior performance of our approach. To evaluate the outdoor performance of our method, we use commercially available ZED camera for map generation and dynamic filtering. Experiments illustrate that our method produces consistent result both in indoor and outdoor applications. These are demonstrations of real-world unstructured dynamic environments of our approach.
The rest of this article is organized as follows. The second section reviews state-of the-art visual SLAM methods that attack the problem of dynamic environments. The third section is devoted to the overall structure of our system by giving details about proposed approaches for local keyframe extraction and dynamic removal. The fourth section shows the experiments conducted and gives the evaluation result by comparing our method against other state-of-the-art methods, whereas the fifth section provides concluding remarks.
State-of-the-art methods
ORB-SLAM2 7 (latest version ORB-SLAM3 8 ), S-PTAM, 9 and RTAB-Map 10 are the best state-of-the-art feature-based visual SLAM approaches in static environments. To increase the performance of such feature-based method in dynamic environment, dynamic objects are considered generally as spurious data, and dynamic object is removed as outliers using RANdom SAmple Consensus (RANSAC) and robust cost function. On the other hand, targeted attempts are still being made to increase performance in dynamic scenes. For instance, DVO-SLAM 11 uses photometric and depth errors instead of visual features. The joint visual odometry scene flow 12 proposes an efficient solution to estimate the camera motion. However, odometry-based methods either cannot recover from inaccurate image registration or lacks a loop closure detection approach independent of pose estimate.
SDFs have long been studied to represent the 3D volumes in computer graphics. 13 –15 Newcombe et al. 38 proposed the SDF-based RGB-D mapping by generating precise maps in static environments. Elastic fusion (EF) 16 is another method based on SDF, which can work in small scenarios. CoFusion (CF) 17 is a contemporary method for reconstructing several moving objects, however, it works with slow camera motions only and its performance deteriorates significantly with increasing camera speed. Static fusion (SF) 18 simultaneously estimates the camera motion together with dynamic segmentation of the image. However, it works only sequences without having high dynamics at the beginning. Palazzolo et al. 4 propose refusion, where dynamics detection is done using the residuals obtained from the registration on SDF. This approach can create a consistent mesh of the environment, however, highly dynamical change deteriorates mapping performance.
Some methods use motion consistency to validate tracked points, where dynamic objects are segmented generally as spurious data since they conflict with the motion consistency of background over consecutive frames. For instance, Wang and Huang 19 segment dynamic objects using RGB optical flow. Nevertheless, the algorithm is still not robust enough for TUM high dynamic scenarios. Kim and Kim 20 propose to use the difference between depth images to eliminate the dynamics in the scene. However, this algorithm requires an optimized background estimator suitable for parallel processing. Azartash et al. 21 use the image segmentation for discrimination of the moving region from the static background. Experimental results show that the accuracy remains almost the same in low dynamic scenarios. Tan et al. 22 use an adaptive RANSAC for removing outliers. This method can work in dynamic situations with a limited number of slowly moving objects.
Other methods use classifiers to identify the dynamic objects. Kitt et al. 23 combine the motion estimation with object detection; however, this method requires a classifier, which makes this method inapplicable to online explorations. Bescos et al. 24 propose DynaSLAM, which combines a prior learning by mask region-based convolutional neural network (R-CNN) 25 and multiview geometry to segment dynamic content. Multiview geometry consists of region growth algorithm, which makes it unsuitable for real-time operation even running on NVIDIA Titan GPU. Mask fusion 26 also uses mask R-CNN for semantic segmentation. DS SLAM, 27 RDS-SLAM, 28 and semantic SLAM 29 are other semantic-based algorithms, which use the SegNet. 1 Pose fusion, 30 implemented on EF, uses open pose CNN 31 for human pose detection, which limits this method in the nonhuman dynamic object scenes. Flow fusion 32 uses optical flow residuals with PWC-Net 33 for dynamic and static human objects. However, such approaches are relying heavily on prior training methods. Therefore, if an unlearned dynamic occurs in camera view, estimation results are bigger. Furthermore, learning-based semantic information is time-consuming with heavy computational burden.
In our work, we reconstruct our scene geometry using SDF instead of surfels in contrast to EF and SF, and therefore, we can directly generate the mesh of the environment using such representation without using object tracking and object classifier. Moreover, a number of dynamic objects or their speeds do not limit our approach.
Our proposed methodology
Preliminaries and notations
In our approach, we denote a 3D point as [X, Y, Z]∈R 3, rotation of the camera, and translation R∈SO(3), T∈R 3, respectively. At time t, RGB-D frame contains an RGB image and a depth map. The homogenous point X = (x, y, z,1)T can be computed by assuming a pinhole camera model with intrinsic parameters fx , fy , cx , and cy (focal length and optical center) such as
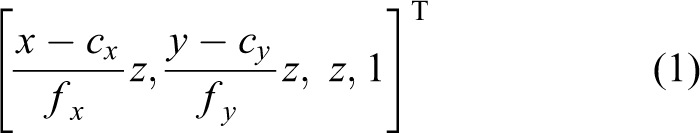
The 3D point corresponding to a pixel is reconstructed as

In rigid body motion, the common representation matrix H consisting of a 3 × 3 rotation matrix and 3 × 1 translation vector T
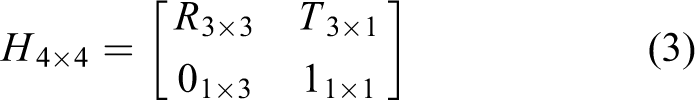
is used in the transformation of a point

The rotation matrix R has nine parameters and if we were to estimate the camera motion, we have to solve these nine parameters by forming a constrained optimization problem, which can be very slow to implement. The Lie algebra allows us lower dimensional linear space for rigid body motion representation, making it popular in computer vision problems.
We use a Lie algebra SE(3) representation as twist coordinates ξ as in the literature 34 because the rigid motion has six degrees of freedom while transformation matrix T has 12 parameters. Using the Lie algebra representation, rigid body motion can be written as

Figure 1 depicts the important steps of our proposed method. We first apply a depth filter to eliminate significant amounts of noise in raw depth images. To eliminate redundant data in fusion process, we trim repeated camera views by measuring the similarity ratio of RGB images. We then perform pose estimation and continue the process by detecting the dynamic elements in the scene. The subsequent subsections provide the details of each block in our proposed system.

Our proposed scheme.
Depth smoothing and feature matching
Commercially available RGB-D cameras usually produce invalid depth measurements. In addition, there exist significant amounts of noise in raw depth images. In this study, we use a depth adaptive bilateral filtering 42 method because it modifies the weighting to account for variation of intensity. Figure 2 depicts the original depth image, smoothed image, and filtered image, respectively. In addition, we change the zero values in the original depth images by neighboring 5 × 5 pixel mean value in smoothing process.

(a) Original image, (b) smoothed image, and (c) filtered image.
SDF fusion is an averaging process, therefore, it is important not to use redundant data in the fusion process because small error makes the SDF model as unclear. To eliminate redundant camera views, we perform similarity ratio test based on feature matching. A typical feature matcher consists of the following steps: extracting local feature, matching features using nearest-neighbor approach, and selecting good correspondences.
In the literature, scale-invariant feature transform (SIFT) is being proposed for extracting keypoints and widely used in different applications. SIFT feature-matching works well for scaled images but fails some cases such as faces with pose changes. 36 Application of feature matching method FLANN with SIFT descriptor overcomes such disadvantages of SIFT. In similarity analysis, we use FLANN-based feature matching with SIFT descriptor and we use RATIO 37 to select good correspondences that compare the lowest feature distance and the second lowest feature distance for recognizing good ones. Similarity ratio of the VolumeDeform “boxing” sequence is depicted in Figure 3. Since the ratio is not high, which indicates low degree similarity, all the frames are included in the mapping process. On the other hand, BONN dataset “crowd2” sequence is a high dynamic sequence having 895 frames. If 80% similarity threshold is utilized, 78 frames are skipped, which results in 8.7% decrease in computational time. Absolute translational error increases only 2.2%, while rotational relative pose error increases by 0.3%. In low dynamic sequences, the number of similar frames will be higher, which decreases the unnecessary computational power. This is the novel enhancement we provide to existing methods in the literature for the betterment of the performance. We use the 80% similarity threshold.

VolumeDeform boxing sequence similarity ratio.
Pose estimation
We can represent the geometry using SDF. To reconstruct the scene, we fuse incrementally RGB-D data into SDF and geometry is stored in voxel grid (see Figure 4 for SDF calculation). First, camera pose is estimated using SDF, and SDF is updated based on newly computed camera pose. In the literature, most of the volumetric fusion techniques, for example, KinectFusion 13 use synthetic depth images and align them using iterative closest point. However, we use the camera pose directly on the SDF because SDF encrypts the 3D geometry of the environment.

Illustration of SDF calculation and zero SDF function on the surface (grids represent the voxel border). SDF: signed distance function.
Assuming independent and identical distributed pixels with Gaussian noise in depth values, the likelihood of observing a depth image is

To find the camera poses that maximize this likelihood, we define a pose error function as

A rigid-body motion can be described in Lie algebra with the 6D twist coordinates

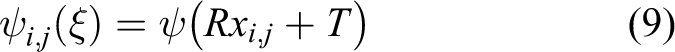
If image registration is correct with the 3D model, the projected colors should be consistent as well. We incorporate this condition by adding an extra term. Since there is no absolute reference of the image for comparison, color value stored in the voxels is used. Using color intensities of the pixels and corresponding voxels, the error function becomes

The joint error function is given in equation (11) with υ intensity contribution with respect to the depth

and start by linearizing ψ around initial pose estimate

In equation (12),

where

Algorithm 1 summarizes the pose estimation process.
Pose estimation algorithm.


We solve equation (14) iteratively until difference (
Signed distance function representation and 3D reconstruction
We use the discrete voxel grid to represent the SDF. Signed-distance value is calculated by trilinear interpolation of eight neighboring pixels. We project each voxel onto the image plane instead of ray casting because this process is suitable for parallel processing since each voxel is independent of its neighbors. Since the operation has to be carried out for each voxel, GPU is used for this operation. Finally, we implement marching cubes algorithm 35 to extract the triangle mesh. In RGB-D mapping approaches, storing the SDF in a 3D grid requires a large amount of memory. Therefore, we use a special memory allocation technique proposed by Nießner et al. 39 In this technique, we only allocate the voxels in required areas, which enable to scan the large areas with limited memory.
Dynamic detection
Let Im and Is be the instantaneous image of the generated model and source, respectively. The error in color map denoted by ec as

If the images Im and Is are accurately registered and if there is no change in the geometry, the resulting error would be zero (Figure 5). In general, minimizing equation (15) results in a sufficient image registration. SDF represents the distance to the nearest surface, and therefore, we select to use SDF as an error function. The error in the depth can be written as


Inconsistency map of two images (EPFL RGB-D pedestrian dataset sequence frame 250 and 278).
In equation (16), N is the pixel number,
After performing an initial registration using equation (15), we compute for each pixel and its residual as defined in equation (17)

The residual obtained after image registration is used as for dynamic detection (Figure 6). Our aim is to compute the binary labeling for each element according to occurred changes. For example, li = 0 indicates consistency and li = 1 shows the presence of change in corresponding voxel i.

(a) RGB image, (b) reconstruction error, and (c) dynamic label image.
If h(d) be the histogram of the image, our problem is in the form of binary classification problem using a dynamic label threshold. Then, probability density function can be defined as the combination of two density functions related class label as

using class conditional densities and prior probabilities. To calculate an estimate of dynamic change, we maximize p(l|D)

where

The final log-likelihood function is in the form of

In equation (21), u(d) is the indication of static or dynamic component.
After dynamic label identification and updating the label grid (Algorithm 2), a second pose estimation and registration are performed using newly obtained label set (Algorithm 3). However, we must filter out dynamic labels that originated from noise. We compare the SDF value of new observation with the previous static reconstruction and compute the difference

Figure 7 shows the overall flowchart of our proposed methodology including RGB similarity check, pose estimation, and dynamic detection.
Dynamic labeling algorithm.


DUDMap.


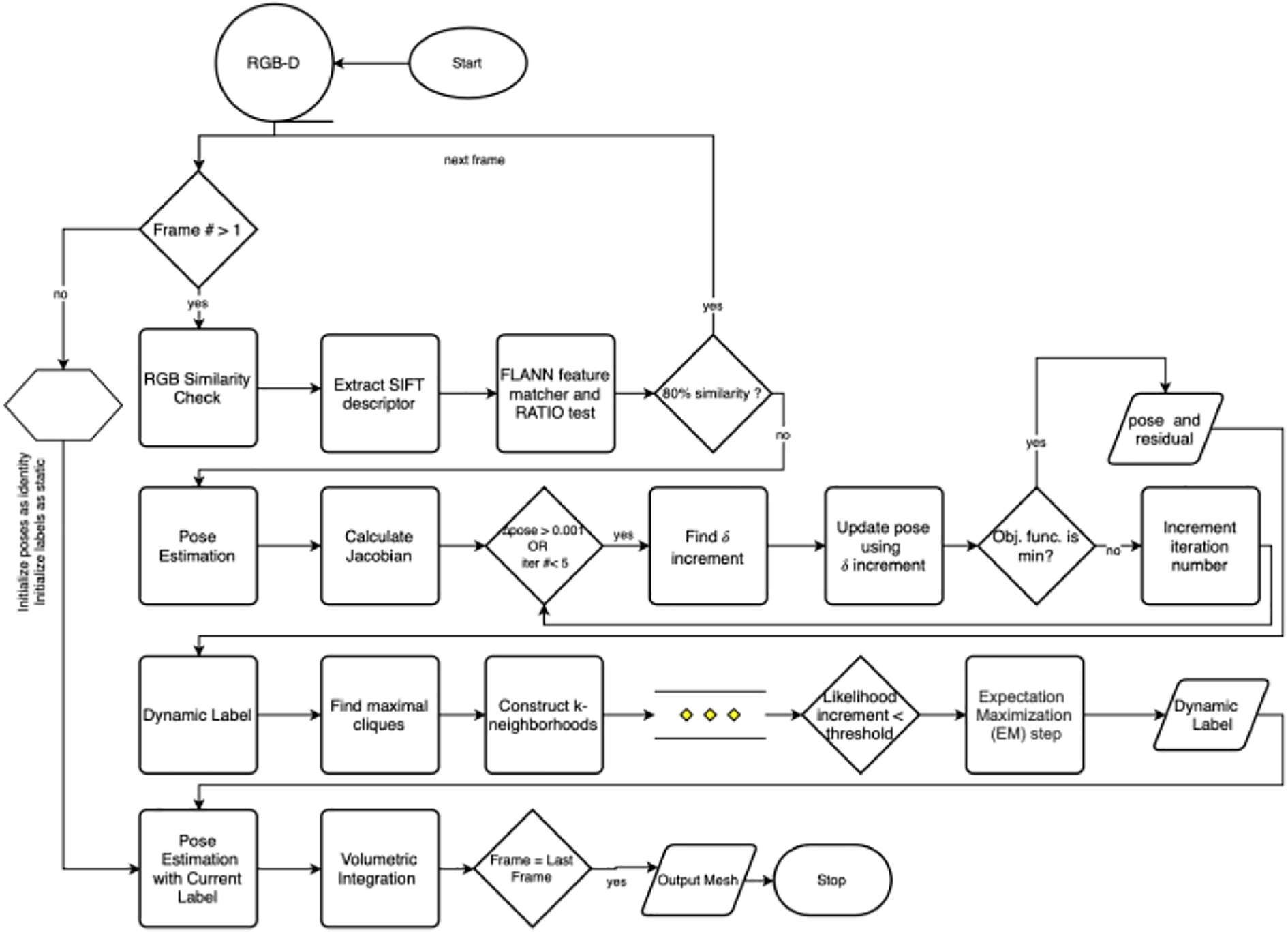
Flowchart of the proposed algorithm,DUDMap.
Experiments
Our proposed method is able to operate in dynamic environments without requiring any dynamic object detection and tracking. Our experiments support our main claims, which are as follows: Robustness to dynamic elements regardless of their quantity and speed of change in the environment. That approach requires no explicit object tracking, object classifier and generate a consistent a dense model of the environment.
The experiments were conducted on a workstation computer Intel i7 running at 3.20 GHz and a GeForce 1070 GPU using Ubuntu 16.04. Our default parameters have been determined empirically so that a sensitivity analysis is performed on change of parameters.

ATE/RPE of TUM fr3/walking static sequence. ATE: absolute trajectory error; RPE: relative pose error.
TUM RGB-D dataset
In this dataset, walking sequences are highly dynamic and complex because moving objects cover almost all camera views. Sitting sequence is low dynamic and there exists a person sitting and moving their arms. In this dataset, the evaluation is performed through the metrics proposed by Sturm et al. 3 as translational, rotational relative pose error (RPE), and translational absolute trajectory error (ATE). Obtained results of dense visual SLAM methods are listed in Tables 1 to 3. In the TUM dataset, the ground-truth trajectory is obtained from a high-accuracy motion-capture system with eight high-speed tracking cameras (100 Hz). Therefore, quantitative evaluation is possible regarding the accuracy of pose estimation. However, TUM dataset has no exact 3D model of the environment, therefore, we can evaluate the 3D reconstruction performance results of our method qualitatively. Qualitative results are shown in Figures 9, 11, and 12. Figure 12 also shows the scene reconstruction result of fr3/walking xyz sequence obtained using EF, DynaSLAM, and DS-SLAM.
TUM dataset—translational RPE (RMSE, cm/s).

VO-SF: visual odometry scene flow; EF: elastic fusion; SF: static fusion; CF: CoFusion; RMSE: root mean square error; CNN: convolutional neural network; RPE: relative pose error.
a Mean value excluding sit/xyz, all methods are given with corresponding paper in the reference set.
TUM dataset—translational RPE (RMSE, °/s).

VO-SF: visual odometry scene flow; EF: elastic fusion; SF: static fusion; CF: CoFusion; RMSE: root mean square error; CNN: convolutional neural network.
a Mean value excluding sit/xyz, all methods are given with corresponding paper in the reference set.
TUM dataset—translational ATE (RMSE, cm).

VO-SF: visual odometry scene flow; EF: elastic fusion; SF: static fusion; CF: CoFusion; ATE: absolute trajectory error; RPE: relative pose error; RMSE: root mean square error.
a Mean value excluding sit/xyz, all methods are given with corresponding paper in the reference set.

Mesh of TUM fr3/walking static sequence.

ATE/RPE of TUM fr3/walking halfsphere sequence. ATE: absolute trajectory error; RPE: relative pose error.

Mesh of TUM fr3/walking halfsphere sequence.

Scene reconstruction of fr3/walking xyz sequence.
As given in Table 1, our proposed scheme achieves an average translation RPE of 0.045 m/s, which is considerably lower than other dense methods such as VOSF, EF, SF, and mask fusion. Our aim is to develop a dense RGB-D SLAM algorithm without using high computational power in dynamic environments. According to Tables 1 to 3, our method achieves smaller relative and translational error than other dense methods. For all high dynamic sequences, our method reaches the lowest RPEs except for the “fr3/walk stat” sequence. In a highly dynamic scene, our proposed method produces better results for the following reasons:
EF is not capable of dynamics in the sequences. Hence, dynamic object deteriorates the 3D mesh and pose estimation. CF works well for slow camera motions but its performance deteriorates noticeably when the speed of the camera increases. SF works sequences with limited dynamics at the beginning, and therefore, it produces large errors on a highly dynamic environment. In general, existing high dynamics in the scene leads to blurry motion in the image, resulting inconsistent mesh.
In addition, according to Tables 1 to 3, there is no doubt that semantic-based visual SLAM methods have better results in ATE and RPE criteria. However, such method does not provide a dense model and it is relying heavily on the prior result from the learning techniques. If an unlearned condition exists in the camera view, the estimation result is highly influenced.
Table 4 compares the execution time of our proposed method with semantic-based SLAM algorithms. Most of the modern segmentation-based SLAM methods are built on ORBSLAM, therefore, it is included in timing analysis. The execution time data are obtained from the corresponding published papers. DynaSLAM has a good tracking performance, however, mask R-CNN makes this method unsuitable for real-time operation.
TUM dataset—execution time.

If a lightweight semantic segmentation such as Seg.Net is used, as in DS-SLAM and RDS-SLAM, the required time for per frame for segmentation decreases from 200 ms to 30 ms. However, an unlearned dynamics in the camera field-of-view results in pose error, leading to moving object to be mapped as a static object. Our method without using any semantic label criteria runs almost constant rate regardless of moving object type and speed. In addition, our method does not require high-end graphic units.
Figure 12 shows that a person remains in the model because the model built has artifact in the “walking xyz” sequences. This situation also occurs in “walking halfsphere” (Figure 11) and “walking static”(Figure 9) sequences because the camera is tracking a person initially, and finally, the camera never looks again, hence, it is not possible to identify that the voxels are free. Figure 13 also confirms such a case. It is clear that translational error is higher at the beginning when the camera tracks the person.

Relative translational error (walking-xyz) of our method.
Figure 8 and 10 depict the ATE/RPE of TUM “fr3/walking static" and "fr3/walking halfsphere” sequences. In addition, Figure 14 shows the estimated trajectory result of fr3/walking xyz sequence obtained by the state-of-the-art visual SLAM system. Trajectory results are consistent with Tables 1 to 3. Semantic-based visual SLAM methods except pose fusion and flow fusion have better results in ATE and RPE criteria. Our proposed method can compete with semantic SLAM and RDS-SLAM, however, DynaSLAM and DS-SLAM have the best estimate. However, our method has the best result among the dense and CNN-free methods.
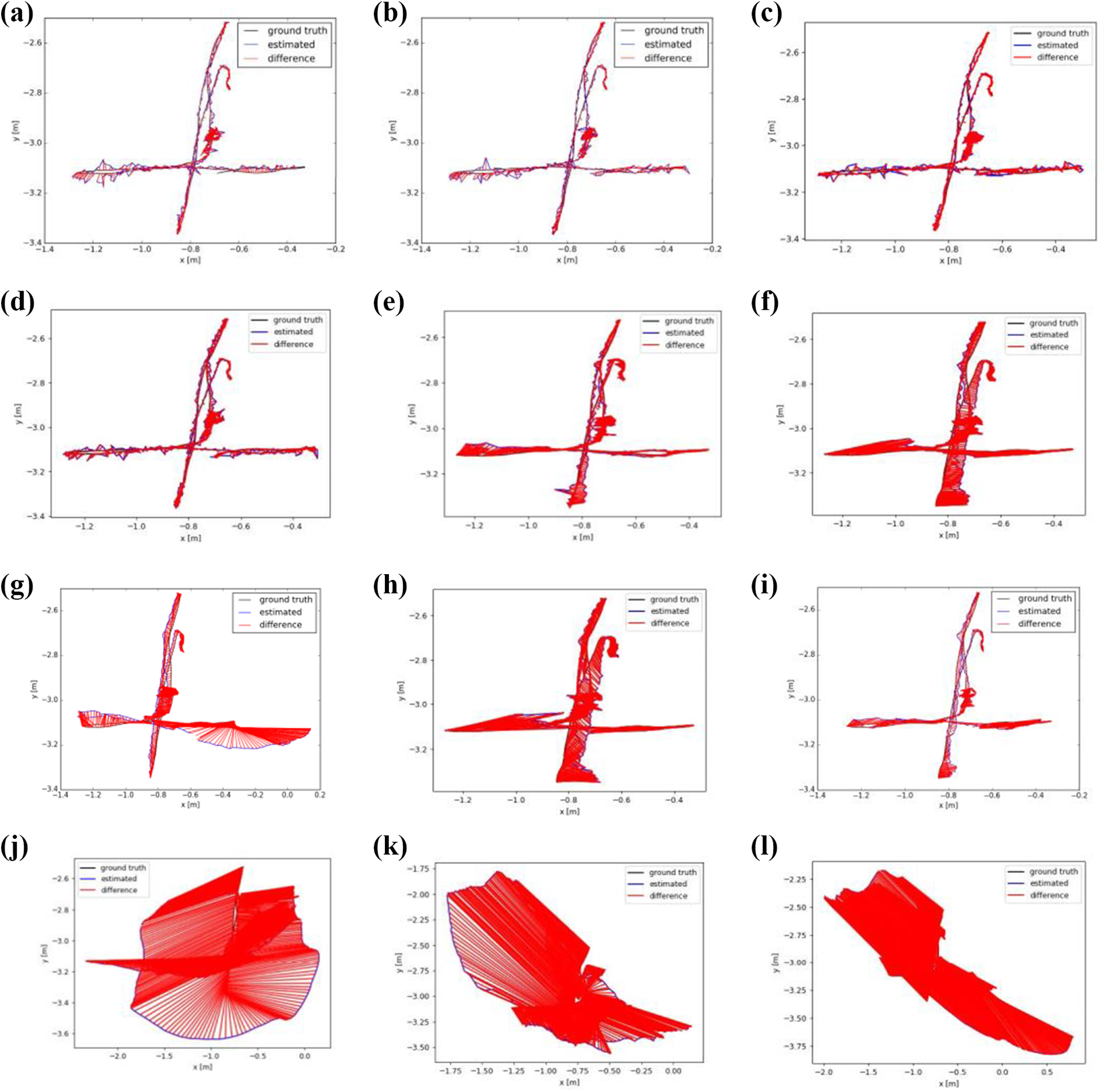
Comparison of estimated trajectories of TUM fr3/walking xyz sequence. (a) DynaSLAM: Sparse, mask R-CNN; (b) DS-SLAM: Sparse, SegNet CNN; (c) Semantic SLAM: Sparse, Blitznet CNN; (c) RDS-SLAM: Sparse, mask R-CNN/SegNet; (d) pose fusion: Dense, open pose CNN; (e) flow fusion: Dense, Pwc.Net CNN; (f) Refusion: Dense, no CNN; (g) Static fusion: Dense, no CNN; (h) DUDMap: Dense, no CNN; (i) Elastic fusion: Dense, no CNN; (j) ORBSLAM3: Sparse, no CNN; (k) VO-SF: Dense, no CNN. VO-SF: visual odometry scene flow.

RGB-D image and mesh of VolumeDeform boxing sequence of our proposed method.
Bonn RGB-D dynamic dataset
We compare methods on the dynamic scenes of Bonn dataset published by Palazzolo et al. 4 This dataset has a variety of sequences. For example, “moving_obstructing_box” scene assesses the kidnapped camera problem, where the camera is moved to a different location, whereas “balloon_tracking” has uniformly colored balloon having no features on it. Figure 16 shows the resulting mesh of BONN moving obstructing box sequence.

Mesh of BONN moving obstructing box sequence.
Table 5 presents that DynaSLAM outperforms the other methods in balloon tracking. However, it has poor performance on the obstructing box scene. Since DynaSLAM is the combination of neural network and geometric approach, the available semantic information on scene helps to increase the performance.
BONN dataset—translational RPE (RMSE, cm/s).

SF: static fusion; RPE: relative pose error; RMSE: root mean square error.
VolumeDeform dataset
VolumeDeform is an RGB-D dataset for the purpose of real-time nonrigid reconstruction and is used for evaluation of the nonrigid object reconstruction algorithms at real-time rates. 5 Since dynamic datasets for evaluating RGB-D SLAM method with exact trajectory are limited, this dataset is used to measure the elimination capability of our method to handle dynamic parts in the scene. Figure 15 illustrates the moving object elimination capability of the proposed method by using VolumeDeform boxing sequence. In addition, results of pose error and trajectory error are listed in Table 6.
VolumeDeform dataset results.
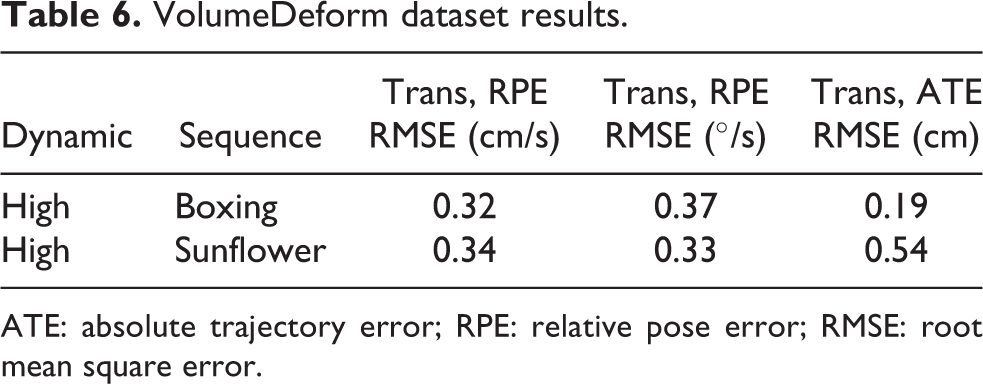
ATE: absolute trajectory error; RPE: relative pose error; RMSE: root mean square error.
CVSSP RGB-D dataset
“CVSSP dynamic RGB-D dataset has RGB-D sequences of general dynamic scenes captured using the Kinect V1/V2 and two synthetic sequences.” 6 This dataset is designed for nonrigid reconstruction. “Dog” sequence is selected because there exists little clearly distinct geometry in the environment with nonrigid dynamic object. In this sequence, the dynamic part is the movement of the arm of the person and the head of the dog. The exact value of the trajectory and reference 3D model of the environment are not provided, therefore, we evaluated the 3D mesh result qualitatively. As the frame number increases, our proposed method successfully eliminates dynamic in the frame (Figure 17).

RGB-D image and final mesh of the CVSSP “dog” sequence.
Outdoor mapping performance
We used the ZED camera in a hand-held setup for acquiring RGB-D images. We captured the frame in a resolution of 1280 × 720 with a rate of 30 fps. To measure the 3D mapping performance of our proposed approach, default camera properties and standard settings are used without calibration or lens distortion correction. The voxel size of 0.01 m with a minimum of 0.3-m depth sensor setting is used. Our method successfully created the mesh of the environment with some distortions. For instance, 0.01-mm voxel size results in coarse map especially in missing wire grid fence and part of the fence door (Figure 18).

RGB-D image and final mesh of the “outdoor-1” sequence.
Using smaller voxel size increases the mapping performance helps to maintain grid fence as in Figure 19. If an autonomous robot is flying around thin branches, telephone lines, or chain link fencing, a detailed map is required to avoid from the collision because those are the main collision areas for outdoor autonomous drones.

(a, b) Outdoor-1 sequence grid fence mapping result.
In the second sequence, we captured the frame in a resolution of 1280 × 720 with a rate of 10 fps using default camera properties. The voxel size of 0.02 m and maximum depth of 16 m settings are used in this sequence. As can be seen from Figure 20, the final mesh has no artifact of the walking person in the scene. However, the result of EF has traces of the walking person.

RGB-D image and final mesh of the “outdoor-2” sequence: (a) DUDMap and (b) elastic fusion.
Sensitivity analysis
In this section, the sensitivity of the proposed methodology to the voxel size and the contribution weight of the intensity with respect to the depth are examined (see Table 6). In addition, the required time for per image is analyzed. The fr3/walking static xyz dataset is selected for the error and timing analysis because, in this sequence, camera is tracking a person at the beginning, and finally, camera never revisits again, which results in artifact in resulting mesh. In addition, most of the state-of-the-art system use this sequence for performance analysis.
According to Table 7, in all cases, using larger voxel dramatically decreases the required calculation time, which makes that the proposed scheme is more suitable for real-time applications. However, using larger voxel increases the absolute translational error. Using larger ratio of the intensity information with respect to the depth information decreases the RMSE error, however, such situation is not valid for all cases. Therefore, utilization of application-specific constant increases the performance of the proposed scheme.
TUM “fr3/walking static” sequence translational ATE error (RMSE, cm).

ATE: absolute trajectory error; RMSE: root mean square error.
Conclusion
Visual SLAM has been studied over the last years. The research efforts have addressed SLAM problem. However, most of the approaches assume a stationary environment.
Our proposed method, SDF-based dynamic mapping approach, can operate in environments, where high dynamics exist without depending on moving objects. In addition, a static object is moved, and the corresponding voxels are removed successfully from the mesh.
After performing a complete evaluation of our proposed method for several sequences of the TUM, Bonn, and VolumeDeform datasets, our method has an improved pose estimation capability even though there exist dynamic elements in the scene.
SDF is generally straightforward to split into independent tasks that may run in parallel, however, memory requirements are used for storing a given SDF volume scales cubically with the grid resolution. Hence, special care has to be taken for efficient memory usage considering the performance. In addition, the SDF encodes surface interfaces at subvoxel accuracy through interpolation, however, sharp corners and edges are not straightforward to extract from an SDF representation. Improvement using adaptive variable voxel size and implementing feature-preserving surface extraction on sharp corners is left for future work.
Given rising interest in developing visual odometry and SLAM algorithms for very dynamic environments, it is clear that a new RGB-D dataset containing fast and slow camera motions and varying degrees of dynamic elements would be greatly appreciated by researchers if made available.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Roketsan Missiles Industries Inc.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.