
Abstract
3D object recognition has been a cutting-edge research topic since the popularization of depth cameras. These cameras enhance the perception of the environment and so are particularly suitable for autonomous robot navigation applications. Advanced deep learning approaches for 3D object recognition are based on complex algorithms and demand powerful hardware resources. However, autonomous robots and powered wheelchairs have limited resources, which affects the implementation of these algorithms for real-time performance. We propose to use instead a 3D voxel-based extension of the 2D histogram of oriented gradients (3DVHOG) as a handcrafted object descriptor for 3D object recognition in combination with a pose normalization method for rotational invariance and a supervised object classifier. The experimental goal is to reduce the overall complexity and the system hardware requirements, and thus enable a feasible real-time hardware implementation. This article compares the 3DVHOG object recognition rates with those of other 3D recognition approaches, using the ModelNet10 object data set as a reference. We analyze the recognition accuracy for 3DVHOG using a variety of voxel grid selections, different numbers of neurons (Nh ) in the single hidden layer feedforward neural network, and feature dimensionality reduction using principal component analysis. The experimental results show that the 3DVHOG descriptor achieves a recognition accuracy of 84.91% with a total processing time of 21.4 ms. Despite the lower recognition accuracy, this is close to the current state-of-the-art approaches for deep learning while enabling real-time performance.
Keywords
Introduction
Over the last decade, object recognition through visual cameras has been a fundamental computer vision research question. The introduction of consumer depth cameras in recent years has led to an extension of computer vision from 2D to 3D data, thus enabling a real-world visual perception. Methods for object recognition therefore need to be extended to extract 3D object shapes and volumetric features. In addition to 2D data, 3D data can provide geometrical information and true distance measurements for the objects, and ideally is insensitive to illumination variations. Therefore, 3D data can be used to improve the overall performance compared to 2D.
This study was motivated by the desire to develop a contactless control of a powered wheelchair using the caregiver’s position as a reference to drive the wheelchair in a side-by-side procession. Hence, the powered wheelchair requires to measure relative distances (d) from the surrounding objects while at the same time recognizing the caregiver from any other objects (Figure 1). A depth camera is the most suitable selection for the camera system. However, although depth data processing and 3D object recognition are simple tasks for human perception, they are a huge challenge for computer vision due to limitations of the 3D image data acquisition and the computational power required for real-time 3D data processing. 1 These limitations must be evaluated in advance to choose a proper depth data processing approach.

Contactless controlled wheelchair using caregiver’s detection and distance measurement to allow wheelchair contactless control.
Deep learning is a cutting-edge approach for object recognition which tries to imitate the human learning behavior by extracting information directly from the raw images. This requires complex algorithms such as convolutional neural networks (CNNs), to extract and classify a hierarchy of increasingly abstract features to detect and recognize the objects in the scene. Despite their good performance, CNNs pose high requirements on computational and memory resources, especially for large data amounts as in 3D point clouds. Unfortunately, powered wheelchairs and autonomous robots have severe constraints in terms of power, space, heat dissipation, and hardware resources, 1 meaning that real-time CNN implementations are unfeasible for our application.
As an alternative to CNNs, the use of handcrafted features is the classic computer vision approach for object recognition. The idea is to extract different features from the raw image to generate an object descriptor, after which a supervised classifier learns patterns from the descriptor to estimate the object’s class. The computational requirements for this approach depend mainly on the total number of features (
In this article, we evaluate a 3D handcrafted object descriptor that was developed by Dupre and Argyriou 2 as an extension of the original 2D histogram of oriented gradients (HOG) 3 to support volumetric 3D data (3DVHOG). This descriptor is applied in combination with a supervised support vector machine (SVM) or a single hidden layer feedforward neural network (SLFN) classifier for 3D object recognition. The scientific contribution of this article is to explore firstly the 3DVHOG descriptor for 3D object recognition 2 and secondly the combination of data preprocessing, post-processing, and classifier settings to reduce both the computational cost and the power requirements while balancing the classification performance. Our study therefore provides the base information required to enable implementation in an embedded system for robotics and real-time applications.
We analyze the effect of reducing the extremely high dimensionality of the 3DVHOG features by applying principal component analysis (PCA) as well as the effect of choosing different numbers of hidden neurons (Nh ) in an SLFN classifier. We use the Princeton ModelNet10 data set 4 with volumetric images of 10 different object classes as a reference to train, validate, and test the overall data processing steps and also to compare our recognition rates with those of others. Despite targeting an embedded system to detect the caregiver in the end, we perform our analysis on principal component (PC) hardware at this stage. We do this to compare the performance of the found processing chain in general with other object recognition approaches based on the ModelNet10 data set. In the future, we plan to evaluate the system using real data and focus on the caregiver detection. Besides that, the proposed method is not limited to embedded systems and the caregiver detection. It is rather applicable to any other object recognition task as well.
Related works
The extensive existing work on 3D object recognition uses several different approaches that can generally be classified in terms of input data type: (1) RGB-D data approaches, (2) multi-view CNN (MVCNN) approaches, (3) volumetric CNN approaches, and (4) handcrafted 3D object descriptors.
RGB-D data approaches
Depth cameras such as Microsoft Kinect provide an additional 2D parallel output channel to RGB to encode the depth information (RGB-D). RGB-D approaches, then, extend the 2D image architecture to four channels by adding the depth information for each camera pixel (2.5D). Due to the popularization of depth cameras along with the possibility to using well-known 2D image recognition frameworks, there is a very extensive body of research using RGB-D approaches for 3D object recognition in combination with 2D handcrafted object descriptors 5,6 or 2D CNN approaches. 7,8 However, RGB-D is still a 2D image and so does not fully exploit the complete 3D volumetric information of the objects. We believe that using the entire 3D information will provide better results than the 2D recognition approaches to RGB-D data processing.
MVCNNs approaches
MVCNN approaches transform 3D object recognition into a series of 2D image recognition tasks by rendering each 3D object from different 2D viewpoints and extracting 2D features for each image projection. MVCNNs uses the same well-developed CNN recognition frameworks for 2D images. 9 –12 However, in comparison with volumetric approaches, MVCNN approaches have a lower feature dimensionality, are more efficient to compute, and are more robust against noise and artifacts such as holes. 13 Thus, they are more suitable for real-time applications and noisy camera data. A 2D cylindrical panoramic projection (DeepPano) 14 enables rotation invariance and achieves a 88.66% accuracy on the ModelNet10 data set. Su et al., 13 instead, used an MVCCN approach including 80 rendered object views, achieving a maximum recognition accuracy of 90.1% on the ModelNet40 data set. Johns et al. 15 extended the idea of MVCCN to use generic multi-view camera trajectories and achieved a maximum recognition accuracy of 92.8% on the ModelNet10 data set. Sfikas et al. 16 create an augmented panoramic view by a concatenated spatial and orientation domains to create an augmented panoramic view to feed a CNN, achieving a recognition accuracy of 91.1% on the ModelNet10 data set. Finally, Yavartanoo et al. 17 proposed a cutting-edge multi-view approach (SPNet) that achieved a recognition accuracy of 97.25% on the ModelNet10 data set. This approach uses a stereographic mapping to project the 3D surfaces onto a 2D planar image and has lower processing and memory requirements than other recognition approaches. However, it requires the use of a powerful graphical processing unit (GPU) that involves high power consumption and high heat dissipation. Hence, it is not suitable for robotics or powered wheelchair applications due to their real-time operation and hardware constraints.
Volumetric CNN approaches
Volumetric approaches extract 3D volumetric features through a CNN directly from the 3D data, thus exploiting the complete 3D geometry of the objects without including additional 2D features. The object’s data is preprocessed through a voxelization processing step, and then the point-cloud data of each object is converted into a uniform 3D grid of binary voxels. 18 RGB-D data can be preprocessed to convert the depth information to a point-cloud representation and then voxelized, 19 and so this approach is suitable for depth cameras. The first volumetric approach to be proposed was the 3DShapeNets, 4 which represents the 3D mesh as a probability distribution of binary voxels. 3D shape distributions are learned by a five-layer convolutional deep belief network. This approach achieves a recognition accuracy of 83.5% on the ModelNet10 data set. Hegde and Zadeh 20 then proposed the FusionNet CNN volumetric approach that uses up to two CNNs in combination with the AlexNet-based 21 MVCNN approach. The three CNN subnetworks are fused to combine multiple data representations and improve the recognition accuracy to 93.1%. Brock et al. 22 presented the state-of-the-art approach, which uses a 45-layer 3D volumetric CNN and a large data augmentation data set for training, achieving a maximum recognition accuracy of 97.25% on the ModelNet10 data set. Despite their good recognition performance, 3D volumetric CNN approaches are large, complex, and highly computational and memory demanding, meaning that none of the above mentioned volumetric approaches are suitable for real-time operation. 18,17
Maturana and Scherer 23 proposed the VoxNet approach, which considerably reduces the number of model parameters. This enables real-time operation while at the same time increasing the recognition accuracy to 92% on the ModelNet10 data set. Qi et al. 24 proposed the PointNet, a real-time CNN for object recognition based on a point density occupancy grids data representation, achieving a recognition accuracy of 77.6% on the ModelNet10 data set. Zhi et al. 18 proposed a real-time 3D object recognition approach called LightNet, which combines the task of subvolume, supervision, and orientation prediction to learn discriminative 3D features from multitask learning. LightNet achieves a recognition accuracy of 93.94% on the ModelNet10 data set.
Uniform voxel grids lead to excessive use of memory and processing resources. Reviewed approaches above use, consequently, a relatively small spatial resolution to map the 3D data onto the volumetric uniform grid of voxels, typically
Handcrafted descriptors
Handcrafted descriptors are the classical approach to object recognition. The idea is to extract a set of features from the object to generate an object descriptor that can be used as an object signature. By training a supervised classifier, it is possible to learn from the descriptors to identify a pattern regarding the object’s class. This 2D classical approach can also be applied to 3D data by using specific 3D object descriptors. The efficiency of the approach relies on the effectiveness of the descriptor in capturing the object class information. A large number of handcrafted approaches exist. 28 –30 Generally, handcrafted descriptors can be divided into local and global features. 31 Local feature descriptors capture key points of the object’s shape and so are focused on the shape around several key points. They tend to be more computationally expensive, and thus are not suitable for real-time robotics applications with high limitations in terms of hardware and heat dissipation. The most popular local descriptors are spin images, 32 fast point feature histograms, 33 and 3D SURF. 34 Conversely, global feature descriptors capture shape information using the overall appearance of the object. They are increasingly used in object recognition, object manipulation, and geometric characterization. They are efficient in terms of computation time, thus allowing real-time performance. 35 Uses in 3D object shape recognition include ensemble of shape functions, 36 global fast viewpoint feature histograms, 33 and 3DVHOG. 2,37 However, they ignore the local object’s details, leading to lower performance. In both of the above mentioned 3DVHOG implementations reviewed, 2,37 the level of local object detail is configured by different 3DVHOG parameters and thus can be modified according to the recognition requirements. However, there is a compromise between the local detail level, the descriptor feature dimensionality, and the elapsed processing time. Analysis of this compromise is the intent of the present article.
Method
Our goal was to evaluate the 3DVHOG handcrafted object descriptor to reduce the computational cost as much as possible compared to deep learning approaches for 3D object recognition tasks. Our proposed processing steps are summarized in Figure 2.

Object recognition processing steps.
Data preprocessing
We chosen the Princeton ModelNet10 data set as a common reference to validate our classification results. This data set includes a volumetric 3D representation of 10 different object classes (
Object classes and total numbers of training and test objects in the ModelNet10 data set.

Validation example of data set objects with a grid of
Pose normalization
We propose an additional data preprocessing step to achieve rotation invariance in the object classification. Rotation invariance is crucial for detecting objects whose pose is rotated according to the camera position. As a HOG-based descriptor, the 3DVHOG is not rotation invariant. Thus, when an object is rotated the 3DVHOG descriptor changes, making it impossible for the classifier to estimate the correct object class. To solve this, we have proposed a pose normalization method based on the PCA pose normalization in combination with the standard data deviation (PCA-STD). 38 To include the pose normalization preprocessing step into the recognition results, we first rotate each test data set object randomly along the three-axis and later we normalize its pose using the PCA-STD method.
Feature extraction
The 3DVHOG object descriptor
2
was originally developed for environment hazard detection and risk evaluation by detecting the presence of dangerous 3D objects in the 3D scene. Here, we instead use it as a general object descriptor to extract volumetric features from the objects. Like the 2D implementation of the HOG, there are some input parameters to configure the descriptor, but in this 3D implementation they are extended to a 3D representation and hence include the number of angle bins, (
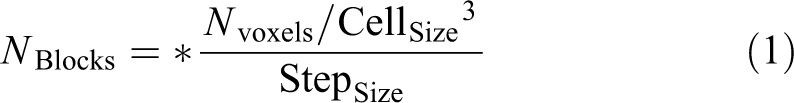

with the number of cells per object (

It is important to evaluate the impact of each parameter to choose a proper descriptor setup that minimizes the required
Data postprocessing
The different
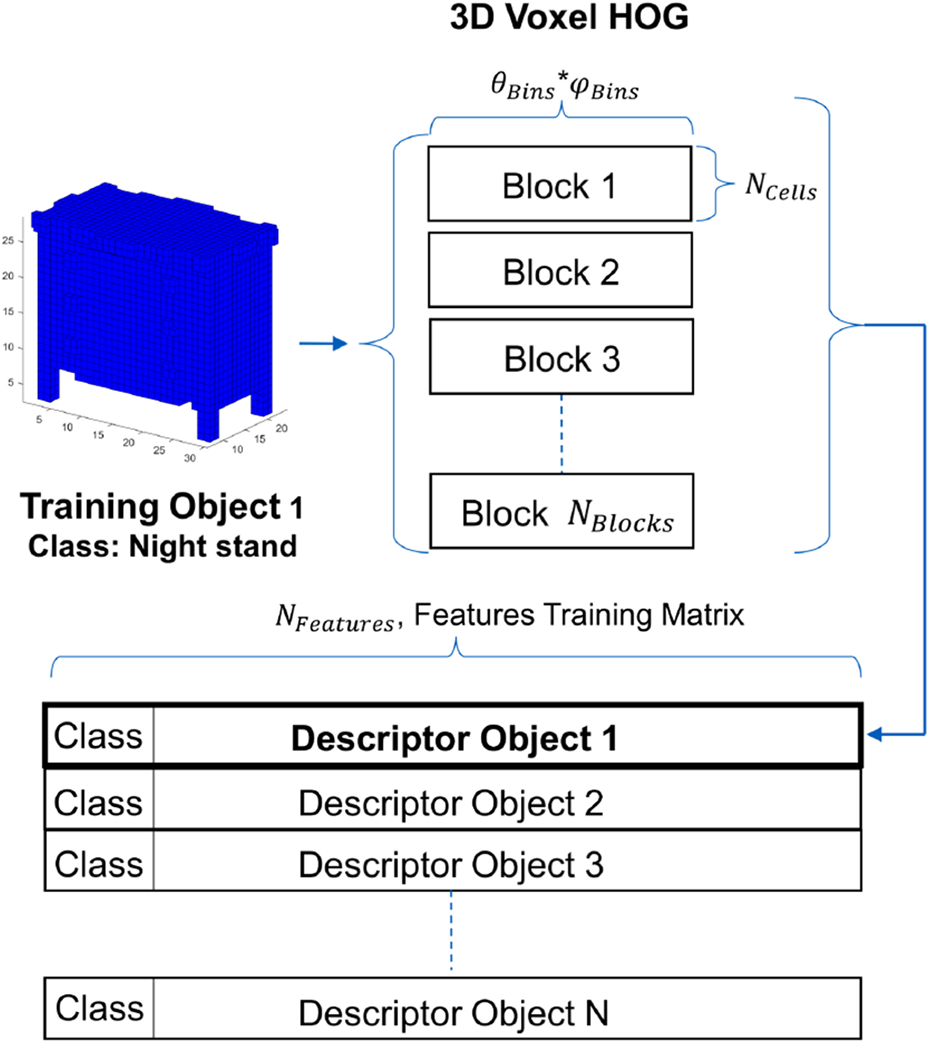
3DVHOG feature matrix and feature vectorization. 3DVHOG: 3D voxel-based extension of the 2D histogram of oriented gradient.
We therefore apply the PCA as method to reduce the feature dimensionality. The final number of recomputed features depends on the number of principal components (


PCA feature reduction. PCA: principal component analysis.
The maximum
Object classifiers: SVM and SLFN
Information regarding the object classes must be extracted from the feature vector. Once we have learned this information from the training data set, it is possible to estimate the class of a new input object. The learning process is performed by training a supervised multiclass classifier. We have evaluated two different classifiers: an SVM and an SLFN. We expect different classification results when they work in combination with 3DVHOG and PCA, and an evaluation of this was one of the aims of the present study. Configuration and data parameters of the classifiers are shown in Table 2.
SVM and SLFN classifier configuration parameters.

SVM: support vector machine; SLFN: single hidden layer feedforward neural network; ECOC: Error correcting codes; ISDA: iterative single data.
Regarding the Nh
used in the SLFN classifier, there is no specific rule to choose a proper Nh
that maximizes the classification accuracy.
39
As shown in Table 4, we need to deal with extremely large

However, we also evaluated Nh
as a design criterion to minimize the elapsed processing time and measure the dependence of the classification accuracy on Nh
. We selected Nh
criteria according to
Experiments
We defined several experiments to evaluate the effect of the different preprocessing and postprocessing parameters on the classification accuracy (Figure 2). The order of these experiments follows the logic design flow that must be considered for a proper parameters configuration and data analysis, (Figure 6).

Experimental design flow.
Results and analysis
Experiment 1: Voxel grid and PCA
In experiment 1, we analyzed the effect of choosing different voxel grid configuration parameters while reducing the

where
Increasing the voxel grid will provide more detailed volumetric information about the objects but can also increase the differences between objects of the same class. By contrast, when the voxel grid is decreased, the objects are less detailed but the differences between objects of the same class are smaller. Smaller intraclass differences make it easier for the classifier to extract a pattern from the feature matrix and, hence, can increase the classification performance. However, this can also cause smaller differences between objects of different classes, thus decreasing the classification performance. It is therefore necessary to find a combination of the lowest voxel grid value, the minimum required
In line with the literature and the total
3DVHOG initial configuration parameters.

3DVHOG: 3D voxel-based extension of the 2D histogram of oriented gradient.
A higher voxel grid means a higher
3DVHOG

3DVHOG: 3D voxel-based extension of the 2D histogram of oriented gradient.
Classification accuracy, standard deviation, and data variance after all the preprocessing and postprocessing steps illustrated in Figures 2 and 5 for each voxel grid case are shown in Figure 7 for the SVM and Figure 8 for the SLFN. These results were calculated by averaging 10 different measurements. The figures also show the classification accuracy without applying PCA.

SVM classification accuracy, data variance, and PCA dimensionality reduction for grids of

SLFN classification accuracy, data variance, and PCA dimensionality reduction for grids of
Classification accuracy was improved for both classifiers when PCA was applied. The maximum value was achieved by using approximately 100 PC in both cases (SVM: Figure 7, SLFN: Figure 8). The improvement was significantly better for the SVM classifier, which achieved a maximum classification accuracy of
Experiment 2: Explore 3DVHOG bins
In experiment 2, we evaluated the impact of using different
3DVHOG configuration parameters and

3DVHOG: 3D voxel-based extension of the 2D histogram of oriented gradient.

Classification accuracy with respect to the 3DVHOG angles using 100 PC for SVM and SLFN classifiers and grids of
For SVM and SLFN classifiers, the recognition accuracy remains constant with respect to the number of angle bins. Thus, a low number of angle bins is enough for capturing the object class information. In addition, the SVM classifier performs better than SLFN for all analyzed cases. The maximum recognition accuracy achieved is
Experiment 3: Explore numbers of hidden neurons
In experiments 1 and 2, we used the

SLFN classification accuracy with respect to Nh
for a
As shown in Figure 10, SLFN classification accuracy was invariant to the Nh
used. Thus, the results of this experiment agree with those of experiment 2. However, a lower Nh
(
Experiment 4: Pose normalization
In experiment 4, we evaluated the pose normalization preprocessing step shown as the second operation in Figure 2. This pose normalization achieves rotational invariance for the 3DVHOG descriptor using the PCA-STD method defined by Vilar et al.
38
Performance is evaluated in terms of averaged
An initial evaluation without pose normalization showed a recognition accuracy of
Experimental maximum accuracy comparison for a grid of

PCA: principal component analysis; STD: standard data deviation.
Experiment 5: Explore processing time
In experiment 5, we measured the mean value of the elapsed processing time for the overall object recognition chain. This experiment compared all the processing durations according to the 3DVHOG parameter configuration, pose normalization, and also evaluated the elapsed processing time improvements achieved by using PCA and a lower Nh
. Experiments 1 and 2 gave us information on the best 3DVHOG parameter configuration to find a good balance between classification accuracy and required
With these preprocessing and postprocessing parameter configurations, we trained the SVM and SLFN classifiers to estimate the object class from the test data set objects as shown in Figure 11. We computed, object-by-object, the elapsed processing time for the 3DVHOG descriptor computation (
Laptop computer specification parameters.

GPU: graphical processing unit.

Processing chain and processing times definitions.
Although these measurements are not from an embedded system, they provide a valuable reference to qualitatively compare and analyze the different processing times. As such, our analysis gives an early insight into expected processing to select an appropriate variant for later implementation in the real embedded system. Summarized mean values of the different processing times are shown in Table 8 for a
Averaged accuracy and elapsed processing times for a

SVM: support vector machine; SLFN: single hidden layer feedforward neural network.
Averaged accuracy and elapsed processing times for a
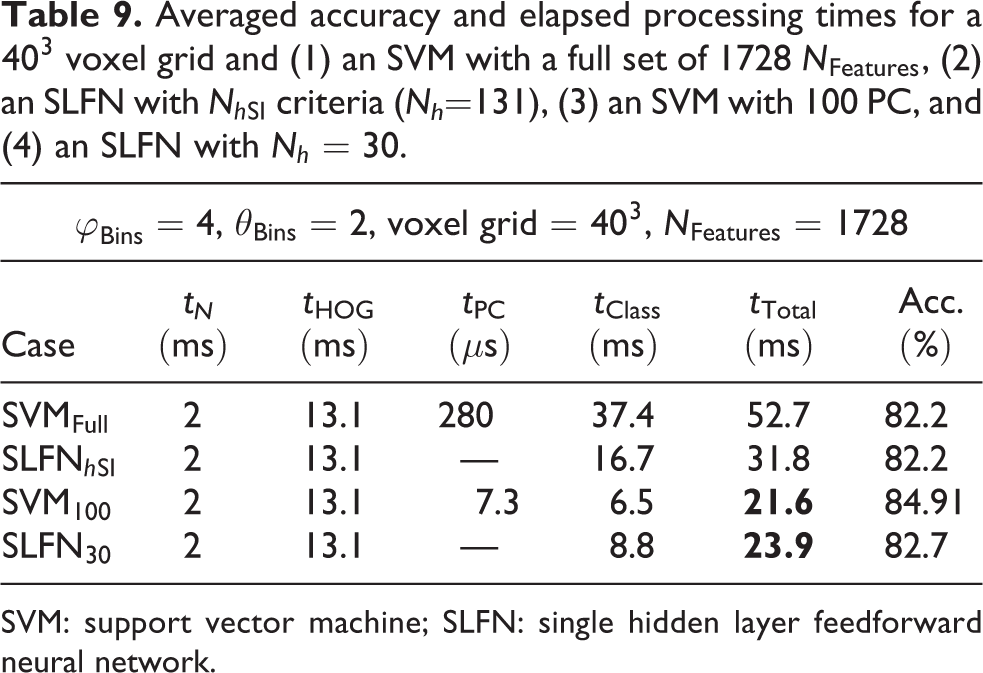
SVM: support vector machine; SLFN: single hidden layer feedforward neural network.
The measured tN
and
Object classification analysis
The confusion matrix for the highest recognition accuracy analyzed in Tables 8 and 9 is shown in Table 10. Most of the object classes were relatively well classified, but there was clear misclassification between 4 (desk) and 9 (table) and between classes 5 (dresser) and 7 (nightstand) (Table 1).
Confusion matrix for SVM classifier with

SVM: support vector machine.
Discussion
Comparison with previous results
The 3DVHOG descriptor in combination with PCA-STD pose normalization and PCA dimensionality feature reduction achieved a recognition accuracy of 84.91% and a
Averaged accuracy and total elapsed time comparison of the PCA-STD + 3DVHOG descriptor with respect to other CNN approaches using the Princeton ModelNet10 data set.

PCA: principal component analysis; STD: standard data deviation; 3DVHOG: 3D voxel-based extension of the 2D histogram of oriented gradient; CNN: convolutional neural network; GPU: graphical processing unit.
Classification analysis
As shown in Table 10, there was substantial misclassification between classes 4 (desk) and 9 (table) and 5 (dresser) and 7 (nightstand) (Table 1). These classification errors considerably decreased the final recognition accuracy. The main reason for the misclassified objects is the high similarity between classes (Figure 12). The 3DVHOG descriptor cannot capture enough local detailed information from the classes to allow the classifier to differentiate between them. This problem can be solved by using a higher voxel grid to capture more local detailed information. However, increasing the local detailed information can also reduce the similarities between objects of the same class and consequently reduce the overall recognition accuracy. In addition, a higher voxel grid leads to a considerable increase in

Object similarity between classes 4 (desk), 9 (table) and 5 (dresser), 7 (nightstand).
Experimental design flow
The results from this study can guide us in choosing the best classifier, voxel grid, and configuration of parameters
Conclusions
Experimental results show that the 3DVHOG descriptor in combination with PCA-STD pose normalization achieves a classification accuracy of
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.