
Abstract
Multiagent coordination is highly desirable with many uses in a variety of tasks. In nature, the phenomenon of coordinated flocking is highly common with applications related to defending or escaping from predators. In this article, a hybrid multiagent system that integrates consensus, cooperative learning, and flocking control to determine the direction of attacking predators and learns to flock away from them in a coordinated manner is proposed. This system is entirely distributed requiring only communication between neighboring agents. The fusion of consensus and collaborative reinforcement learning allows agents to cooperatively learn in a variety of multiagent coordination tasks, but this article focuses on flocking away from attacking predators. The results of the flocking show that the agents are able to effectively flock to a target without collision with each other or obstacles. Multiple reinforcement learning methods are evaluated for the task with cooperative learning utilizing function approximation for state-space reduction performing the best. The results of the proposed consensus algorithm show that it provides quick and accurate transmission of information between agents in the flock. Simulations are conducted to show and validate the proposed hybrid system in both one and two predator environments, resulting in an efficient cooperative learning behavior. In the future, the system of using consensus to determine the state and reinforcement learning to learn the states can be applied to additional multiagent tasks.
Keywords
Introduction
Motivation
Multiagent cooperative learning has been continuing to be a large research interest in the field of robotics with a wide range of applications. 1 –3 Tracking wildfires using multiple agents communicating together to better handle the fire, so it does not destroy as much, is one such possibility. 4,5 Another one is that using multiple agents to better map the structure of a pipeline that if it structurally fails could cause large damage and loss of money. 6 An additional possibility is mapping and exploring unknown environments. 7 This article aims to solve the task of multiagent predator avoidance 8,9 with an intelligent hybrid system.
Most current multiagent research incorporates some form of consensus, 10 movement control, 11 or reinforcement learning, 12 but a combination of all three to achieve an efficient cooperative learning behavior is largely unexplored. Some uses of consensus are to determine the location of obstacles 13 or to make measurements in a scalar field. 14 –16 Movement control of multiagent systems can come in the form of cooperatively doing path planning as in the literature. 17 –19 Alternatively, there are means of control through flocking in varying formations 20 –22 to achieve a variety of tasks. 23,24 Reinforcement learning has been implemented cooperatively in a variety of ways for multiagent environments, such as a GridWorld 25,26 and box pushing. 27 Although all of these use for consensus, movement control, and reinforcement learning that are good in their own right, this article aims to make a more intelligent hybrid system.
In nature, flocking has long been observed in many environments 28 –30 with one possible goal being to defend from predators as can be seen with schools of fish. Even simulated environments 31,32 that reward individuals for their own survival result in flocking like formations of the agents. It is thus clear that flocking for survival has clear benefits in both natural and simulated environments. The goal of this article is then to create a hybrid system that combines consensus, flocking, and multiagent reinforcement learning into one intelligent system that can sense and learn to escape from attacking predators.
Literature review
Flocking background
Methods of ensuring agents flocking have been proposed and studied in the literature. 33 –37 Inspired by the natural world of birds and fish flocking together, 38 flocking algorithms have been formed. The algorithms allow agents to flock in different patterns in a distributed manner that requires on communication between direct neighbors rather than the entire flock. The main rules that define flocking are that flockmates maintain a distance from each other without getting too close or far from each other and match the velocity of the other flockmates. Reinforcement learning approaches have also been applied to flocking in which agents individually or cooperatively learn to flock without the use of specific algorithms. 39,40 There are also cases in which reinforcement learning is implemented to teach agents to go to specific targets, but in cases where learning fails, a flocking algorithm to avoid obstacles is used. 41 Flocking by itself is not particularly useful if the agents flock directly to a predator so this work aims to combine learning with flocking to effectively escape from predators. Other flocking implementations such as that proposed in the literature 42 allow agents to flock together with minimal information transfer, but the formation is not ideal for quickly avoiding a predator. Additional flocking features can be added, such as handling faulty robots, 43 time delay for information transfer between robots, 44 or change of formation. 45 For this article, these are not the focus but could potentially be added in the future.
Reinforcement learning background
Cooperation is an important part of a flock learning to do a task together. In the literature, 46 agents are not necessarily flocking together, but through cooperation, they are completing their task effectively. Cooperation is already a large part of flocking algorithms so that they can be done in a distributed manner. Cooperation must also be used to effectively learn in a distributed manner. Using simple Q-learning 47 does not achieve the necessary amounts of cooperation required, so a more cooperative approach 9,48 is required. Unfortunately, the number of agents increases the state space that grows and requires longer amounts of training to effectively learn to flock together to the same destination. For this, function approximation techniques 49,50 are useful. However, in current research, function approximation in combination with cooperative learning is largely unexplored. 51,52
Consensus background
Partial observability of the state space is another issue for purposes of escaping attacking predators. For a school of fish, not all fish will be able to see an attacking predator yet they manage to utilize flocking to maximize their safety anyway. For our agents, this is the same case in that only agents on the outside of a flock will be able to see an oncoming predator. A method of communicating to the other agents that a predator is approaching is thus necessary. This can be seen as a sort of event-triggered consensus such as that proposed in the literature. 53 Algorithms have been proposed to allow multiagent systems to come to a consensus on measurements from multiple agents that do not necessarily agree with each other. 54,55 Many uses of consensus, however, are for estimating some kinds of measurements. 56,57 This work intends to use consensus in combination with reinforcement learning to make a more intelligent system. Some works, such as by Zhang et al. 51 and Xu et al., 52 implement a hybrid system of consensus and reinforcement learning, but they use consensus to determine the global reward of the system. This work uses consensus to determine the state relying on local rewards instead.
Contributions
In this article, we combine the benefits of consensus, flocking, and reinforcement learning to create a hybrid system, as shown in Figure 1. This system assumes partial observability in that only agents on the outside of the flock near an approaching predator are able to see the attacking direction of the predator. They must use consensus to inform the rest of the flock about the attacking direction of the predator, which is then used with reinforcement learning to learn a target (a safe place) to move toward. That target is then used by a flocking algorithm to give each agent a control input to move each agent toward the target in a flocking formation.

Block diagram of the hybrid system.
The contributions of this article are then as follows: Utilization of consensus between agents for state approximation in reinforcement learning. Cooperative learning with a large number of agents. Implementation of function approximation to reduce state space for a large number of agents used. Integration of reinforcement learning and flocking to learn where to flock. A fast and accurate consensus algorithm for a large number of agents. An entirely distributed system.
Paper organization
The organization of the remainder of this article is as follows. In “Flocking control” section, a method for flocking is introduced. The “Multiagent learning” section goes over the multiagent learning that used to ensure the agents flock together to the same target. The “Consensus for multiagent state approximation” section details a method of state approximation called consensus for the agents. This is followed by “Simulation and results” section, which details the combination of flocking, reinforcement learning, and consensus into a hybrid system for the agents to learn to flock away from a predator. Lastly, “Conclusion and future work” section covers the conclusion with analysis and potential future development.
Flocking control
Flocking control algorithm
In this section, the flocking algorithm used for the hybrid system is presented. To learn to avoid predators, the agents must be able to flock together. Using flocking methodologies presented in the literature,
33
a network topology consisting of a graph G that is a pair

where
The neighbors of an agent can be determined by

where
There are many formations that flocking can take, but the formation used here is an α-lattice formation in which
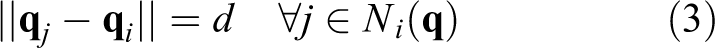
for desired distance d, where
In flocking, each agent determines its control input with a gradient-based term

where c
1 is a positive constant,

where

where

where

where

This method allows the agents to flock together in an α-lattice formation toward a target location.
Results of flocking algorithm
The results of this flocking algorithm (

(a–d) Fifty agents flocking to the green target.

(a–d) Fifty agents flocking to the green target while avoiding the red obstacle.
Multiagent learning
In this section, an entirely decentralized reinforcement learning method for a network to learn to flock together to specified targets is presented. Independent and cooperative learning methods are presented. In addition to this, a method of cooperative learning with function approximation is evaluated against standard cooperative learning.
Learning model
The model of the learning algorithm is similar to that proposed in the literature. 9 Using a state, action, and reward model for an agent i, let current state, action, and reward be si , ai , and ri with the next state and next action as s′ i and a′ i , respectively.
State
The state can be defined as
Action
For actions, the agents want to move in one of eight cardinal directions to escape a predator depending on the direction the predator is coming from. These actions can be encoded as 1, 2, 3, 4, 5, 6, 7, and 8 mirroring the possible directions in the state defined above. The action list can then be defined as
Reward
The flocking algorithm used provides flocking in an α-lattice formation. This formation ensures that agents on the inside of the formation have up to six neighbors while agents on the outside have one to five neighbors. To match this formation, the reward is then defined as

so that the max reward that an agent can get is 6 if it has all six neighbors to encourage flocking.
The reward is then scaled depending on the direction of the predator. The scaling factor is split into five categories consisting of the best target, good targets, average targets, bad targets, and the worst target, which can be visualized in Figure 4. Agents choosing the action corresponding to the best target have their reward equal to the reward defined in equation (10). Dr is a scale factor that is determined as follows: Actions corresponding to good targets are scaled down to 75% of the reward above, average targets to 50%, bad targets to 25%, and the worst target to 0%. This is done to encourage the agents to learn the optimal target to go toward while maintaining the importance of flocking together. The addition of more predators multiplicatively scales the reward. For example, if there are two predators and an agent chooses an action that is a good direction for both of them, the reward will be scaled down by 75% twice. This would fail if there are eight predators with one in each direction, but in that case, there is no safe space for the agents to go.

Visualization of the direction classifications. The large red circle represents the predator while the triangle represents the agent. The blue circle represents the best target, green circles are good targets, yellow circles are average targets, orange circles are bad targets, and the small red circle is the worst target in this scenario.
Cooperative learning
To learn to flock to the same target together, a cooperative learning method is implemented. Agents learning independently in this environment will take many learning episodes to converge or never converge at all which can be seen in the literature. 9 However, to cooperatively learn, each agent must first do independent learning 47 for an individual table, Qi , as follows:

where α is a learning rate and γ is a discounting factor. This independent learning is not capable of converging in any reasonable amount of time for this application, so cooperative learning must be used. After performing independent learning, the Q-table of each agent is further updated by communicating with its neighbors using the following 9 :
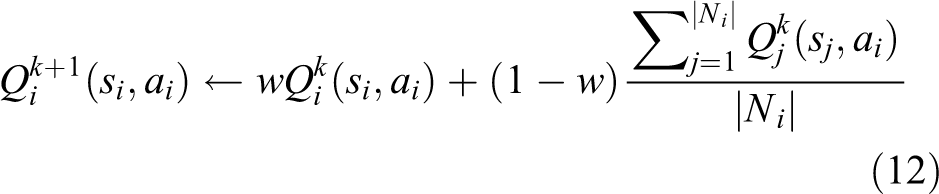
where w is a weight, such that
Action selection
The action selection of an agent is based on the maximum Q-value approach
48,58
in which the action with the highest Q-value for a given state is the action chosen. This method of choosing the action is highly exploitative with no exploration. To introduce exploration, we use ε-greedy.
47
We use a small probability
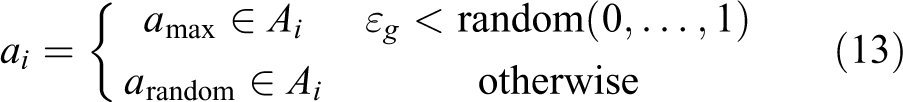
This random action selection allows an agent to explore a new action that might return a higher reward. The same action selection can be used for function approximation learning replacing the Q-value with the
Function approximation
Despite the cooperative Q learning algorithm performing better than independent learning, as seen in the literature,
9
it still can be improved upon to get better results and faster convergence. The direction of the predator
Radial basis function
Function approximation allows to approximate a state space rather than just discretize it. There are many methods of doing function approximation, but the method that seemed most applicable was a simple RBF approach. The RBF scheme maps the original Q table to a parameter vector

where the RBF kernel ϕ is a column vector of length

where s is the current state,
Function approximation learning
The cooperative learning algorithm from equations (11) and (12) is still used to learn, however, it is modified to account for the parameter vector

with the same learning rate α and discount factor γ as before. The cooperative portion is as follows
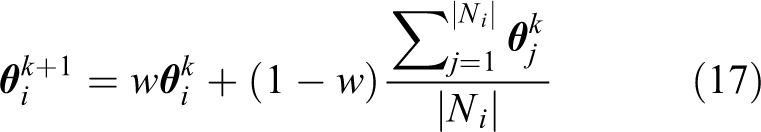
The key difference here is that each agent must now communicate a
Function approximated distributed cooperative learning.


Comparison of learning algorithms
If we use 50 agents

Comparison of convergence between RBF and Q learning with and without cooperative learning. All four algorithms were run 10 times for 20 episodes, and the results were averaged. Over the course of these runs, cooperative RBF was able to converge within four episodes while cooperative Q learning was unsuccessful in fully converging within 20 episodes. Both independent algorithms were not able to learn. RBF: radial basis function.
Consensus for multiagent state approximation
In this section, a way of sensing and communicating the direction of a predator is presented. Each agent has a predator sensing radius rp that allows them to sense a predator. If a predator is within that radius, then the agent is able to know its relative angle to the predator. These angles can be used to determine the direction the predator is coming from. However, not every agent will be in range of the predator to see the direction that it is coming from and not every agent that is in range will agree on which direction the predator is coming from. To solve this, a weighted voting method is introduced for agents to share and achieve a consensus on the direction of the predator.
Predator sensing
A method of agents achieving consensus proposed in the literature
56
is used as a start point for the weighted voting procedure. The algorithm is split into two components: a measurement step and a consensus step. For the measurement step, if an agent is in range of the predator, then it performs a measurement of the relative direction of the predator. As mentioned previously, the direction is discretized into eight evenly split directions. These directions are assigned to an information vector

where wp
is the angle between the agent and the predator such that

Direction and associated information values for an agent observing a predator. Each color corresponds to an information value 1 through 8 with 1 representing east, 3 representing north, and so forth.
Each agent’s information vector is assigned a weight or a belief factor

Consensus
For consensus, each agent updates its information
Consensus on direction of predator.


Using this algorithm,
Validation
Algorithm 2 is tested in an environment, where 50 agents are flocking to a static position while seeing a predator, denoted by a large red circle, moving in a circle around the flock over 900 iterations, as can be seen in Figure 7. Visually, the agents that are represented by the triangles change color in association with the direction they perceive the predator to be in after consensus. The consensus component was allowed to run for 20 consensus iterations and was found that all agents converged to the same

(a–d) Predator moving in circle around flock with consensus updating the state of the agents based on the direction of the predator.
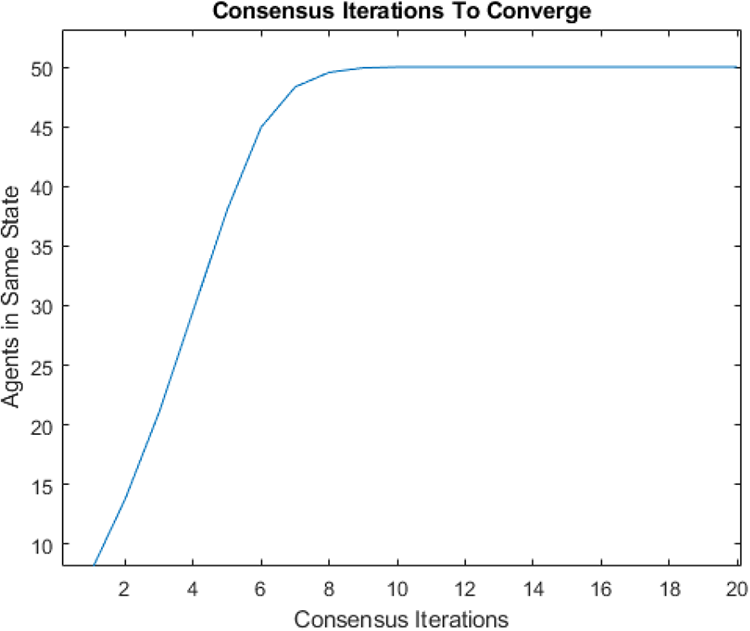
The number of consensus iterations for all agents to converge to the same state.
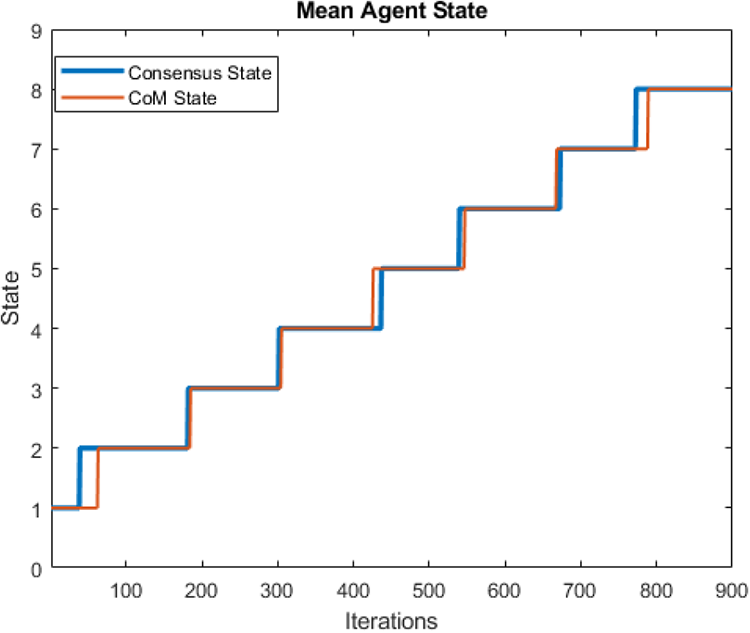
The average

The number of agents in the same state when cm is arbitrarily high. There are multiple predator positions that result in the agents not fully converging even given 40 iterations.

The convergence of the agents state when cm is arbitrarily high. Given 40 consensus iterations, it is not able to fully converge.
The iterations to converge and number of incorrect directions found over 900 iterations.

From Table 1, we can see that if the largest measured weight is spread from one side of the flock to the other,

The cause of error of the consensus algorithm. Despite the predator being east of the flock as a whole the only agent in range senses it as northeast causing the error seen in Table 1.
Through testing alternate consensus methods, one was able to achieve a higher accuracy. This method involved using consensus to determine the center of mass of the flock and absolute position of the predator. When each agent has that center of mass position and the position of the predator, it can then determine for itself the direction of the predator, but this approach is not used for a few reasons. First and foremost, the time it takes to reach a consensus is at least two to three times the number of iterations that the proposed approach uses, thus making it take much longer to both learn and later use practically for predator detection. Secondly, it requires that each agent has an absolute coordinate for itself and the predator rather than relative directions for those agents in range of the predator. In many environments, this may not be known or if it may have a large amount of noise associated with it, so this approach was not used.
Simulation and results
In this section, we go over implementation details and results found for the hybrid learning system. We use consensus to determine the direction of the predator
Simulation environment
The learning environment is set up in a manner, as shown in Figure 13, where the triangles represent the agents, and the large red circle represents the predator. The eight smaller green circles around the edge represent the eight static targets for the eight actions. Each episode begins by randomly initializing 50 agents in a

Initialization of an episode with agents randomly distributed.
Learning configuration
For the single predator environment, the direction of the predator is initially east, then northeast, and so on, in a counter-clockwise rotation so that ideally every possible state
Results
Single direction state
We first look at a scenario in which all agents are in the same direction state with the use of consensus. The average results of 10 runs over eight episodes can be seen in Figures 14 and 15. We can see that the agents are able to fully converge for a single direction state in four episodes. Thus, the theoretical number of episodes required to learn is 8 directions times 4 episodes required or 32. However, due to the nature of flocks not being perfect, it is possible for each direction to not be seen four times within those 32 episodes, so 56 episodes are used to learn for the single predator and 216 for the two-predator environment to account for slower learning due to consensus.

The number of agents choosing the same action for each episode for a single direction state by episode. The agents are able to fully converge by four episodes.

The number of agents choosing the same action for each episode for a single direction state by iteration with the dashed lines representing the start of an episode. It can be seen that most learning is done in the beginning of an episode while the flock is connected.
Single predator
Six runs were conducted and averaged for the single predator environment. In Figure 16, it can be seen that by episode 32, or the predator coming from each direction four times, the agents have mostly converged to the same target, but there are a few cases in which it is not fully converged until approximately episode 48 or each direction occurring six times, which is expected due to potential consensus inaccuracies.

The number of agents choosing the same action for each episode for a single predator environment averaged over six runs. It can be seen that the agents converge by each direction being encountered six times.
The position of agents during the first learning episode can be seen in Figure 17. Some agents are in different states and the agents in the same state have not learned to go to the same target yet. This produces the messy flocking shape that can be seen. In Figure 18, the agents are all in the same state and have learned to go to the same target in an α-lattice formation.

(a–d) Fifty agents flocking away from one predator before learning the same target.

(a–d) Fifty agents flocking away from one predator after learning the same target.
In Figure 19, we have the trajectory the agents take in the final learning episode, where the pink triangles are the random initialization of the agents. By the last episode, it can be seen that all agents have converged to the same target flocking in a relatively smooth manner despite the random action selection of ε-greedy.

Trajectory the agents take in the last episode where the triangles are the initial position of the agents. The flocking can be seen to be smooth to the target after agents get into flocking formation despite the ε-greedy random action selection.
Two predators
Two predators have also been tested to perform well with an expanded information vector to account for the extra predator and thus a larger state space as well. The addition of a second predator increases the number of predator starting positions by a factor of eight from 8 positions to 64. In addition to longer computation times for handling a second predator, there is now eight times the amount of episodes that must be performed for all direction combinations to be encountered. Unfortunately, this cannot be reduced, without reducing the problem size, by applying a function approximation approach to the learning process. However, there is a way to lower the amount of direction combinations. Instead of learning the direction of the two predators separately, we treat both predators as the same predator. This way if the first predator is detected in direction 1 and the second predator is detected in direction 2, it is the same as if the first predator is in direction 2 and the second predator is in direction 1. Thus, the system learns two state combinations simultaneously. However, there are eight direction combinations, where both predators are detected in the same direction, which is not reducible. This reduces the number of direction combinations from 64 down to 36, which reduces the number of episodes and thus the time it takes to learn from 8 times that of a single predator to 4.5 times. For this reason, the two-predator learning is done over 216 episodes, and the results of which can be seen in one run in Figure 20. It can be seen that by 144 episodes, or all combinations of directions being encountered four times the agents have almost converged. By 180 episodes or each direction being seen five times, the agents have completely converged to the same action for each state.

Number of agents choosing the same action for two predators over 216 episodes. It can be seen that after 180 episodes, all agents choose the same action for each state.
The movement of the agents flocking away from the two predators before they have learned and after they have learned to flock away from the predators can be seen in Figures 21 and 22, respectively, which looks similar to that of the single predator.
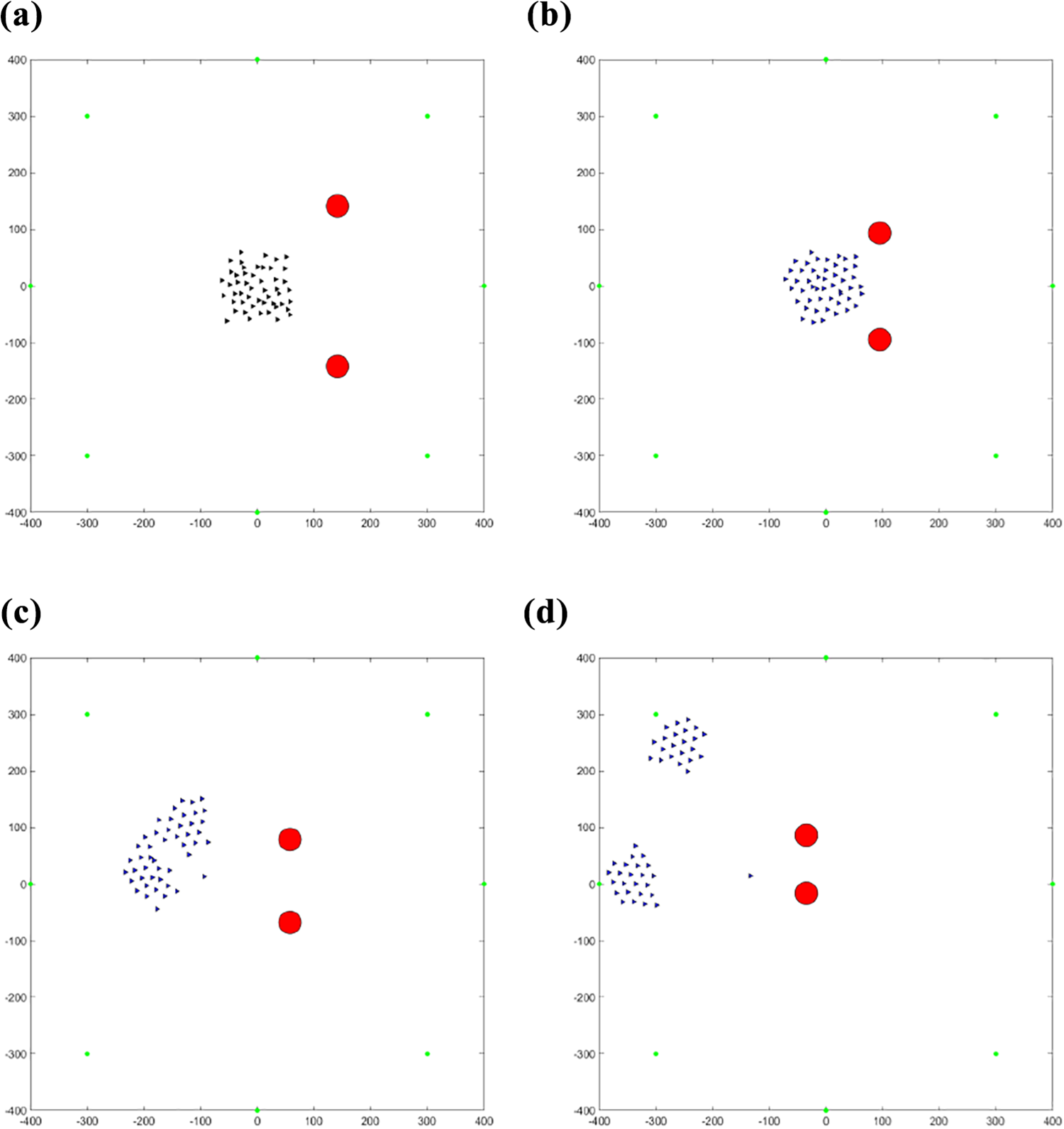
(a–d) Fifty agents flocking away from two predators before learning the same target.
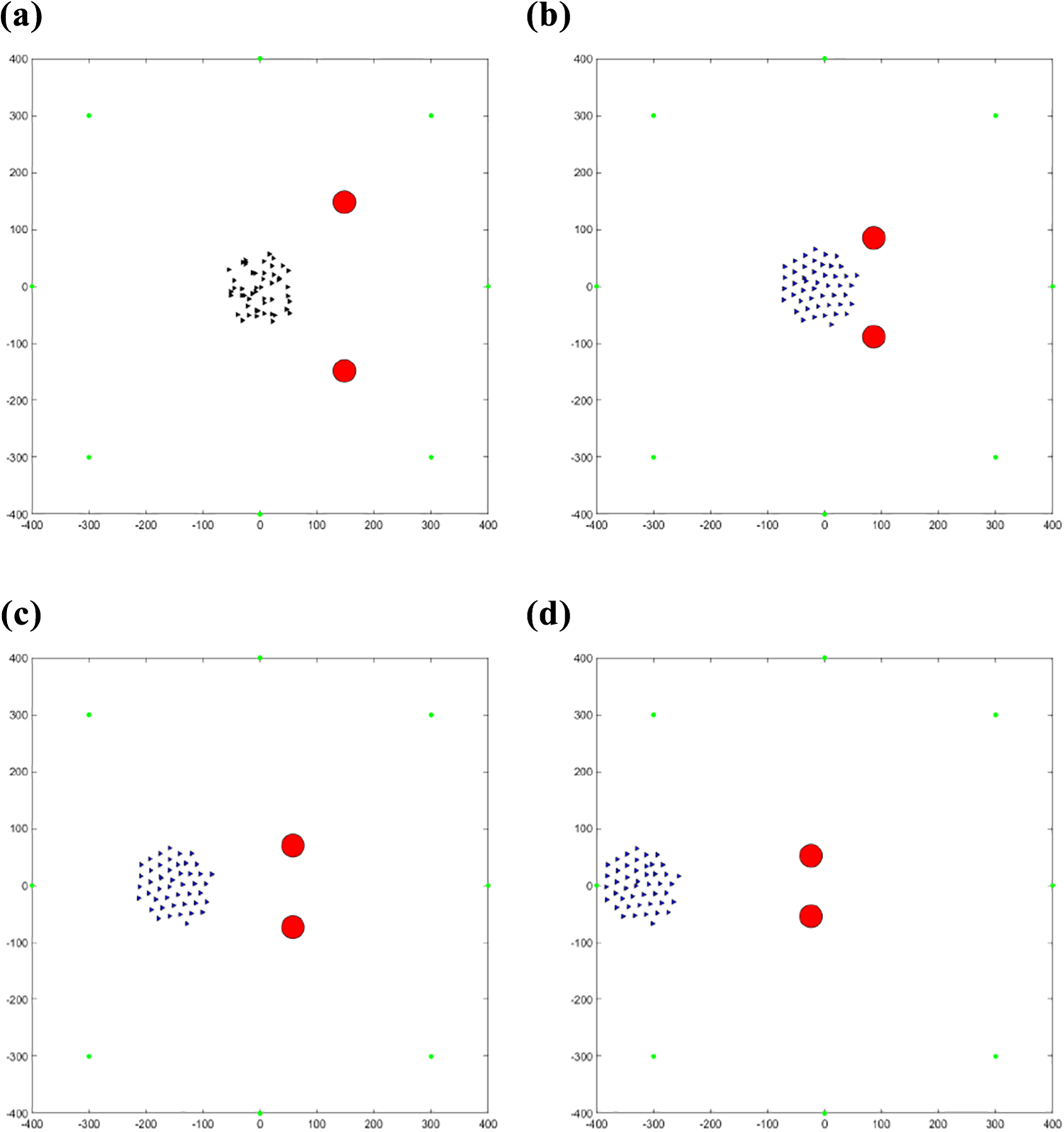
(a–d) Fifty agents flocking away from two predators after learning the same target.
Discussion
In Figure 21, it can be seen that the agents split into two subgroups. This was a fairly common occurrence for unlearned episodes caused by the communication between neighbors. In this case, a lot of the agents may have found the west direction to be the best while others may have found the northwest direction to be best. Eventually, their close neighbors would agree with them and move with them to those targets but not enough to cause the other majority to agree. In this case, the neighborhoods are pretty split between the top half and the bottom half visually with agents on the border picking one or the other depending on the ε-greedy learning algorithm. The best direction is then learned in later episodes when the agents are randomly positioned so that the neighborhoods become mixed together.
Another aspect to consider is what would happen if agents were surrounding a predator. In particular, if agents were equally distributed around the predator, then the predator is not in any particular cardinal direction relative to the flock. Currently, there is no check for that occurring but that would be easily adaptable to stop the agents from moving until the predator moves into a position, where there is a cardinal direction. Alternatively, currently, the agents will move in either the first or last direction depending on implementation at which point the predator will likely obtain a direction after one time step.
Conclusion and future work
Conclusion
This article presented a hybrid system that achieves an efficient cooperative learning behavior. The system is applied to the task of escaping attacking predators while maintaining a flocking formation.
Flocking is used to move the agents in an α-lattice formation to a target location. Then, multiple reinforcement learning methods were presented utilizing the flocking targets as actions in the learning algorithm. Independent learning with and without function approximation proved to be unreliable in learning to flock together to the same target. Cooperative learning without function approximation was shown to be better than both independent learning methods but still took a considerable amount of episodes to learn. Cooperative learning with function approximation was shown to perform the best, requiring very few episodes for the agents to converge to the same target.
Finally, a method of detecting predators is used to determine the direction of attacking predators. The method proposed was shown to be very accurate, requiring only a few more iterations than it takes to transmit information from one edge of the flock to the other. The direction of the detected predators is used for determining the state of the system for the reinforcement learning component.
The hybrid system was then developed consisting of flocking control, function approximated cooperative learning, and consensus to allow agents to learn the location of a predator and where to flock away from it. The system was tested in one and two predator environments with results showing the success of the system as an efficient cooperative learning method.
Future work
Although the hybrid-system proposed here was used to solve the task of avoiding predators by agents flocking together to targets, it is generic enough to be used in a variety of multiagent tasks. Applying this hybrid system of using consensus to determine the states and reinforcement learning to learn the states is something that can be looked further into in the future to achieve efficient learning for a variety of tasks. A possible improvement to this work is to create a more parallelized framework for the simulation to allow for faster learning particularly for increased amounts of predators that grow the state space and learning configuration. Further testing can be done with an expanded state size of more predators and a three-dimensional simulation environment. In addition to this, implementing smarter predators and different types of agents are also tasks that could be looked into in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material was based upon work partially supported by the National Aeronautics and Space Administration (NASA) under grant RRR no. 80NSSC19M0170 and grant no. NNX15AI02H issued through the NVSGC-RI program under subaward no. 19-21, the RID program under subaward no. 19-29, and the NVSGC-CD program under subaward no. 18-54. This work was supported by the U.S. National Science Foundation (NSF) under grant nos NSF-CAREER: 1846513 and NSF-PFI-TT: 1919127 and the U.S. Department of Transportation, Office of the Assistant Secretary for Research and Technology (USDOT/OST-R) under grant no. 69A3551747126 through INSPIRE University Transportation Center. The views, opinions, findings, and conclusions reflected in this publication are solely those of the authors and do not represent the official policy or position of the NSF, NASA, and USDOT/OST-R.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.