
Abstract
Generating response with both coherence and diversity is a challenging task in generation-based chatbots. It is more difficult to improve the coherence and diversity of dialog generation at the same time in the response generation model. In this article, we propose an improved method that improves the coherence and diversity of dialog generation by changing the model to use gamma sampling and adding attention mechanism to the knowledge-guided conditional variational autoencoder. The experimental results demonstrate that our proposed method can significantly improve the coherence and diversity of knowledge-guided conditional variational autoencoder for response generation in generation-based chatbots at the same time.
Introduction
Together with the rapid growth of Internet social network conversation data and the successful application of deep learning in natural language processing, both academia and industry are paying more and more attention to build open domain nontask-oriented chatbots. 1 Retrieval-based methods and generation-based methods are currently the mainstream methods for building chatbots. 2 Many well-known chatbots such as MILABOT (from Montreal Institute for Learning Algorithms) 3 and XiaoIce (from Microsoft) 4 use generation-based methods, because they are end-to-end learnable and are good at capturing complicated syntactic and semantic relations between messages and responses. 5
Sequence-to-sequence (Seq2Seq) model is a recurrent neural network (RNN) model of the encoder–decoder framework, which is commonly used in tasks such as machine translation and text generation in natural language processing. Most of the methods in generation-based chatbots use an improved model of the vanilla Seq2Seq model, which can generate long, diverse, and meaningful responses to meet the needs of response generation. Among them, knowledge-guided conditional variational autoencoder (kgCVAE) is the most distinctive model of these improved models, which building upon encoder–decoder framework (a.k.a. a Seq2Seq model), adding variational autoencoder to the model for improving the model’s response generation diversity. 6 It assumes that the user’s question-and-answer relationship with chatbot belongs to one-to-many relationship, and this relationship conforms to the normal distribution, as shown in Figure 1.
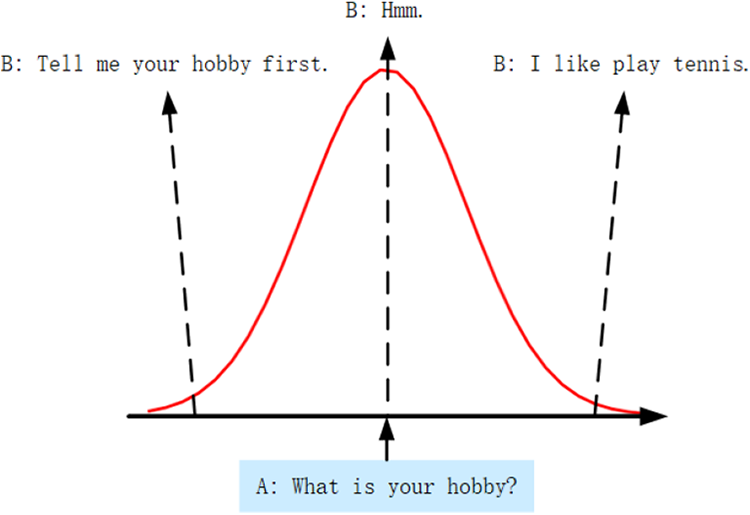
kgCVAE assumes question-and-answer form based on the normal distribution. kgCVAE: knowledge-guided conditional variational autoencoder.
However, kgCVAE using random sampling method based on normal distribution that may not conform to basic law of natural language processing. Bestselling book The black swan: the impact of the highly improbable 7 makes the public realize that the normal distribution is not suitable for all situations, and the abuse of the normal distribution will cause errors. The Zipf’ law 8 is a basic law of natural language statistics in the study of natural language processing. The distribution of words in corpus should be a power-law distribution rather than a normal distribution. Therefore, we believe that random sampling in the model should be performed in accordance with the Zipf’ law, as shown in Figure 2.
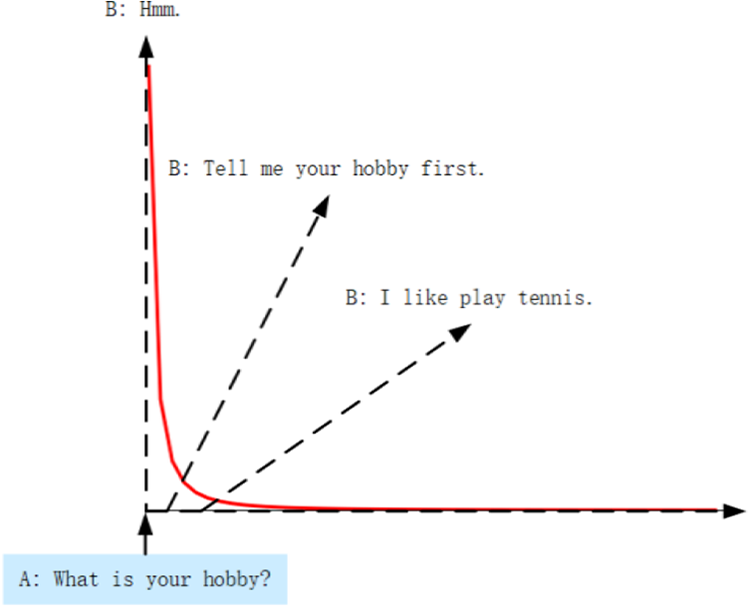
Our method assumes question-and-answer form based on the power-law distribution. The distribution image in this picture is derived from the Zipf distribution function in NumPy. 9
We used the gamma sampling (GS) that comes from TensorFlow 10 for data sampling and adjusted the parameters to make it conform to the Zipf’ law. The experimental results demonstrate that GS significantly improves the diversity of model generation dialog. However, it did lead to a decline in the coherence of the model generation dialog. Therefore, we tried to solve this problem by other methods. In fact, attention mechanism has been widely used for the improvement of the Seq2Seq model, as presented in Table 1. Thus, we also tried this method.
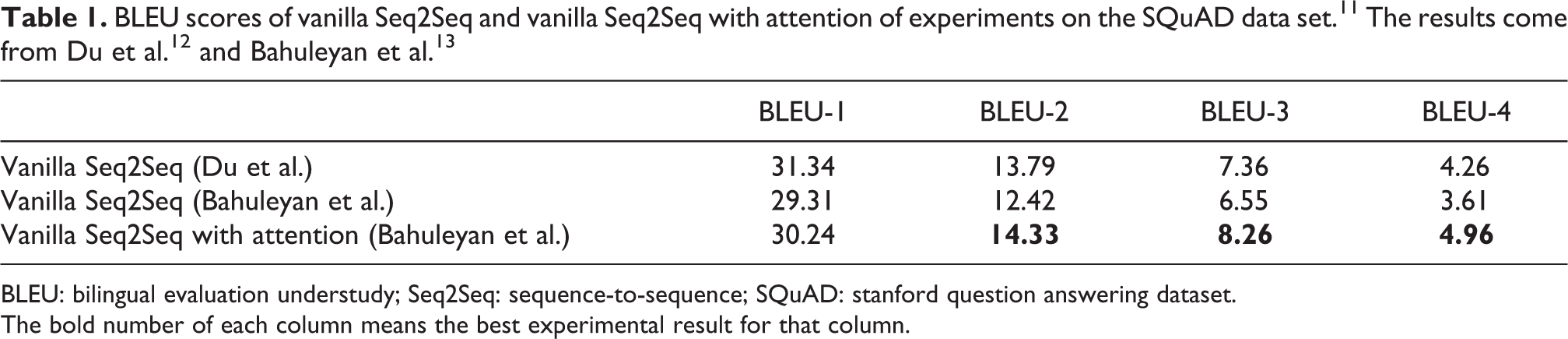
BLEU: bilingual evaluation understudy; Seq2Seq: sequence-to-sequence; SQuAD: stanford question answering dataset.
The bold number of each column means the best experimental result for that column.
After adding attention mechanism to the model, we have greatly improved the coherence of the model’s generated dialog. But this method also led to a decline in the diversity of model generation dialog. Finally, we added the GS and attention mechanism to the model at the same time, which improved the coherence and diversity of response generated by the model. The balance of dialog generation coherence and diversity is achieved, and the best effect of the model is achieved.
Our contributions in this article are 2-folds: (1) we present a novel method that improved the coherence and diversity of response generation of kgCVAE and (2) we verified the effectiveness of our proposed method on a public data set and tested the effectiveness of kgCVAE with GS and kgCVAE with attention mechanism, respectively.
Related work
We briefly review the history of chatbots and introduce the most cutting-edge technology for building chatbots.
Chatbots system
The development of natural language processing is generally considered to be experienced in three eras of rationalism, empiricism, and deep learning. The development of dialog system is basically in sync with the development of natural language processing. The dialog system before the 90 s was usually symbolic rule or template-based. Then with the successful application of the probability model in the field of natural language processing, the statistical learning-based dialog system dominates. After 2014, deep learning gradually began to dominate the field of natural language processing, and the dialog system also entered the era of deep learning. 14 The chatbots system is a kind of open domain nontask-oriented dialog system, which is mainly built by two methods: retrieve-based method 2,15 –18 and generation-based method. 5–6,12,13,19 –30 The principle of the retrieval-based method is to make trained model select a response from a large corpus; the principle of the generation-based method is to generate a response directly by using trained model. Both retrieval-based method and generation-based method are based on deep learning. Our study focuses on generation-based method.
Generation-based methods
The Seq2Seq model has been successful in the field of machine translation. Due to the similarity of the principle, this model is quickly applied to the field of dialog generation, which enables the dialog generated by a trained model. Sutskever et al. 19 used the vanilla Seq2Seq model to generate dialog. However, the vanilla Seq2Seq model has some problems. The ideal goal is to make the model generate long, diverse, and meaningful responses for users, but the vanilla Seq2Seq model does not do well. Li et al. named this problem “safe reply.” 21 In response to this problem, many researchers have proposed solutions. Most of the proposed methods are to add new modules between the encoder and the decoder of the vanilla Seq2Seq. Serban et al. 24 added latent variables to the vanilla Seq2Seq model that improved the diversity of dialog generation. Similarly, Zhou et al. 25 also added latent responding mechanisms to the vanilla Seq2Seq model that improved the diversity of dialog generation. Xing et al. 26 improved the model by introducing topic information into the vanilla Seq2Seq model. Wu et al. 5 added dynamic vocabulary to the vanilla Seq2Seq model that significantly improved the diversity of dialog generation. On the other hand, Li et al. also applied re-ranking technology, 21 reinforcement learning technology, 27 and adversarial learning technology 28 to dialog generation and achieved better results. In addition, Wu et al. 1 proposed a new paradigm for response generation: prototype-then-edit, which outperforms many existing models on some metrics.
Variational autoencoder for dialog generation
In deep learning, Seq2Seq, variational autoencoder (VAE), and generative adversarial networks (GAN) are the most commonly used generation models. Among them, Seq2Seq is mainly used for text generation, and VAE and GAN are mainly used for image generation. Moreover, conditional variational autoencoder (CVAE), as an improved model of VAE, is also commonly used for image generation. Bowman et al. 29 first combined VAE with the encoder and decoder framework and generated more diverse responses through normal distribution sampling in chatbots. However, VAE with the encoder and decoder framework for text generation is not the mainstream of text generation methods, and there are not many related works. Later, Zhao et al. first used CVAE with the encoder and decoder framework to generate dialog, which increased the diversity of dialog generation. In addition, Zhao et al. incorporated the leverage linguistic knowledge into the CVAE and proposed the kgCAVE model, which further improved the diversity of model’s dialog generation. 6 In this article, we propose an improved method for kgCVAE by adding an attention mechanism module between the encoder and the decoder of kgCVAE and replacing normal distribution sampling with gamma distribution sampling.
The method overview
CVAE model is the basic of kgCVAE. Based on the traditional encoder–decoder framework, CVAE adds a prior network and a recognition network between the encoder and the decoder to improve the diversity of the trained model’s dialog generation. KgCVAE is an improved model of the CVAE model. On the basis of CVAE, a new language feature variable y (such as dialog act) is added between the encoder and the decoder to further improve the effect of the CVAE. In addition, we add an attention mechanism module to kgCVAE in our proposed method. The process of kgCVAE with attention mechanism is illustrated in Figure 3.
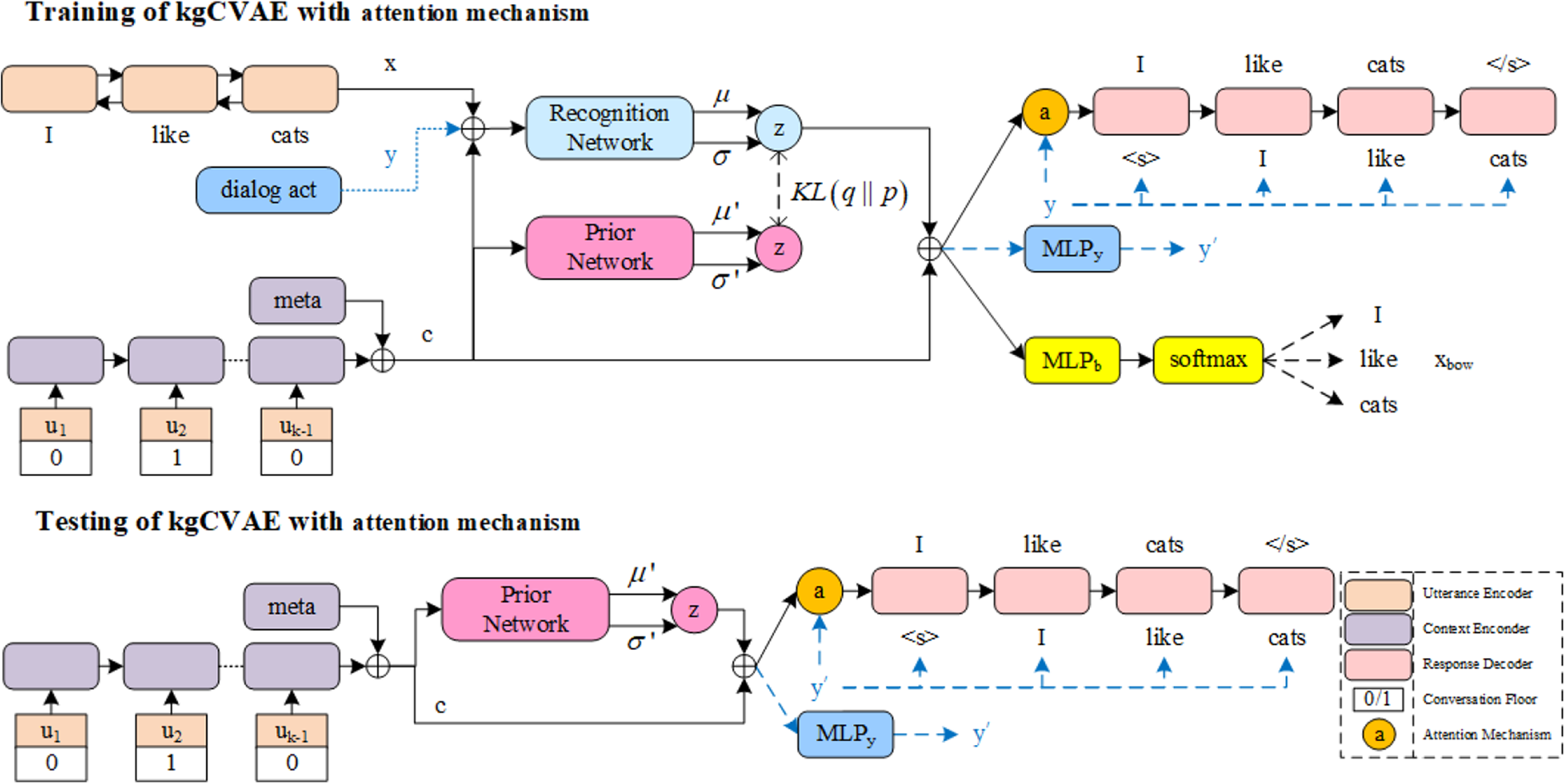
kgCVAE with attention mechanism. kgCVAE: knowledge-guided conditional variational autoencoder.
CVAE model
Each dyadic conversation of CVAE is represented via three random variables: c, x, and z. c is the dialog context, which is composed of the dialog history: the preceding k−1 utterances; conversational floor (1 means the same speaker and otherwise 0) and meta features m, such as conversational topic. x is the response utterance. z is a latent variable, which is used to capture the latent distribution over the valid responses. CVAE defines
CVAE can be efficiently trained with the Stochastic Gradient Variational Bayes framework by maximizing the variational lower bound of the conditional log-likelihood.
6,31
Specifically, CVAE is trained to maximize the conditional log-likelihood of x given c, which involves an intractable marginalization over the latent variable z. In CVAE, the latent variable z follows multivariate normal distribution with a diagonal covariance matrix, and a recognition network

In CVAE, the utterance encoder is a bidirectional gated recurrent unit (Bi-GRU), which encodes each utterance into fixed-size vectors by concatenating the last hidden states of the forward and backward RNN
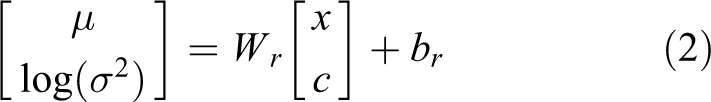
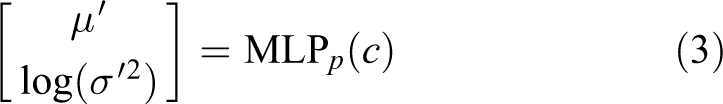
CVAE obtains samples of z either from
kgCVAE model and optimization
KgCVAE is the development of CVAE. It has two advantages: (1) by incorporating linguistic feature y, such as dialog act, into CVAE, so that CVAE’s latent variable z gets more information to facilitate model training and (2) when the model generates a response, an additional linguistic feature y′ is output for each response, which improves the interpretation of the model. In kgCVAE, the generation of x depends on latent variable z, context c, and linguistic feature y, and linguistic feature y relies on latent variable z and context c. In the training stage, the initial state of the response decoder is

However, there is an optimization problem in both kgCVAE and CVAE. Because they all use a straightforward VAE with RNN decoder, the vanishing latent variable problem will cause. To solve this problem, Zhao et al. proposed that bag-of-word (BOW) loss as an auxiliary loss that requires the decoder network to predict the BOWs in the response x. And x is decomposed into two variables: xo
and

where


In the experiment, BOW loss solved the vanishing latent variable problem while complementing the kullback-leibler (KL) annealing technique.
Gamma sampling
The gamma distribution is a continuous probability function of statistics. It has two parameters and is subject to an incomplete gamma function. It is usually used to model sums of exponentially distributed random variables. 32 It is defined as follows
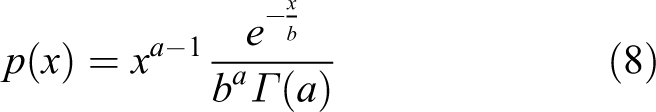
where Γ is the gamma function, a is the shape parameter, and b is the scale parameter. In our proposed method, we use random gamma function from TensorFlow
10
and set
Attention mechanism
In kgCVAE, the decoder generates x based on latent variable z, context c, and linguistic feature y. Attention mechanism is added to dynamically align x and

where
Then, the source information

which is fed to the decoder at the jth step.
Although, the addition of the attention mechanism in the Seq2Seq is a relatively common improving method for the Seq2Seq. However, there is a problem when using variational autoencoder in the Seq2Seq. Bahuleyan et al.
13
found the Seq2Seq with a traditional attention mechanism; the variational latent space may be bypassed by the attention model and thus becomes ineffective. Therefore, they proposed a variational attention mechanism for the Seq2Seq, where the attention vector is also modeled as normal distributed random variables. At each step j, it adjusts its hidden state
We used the variational attention mechanism method of Bahuleyan et al. 13 and used gamma distributed random variables for attention vector modeling. Therefore, when building attention mechanism, we treat both the latent space z and the attention vector aj as random variables. Another noteworthy thing is that we did not use the optimization method proposed by Bahuleyan et al. We still use the optimization method of kgCVAE.
Experiment
We tested our proposed method on Switchboard (SW) 1 release 2 corpus 6,33 and compared the effects of the GS and attention mechanism on the model.
Experimental datasets
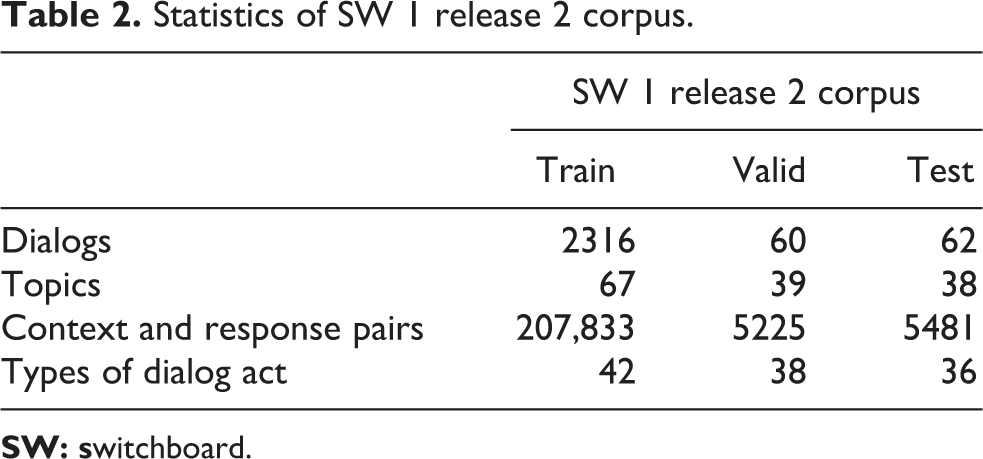
SW 1 release 2 corpus was released in 1997 by Godfrey and Holliman. 33 The data set consists of more than 2400 two-sided telephone conversations data. Each set of data has a topic tag and contains a total of 70 topics. Zhao et al. randomly selected 2316 dialogs for train, 60 dialogs for valid, and 60 dialogs for test. And they used the natural language toolkit (NLTK) 34 tokenizer to tokenize, kept the top 10,000 frequent word types as the vocabulary, and deleted nonverbal symbols and repeated words to process the data set. Finally, train data set has 207,833 context and response pairs, valid data set has 5225 context and response pairs, and test data set has 5481 context and response pairs. This data set is unique in that there are 42 kinds of dialog act features labeled by hand and machine. We used data published by Zhao et al. 6 The statistics of SW 1 release 2 corpus are presented in Table 2.
Statistics of SW 1 release 2 corpus.
Multiple reference evaluation
Since the model was tested using one reference, the testing results were not reliable. Therefore, Zhao et al. used information retrieval techniques to collect 10 additional references with the same topic for each reference, and manually filtered out the poor quality of the reference. Finally, the average per context has 6.69 extra references. The specific data statistics are presented in Table 3.
Statistics of one reference test of SW corpus and multiple reference test collected by Zhao et al.

SW: switchboard.
Note that the multiple reference test data set is distinct from the file storage format of the one reference test of SW corpus. The multiple reference test data set does not contain topic information, and the dialog act is a different format. Therefore, it is very difficult to evaluate the model directly using the multiple reference test data set on the existing data interface. In fact, after noting that there are 5481 context and response pairs for the one reference test data set, researchers only need to train the model and then align the 5481 multiple references with the generated hypothesis. To measure the generated hypothesis, Zhao et al. designed precision and recall as metrics. Precision is used to measure the coherence of the generated dialog; recall is used to measure the diversity of the generated dialog. For a given dialog context c, there exist Mc
reference responses rj
,

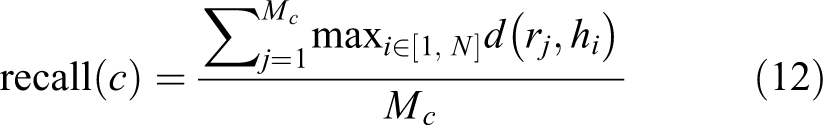
where
In addition to BLEU, perplexity 22 is used to measure models in the experiment but not with precision and recall metrics. Perplexity is used to measure the ability of generation dialog model of the syntactic structure of each utterance and the syntactic structure of the dialog. Note that unlike the BLEU, the lower value of perplexity, the better a trained model.
Experiment setup
Except hierarchical recurrent encoder-decoder (HRED) 22 model is implemented by using Texar 36 that is an open-source text generation toolkit based on TensorFlow, most models of experiments are implemented by using TensorFlow, 10 and all models of experiments are run on a single 1080ti GPU. We follow the work of Zhao et al., use Glove 37 Twitter pretrained Word2Vec file, and choose 200 as word embedding size. We choose Bi-GRU for the utterance encoder and set the hidden size of utterance encoder as 300. Furthermore, the hidden size of context encoder is 600, and the embedding size of topic is the same as the embedding size of dialog act is 30. The number of context RNN layers is 1. We set the hidden size of response decoder to 400, keep 10 utterances in the context window, and choose 40 as maximum number of words in an utterance. The dimension of latent variable is 200. We use word drop decoder as the same as Zhao et al. and set 10,000 batches before KL cost weight reaches 1, but change decoder keep probability to 0.95 for adding attention in kgCVAE. Training of models is optimized by Adam algorithm. 38 We change the initial learning rate to 0.005 and change the mini-batch size to 150 to make full use of GPU resources. Thus maximum number of epoch of training is 20 rather than 60. We set gradient clipping at 5 and set all the initial weights are [−0.08, 0.08] by sampled from a uniform distribution. But we change the dropout rate to 0.95 for adding attention in kgCVAE. Moreover, we adopt early stopping strategy as a regularization strategy and set the improve threshold and patient increase to 0.996 and 2, respectively. It is worth noting that although we change the decoder keep probability, initial learning rate, mini-batch size, and dropout rate, these parameter changes will not improve kgCVAE. We have verified this through experiments. In addition, we used a part of the experimental results from Zhao et al. as baselines.
Automatic evaluation
We choose three response generation models as baselines, including HRED, CVAE, and kgCVAE. Table 4 demonstrates the automatic evaluation results on SW corpus. It shows that our proposed method has greatly improved kgCVAE and is better than other models of baselines. It is noteworthy that our recurring kgCVAE is a little different from the experimental results of Zhao et al. Our BLEU-2 score for kgCVAE is higher than that of Zhao et al., but BLEU-4 is lower than Zhao et al. BLEU-1 and BLEU-3 have little fluctuations. Hu et al. 36 also found the same problem about recurring kgCVAE in their work. In order not to affect our study, we used our recurring kgCVAE as a baseline by referring to the study of Bahuleyan et al. As can be seen from Table 4, the improvement in kgCVAE + GS on perplexity and recall is very obvious, but it causes a significant decline on precision. KgCVAE + attention has a huge improvement on precision, but there is no obvious effect on recall. The effect of kgCVAE + GS + attention is remarkable, with significant improvements on both precision and recall from BLEU-1 to BLEU-4. And perplexity of kgCVAE + GS + attention is lower than kgCVAE. In summary, our proposed method improves the coherence of kgCVAE model generation dialog and improves the diversity of kgCVAE model generation dialog.
Experimental results on SW corpus.a

BLEU: bilingual evaluation understudy;
a Bold font indicates the method our proposed. The bold number of each column means the best experimental result for that column. BLEU scores are [0, 1] by normalized.
Case study
We created a case study on generated responses from kgCVAE and our method, as presented in Table 5. Table 5 illustrates that kgCVAE generates five types of responses including oh, oh i see, oh it’s, um - hum, and yeah; and our method generates six types of responses including yeah, um - hum, um - hum yeah, uh - huh, oh, and oh yeah. This means that the diversity of responses generated by our method is better than kgCVAE. In addition, Samples 5 and 9 generated by our method are completely consistent with Target B, and other responses generated by our method are all reasonable responses. However, kgCVAE does not generate a response exactly the same as Target B, and Sample 6 of kgCVAE is not a reasonable response. Therefore, the coherence of response generated by our method is better than kgCVAE. In summary, our method is better than kgCVAE in the coherence and diversity of response generation.
Generated responses from kgCVAE and our method.

kgCVAE: knowledge-guided conditional variational autoencoder.
Analysis
We visualized values of random sampling and the latent variable z of the prior network and tested the effectiveness of our proposed method on CVAE via model ablation of kgCVAE. In addition, we further explored the different effects by using greedy search decoder and using random sampling decoder in our method.
Visualization
We visually analyzed the random sampled values of the model by using TensorBoard, as shown in Figure 4. The kgCVAE uses a normal distribution for random sampling, and our improved method uses a gamma distribution for random sampling. The image presented by our method is basically in accordance with the Zipf’ law.

(a) Normal sampling in kgCVAE and (b) GS in our method. kgCVAE: knowledge-guided conditional variational autoencoder; GS: gamma sampling.
In addition, we also visualized the latent variable z of the prior network, as shown in Figure 5. Although the shape has changed, in general, the latent variable z image obtained by GS of our method is more in line with the Zipf’ law.

(a) The latent variable z of the prior network after normal sampling in kgCVAE and (b) the latent variable z of the prior network after GS in our method. kgCVAE: knowledge-guided conditional variational autoencoder; GS: gamma sampling.
Model ablation
CVAE is the basis of kgCVAE and can be regarded as a model ablation for kgCVAE. We added GS, attention, and GS + attention to CVAE to verify the effectiveness of our method for CVAE. The experimental results demonstrate that our method can also improve CVAE, as presented in Table 6. When CVAE + GS, perplexity drops sharply, and the precision and recall of BLEU-1 are greatly improved. The recall of BLEU-2 and BLEU-3 is greatly improved, and the precision from BLEU-2 to BLEU-4 is greatly reduced. At CVAE + attention, although perplexity has risen sharply, the precision from BLEU-1 to BLEU-4 has increased significantly. When CVAE + GS + attention, perplexity drops dramatically, and the precision and recall from BLEU-1 to BLEU-4 are greatly improved. Therefore, our improved method is also effective for CVAE.
Experimental results of model ablation.

BLEU: bilingual evaluation understudy; GS: gamma sampling; ATT: attention; CVAE: conditional variational autoencoder.
Bold font indicates the method our proposed. The bold number of each column means the best experimental result for that column.
Greedy search and random sampling
Our improved method uses greedy search decoder because both CVAE and kgCVAE use greedy search decoder. However, one of the baselines, HRED, uses random sampling decoder. Therefore, we also try to use random sampling decoder in our improved method. As presented in Table 7, regardless of kgCVAE + GS and kgCVAE + attention, or kgCVAE + GS + attention, random sampling decoder is not as good as greedy search decoder. Although the perplexity decreased slightly after random sampling decoder was used for kgCVAE + GS, the precision and recall from BLEU-1 to BLEU-4 decreased significantly. The same is true for kgCVAE + attention using random sampling decoder. When kgCVAE + GS + attention adopts random sampling decoder, perplexity drops a little, and the precision and recall from BLEU-1 to BLEU-4 drop sharply. Therefore, our improved method based on kgCVAE uses greedy search decoder better than random sampling decoder.
Experimental results of different types of decoder in our proposed method.

BLEU: bilingual evaluation understudy; GS: gamma sampling; ATT: attention; kgCVAE: knowledge-guided conditional variational autoencoder.
The bold number of each column means the best experimental result for that column.
Conclusions
In this article, we proposed an improved method based on kgCVAE for response generation in generation-based chatbots. This method can help kgCVAE achieve balance and improve the coherence and diversity of dialog generation, which is a key to generate meaningful and diverse response in generation-based chatbots. The experimental results demonstrate that our proposed method has greatly improved the coherence and diversity of kgCVAE for response generation in generation-based chatbots at the same time. In the future, we will study how to apply our proposed method to other applied variational autoencoder tasks and examine if GS with attention mechanism can improve other models.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article was supported by Beijing Municipal Science and Technology Project (Z171100005117002) and Open Fund of Key Laboratory for National Geographic Census and Monitoring, National Administration of Surveying, Mapping and Geoformation (2017NGCMZD03).