
Abstract
To enhance the capability of neural networks, research on attention mechanism have been deepened. In this area, attention modules make forward inference along channel dimension and spatial dimension sequentially, parallelly, or simultaneously. However, we have found that spatial attention modules mainly apply convolution layers to generate attention maps, which aggregate feature responses only based on local receptive fields. In this article, we take advantage of this finding to create a nonlocal spatial attention module (NL-SAM), which collects context information from all pixels to adaptively recalibrate spatial responses in a convolutional feature map. NL-SAM overcomes the limitations of repeating local operations and exports a 2D spatial attention map to emphasize or suppress responses in different locations. Experiments on three benchmark datasets show at least 0.58% improvements on variant ResNets. Furthermore, this module is simple and can be easily integrated with existing channel attention modules, such as squeeze-and-excitation and gather-excite, to exceed these significant models at a minimal additional computational cost (0.196%).
Keywords
Introduction
By interleaving a series of convolutional layers with nonlinear activation functions and downsample operators, convolutional neural networks (CNNs) 1 are able to produce robust representations that capture hierarchical patterns and attain global theoretical receptive field. Thus, CNNs become the paradigm of choice in many computer vision applications, such as image classification, 2 –5 object detection, 6 semantic segmentation, 7 and regression. 8,9 In recent years, attention mechanisms have been a new remedy for feature recalibration by capturing contextual long-range interactions. The attention mechanism started from the introduction of an attention module to draw global dependencies of inputs in neural machine translation, 10 and then, the landmark works about self-attention modules 11 sets a new standard in this field.
Self-attention mechanism is to measure the compatibility of the query and key content pairwise relations. In this field, one approach is that nonlocal network (NLNet) 12 presents a self-attention map to model the correspondence from all positions to each query position. Meanwhile, simplified attention models use a query-independent attention map for all query positions. In the recently proposed convolutional block attention module (CBAM), 13 a single spatial attention map is multiplied back to the channel-attention tuned feature maps for adaptive feature refinement. Our nonlocal spatial attention module (NL-SAM) builds on the benefits of NLNet with effective modeling on global contextual information and CBAM with an efficient attention map generation. NL-SAM incorporates three interdependent operations: context collecting, transformation, and distribution. Context collecting performs feature aggregation to obtain highly compressed global information in spatial dimension. Transformation provides a nonlinear way to recalibrate feature responses. Then, attention map is distributed to each location in the convoluted feature maps.
Our NL-SAM is general and efficient in terms of added parameters, it can be integrated into any CNN architectures individually while maintaining end-to-end trainable or existing channel attention modules with negligible overhead to serve as the complementary attention. We incorporate NL-SAM within ResNet 4 to validate through experiments on CIFAR-10, CIFAR-100, and ImageNet-1K classification datasets. In particular, as shown in Figure 1, deep CNNs embedded with our NL-SAM introduce very few additional computations while bringing notable performance gain. For example, for ResNet50 with 25.53M parameters and 6.995G floating point operations (FLOPs), the additional parameters and computations of NL-SAM are only 0.03M and 0.007G FLOPs, but the accuracy has been improved by 0.58%. And gather-excite network (GENet) 14 combined with NL-SAM reaches the highest accuracy (75.6%) with only 0.085% additional FLOPs (more details are given in Table 7).

Comparison of various attention modules embedded in ResNet50 in terms of accuracy and FLOPs on ImageNet, and the size of circles indicates parameter numbers. FLOP: floating point operation.
The rest of this article is organized as follows. The second section analyzes related works about attention mechanisms. The third section describes the architecture of the proposed NL-SAM and analyzes the relationship between NL-SAM and other attention modules. The fourth section verifies the effectiveness of NL-SAM throughout extensive experiments with various baseline models on multiple benchmarks. The fifth section concludes the article.
Related works
Convolution network architecture
The convolution layer has been the dominant visual feature extractor in computer vision. Recent advances of convolution networks focus on capturing long-range dependencies. 3,4 ResNet 4 solves the degradation problem caused by the increased depth of neural networks, thus, it is able to deliver information between distant positions by simply increasing the network depth. After that, another important direction is to modify the spatial scope for aggregation by enlarging the receptive field, such as atrous/dilated convolution. 7
Attention models
In vision, the key and query refer to visual elements, such as image pixels. Regular convolution can be deemed as a special instantiation of spatial attention mechanism. Given a query element, predetermined positional offsets of key elements are sampled. In the recently proposed attention mechanisms, there are two major patterns as follows.
Query-independent attention models
These models are irrelevant to the query content, and they only capture salient key contents, which should be focused on for the task. By computing a global attention map and sharing this map for all query positions, these models are very efficient. For example, squeeze-and-excitation network (SENet) 15 and GENet 14 perform rescaling to different channels to recalibrate the channel dependency. However, they miss the spatial axis, which is also important for inferring accurate attention maps. Bottleneck attention module (BAM) 16 and CBAM 13 introduce spatial attention using convolution in a similar way with a channel attention mechanism. However, in these spatial attention models, feature transformation is performed by convolution, which results in suboptimal effect for global context exploitation in CNNs.
Query-specific attention models
Motivated by their success in natural language processing (NLP) tasks, self-attention mechanisms have also been employed in computer vision applications, such as image recognition, 17 –21 relational reasoning among objects, 22,23 image segmentation, 17,24 scene parsing, 25 and video recognition. 26 Wang et al. 27 have proposed residual attention network, which uses an hourglass module to generate 3D attention maps for intermediate features. As attention maps are computed for each query position, the time and space complexity are both quadratic to the number of positions. To decrease the large computational overheads caused by the heavy map generation process, dual attention network 20 appends two parallel 2D and 1D attention modules on top of dilated fully convolutional networks (FCN). 28 However, they all have an obvious shortcoming—self-attention models contain a large number of matrix multiplication operations, which increases the computational burden.
Proposed method
In this section, we first overview two major attention modules NLNet 12 and CBAM, 13 and conclude a concise formula that summarizes these attention models. Then, we introduce the NL-SAM and describe its key components. In addition, we analyze the relationship between our NL-SAM and other attention modules.
Overview of attention modules
A representative query-independent attention model is CBAM, 13 which is formulated as


where

In this function, W
1 and W
0 are multilayer perceptron weights, ∀j enumerates all positions in the j’th feature map, and Np
is the number of positions in this feature map.
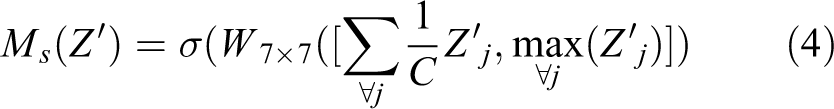
where
NLNet, 12 a typical query-specific attention module, can be expressed as
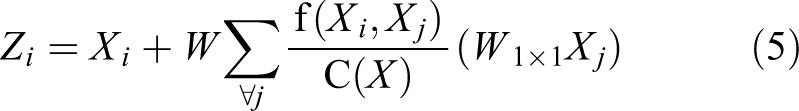
where i is the index of query positions and
After simplifying these attention models, a general attention modeling framework can be summarized as the following formula

Nonlocal spatial attention module
The structure of NL-SAM is shown in Figure 2, which can be roughly divided into three parts: context collecting, transformation, and distribution. According to equation (6), our NL-SAM is formulated as


The nonlocal spatial attention module.
In detail, our NL-SAM consists of
The first part is context collecting for global information aggregation. For simplicity, channel average pooling is used here. For a given feature block
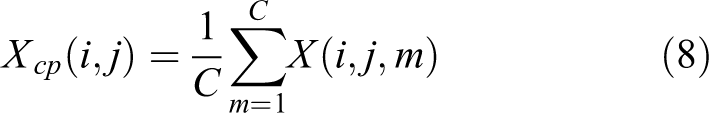
On the basis of channel compression, we further utilize average pooling to aggregate the channel-pooled feature maps. Experimental results in Table 2 demonstrate that pooling of adjacent pixels in early stages where NL-SAM inserted provides translation invariance needed for classification. The final aggregated feature map

where k is a hyperparameter of the pooling operation with different values at different stages,
The second part—feature transformation—has the largest number of parameters. Thus, a bottleneck transformation module is applied, which significantly reduces the number of parameters from
Accuracy (%) on CIFAR-100 test set by ResNet110 with different reduction ratio r.

FLOP: floating point operation.
The bold values indicate the highest accuracy in the comparison experiment.
Then, the 2D pooled feature map

where “fc” means full connection. Finally, the 1D results are restored to 2D, namely, the transformation results
The main calculation cost of NL-SAM is introduced by this part. The FLOPs are
In the last part, fusion function distributes the global context to the features of each position. While the transformed feature map has a width/height that is 1/k of the original size, experimental results in Table 3 draw a conclusion that nearest neighbor interpolation is the best choice to restore the size. The finally refined feature map is obtained by


where ⊗ denotes elementwise multiplication, and the same sized 2D spatial attention feature map
Relationship to other attention modules
We make a theory comparison for deeper analysis on the relationship to other attention modules. To aggregate global context from all positions, SENet 15 utilizes global average pooling, which assumes that every point in a feature map contributes the same to the whole, there is no spatial attention in this module, so it can serve as the channel aggregation block of our NL-SAM. GENet 14 and BAM 16 utilize depthwise global convolution or dilated convolution to obtain a large receptive field, since convolution finally sums up as a single result, it is only one point on our 2D attention map. In the fusion stage, SENet and GENet utilize rescaling to recalibrate a channel as a whole unit by one single parameter; BAM 16 utilizes broadcast elementwise addition; CBAM 13 is almost the same as us, the most sophisticated way is elementwise multiplication.
Our NL-SAM follows the NLNet
12
by acquiring a query-sensitive attention map, but we need to specify that there are two prominent features in this block. Firstly, we use dimension reduction to decompose channel attention and spatial attention. Secondly, we use the combination of
Experiment and analysis
In this section, we evaluate the performance of the proposed NL-SAM on a series of benchmark datasets, including CIFAR-10, CIFAR-100, and ImageNet. 29 Our experiments contain three parts. Firstly, ablation experiments are conducted to determine the optimal value of hyperparameters. Given limited computation resources, CIFAR-10 and CIFAR-100 are selected as experimental datasets. Our module surpasses ResNet on CIFAR datasets both in efficiency and accuracy. Secondly, we analyze the reciprocal relation of NL-SAM with other attention modules. Finally, to be more convincing, we compare classification results with ResNet50 variants on ImageNet. And evaluate original ResNets based on the official code of TensorFlow-Slim image classification model library. 30 Some parameters are modified due to limited computing resources, especially the batch size. For fair comparison, all the relevant attention models are reimplemented by TensorFlow-Slim.
CIFAR and analysis
Implementation details
We follow the simple data augmentation strategy in the literature
4
for training: images are randomly flipped horizontally and zero-padded on each side with four pixels before taking a random
Reduction ratio
The bottleneck compression rate r is intended to reduce redundancy in parameters. The value of average pooling kernel size k is fixed to 0, different values are set to determine the optimal value of r. As given in Table 1, r = 8 achieves a good balance between accuracy and complexity. So, this value is used in the rest of the experiments.
Effect on different inserting stages and pooling kernel size
The influence of NL-SAM is investigated on different stages (here the term “stage” is the same as defined in the literature 4 ) based on different inserting stages and different values of k, the accuracy, computational cost, and parameter numbers, as given in Table 2.
Effect of inserting NL-SAM at different stages with enumerated values of k on ResNet110 with r = 8.

NL-SAM: nonlocal spatial attention module; FLOP: floating point operation.
The bold values indicate the highest accuracy in the comparison experiment.
Based on the results listed in Table 2 and the corresponding Figure 3, we have the following observations: (1) deeper stage which has more semantic information benefits more from NL-SAM; (2) insertion at all stages are not mutually redundant, they can further bolster the accuracy; (3) pooling is not only to reduce the calculation cost but also to keep translation invariant in classification, since our module is position-sensitive, weight sharing within the pooling kernel is necessary to counteract this.

Accuracy of inserting NL-SAM at different stages with enumerate values of k on ResNet110 (r = 8). NL-SAM: nonlocal spatial attention module.
At the same time, the interpolation experiment is conducted in stage 2 with pooling kernel size of 2. The results of Table 3 verify that nearest-neighbor interpolation is the best choice. In fact, due to the previous average pooling of the feature map, the same weights are naturally shared within the
Accuracy(%) of interpolation on stage 2 of ResNet110 + NL-SAM with k = 2.

NL-SAM: nonlocal spatial attention module; FLOP: floating point operation.
The bold values indicate the highest accuracy in the comparison experiment.
Integration with different architectures
We evaluate our NL-SAM on the popular ResNet backbones, plain ResNet110 5 and ResNet164 5 with bottleneck. According to the above experiments, the structure and hyperparameters are determined, as given in Table 4. NL-SAM embedded in stage 1 of the network consumes more resources, but the effect is inferior to the later stages. Thus, it is the best choice to insert NL-SAM into stage 2 and stage 3 with k set to 2, and the results are reported in Table 5. It can be found that NL-SAM consistently improves performance across different depths with a small increase in FLOPs.
Architecture of ResNets and parameters of NL-SAM.

NL-SAM: nonlocal spatial attention module.
Classification accuracy (%) on CIFAR-10/100 test set with NL-SAM embedded in ResNet110 and ResNet164.

NL-SAM: nonlocal spatial attention module; FLOP: floating point operation.
The bold values indicate the highest accuracy in the comparison experiment.
Combination with other attention modules
Comparative experiments are conducted on CIFAR-100 by integrating NL-SAM with SENet and GENet to serve as complementary spatial attention. Average pooling is used in SENet, global depthwise convolution is used in GENet, and bottleneck reduction ratio is set to 4 with sigmoid activation in both SENet and GENet. In Figure 4, the comparison of parameter numbers and accuracy of different models are explicit. It shows that NL-SAM can further improve the accuracy of SENet and GENet by about 0.2% with less than 0.002M parameters added. Furthermore, we replace spatial attention module in CBAM with NL-SAM. In the third column of the figure, we can see that this replacement variant outperforms the original CBAM by 0.32%. It suggests that the designed query-sensitive spatial attention in NL-SAM is superior to query-independent spatial attention in CBAM.

(a, b) Experiments on CIFAR-100 for NL-SAM combined with SENet, GENet, and CBAM. NL-SAM: nonlocal spatial attention module; SENet: squeeze-and-excitation network; GENet: gather-excite network; CBAM: convolutional block attention module.
ImageNet and analysis
Implementation details
This dataset contains 1.2 million training images and 50k validation images, each is cropped to
Classification results on ImageNet
Based on the ablation experiments on CIFAR, the hyperparameters of ResNet50 for ImageNet are defined in Table 6. Due to the large feature map size and insertion stage position study on CIFAR, we add NL-SAM in stages 3, 4, and 5.
Architecture of ResNet50 and the hyperparameters r and k of NL-SAM.

NL-SAM: nonlocal spatial attention module.
We further analyze the effectiveness of NL-SAM by the splitting and combination experiments. The results of the final models are given in Table 7. It can be found that our module is able to effectively improve the accuracy even on large datasets. Compared with SENet and GENet, NL-SAM is slightly inferior but still has a notable improvement on ResNet50 baseline. The best result is produced when NL-SAM is integrated with GENet. CBAM seems to be unsteady, which does not reach the baseline result, but when integrated with NL-SAM, the accuracy is improved by 0.22%. These experiments verify the consistent improvement of NL-SAM when integrated with channel attention modules. NL-SAM exhibits the ability to use without bells and whistles.
Classification accuracy (%) on ImageNet validation set with embedded NL-SAM, CBAM in ResNet50, SENet50, and GENet50.

NL-SAM: nonlocal spatial attention module; FLOP: floating point operation.
The bold values indicate the highest accuracy in the comparison experiment.
Analysis and discussion
We compare the visualization results of NL-SAM inserted to ResNet50 or combined with other modules. The grad-CAM 31 visualization is calculated for the last convolution layer outputs, ground-truth label is shown on the top of each input image and P denotes the softmax score of each network for the predicted class. As shown in Figure 5, according to P’s score, ResNet50 misclassifies siamese cat and obtains the lowest score. ResNet50 + GE + NL-SAM always gets the highest score, ResNet50 + NL-SAM and ResNet50+ GENet both have their own advantages. We can clearly see that NL-SAM integrated networks have a good incentive or suppression in some regions. For example, they focus more precisely on the head of the merganser and pay less attention to the water, and attention on the whole body of siamese cat shows the benefit of global visual field.

Grad-CAM visualization results. Grad-CAM: gradient - class activation map.
Conclusion
We propose the NL-SAM, which is a new method to enhance the representation ability of the network. Through modeling on global contextual information, our module learns where to focus or suppress, and refines intermediate features. To verify its effectiveness, extensive experiments were conducted on three benchmark datasets. The results show that NL-SAM improves classification accuracy by 0.98% on CIFAR-10, 1.01% on CIFAR-100 when embedded in ResNet110, and 0.58% on ImageNet when embedded in ResNet50. What is more, the combination of NL-SAM and GENet improves accuracy on ImageNet by 1.05% with only 0.038G FLOPs added. For future works, we plan to devise a flexible way to switch between NL-SAM and convolution in a layer.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Foundation of China [Grant Nos. 61701351] and the Fundamental Research Funds for the Central Universities of CCNU [No. CCNU16A05028].