
Abstract
Effectively and efficiently recognizing multi-scale objects is one of the key challenges of utilizing deep convolutional neural network to the object detection field. YOLOv3 (You only look once v3) is the state-of-the-art object detector with good performance in both aspects of accuracy and speed; however, the scale variation is still the challenging problem which needs to be improved. Considering that the detection performances of multi-scale objects are related to the receptive fields of the network, in this work, we propose a novel dilated spatial pyramid module to integrate multi-scale information to effectively deal with scale variation problem. Firstly, the input of dilated spatial pyramid is fed into multiple parallel branches with different dilation rates to generate feature maps with different receptive fields. Then, the input of dilated spatial pyramid and outputs of different branches are concatenated to integrate multi-scale information. Moreover, dilated spatial pyramid is integrated with YOLOv3 in front of the first detection header to present dilated spatial pyramid-You only look once model. Experiment results on PASCAL VOC2007 demonstrate that dilated spatial pyramid-You only look once model outperforms other state-of-the-art methods in mean average precision, while it still keeps a satisfying real-time detection speed. For 416 × 416 input, dilated spatial pyramid-You only look once model achieves 82.2% mean average precision at 56 frames per second, 3.9% higher than YOLOv3 with only slight speed drops.
Introduction
Real-time multi-scale object detection is one of the most challenging tasks in computer vision. Generally, the traditional object detection algorithms are composed of three stages: select candidate regions on the given image, extract features from these regions, and finally classify each region with trained classifier. The performance of such kind of algorithms generally depends on the expression ability of features extracted by designers.
In recent years, with the development of big data technology and the improvement of computing performance, deep convolutional neural networks (DCNNs) have achieved significant advances in object detection. Existing object detection algorithms based on DCNN can be roughly divided into two categories: (1) two-stage methods, mainly including R-CNN, 1 Fast R-CNN, 2 Faster R-CNN, 3 and R-FCN 4 and (2) one-stage methods, mainly including You only look once (YOLO) 5 and Single Shot MultiBox Detector (SSD). 6
The two-stage methods firstly generate a series of region proposals and then do feature extraction with CNN for classification and bounding box regression. Although the two-stage methods have achieved competitive performance, they are too slow for real-time applications due to its intensive computation cost.
The one-stage methods consider object detection as a single regression problem and are able to realize real-time detection due to its high computational efficiency, while its accuracy is usually lower than that of those two-stage methods. YOLO 5 and SSD 6 are two representative one-stage methods. The YOLO algorithm has gone through three stages of development: (1) YOLO 5 divides the input image into s × s gird cells, but each grid cell can only predict one kind of objects and, therefore, YOLO has difficulty on dense and small object detection; (2) YOLOv2 7 improves the base network of YOLO and adopts anchor mechanism and multi-scale training method, consequently, both accuracy and speed have been improved; and (3) YOLOv3 8 proposes a new network Darknet-53 and predicts objects at three different scales. Considering the algorithm performance, for 320 × 320 input, YOLOv3 achieves 28.2% mean average precision (mAP) in 22 ms on MS COCO data set, being as accurate as SSD but with a three-time faster speed.
Although YOLOv3 has very good performance on small object detection with multi-scale predictions, it performs relatively worse on medium and larger size objects. 8 Much has been done to improve the accuracy of the YOLO algorithm. In 2018, Li and Yang 9 replaced the standard convolution with depth-wise separable convolution and introduced feature pyramid network (FPN) 10 into the detection module in YOLOv2 to reduce parameters and improve feature extraction ability, and the improved YOLOv2 algorithm outperforms YOLOv2 on small object detection. In 2019, Zhang et al. 11 added three residual blocks to the bottom of residual network of original YOLOv3 and designed six multi-scale convolutional feature maps for prediction to formulate DF-YOLOv3 model, thus improving the vehicles detection accuracy in complex scenes. To make full use of multi-scale feature maps, Huang and Wang 12 proposed DC-spatial pyramid pooling (SPP)-YOLO model, which adopted dense connection and an improved SPP 13 module to YOLOv2. Xu et al. 14 proposed Attention-YOLO, in which channel and spatial attention mechanism is added to the feature extraction network of YOLOv3; as a result, Attention-YOLO achieves about 0.6% AP50 higher than YOLOv3 on MS COCO data set.
Although the above improved YOLO algorithms improve the accuracy, the inference speed decreases obviously at the same time, and recognizing objects at multiple scales is still the challenging problem for YOLOv3 which is waiting to be improved.
There are a variety of ways to remedy the scale variation problem for object detector. The direct but inefficient method is to extract features and predict different scales of images, such as image pyramid, 15 which is widely used in hand-engineered feature-based methods. 16,17 Instead of taking multiple scales of images as input, one kind of methods deals with scale variation problem by exploiting multiple layers in CNN. SSD 6 used a pyramidal feature hierarchy structure to perform object detection at different layers and finally combined predictions from multiple feature maps with different resolutions to deal with objects of various sizes. FPN 10 utilized a top-down architecture with lateral connections to build high-level semantic feature maps at all scales, which has shown significant improvements over several baselines. Feature Fusion Single Shot Multibox Detector (FSSD) 18 concatenated features from different layers with different scales and then generated a new pyramidal feature hierarchy structure to predict objects by down-sampling the concatenation layer for several times; as a result, FSSD improved the accuracy significantly over SSD with only a slight decrease on speed. PANet 19 added bottom-up path augmentation to the FPN, which shortened the information path between low-level feature maps and high-level feature maps to enhance the feature fusion structure.
Instead of conducting feature fusion between different layers with different resolutions, some other methods resample the feature maps at the same scale to obtain multi-scale information. He et al. 13 proposed a feature extraction module named SPP, which resampled the feature maps by using different pooling rates, and test results showed that the objects at different scales can be accurately classified by resampling the same feature maps. Liu et al. 20 proposed a receptive filed block (RFB) module consisting of multi-branch convolution layers with different dilation rates and kernels, and by simply replacing the top convolution layers of SSD with RFB, the performance get significantly improved. Sachin Mehta et al. 21 proposed an efficient spatial pyramid consisting of spatial pyramid of dilated convolutions and point-wise convolutions for semantic segmentation.
YOLOv3 adopts the method that exploiting multiple layers for detection and thus the performance of small object detection is improved, but it still performs relatively worse on medium and larger objects. Inspired by the method that resampling the feature maps at the same scale, a novel dilated spatial pyramid (DSP) module is proposed in this article to integrate multi-scale information by resampling the feature maps to deal with scale variation problem.
The main contribution of this article is as follows: A novel DSP module consisting of multiple parallel branches with different dilation rates is proposed to learn multi-scale information from large effective fields to deal with scale variation problem. DSP-YOLO is presented by integrating DSP module to YOLOv3 in front of the first detection header and it gains significant improvement in accuracy, while it is still able to maintain comparable speed with YOLOv3. Experiments are designed to explore the optimal number of branches and fusion method of DSP and evaluate the performance among DSP-YOLO and other state-of-the-art object detectors.
The experiment results demonstrate that our DSP-YOLO model outperforms other state-of-the-art object detection methods in accuracy on PASCAL VOC2007, while it is still able to keep a satisfying real-time detection speed.
Proposed methods
The structure of original YOLOv3 is shown in Figure 1. Through extracting features from three different scales and combing low-resolution and high-resolution features via a top-down pathway and lateral connections, YOLOv3 improves the performance of small object detection ability, but it still performs relatively worse on medium and large size objects. 8

The structure of YOLOv3. YOLOv3 predicts objects at three different scales and finally combines the results to get the final detection. YOLO: You only look once.
Theoretically, the detection performance on objects with different scales is influenced by the effective receptive field of the network. Large effective receptive field could be used to enhance the performance of larger scale object detection, but it compromises the performance on small objects at the same time. 22 Thus, exploiting multi-scale receptive fields is one of the ways to improve the ability of multi-scale object detection.
Large effective receptive fields can be achieved by conducting down-sample operation, increasing convolutional layers, applying dilated convolution (atrous convolution), 23 and enlarging the size of the convolutional kernel. Suppose the down-sample rate is s, then the receptive field is increased by s times, while the resolution of the feature map is reduced by s times, which may result in information loss. Increasing both convolutional layers and the kernel size of convolutional filters increases the receptive field at the cost of increasing the number of parameters and deep network may cause the problem of vanishing gradient during training process. Dilated convolution expands the convolutional kernel by inserting holes between each pixel, enlarging the effective receptive filed without additional parameters and computations cost. As shown in Figure 2, dilation rate m means inserting m − 1 holes between each pixel and the dilated convolution is equal to standard convolution when dilation rate is set as 1.
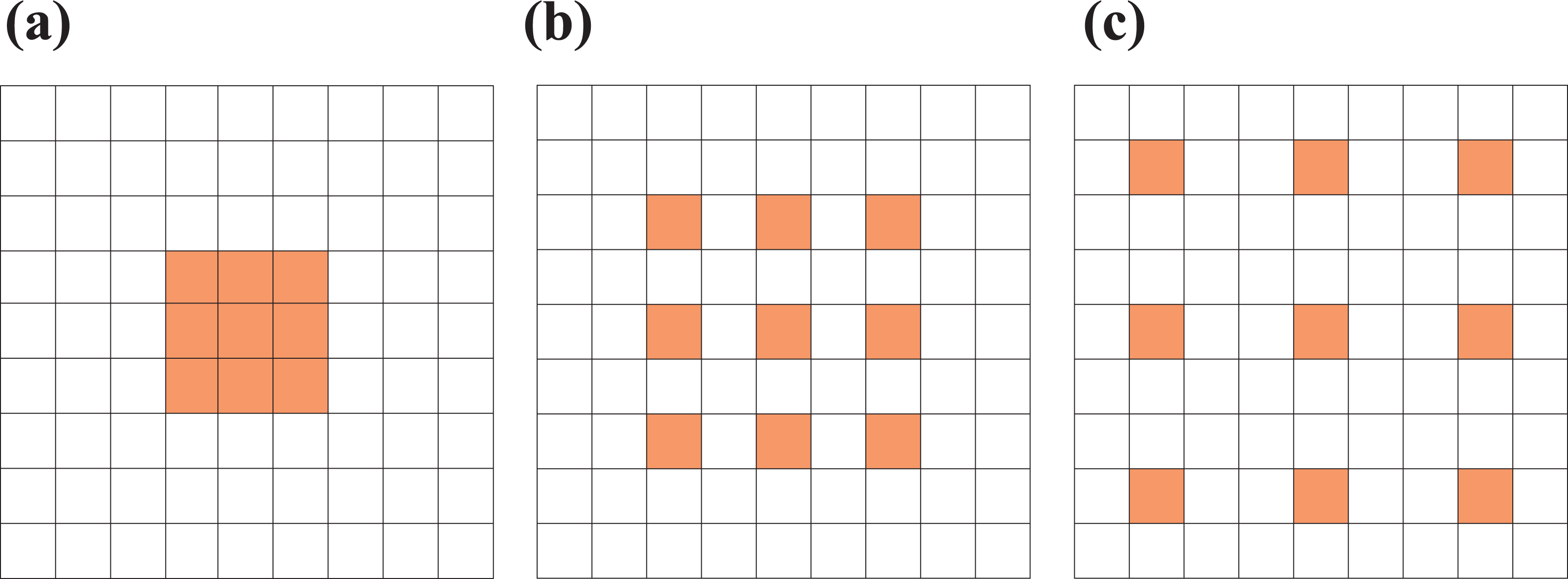
Dilated convolution with 3 × 3 kernel size and different dilation rates: (a) the dilation rate is 1, (b) the dilation rate is 2, and (c) the dilation rate is 3.
Suppose the kernel size of the dilated convolution is k, dilation rate is r, then the actual kernel size k′ is
Suppose stride is 1, a k × k dilated convolution can obtain the same receptive fields as the standard convolution with kernel size of
Dilated convolutional layers with different dilation rates will generate different receptive fields, so the choice of dilation rate depends on the scale of the object to be measured. To deal with scale variation problem, the receptive fields are expected to balance between small- and large-scale objects. Inspired by SPP, a novel DSP module consisting of multiple parallel branches with different dilation rates is proposed in this article. As shown in Figure 3, in DSP structure, the multiple parallel branches resample the convolutional feature maps using a 3 × 3 convolution with different dilation rates simultaneously to generate feature maps with different receptive fields. The kth branch uses dilation rate k and the padding parameter
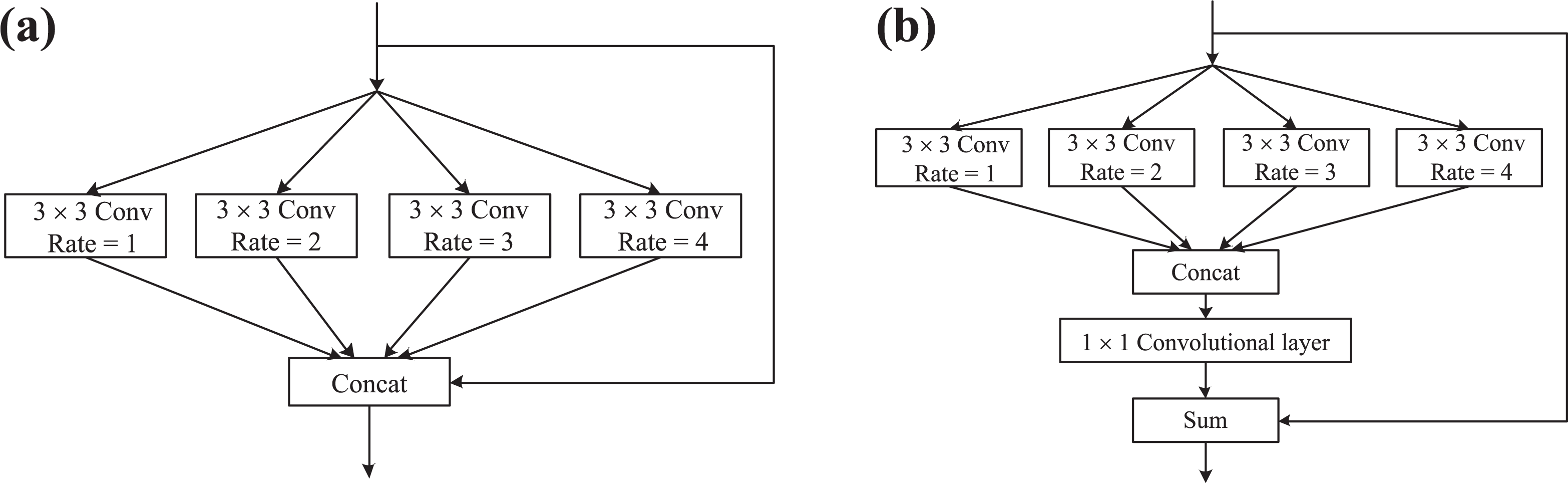
The structure of DSP module: (a) the input of DSP and outputs of different branches are concatenated to integrate multi-scale information; (b) using element-wise addition between the input of DSP and output of 1 × 1 standard convolutional layer to improve the gradient flow inside the network. DSP: dilated spatial pyramid.
The first method is concatenation. As shown in Figure 3(a), the input of DSP a module and outputs of different dilated convolutional layers are concatenated in the channel dimension of feature maps to obtain richer semantic information.
The second method is element-wise addition operation. As shown in Figure 3(b), the outputs of different branches are concatenated in the channel dimension of feature maps. The following 1 × 1 standard convolutional layer is used to reduce the number of the channel of feature maps, since element-wise addition is performed on two feature maps channel by channel, requiring the input and output are of the same dimensions. To improve the gradient flow inside the network, the element-wise addition is performed between the input of DSP b module and output of 1 × 1 standard convolutional layer.
As shown in Figure 4(a), the DSP a module is integrated with YOLOv3 after the third convolutional layers in the first convolutional set (the gray block in Figure 1) and 1 × 1 standard convolutional layer is added following DSP a module to reduce dimensions, leaving the 3 × 3 convolutional layer with smaller input dimensions to reduce computation.

The structure of convolutional set before the first detection header of DSP-YOLO. (a) DSP a is integrated after the third convolutional layer in the first convolutional set and 1 × 1 convolutional layer is added to reduce dimensions; (b) DSP b is integrated between the third and fourth convolutional layers in the first convolutional set. DSP: dilated spatial pyramid; YOLO: You only look once.
The DSP b module is integrated with YOLOv3 between the third and fourth convolutional layers in the first convolutional set (the gray block in Figure 1) to present DSP-YOLO b model. The corresponding structure is shown in Figure 4(b).
Experiments
The performance of the DSP-YOLO is compared with state-of-the-art object detection methods on PASCAL VOC 2007 data set, 24 which has 20 categories, and mAP and frames per second (FPS) are used to evaluate the performance of our approach.
Regarding the experiment on VOC2007 test, the union of VOC2007 trainval and VOC2012 trainval is used as the training data and the VOC2007 test (4952 images) as the test data.
Experiment condition
The proposed model is trained on GPU, and the detailed experimental configurations are listed in Table 1.
Experimental configurations.

Training strategy
The DSP-YOLO is based on Darknet53, which is pretrained on the ImageNet, 25 and it is trained in a batch size of 64 on a Titan Xp GPU with a starting learning rate of 10−3, which is divided by 10 at 40,000 and 45,000 iterations. The max training iteration is 60,000, the weight decay is 0.0005, and momentum is 0.9. The training strategies mostly follow YOLOv3, including multi-scale training, data augmentation, convolutional with anchor boxes, and loss function. For a fair comparison, the YOLOv3 and YOLOv3-spp are trained in the same way as that of DSP-YOLO.
Ablation study on VOC2007
The number of branches in DSP module
To find the optimal number of branches in DSP, DSP-YOLO a with different number of branches is evaluated on PASCAL VOC2007, and the performance evaluated with 320 × 320 input is recorded in Table 2. According to the results in Table 2, with three branches, DSP-YOLO a achieves 79.8%, 4.2% higher than the original YOLOv3, demonstrating that the DSP structure indeed improves the performance of YOLOv3 though with slight speed drop. With five branches, DSP-YOLO a achieves 79.7% mAP, 0.3% lower than that with four branches, indicating that five branches do not bring further improvement over four branches. Considering the accuracy and speed, the branches of DSP module is selected as 4.
PASCAL VOC2007 test detection results with different number of branches.
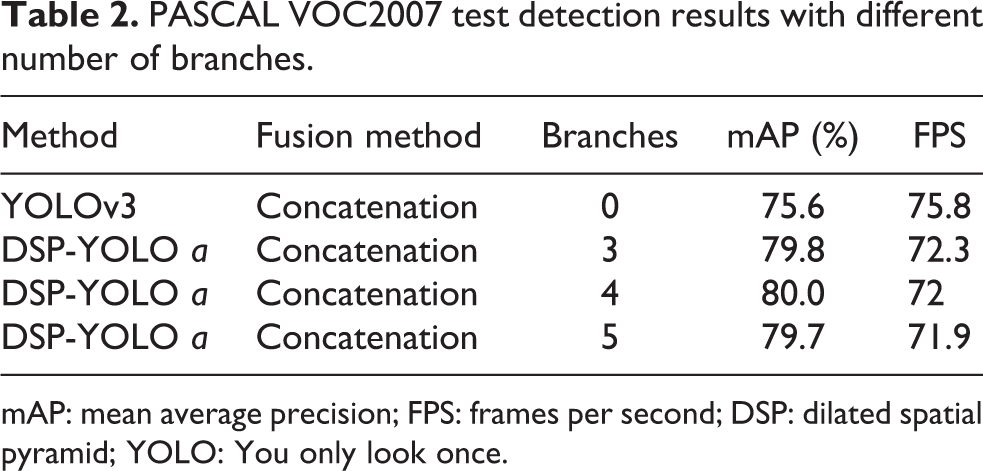
mAP: mean average precision; FPS: frames per second; DSP: dilated spatial pyramid; YOLO: You only look once.
Fusion method of feature maps in DSP module
To evaluate the performances of different fusion methods of feature maps in DSP module, DSP-YOLO a and DSP-YOLO b are evaluated on PASCAL VOC2007, and the performances evaluated with 320 × 320 input are recorded in Table 3. According to the results in Table 3, DSP-YOLO a achieves 80.0% mAP, little higher than that of DSP-YOLO b, indicating that concatenation is more effective for feature maps fusion in DSP module. Considering the accuracy and speed, the DSP-YOLO a with 4 branches is selected and called DSP-YOLO.
PASCAL VOC2007 test detection results with different fusion methods in DSP module.

mAP: mean average precision; FPS: frames per second; DSP: dilated spatial pyramid; YOLO: You only look once.
Experiments on PASCAL VOC 2007
Table 4 shows the PASCAL VOC2007 test detection results. Since Redmon and Farhadi did not present the results of the original YOLOv3 and YOLOv3-spp on PASCAL VOC 2007 test in this article, 8 the YOLOv3 and YOLOv3-spp are trained in the same training strategies as DSP-YOLO based on this article to get the benchmark results.
PASCAL VOC2007 test detection results.

mAP: mean average precision; DSP: dilated spatial pyramid; YOLO: You only look once; SPP: spatial pyramid pooling; SSD: Single Shot MultiBox Detector.
The boldface values represents the maximum value in the column.
With low-dimension input images (e.g. 320 × 320), DSP-YOLO achieves 80.0% mAP, 1.0% lower than DSSD513. 26 However, with high-dimension input (e.g. 608 × 608), DSP-YOLO can produce 83.1% mAP, much better than other improved YOLO models, like DC-SPP-YOLO 12 and other state-of-the-art methods like R-FCN, 4 DSSD513, 26 STDN513, 27 and so on.
For 416 × 416 input, compared to original YOLOv3, DSP-YOLO improves detection performance in almost every category, improving the ability for multi-scale detection, which proves the effectiveness of the proposed DSP module.
Inference time
Table 5 presents the comparison test results among the proposed DSP-YOLO and the state-of-the-art object detection methods in mAP and FPS on PASCAL VOC2007 test. With NVIDIA Titan Xp and CUDA 9.1, DSP-YOLO achieves 82.2% mAP at 56 FPS with input 416 × 416, being as accurate as RFB Net512 but much more faster. For high-dimension input (e.g. 608 × 608), DSP-YOLO achieves 83.1% mAP at 31 FPS, surpassing other state-of-the-art object detection models including two-stage and one-stage methods and other improved YOLOv3 algorithms, while it still maintains real-time detection speed.
Comparison of object detection methods on PASCAL VOC2007 test.
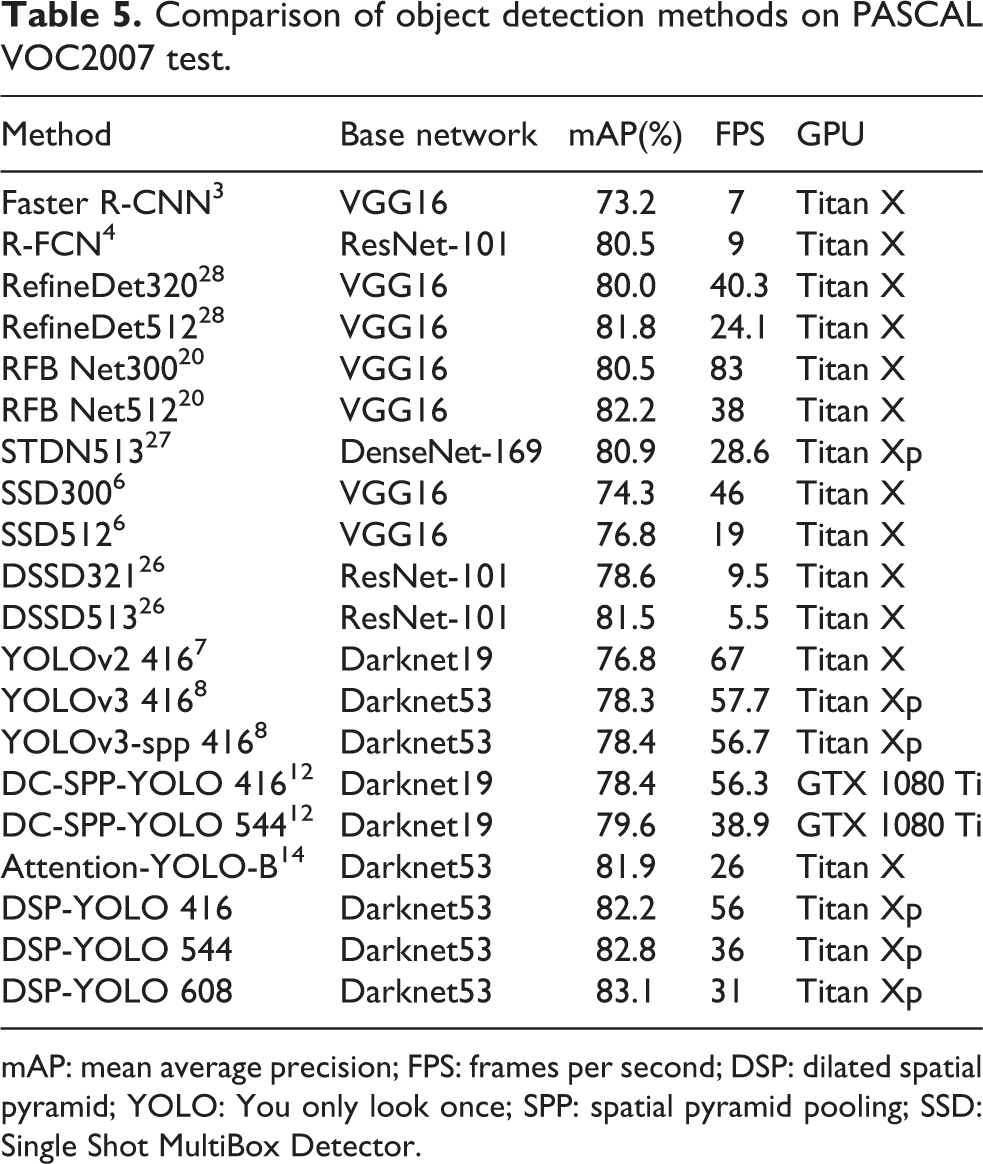
mAP: mean average precision; FPS: frames per second; DSP: dilated spatial pyramid; YOLO: You only look once; SPP: spatial pyramid pooling; SSD: Single Shot MultiBox Detector.
Visualization
In Figure 5, we show several detection examples of YOLOv3 and DSP-YOLO on PASCAL VOC2007 test. Compared to original YOLOv3, the proposed DSP-YOLO model improves in two scenarios. The first scenario is for detection on multi-scale objects. YOLOv3 has relatively poor performance on medium and larger object detection and has the problem of false detection (the false detection “train” and “aeroplane” in Figure 5(a)), repeated detection (Figure 5(c)) and missed detection (Figure 5(c), (e), and (g)), but DSP-YOLO shows significant improvement, as shown in Figure 5(b), (d), (f), and (h). And comparing Figure 5(i) with Figure 5(j), DSP-YOLO also works well on small object detection. The second scenario is for detection on occluded object. As shown in Figure 5(a) to (d) and (k) to (n), objects which are heavily occluded are well detected with DSP-YOLO.

Comparison of detection results of YOLOv3 and DSP-YOLO. The first column shows the results of YOLOv3 and the second column is the result of DSP-YOLO. DSP: dilated spatial pyramid; YOLO: You only look once.
Conclusions
To improve the multi-scale object detection performance of YOLOv3, in this article, a novel DSP module consisting of multiple parallel branches with different dilation rates is proposed and integrated with YOLOv3 in front of the first detection header to present DSP-YOLO model. Experiments show that our DSP-YOLO model outperforms YOLOv3 on PASCAL VOC2007 for not only its medium and larger object detection ability but also its detection ability on occluded and small objects, and at the same time, it is still able to maintain the comparable speed as that of YOLOv3. What’s more, for 608 × 608 input, DSP-YOLO achieves 83.1% mAP, surpassing other state-of-the-art object detectors on PASCAL VOC2007 while keeping the real-time speed. In addition, although the DSP module is only applied to YOLOv3 in this article, it can act as a generic solution for scale-invariant representations and can be integrated with other object detectors like SSD.
In the future work, DSP-YOLO will be applied to the autonomous driving filed to deal with the car and people detection in both close and far scene.
Footnotes
Acknowledgements
The authors would like to thank the support from Jiangsu Overseas Visiting Scholar Program for University Prominent Young & Middle-aged Teachers and Presidents.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has supported by the projects of the National Key Research and Development Plan of China [Grant Number: 2016YFB0502103] and the Natural Science Foundation of Jiangsu Province of China [Grant Number: BK20160696].