
Abstract
With the development of technology, human motion capture data have been widely used in the fields of human–computer interaction, interactive entertainment, education, and medical treatment. As a problem in the field of computer vision, human motion recognition has become a key technology in somatosensory games, security protection, and multimedia information retrieval. Therefore, it is important to improve the recognition rate of human motion. Based on the above background, the purpose of this article is human motion recognition based on extreme learning machine. Based on the existing action feature descriptors, this article makes improvements to features and classifiers and performs experiments on the Microsoft model specific register (MSR)-Action3D data set and the Bonn University high density metal (HDM05) motion capture data set. Based on displacement covariance descriptor and direction histogram descriptor, this article described both combine to produce a new combination; the description can statically reflect the joint position relevant information and at the same time, the change information dynamically reflects the joint position, uses the extreme learning machine for classification, and gets better recognition result. The experimental results show that the combined descriptor and extreme learning machine recognition rate on these two data sets is significantly improved by about 3% compared with the existing methods.
Keywords
Introduction
With the rise of big data on the Internet, the explosive growth of information, and the widespread application of machine learning algorithms such as deep learning in the Internet field, artificial intelligence has once again entered a period of rapid development. 1 –3 At present, the main concern of the market is robot technology. Robot technology is a modern technology that integrates multiple technologies. With the development of big data technology, robot technology has become more and more widely used in the modern industry. 4,5 Robot technology has the following characteristics: First, it has a high degree of freedom and a strong ability to control the system. In the modern professional industry, to achieve high control of the system, the robot will show a high degree of freedom to meet the needs of different programs; the second is that the robot depends on the Internet of Things and big data in the process of operation technical support, through the use of Internet technology to achieve automatic control of robots; and the third is to have high computing and information feedback. 6,7 Through the joint research of robot technology and computer vision to study human behavior recognition, analyzing and identifying different actions from video data are very important in many visual applications. 8 For example, in the field of security monitoring, human motion recognition is used in video surveillance systems, which can automatically warn of emergencies, which is of great significance in urban law and order, fire protection, and traffic dispatching; in the field of intelligent monitoring, it can fall in the elderly or children or send out an alert when a dangerous behavior is made for timely rescue; to a certain extent, it can solve the problem that some contemporary people have no time to take care of the elderly and children; and in the field of health care, by studying the performance of human gait, it can hurt the legs of patients. The degree of analysis is used to develop the best treatment plan. In the field of virtual reality technology, the somatosensory games and virtual fitting rooms that are currently popular among young people are the application of human motion recognition technology. 9–11 It can be seen that computers and smart devices are increasingly becoming an essential part of our lives. The growing demand for these smart devices has increased the need to use simple and practical smart systems. Therefore, systems based on visual interaction and control are becoming more and more common, and motion recognition is becoming more and more popular in the research field because of its wide application in various fields of human–computer interaction. However, in terms of calculation of exercise volume, the research is relatively simple. 12,13 For example, recently popular step counting software and applications such as sports bracelets and WeChat sports are counting walking movements and calculating caloric calories. This kind of equipment and software does not recognize the motion accurately, which further leads to inaccurate step counting results, so the results obtained when calculating the calories consumed by exercise are also inaccurate. The research value of body motion behavior recognition is more and more important in the world today, and the number of people who pay attention to this research will be more and more. 14 The research topics of motion recognition include image processing technology, machine learning, pattern recognition, artificial intelligence, and other fields. It is a research area combining various technologies. As a key technology, motion recognition technology has been paid more and more attention by scholars, and many schools, research institutions, and scholars have invested in this work and achieved some success, such as MIT, Carnegie Mellon University Colleges, and universities, and have established specialized research laboratories to carry out this research work. 15 –17
This requires extracting each frame of image from the video and then recognizing the human body from the image, further recognizing the human motion. 18 Therefore, estimating a person’s complete three-dimensional (3-D) pose from an RGB image is one of the most challenging problems in computer vision. This involves dealing with two tasks that are inherently confusing. 19,20 First, the two-dimensional (2-D) position of the human joint point or landmark must be found in the image, which is a blur due to the huge change in visual appearance caused by the viewpoints of different cameras, external and self-occlusion, or changes in clothing, body shape, and lighting. Sexual problems. 21 Secondly, it is still an uncertain problem to upgrade the coordinates of 2-D landmarks from a single image to 3-D. The number of 3-D spaces that can be formed consistent with the position of 2-D landmarks of humans may be infinite. 22 Finding the correct 3-D pose that matches the image requires injecting additional information, which is usually in the form of 3-D geometric pose priors and time or structural constraints. In the field of computer vision, due to its complexity and variability, human movements and poses have always been the focus of attention. 23 Although video retrieval and classification technology has been widely used, the problem of human motion recognition has not been solved well. 24 First of all, there are too many human bones, and each bone has multiple degrees of freedom, which makes the performance of human movements extremely complicated. In addition, different activities of the human body may have similar movements, such as the two actions of shooting and waving. It can be easily identified, but if you only look at the limb movements, the existing recognition algorithms may be difficult to distinguish, and the above problems need to be solved urgently. 25
To solve the problem of human motion recognition based on hidden Markov model (HMM), Pichao solved the problem of reducing the dimension of feature space. First, they describe how to derive different features from human motion capture based on markers and define a total of 29 features and a total of 702 dimensions to describe human motion. They then proposed a strategy for systematically exploring the space of possible subsets of these features and identifying meaningful low-dimensional feature vectors for motion recognition. They evaluated our approach using a data set of 353 movements, which were divided into 23 different types of full-body movements. Their results show that the low-dimensional feature space is sufficient to achieve high motion recognition performance, and using only four dimensions, they can achieve 94.76% accuracy on the data set, which is quite high-dimensional compared to the feature vector considering many features, such as joint angles. 26 In recent years, smartphone-based human motion recognition has received increasing attention in many fields such as mobile health, health tracking, and pervasive computing. However, changes in mobile phone orientation and position can easily affect motion recognition performance. Different users also have an impact on recognition accuracy. Most of the existing work focuses on one or two aspects of the above problems or training different models for different phone positions and directions. Peng proposed a universal framework for human motion recognition based on smartphones, which can effectively distinguish six daily movements, regardless of the position and orientation of the device. They chose a set of more powerful and effective features to solve the performance degradation caused by different phone locations, phone orientations, and users. In the experiment, they used data sets collected by three volunteers on Android smartphones to access our methods. Experimental results show that the proposed feature extraction algorithm is superior to most existing algorithms. 27
Sevgi proposes a new human motion recognition framework based on HMM, namely hybrid event probability sequence (HEPS), which can identify unlabeled motion in video. First, the center of the moving object is used to extract the trajectory effectively. Second, HEPS is constructed using these trajectories, which represent different human behaviors. Finally, an improved particle swarm optimization (PSO) with inertial weights is introduced to recognize human actions using HMM. The proposed method was evaluated on the University of central Florida (UCF) human behavior data set with an accuracy rate of 76.67%. Comparative experimental results show that HMM has better effect than HEPS and PSO. 28 Wang et al. proposed a variety of human motion pattern recognition algorithms based on microelectromechanical system (MEMS) inertial sensors, which solved the problem of low pattern recognition accuracy in various human motion pattern recognition. The time-domain features of the MEMS acceleration sensor are selected as the features of pattern recognition. The time-domain features of MEMS gyroscopes are used as features to aid recognition. The algorithm can accurately identify a variety of motion patterns, including walking, running, standing, going upstairs, going downstairs, falling forward, falling backward, and walking backward. A hierarchical recognition algorithm is used in the recognition process. Support vector machines (SVMs) are trained to recognize these two types of motion patterns because they are difficult to distinguish. Experiments based on the embedded firefighter positioning system platform show that the recognition algorithm can recognize multiple movement modes of firefighters with an average accuracy rate of more than 94%. 29
Depth motion maps (DMMs) have shown effectiveness for human motion recognition; however, they have lost time information and suffered intraclass changes due to changes in motion speed. To solve these challenges, Javid proposed a new method for human motion recognition. First, an adaptive layered DMM (AH-DMM) is calculated on the temporal layered window of the video sequence to capture temporal information. In addition, adaptive windows and steps are used to ensure that the AH-DMM is robust to changes in motion speed. Then, the Gabor filter is used to encode the texture information of the AH-DMM to generate a compact and differentiated motion representation. Finally, the representation is used as an input to the collaborative representation classifier. Experimental results on the public benchmark MSR-Action3D data set and DHA data set prove that the method is better than the latest depth-based action recognition method. 21
The covariance descriptor and the direction displacement histogram descriptor (HOD) are combined to form a new descriptor that contains both the static dependency information of each joint between each joint and the dynamic displacement relationship of each joint between adjacent frames. And these three feature descriptors were, respectively, tested on the MSR-Action3D data set and the HDM05 data set with linear SVM, extreme learning machine (ELM), and voting-based ELM (V-ELM). The results show that the ELM classifier has better classification performance on human action data, and the recognition rate of the combined features on the MSR-Action3D data set is much higher than the two original features used alone.
Proposed method
Basic extreme learning machine
Feedforward neural networks, especially back propagation (BP) neural networks, have been widely used in recent years, but the traditional BP algorithm is essentially a one-step method parameter optimization problem, which has problems of slow convergence and convergence to a local minimum. Even though various improved feedforward networks have faster training speed and better generalization ability than BP algorithm, they still cannot get the global optimal solution.
To solve the above problems, an ELM method was proposed to train a single-hidden layer feedforward neural network (SLFN). In ELM, hidden nodes are randomly initialized and no longer adjusted during the entire training process. The only freedom to learn the parameters is the weights between the hidden layer and the output layer. In this way, ELM can be reduced to a parametric linear model for solving linear classification problems.
Traditional feedforward neural networks use gradient descent to train the network. This makes the training speed of the neural network slow, and each weight needs to be adjusted. A large number of network parameters need to be set, and it is easy to fall into a local optimal situation. Existing problems limit the development of feedforward neural networks. As a new type of single-hidden layer neural network, the ELM neural network solves the current shortcomings of traditional feedforward neural networks. It has the advantages of extremely fast learning speed, simple and easy to learn, and good generalization ability. He has paid close attention and researched extensively and has been widely used in various fields such as image quality assessment, image classification, short-term wind speed prediction, fault diagnosis, and medical diagnosis traffic sign recognition.
The network structure of the basic ELM is the same as that of an SLFN, as shown in Figure 1, including an input layer, a hidden layer, and an output layer. The learning algorithm of an SLFN uses an error BP algorithm to update the weights, and the learning algorithm of the ELM neural network is based on randomly setting the input weights and hidden layer offsets. For adjustment, you only need to set the number of hidden neurons, and the output weight is obtained by solving a linear equation system. Its training process does not need iteration and is completed in one time. Compared with traditional neural networks, its training speed is significantly faster.

Structure of the ELM. ELM: extreme learning machine.
For a given training

Among them, ai , i = 1,…, L is the input weight, bi , i = 1,…, L is the offset, and k is the number of samples.

where Hk is the neuron matrix and can be expressed as
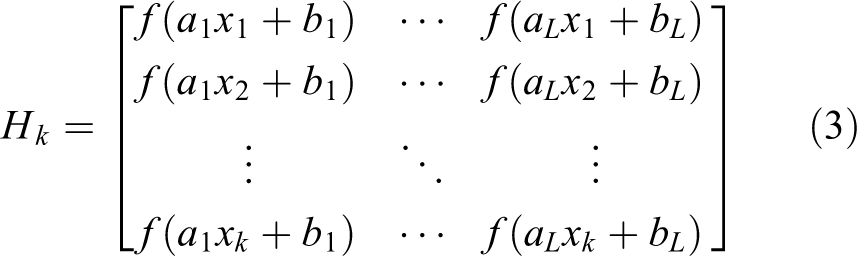

Tk is the output layer matrix and can be expressed as
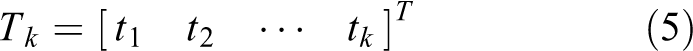
The output weight can be obtained by solving equation (4)

Therefore, the prediction model of the time series after the basic ELM training can be expressed as
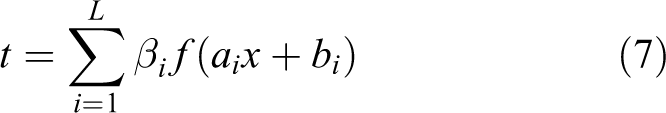
The algorithm steps of the basic ELM can be summarized as
Step 1: Convert the initial N sample sequences x1
, x2
,…xN
into the training set (x1
, t1
), (x2
, t2
),…(xk
, tk
),
Step 2: Determine the number of hidden layer neurons L, the activation function is f(x), randomly generate input weight wi
, and hidden layer threshold
Step 3: Calculate the neuron matrix Hk .
Step 4: Calculate the output weight βk by formula (6).
Motion capture technology
Motion capture refers to the process of recording the movement of objects or people. It has been widely used in military, entertainment, sports, and medical fields and has also been used in computer vision and robotics. During the motion capture process, the actors’ actions are sampled multiple times per second, and the images obtained from multiple cameras are used to calculate the 3-D position. The experimental data used to verify the motion recognition algorithm in this article are obtained through motion capture technology. The two types of motion capture methods used in the data set used in this article are introduced below.
High-precision motion capture system
The emergence of motion capture as a photogrammetric analysis tool in biomechanical research can be roughly divided into two categories, namely optical systems and nonoptical systems:
The optical system uses the data obtained from the image sensor to triangulate the 3-D position of the actor. The data are usually collected using markers installed on the actors. However, recent systems can dynamically generate accurate data by tracking the surface characteristics of each actor. To track multiple actors or expand the capture area, simply increase the number of cameras. Each of these systems has three degrees of freedom for each marker, and rotation information requires at least three orientations between the markers to determine. Optical systems generally include passive marking, active marking, semiactive nonperceptual marking, and no marking.
In addition to optical systems, there are many motion capture systems that do not use visible light as markers and are collectively referred to herein as nonoptical systems. There are mainly the following: inertial motion capture systems, mechanical motion capture systems, and magnetic motion capture systems.
Kinect motion capture system
The Kinect sensor was developed by Microsoft and was originally applied to the Xbox game console. It allows players to control the game console by voice and gestures without the need for a handheld controller. The word Kinect is a self-innovating word combining the words kinetic and connection.
The shape of the Kinect sensor is similar to a webcam, with three lenses, an RGB color camera in the middle, and a 3-D structured light depth sensor composed of an infrared emitter and an infrared complementary metal oxide semiconductor (CMOS) camera on the left and right sides. This device can generate a 3-D image of the space in front of the sensor and use a random decision forest algorithm to automatically recognize the structure of the human body in near real time. The existing research results show that the depth sensor itself can accurately calculate the 3-D position of the working environment, and the joint center of the human body structure can be used to judge the human body posture. Compared with large motion capture systems, motion data captured by Kinect sensors are relatively noisy and have a low frame rate. However, due to its low price, it is still widely used in places where data accuracy is not high.
Human motion recognition technology
Human motion recognition is one of several major problems in the field of computer vision and has many important applications in many fields. One of the most active applications is the interactive entertainment system. The recent popularity of contactless perception interoperators (such as Microsoft’s Kinect sensor) has made it more widely used in this field. The depth data collected by the sensor can be used to analyze the operator’s body skeleton information in real time and then analyze the operator’s motion or posture. 30
At present, there are mainly three motion recognition methods for visual information: the first is a motion recognition method based on spatiotemporal features. This method first converts human motion sequences into a set of static models and compares them with existing motion samples during the recognition phase. This method has low computational complexity but is more sensitive to noise. The second is an image-based statistical recognition method. This method statistically analyzes the low-level information of each frame of action to understand the entire sequence of actions, but the disadvantage of this method is that it requires a large amount of calculation. The third method is based on a skeleton model. This method first uses a 2-D or 3-D skeleton model of the human body to obtain the human pose of each frame and then describes different actions that change at any time. 31 This method has high accuracy, but the requirements are also high, and the recognition method used in this article belongs to the third category.
Experiments have shown that using skeleton information alone to identify actions is more effective than using other low-level image data. This method is particularly effective when identifying simple user gestures, but its application in other fields, especially nonentertainment fields, has not been proven.
In human motion recognition, there are three main tasks: data capture, feature description, and motion modeling. This section will introduce the research progress of these tasks.
The first point is the usability and quality of motion capture data. Using high-precision motion capture systems to obtain accurate skeleton data usually requires a higher price, but many organizations provide open databases, such as the Carnegie Mellon University (CMU) Mocap database at Carnegie Mellon University and the HDM05 database at the University of Bonn. On the other hand, Kinect like Microsoft and some other relatively cheap sensors make it much easier to obtain motion data. 32 Although there will be a loss in accuracy, these losses are still within acceptable limits, plus these sensors, the depth information can be obtained, and the position of the joint can be calculated, it can be used in general. And these acquisition systems are widely used due to their low price. Many such data can be found at present, the most typical of which are the MSR-Action3D data set and MSRCl2 Kinect Gesture Data set released by Microsoft Corporation.
The second point is to find reliable feature descriptors for the action sequence. There are three main types of action descriptors: full sequence descriptors, single frame descriptors, and point of interest descriptors. The latter two require subsequent steps such as descriptor aggregation and timing modeling to complete the goal of action recognition. 33
The third point is to dynamically model the action. Generating models such as HMM or discriminative models such as conditional random field (CRF) can be used to analyze motion sequences. In these methods, joint positions and joint position histograms are used. And because these complex models cannot find enough training data, it is very easy to cause overfitting problems. In addition, the 3-D joint positions calculated from the depth data are much more noisy than the motion capture data, which make these data from it is very difficult to obtain an accurate classification, especially among similar actions. There are other methods that use recurrent neural networks to describe complex nonlinear actions, but the results are not ideal. Another neural network method is a conditionally restricted Boltzmann machine. 34 Because a large number of parameters need to be calculated, these models require a large number of data samples and long-term training to obtain more accurate estimates of the model parameters.
Experiments
Experimental background
To evaluate the combined new descriptors and verify the classification ability of the ELM algorithm on human action data, a comparative experiment was performed on the data sets MSR-Action3D and HDM05. To compare experimental results, this chapter uses the same training and test set partitions as in the above references. To avoid the randomness brought by one partition method, this chapter and subsequent chapters also perform a variety of different data set partitions. In the experiments, linear SVM and ELM classifiers and V-ELM classifiers based on voting were used. Among them, support vector machine (LIBSVM) software (version 3.1.7) was used for SVM.
Experimental data
(1) MSR-Action3D data set
The MSR-Action3D data set contains 20 different actions of 10 actors. Each action is repeated two to three times. There are a total of 567 motion sequences. This article uses the same 544 as the reference 7 L. This data set was collected by Microsoft Kinect sensor and recorded depth information and skeletal joint position information. All the methods in this article only use the skeletal joint position information. Each skeleton of this data set contains 20 joint points, as shown in Figure 2. This data set collects 30 frames of data per second and adopts a data recording method that directly records the 3-D spatial position of joint points in each frame.

Human skeleton structure of the SR-Action3D data set.
In the use of data, the entire data set is divided into three subsets, each of which contains eight types of actions, and there are intersections between the subsets. Each subset is tested separately, and the average training accuracy of the three subsets is finally calculated. In all experiments of this data set, the actions of five performers are selected as the training set, and the actions of the remaining five performers are used as the test set.
(2) HDM05 data set
The HDM05 data set is recorded in advanced streaming file/advanced MP3 catalog (ASF/AMC) format. The main differences from the MSR-Action3D data set are (i) the data set uses the professional motion capture device Vicon Mx system to obtain data with less noise. (ii) There are 31 skeleton nodes in this data set, which records more details than MSR-Action3D. (iii) The number of motion frames collected per second is much higher, reaching 120 fps.
In each experiment in this article, 11 moves performed by 5 people were used, these 11 moves were deposit floor, elbow to knee, grab high song, hop both legs, jog, kick forward, lie down, floor, rotate both arms backward, sneak, squat, and throw basketball. In this article, 277 motion sequences are selected in this data set. The movements of three actors are trained and the movements of the other two actors are tested.
The human skeleton structure recorded by ASF is shown in Figure 3, which consists of 31 joint points including the root node and a total of 56 degrees of freedom.

ASF human skeleton model.
The whole skeleton can be recorded as a tree with the waist node as the root node and the remaining nodes according to the hierarchical relationship. Among them, the root node is a special node that determines the position and orientation of the entire skeleton. The remaining joint points are displaced relative to the parent node. According to the actual situation of the human body, each joint point has different degrees of freedom.
Discussion
Experimental analysis on MSR-Action3D data set
In the case of changing the descriptor hierarchy parameters, different combinations of features and classifiers are used for experiments. The SVM uses a linear kernel function, the number of ELM hidden layer units is set to 10000, and V-ELM is voted for 10 ELM, each of the number of hidden layer units of ELM is 1000, and the same data subset division method is used. The average recognition rate of each data subset is presented in Table 1.
Recognition rates of various methods on the MSR-Action3D data set.
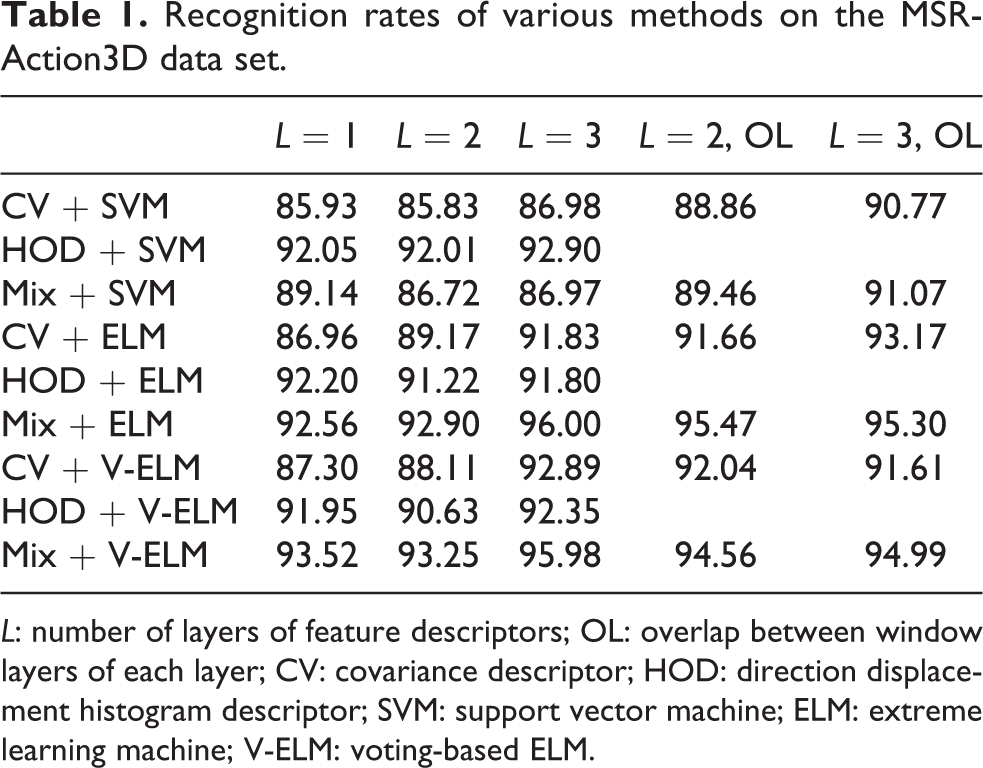
L: number of layers of feature descriptors; OL: overlap between window layers of each layer; CV: covariance descriptor; HOD: direction displacement histogram descriptor; SVM: support vector machine; ELM: extreme learning machine; V-ELM: voting-based ELM.
HODs do not overlap, so the last two cells of the table are empty. Mix stands for combined feature descriptors. The overlap of combined feature descriptors refers to the combination of covariance descriptors with overlap and HODs without overlap.
To easily see the difference in data, the highest recognition rate of each combination of features and classifiers in different layers is shown in Figure 4.

Comparison of the highest recognition rates of various methods on the MSR-Action3D data set.
It can be seen from Table 1 and Figure 4 that the combined feature descriptor combined with the ELM classifier has obvious advantages in this division of the data set. In addition, the classification effect of the ELM algorithm on the covariance descriptor and combined feature descriptor is better than SVM. There has also been a noticeable improvement.
Experimental analysis of different training and test sets
To avoid the randomness caused by a partitioning method of the data set, this article conducted the above experiments 10 times under different training and test set partitioning methods. The average results are presented in Table 2 and Figure 5:
Average recognition rate of MSR-Action3D data sets under 10 divisions.
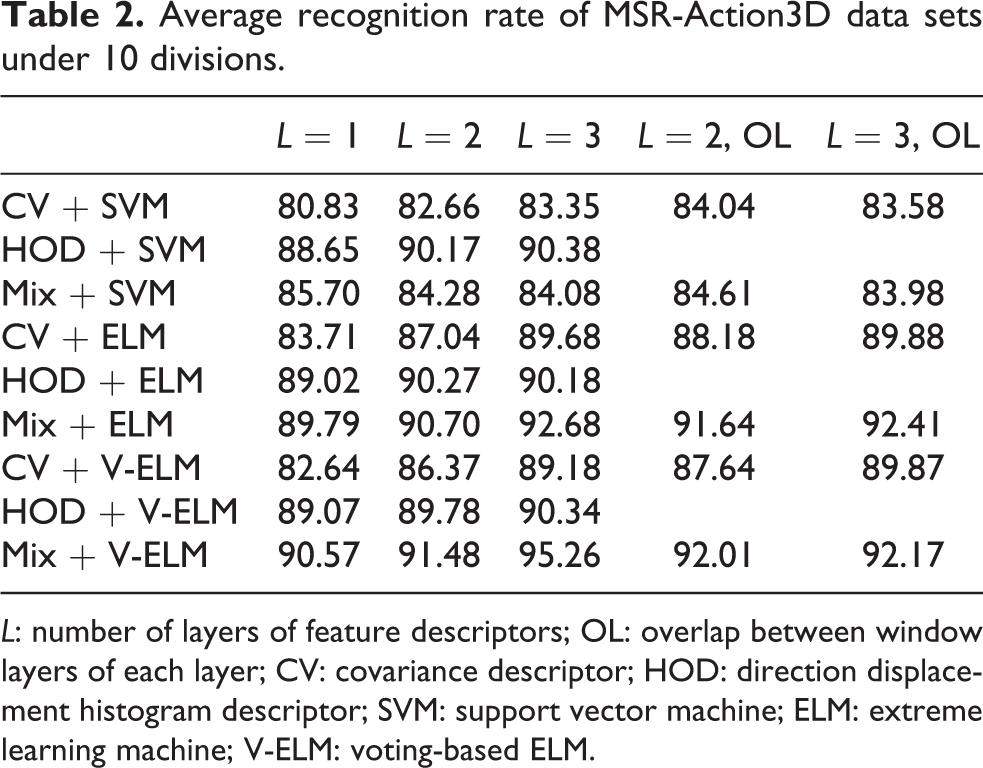
L: number of layers of feature descriptors; OL: overlap between window layers of each layer; CV: covariance descriptor; HOD: direction displacement histogram descriptor; SVM: support vector machine; ELM: extreme learning machine; V-ELM: voting-based ELM.

Comparison of average highest recognition rates of MSR-Action3D data sets in 10 different ways.
The experimental results show that the combined feature descriptor combined with the ELM classifier has obvious advantages in this data set under many different partitioning methods of the data set, and the classification effect of the ELM algorithm on covariance descriptors and combined feature descriptors is better significantly improved than that of SVM.
Experimental analysis of high density metal oxide semiconductor (HDMOS) data set
To verify the effectiveness of the method on high-quality data, a similar experiment was performed on the motion capture data set HDM05. The main differences between this data set and the MSR-Action3D data set are: (i), HDM05 data set uses professional motion capture equipment to obtain data with less noise; (ii) the skeleton joint points of this data set are 31, which will make all kinds of feature descriptors longer. (iii) The number of frames collected per second is also much higher, reaching 120 fps instead of 30 fps in the previous data set.
In the experiment, 11 actions performed by 5 actors were used. In the case of ensuring that the action categories are the same, this article randomly selects 277 motion sequences in this data set, using the actions of 3 actors for training and the action of the remaining 2 actors for testing; as in the previous data set, exhaustively divided all 10 types of training and test sets, eliminated one of the obvious errors, and finally counted the experimental results of the remaining 9 types of partitions. The average results of nine experiments are presented in Table 3 and Figure 6, where Figure 6 shows the highest recognition rate under the combination of each feature and classifier in Table 3.
Average recognition rate of HDM05 data set under nine classification methods.

L: number of layers of feature descriptors; OL: overlap between window layers of each layer; CV: covariance descriptor; HOD: direction displacement histogram descriptor; SVM: support vector machine; ELM: extreme learning machine; V-ELM: voting-based ELM.

Comparison of the average highest recognition rate of HDM05 data sets under nine divisions.
It can be seen from the experimental results that the classification results of the ELM and V-ELM algorithms for various feature descriptors are better than SVM. Although the recognition rate of V-ELM is slightly lower than that of ELM, the time spent during the experiment is significantly reduced compared to ELM. Comparing Table 2 and Table 3, it can be found that although the number of samples used for training is similar, the classification accuracy of the same feature descriptor and classifier on the HDM05 data set is much higher than that of the MSR-Action3D data set. Analysis shows that this is determined by HDM05 data set of low noise, high frame rate, and more joints.
The experiment used 11 actions performed by 5 people. Under the condition of ensuring that the action categories are the same, 277 motion sequences were randomly selected under this data set, and the actions of 3 actors were used for training and the actions of the remaining 2 actors were the test; like the previous data set, exhaustively divided all 10 training and test set division methods and eliminated one of the obvious errors. Finally, the remaining nine types were counted. The average results of nine experiments are presented in Table 4 and Figure 7. It needs to be mentioned that, because the data recorded by the HDM05 data set is high in accuracy, the feature descriptors also increase accordingly. When the number of hidden layer nodes reaches 100,000, the computer memory used in the experiment can no longer meet the experimental requirements. Considering this situation, currently there is no actual use value, so no experiments with a higher number of nodes in the hidden layer have been performed on this data set.
Average recognition rate of HDM05 data set under nine partitioning methods.
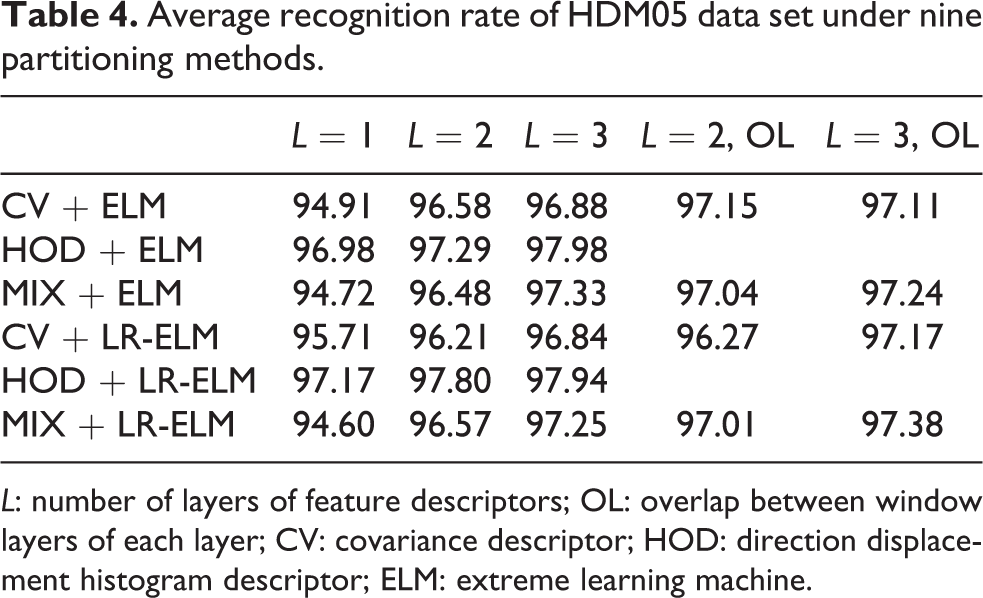
L: number of layers of feature descriptors; OL: overlap between window layers of each layer; CV: covariance descriptor; HOD: direction displacement histogram descriptor; ELM: extreme learning machine.

Comparison of the average highest recognition rate of the HDM05 data set under nine partitioning methods.
It can be seen that the recognition rate of HDM05 is much higher than that of MSR-Action3D data set due to the high quality of data collection, but the extreme learning machine (LR-ELM) classification algorithm has no obvious advantage over the original ELM algorithm on high-quality data sets such as HDM05. According to the analysis, for high-quality data such as HDM05, the HOD feature can already distinguish different types of actions well. After adding the covariance feature of each frame, it will instead form noise and reduce the recognition rate.
Conclusions
With the development of economy and science and technology, robot technology is becoming more and more powerful in terms of applications and functions. The recognition of human motion through robotics has a wide range of applications in many fields and has become a research hotspot in the field of computer vision in recent years. Human motion recognition based on ELM aims to determine the category to which the action belongs by extracting features and modeling from human motion capture data. In this article, the covariance descriptor and the HOD are combined to form a new descriptor that contains both the static dependency relationship of each joint in each frame and the dynamic change of the position of each joint between adjacent frames. These two descriptors were used to recognize human motion on the MSR-Action3D data set and the HDM05 data set in combination with linear SVM, ELM, and V-ELM. The results show that (i) ELM and V-ELM based on voting have better covariance features and combined features than SVM, and combined with combined features on low-quality MSR-Action3D data sets have a large recognition rate This proves that the ELM algorithm has advantages in the application of human motion classification; (ii) the combined feature descriptors can complement the features on low-quality data and improve the classification accuracy.
This article studies a human motion recognition algorithm based on ELMs. The research analyzes the existing algorithms to recognize human movements and analyzes their shortcomings in real time. By extracting the histogram of oriented gradient (HOG) and local binary patterns (LBP) features of the action and constructing a joint feature vector, the grayscale, deformation, and rotation invariance of the image can be effectively guaranteed. The precise positioning of markers based on human motion characteristics, making full use of human motion shape characteristics, helps to remove suspected unrelated areas. Compared with other methods to detect human motion, experimental comparison proves that the algorithm has improved real-time performance and robustness. Using the ELM network to classify and recognize human movements, compared with traditional machine learning methods, the ELM network avoids iterative adjustment of its weights, saves computing time, and improves computing efficiency. The experimental comparison proves that the algorithm has good real-time performance.
The depth of research in this article is limited. It is just a single human motion recognition based on ELM. In the later work, I hope to achieve the following goals: extract features from the rotation angle of the subjoints to the subjoints to achieve rotation, scaling, translation, and invariance of scale to further improve the classification effect. For low-precision human motion capture data, we can first use spherical or spline differences for each joint point in the motion sequence to reduce noise in this way and then perform subsequent feature extraction and classification. At present, the recognition of human movements using ELM is based on a large number of hidden layer nodes, and the memory requirements of the experimental machine are very high. In later work, I hope to find new methods to reduce the demand for hidden layer nodes to improve practicality of the algorithm. The classification method in this article is applied to more fields to verify its universality.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by Planning Subject of “the thirteenth Five-Year-Plan” key laboratory of National Defense Science and Technology of China (grant number 61421070104) and the National Natural Science Youth Foundation of China (grant number 61805067).