
Abstract
The goal of this research work is to improve the accuracy of human pose estimation using the deformation part model without increasing computational complexity. First, the proposed method seeks to improve pose estimation accuracy by adding the depth channel to deformation part model, which was formerly defined based only on RGB channels, to obtain a 4-dimensional deformation part model. In addition, computational complexity can be controlled by reducing the number of joints by taking into account in a reduced 4-dimensional deformation part model. Finally, complete solutions are obtained by solving the omitted joints by using inverse kinematic models. The main goal of this article is to analyze the effect on pose estimation accuracy when using a Kalman filter added to 4-dimensional deformation part model partial solutions. The experiments run with two data sets showing that this method improves pose estimation accuracy compared with state-of-the-art methods and that a Kalman filter helps to increase this accuracy.
Keywords
Introduction
Human pose estimation has been extensively studied for many years in computer vision. Many attempts have been made to improve human pose estimation with methods that work mainly with monocular RGB images. 1 –5
With the ubiquity and increased use of depth sensors, methods that use RGBD imagery are fundamental. One of the methods that used such imagery, and which is currently considered the state-of-the-art for human pose estimation, is Shotton et al.’s method, 6 which was commercially developed for the Kinect device. Shotton et al.’s method allows real-time joint detection for human pose estimation based solely on depth channel.
Despite the state-of-the-art performance of Shotton et al.’s method 6 and the commercial success of Kinect, the many drawbacks of Shotton et al.’s method 6 make it difficult to be adopted in any other type of 3-D computer vision system.
Some of the drawbacks of Shotton et al.’s algorithm 6 include copyright and licensing issues, which restrict the use and implementation of the algorithm for working on any other devices. Another drawback of the algorithm is the large number of training examples (hundreds of thousands) that are required to train its deep random forest algorithm and which could make training cumbersome.
Another drawback of Shotton et al.’s algorithm 6 is that its model is trained only on depth information and thus discards potentially important information that could be found in the RGB channels and could help approach human poses more accurately.
To alleviate these and other drawbacks in Shotton et al., 6 we propose a novel approach that takes advantage of both RGB and depth information combined in a multichannel mixture of parts for pose estimation in single frame images coupled with a skeleton constrained linear quadratic estimator Kalman filter (SLQE KF) that uses the rigid information of a human skeleton to improve joint tracking in consecutive frames. Unlike Kinect, our approach makes our model easily trainable even for nonhuman poses. By adding depth information, we increase the time complexity of the proposed method. For this reason, we reduced the number of points modeled in the proposed method compared with the original deformation part model (DPM). Finally, to speed up the proposed method, we propose an inverse kinematics (IKs) method for the inference of the joints not considered initially, which cuts the training time.
The main contribution of our method extends to (i) an optimized multichannel mixture of parts model that allows the detection of parts in RGBD images; (ii) a linear quadratic estimator (LQE KF) that employs rigid information and connected joints of human pose; (iii) after adding depth information, time complexity was adversely affected. However, we could reduce the number of joints searched in our proposed method to overcome this inconvenience; and (iv) a model for unsolved joints through IK that allows the model to be trained with fewer joints and in less time.
Our results show significant improvements over the state-of-the-art in both the publicly available CAD60 data set and our own data set.
Related work
Human pose estimation has been studied for many years, and some of the methods in the literature that attempt to solve this problem date back to the use of pictorial structures (PSs) introduced by Fischler and Elschlager. 7 More recent methods 3,8,9 improve the concept of PS with improved features or inference models.
Other methods that use more robust joint relationship include Yang and Ramanan’s method 1 which uses a mixture of parts model, Sapp and Taskar’s method 10 which, in turn, uses a multimodel decomposable model, and Wang et al.’s model 11 consider part-based models by introducing hierarchical poselets. Other methods that have attempted to reconstruct 3-D pose estimation from RGB monocular images include the methods of Bourdev and Malik, 12 Ionescu et al., 13 and Gkioxari et al. 14
Object detection has been done using RGBD with Markov Random Fields (MRFs) and features from both RGB and depth. 15
Recently, 3-D cameras such as Kinect have added a new dimension to computer vision problems. Such cameras allow us to capture not only RGB information as done with monocular cameras but also depth information whose intensities depict an inversely proportional relationship of the distance of the objects to the camera.
Some methods that use depth images to reconstruct pose estimations include the methods of Grest et al., 16 Plagemann et al., 17 Shotton et al., 6 Helten et al., 18 Baak et al., 19 and Spinello and Arras. 20 Among such methods, Shotton et al.’s method, 6 which was developed for the Kinect algorithm, has become the state-of-the-art for performing human pose estimation that predicts 3-D positions of body joints from a single depth image.
Proposed method
In this section, we first explain the preprocessing step for the depth channels in which the background was removed to improve the accuracy of our algorithm (see Figure 1). The “Multichannel mixture of parts” section explains the formulation of our 4-D mixture of parts model. The “Joint detection in consecutive frames” section explains our structured LQE for correcting joints in consecutive frames. Finally, the “Model simplification” section describes the strategy to reduce the computational complexity of our proposed method.
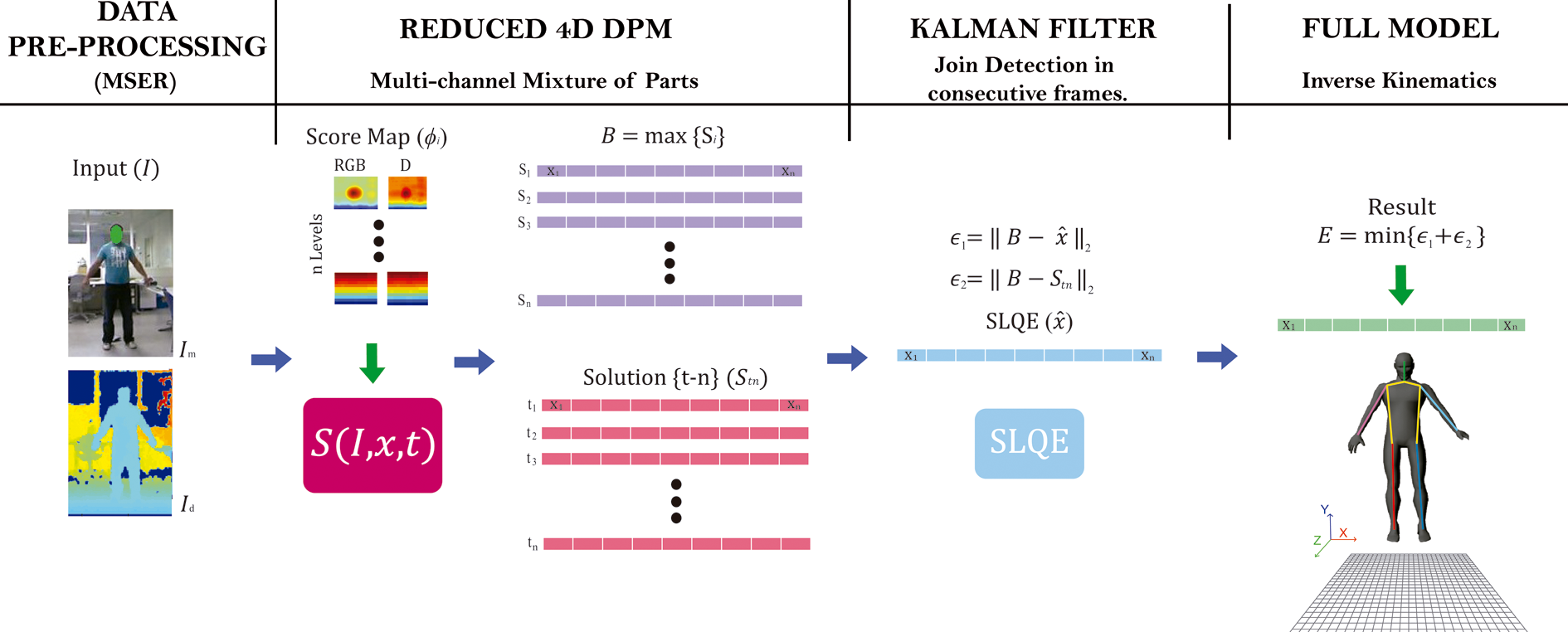
Outline of our method.
Data preprocessing
As a processing step of RGB channels, we isolate significant foreground areas in these channels from background noise. This is done by removing regions in the depth images that are most stable to different thresholds that belong to the background. Such a foreground and background template is then transferred to the RGB images to thus remove noise or conflicting object patterns that would confuse foreground and background features in our method and would hinder detection accuracies.
The intuition behind this approach is that objects or people in the foreground seen through the depth sensor share areas with similar pixel intensities. The reason for this is that the infrared (IR) rays being reflected from the objects in the foreground are reflected more or less at the same time and with the same intensity. Other objects or areas that are much farther away from the IR camera unevenly reflect such rays, and these areas appear more noisy and with varying intensities. Figure 2 shows the different intensities reflected from the IR sensor that represents the depth coordinates of the objects.
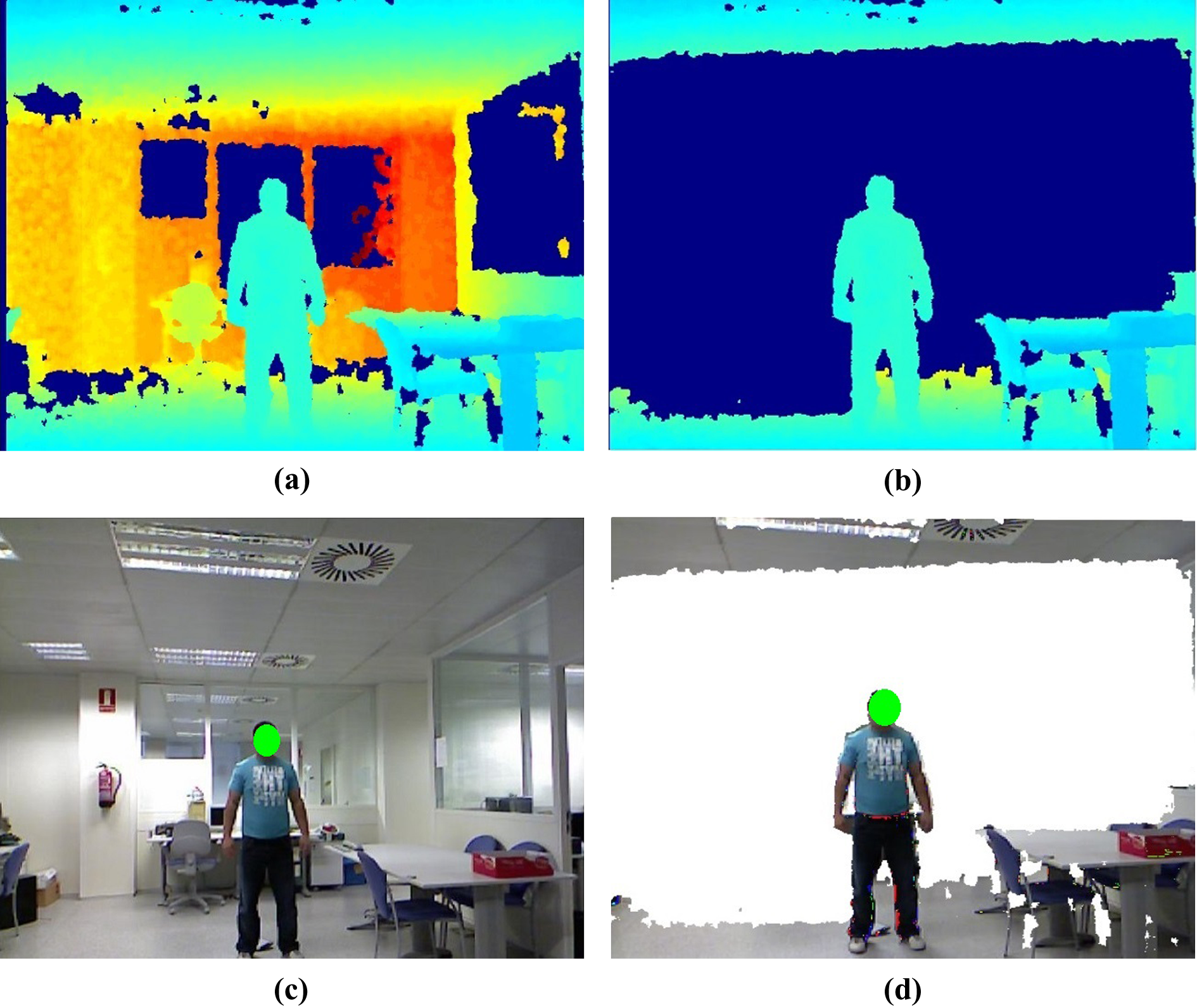
(a) Original depth; (b) depth after applying MSER; (c) original RGB; (d) combining images (c) and (d). MSER: maximally stable extremal region.
Due to this property of the pixel intensities in the depth images, our background removal
method, which is used for depth and later applied to the RGB images, uses a maximally
stable extremal region (MSER)-based approach.
21
These regions are the most stable ones within a range of all possible threshold
values being applied to them. A stability score δ of each region in the
depth channels is calculated so that

Score maps of component at different levels. The figure shows that mixture of parts in RGBD is complementary.

Left: full model with 14 parts (green points). Right: reduced model with 10 parts.

State variables. Left: coordinate systems of the arms. Right: coordinate systems of the legs.

Results of our method. First row shows joints of the reduced model on a sequence which does not belong to CAD60 data set. Second row shows the full model inferred where elbows and knees are estimated by IKmodel. IKs: inverse kinematics.

Qualitative comparison of four different methods for pose estimation on four sequences which belong to CAD60 data set. Fourth row shows joints of the reduced model.
Multichannel mixture of parts
Until recently, Yang and Ramanan’s method 1 has been a state-of-the-art method for pose estimation in monocular images. Yet as we can see in Figure 6 of our “Results” section, Yang and Ramanan’s method performs poorly on images that vary from those in its training set, and their method only improves by a small margin even after retraining.
Although there have been other algorithms 2,3,5 that have improved Yang and Ramanan’s model, all these methods, including Yang and Ramanan’s, use a mixture of parts for only the RGB dimension of channels. Conversely, our method uses a multichannel mixture of parts model that allows us to extend the number of mixtures of parts to the depth dimension of RGBD images.
The depth channel increases time complexity, but this disadvantage has been solved by cutting the number of joints modeled in our 4-dimensional DPM (4D-DPM) method. Hence, our method differs significantly from other previous methods in many important ways that we explain in this section.
In our method, we formulate a score function (S) for the parts or joints that belong to pose through an appearance and deformation functions as follows 1
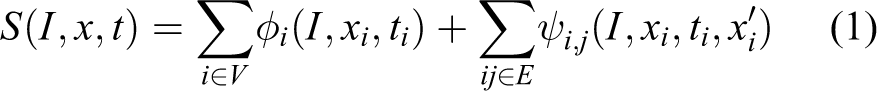
where I corresponds to the RGBD image, x is the
location of joint i, which corresponds to the type of joint being
detected, j is the potential joint being connected to i
and
In order to obtain features and deformations in all RGBD channels, we formulate ϕ and ψ as a multichannel mixture of parts in the following way
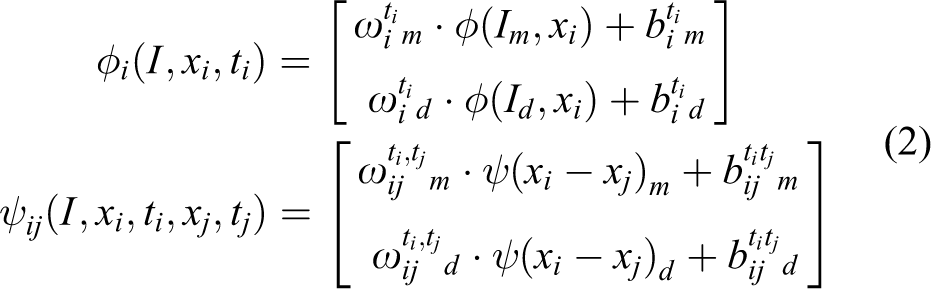
where
The deformation function is given by
As the structure of


Equation (3)
computes the local score of part i, at all the pixel locations
pi and for all possible types
ti, by collecting messages from the children of part
i. Equation (4) computes every location and type of its child part
i. Once messages are passed to the root
In contrast to Yang and Ramanan,
1
we parametrize equation (1) as

Joint detection in consecutive frames
To date, we have dealt only with pose estimation for each single frame independently. However, most of the joint movement performed in normal circumstances displays uniform and constant changes of displacement and velocity. Hence, we can use the properties of the velocity and acceleration of joints to make predictions based on the past where joints would most likely be. This motion-based prediction could help us to validate our frame-based prediction.
One way of predicting joint location based on previous detections is by using an LQE KF. 23 Using a simple LQE works well when the joints being tracked are independent of each other and their movement does not correlate. However, in our case, our joints are connected to each other through limbs, which are rigid connections and allow the movement of one joint related to the other one to be connected; for example, the foot joint movement would be relative to a parent joint such as a knee or a hip.
In order to utilize this joint relationship, we introduce a novel SLQE, which uses joint relationship constraints from a human skeleton model to predict the location of joints at the same time. In this section, we explain this step of our approach.
We first define a state joint obtained by equation (6) with its respective vector components for position (xi, yi), velocity (vxi, vyi), and acceleration (axi, ayi) as follows

We also define the measurement matrix for a joint as H1 that considers only location components xi and yi of the joint

Thus, the measurement matrix for all the joints is represented as

Given a state model A, which models the relationship of each joint to all the other joints being considered, we define a pair of joints that are connected to each other as A1 and A2 to be

where the main diagonal represents the same elements as equation (6) and the upper diagonal denotes the relationships between these elements (e.g. vxi to depend on xi). We take 1 to describe these relationships
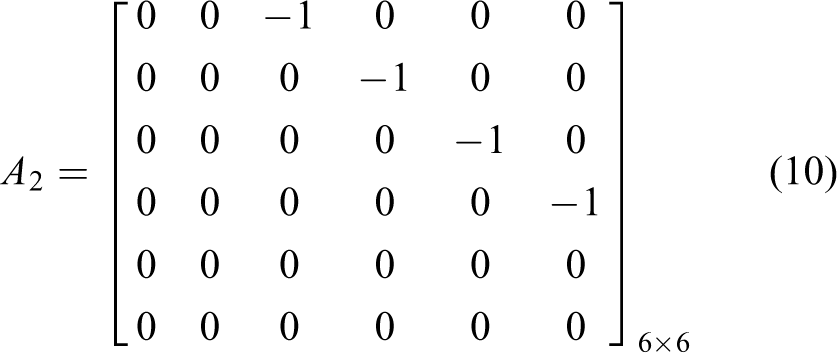
where the upper diagonal represents how the relationships in the consecutive frames change. By changing this value, we can change the velocity of the predicted joints, and to what extent a point, compared to a previous one, can be predicted. After some experiments, we took −1 to represent velocity in the system changes
A1 is fixed and A2 can be adjusted to fast track the movement dynamics. Thus, the final transition state matrix A for all the joints is defined as

Note that the joints whose movement depends on another joint are paired up through the relationship A1A2. The movement of joints that are connected to each other is dependent on each other, thus their velocity and acceleration components are subtracted from each other. Matrix A represents our observed model that is to be predicted. Choosing the correct matrix A is important to correctly predict joints.
The prediction of a posteriori joint

We also calculate a posteriori error covariance Pt so that

where Q is the measurement noise, which is an identity matrix in our case.
We also compute residual covariance S based on noise covariance prediction R to calculate gain K in this way

Once the outcome of measurement
The final estimation of the coordinate joints by our SQLE is given by

Although SLQE can accurately predict the direction and speed of movement for continuous movements, in these cases, joint movement changes direction suddenly, so prediction can fail.
To avoid this issue, we compare our prediction from SLQE and the last successful
prediction from the last frame
Thus, we can avoid making mistakes by SQLE or the score function by choosing the solution

Given the algorithm’s recursive nature, this process can run in real time using only the present input measurements and the previously calculated state and its uncertainty matrix. No additional past information is required.
3-D pose estimation
Once the coordinates of joints have been calculated in planes X and Y, finding their coordinates in the Z plane is as simple as converting the pixel values into the depth images and back into Z coordinates.
Model simplification
The additional depth images included in our formulation add a computational cost to our training and testing phases.
In this section, we explain a simplification technique that uses inverse kinematic equations in order to infer shoulder and knee joints. The original DPM calculates the full body parts with 14 joints. By using IKs, we can lower that number of points to 10. The joints modeled in our proposed 4D-DPM method were reduced, as were the variables to be predicted with KF.
Figure 4 shows the full model with 14 parts on the left and the reduced model with 10 parts on the right, where the joints from the elbow and knee have been deleted.
Human body model
In order to track the human skeleton, we model it as a group of kinematic chains, where each part and joint in the human body corresponds to a link and joint in a kinematic chain. Given the joint positions predicted by the KF, IKs are used to obtain full joints using Denavit–Hartemberg (D-H) model. 24,25
State variables
The human body model is divided into four kinematic chains (KCs), namely in essence, one KC for each arm and one KC for each leg.
Figure 5 shows the coordinate system for each part used to represent legs and arms. The reduced model uses only shoulder and hand points to represent arms, and hip and feet to represent legs. However, by using the IKs with the coordinate systems described in Figure 5, we can obtain elbow and knee points and obtain the full model with 14 points. All these coordinate systems are represented in relation to the same base coordinate system. Since the proposed 4D-DPM method returns the relationships of the locations between all the parts, each KC can be considered independent of the others.
D-H model
We use D-H to model each KC. Hence, we use six joints for each KC for shoulders, hips, hands, and feet (see Figure 5).
First, we establish the base coordinate system
We also locate the origin of the i-th coordinate at the intersection
of the Zi and
For each KC, we have six variable joints qi. Each
qi is placed on the zi-axis
in Figure 5. Now, we can define
the table of the D-H parameters. A generic D-H parameter table for the proposed KC is
shown in Table 1. Given the
six variable joints
D-H table.

θi: rotation along axis
Given the homogeneous transformation matrix that establishes the relationship of a joint with an adjacent one

where
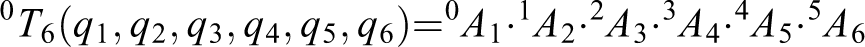
where

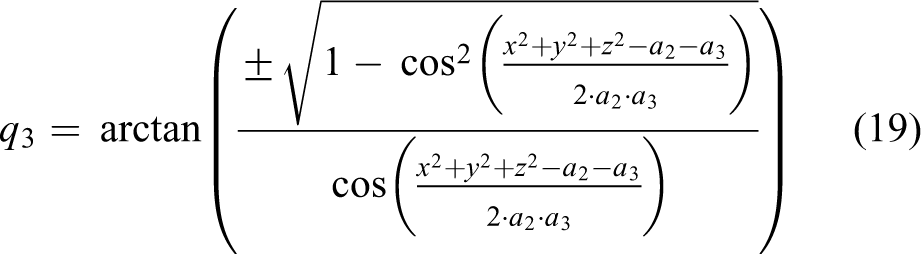

where

Now, we can use IKs to calculate the last three joints. We define

By applying



We use IKs because we can obtain the base of our KC (shoulders or hips), and where the
final effector and orientation (hands and feet) are, thus we obtain these parameters
Figure 6 shows at the top the solutions from the proposed method using 10 parts. These parts correspond to the 10 parts shown in Figure 4 on the right. The bottom images show the full model solutions after applying IKs.
Results
3-D camera calibration
Our method works with any RGBD sensor after correct calibration. In our experiments, we use a Kinect device and calibrate the intrinsic and extrinsic parameters of the monocular and IR sensors. The calibration system is done similarly to Berti et al. 27 or Viala et al. 28,29
Data sets
To train and test our method, we use a combination of videos from our own data set and a subset of the publicly available CAD60 data set. 30
CAD60 data set
The original CAD60 data set. 30 contains 60 RGB-D videos, 4 subjects (2 male, 2 female), 4 different environments (office, bedroom, bathroom, and living room), and 12 different activities. This data set was originally created for the activity recognition task. 31,32,33 The size of the images is 320×240 pixels.
Our data set
It consists of seven videos with only one person on the scene moving his arms and legs. We had almost 1000 frames of people to obtain specific movements, for example crossing arms over one’s body, to complement the CAD60 data set. Images were taken indoors in different scenarios. The subject inside the images is male who wears different clothes. The size of the images is 320×240 pixels.
The ground truth of the joints in this data set was obtained by recording predictions from Kinect. Thus, in order to make a fair comparison of the predictions from the methods being tested, we provide the videos to our human annotators to manually record the ground truth of the joint positions in the CAD60 data set. Thus, our annotators recorded over 15,000 frames of videos that correspond to 16 videos from the CAD60 data set with different activities and environments. For training and testing purposes, we use two different splits of such annotations. We chose to manually annotate the CAD60 data set because, to our knowledge, there is no RGBD data set with ground truth of human pose joints. We will also publicly release our annotated videos for the benefit of the research community.
Metrics
The metrics we use in our different experiments are probability of a correct keypoint (PCK), Average Precision Keypoint (APK), and error distance.
PCK
The PCK was introduced by Yang and Ramanan.
1
Given the bounding box, a pose estimation algorithm must report back the keypoint
locations for body joints. The overlap between the keypoint bounding boxes was measured,
which can suffer from quantization artifacts for small bounding boxes. A keypoint is
considered correct if it lies within
APK
In a real system, however, one has no access to annotated bounding boxes at the test
time, and one must also address the detection problem. One can cleanly combine the two
problems by thinking of body parts (or rather joints) as objects to be detected and
evaluate object detection accuracy with a precision–recall curve. The average precision
keypoint is another metrics introduced by Yang and Ramanan,
1
where, unlike PCK, it penalizes false-positives. Correct keypoints are also
determined through the
Error distance
This metrics calculates the distance between the results and the correct labeled point. To do this, we calculate the distance error between the predicted result and the ground truth location. For each joint, we obtain an error score that is the mean value calculated from all the frames.
Quantitative results
Table 2 shows the results of comparing our proposed method (P. Method) with other methods, such as Shotton et al.’s method, 6 which is used with the Kinect device. Some of the issues we encountered with the Kinect algorithm is that the detections which vary from frame to frame are not consistent. Moreover, Kinect usually mis-predicts hip joints compared to our ground truth, which was generated by our human annotators. We can also see in Figure 7 that Kinect has issues with correctly positioning head, ankle, and wrist joints.
Experimental comparisons with the state-of-the-art methods and different components of our methods on CAD60 data set.a
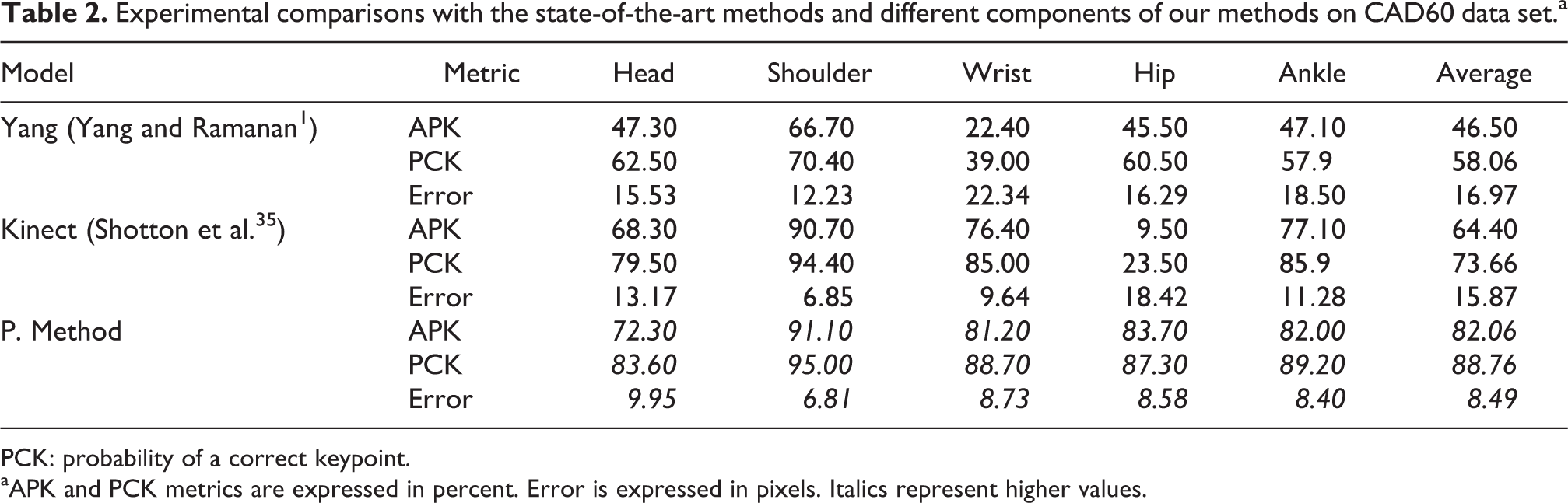
PCK: probability of a correct keypoint.
aAPK and PCK metrics are expressed in percent. Error is expressed in pixels. Italics represent higher values.
Although a fairer comparison with Shotton et al. 6 would be to use the exact training set for both algorithms, such a comparison of the training step is difficult to make because there is no open source of the Kinect algorithm available to produce this type of experiments.
Unlike Shotton et al.’s method, 6 in our experiments we observe that our algorithm can produce competitive results, even with only a few hundred frames in the CAD60 training set.
We also compare our results with Yang and Ramanan’s 1 original method trained on the image parse data set 34 in Table 2 and also retrain it (Yang*) with the same images that we used to train our proposed method (P. Method*; Table 3). Note that although we retrain Yang and Ramanan’s model, our model is still significantly better than their method. Observing the results obtained in Table 3, and by comparing our proposed method with the original DPM, both trained with the same range of images and tested with the same range of images, but a different one of trained images, we have improved the results with the proposed method by adding depth information, a KF, and using IKs to cut the number of points modeled in the DPM. Observing the results in Tables 2 and 3 and independently of the data set used to test or train parts, our proposed method obtains better solutions. This means that the results can be repeatable with different data sets.
Experimental comparisons with the state-of-the-art methods on our proposed data set.a

PCK: probability of a correct keypoint.
aAPK and PCK metrics are expressed in percent. Error is expressed in pixels.
*Signifies difference between two equals methods trained differently. Italics represent higher values.
In addition, in Table 3, our proposed method accuracy is compared both with and without a KF and obtained around 3.5% more accuracy using KF compared to not using KF. The reason for this is that when our proposed method fails in one frame, the wrong solutions obtained in the DPM are not corrected, while wrong solutions are corrected using the past information by KF when KF is employed.
Our results also show significant improvements over Kinect. However, this comparison is not completely fair since our method, having been trained on a smaller data set, is somewhat bias toward this data set. Thus, our results resemble a bias of our method toward the data set being trained on. Hence, if our method were to be tested on other data sets that have not been seen before, it would fail, whereas Kinect might not. This is possibly because Kinect has been trained on a much larger data set and its method can generalize better.
Qualitative results
In this section, we analyze the qualitative results of our proposed method. Figure 7 shows the visual comparisons of our algorithm with the algorithms of Shotton et al. 35 (Kinect), Yang and Ramanan, 1 and Wang and Li. 2 The results of Wang do not seem better than those of Yang and Ramanan. The results of Yang and Ramanan and Kinect fail dismally when limbs fall outside the boundaries of the image or pose is more difficult. The Kinect algorithm also tends to fail when limbs fall outside boundaries and at times finds it difficult to identify the hip points that differ from person to person.
Our proposed method fails when two different joints are closer to each other, which could confuse our model with similar deformation and appearance costa for both joints (see Figure 7). Our proposed model could also fail when the pose configuration in question is not seen during training.
Time complexity analysis
For our experiments, we use a system based on windows 7 with 64 bits and 4 GB RAM. The processor that we use is Inter Core Quad 2.33 GHz. For each frame, we calculate the average time taken by the proposed algorithm to process the frame. The used images have 320×240 pixels.
On training parts, our method takes about 8.12 min per frame, whereas Yang and Ramanan’s method 1 takes about 8.54 min per frame, which is approximately a 5% gain in training time.
On testing part, our method takes about 7.26 s per frame using KF, whereas Yang and Ramanan’s method 1 takes about 9.21 s per frame, which is approximately a 20% gain in pose estimation accuracy from Yang and Ramanan. 1
Although the time performance of our method is much slower than Kinect, which is a real-time method, we show in our article that our method can be trained with fewer frames compared to Kinect, which requires hundreds of thousands of frames.
Conclusions
In this article, we present a novel approach that combines monocular and depth information with a multichannel mixture of parts model, a novel structured LQE, and an IKs model to estimate joints for human pose estimation in RGBD data.
Our results demonstrate a significant improvement over state-of-the-art methods with CAD60 and our own data set. Our method can also be trained in less time and with a smaller fraction of training samples compared to the state-of-the-art.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially financed by Plan Nacional de I+D, Comision Interministerial de Ciencia y Tecnologa (FEDERCICYT) under the project DPI2013-44227-R.