
Abstract
Vision-based detection methods often require consideration of the robot’s sight. For example, panoramic images cause image distortion, which negatively affects the target recognition and spatial localization. Furthermore, the original you only look once method does not have a reasonable performance for the image recognition in the panoramic images. Consequently, some failures have been reported so far when implementing the visual recognition on the robot. In the present study, it is intended to optimize the conventional you only look once algorithm and propose the modified you only look once algorithm. Comparing the obtained results with the experiment shows that the modified you only look once method can be effectively applied in the graphics processing unit to reach the panoramic recognition speedup to 32 frames rate per second, which meets the real-time requirements in diverse applications. It is found that the accuracy of the object detection when applying the proposed modified you only look once method exceeds 70% in the studied cases.
Introduction
Currently, service robots are getting popular in numerous applications at diverse industries. Meanwhile, these devices are continuously miniaturized and become more intelligent. Focusing on the requirements of service robots indicates that although the robot’s functionality is continuously getting stronger, there still exists a serious lack of mature interaction capabilities. Among the functions required for service robots, robotic grasping is the primary step of interacting with the real world. In fact, the robot needs to recognize the position of objects, which require the use of sensors and image recognition approaches. 1 Involving the object detection methods, a remarkable research model 2 in the field of computer vision roars across the horizon. The majority of performed researches so far apply sensors, mostly cameras to manually extract features and then conventional machine learning methods are applied to learn the relational mapping 3 between artificial features and grasping poses from supervised data. Compared to the conventional grasping approaches of industrial robots, which create model libraries based on known objects, 4 this method can transfer obtained experiences to grasp unknown objects. 5 However, since the characteristics of the artificial design are restrained by human cognition, there are some limitations in the robot grasping, including the complexity of making more complicated representations. 6 Therefore, the current technology is only valid for a specific object or a certain task. 7 Since the object is distinct, the object detection may be affected by different factors, including shape, size, perspective variation, and external illumination. Accordingly, the extracted features cannot be generalized resulting in poor robustness. Therefore, finding an algorithm for each specific object is highly demanded, which is a great challenge to adapt to new objects. 8
With recent advancements in the deep learning, which is mainly divided into convolutional neural networks (CNNs) and regional proposal networks (RPNs), 9 object detection has made a huge breakthrough. This is especially more pronounced in the deep learning that promotes the progress of automatic object recognition and localization. 10 To this end, different schemes, including the region-based convolutional neural network (R-CNN), 11 Fast R-CNN, 12 Faster R-CNN, 13 and you only look once (YOLO) detectors 14 have been proposed so far. Among them, the YOLO algorithm is a unified and real-time object detection model, which is based on a single neural network proposed by Redmon and Farhadi. 14 In fact, the YOLO model is a new object detection method that combines the object determination and the object recognition into one by end-to-end detection scheme, which has superior characteristics, including fast detection and high accuracy. Currently, the RCNN algorithms are mainly applied as the mainstream for the deep learning object detection of robotic grasping. However, the corresponding detection speed does not satisfy the real-time requirements. Therefore, the YOLO model has significant potential in robot vision applications. Since the YOLO model learns to predict bounding boxes from supervised data, it is a challenge to generalize prior learning to new objects or objects with unusual aspect ratios or irregular configurations. Since the proposed architecture has multiple downsampling layers from the input image, the YOLO model applies relatively coarse features for predicting bounding boxes. Therefore, the YOLO model is weak in generalization when dealing with irregular aspect ratios in which the same type of object appears in other situations. 15
On the other hand, the camera sight is another challenge to solve. Normally, a captured image has a limited vision field that shows less image information than a panoramic image. When target objects are located out of sight, the robot cannot detect the object. Consequently, vision-based detection methods often require consideration of the size of the camera sight. Considering this drawback, the panoramic image plays an important role in the object detection 16 –18 and spatial positioning of the robot. Considering limitation in the internal space, design, and the initial cost of the robot, the robot is usually not equipped with a panoramic camera. However, the image stitching technology is quite mature without traces so that it is widely applied to investigate the fields of image processing, computer graphics, and virtual reality. Panoramic image stitching refers to the process of seamlessly stitching a series of ordinary images with overlapping borders to obtain a panoramic image. Moreover, the panoramic field of view is obtained through the panoramic image stitching technology, which can easily detect targets in the surrounding. Panoramic photography is performed by rotating the camera evenly on a horizontal plane. It should be indicated that the achieved effect during the performing of the panoramic photography is similar to the rotation of the eyes or head watching around. Unlike normal images, the length–width ratio of the panoramic picture changes greatly. Therefore, the original YOLO image recognition cannot be applied to this picture size, which causes very poor performance of the object detection. The network structure of the YOLO is flexible, and such problems can be resolved by applying appropriate changes to the YOLO. To solve effects originating from the panoramic images, it is intended to build a deep neural network based on the idea of changing the structure of grid cells. It is expected to improve the detection accuracy by modifying the network structure to achieve a high recognition accuracy in the real time.
Multiobjective recognition algorithms based on the deep learning
To evaluate the performance of the modified YOLO (M-YOLO) algorithm in the robotic grasping, YOLO and Faster R-CNN algorithms are employed to perform the comparison.
Faster R-CNN
Faster R-CNN is a deep learning method for identifying objects in the image. Figure 1 demonstrates the entire framework of the Faster R-CNN.
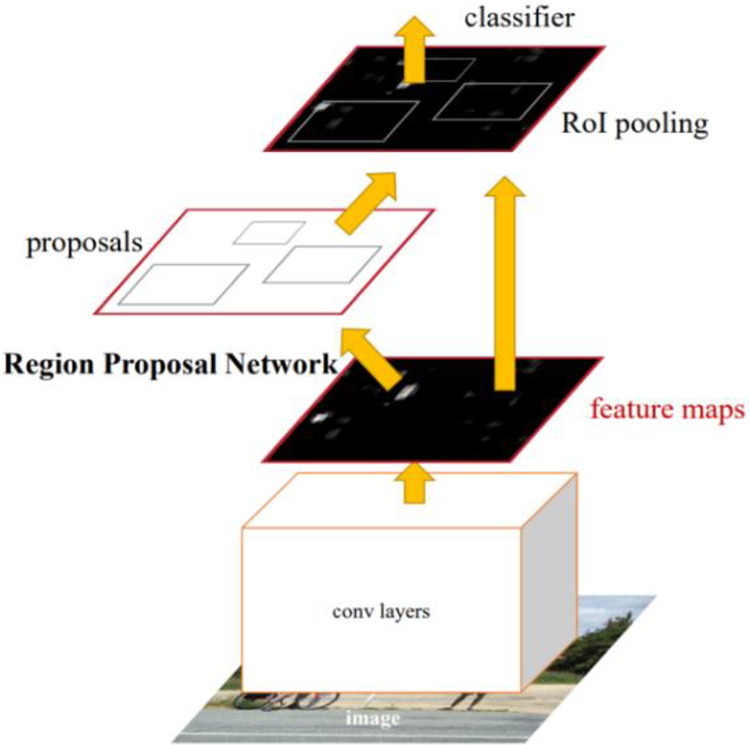
Faster R-CNN.11 R-CNN: region-based convolutional neural network.
Figure 1 indicates that the Faster R-CNN consists of four main layers as the following:
Convolution layers for feature extraction
As an object detection method for the CNN, Faster R-CNN initially uses a set of basic convolutions, rectified linear unit activation functions, and pooling layers to extract feature maps of the input image. These convolutions are used in the subsequent RPN layers 19 and full connection layers.
Region proposal network
RPN is mainly applied to generate regional proposals. First, it generates a pile of anchor boxes. After performing the clipping and filtering processes, Softmax software is employed to determine which anchors belong to the foreground or background. Meanwhile, the bounding box regression modifies the anchor box to form more accurate proposals. More specifically, it is relative to the next box regression of the full connection layer behind it.
Region of interest pooling
This layer uses the feature map generated by RPN proposals and the last layer of the visual geometry group (VGG16) 20 to obtain a feature map with the fixed-size proposal, which can be used to identify and locate objects by the fully connected operation.
Classifier
The region of interest pooling layer is formed into a fixed-size feature map for full connection operation. Softmax software is applied to classify specific categories. 21,22 Meanwhile, the L1 loss is used for completing the bounding box regression operation to obtain the precise position of the object. 23
YOLO
Apart from the Faster R-CNN scheme, the YOLO model is another recognition algorithm for the multitarget deep learning. 24 Considering the superior characteristics of the YOLO scheme, it is applied in the present study for robotic grasping. Figure 2 presents the flowchart of the YOLO model. It indicates that the YOLO model consists of three steps as the following:

Flowchart of the YOLO algorithm.12 YOLO: you only look once.
The original image of the camera is captured and then it is divided into a grid with S × S resolution.
Each grid predicts B bounding boxes with confidence scores. Each record has five parameters, including x, y, w, h, and p* intersection over union (IOU), where p and the IOU denote probability that a current position is an object and the function that predicts probability of the overlap area. Moreover, x and y are the center coordinates, while w and h are the width and height of the bounding box, respectively.
Then class probability of each grid prediction is calculated as Ci = p (class i |object).
The YOLO algorithm uses a CNN to implement the multiobject recognition model. In the present study, the pattern analysis, statistical modeling, and computational learning visual object classes (PASCAL VOC) 25 data set are utilized to evaluate the model. The initial convolutional layer of the network extracts features from the image, while the fully connected layer predicts the output class probability and corresponding image coordinates. Figure 3 indicates that to perform the image classification, the network structure reference employs the GoogleNet model with 24 convolution layers and 2 fully connected layers. 4

Convolutional network used by the YOLO algorithm.12 YOLO: you only look once.
During the training session, the sum-squared error is weighted equally in large and small bounding boxes. Furthermore, the error metric indicates that small deviations of large bounding boxes are less relevant than that of small bounding boxes. To solve this problem, the regression is performed based on the square root of the width and height of bonding boxes, instead of the width and height directly. The YOLO algorithm predicts multiple bounding boxes in each grid. During the network training, only one bounding box is required to be responsible for each project. Subsequently, the following loss functions are optimized 13 :

where
When the object is in the cell, the loss function will punish the classification error. Moreover, the loss function penalizes the coordinate error of the bounding box for an active predictor. After the training session, the regression equation can be applied to predict coordinates of the object category and the object in the image coordinate system in real time. Then the three-dimensional position of the object in the camera coordinate system 26 can be obtained by calculating the center depth.
Differences between the YOLO and Faster R-CNN algorithms
In this section, it is intended to reveal differences between the YOLO and the Faster R-CNN schemes. First, the R-CNN is a feature extractor. In fact, a selective search is normally applied to extract a certain number (e.g. 2000) of region proposals and then it convolutes the region proposals and extracts features of the fc7 layer for the classification and regression of the coordinates. In the present study, the support vector machine classification method is utilized instead of the conventional Softmax model. The main contribution of this algorithm is to propose an effective feature utilization method. The majority of researchers in this area use features of the fc7 layer in engineering practice based on the Fast R-CNN algorithm. Fast R-CNN scheme uses a network to implement all parts except region proposal extraction. Unlike the conventional R-CNN, the classification and loss of coordinate regression in the Fast R-CNN scheme initially update network parameters by the back propagation. Second, not all region proposals but the whole one are put into the extraction when extracting the feature. Then the feature is extracted through the coordinate mapping. It should be indicated that this type of extraction has two advantages, including the fast performance and wide operational range. Since a picture walks through the network only once, the feature is affected by the receptive field so that it can fuse features of the adjacent background to “see” farther. Finally, studies show that it is almost impossible to operate a real-time detection by applying the selective search method. 27 Therefore, it is intended to replace the selective search method with the RPN and share the feature extraction layer 28 with the Fast R-CNN classification and regression network to reduce the computational expense. Experimental results also show that applying the Fast R-CNN improves the speed and accuracy of the prediction. It is found that the RPN is an essence of Faster R-CNN. Moreover, it is the main reason for the high accuracy and low speed of the R-CNN algorithm compared to that of the YOLO scheme.
On the other hand, one of YOLO’s contributions is to convert detection problems into regression problems. In fact, the former Fast R-CNN is divided into two steps, including extracting the region proposal and classifying. The former step judges whether the anchor is the foreground or the background, while the main purpose of the later step it to see what the foreground is. The YOLO scheme generates coordinates and probabilities of each type directly through the regression.
YOLO is characterized by its fast speed, regression mechanism, and the extraction process of the regional proposal. Unlike other algorithms, YOLO roughly divides the images into 7 × 7 grids to analogize the Fast R-CNN. Each location may belong to two objects by default, and 98 region proposals are extracted. In fact, Fast R-CNN is a sliding window mechanism, and each feature map 29 is a map. Moreover, 9 anchors are returned, totaling about 20 K anchors, and 300 regional proposals are eventually obtained through nonmaximum suppression. There is a huge difference in candidate boxes between two algorithms, so reasonable accuracy of the Faster R-CNN can be justified. Since each location should be refined, the efficiency further decreases. Therefore, the recognition speed of the R-CNN cannot meet the real-time requirements. In addition, YOLO 30 streamlines the network, has slightly less computational expense than VGG, and may result in some speedup. However, the importance of computational expense is less than the other two points mentioned above.
In the following section, the performances of each algorithm will be compared with experimental data.
M-YOLO algorithm based on the integrated convolution network
In the present study, robot iKudo is employed to grasp the objects from a complex background containing chairs, tables, and other objects. This session will focus on designing the M-YOLO algorithm.
Figures 4 and 5 indicate that the iKudo has a manipulator and a camera for grasping objects and taking images. General steps of the object grasping 31 are presented in the flowchart. A mission is initially assigned to a robot as a command to grasp an object, for example, a bottle. Once the robot receives the task, it starts to look for an object. There might be some similar objects in the scenario, while the robot should pick a particular object. Therefore, the robot starts to rotate to scan the surroundings through a depth camera and generate a panoramic image. The panoramic cylindrically expanded image is obtained by projecting the annular panoramic image onto a cylindrical surface with a specified radius from the mirror. A two-dimensional rectangular cylindrical panorama 32 is obtained by cutting and spreading the cylindrical surface along the radial direction. Figure 6 illustrates the obtained panoramic image.

Object recognition flowchart of the M-YOLO method. M-YOLO: modified you only look once.

Bottle grasping.

An example panoramic image.
Based on the obtained panoramic image, the object detection 33 is triggered and the robot is asked to process the image with object detection algorithms to detect the particular object. As a result, the robot finds the object location and starts the navigation to the target object by using the simultaneous localization and mapping technology. Finally, once the iKudo robot arrives at the position with an acceptable standard for the object grasping, the manipulator starts to grasp the detected object.
The YOLO system divides the image into S × S grid cells, where each grid allows to predict two bounding boxes so that there are 2 × S × S bounding boxes in total. These generated proposals cover the entire area of the image. If the target center falls in a grid cell, the corresponding cell will be in charge of detecting the object. In this case, the two bounding boxes of such grid cell are expressed as p(object) = 1. In each iteration, the network predicts the location and confidence of 2 × S × S bounding boxes and 20 class probabilities of S × S grid cells excluding the background classification. The class probabilities of bounding boxes are predicted by class probabilities of grid cells corresponding to the bounding box center. In the fully connected layer, it requires a fixed-size vector as an input. In other words, this layer requires original images with a fixed size. To this end, the input size of the YOLO is set to 448 × 448. Since panoramic images contain many objects to be detected, applying the conventional grid generation method on panoramic images allows the single grid to predict two objects which can easily cause detection failures. This may be attributed to the grid numbers, because the number of target objects in a single grid increases as the grid number decreases. 34
However, when the panoramic picture of the robot is processed by YOLO, the aspect ratio of the object in the captured image is not an accurate reflection of its ground truth and the features that look high and thin are formed. Therefore, YOLO is less adaptive to the new samples. To solve this problem, the number of forecasting frames in the longitudinal direction is changed, such as in the scene where the height of the object is compressed in the actual image.
M-YOLO, which is proposed in the present study, reduces the number of objects detected in a single grid by increasing the number of transverse grids. In other words, it changes from S × S to S × nS where the number n is an adaptive number (see Figure 7) and changes the network structure 35 by adding a feature layer at the end of YOLO’s original network structure. It is worth noting that in the present study, parameters n and S are set to 2 and 7, respectively. The new network structure consists of 19 convolution layers and 5 max pooling layers. Figure 8 shows that these layers generate an improved M-YOLO network based on the YOLO network to meet the requirements of the robot-based panoramic image detection. The main purpose for establishing the M-YOLO algorithm is to provide a more generalized model when the comparison is made with conventional models. Moreover, the established algorithm should allow the model to flexibly detect images with large aspect ratios such as panoramic images. Ideally, this means that until the input image size is regular, the M-YOLO and YOLO algorithms have the same performance. However, in processing images with large aspect ratios such as panoramic images, the M-YOLO algorithm supposed to show a better performance and higher processing speed compared with the YOLO algorithm.

Improved grid of the M-YOLO. M-YOLO: modified you only look once.

M-YOLO network structure. M-YOLO: modified you only look once.
To train the M-YOLO network, a python crawler is applied to generate a training set for the experiment. Then a standard VOC data set is constructed to obtain pretraining parameters after 100 cycles (one epoch). It should be indicated that the input image size of the network is randomly changed every 10 cycles.
Build a VOC data set
According to the architecture of the VOC data set, the present study constructs a new data set 36 by using OpenCV to initially read all of the images under the folder. Then, the VOC format is renamed and changed. Figure 9 shows that after preparing the data, it is required to place the image file corresponding to the structure of the VOC data set.
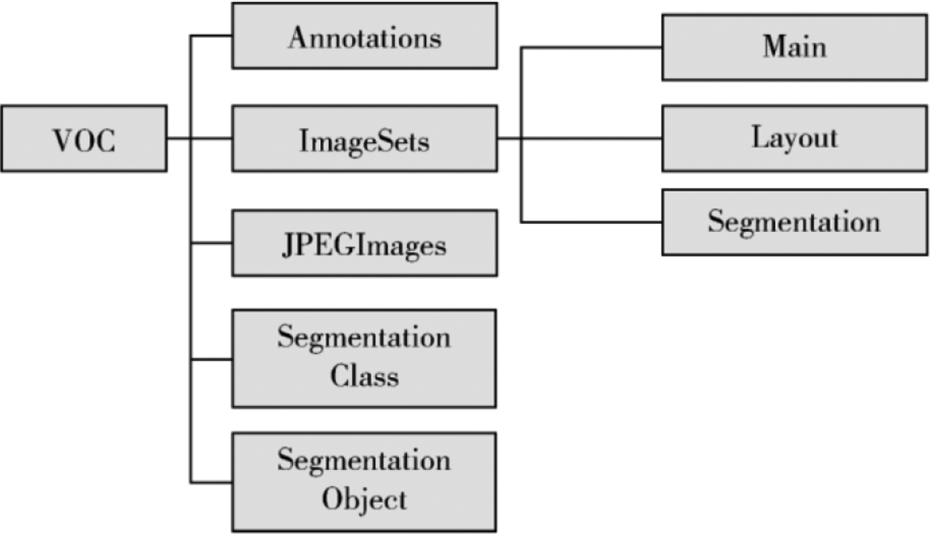
Build a VOC data set. VOC; visual object classes.
Labeling the object area
The object area in the original image is marked with the labeling software for training.
37
The fundamental method is to frame the object area and double-click the category. Then, the complete image is marked and saved. The category selects 20 common types of objects, such as mineral water bottles, parcels, boxes, and chairs. The annotation information is saved in the format of the PASCAL VOC data set, which contains the category of the target and the outsourced border. Then, the actual data of the target are divided by the width and height of the image so that the data are in the range of 0–1. The data can be read faster during the training and the images of different sizes can be trained. The format is five parameters for a set of data, including index (sequence of category), x (x coordinate of the target center), y (y coordinate of the target center), w (width of the target), and h (height of the target). Equation 3 indicates that x
max and y
max are the coordinates of the lower right corner of the frame, while x
mi
Training
The configuration of the computing environment that this article utilizes during the training session is configured with Windows 10 system, Intel Core i7-8700 central processing unit (CPU), NVIDIA GeForce GTX1080, graphics processing unit (GPU), 16 GB RAM, with Cuda 8.0, and Python 3.5 installed. Moreover, the corresponding libraries such as Tensorflow v1.1, Numpy, OpenCV3, and CPython extension are used. The robot vision system is connected to the computer equipped with a 1394 capture card. The YOLO parameters are set with a momentum of 0.9 and a weight decay of 0.0005 to prevent overfitting. Table 1 presents the parameters for training.
Key parameter selection.

Experimental test and the result analysis
In the experiment, a testing data set consisting of 1000 images is built. It should be indicated that the resolution of each image is 300 × 1200. These images consist of 200 images for each class, including occlusion, no occlusion, normal illumination, and weak illumination. The control experiments are set up and tested under YOLO, M-YOLO, and the mainstream detection method of Faster R-CNN. Among them, YOLO and M-YOLO used the Darknet framework, while Faster R-CNN used the Tensorflow framework. Moreover, during the experiments, the bottles and chairs are selected as statistical objects since both of them have obvious motion characteristics.
There are three measurements for the object detection algorithm, including rapidity, accuracy, and robustness. It should be indicated that the detection frame rate per second (FPS), the accuracy rate, and the average overlap rate are considered as comparison parameters.
Processing speed
Three detectors YOLO, M-YOLO, and Faster R-CNN are tested with both CPU and GPU. Moreover, the detection frame rate is calculated according to the average time consumption of the test pictures. Liu et al. 22 investigated the single-shot detector (SSD) and compared the model processing speed (FPS) of SSD300 and SSD512. They showed that data with different input sizes adversely affect the processing speed of the model. Therefore, input images with the same input size (448 × 448) are utilized for all models. However, since the YOLO algorithm has to process more images than the M-YOLO algorithm does, the total processing time of YOLO and M-YOLO algorithms are measured to perform the evaluation.Table 2 presents the obtained statistical results in this regard. It is observed that all three detectors do not meet the real-time performances under CPU. However, YOLO and M-YOLO detection speeds exceed 30 FPS under GPU, which is fully satisfied in real time. Moreover, the current detection method of Faster R-CNN is less than 5 FPS. As a result, YOLO and M-YOLO algorithms have a more reasonable performance in comparison with that of the Faster R-CNN scheme.
Comparison of detection speed.

YOLO: you only look once; M-YOLO: modified you only look once; R-CNN: region-based convolutional neural network; CPU: central processing unit; GPU: graphics processing unit; FPS: frames rate per second.
In the present study, the M-YOLO method is performed on a webcam to evaluate the corresponding real-time performance for fetching images from the camera and display the detected objects.
Table 2 indicates that performing the object detection process on each panoramic image by the M-YOLO takes about 1 s on CPU and 35 ms on GPU. Moreover, when the standard YOLO algorithm is applied to scan the real-time rotation of the robot, several frames should be processed so that longer processing time is required in comparison with the M-YOLO algorithm. In fact, the M-YOLO algorithm only processes a single frame (panoramic image). Table 2 indicates that the processing speed of the standard YOLO algorithm on the CPU is 0.87 FPS, while that of the M-YOLO algorithm is 0.81 FPS. In other words, processing one frame through the YOLO and M-YOLO algorithms takes 1.15 s and 1.23 s, respectively. Therefore, it is concluded that the performance of the YOLO and M-YOLO algorithms in this case study is similar. However, for the object detection in the rotating case, since the YOLO algorithm has to detect several frames during the rotation, the processing time is about 11.49 s, while that of the M-YOLO algorithm is 1.23 s. This remarkable difference in the processing time can be interpreted as the following: In the studied case, the scanning and merging processes in the standard YOLO algorithm take 10 frames with an overlap of 50%, while only a single frame (panoramic image) is processed in the M-YOLO algorithm. A similar result is obtained when the experiment is conducted on the GPU. As a result, it is concluded that the M-YOLO algorithm has a high efficiency rate and reasonable generalization ability for object detection in the rotating case studies.
Accuracy
The accuracy of the object detection is reflected by the error rate. The lower the error rate, the more reliable and accurate the detection model. 38 Among the obtained results, false positive (FP) indicates that the object is classified incorrectly, while a false negative (FN) indicates that the object cannot be located. Images are tested by using YOLO, M-YOLO, and Faster R-CNN.Table 3 presents respective error rates. It is concluded that:
The error rate is about 40% by using YOLO for the detection process. Since the object is in a “short and thin” state, the conventional detector cannot be adapted. However, by using the M-YOLO detector, the error rate is reduced to 30% by increasing the number of longitudinal prediction frames to fit the “short and thin” object. Therefore, the performance of the M-YOLO detector is superior to that of the YOLO detector.
Comparing the M-YOLO detector with the Faster R-CNN detector, the Faster R-CNN error rate is less than 30%, which is the best detector in terms of accuracy. The error rate of the M-YOLO detector is about 3% higher than that of the Faster R-CNN detector. However, considering the significant advantages of the M-YOLO detection speed, it performs more practically in terms of robot vision detection.
Comparison of detection accuracy.

YOLO: you only look once; M-YOLO: modified you only look once; R-CNN: region-based convolutional neural network; FP: false positive; FN: false negative.
With these comparisons shown above in section A and section B, it could be concluded that the M-YOLO method is a fast, accurate object detector, which is ideal for robot vision applications.
Robustness
The bottle is selected as the object to be detected, and other objects such as the chair, box, and table are interference objects. The accuracy and average overlap rate are used as quantitative statistical indicators. The overlap ratio refers to the ratio of the overlap between the detected region and the real region. The higher the value, the more accurate the region of the detection result.
The test results (Figure 10) show that M-YOLO obtains a certain degree of missed detection when the object is occluded. The prediction accuracy and average overlap rate are 6% and 7% lower than the normal environment, respectively. However, the average overlap rate is higher than 65%. When the lack of illumination leads to a certain degree of convergence between the object and the background, the detection accuracy decreases by 5%, and the average overlap rate decreases by 3%. It is concluded that in the occlusion and underlight environment, the M-YOLO method has lower performance. However, it still maintains a higher accuracy and average overlap rate when the comparison is made with the Faster R-CNN.Table 4 presents the robustness of the M-YOLO method.

Test results in four cases. (a) Occlusion, (b) no occlusion, (c) normal illumination, and (d) insufficient illumination.
Robustness quantitative test.

Conclusion
The original YOLO image recognition does not perform well on the panoramic images, which cause some failures when implementing the visual recognition 39 on the robot. The present study proposes a real-time object detection method based on the improved YOLO algorithm that is named as the M-YOLO method. The experimental results demonstrate that the M-YOLO method ran with the GPU can detect the panoramic shooting rate up to 32 FPS, which exceeds the real-time requirement and also shows a good generalization ability for processing the regular and panoramic images. Moreover, it maintains the object recognition accuracy rate of over 70%. However, there are still some problems. For example, the current M-YOLO model only detects a small number of objects and does not obtain a reasonable result in object-intensive scenarios. In the future studies, increasing and training the number of detecting objects should be considered. Moreover, the general ability of the M-YOLO model should be developed to make it perform well in object-intensive scenarios.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.