
Abstract
This article proposes a unique active relative localization mechanism for multi-agent simultaneous localization and mapping, in which an agent to be observed is considered as a task, and the others who want to assist that agent will perform that task by relative observation. A task allocation algorithm based on deep reinforcement learning is proposed for this mechanism. Each agent can choose whether to localize other agents or to continue independent simultaneous localization and mapping on its own initiative. By this way, the process of each agent simultaneous localization and mapping will be interacted by the collaboration. Firstly, a unique observation function which models the whole multi-agent system is obtained based on ORBSLAM. Secondly, a novel type of Deep Q Network called multi-agent systemDeep Q Network (MAS-DQN) is deployed to learn correspondence between Q value and state–action pair, abstract representation of agents in multi-agent system is learned in the process of collaboration among agents. Finally, each agent must act with a certain degree of freedom according to MAS-DQN. The simulation results of comparative experiments prove that this mechanism improves the efficiency of cooperation in the process of multi-agent simultaneous localization and mapping.
Keywords
Introduction
A critical task of a mobile robot is to determine its pose (position and orientation) under the given environment map, which is also the basis of other type of tasks. However, the environment map does not exist at the beginning. When the mobile robots enter an unknown part of environment, they need to construct the map (3-D point cloud map, topological map, 2-D map) to satisfy their tasks through its own sensors, and at the same time determine their own localization in the map, this is called simultaneous localization and mapping (SLAM) problem. Mapping and localization are mutually complementary. In order to build accurate maps, it is necessary for the robot to have an accurate estimation of its pose, vice versa, localization also requires established high-quality maps, it is the difficulty of SLAM. Visual SLAM refers to the SLAM that only the camera acts as the only visual sensor. Compared with the traditional laser, the visual sensors can obtain more abundant information and can be deployed on mobile robots at very low cost.
Multi-agent system (MAS) refers to that agents in one system collaborate and negotiate with others to accomplish goals that cannot be accomplished by a single agent or to increase the efficiency of task execution. Each agent’s ability, attributes, and structure are different, which provides a great space for collaboration. MAS has attracted many researchers to investigate the applicability of it in many pertinent areas closely related to human livelihood and industry such as security system, 1 exploration and rescue, 2 surveillance, 3 humanitarian assistance, 4 environment protection, 5,6 and health care. 7,8 Traditional SLAM has been considered as an independent behavior. With the continuous application of MAS, multi-agent SLAM has become the focus of scholars’ research.
Multi-agent SLAM can be divided into two types: off-line mode and online mode. Off-line mode means that each agent’s SLAM process is independent and the results are fused together after all agents stop. Online mode refers to that agents can cooperate with each other in SLAM process, such as cooperative loop closure detection and cooperative localization, cooperative map fusion, and so on. Relative orientations in MAS are important on account of that it is a basis for combining maps built with data from two agents. The difficulty of online multi-agent SLAM is how to cooperate in the best way under the condition that each agent has different attributes with different states. This issue is particularly prominent in the relative localization between robots. For instance, the localization ability of wheeled robot is stronger than that of unmanned aerial vehicle (UAV) because of the odometer, but the pose of UAV is more abundant, which leads to its strong mapping ability. If there are these two kinds of robots in the system at the same time, an appropriate collaboration model will make full use of the advantages of both. 9 This type of relative localization is controlled manually. If MAS wants to optimize the efficiency of automatic cooperative positioning between agents, each agent needs to perceive all the states and their attributes related to SLAM to determine whether it has the optimal condition to observe the agent in need of assistance or not. But in most cases, the task-related attributes and states of robots are not quantifiable which brings difficulties to collaboration.
In order to solve the above problem of SLAM of agents in MAS, this article proposes a cooperative mechanism applied to multi-agent SLAM, which can learn the main attributes related to each agent and extracts the state feature vectors of all agents in MAS based on ORBSLAM, 10 each agent will determine its specific behavior outputted by MAS-DQN. In the “Experiment” section, we use model of isomorphic robots with different attributes to simulate various robots, and the validity of our algorithm is proved.
The article is organized as follows: in the second section, related work about coalition formation for MAS and multi-agent SLAM is discussed. In the third section, the DQN and “Rainbow” which we applied to drive MAS-DQN are introduced. In the fourth section, the structure of MAS-DQN including the novel observation function and reward function is described. In the fifth section, we introduce relative observation between agents based on the proposed mechanism. In the sixth section, the effectiveness of the algorithm is discussed. In the seventh section, the complete algorithm of the approach is shown.
Related work
The relative localization among agents in MAS refers to the location of an unknown agent whose pose is unknown using others limited knowledge and ability. This process is mainly composed of two steps: first, select the agents that can provide location-based services. These agents can be determined by a general control center or freely negotiated by the agents according to their own demands, interests, and attributes. This step mainly involves multi-agent task allocation (MRTA). In the second step, the selected agent uses its own pose and different types of map such as graph-based map, 11,12 landmarks with covariance matrix, 13 and grid-based map 14,15 to measure or observe the pose of the agent to be localized. Next, we will introduce the related work of these two points separately.
MRTA has always been a hot topic in MAS research. Task allocation in MAS (MRTA) can be formulated as an optimal assignment problem where the goal is to optimally assign a set of agents to a set of tasks in such a way that optimizes the overall system performance under a condition of satisfying a set of constraints. According to team organizational paradigm, MRTA can be divided into two categories: centralized approaches and distributed approaches.
There is a central agent that monitors and assigns tasks to other agents in a centralized MAS. Agents who are assigned tasks need to send all the information they obtain to that central agent. They need to keep communication with each other at all times. The center-based algorithm is very general for solving the MRTA problem as a result that monitors can directly control each agent. 16 Coltin and Veloso 17 proposed centralized approaches for mobile robot task allocation in hybrid wireless sensor networks. In the literature, 18 a centralized multi-robot task allocation for industrial plant inspection by using A* and genetic algorithm is introduced. Higuera and Dudek 19 proposed a fair division-based MRTA approach as another centralized algorithm to handle the problem of allocating a single global task among heterogeneous robots. In order to solve the problem of curse of dimension caused by multi-agent reinforcement learning, Wadhwania et al. got inspiration from distillation and value-matching and proposed a new actor-critic algorithm and method for combining knowledge from agents with the same structure. 20
In configuration of distributed approaches, agents do not need to report to a central agent, and they do not need to be online at all times. They can freely communicate with other agents and assign tasks through negotiation with different demands. This type of algorithm is also widely used to solve MRTA problem. Farinelli et al. proposed a distributed online dynamic task assignment for multi-robot patrolling. 21 Luo et al. 22 proposed distributed algorithm for constrained multi-robot task assignment for grouped tasks. Various ambient assisted living technologies have been proposed for MRTA in Healthcare Facilities. 23 Emotional robots model use artificial emotions to endow the robot with emotional factors, which makes the robot more intelligent and adjust its behavior choice through the emotional mechanism. The introduction of emotional and personal factors improves the diversity and autonomy of robots. 24 Jonathan How’s team focused on using consensus-based auction algorithms to solve decentralized task assignments 25,26 and utilized game theory to prove that the consensus-based bundle algorithm converges to a pure strategy Nash equilibrium. 27 Johnson et al. used implicit coordination to satisfy allocation constraints. 28
Some relative localization algorithms for MAS use some prior information such as initial positions of the agents and exact positions of landmarks. 29 Shames et al. 30 presented the theoretical basis of relative localization between agents by using prior knowledge in maps. Zhou and Roumeliotis 31 proposed a mechanism for relative localization in which agents try to observe each other in-time if they have a chance with unknown initial correspondence. Zkucur and Levent 32 establishes the relationship between relative observation and map fusion. However, in most cases, agents cannot get enough prior knowledge for relative location. Some statistical estimation algorithms, such as Kalman filtering, 33 particle filtering, 34 Markov localization perform better in this case. 35
Most of the relative observation approaches serve for map fusion. In the mechanism proposed by this article, the data from relative observations between agents are also applied for optimizing the pose graph of the observed agents which improves the efficiency of data utilization.
DQN and rainbow
Q-learning is an off-policy learning method in reinforcement learning. It uses Q-table to store the cumulative value of each state–action pair. According to Bellman equation, when the strategy of maximizing Q value is adopted in every step, the

where
The training process of DQN.


where x is the state of the system that has not been purified by observation function and ϕ is the observation function, M and t respectively represent the number of iterations and the number of training samples. However, the combination of deep learning (DL) and reinforcement learning (RL) will inevitably lead to some problems, such as: DL needs a large number of labeled samples for supervised learning; RL only has the reward of state–action pairs as return value. The sample of DL is independent, and the state of RL is correlative. The distribution of DL targets is fixed; the distribution of RL is always changing, that is, it is difficult to reproduce the situation that was trained before. Previous studies have shown that the use of nonlinear networks to represent value functions is unstable.
This article used “Rainbow” to build the training model of MAS-DQN. Rainbow
37
is an integrated DQN. It mainly integrates the following algorithms to try to solve the above problems: Double Q-Learning constructs two neural networks with the same structure but different parameters: behavior network and target network. When updating the model, the best action at Priority replay buffer makes the model choose more samples that can improve the model to use the replay memory more efficiently. Dueling DQN decomposes the value function into two parts, making the model easier to train and expressing more valuable information. Distributional DQN changes the output of the model from computational value expectation to computational value distribution in order to let the model can learn more valuable information. Noisy DQN adds some exploratory ability to the model by adding noise to the parameters, which is more controllable. In order to overcome the weakness of slow learning speed in Q-learning earlier stage, multistep learning uses more steps of reward, the target value can be estimated more accurately in the early stage of training, thus speeding up the training speed.
Rainbow model integrates the advantages of the above models which proves the possibility of integrating the above features successfully.
The network for propose mechanism
Observation function for MAS-DQN based on ORBSLAM
In deep RL, the local information obtained by an agent is called observation. Unlike previous deep RL algorithms, the observation function of the proposed mechanism models all agents and determines the behavior of each agent at the same time instead of for only one agent. In this section, ORBSLAM feature vector and output of the observation function are introduced.
ORBSLAM feature vector
ORBSLAM 10 is one of the most commonly used system among modern visual SLAM frameworks. It runs in three threads: In tracking thread, the system tracks motion of the platform by using tracked feature points; local mapping thread is used for constructing global map and optimizing local map, loop closure thread takes responsibility for detecting loop when agent revisited to an already mapped area, which can prevent increase of the accumulative errors.
ORBSLAM is deployed on each agent independently to simultaneously construct the map. In our system, the state of the environment consists of all pose estimation states of agents which are mainly determined by three items: map points, key frames, and loop closure detection. Some variables related to the three items are used to compose the state vector of the agent called ORBSLAM feature vector whose members are introduced as follow: The first of component of the ORBSLAM feature vector is a variable related to the map point. The map point is constructed from the matched point features. We include the number of map points observed from current frame in feature vector. The second of component of the feature vector is a variable related to the key frames which are the selected frames according to strict requirements to ensure that they contain sufficient map information. Some key frames proved to contain insufficiently accurate map information will be gradually removed. In order to estimate the content of map information at nearby locations which play a decisive role in pose estimation, the number of the generated new key frames and that of the eliminated old key frames from our last sampling time in the state vector are included in the state vector. The third of component of the feature vector is a variable related to the result of loop closure. Loop closure detection is the problem that a mobile agent determines whether itself has returned to a previously visited location. If a closed-loop is detected, it will impose a strong constraint on global optimization. In feature vector, we add the time interval of the frame from last loop closure detected to measure the impact of loop closure to the current frame. Another critical factor is the collection of distances from the agent to other agents. The longer the distance from the agent to target agent is, the bigger difficult to it to assist the target. The distance is calculated by D* algorithm. The characteristic of D* algorithm is that when the terrain between the target point and the source point is known, the shortest path and the shortest distance can be obtained. If not fully known, the shortest path in the known terrain and the estimated distance between the target point and the source point can be output. An ORBSLAM feature vector contains m − 1 (m is the number of agents) such distances, representing the distance between the agent and the other m − 1 agents, respectively.
An ordered arrangement of all the above variables is an ORBSLAM feature vector. On the next subsubsection, the observation function base on the ORBSLAM feature vector will be introduced.
The observation function
The output of the observation function represents the perception of the overall SLAM state of the whole MAS. The ORBSLAM feature vectors of all agents at the same time form an observation frame. Considering the continuity of the SLAM process, the previous states should be taken into count when the system makes macro-decision for each agent, so that the output of the observation function should include the current frame and the fixed number of preceding frames. These frames consist of an observation frame set, which eventually flattens into a vector as the output of the observation function. The specific steps of the observation function are shown in Algorithm 2.
Observation function of the proposed algorithm.


While the parameter n is the number of observation frames, m is the total number of agents in the system, and
Reward function
The reward function is generally used to reflect the immediate benefit of an agent reaching a new state through action. In our proposed algorithm, the transition error is used to measure the reward, which is shown in the equation (3)

In order to embody the collaboration between agents, the reward function also adds the influence of agent’s target on his decision-making. The final reward function of agent is as equation (4)
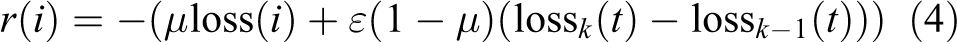
where

The output formation of the proposed DQN
There are

Structure of MAS-DQN. MAS: multi-agent system; DQN: Deep Q Network.
Relative observation between agents in the proposed mechanism
In the proposed mechanism, agents execute the order given by MAS-DQN through mutual observation with each others. As shown in Figure 2, red agents are assigned to assist blue agents. First, they shall reach the predetermined observation position. If all the predetermined positions cannot be reached, the observation will be judged as a failure, agent obtains the pose of the target through the relative localization of the target agent. The obtained position and posture will provide a strong constraint for the target agent to optimize the pose graph. In another word, it is used to improve the accuracy of correcting pose. This observation actually has the same effect as the loop closure detection. The way of calculating the pose of the target agent is introduced consequently.
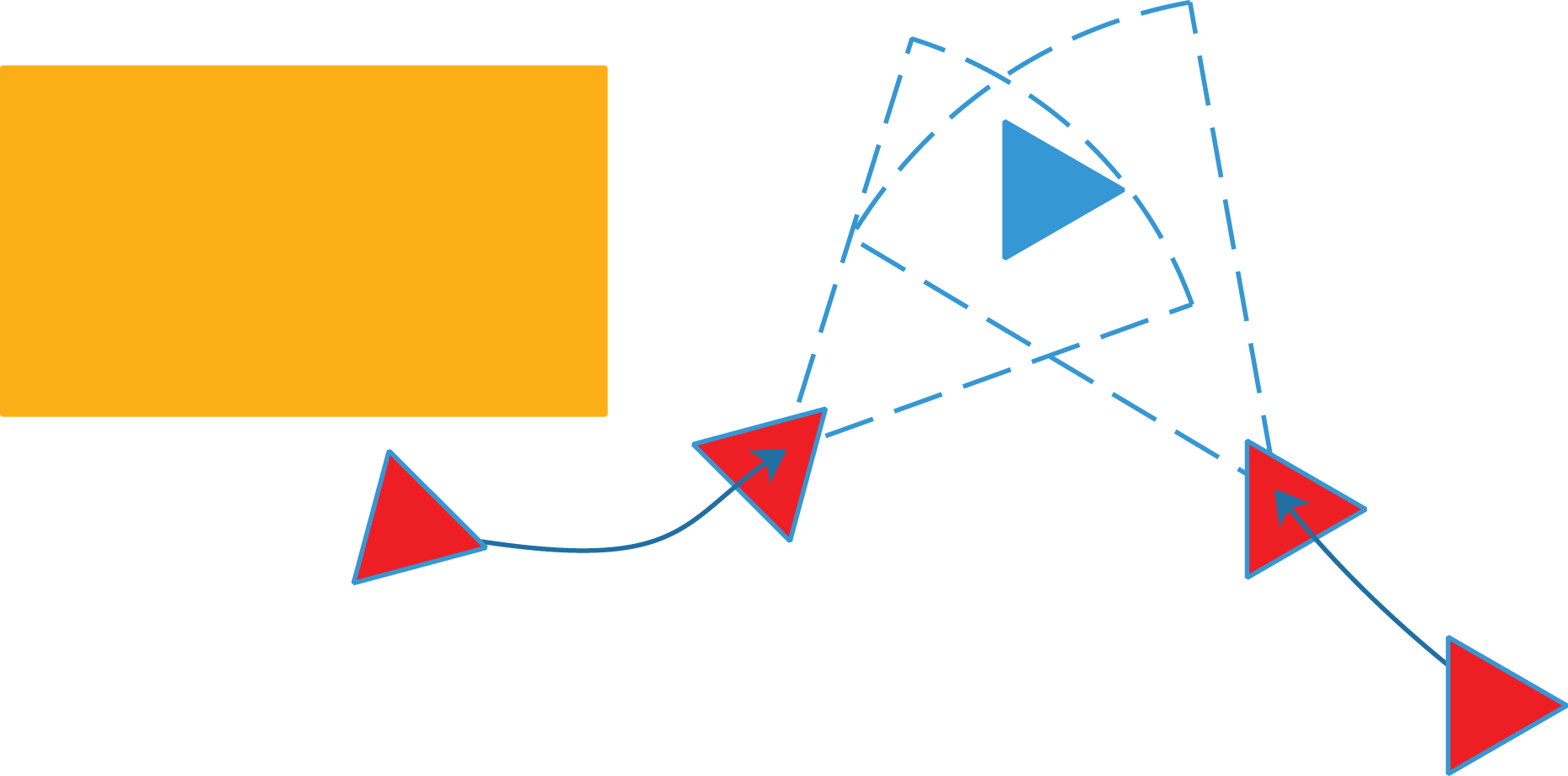
Assistance in MAS based on relative observation. MAS: multi-agent system.
Assume that agent i observes a feature point

where Ri refers to agent i’s rotation matrix which converts camera coordinates into world coordinates and ti refers to translation matrix. R and t together constitute the pose of robot camera. The world coordinates of one feature point are the consistent, the relationship between the world coordinates of point p and the coordinates of point p in the camera coordinate system of agent j is shown in equation (7).

where Rj
and Tj
is the pose of agent j,

where
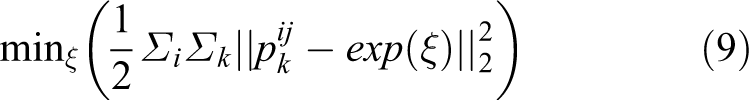
The derivative of error term with respect to pose can be obtained by using Lie algebraic perturbation model, and the value of
Effectiveness proof of the proposed algorithm
In this part, we will prove the effectiveness of our algorithm. That is to give the demonstration that after experience replay, the proposed DQN can make macro-decision to improve the efficiency of the whole MAS for each agent after training. We use the utility theory to model the performance of the whole MAS. As shown in the previous section, the effect of SLAM of a single agent x can be regards the immediate utility value of x which is associated with

The expectation of the immediate utility value of a non-cooperative MAS is as follows

The calculation of that in collaborative MAS is relatively complex since the effect of collaboration between agents on the overall system utility value should be considered, we use a graph to represent the cooperation of the whole system. An agent will be regard as a node in the graph and a directed edge from the itself to the target will be established as shown in Figure 3. If the collaboration is not executed at that time, the edge is the solid line. If the collaboration is just completed, the edge is a double-line edge. If the collaboration fails, the line is a dashed line, and if there is no collaboration object, the arrow points to itself. The whole MAS can be divided into several maximally connected subgraphs, as shown in the Figure 3, where one subgraph is a group which can represent the collaboration relationship between agents. The total utility value of a group

where


Graph of coordination.
In summary, to calculate the cumulative reward of all agents is to calculate the total cumulative utility value. MAS-DQN will gradually learn the cumulative utility function
The last layer of MAS-DQN is the decision-making layer. All the layers before the decision layer are called feature extraction layer. The feature extraction layer is actually a high-level abstraction of ORBSLAM feature vector. The weights connected with the decision-making level determine the discrepancy of different decision-making of agents. That is, in the face of the same extracted high-level characteristics, different action produce different cumulative reward. This situation is caused by the different attributes between agents, which DQN learns through the cooperation between agents.
Sequences of the proposed mechanism
The implementation steps of the proposed overall cooperation mechanism for multi-agent SLAM are shown in Algorithm 3.
Complete algorithm.


The system consists of mobile agents and organizer which MAS-DQN is deployed on. The following is a detailed explanation of this algorithm: Initialize the whole algorithm and all variables (01). Organizer broadcasts the requirements for synchronizing agent information and waits for the reply of all the agents (03–04). Each agent respond organizer with their world coordinates, built local maps, ORBSLAM feature vectors, and assistance status (05–07). The local maps are not the final form of maps. They are only 2-D maps that provide information for agent global navigation. After the organizer obtains the information returned by all agents (08), the first thing to do for it is to merge the local maps of all agents and feedback the global maps to agents (09–10). The second mission is to get the output of the observation function according to the set of ORBSLAM feature vector of all agents (11). Next, the immediate reward of each agent is calculated (12). Finally, the output is imported to MAS-DQN to get the action of each agent which will be broadcasted (13–14).
Experiment
The simulation experiments introduced in this section is to evaluate the performance of the proposed mechanism and MAS-DQN with different parameters. The experiment was implemented on the Robot Operating System (ROS) platform which can be used to simulate the real physical environment. We build one simulation mobile agent with the “telobot” model which equips “Kinect” as vision sensor. The initial pose of each robot is known and ORBSLAM is deployed independently on each robot. The experimental world is shown as Figure 4.

Experimental world.
The main indicators to measure the effect of SLAM in MAS are translation root mean square error (RMSE), orientation RMSE of the tracks of agents. Although agents in experimental environments have the same model, we can embody the differences of their attributes by changing their ability values related to motion and vision sampling. Their maximum angular acceleration, linear acceleration, maximum angular velocity, and maximum linear velocity obey normal distribution
We set up four experiments to verify the effectiveness of our algorithm. The following are the details of all experiments and the corresponding experimental results. The experiments have been done with
Experiment 1: This experiment shows the role of collaboration in multi-agent SLAM. The results are shown in Figure 5 in which the two algorithms for comparison are explained as follows:
Case1: The proposed collaboration mechanism based on MAS-DQN.
Case2: Each agent SLAM independently without any collaboration.

Result of experiment 1.
The proposed algorithm reduce translation RMSE (m) by 35.68% orientation RMSE (°) by 32.02% compared with the mechanism without coordination
We use these two different mechanisms to generate octomaps 38 of the same environment, which are shown in Figures 6 and 7.

The octomap built by the proposed mechanism.

The octomap built by the agents in MAS without any coordination. MAS: multi-agent system.
Experiment 2: The main purpose of this experiment is to compare mechanism that agents collaborate with each other without considering attributes and states. The experimental results are shown in the Figure 8, which illustrate that the proposed algorithm reduce translation RMSE by 28.33% and orientation RMSE by 31.68%.
Case 1: The proposed collaboration mechanism based MAS-DQN.
Case 2: Relative localization based on cluster matching algorithm without distance IR in the environment. 39

Result of experiment 2.
Experiment 3: This experiment is used to compare the proposed algorithm with other feature-based MRTA algorithms that take agent attributes as constants. The experimental results are shown in the Figure 9.
Case 1: The proposed collaboration mechanism based on MAS-DQN.
Case 2: The proposed collaboration mechanism based on emotional recruitment model.
Case 3: The proposed collaboration mechanism based on auction model.
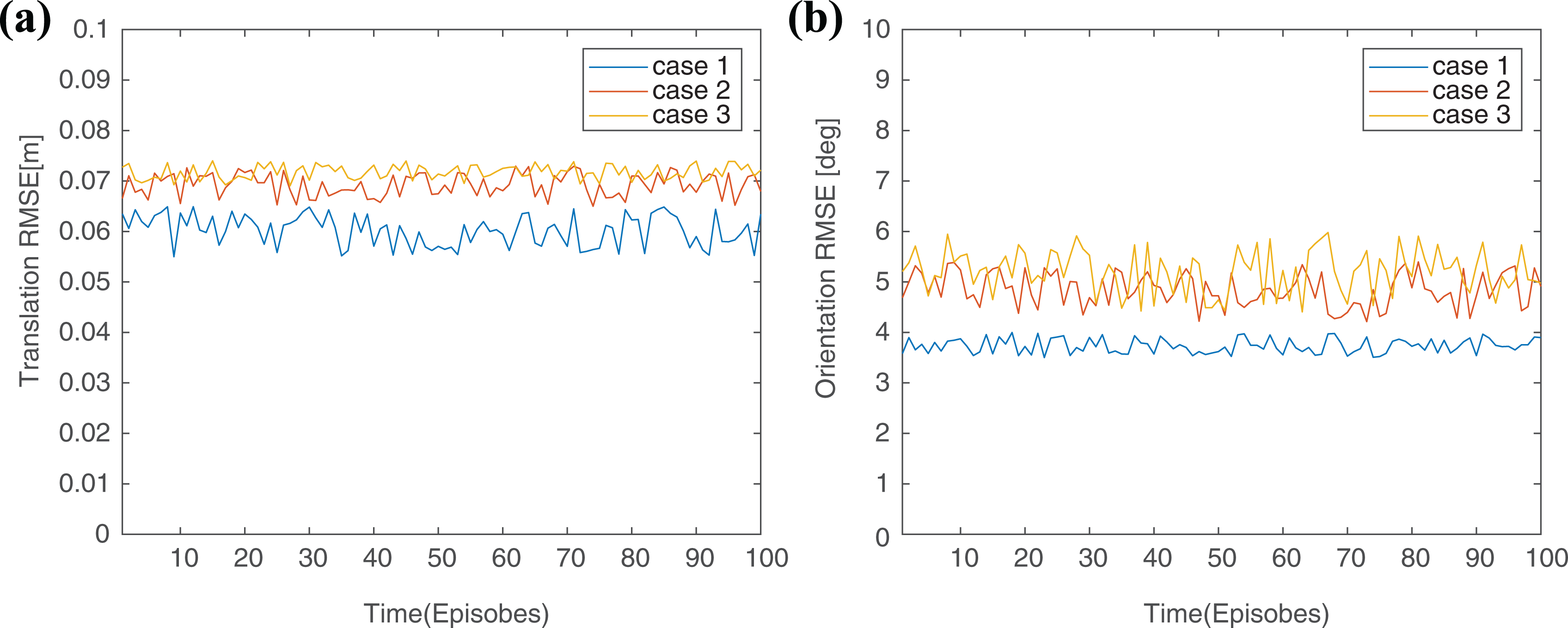
Result of experiment 3.
The proposed algorithm reduce translation RMSE (m) by 13.00% and orientation position RMSE (°) by 23.01% compared with the mechanism based on emotional recruitment model. Compared with auction model, the MAS-DQN reduced translation RMSE by 16.03% and orientation RMSE by 28.32%.
Experiment 4: In order to test the effectiveness of our algorithm in dealing with different degrees of difference in agent attributes, experiment 4 were performed when variance
Translation RMSE (m) with different variance.

Orientation RMSE with different variance.

Experiment 5: This experiment mainly compares our algorithm and the multi-agent SLAM algorithm called MR-vSLAM which only uses the prior information of map to collaborate in the aspect of localization. 40 The experimental results are shown in the Figure 10, which illustrate that the proposed algorithm reduces translation RMSE by 7.81% and orientation RMSE by 13.80%.

Result of experiment 5.
Table 3 compares the computational costs of several algorithms mentioned in this article. Where the n is the number of agent, k is the number of natural landmark, L is the number of hidden layers of the MAS-DQN, Cl is the number of neurons of the lth hidden layer.
Comparison of computational cost of the algorithms.

Conclusion
This article proposes a novel centralized multi-agent cooperative SLAM mechanism with considering the status and attributes of agents. The algorithm applies a new observation function based on ORBSLAM to apperceive the SLAM state of the whole MAS, a rainbow-based deep RL framework called MAS-DQN is designed to learn the overall utility function
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a special fund project of Harbin Science and Technology Innovation Talents Research (grant no. RC2013XK010002) and the National Natural Science Foundation of China (grant no. 61375081).