
Abstract
This article introduces a continuous reinforcement learning framework to enable online adaptation of multi-objective optimization functions for guiding a mobile robot to move in changing dynamic environments. The robot with this framework can continuously learn from multiple or changing environments where it encounters different numbers of obstacles moving in unknown ways at different times. Using both planned trajectories from a real-time motion planner and already executed trajectories as feedback observations, our reinforcement learning agent enables the robot to adapt motion behaviors to environmental changes. The agent contains a Q network connected to a long short-term memory network. The proposed framework is tested in both simulations and real robot experiments over various, dynamically varied task environments. The results show the efficacy of online continuous reinforcement learning for quick adaption to different, unknown, and dynamic environments.
Introduction
Real-time motion planning of robots often needs to consider multiple and sometimes conflicting optimization criteria, such as time efficiency (in terms of the shortest distance or time), safety (in terms of the clearance to obstacles), and energy efficiency. 1 –3 A common practice is to combine these criteria in a cost function as a weighted sum. However, determining proper values for the coefficients in the cost function is not a trivial issue but often done manually in an ad hoc manner. It is difficult to determine the coefficient values of a combined optimization function before having the robot perform in an environment (i.e. all the set values may not be optimal). Moreover, when the task environment changes, the previously set coefficient values may not be suitable anymore.
Hence, there are two related open problems: (1) how to determine values for coefficients of a compound optimization function automatically and (2) how to make the coefficients self-adapt to environmental changes. There is little work on both problems. Ishigami et al. 4 tried to generate different paths with different sets of coefficients and evaluate theses paths based on a metric, but the values of all coefficients still need to be set off-line manually. The main contribution of this article is that we propose to tackle both problems by continuously training a reinforcement learning (RL) agent in different environments, even during the test. The agent is trained to adjust the values of the coefficients of a multi-objective optimization function based on the robot’s performance in an environment with unknown dynamic obstacles, and the agent keeps learning by itself to best adapt to all kinds of environmental changes continuously. During the process, the agent becomes more and more knowledgeable and better and better at learning.
Specifically, we introduce a continuous RL agent that leverages motion planning results and can accommodate real-time robot motion planning methods. The observations of the agent are motion trajectories, whose dimension is far lower than the dimension of raw sensor data (such as the image of a camera) that is often used in end-to-end learning. Therefore, a convolutional neural network (NN) that is used to extract observation features can be removed from the agent. This simplifies the formulation of the agent and enables continuous learning. Learning continuously means that 5 –7 the agent can accumulate the knowledge learned in the past environments to help future learning and problem-solving and that later learning does not degrade much its performance in task environments learned earlier.
Related work
Lifelong or continuous learning has been a long-standing challenge for machine learning and autonomous systems. 8 –10 Mimicking humans and animals that continuously acquire new knowledge and transfer them to new tasks throughout their lifetime, continuous learning builds an adaptive system that is capable of learning from a continuous stream of information. However, dilemma between plasticity and catastrophic forgetting 11,12 is the main challenge due to inefficiency and poor performances when relearning from scratch for new tasks. 6 Thus, accommodation of new knowledge while not forgetting or interfering current learning process requires a sophisticated approach to consolidate knowledge. Memorizing past experiences 13 –15 or allocating NN resources dynamically 16,17 has been introduced to alleviate the forgetting problems. Replaying previous experiences 18,19 improves learning efficiency by reducing sequential dependence of data and forgetfulness of important experiences, but experience replay only does not provide enough self-adaptability to dynamically changing environments.
Acknowledging the impossibility of providing all the prior knowledge to perform well in the real-world, continuous learning models has been emerged for robots. One aim of the continuous learning is to train an agent that can quickly adapt to new tasks (e.g. changing navigation goals or environments). A hierarchical Bayesian model 20 has been used to transfer the knowledge learned between different but related tasks. Actor-Mimic 21 conducts the training over related source tasks, but the generalization to new target tasks needs a sufficient level of similarity between the source and the target tasks. Zhang et al. 22 employ the conception of successor factors into RL. Besides, universal value function approximators (UVFAs) 23 propose to handle different goals in one environment by incorporating the goal into the input of the value function. The generalization ability of navigating new tasks can also be achieved by combining RL with conventional motion planning methods. 24,25 However, the above method can only transfer the learned knowledge to new tasks just slightly changed from the training tasks, for example, removing or adding one or two static obstacle(s) in the test environment.
A few researchers consider transferring the trained agent to totally different environments with only static or moving obstacles. For example, one method called reinforcement planning 26 extends RL to automatically learn cost functions for search-based planners such as A* and Dijkstra’s algorithm. The method successfully transfers the trained agent to some new static environments without moving obstacles, but it lacks the ability to improve the performance continuously as the learning progresses in different, dynamically changing environments. Everett et al. 27 use a long short-term memory (LSTM) network to handle an arbitrary number of obstacles, but there are only moving obstacles and the number of moving obstacles is fixed in each environment. There is little research on solutions that can continuously train an RL agent with feedback to adapt the robot motion to changing mixed environments, where there are a variable number of static and moving obstacles. This leads us to propose a continuous, incremental knowledge acquisition model, which is essential for a lifelong learning robot that does not lose important knowledge obtained through a motion planner.
Overview of the framework
The proposed framework is illustrated in Figure 1. There are two closed loops: one is among a real-time motion planner, a robot, and an environment and the other one is between the real-time motion planner and an RL agent. In the first closed loop, the real-time motion planner interacts with the task environment based on sensing and generates the best motion trajectory according to the current multi-objective cost function for the robot to execute. Here, the “coefficients” are used in the linear combination in the cost function. In the second closed loop, an RL agent develops proper coefficients for the multi-objective cost function to maximize the desired performance in real-time motion planning.

Continuous RL with motion planning. RL: reinforcement learning.
The RL agent has three NNs: an LSTM NN, an online NN, 28 and a target NN. The three networks can be classified in two parts. One includes the LSTM network, which is used to preprocess the motion trajectories. This will be described in detail in “Observation” section. The other includes the online network and the target network, which are used for RL. The online network is continuously trained based on the continuous observation, reward, and loss calculated using the target value from the target network. The target network is created by copying the online network during initialization. During training, only the online network is trained, and then its weights are copied to the target network periodically. Note that directly implementing RL with only the online network is unstable, because the network being trained is also used to calculate the target value. To solve this problem, the separate target network is used to calculate the target value. The target network can greatly improve the stability of continuous RL and enable the agent to continuously build skills on how to adjust the coefficients to best adapt to environmental changes. If we use only the online network, the learning is prone to diverge. Note that the NN weights in RL and the planner’s optimization function coefficients are different. The former is trained through backward propagation, and the latter is tuned by the RL agent.
The proposed framework is validated by a case study with the real-time adaptive motion planner (RAMP)
29,30
and can be easily extended to benefit other real-time motion planners. The framework has the following characteristics: The skills learned from the earlier task environments are accumulated and used to make the learning in the current task environment more efficient. While the robot benefits from the learned skills provided by the learning agent to perform and adapt well in constantly changing environments, the learning agent itself is trained continuously through the online network to improve its own performance. The proposed framework is general and abstract and, hence, is independent of real-time motion planners, platforms, and task environments. The agent does not learn specific coefficients but learns a mapping from motion trajectories to coefficient changes. This enables the robot to adapt to different numbers of obstacles moving in unknown ways during the navigation. The learned skills can be transferred to different types of task environments and motion planning objectives and from a simulated world to the real world. By using motion trajectories as feedback observations, the formulation of the RL agent is greatly simplified. This makes continuous training much more efficient and hence effective. The learned optimization coefficients have clear meanings, so the resulting robot performance is understandable. This feature allows us to analyze the relationship between robot motions and coefficient changes.
The rest of this article is organized as follows. The fourth section describes our RL strategy. The fifth section provides a case study with RAMP as the motion planner. The sixth section provides and discusses the training and test results in both simulations and real robot experiments. The last section concludes the article.
RL-based coefficient determination
In this section, we will introduce the method of continuously training the RL agent in the proposed framework. Generally, the agent with discrete action space provides better stability than that with continuous action space, so we use Q networks to adjust the coefficients discretely. The input of the Q networks must have fixed length, but the observation input contains a hybrid trajectory with variable length. Therefore, we use an LSTM network to encode the information of the hybrid trajectory into a fixed-length representation.
Besides, when NNs are used in RL, the samples are assumed to be independently and identically distributed. However, when the samples are generated from exploring in an environment sequentially, this assumption doesn’t hold. Therefore, to minimize correlations between samples, the agent is trained off-policy with samples from a replay buffer. Using replay buffer may slow learning, but in practice we found that this is greatly outweighed by the stability of learning.
Observation
An observation is the input of the RL agent, but it does not contain environmental information. First, we are interested in an agent being able to handle different goals, so we follow the approach from UVFA,
23
that is, the observation includes the navigation goal

Examples of hybrid trajectories: (a) planned trajectory 0-B, (b) hybrid trajectory 0-A′-1-B, (c) switching to planned trajectory 1-D, and (d) hybrid trajectory 1-C′-2-D.
We use
Note that K is not a constant. Thus, an LSTM NN is used to transfer the variable-length trajectory ( The architecture of the LSTM Q network. LSTM: long short-term memory.

where
The LSTM network has the ability to add relevant information of motion states to the cell state. Hence, the final hidden state
Parameters of LSTM network and Q network.

LSTM: long short-term memory.
The best action is selected by the
Action
Now suppose we have n coefficients W
1, W
2,
Reward
An RL agent should learn from performance-driven feedback. This feedback can be modeled as a simple delayed reward function used in the training process, such as the time to reach a goal location or the number of collisions. Our reward r is calculated to evaluate the robot’s performance as follows:

where

and the constant
According to equation (2), the agent can only receive a positive reward when it succeeds in arriving at the goal region within the time limit
Updating of weights in NNs
There are totally three NNs in our RL agent: the LSTM network, the online network, and the target network. The weights of the online network and the LSTM network are updated by the backward propagation of the error e, and the weights of the target network are copied from the weights of the online network periodically. The interval (or number of steps) for this copying is a hyper-parameter, which is determined by a pilot test in the simulation. The error e is

where

and
Case study
In this case study, we use the RAMP as a selected motion planner module in the proposed continuous RL framework. We will first review RAMP and then introduce how to utilize it in the proposed framework.
Overview of RAMP
RAMP enables the simultaneous planning and control in dynamic environments. RAMP always maintains multiple trajectories called a population through a trajectory generator. At the start of each control cycle, the lowest cost trajectory in the population is selected as the best trajectory. Trajectory costs are calculated through a trajectory evaluator. While the robot moves along the current best trajectory, RAMP keeps modifying the population based on the latest sensing information. The above process continues until the robot reaches the goal. There are both feasible (collision-free) and infeasible (not collision-free) trajectories in the population. Sometimes the robot has to follow an infeasible trajectory when there is no feasible one, and the robot will stop if a collision will occur within a short time threshold, called imminent collision. While the robot is stopped, RAMP continues to modify the population until (1) it finds a better trajectory for the robot to switch to or (2) the obstacle causing the imminent collision moves away.
RAMP uses different cost functions to evaluate feasible and infeasible trajectories. The cost functions for feasible trajectories and infeasible trajectories are shown in equations (4) and (5), respectively.


where T, A, and D are the estimated execution time, the orientation change, and the distance to the nearest obstacle of the feasible trajectory, respectively, and
Continuous RL with RAMP
The continuous RL framework after utilizing RAMP is shown in Figure 4. Here, the target NN is hidden for clarity. In Figure 4, the best trajectory generated by RAMP is represented as

Case study with RAMP. RAMP: real-time adaptive motion planner.
Results
In this section, we present both the simulation and the real experimental results from the above case study with RAMP.
Simulation experiments
The simulations are conducted on the Gazebo simulator using a four-core i5 2.4 GHz CPU. The Gazebo simulator uses a physical engine. The robot in the simulator needs to receive control commands (linear and angular velocities) and respond to the commands under the constraints of the physical engine, so there are control errors even in simulations. The moving obstacles in the simulations are able to move in different ways. The trajectories of all moving obstacles are unknown to the robot. Only the instant positions and orientations of moving obstacles are sent to the robot as sensed results at a fixed frequency. The size of one simulation environment is 6
Training
The training environments are shown in Figure 5 (called Tr. A
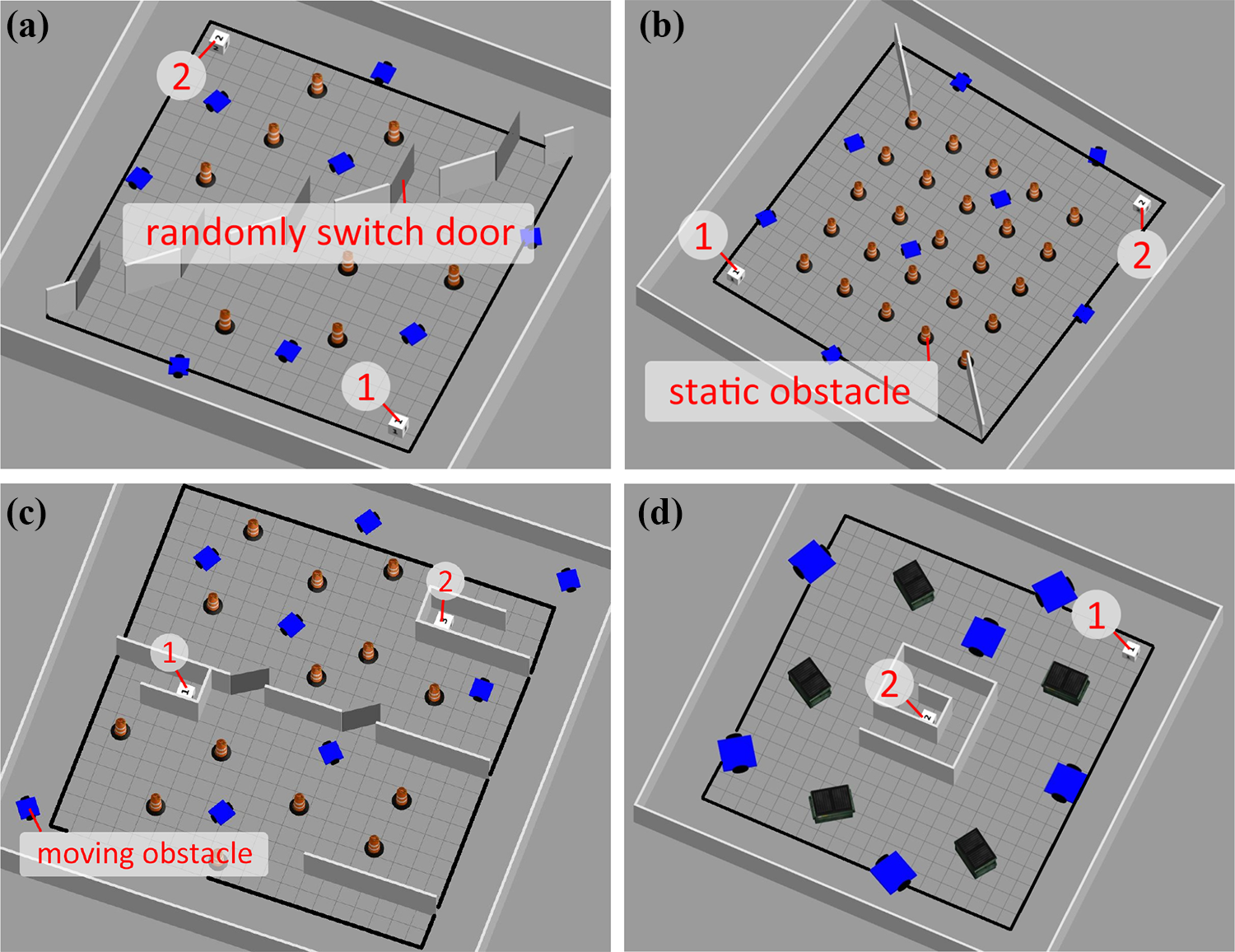
The training environments (note that the blue cars are unpredictable moving obstacles): (a) Tr. A, (b) Tr. B, (c) Tr. C, and (d) Tr. D.
The RL agent was trained for two rounds. In each round, the agent was trained in Tr. A, Tr. B, Tr. C, and Tr. D, sequentially. In each training environment, we trained the agent for 50 episodes and then switched to the next environment. Recall that the coefficients are changed by a fixed step
The average execution time (s) with the standard deviation using different

Boldface values are used to highlight the maximal or minimal values in the corresponding table.
The average # collisions with the standard deviation using different dW and Tu .

Boldface values are used to highlight the maximal or minimal values in the corresponding table.
The 95% confidence interval of execution time (s) using different dW and Tu .

Boldface values are used to highlight the maximal or minimal values in the corresponding table.
The 95% confidence interval of # collisions using different dW and Tu .
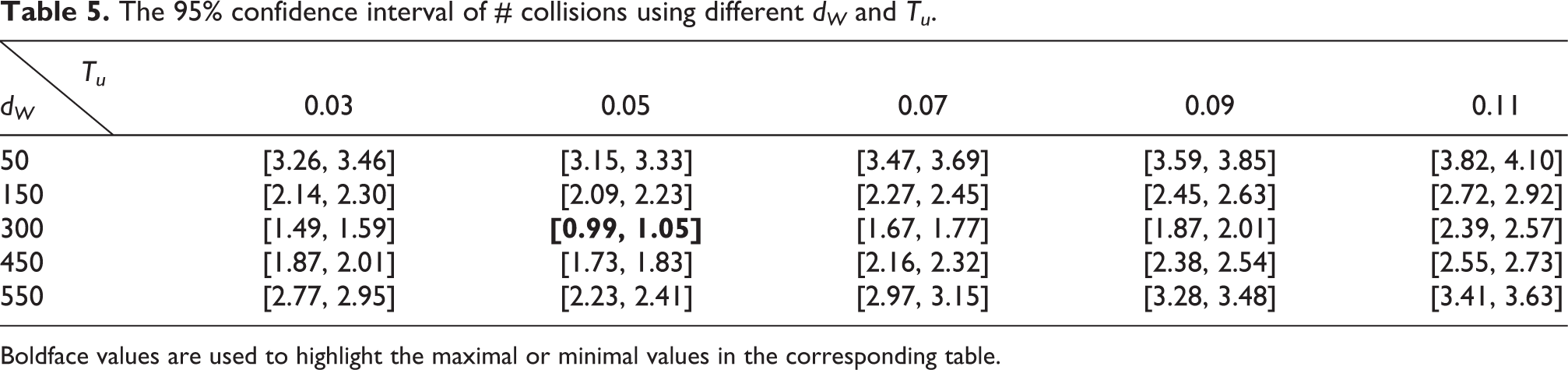
Boldface values are used to highlight the maximal or minimal values in the corresponding table.
The curves of the execution time, the number of collisions, the number of coefficient changes, and the loss during the training process are shown in Figure 6. They were filtered by the moving average with a window size of 10. The points marked by “Tr. A, Tr. B,…” mean that the training was switched to the corresponding environments. We use a value called ne to measure the skill that the agent has learned, as shown in Table 6. At the start of the training, the agent could not converge (the execution time was still decreasing when we switch the training). After the agent was trained in more environments, it starts learning with a shorter initial execution time and converges faster. This means our agent was learning continuously to optimize its performance in different types of task environments.

(a to d) The training results under the setting of
The maximum continuous number of episodes in which the shortest execution time has not become better in the training (denoted by ne ).

Test
To illustrate the generalization ability of the trained agent, we tested the agent trained with
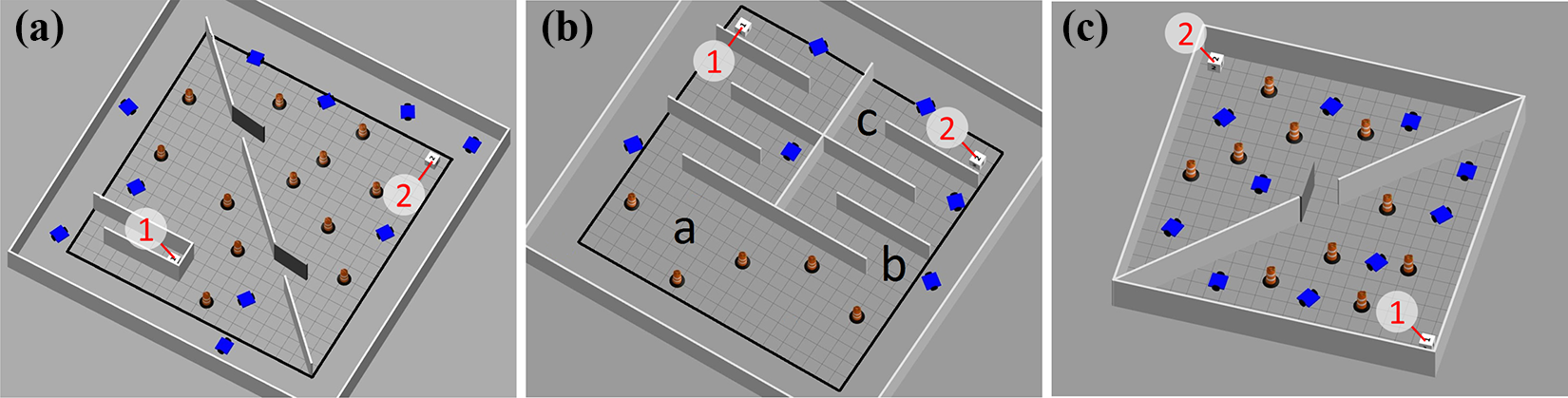
The test environments (note that the blue cars are unpredictable moving obstacles): (a) Te. A, (b) Te. B, and (c) Te. C.
In Te. A, the walls and the doors in the working zone are placed along the diagonal.
In Te. B, there is an area similar to a maze in the upper half of the working zone. It is less cluttered than the training environments, but the distance from the start to the goal is longer.
In Te. C, the working zone is directly bounded by walls. Both the robot and the moving obstacles can only move within the working zone, so that the robot will always work with 10 moving obstacles in this environment.
The test results are shown in Figure 8 and Tables 7 and 8. The performance measurements are the same as those in the training. We found that both the continuous learning agent and the noncontinuous learning agent outperformed the fixed human-tuned coefficients. Furthermore, the continuous learning agent significantly improves the performance of noncontinuous agent (

(a to c) Average test results over 100 episodes.
The 95% confidence interval of execution time (s) in the test.

FHC: fixed human-tuned coefficients; NLA: noncontinuous learning agent; CLA: continuous learning agent.
Boldface values are used to highlight the maximal or minimal values in the corresponding table.
The 95% confidence interval of # collisions in the test.

FHC: fixed human-tuned coefficients; NLA: noncontinuous learning agent; CLA: continuous learning agent.
Boldface values are used to highlight the maximal or minimal values in the corresponding table.
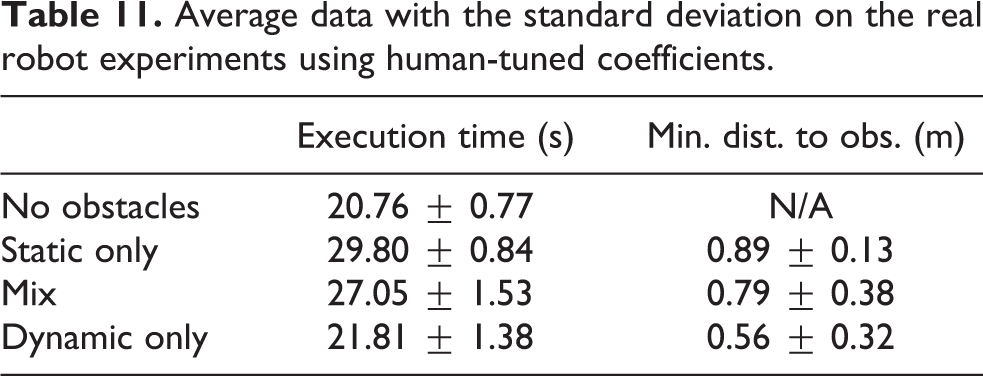
Average data with the standard deviation on the real robot experiments.

Figure 9 shows the curves of the coefficients tuned by the continuous learning agent and the snapshots at three different time instants during one of the test episodes in Te. B. The corresponding places of the snapshots in Te. B are marked in Figure 7(b) to (d). The horizontal “plan number” means the number of planning cycles. At the start of the test episode, the values of the coefficients are set randomly. In snapshot (b), mixed static and dynamic obstacles are being dealt with. In this case, drastic orientation changes can easily result in collisions, and there is no space for the robot to keep far away from the obstacles. Hence, the penalties for the orientation change

(a) Curves of coefficients and (b to d) snapshots during one of the test episodes in Te. B in the simulation (note that the blue cars are unpredictable moving obstacles).
Moreover, from the results we can tell that in the same environment, when using the RL agent to tune the coefficients of cost functions online, more frequent coefficient changes often result in more efficient and safer navigation. The frequency depends largely on the changes of the environment during navigation, such as the number of moving obstacles. For example, the number of moving obstacles in Te. C remains fixed all the time, so the number of coefficient changes needed in this environment is smaller than that in the other environments, even though the environment itself is cluttered. Note that if the number of the moving obstacles in the working zone is fixed and the obstacles move along fixed trajectories, the coefficients in the cost function will converge after training for some time. This means that the number of coefficient changes in such environments will be nearly zero after convergence, because both the number and the motion pattern of the obstacles become unchanged.
Real robot experiments
Real robot experiments were performed with a Turtlebot 2 platform. The experiments were ran on a sequence of 3.5 m2 environments. As the robot traversed the environment, the continuous learning agent modified the coefficients at real-time until the robot reached the goal. For each subsequent environment, the initial coefficients were set to the final coefficients when the robot reached the goal in the previous environment.
The first environment contains no obstacles. The robot is easily able to move on a straight line to the goal. The second environment contains four static obstacles. The third environment contains two static obstacles and one dynamic obstacle moving on a straight line back and forth. The fourth environment contains two dynamic obstacles that move on straight line trajectories repeatedly and no static obstacles. An image for each environment containing obstacles is shown in Figure 10.

Real robot environments. The dynamic obstacles move on straight lines back and forth repeatedly: (a) only static obstacles, (b) mixture of static dynamic obstacles, and (c) only dynamic obstacles.
Figure 11 shows how the coefficients change over time, while the robot is executing motion. In general, the
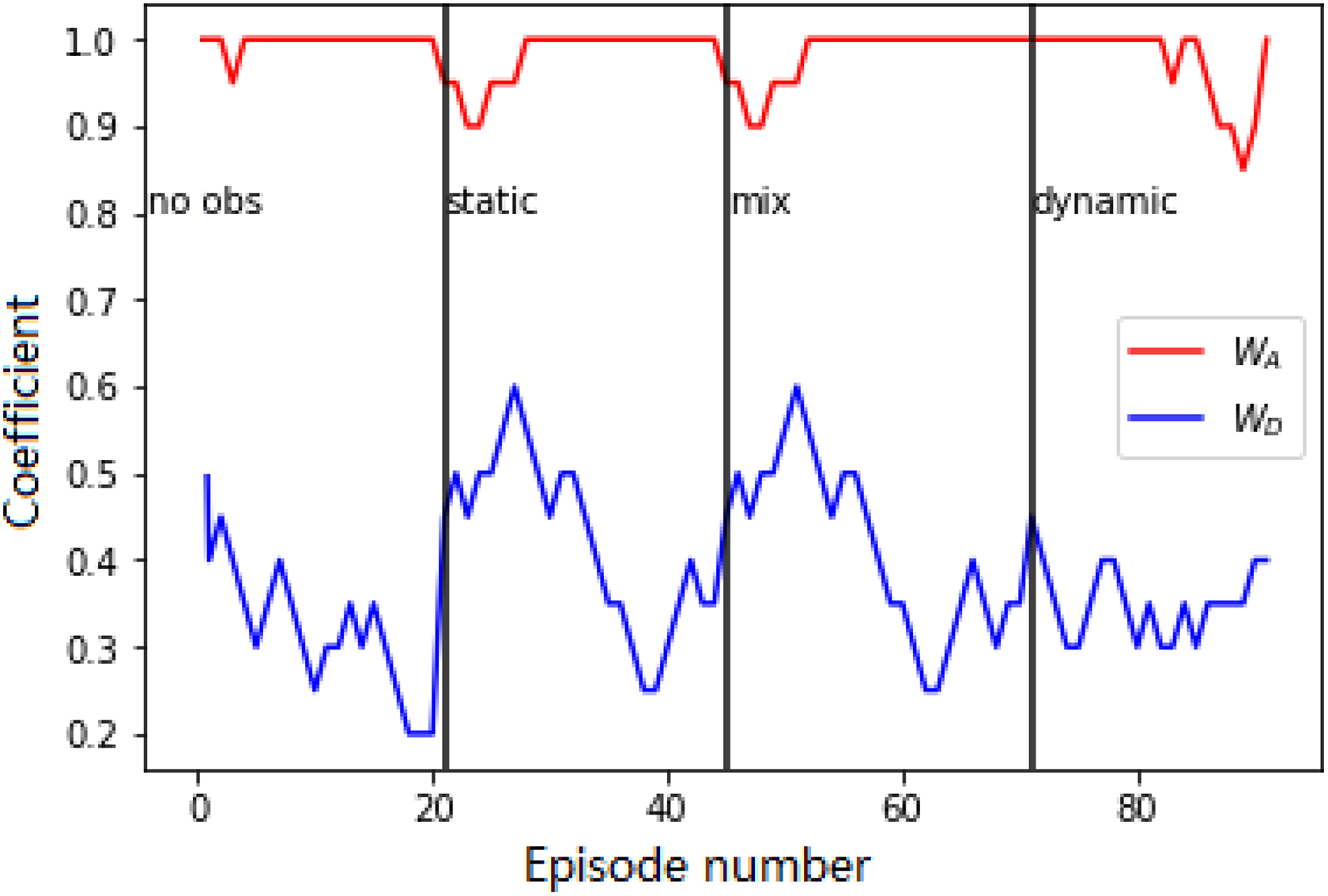
The values of the coefficients while the real robot is navigating environments. The vertical lines show when the robot begins a new environment.
Comparing the results shown in Tables 9 and 10, under the RL agent, and in Tables 11 and 12, under manually tuned coefficient values, it is clear that the reinforcement agent results in more efficient and less conservative robot motion in the environment with static obstacles and safer motion in the environment with dynamic obstacles. Note that the RL agent was trained entirely in simulation and with different environments. No further training of the agent was done before running it in the real experiments. The purpose of this is to verify the agent’s ability of transferring the knowledge learned in the simulations to the real world. With further training of the agent in real experiments, we expect that the robot will have better performances.
The 95% confidence interval of data on the real robot experiments

Average data with the standard deviation on the real robot experiments using human-tuned coefficients.
The 95% confidence interval of data on the real robot experiments using human-tuned coefficients

Conclusions
We have introduced a utility-based multi-objective continuous learning framework utilizing a real-time motion planner to make a robot continuously learn how to adapt online multi-objective optimization for robot motion. We focus on improving and testing our framework for continued learning and adaptation in changing dynamic environments. Moreover, by the simultaneous robot motion and continuous coefficient-update model learning, our framework enables the robot to self-tune its behavior online to constantly adapt to unknown changes in task environments with ever improved performance. The effectiveness and practicality of the proposed framework have been demonstrated by a case study with the RAMP, through both the simulations and the real robot experiments in various dynamic environments. In comparison with the human-tuned coefficients, the proposed framework improved the execution time about 17% on average in the simulations and 10% on average in the real robot experiments. The encouraging results verify the performance gain in the robot navigation from our framework and the transferability of the trained agent from training environments to unseen environments, and even from simulation to real environments. As such, the trained agent acquires a general ability for effective navigations in different environments.
The application of the proposed framework is not restricted to the case study with RAMP shown in this article. Our framework can accommodate other real-time motion planners and enable stability and intelligence for the robot navigation. In the real-time motion planning problem of mobile robots, the role of RL is making decisions at a semantic level for the robot navigation. One of the ways to make such decisions is tuning the behavioral multi-objective coefficients online based on the performance-driven feedback. In this way, the RL agent is able to determine the time-varying preferences among different objectives at different navigation time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by xiangtan university (no. IRT-16R06 and no. T2014224) and National Natural Science Foundation of China (no. 61105092, no. 61173076 and no. 61473042).