
Abstract
In this article, a robust long-term object tracking algorithm is proposed. It can tackle the challenges of scale and rotation changes during the long-term object tracking for security robots. Firstly, a robust scale and rotation estimation method is proposed to deal with scale changes and rotation motion of the object. It is based on the Fourier–Mellin transform and the kernelized correlation filter. The object’s scale and rotation can be estimated in the continuous space, and the kernelized correlation filter is used to improve the estimation accuracy and robustness. Then a weighted object searching method based on the histogram and the variance is introduced to handle the problem that trackers may fail in the long-term object tracking (due to semi-occlusion or full occlusion). When the tracked object is lost, the object can be relocated in the whole image using the searching method, so the tracker can be recovered from failures. Moreover, two other kernelized correlation filters are learned to estimate the object’s translation and the confidence of tracking results, respectively. The estimated confidence is more accurate and robust using the dedicatedly designed kernelized correlation filter, which is employed to activate the weighted object searching module, and helps to determine whether the searching windows contain objects. We compare the proposed algorithm with state-of-the-art tracking algorithms on the online object tracking benchmark. The experimental results validate the effectiveness and superiority of our tracking algorithm.
Keywords
Introduction
As a major and challenging research topic in the computer vision community, object tracking has been researched for several decades. A large number of papers and algorithms have been published and presented, and readers can refer to surveys 1 –3 or visual object tracking competitions on various benchmarking data sets. 4 –6 According to statistical models of visual appearance, trackers can be mainly divided into two categories: generative model-based object tracking and discriminative model-based object tracking.
Generative model-based trackers firstly construct an object appearance model and then find out the most similar region in the image by fitting the model. Wang et al. 7 presented the spatial color mixture of Gaussians appearance model by simultaneously encoding both color and its spatial layout. Black and Jepson 8 put forward a vector-based subspace method to model rigid and articulated objects. Chin and Suter 9 proposed an incremental kernel principal component analysis method to construct a nonlinear subspace model for tracked objects with constant updating speed and memory usage. Generative models only use the information of object appearance without taking into account the background. As a result, good performance cannot be obtained in cluttered environments. Discriminative model-based trackers take visual object tracking as a binary classification problem, which models both the object and its surroundings. Grabner et al. 10 employed an online boosting algorithm to train ensemble classifiers to distinguish the tracked object and the background. Zhang et al. 11 learned Naive Bayes classifiers from compressive features for object tracking. Kalal et al. 12 proposed a tracking-learning-detection framework for long-term single object tracking. An independent detector can recover or correct a tracker from tracking failures, or with a large drift. The combination of the tracking trajectory generated by the tracker and the object’s location obtained by the detector provided unlabeled training data with structure constraints, which can improve the discriminative performance of binary classifiers.
In recent years, correlation filters have been widely applied in object tracking and object recognition, and good performance has been achieved. Correlation filter-based object tracking methods employ discriminative models to represent the object’s visual appearance, which is very efficient and simple because of the fact that the convolution of two image patches in the time domain equals an element-wise product in the Fourier domain. Bolme et al. 13 proposed an object tracking algorithm based on minimum output sum of squared error (MOSSE) filters. The tracker is robust to variations in the lighting, pose, and even locally nonrigid deformations and has shown remarkable performance despite their simplicity and high frame rates. However, the MOSSE tracker does not take into consideration variations in the scale and rotation. By employing the kernel trick on the correlation filter, the kernelized correlation filter (KCF) tracker achieved impressive performance in object tracking. 14 The KCF tracker is also restrained to only estimating the object translation. To sort out this problem, the SAMF tracker was proposed to estimate the object’s scale factor by detecting the tracked object in several scaled images by bilinear interpolation. At the same time, histogram of oriented gradient (HOG) and color naming were fused together to improve the performance. 15 Danelljan et al. 16 proposed a discriminative scale space tracker to estimate the object scale by training correlation filters in a scale pyramid using HOG features. However, correlation filter-based object tracking methods usually utilize a periodic assumption to generate the training samples in the target neighborhood, thus boundary effects are inevitable. To address the problem, a spatial regularization component was introduced to penalize correlation filter coefficients. 17 Ma et al. 18 proposed a robust scale adaptive tracking algorithm which used a sequential Monte Carlo method to estimate the object scale and determined the object location by a KCF. Hu et al. 19 introduced an independent filter to estimate the object’s scale and figured out a local strategy to expand the searching area of the tracker to deal with the object’s fast motion and occlusion. Zhou et al. 20 proposed a spatiotemporal context learning method with multichannel features using an improved scale adaptive scheme for object tracking, and good performance was achieved. Correlation filter-based trackers are robust to motion blur and illumination changes, but they are notoriously sensitive to the deformation since the learned models depend strongly on spatial layouts of the tracked object. Bertinetto et al. 21 proposed a simple combination of correlation filters and histogram scores to deal with motion blur, illumination changes, and deformation, and it hit the target that coming up with a good performance. Zuo et al. 22 proposed an effective and efficient approach to learn robust and discriminative support correlation filters for real-time object tracking. Ma et al. 23 proposed a long-term correlation tracking algorithm. Three correlation filters were trained to estimate the translation, the scale variations, and the confidence of tracking results. In addition, a random fern classifier was trained to redetect the tracked object in case of tracking failures.
During security robots performing the surveillance and reconnaissance tasks, it is highly impossible to avoid scale changes and rotation motion of the object in tracking. In the past, researchers focused much more on the estimation of the object’s scale while less on the object’s rotation motion else. As a result, robust scale and rotation estimation is still a critical and challenging problem. Furthermore, in object tracking, especially long-term object tracking, trackers sometimes lose the object or suffer from a large drift due to some unavoidable difficulties such as the occlusion, changes of the scene illumination, and the object’s appearance, low-quality or compressed images, fast and complex object maneuvering. It is critical for long-term trackers to be self-recovered or reinitialized from failures. The detection modules are dedicatedly designed to recover or correct the tracker in the literture. 12,23 However, it is difficult to detect rotated objects robustly and accurately. Moreover, these detectors need to scan each sliding window to determine whether it contains the object, which usually requires a lot of computing time and resources so as to reduce the real-time performance of tracking algorithms. In this article, we proposed a robust long-term object tracking (RLOT) approach with adaptive scale and rotation estimation. The Fourier–Mellin transform takes advantage of the fact that scale changes and rotation motion in the original image are manifested as pure translations in the log-polar space of the magnitude spectrum, which has been widely employed in image registration. 24 –26 Inspired by the Fourier–Mellin transform, we employed the KCF on the log-polar space of the magnitude spectrum and hit the target of robust scale and rotation estimation in object tracking. What’s more, we proposed a weighted object searching method based on the histogram and the variance to redetect the lost object for trackers. Some high weight candidate sliding windows can be sampled for further processing by Monte Carlo sampling techniques, thus lots of sliding windows are discarded and the real-time performance of the detection module is improved. Furthermore, two other correlation filters are trained to estimate the object translation and the confidence of tracking results. Accurate estimation of the confidence can be used to activate the weighted object searching module for relocating the tracked target when the tracker fails. The proposed algorithm will greatly improve the long-term object tracking ability of security robots in complex environments.
The rest of this article is organized as follows. The proposed scale and rotation estimation based on the Fourier–Mellin transform and the KCF is described in the second section. The estimation of the object translation and the confidence of tracking results is introduced in the third section. The fourth section presents the weighted object searching method based on the histogram and the variance. The framework of our proposed method is shown in the third section. The experiments on the online object tracking benchmark (OTB) are carried out, and the results and analysis are given in the sixth section. Finally, we give a brief summary of this article.
Scale and rotation estimation
Varied image registration techniques recover the rotation, translation, and scale parameters to align two images of the same object or of the same scene acquired from different geometric viewpoints, at different time, or by different image sensors. In object tracking, the object and its surroundings can be regarded to be approximately stationary in a short period. This assumption will hold in most cases considering that the object moves slow relative to the video frame rate, and the appearance of any adjacent two frames has little changes. So many popular and successful image registration methods such as the Fourier–Mellin transform 24 –26 can be applied to estimate the scale and rotation for object tracking. However, only two independent images are employed to estimate scale and rotation parameters in image registration, so it poses risk to hit the target of robust and accurate object tracking. In this section, the Fourier–Mellin transform 25 and the KCF 14 are combined to improve the robustness and accuracy of rotation and scale estimation.
Fourier–Mellin transform
The scale changes and rotation motion of the tracked object in the Cartesian coordinate domain correspond to purely translational motion in the log-polar domain. Similar with the human visual system, the log-polar transformation is performed through a space-variant sampling strategy with the sampling period increasing almost linearly with the distance from the transformation center to actual pixel coordinates of the samples. Therefore, the log-polar transformation is very sensitive to changes of the transformation center, namely to the translational motion of the tracked object in object tracking. The scale and rotation parameters can be estimated in the log-polar image in the time domain. However, the translational motion of the tracked object usually prompts changes of the transformation center in log-polar transformation, resulting in the inaccurate estimation of the scale and rotation parameters. In order to improve the accuracy and reduce the impact of the transformation center, we can firstly estimate the translation of the tracked object in the original image, then obtain the scale and rotation parameters in the log-polar image. However, scale changes and rotation motion of the tracked object sometimes make the estimated translation inaccurate, so it is difficult to estimate the scale and rotation parameters in the time domain. According to the shift property of the Fourier transform, the phase of the cross-power spectrum is equivalent to the phase difference between the two images that differ only by a displacement; thus, bilateral magnitude of the spectrums is likewise. To avoid the impact of the transformation center, the scale and rotation parameters can be estimated in the frequency domain. In this article, the Fourier–Mellin transform in the image registration community is used to estimate the scale and rotation parameters in the log-polar images of the magnitude spectrums.
Let us consider the image patch

Ignoring the multiplication factor

where

where
In object tracking, the FMT features are extracted as follows: Perform a Fourier transform on the input image and obtain the magnitude spectrum. Apply a high-pass emphasis filter on the magnitude spectrum. Apply a log-polar transformation on the magnitude spectrum.
A high-pass filter aims to retain the high-frequency information within an image while reducing the low-frequency information, which emphasizes the edge and contour features being in the ascendancy in scale and rotation estimation. A simple high-pass emphasis filter is used with the transfer function.
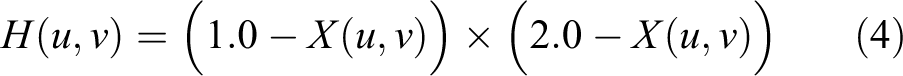
where
Kernelized correlation filter
With the circulant samples and kernel matrices, the kernel ridge regression is equivalent to a KCF which can be computed by element-wise multiplication in the frequency domain. The kernel ridge regression model of a sample

where

where the hat

Notice that

where
Scale and rotation estimation
In object tracking, the appearance of a tracked object is modeled using a correlation filter

In terms of scale and rotation estimation,

The model learning based on the correlation filter and the Fourier–Mellin transform.
In object tracking, the FMT feature z with the same size as

Therefore, we can estimate the translation of the object on the log-polar space by searching for the location of the maximal value of
It is important for the regression model to be adaptive to changes in the appearance of the object. In the last frame, the regression model

where
Estimation of the translation and the confidence of tracking results
For object tracking, there are inevitable appearance variations over time caused by the scale, out-of-plane rotation, illumination, occlusions, deformations, and so on. The core of object tracking is to robustly estimate the location of the object in every frame under these challenging circumstances. Besides, it is critical for trackers to measure the confidence of tracking results robustly and accurately. In the study by Henriques et al., 14 trackers exploited the trained template and model to measure the confidence of tracking results while estimating the location of the object. However, drifts of the object template or model updated online always exist. In the literature, 27,28 trackers employed the template and model trained in the first frame to measure the confidence of tracking results in the following frames. In practical applications, both methods mentioned above cannot provide accurate confidence of tracking results. In this article, we dedicatedly train two KCFs to estimate the object’s translation and the confidence of tracking results, respectively.
The model learning for the estimation of the object’s translation and the confidence of tracking results based on the KCF are shown in Figure 2. The model learning and fast detection of the two filters are equivalent to that of the correlation filter for scale and rotation estimation. The details can be referred to equations (10) and (11). The HOG feature is highly robust to illumination variations and local deformations, which is widely applied in object tracking, and it hits the target that coming up with good tracking performance in previous applications. For the estimation of object translation, HOG features are extracted from an image patch cropped from the object and its surroundings, which are weighted by a Hanning window. For the estimation of the confidence of tracking results, we learn another discriminative regression model Mc
only from the most reliable object region. And a layer of spatial weights is not added on the extracted HOG features. The maximal value of
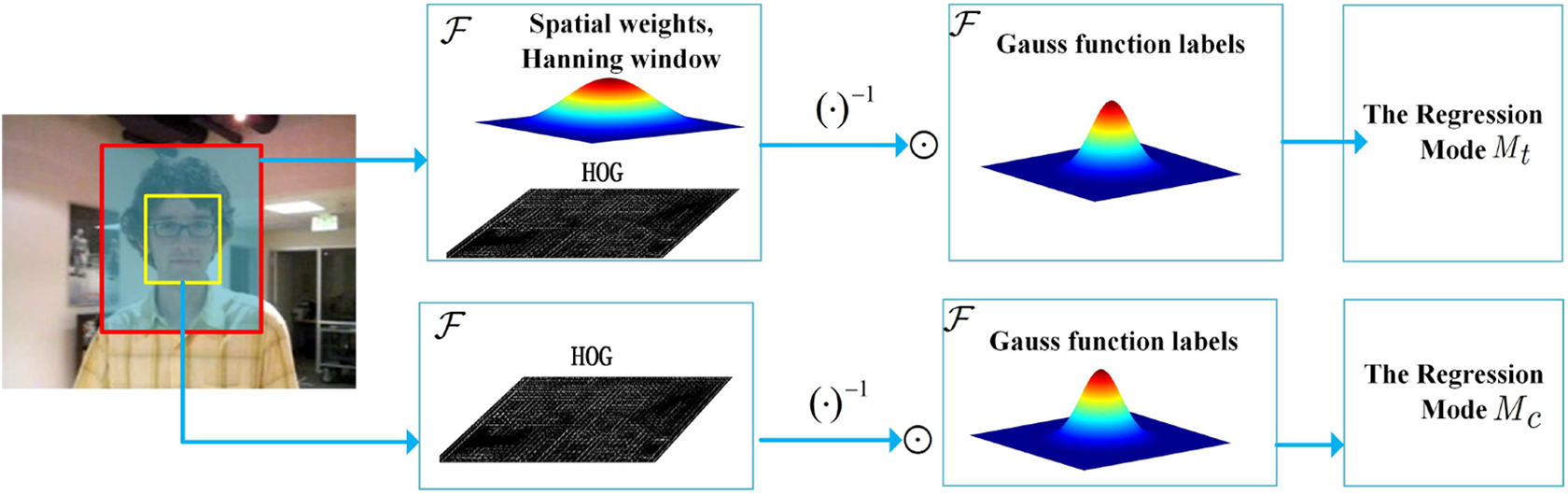
The model learning for the estimation of the object translation and the confidence of tracking results based on the kernelized correlation filter.
Weighted object searching based on the histogram and the variance
Color histograms are invariant to the translation, rotation about an axis perpendicular to the image plane, and change slowly from different angles of view. Histograms for different objects can be different markedly.
29
Simultaneously, it can acquire the distribution of colors inside the object region. Thus, color histograms have been widely applied in the computer vision community. Let I be an image. The colors in I can be quantized into n distinct color bins. Color histogram is a vector

Here we construct a histogram model

where
If the tracker loses the object, it should be able to relocate the object in the whole image Is
using the model Mh
. If the pixel x of the image Is
belongs to the color bin bx
, the probability of the pixel x coming from the tracked object is

To increase the calculation speed, the integral image of L can be used to compute

In the histogram, only the probability distribution of each color in the image is taken into account, which is not enough to describe the tracked object. The variance as an important tool reflects how “spread out” a probability distribution is. The variance is defined as the average squared deviation from the mean. Here, we exploit the variance to measure how far a set of colors in the image are spread out from their average value. The variance is very effective to weight sliding windows. We use the variance
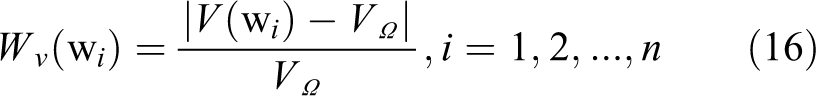
Both

where

where
When the tracker fails or suffers from large drifts, the object is likely to be around the location where the object lost. Therefore, the probability that sampled windows contain the tracked object can be boosted only using a limited searching region instead of the whole image. In this article, the searching region is set to L times of the object area. For the weighted object searching module, the model

The proposed tracking method
In this article, we train three different correlation filters to estimate the object’s translation, scale, and rotation, and the confidence of tracking results, in order to realize robust and accurate long-time object tracking. At the same time, the weighted object searching module based on the histogram and the variance is employed in case of tracking failures, which relocates the lost object. The architecture of the proposed RLOT with an adaptive scale and rotation estimation is shown in Figure 3. The proposed algorithm is described in Algorithm 1.
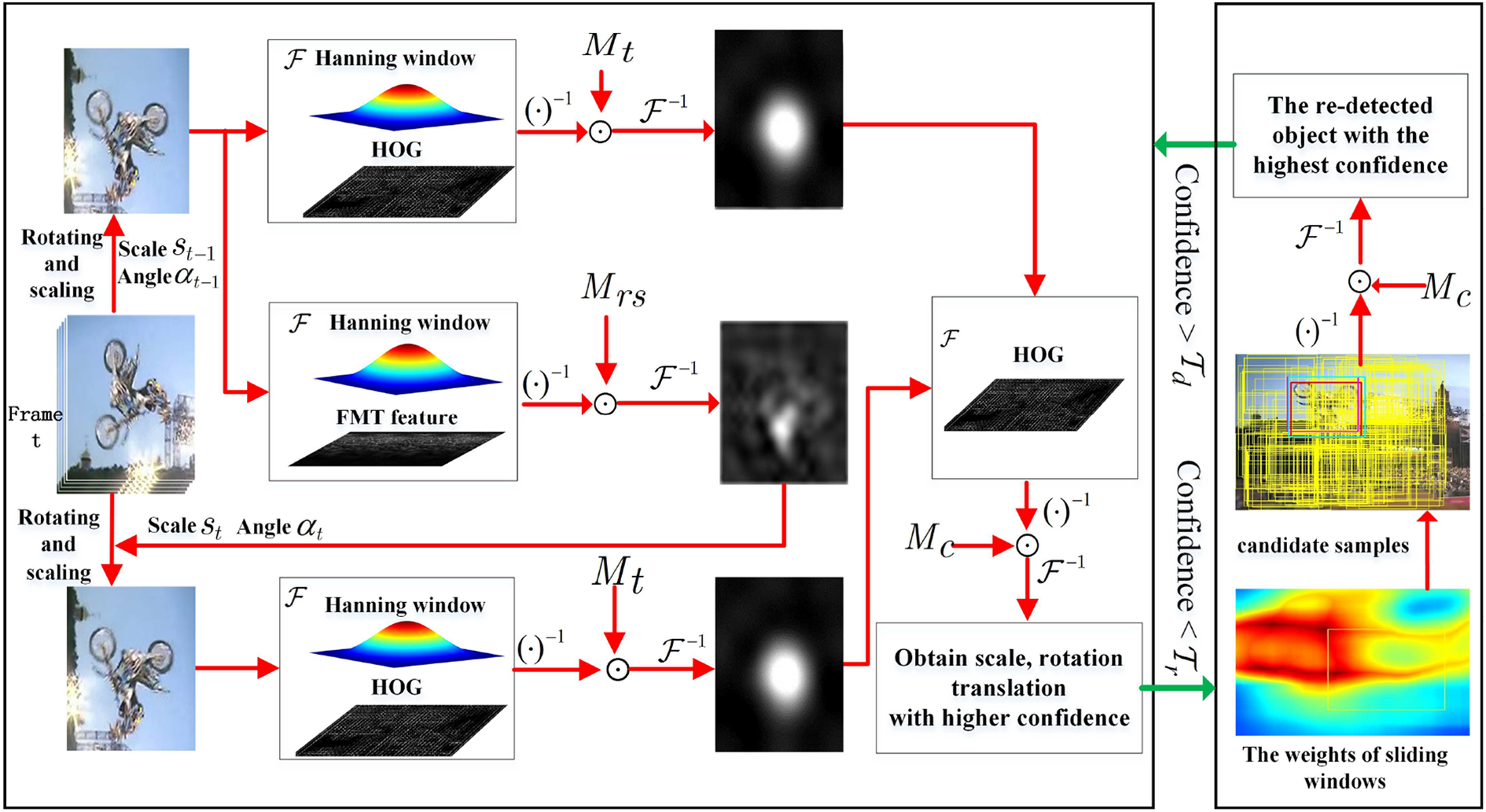
The architecture of RLOT with adaptive scale and rotation estimation. RLOT: robust long-term object tracking.
Proposed tracking algorithm


The KCF for scale and rotation estimation uses the FMT feature as input feature. The HOG feature is used to train the other two correlation filters for estimating the object’s translation and the confidence of tracking results, and its dimension is 31. We use a Gaussian kernel
Experiments
In this section, we thoroughly compare our proposed RLOT tracker and ROT tracker with state-of-the-art methods on the OTB data set that contains 100 video sequences. 6 The OTB data set contains 11 types of visual tracking challenges: illumination variation, scale variation, occlusion, deformation, motion blur, fast motion, in-plane rotation, out-of-plane rotation, out-of-view, background clutters, and low resolution. These video sequences have been annotated manually. In this article, C++ is used to implement the proposed tracking algorithm, and all experiments are performed on a PC with 3.1 GHz i7-5557U CPU and 8 GB RAM.
Experimental setup
In experiments, the precision plot and the success plot are used to evaluate the trackers. The tracking precision is based on the center location error, which is defined as the Euclidean distance between the center location of the bounding box and the manually labeled ground truth. The precision plot shows the proportion of frames in which the center location error is within the given threshold. The bounding box overlap is used to estimate whether trackers are successful or not, which is defined by
The annotated ground truth bounding boxes of OTB data sets are standard rectangles (the boundaries of the rectangle are parallel with the boundaries of the image). For OTB data sets, only standard rectangles are used to estimate the performance. In this article, we use the proposed tracking method to evaluate scale and rotation parameters, coming up with tracking results represented as nonstandard rectangles. However, according to the evaluation method provided by OTB data sets, only the external rectangles of nonstandard rectangles can be used for computing bounding box overlap ratio and center location error. The diagrams of target annotations (blue), nonstandard rectangles from our trackers (red), and external rectangles of nonstandard rectangles (green) are shown in Figure 4. It is obvious that the successful rate may be reduced when external rectangles are used to estimate bounding box overlap ratio. However, center locations of external rectangles and nonstandard rectangles are close to each other, thus precision performance may be less affected. To improve the accuracy of performance evaluations, we use nonstandard rectangles and target annotations to directly evaluate the performance of RLOT and ROT. In the meantime, due to without considering rotation motion of the object, target annotations are standard rectangles and not exactly equivalent to actual target area, but the center locations of target annotations and actual target areas are close to each other. Finally, there are still small errors using our proposed evaluation method for estimating bounding box overlap ratio. However, compared to the evaluation method proposed in OTB data sets, the error has been greatly reduced. Center location error can be estimated accurately using our proposed method.

The diagram of target annotations (blue), nonstandard rectangles from our trackers (red), and external rectangles of nonstandard rectangles (green).
Three KCFs are designed for the RLOT tracking algorithm, and their parameters are shown in Table 1, where n and m mean the width and the height of the object, respectively, measured in HOG cells, and d and a refer to the width and the height of the FMT feature, respectively. For KCFs to estimate the translation, scale, and rotation, the target region and its surrounding region should be cropped out for feature extraction, correlation filters training, and object detection. In this article, the size of the cropped image patch is 2.8 times that of the tracked object area. From Algorithm 1, a few parameters need to be set in particular. Tr
, being used to activate the weighted object searching module, is set to 0.25. We set Td
to 0.4 to decide whether the relocated tracked object is accepted and believed or not. We set Tu
to 0.4 to update the models
The parameters of three kernelized correlation filters.

KCF: kernelized correlation filter.
Quantitative evaluation
In this section, we evaluate quantitatively RLOT and ROT in comparison with some state-of-the-art tracking methods. The OTB has provided the tracking results of 29 trackers, including TLD, 12 Frag, 30 Struct, 31 CT, 11 SCM, 27 ASLA, 32 CXT, 33 and so on. Besides, we also compare KCF, 14 SAMF, 15 DSST, 16 SRDCF, 17 Staple, 21 and LCT. 23 In order to make a fair and comprehensive comparison, we give the precision plot and the success plot with three standards: the one-pass evaluation (OPE), the temporal robustness evaluation (TRE), and the spatial robustness evaluation (SRE). 4 The OPE refers to that a tracker runs throughout the entire sequence with the initialization from the ground truth location in the first frame. However, it cannot evaluate the impact of the initialization on the performance of trackers. To analyze a tracker’s temporal and spatial robustness, the TRE and the SRE introduce temporal (i.e., starting at different frames) and spatial (i.e., starting by different bounding boxes) correlated perturbations to the initialization, respectively.
The precision plots and success plots of our proposed tracking method and some state-of-the-art tracking methods, evaluated by the OPE, SRE, and TRE standards, are shown in Figure 5, where only the top 10 trackers are presented for clarity. SRDCF and Staple attain superior performance. Our proposed RLOT hits the target of robust object tracking, although there is a slight performance degradation compared to SRDCF and Staple. However, due to the lack of a detection module, ROT performs worse than RLOT. It achieves approximate performance compared to SAMF and LCT and exceeds DSST and KCF. With the OPE standard, RLOT obtains the second highest average precision performance for 0.006 (0.8%) lower than that of SRDCF. Simultaneously, its successful rate is close to that of Staple, and only 0.02 (4.3%) lower than that of SRDCF. ROT acquires similar results with SAMF and LCT in the precision and the successful rate. With the SRE standard, our RLOT realizes approximate precision performance compared to SRDCF and Staple. However, its success score ratio is lower than that of SRDCF, Staple, and SAMF but higher than that of LCT. In the same situations, ROT is also sensitive to spatial correlated perturbations. The imprecise initial bounding box results in the inaccurate estimation of rotation and scale parameters, which eventually leads to a decrease in the tracking performance. For the TRE standard, RLOT reaches the third highest average precision performance which is 0.005 (0.68%) lower than that of SRDCF. Its successful rate is the same as SAMF, which is slightly worse than Staple and SRDCF. ROT accomplishes similar tracking performance with LCT. RLOT and ROT are given the same parameters, but RLOT contains a unique detection module. RLOT outperforms ROT in the precision and the successful rate. It is obvious that the detection module is effective for object tracking.

Precision plots and success plots of tracking algorithms evaluated by the OPE, SRE, and TRE standards, where only the top 10 trackers are presented for clarity. OPE: one-pass evaluation; SRE: spatial robustness evaluation; TRE: temporal robustness evaluation.
The OTB contains 11 different types of tracking challenges, and these challenges have been annotated for each sequence. Thus, the subset with different dominant challenges can be constructed to analyze the performance of trackers under different challenges. RLOT has two main advantages: estimating rotation and scale parameters, and redetecting lost objects. Especially, the OTB data set, which contains in-plane/out-of-plane rotation and scale variation challenges, can be used to evaluate the effectiveness of the proposed rotation and scale estimation algorithm. In object tracking, the tracker is sometimes inevitable to lose its object or suffer from a large drift when it suffers from partial or full occlusion. Thus, these sequences can be used to estimate the performance of the redetection module by sequence-specific challenges including partial or full occlusion. The tracking results under different challenges including out-of-plane rotation, in-plane rotation, scale variation, and occlusion are shown in Figure 6. It is clear that our proposed RLOT gets the best performance under challenges of both in-plane rotation and out-of-plane rotation compared to the existing methods. In case of in-plane rotation, ROT’s performance that ranks second is close to that of LCT. In case of out-of-plane rotation, ROT has a slight decrease in the performance but still surpasses KCF and DSST. In case of scale variation, RLOT achieves the highest and second-class performance in the precision and the successful rate, respectively. ROT obtains the similar tracking results with SAMF. According to the above discussions, the proposed scale and rotation estimation method is quite effective, which can help to improve tracking performance. In case of occlusion, RLOT achieves better tracking performance than ROT, which also verifies the effectiveness of the detection module for object tracking.

Precision plots and success rate plots of tracking algorithms evaluated by the OPE standard under different visual tracking challenges, where only the top 10 trackers are presented for clarity. OPE: one-pass evaluation.
Qualitative evaluation
In this subsection, we compare qualitatively RLOT and ROT with current mainstream tracking algorithms, including a correlation filter tracker (SRDCF), a correlation filter tracker with a redetection module (LCT), a tracker based on tracking by detection (Struck), and a tracker with the combination of tracking, learning, and detection (TLD). We focus on 11 representative image sequences selected from the OTB data set. These sequences almost contain all the tracking challenges, as shown in Table 2. RLOT, ROT, SRDCF, LCT, Struck, and TLD are performed on the 11 image sequences, and their tracking results are demonstrated in Figure 7. In SRDCF, several adaptive and effective correlation filters are learned using some powerful features including HOG, color naming, and raw pixels; and a spatial regularization component is introduced in the learning to address boundary effects for a periodic assumption. To estimate the object’s scale, SRDCF refers to a multiple scales searching strategy, which firstly samples the target with different scales and then resizes the samples into a fixed size to compare with the learnt model at each frame. Without the rotation estimation, SRDCF performs well in dealing with most of visual tracking challenges except rotational motion (MotorRolling). In LCT, HOG features are employed to learn correlation filters. In addition, a random fern classifier is used to redetect the tracked object in case of tracking failures. Without the rotation estimation, LCT is not robust to in-plane rotation (MotorRolling). In the meantime, its redetection module suffers from drifts or even failures in cluttered environments, especially when the appearance of the background is similar to that of the tracked object (Soccer). LCT performs well under other visual challenges. Struck does not perform well in handling scale variations (CarScale and Dog1), deformation (Tiger1), and heavy occlusion (Jogging-2, Tiger1). It drifts when the object undergoes out-of-plane rotation (David), dark illumination, and background clutters (Singer2 and Soccer) and fails under fast in-plane rotation (MotorRolling). Struck achieves good tracking performance under other visual tracking challenges. In TLD, tracking, learning, and detection are combined to make up their own deficiencies. A tracker can help to provide weakly labeled training samples with structure constraints for a detector which can recover the tracker when large drifts happen or the tracker fails in turn. However, the tracking module of TLD is based on the optical flow, which is not robust to visual appearance variations. The tracking module usually suffers from large drifts, even failures under certain tracking challenges; thus, it is not able to provide its temporal motion cues to the detector. In the meantime, the detector is less effective in handling background clutters, dark illumination conditions, and rotation motion. Due to the reasons mentioned above, TLD does not achieve good tracking performance on image sequences (Singer2, Shaking, Soccer, MotorRolling, and Tiger1). In RLOT and ROT, the Fourier–Mellin transform and the KCF are engaged to improve the robustness and accuracy of the rotation and scale estimation; thus, good tracking performance is achieved in several situations of in-plane rotation, out-of-plane rotation, and scale variations (CarScale, Dog1, FaceOcc2, MotorRolling, Singer2). In case of occlusion, due to the lack of a detection module, ROT cannot be recovered and reinitialized from failures. But RLOT can redetect the tracked object (Jogging-2, Lemming, Shaking, and Tiger1). Finally, similar to LCT, RLOT’s redetection module also suffers from drifts or even failures in cluttered environments, especially when the appearance of the background regions is similar to that of the tracked object (Soccer). From the qualitative analysis, we can see clearly that RLOT and ROT perform well in dealing with scale variations, in-plane rotation, and out-of-plane rotation. At the same time, the experimental results also validate the effectiveness of the detection module for object tracking.
The visual tracking challenges of the selected 11 image sequences from the OTB.a

OTB: object tracking benchmark.
a The value 0 indicates that the sequence does not contain the corresponding challenge, while 1 indicates that the sequence contains the corresponding challenge.

Tracking results using our proposed RLOT, ROT, SRDCF, LCT, 23 KCF, 14 Struck, 31 and TLD 12 on 11 OTB image sequences (from top to down: David, CarScale, Dog1, FaceOcc2, Jogging-2, Lemming, MotorRolling, Shaking, Singer2, Tiger1, and Soccer). RLOT: robust long-term object tracking; OTB: object tracking benchmark.
Real-time performance
The real-time performance of different tracking algorithms including our proposed RLOT, SRDCF, LCT, KCF, DSST, TLD, and Struck is compared in Table 3. The average frames per second (fps) is evaluated using all the sequences on the OTB. Obviously, the KCF tracker based on the correlation filter can be run with the highest fps and followed by the proposed RLOT tracker. The KCF tracker has the best real-time performance because it uses a simple KCF to track the object, which makes it has a low computational complexity and a limited tracking performance. Most other trackers, including the proposed RLOT, are based on the KCF, which improved the tracking performance, increasing the computational complexity. The fps of RLOT is lower than that of the KCF due to the additional scale and rotation estimation and the weighted object searching module. The average processing fps of SRDCF is the lowest (only 4 fps). This is because SRDCF employs more features, including HOG, color naming, and raw pixels, to learn the object filter. The average processing fps of SRDCF, LCT, DSST, TLD, and Struck is less than 30. In practical applications, RLOT can be run at about 36 fps, so real-time requirements can be met.
The average frame rates of different object tracking algorithms.

RLOT: robust long-term object tracking; KCF: kernelized correlation filter.
Conclusions
When the security robots perform surveillance or reconnaissance tasks, the scale of the tracked object may change, the object may rotate, and the object tracking may fail. In this article, an RLOT approach with adaptive scale and rotation estimation is proposed. Our method can be divided into three parts: the estimation of the scale and rotation based on the Fourier–Mellin transform, the estimation of the object’s translation and the confidence of tracking results based on correlation filters, and the weighted object searching module based on the histogram and the variance. Our method is able to estimate the translation, scale, and rotation and the confidence of tracking results accurately and efficiently. The weighted object searching module can be used to redetect the lost object in case of tracking failures. Experiments are performed on the OTB, and comparisons are made among our proposed RLOT and state-of-the-art trackers. The experimental results validate the effectiveness and superiority of the proposed tracking algorithm.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Key R&D Program of China (no YFC20170806503) and the National Science Foundation of China (no 61773393 and no U1813205).