
Abstract
High tracking frame rates have been achieved based on traditional tracking methods which however would fail due to drifts of the object template or model, especially when the object disappears from the camera’s field of view. To deal with it, tracking-and-detection-combination has become more and more popular for long-term unknown object tracking, whose detector almost does not drift and can regain the disappeared object when it comes back. However, for online machine learning and multiscale object detection, expensive computing resources and time are required. So it is not a good idea to combine tracking and detection sequentially like Tracking-Learning-Detection algorithm. Inspired from parallel tracking and mapping, this article proposes a framework of parallel tracking and detection for unknown object tracking. The object tracking algorithm is split into two separate tasks—tracking and detection which can be processed in two different threads, respectively. One thread is used to deal with the tracking between consecutive frames with a high processing speed. The other thread runs online learning algorithms to construct a discriminative model for object detection. Using our proposed framework, high tracking frame rates and the ability of correcting and recovering the failed tracker can be combined effectively. Furthermore, our framework provides open interfaces to integrate state-of-the-art object tracking and detection algorithms. We carry out an evaluation of several popular tracking and detection algorithms using the proposed framework. The experimental results show that different tracking and detection algorithms can be integrated and compared effectively by our proposed framework, and robust and fast long-term object tracking can be realized.
Introduction
As one of the major research topics in computer vision, object tracking is defined as estimating the location of a tracked object in continuous frames. With the springing up of high-power computers, the availability of high quality and cheap cameras and the need for automated video analysis, it has been attracting increasing attention. The achievements in object tracking have been applied to many domains such as automated surveillance, traffic control, and augmented reality (AR). However, inevitable difficulties would occur during object tracking, especially long-term object tracking, such as occlusion, changes of the scene illumination and the object’s appearance, low-quality or compressed images, fast and complex object maneuvering and real-time requirements.
As is known to all, tracking and detection can be combined to make up their own deficiencies. A tracker can provide weakly labeled training samples for a detector which can help to reinitialize or correct the former when the tracked object is lost, or large drifts exist. In the Tracking-Learning-Detection (TLD) algorithm, the tracking and detection are performed simultaneously to realize long-term object tracking. 1 However, due to the fact that the tracking and detection tasks are placed in the same thread and run sequentially at the same frame rates, thus it presents several limitations in practical applications. For example, the consumption of computing resources must be limited to the right range so as to guarantee the real-time performance; therefore, many popular and successful tracking, detection, and learning algorithms in the pattern recognition community with high computation cost cannot be integrated into the TLD framework. What’s more, the appearance of the object usually changes slowly during long-term object tracking. Typically, it is unnecessary to perform both multiscale object detection and object model updating for all frames, from which a detector can be run at a lower frame rate than that of a tracker.
Parallel tracking and mapping (PTAM) inspires us by dividing tracking and mapping into two separate parts which are processed in parallel threads on a multicore computer. 2 We here find that the front-end tracking thread can realize real-time camera pose estimation due to lower computation costs. The back-end mapping thread usually requires more computing resources to map the perceived environment, which can be processed at low frame rates. PTAM has been successfully applied in AR systems and simultaneous localization and mapping for mobile robots.
In this article, we propose a parallel tracking and detection (PTAD) framework which contains two parallel modules: a tracker as a front end is performed in real time with low computation costs; a detector including online learning and object detection regarding as a back end needs more computing resources and can be processed at a lower speed. Furthermore, our framework provides an interface to integrate and test different tracking and detection algorithms as open source. In this article, several tracking and detection algorithms are integrated to realize object tracking, and then evaluated and compared on several benchmarking datasets.
The rest of this article is organized as follows. The related work are presented in the second section. We describe our whole framework and introduce several popular tracking, detection, and learning algorithms in the third section. In the fourth section, we validate the effectiveness of the proposed PTAD framework by integrating the algorithms introduced in the third section and comparing their performance. Finally, we give a brief summary of our proposed framework and a statement of the future work.
Related work
As a major and challenging research topic in computer vision community, object tracking has been studied for decades. A large number of papers can be found, and readers can refer to surveys 3 or visual object tracking challenges on various benchmarking datasets. 4 In this section, we just introduce some work related to tracking and detection modules of our PTAD framework briefly.
Object tracking
The core of object tracking is to robustly estimate the location of an object in every frame of an image sequence. Effective appearance modeling for the tracked object is a key factor to realize robust and accurate object tracking, which generally consists of two components: visual representation and statistical modeling. 3
Essentially, visual representation refers to extracting salient visual features and designing appropriate descriptors for a tracked object. Ideal visual representations should be qualified to distinguish the tracked objects and the background, and preferably keep invariant to translation, scale, and rotation as well as robust to affine transformations. It is unrealistic to design a robust visual representation for all types of tracked objects. Therefore, various visual representations have been proposed, which can be divided into two categories: global visual representations and local visual representations. Global representations describe global characteristics of the object appearance through global visual features and descriptors such as color histogram. 5 They are generally simple and computationally efficient but sensitive to global appearance changes. For local representations, local visual features are used to characterize the object appearance. Although local visual features require more computing resources, they have many advantages: invariant to image translation, scale, and rotation; partially invariant to illumination changes and affine 3-D projection; robust to partial occlusion and relatively insensitive to viewpoint changes. Many local visual feature methods have been proposed for object tracking and detection. 6 With the rapid development of artificial intelligence technology, deep visual features learned by convolutional neural networks has been employed in object tracking. Ma et al. 7 exploited visual features extracted from deep convolutional neural networks to improve tracking accuracy and robustness. Deep features were used to train correlation filters, and good tracking performance have been achieved. 8 Furthermore, for object tracking, especially for long-term object tracking, multiple types of features can be combined to model the appearance of tracked objects, which can help to improve the robustness.
According to statistical models, trackers can be typically classified into generative and discriminative trackers. Generative trackers build an object appearance model, and then find out the most similar region in the image by fitting the model. The generative model can be built off-line or online, while it should be able to be updated online for adapting to changes of the object appearance. Wang et al. 9 proposed the spatial-color mixture of Gaussians appearance model by simultaneously encoding both of the color and the spatial layout information, which has a good discriminative ability. In recent years, sparse representation and compressive sensing techniques have been widely used to learn some generative models, which can help to improve the tracking robustness and accuracy. 10 The major problem of online generative models is lack of consideration on the background information. As a result, these trackers suffer from failures in cluttered environments, especially when the appearance of the background regions are similar with that of the tracked object.
Discriminative trackers, which aim at building a binary classifier by maximizing the separability between the object and the background, take visual object tracking as a binary classification problem. Different from generative models which only use the object appearance information, discriminative trackers model both of the object and its surroundings. Kalal et al. 1 proposed a semi-supervised P-N learning method for object tracking to build binary classifiers with structural constraints. In recent years, correlation filters have been widely applied in object tracking, and good performance has been achieved. Ma et al. 11 designed three correlation filters to estimate the translation, scale variations, and the confidence of tracking results. In addition, they trained a random fern classifier to redetect the lost object. Bertinetto et al. 12 combined correlation filters and histogram scores to deal with motion blur, illumination changes, and deformation. A spatiotemporal context learning method with multichannel features is proposed for object tracking, and good performance was achieved. 13 Lukežič et al. 14 proposed deformable parts models with correlation filters for object tracking.
Recently, deep object tracking approach has been widely applied. Held et al. 15 trained off-line neural networks that can track novel objects at 100 frames per second (FPS). In particular, to improve tracking performance, the fully convolutional Siamese approach 16 has been applied in object tracking by making use of region proposals, 17 ensembling, 18 segmentation, 19 and memory networks. 20
Object detection
Object detection is defined as identifying the presence of objects and locating identified objects in an image. Object detection can be divided into two phases: the learning phase and the recognition phase. 21 In general, detectors firstly train classifiers using prelabeled samples off-line. Then the detectors recognize and locate objects online in an image using the trained classifiers. The traditional object detection is not appropriate for object tracking due to several reasons. Firstly, the learning phases of these methods cannot be run in real time due to the consumption of large computational resources. Secondly, the tracked object needs to be manually selected in the first frame in practice, which is difficult to obtain enough prelabeled samples to train highly discriminative classifiers. Finally, these detectors are trained for a generic category of objects (such as any car) rather than a single specific object (such as a particular car). As a result, these detectors are hard to classify similar objects from the same category in object tracking. Essentially, during object tracking, detectors can obtain a small number of labeled samples from the first image and a large number of unlabeled samples from subsequent images. Therefore, the learning methods for object tracking should be competent to exploit both labeled and unlabeled samples for online incremental learning and training. As a result, online semi-supervised learning methods have been proposed to solve these problems.
Online semi-supervised learning can be mainly categorized into self-learning and co-learning. 22 Self-learning is a widely used semi-supervised learning framework, which firstly trains an initial classifier with the labeled data. The labels of the unlabeled data are predicted in advance according to the classifier, and the most confident data are added into the training set. Then the classifier is retrained using the new training set. This procedure is run iteratively and repetitively. In the work of Grabner et al., 23 online boosting learning algorithms based on self-learning were proposed for selecting discriminative features to train classifiers. The discriminative capability of each feature can be ranked in a feature pool, and top-ranked features are selected to construct classifiers for object detection and tracking. The self-learning support vector machines (SVM) can be used to train SVM classifiers with strong discriminative competence to classify the object and the background. 24 Ding et al. 25 proposed a novel manifold regularized model in a reproducing kernel Hilbert space to solve the online semi-supervised learning. Chen et al. 26 proposed a novel online semi-supervised learning framework which exploited multiple regularization terms based on the notion of ascending the dual function in constrained optimization. Liu et al. 27 proposed an adaptive and online semi-supervised least square SVM with a manifold regularization for the online classification of streaming data. Self-learning is a kind of wrapper algorithms, whose performance is affected greatly by the chosen supervised learning method and the collected labeled and unlabeled data. For example, when unlabeled training samples are misclassified or polluted, tracking errors will be accumulated during object tracking, which will result in great drifts and even failures.
To deal with these problems, researchers developed co-learning frameworks for object detection by building multiple and independent classifiers. In co-training, it is assumed that features can be divided into several conditionally independent subspaces. Classifiers are trained using the prelabeled data in the feature subspaces. Then each classifier classifies the unlabeled data, and most confident data (data and its predicted label) are recorded. The data recorded from one classifier are regarded as training samples to train other classifiers. The co-learning strategy has been widely used for object detection and object tracking. Zeisl et al. 28 proposed an online semi-supervised multiple instance boosting algorithm, which can incorporate more priors and deal with uncertainties to update positive model for occlusions. Li et al. 29 developed a novel semi-supervised CovBoost method which utilizes the information from auxiliary samples, target samples, and unlabeled samples to train a strong classifier. The CovBoost method adapts to appearance variations of the object and background successfully in experiments. Co-learning strategy can also be introduced into the semi-supervised SVM learning framework, especially multiple kernel SVM for object tracking and detection. 30 Meshgi et al. 31 proposed a novel co-learning framework which combined two different detectors: a rapid adaptive exemplar-based detector and another more sophisticated but slower detector with a long-term memory.
After training classifiers, detectors can identify and locate objects in an image. Similar to visual appearance representations mentioned above, the detected object can also be characterized using either local visual features or global visual features. For local visual features, detectors search objects in the whole image using feature matching methods. However, when the area of the object in the image is small or the object has less texture, the number of the features extracted from the object region may be not enough to realize robust object detection using matching methods. Thus, the applications of feature matching methods are restricted in practice. The sliding window-based methods are widely used, where the whole image is divided into a number of subimage patches. Then a classifier is applied to each patch to decide whether it contains the object or not. The size of an object (objects) may not be fixed in an image sequence. To detect objects at any scale and position, researchers made use of a pyramid of images to generate sliding windows with a fixed size. However, it usually requires lots of computing resources to construct a multiscale pyramid of images. Considering the abovementioned reasons, researchers designed sliding windows with different sizes in original images to improve the real-time performance. 1 However, the number of the sliding windows may still be too large to process in real time, especially for high-resolution images. Thus cascaded classifiers concatenated with several different classifiers were introduced to reduce the computing time. 32 Each classifier in the cascade architecture either passes a sample to the next classifier when its predicted label is positive or rejects the sample and processes a new sample from the beginning again. A sample that passes through all classifiers can be regarded as a positive sample. In cascaded classifiers, the first few classifiers are dedicatedly designed to classify samples using simple and efficient features, which can be processed at high speed. Thus a large number of samples are rejected with less time consumption using the first few classifiers.
As a subset of machine learning, deep learning based on artificial neural networks has been applied to solve the semi-supervised learning problem, such as pixel recurrent neural networks, 33 deep convolution generative adversarial networks, 34 generative adversarial networks, 35 ladder models, 36 and auxiliary deep generative networks. 37 Currently, real-time performance has been achieved in deep learning applications, 15,38 but training deep neural networks is complicated by the fact that a large number of parameters are updated during training. This slows down the training by requiring lower learning rates, careful parameter initialization and more computing resources, and makes it notoriously hard to realize online, semi-supervised deep learning.
The framework of PTAD for object tracking
As our work is closely allied with TLD, we make a brief introduction here. TLD was proposed for long-term single object tracking. As shown in Figure 1(b), it mainly consists of three components: a tracker, a detector, and a learning module. The tracker used to estimate the motion state of an object in each frame is named the median flow (MF) tracker that is based on the Lucas–Kanade (LK) optical flow method. 1 The detector, which is cascaded by a variance filter, a random forest classifier, and a nearest-neighbor classifier (NN classifier), scans each sliding window and makes a judgment that whether the object exists or not. Then the outputs of the tracker and the detector are integrated into a single bounding box as the output result of TLD. The P-N learning module exploits the output result to generate training samples and update the cascaded classifiers. From Figure 1, it can be seen that TLD is different from general tracking-by-detection methods. 39 In TLD, the tracking and detection are performed separately, and fulfill information exchange via a learning component. This framework has several advantages. On the one hand, an independent detector can recover or correct a tracker when it fails, or drifts are large. On the other hand, the combination of the tracking trajectory generated by the tracker and the object’s location obtained by the detector can provide unlabeled training data with structure constraints. The data can be used to train more discriminative binary classifiers.
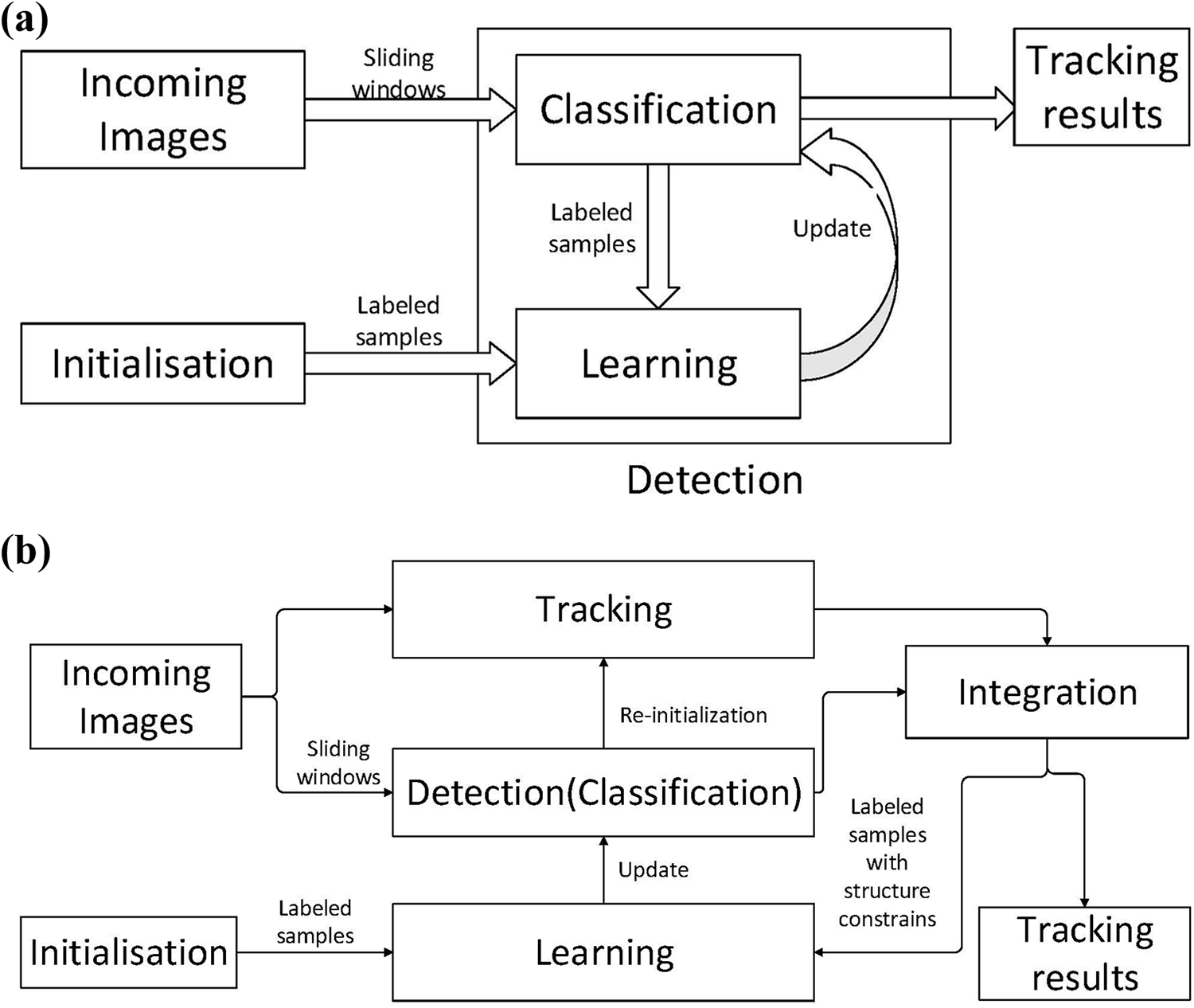
General tracking-by-detection paradigms and TLD method for object tracking. For general tracking-by-detection paradigms, a single process deals with tracking and detection simultaneously, and tracking results are brought from the detector’s output directly. For TLD, tracking and detection are processed separately, and their outputs are integrated into learning modules with structure constrains. A detector helps to recover a tracker when drifts are large or the tracker fails. (a) General tracking-by-detection paradigms. (b) TLD method for object tracking. TLD: Tracking-Learning-Detection.
However, the TLD framework has some demerits. Firstly, the appearance of the object usually changes slowly during long-term object tracking. For example, as shown in Figure 2, the visual appearance of the panda changes slowly and gradually during several consecutive frames. In most periods of object tracking, visual appearance always changes gradually and slowly. So it is unnecessary for the learning module to update the classifiers in every frame. Secondly, with the development of tracking techniques, many proposed trackers do not often encounter failures. Thus a detector does not have to be processed in each frame for recovering or correcting a tracker. Finally, in the TLD framework, tracking, learning, and detection modules are operated in the same thread, and each frame is processed by the three modules successively. Currently, there are many tracking, learning, and detection algorithms with good performance which can be used to improve the performance of object tracking, but their computation costs may be quite high. Hence it is difficult to integrate these algorithms into the TLD framework for real-time applications.

Example frames from benchmarking tracking sequences, which can be found at http://cmp.felk.cvut.cz/tld. We can find that the appearance of the target object (panda) usually changes slowly between several continuous frames.
Due to the drawbacks mentioned above, we propose a PTAD framework which consists of two independent and parallel components: the tracking component and the detection component which are processed in two different threads, respectively. A tracker similar with the tracking component of TLD is used to localize the object from frame to frame. The tracker is regarded as the front end of PTAD, which should have low computation burden for real-time implementations. In PTAD, if the tracker loses the object, it cannot be self-recovered or reinitialized. The detector including classification and learning modules is defined as the back end of PTAD. For realizing multiscale object detection, a detector must scan lots of sliding windows in the whole image to decide whether a tracked object exists or not. Due to lack of enough prelabeled samples, it is impossible to train a robust and accurate binary classifier off-line for practical applications. Therefore, an online semi-supervised learning algorithm is employed to update the classifier for object detection. The detector commonly requires more computing resources and computing time. In object tracking, the tracker is sometimes inevitable to lose its object or suffer from a large drift, while it can be recovered and reinitialized from failures as expected. In PTAD, the detector can help to reinitialize and correct the tracker.
The architecture of PTAD is shown in Figure 3. In the first frame, an initial object is manually defined, which is used to initialize a tracker and train a detector via semi-supervised learning algorithms. After initialization, the entire process of the PTAD framework is divided into consecutive segments which are shown as cyan boxes. Red boxes in the segments represent that these frames are processed only by the tracker. The number of these frames in the red boxes is adjustable in real applications, which has been noted as

The architecture of the proposed PTAD. The PTAD framework is split into tracking and detection (including classification and learning modules), which are two separate and independent tasks and processed in two different threads respectively. A tracker regarded as the front end of PTAD can process the image sequence at high speed. A detector is the back end of PTAD. The outputs of the tracker and the detector are integrated into the learning modules. At the same time, the outputs of the detector are used to reinitialize and correct the tracker. Red boxes represent that these frames are processed only by the tracker. The number of these frames in the red box of each segment is adjustable in practical applications, which is represented as
In PTAD, the precision of the tracker is important in the process of generating accurate training samples for training robust cascaded classifiers with a low misclassification rate. Knowing whether the tracker fails or not matters a lot in order to improve the precision of the tracker. A tracking failure detection module has already been integrated in existing trackers such as the MF tracker. If such trackers are integrated into PTAD, their own tracking failure detection module will be directly used. For other trackers without tracking failure detection modules, the normalized correlation coefficient (NCC) method will be employed to identify their tracking states. In this case, several last correct tracking results before the current frame are stored as templates with which the current tracking result is compared to obtain the pairwise similarities. If the maximum similarity is greater than a threshold, the current tracking will be considered to be successful, or failed on the contrary. If the tracking succeeds, the current tracking result will be regarded as a new template to replace the earliest one. If fails, the detector will reinitialize the tracker, delete all the previous templates, and add a new template cropped from the new initial location. The threshold is a parameter only for the NCC method. The tracking failure detection can help to improve the precision performance of a tracker, at the cost of spontaneous reducing the recall rate. However, robust detectors can help to reinitialize and correct the tracker to improve the recall performance of the tracker. Therefore, it is possible to achieve both high precision and recall rate at the same time for tracking algorithms when they are embedded in PTAD.
When the tracker loses the object, the output bounding box of the detector is used to reinitialize the tracker. Since the two modules are performed in parallel, the tracker may handle with the next several frames during the reinitialization. Based on the assumption that the object appearance varies slowly and gradually among several successive frames, a template matching method has been utilized to locate the object in the current TF. As shown in Figure 3, the detector should reinitialize the tracker in the last frame of each segment. If the detector fails finding the object, it continues to reinitialize the tracker in the following segments until it succeeds. If the tracker succeeds, the detector will process the image patch cropped from the tracking output and obtain a confidence. At the same time, the detector deals with the sliding windows. If the detector fails locating the object in the image and the confidence of the tracking result is high, the tracking result will be added into the learning module to update the classifiers. The two outputs will be merged into a single bounding box to correct the tracker under the circumstance that the detector locates the object with a high overlap rate. Furthermore, if the confidences of the two results are high, the merged result will be also fed into the learning module. On the contrary, we regard the bounding box with the maximal confidence as the final result. The tracker is reinitialized when the confidence of the tracker result is lower than that of the detection result. The affine transformation is operated on the object fed into the learning module to generate enough training samples.
As a significant advantage compared with TLD, various tracking and detection algorithms can be integrated into our PTAD framework under a real-time constraint. In the following sections, several tracking and detection algorithms will be integrated into the framework, and experiments will be performed on benchmarking datasets.
Trackers
Here we only focus on single object tracking algorithms. Trackers, which are regarded as the front end of PTAD, should be able to realize real-time operations and accurate object tracking. We introduce two famous tracking algorithms into PTAD.
Correlation filter-based trackers
Conventionally, correlation filters are used to measure the similarity between two signals, which can produce high correlation responses for two similar signals and low responses for two distinctive signals. Thus correlation filters can provide a reliable distance metric between the object and the background. Here we give a brief introduction of the core workflow of general correlation filter-based trackers. Firstly, the initial position of an object is manually determined in the first frame and an image patch is cropped from the location. Visual features are extracted from the image patch, which are used to train an initial correlation filter. For each frame after initialization, the estimated position and size in the previous frame is used to crop an image patch from the current frame, where visual features are extracted. A cosine window is applied for smoothing artifacts introduced by wrapped-around edges. Subsequently, correlation operations between current visual features and the previously trained correlation filters are performed based on convolution. Then inverse fast Fourier transform is performed on the correlation results to obtain a spatial confidence map where the object’s position has high peak responses. Finally, trackers can obtain new training samples from the estimated position in the current image to learn and update the correlation filter for other images. Henriques et al. 40 proposed the kernelized correlation filter (KCF) tracker. Correlation filters combined with kernel methods are more robust to appearance variations than simple linear classifiers. In KCF, the histogram of oriented gradient (HOG) feature and multichannel color features are fused together to facilitate robust object tracking. In actual experiments from Henriques et al., 40 KCF can be run at over 100 FPS, which actualizes a high accuracy. Here the KCF is employed to evaluate the PTAD framework.
Optical flow trackers
Optical flow is commonly used to capture the apparent motion of an object from spatiotemporal image brightness variations, which is usually estimated by the LK differential method. It has been widely applied in object tracking, and good tracking performance has been achieved. In object tracking, object is represented as a bounding box, and a number of points in the box are selected to estimate the translational vectors between consecutive frames, which yields the object’s motion information. There are two key assumptions for the LK tracking method to be considered. Firstly, a constraint exists on the local brightness constancy, which shows the object in a certain image region has the same apparent brightness during a short time. Secondly, it assumes that the magnitude of the flow is small, and the object in an image region only moves to a local neighborhood of the object. The LK tracker can be processed at high speed. Thus the LK tracker is not only appropriate to deal with small illumination fluctuation, low noises and slight local deformation, but also proper for real-time implementations. In TLD, the MF tracker is based on the LK tracking method and has realized tracking failure detection using Forward-Backward error. The MF tracker is integrated into PTAD for testing our framework.
Detectors
Detectors identify the existence of an object in the whole image by a sliding-window method and locate its position if existed. In this article, object detection is considered as a binary classification problem for generated sliding windows. In order to improve detection efficiency, cascaded classifiers are used to classify these sliding windows.
The sliding window-based method is used to resolve the whole image into a large number of subimage patches in PTAD. To detect an object at any scale and position, two methods are proposed to generate sliding windows with all possible scales and shifts. One is to construct an image pyramid by down-sampling or up-sampling the original image. Then sliding windows are generated in each level of the pyramid with fixed scale. The other is to generate sliding windows with all possible scales and shifts in the original image, where the image pyramid is not required. Every sliding window inherits a scaling factor should be considered. This method is mainly applied in object detection with scale-invariant features. 1
Variance Filter can help to eliminate redundant sliding windows with less time consumption. The variance of any sliding window p in an image I can be represented as
The screened sliding windows should be classified again to determine whether they contain objects or not. Several popular detectors will be introduced into PTAD for dealing with the remaining sliding windows. The performance of each detector mainly depends on two key factors: visual features and trained classifiers. The combination of different classifiers and visual features can be used to construct multiple types of detectors. We will give a detailed introduction about these classifiers in next subsection.
Haar-like feature is calculated only using color information, which is very simple. 41 The adjacent sub-windows at random locations and scales within a sliding window are generated, and the difference between the sum of pixels of sub-windows is calculated as the Haar-like feature. Due to the use of integral images, the calculation speed of a Haar-like feature at any size is fast in constant time. It is a preferable selection for real-time tracking and detection systems. For Haar-like features, multiscale object detection can be realized using all possible scales and shifts of an initial bounding box in the original image without constructing a multiscale pyramid of images.
Compressive feature proposed by Zhang et al. 42 has been applied in object tracking successfully. Here we use the compressive feature for object detection. The compressive feature is similar with the Haar-like feature. Actually, it can be regarded as the sparse Haar-like features, which are generated by compressively sensing in a large set of Haar-like features with a sparse measurement matrix. The compressive features preserve almost all the information of the original image. During object detection, the sparse measurement matrix can be computed only once off-line. The integral image can also be applied. Thus the computational speed of the compressive feature realizes a distinctive rise.
HOG is a feature descriptor which is used to represent the gradient orientation and intensity of an image. 43 The basic idea behind HOG is that the object’s local appearance and shape within an image can be well described by the distribution of local intensity gradients or the oriented intensity of the edge. To construct HOG descriptors, the sliding windows are firstly divided into small spatial connected regions (cells). For each cell, HOG directions or edge orientations are calculated using all pixels within the cell. These cells are merged together into some larger connected regions (blocks). The local histograms can be contrast-normalized by accumulating a measure of local histograms of all cells within the block. Finally, these normalized histograms are combined as the descriptor.
Pixel comparisons are very simple visual features for object tracking. The pixel comparisons are randomly determined only once off-line and stay fixed online. For better robustness to shift and image noise, the image patch is firstly smoothed. The predefined pixel comparisons are performed in the smoothed image patch. The results can be concatenated into a binary feature. The pixel comparisons are very similar with BRIEF, ORB, and BRISK features. In object detection, pixel comparisons are predesigned, which are permutated and split into some large set of comparisons. Every set can be linked together into a feature.
After passing through above classifiers, some negative samples may be misclassified as positive. The further processing based on the online model and the nearest neighbor can help to reduce the error rate of the detector.
NN classifier based on the online model can be used to classify the sliding window.
1
The online model is a collection of positive and negative samples, which represents the object and its surrounding. These samples in the online model are some normalized image patches cropped from previous images. Image patches cropped from the remaining sliding windows are firstly normalized into the same size with the samples in the online model. Then the NCC is used to measure the similarities between the samples in the online model and these image patches. For each image patch, the positive nearest neighbor for the first
Learning modules
Learning modules are used to initialize the detectors in the first frame and update the classifiers online. The output results of the tracker and the detector are integrated by the learning modules to generate the training samples and to update the classifiers. The spatiotemporal properties of a video can help to generate more accurate training samples. The image patches cropped from the sliding windows in an image represent unlabeled samples, containing the spatial structure. The tracker can generate a tracking trajectory which has the temporal structure. In general, the image patches which are close to the tracked trajectory are positive samples (temporal constraints), and the patches in surrounding of a trajectory are negative samples (spatial constraints), where the P-N learning strategy can exploit the spatiotemporal structure information of the data to train more robust and discriminative detectors. The P-constraints (P-experts) and the N-constraints (N-experts) represent the temporal constraints and the spatial constraints, respectively. The number of negative samples is much larger than positive samples. To equalize the ratio of positive and negative samples, all positive samples are added to the training set without any restriction, while only partial negative samples, which is difficult to be distinguished from the tracked object (i.e. image patches cropped from the same class of the tracked object), are added to the training set. Here we introduce several popular learning methods to train binary classifiers that can combine with the features introduced in the last subsection to construct different detectors.
Boosting learning as a general learning framework is widely applied in detection, recognition, and tracking tasks, obtaining impressive performance and efficiently improving the accuracy of the given learning algorithm.
23
Here we briefly introduce the boosting approach that converts weak classifiers to a strong classifier by selecting discriminative features. A weak classifier only needs to label samples better than random speculation. Each weak classifier, corresponding to a feature and being trained by a given learning algorithm, generates a hypothesis
Multiple instance learning (MIL) is a discriminative learning paradigm which can handle problems with incomplete comprehension on labels of the training samples. Most of them require a training data set
Random Forests (Ferns) (RFs) is a strong classifier which is constructed using an ensemble randomized decision trees (weak classifiers).
44
These trees are constructed and tested independently from each other, and their training and testing procedures can be performed in parallel. Each internal node of a tree defines a test which can split the input data into the left child tree or the right one. The input data finally reaches a leaf node of a tree. The leaf nodes of each tree contain the posterior distribution of class labels estimated based on the training set. In a forest, a tree i can be represented as
Experiments
The proposed PTAD framework can be used to realize fast and robust long-term object tracking by integrating different tracking and detection algorithms. We integrate several well-known tracking and detection algorithms into the PTAD framework, in order to validate its effectiveness. Tracking experiments are performed on the TLD data set. 1 The KCF tracker 40 and the MF tracker 1 are selected as the trackers. The cascade classifiers are designed for object detection, where the variance filter and the NN classifier are the first node classifier and the last node classifier respectively. We design several middle node classifiers including MIL + HOG (MIL-HOG), Random Ferns + Pixel comparisons (RFs-PCs), Boosting + Haar-like feature (Boosting-HL), and MIL + Compressive feature (MIL-CT). As a result, eight different object tracking algorithms are constructed by combining four different detectors and two trackers. We tested all the tracking algorithms on the TLD data set, and all the experiments were performed on a PC with 2.4 GHz i7-4700MQ CPU and 8 GB RAM.
Experimental setup
The TLD data set contains 10 image sequences: David, Jumping, Pedestrian1, Pedestrian2, Pedestrian3, Car, Motocross, Volkswagen, Carchase, and Panda, which confront most of the challenges in object tracking (e.g. camera moving, partial or full occlusion, pose change, illumination change, scale change, and similar objects). Some of the sequences are long enough to be appropriate to test our algorithms, which have been manually annotated. Readers can refer to Kalal et al. 1 for the detailed introduction of the property of each sequence.
PTAD is implemented in C++. In the experiments, the tracked object is manually chosen in the first frame to initialize the tracker and the detector. PTAD then tracks the defined object up to the end and record the tracked trajectory. The performance of different tracking algorithms is evaluated based on the recorded trajectories and the annotated ground truth using the predefined performance criterions including precision P, recall rate R, and F-measure F.
1
A tracking result is considered to be a true positive if the overlap between the estimated bounding box and the ground truth is larger than 25%. P is defined as that the number of true positives divided by the total number of responses that contain both true positives and false positives. R is represented as the number of true positives divided by the number of frames that contain the tracked object. F is defined as
In the experiments, all parameters of the tracking modules are fixed. The parameters of the KCF tracker and the MF tracker are the same as those in Kalal et al. 1 and Henriques et al. 40 In the work of Kalal et al., 1 the tracking failure detection has been designed, which is directly used in our experiments. For the KCF tracker, the NCC method is employed to judge whether the tracker fails or not. The threshold for the NCC tracking failure detection method is set to be 0.65.
The detection modules consist of a set of the cascade classifiers. In the beginning, we make use of the two aforementioned approaches to build a number of sliding windows. For the HOG feature, an image pyramid with six levels is built by successively down-sampling and up-sampling the original image using scales step as 1.2. Then the sliding windows are generated with shifts in all pyramid images: horizontal step = 10% of the initial width, vertical step = 10% of the initial height. For the Haar-like feature, the pixel comparisons and the compressive feature, the sliding windows are generated with different scales and shifts in the original image using the same construction method and parameters in TLD. 1 The number of scales is also set to be 6. For the variance filter, the variance threshold is set to be 50% variance of the image patch cropped from the initial bounding box in the first frame. The NN classifier for online model uses the same parameters as those in TLD.
We exploit four different classifiers as the middle node classifiers to test our framework. In our experiments, few parameters for Boosting, MIL, Random Ferns learning modules needs to be set in particular. The initial parameters of the Boosting and MIL trackers in OpenCV are used as the parameters of Boosting and MIL learning algorithms. The parameters of Random Ferns are the same as those in Kalal et al.
1
A fast HOG feature extraction method proposed in Felzenszwalb et al.
43
is used in the classifiers of HOG + MIL. The Haar-like feature is extracted using OpenCV, and the feature dimension is set to be 650. The dimension of the compressive feature proposed in Zhang et al.
42
is set to be 100. For Random Ferns + Pixel comparisons, 10 ferns locate in random ferns, and each one consists of 13 pixel comparisons with
Experimental results and analysis
In the beginning, we test the performance of the selected trackers (KCF, KCF with tracking failure detection based on the NCC method and MF) on the TLD data set. The trackers are designed for short-term object tracking without any method to recover and reinitialize from a failure. In the experiments, the tracker would be terminated if it lost the object during the tracking period, and the remaining images would not be processed. Table 1 shows their performance evaluated by the criterions of Precision/Recall/F-measure, and bold numbers indicate the best scores between the KCF tracker with tracking failure detection and the MF tracker. The last row represents the weighted average performance for all the image sequences (weighted by the number of frames in the sequence). The original KCF tracker can achieve a higher recall rate but a lower precision than that of the KCF tracker with tracking failure detection. The tracking failure detection based on the NCC method can help to improve the precision performance for the KCF tracker, and the performance of the tracker is close to the MF tracker. Neither of the two trackers achieves the best performance for all the image sequences. Some of the proposed trackers could only adapt to some specific scenarios and failed achieving the best performance in practical situations. So it is significant to provide an open interface to integrate different trackers into PTAD for long-term object tracking. Next, we will integrate the two trackers with several detectors into PTAD and validate the effectiveness of our framework using the TLD data set.
Performance evaluation of the selected trackers (KCF, KCF with tracking failure detection, and MF) measured by Precision/Recall/F-measure.a

KCF: kernelized correlation filter; MF: median flow; PTAD: parallel tracking and detection.
a The KCF tracker with tracking failure detection and the MF tracker will be integrated into PTAD, and bold numbers indicate the best scores.
For PTAD, the assumption that the appearance of the object varies slowly among several frames is important for long-term object tracking. Thus the tracker would not often lose the object in a short period. And the detector does not need to reinitialize and recover the tracker and update the classifiers in each frame of an image sequence. Thus we propose the PTAD framework in which the tracker and the detector can be processed independently and separately respectively. However, the appearance of the object and the scene may change relatively quickly in some practical applications. What’s more, there are a few TFs in each segment being unprocessed by the detector. It is necessary to make several experiments to evaluate the impact of the assumption and the number of the TFs (
In the experiments, Motocross, Volkswagen, and Carchase are selected as the tracking datasets. The three sequences in the TLD dataset are long enough and contain all the typical challenges for long-term tracking. The tracked object in Motocross moves very fast, and its appearance changes relatively quickly. The appearance of the tracked object in Volkswagen changes slowly and gradually. In Carchase, the appearance of the object changes more quickly than that of the object in Volkswagen and more slowly than that of the object in Motocross. We select the KCF tracker as the tracker of PTAD, and the detector consists of three cascaded classifiers: the patch variance filter, RFs-PCs and the NN classifier. In order to better explain the experimental results, the number of the TFs (
The performance of the tracking algorithms, which is evaluated by Precision/Recall/F-measure, is shown in Table 2. Comparing with Table 1, we can find that all the performance using PTAD is better for the three image sequences. The combination of the detection and the tracking can improve the performance of long-term object tracking. Table 2 shows the recall rate of the tracking algorithm declines with the increasing of the number of the TFs in each segment. The recall rate has the fastest and the slowest declining for Motocross and Volkswagen respectively. The more the image sequence satisfies the assumption, the slower decline with the increasing of the number of the TFs the recall rate will have. From Table 2, it can also be found that the precision of the tracker remains relatively stable when the number of the TFs is relatively smaller. When the assumption is well met, the tracking algorithm based on PTAD can obtain the approximate performance as that achieved by combining tracking with detection sequentially like the TLD algorithm. Moreover, in order to achieve good tracking performance, we should improve the detector’s effectiveness and reduce the number of the TFs in practical applications.
Performance evaluation of the tracking algorithm based on PTAD measured by Precision/Recall/F-measure.a

PTAD: parallel tracking and detection; TF: tracking frame.
a
In the final experiments, different tracking and detection algorithms are integrated and compared in our proposed framework. Here we combine two tracking algorithms (KCF and MF) and four detection algorithms (RFs-PCs, Boosting-HL, MIL-CT, and MIL-HOG) to form eight trackers. The tracking and detection are performed in parallel, running at different speeds. By adjusting the running speed of the tracker and the detector, the number of the TFs may be changed, which would affect the performance of the tracking algorithms. In the experiments, confirming the appropriate number of the TFs seems to be trivial and complex task in order to guarantee the eight trackers to achieve the best performance. We only set the frame rates of the trackers to be about 30 FPS, and the detectors are performed as fast as possible. Therefore, the number of the TFs in each segment is elastic. In practical applications, users can adjust the frame rates of the tracker and the detector to meet their requirements. Furthermore, users can exploit the thread synchronization mechanism to perform the tracking and detection tasks sequentially like the TLD framework. In the repeated experiments with the same experimental setup, the computational resources of the tracker and the detector may be different. At the same time, the tracking and detection algorithms are performed in parallel. The keyframes and the number of the TFs in each segment are also different in the repeated experiments, thus the experimental results are also not exactly the same. In order to perform a fair comparison with other tracking algorithms, each experiment is repeated five times and the final experimental results come from the average of the five results.
The experimental results are shown in Table 3, and bold numbers indicate the best scores. The last row represents weighted average results for all the image sequences. Obviously, the performance of the eight trackers in Table 3 is better than that of the three trackers in Table 1. Meanwhile, the trackers in Table 3 also achieve better performance compared with OnlineBoost, SemiBoost, BeyondSemiBoost, MIL, and coGD in Table 4 which comes from Kalal et al. 1 The TLD tracker achieves the best performance in Table 4. This shows that the combination of the tracking and the detection can help to improve the performance for object tracking, especially for long-term object tracking. Furthermore, comparing Table 3 with Table 4, we observe that the trackers based on PTAD can achieve similar performance as the TLD tracker, such as KCF + RFs-PCs, MF + RFs-PCs, KCF + Boosting-HL, KCF + MIL-CT, and KCF + MIL-HOG. Especially for KCF + RFs-PCs, its performance is slightly better than that of TLD. In object tracking, the assumption conditions are usually satisfied. Thus the tracker and the detector can be performed in parallel, and the tracking algorithms based on PTAD can achieve comparable performance as TLD where the tracking, detection and learning are run sequentially.
Performance evaluation of the tracking algorithms based on PTAD measured by Precision/Recall/F-measure.a

RFs-PCs: Random Ferns + Pixel comparisons; Boosting-HL: Boosting + Haar-like feature; MIL-CT: Multiple instance learning + Compressive feature; KCF: kernelized correlation filter; MF: median flow; PTAD: parallel tracking and detection; MIL-HOG: Multiple instance learning + histogram of oriented gradient.
a Bold numbers indicate the best scores.
Performance evaluation of several trackers on TLD data set evaluated by Precision/Recall/F-measure.a
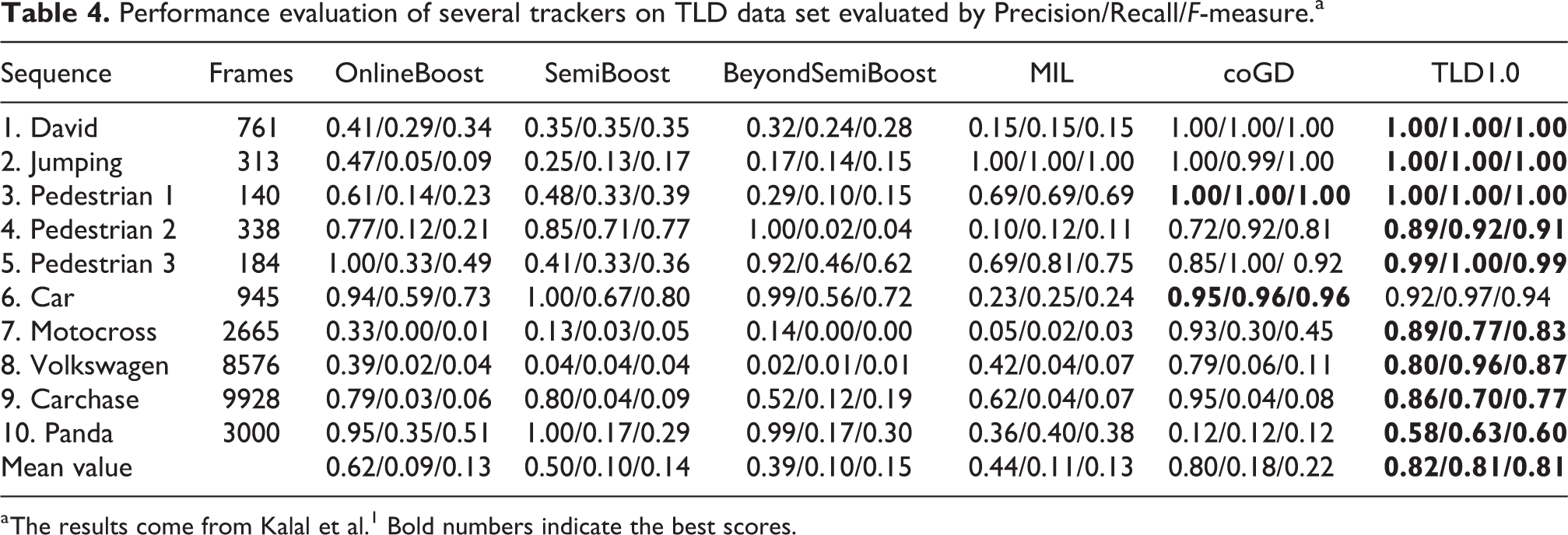
a The results come from Kalal et al. 1 Bold numbers indicate the best scores.
Comparing with TLD, PTAD has its unique advantages: providing an open interface to integrate different object tracking and detection algorithms and ensuring the real-time performance. On the one hand, PTAD provides an open interface. As is known to us, none of the trackers and the detectors can achieve the best performance for all the image sequences. From Table 3, the MF + RFs-PCs tracker achieves good performance for David, Jumping, Pedestrian2 and Motocross, and the KCF + RFs-PCs tracker achieves good performance for other image sequences. Therefore, it is significant to provide an open interface to integrate different object tracking and detection algorithms to deal with different tracking scenarios. Users can integrate more trackers and detectors into our framework according to their practical requirements. The source code of PTAD framework can be downloaded from: https://github.com/nubot-nudt/ptad.
On the other hand, real-time performance can be obtained. The four detection components are run at different speeds. When the same detector combines with the KCF tracker or the MF tracker, the number of keyframes processed by the detector is approximate. The numbers of the keyframes (
The number of the keyframes, the average number of the TFs in each segment (
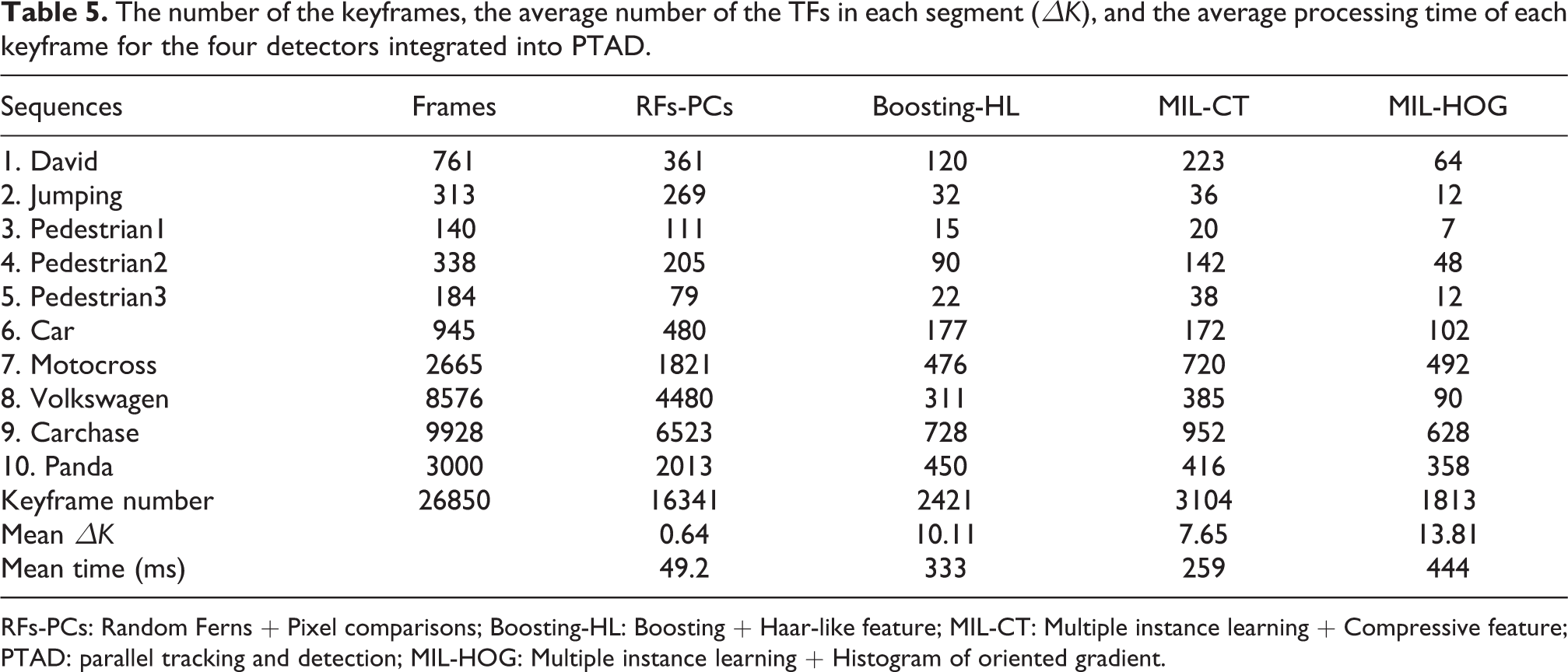
RFs-PCs: Random Ferns + Pixel comparisons; Boosting-HL: Boosting + Haar-like feature; MIL-CT: Multiple instance learning + Compressive feature; PTAD: parallel tracking and detection; MIL-HOG: Multiple instance learning + Histogram of oriented gradient.
Choosing appropriate trackers and detectors
Trackers may be just for some specific scenarios. It’s almost impossible for a tracker to achieve the best performance for all image sequences. However, in order to deal with unknown tracking objects, we should select real-time, accurate, and robust trackers which can adapt to different objects and more tracking scenarios. Similarly, we should also choose more robust and accurate detectors. In addition, the real-time performance of object detectors should be considered according to the appearance variations of the tracking object. When the object appearance changes fast, the assumption that the appearance of the object varies slowly among several frames is not met. In this situation, we should select the detector with better real-time performance. On the contrary, we can choose some slower detectors. According to the above principles, we can choose some appropriate trackers and detectors from state-of-the-art object tracking and detection algorithms for the PTAD framework.
What is more, we can train deep learning detectors for known objects off-line, and these models do not need to be updated online. Thus, the PTAD usually contains two modules: tracking and detection. We make use of a pretrained deep learning Single Shot Detector (SSD) model 45 to detect the tracked object. About the real-time performance, it takes about 77 ms to process a frame of perspective image with GeForce GTX960M GPU. We perform the tracking experiment on the UAV123 data set. 46 The tracked object is a car. In the Table 6, it can be seen that the detector trained off-line can be used to track the known object.
Performance evaluation of several trackers on UAV123 data set evaluated by Precision/Recall/F-measure.a

SSD: Single Shot Detector; KCF: kernelized correlation filter; RFs-PCs: Random Ferns + Pixel comparisons.
a Bold numbers indicate the best scores.
Ground moving object tracking
In recent years, vision-based ground moving object tracking has become a very active field of research for macro aerial vehicles (MAVs). We employ the PTAD tracker (KCF + RFs-PCs) to estimate the location of the ground moving object between the consecutive frames. As shown in Figure 4, the DJI Matrice 100 is selected as the experimental platform. All experiments are performed on an Intel’s NUC computers with 3.1 GHz i7-5557U CPU and 8 GB RAM. A downward looking USB camera is mounted on the bottom of the MAV.

The MAV platform. MAV: macro aerial vehicle.
We perform object tracking experiments in a basketball court and a garden. The tracking results are demonstrated in Figure 5. It can be clearly seen that the PTAD tracker is robust to illumination variations, scale changes, out-of-view, and cluttered environments. The tracked object almost goes out of view of the camera in the penultimate frame. When the object appears again in the last frame, the detection module can detect the object and recover the failed tracker. In practical applications, the processing speed of the PTAD tracker can be higher than 30 FPS, so real-time requirements can be met.

Ground moving object tracking results using the PTAD tracker. PTAD: parallel tracking and detection.
Conclusions
In this article, we propose a framework of PTAD for unknown object tracking, especially for long-term unknown object tracking. The proposed framework has several advantages. Firstly, PTAD can combine tracking and detection and make up their own deficiencies. A tracker can provide weakly labeled training samples for a detector, and a detector can recover a tracker when drifts are large or the tracker fails. Secondly, the tracking and detection are run in parallel like PTAM. The tracker requires little computing resources and is performed as the front end. The detector is run as the back end. Thus our framework can achieve real-time performance in practical applications. Finally, PTAD provides an open interface to integrate and compare various tracking and detection algorithms. The source code of PTAD framework can be downloaded from: https://github.com/nubot-nudt/ptad. In this article, two trackers and four detectors are integrated into PTAD, and their performance is evaluated on the TLD data set. The experimental results demonstrate that our framework is effective for long-term real-time object tracking. Our future work will focus on two aspects. Firstly, we will extend our framework to GPU and improve the real-time performance of the detection component. Secondly, we will develop more robust trackers and detectors for PTAD.
Footnotes
Acknowledgement
The authors would like to thank the anonymous reviewers, whose insightful comments can greatly improve the quality of this article.
Declaration of conflicting interests
The author(s) declared no potential conflict of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Natural Science Foundation of China (grant nos U1813205 and 61773393).