
Abstract
The goal of reinforcement learning is to enable an agent to learn by using rewards. However, some robotic tasks naturally specify with sparse rewards, and manually shaping reward functions is a difficult project. In this article, we propose a general and model-free approach for reinforcement learning to learn robotic tasks with sparse rewards. First, a variant of Hindsight Experience Replay, Curious and Aggressive Hindsight Experience Replay, is proposed to improve the sample efficiency of reinforcement learning methods and avoid the need for complicated reward engineering. Second, based on Twin Delayed Deep Deterministic policy gradient algorithm, demonstrations are leveraged to overcome the exploration problem and speed up the policy training process. Finally, the action loss is added into the loss function in order to minimize the vibration of output action while maximizing the value of the action. The experiments on simulated robotic tasks are performed with different hyperparameters to verify the effectiveness of our method. Results show that our method can effectively solve the sparse reward problem and obtain a high learning speed.
Introduction
Reinforcement learning (RL) 1 has shown impressive results in numerous simulated tasks ranging from attaining superhuman performance in video games 2,3 and board games 4 to learning complex motion behaviors. 5,6 However, sparse reward has always been a challenging problem for RL on robotic tasks. In robot learning, a sparse reward problem naturally arises when the robot is hoped to be able to achieve some binary goals such as moving an object to a desired location. The form of sparse reward is often easy to be specified, but in many situations it does not guide the robot to effectively explore and obtains the learned policy to realize the desired goal instead of getting stuck in local optima. 7,8
A common way to deal with sparse rewards in RL is to combine an off-policy RL algorithm with Hindsight Experience Replay (HER). 7 The HER method randomly replaces the original goal with the achieved goal with a certain probability, so that the agent can learn not only from the successful experiences but also from part of the failed experiences. HER greatly accelerates the exploration of agents without reward signals. However, in multi-goal tasks, due to the diversity of the goals and the randomness of the RL algorithm, HER might take a very long time to discover how to reach specific areas in the state space. An improved HER method 9 combining curiosity with priority mechanism is proposed to improve both the performance and sample efficiency of HER. But this method inherently believes that both the real and hindsight experiences have the same effects and arbitrarily puts more focus on the underrepresented achieved states. Another improvement of HER is ARCHER, 10 which compensates for the bias in HER by giving more rewards to hindsight experiences, but this method may bring harm to the final performance of the algorithm for some complex tasks.
Imitation learning (IL) 11 –13 is a well-studied field in robotics. Such methods do not require a reward function, which can significantly speed up the learning of the robot. A wide variety of IL methods have been proposed in the last few decades. The simplest IL method among those is behavior cloning (BC), 14,15 which learns an expert policy in a supervised fashion without environment interaction during training. BC can be the first IL option when a large amount of high-quality demonstrations are available. However, when only a small amount of demonstrations are available or the quality of demonstrations is low, this method fails to imitate expert behavior due to the compound error. 16 Since it is often difficult to provide sufficient high-quality demonstrations in the real-world environment, the application of BC is limited seriously.
Inverse reinforcement learning (IRL) 17 –19 is another widely used IL method, which can overcome the problem of compound error. The goal of IRL is to extract a reward function from those demonstrations and then train a policy to maximize the cumulative reward. 20 –22 Apprenticeship learning 20 uses the maximum marginal method to solve the reward function, which is to find a hyperplane for dividing the demonstration policy and ordinary policy into two categories and maximize the marginal between them. Subsequently, to solve the problem of artificial base in IRL, neural network is used to replace artificial base in order to improve the expression ability of the reward function. 23 However, since the IRL algorithm needs to solve a RL problem in the inner loop, its huge computational complexity makes it difficult to be applied to complex tasks with high-dimensional spaces.
In recent years, an emerging IL method based on IRL has emerged, namely generative adversarial imitation learning (GAIL). 24 This method combines RL with generative adversarial networks. 25 The generator network uses RL to generate the action policy, and the discriminator network is used to discriminate the generated policy and the expert policy, and finally the generated policy converges to expert policy. Since GAIL has achieved the state-of-the-art performance on a variety of continuous control tasks, the adversarial IL framework has become a popular choice for IL. 26 –30 GAIL has achieved amazing results on complex tasks, but it has serious instability during training, which needs a long training time and strong training skills.
In addition, other methods 8,31 combining RL with IL use demonstrations to accelerate the exploration of agents in the environment with sparse rewards, but they are too dependent on the quality of demonstrations, and the final performance is not satisfactory.
In order to address the challenges mentioned above, we put forward a novel RL algorithm based on Twin Delayed Deep Deterministic policy gradient algorithm (TD3). 32 The method use a new experience replay mechanism called Curious and Aggressive Hindsight Experience Replay (CAHER) to improve the sample efficiency and solve the sparse reward problem. Moreover, we leverage the demonstrations to accelerate learning and design an action loss to make the robot action as smooth as possible. We conducted several different experiments in robotic environment to evaluate the proposed algorithm.
The remainder of this article is organized as follows. Some preliminary knowledge is described. In the “Method” section, we introduce the proposed approach in three parts in detail. The experiment evaluation is conducted in the next section. Finally, the last section concludes the article.
Background
Markov decision process and RL
Considering an agent interacting with an environment and assuming that the environment is fully observable, a Markov decision process is defined as a tuple
At the beginning of each episode, an initial state s
0 is sampled from the distribution
So far, many RL algorithms are proposed to solve this problem, most of which involve estimating the action value after taking action at

Equation (1) is the Bellman equation, where
Twin Delayed Deep Deterministic policy gradient
Deep deterministic policy gradient (DDPG) includes an actor network
For the critic part, its purpose is to evaluate the value of the action taken in the current state, thereby to guide the actor network to select the optimal action. The loss function of critic network is as follows
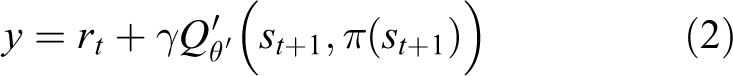

The main purpose of the actor part is to learn a policy to maximize accumulated rewards. For the purpose of enhancing exploration, the action
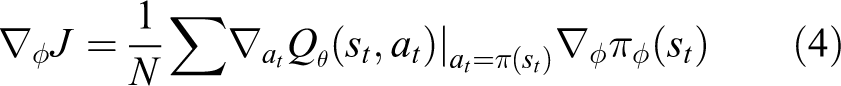
However, as described in Q-learning,
33
due to the Q function estimation error Two Q functions are learned and the smaller is used when updating the parameters of the critic networks to avoid overestimation of the action values To reduce the errors in multiple updates, the actor network should be updated at a lower frequency than the critic network. The modification is to update the policy and target networks after a fixed number of updates to the critic networks. TD3 emphasizes on the notion that similar actions should have similar values. The target policy smoothing, which adds a small amount of random noise to the target policy, is used to reduce the error in the value function estimation process



Hindsight Experience Replay
HER is an experience replay method which can be used to overcome the learning difficulties caused by the use of sparse rewards and avoid complex reward projects. Different from the traditional RL methods, HER is proposed with a new parameter goal which consists of desired goal and achieved goal. The desired goal represents the task that the agent should accomplish. The achieved goal represents the task that the agent has completed at the current time. The key idea of HER is as follows: at some moment, although the agent has not achieved the desired goal, it has completed achieved goal. At this time, the desired goal can be replaced by the achieved goal so that the method can transform failed experiences into successful experiences and learn from them. In HER, even though the desired goal is not completed at present, if the learning process is repeated, the agent will complete the desired goal in the final so as to complete the task with the sparse rewards.
Gaussian mixture model
The Gaussian mixture model (GMM)
37,38
is a probability model that assumes that all data are derived from K Gaussian distributions with unknown parameters, mathematically:
Method
In this section, we describe the proposed method in detail and give its complete algorithm flow in Algorithm 1.
TD3 from demonstrations based on CAHER.

Curious and Aggressive Hindsight Experience Replay
Motivation
The inspiration of combining curiosity with RL comes from two aspects. First, neurology 40 has shown that curiosity can enhance the ability of learning. For example, when people learn to play basketball, they practice repeatedly in a trial-and-error fashion. In memory, people are more interested in those different episodes and focus more on these episodes. This curiosity mechanism has been proven to speed up learning. Second, the inspiration of adding a curiosity mechanism to RL agents comes from supervised learning. In the face of complex imbalanced datasets, standard supervised learning algorithms, such as neural networks, fail to learn useful information from the datasets. An effective solution is to oversample the samples in the underrepresented class. Zhao and Tresp 9 propose a Curiosity-Driven Prioritization (CDP) framework to focus more attention on the underrepresented trajectories. Our method is studied on the basis of the CDP framework.
Curiosity ranking
At the beginning of each episode, the agent uses a policy to explore the environment and store the trajectory in the replay buffer. A complete trajectory
After the trajectories are collected, we can use these trajectories to fit the density model. The model fits on the data in the replay buffer every epoch and refreshes the density for each trajectory. When a trajectory is stored in the replay buffer, the density model predicts its density

where
Then the trajectory is normalized as follows

where N is the number of trajectories in the replay buffer.
After normalizing the trajectory density, the density value along with the trajectory is stored in the replay buffer for later prioritization.
During training, the agent puts more focus on the underrepresented achieved states. So we adopt the complementary trajectory density

Furthermore, all the trajectories are ranked according to their complementary trajectory density values and the ranked numbers are used as the probability for sampling, which means that the underrepresented trajectories with low density are easier to be replayed. In this way, for off-policy RL, the agent puts more focus on the rare achieved states in the replay buffer and improves its sample efficiency.
Finally, when the transitions of those trajectories are sampled, the HER method is used to update the off-policy RL algorithm.
Aggressive rewards
Although curiosity enhances the exploration ability of the algorithm, it inherently believes that both the real and hindsight experiences have the same values. The cause of bias in HER analyzed in ARCHER
10
is that both experiences cannot be rewarded in the same way. In our method, we incorporate the idea of aggressive rewards into curiosity to eliminate the bias and increase the sample efficiency of the RL methods. Specifically, in traditional HER methods, the hindsight experience has the form of
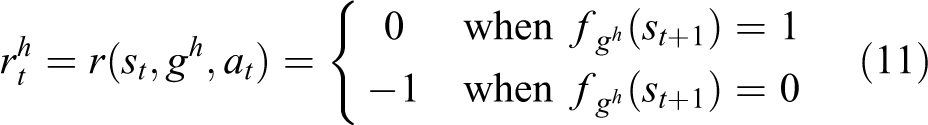
where
But in our method,
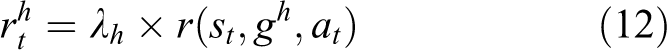
where the parameter
TD3 from demonstrations
In traditional TD3, the actor network and the critic network are updated by sampling a mini-batch experiences from the replay buffer. In our method, the trajectories are stored in the replay buffer as
To update the critic network, two one-step off-policy evaluations are used and the smaller is used to avoid the overestimation of action values

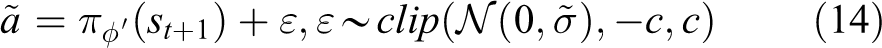
and the critic loss is in the following form

To update the policy, the policy gradient is used as follows
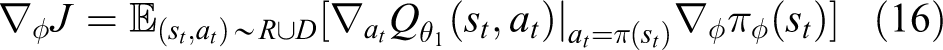
Action loss
In TD3, the main purpose of the actor network is to maximize the value of the output action. However, simply maximizing the action value function will result in dehumanized and excessively stereotyped behaviors. Therefore, the action loss in our method which is the square of the actor network output is added into the loss function of the actor network in order to optimize the output actions when updating the gradients. The loss function of the actor network is as follows
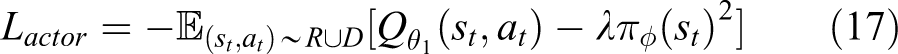
and the gradient step is taken with respect to

During training, the actor network maximizes the output of the critic network by minimizing the loss function, that is, maximizing the value of the output action. At the same time, since the action loss is added into the loss function, the vibration of the output action is restrained, that is, the smoothness of the output action is maintained.
Experimental evaluation
In this section, we first describe the experimental environment and the tasks to be completed by the agent in detail. Then, the network architecture and training details are explained. Finally, the push and pick-and-place tasks are conducted in the robotic environment to answer the following three questions: Does our method have advantages over other ones in terms of performance and learning speed? For our method, what effect does different settings of demonstrations have on the experimental results? What is the effect of the action loss?
Experimental environment
The environment we used is the robotic simulations provided by OpenAI Gym, 44,45 using the MuJoCo physics engine. 46 The 7-DOF Fetch robotic arm in the environment has a two-fingered parallel gripper, and there are several manipulation tasks with different goals to be completed. Figure 1 illustrates the push and pick-and-place tasks to be conducted in our experiments.

Experimental tasks: (a) Push: the fixture of manipulator is locked and the manipulator needs to use the locked fixture to push the object to the target position. (b) Pick-and-place: the fixture of manipulator is unlocked, and the manipulator needs to clamp the object and place the object to the target position.
State st
: the state
Goal g: the goal
Achieved goal
Action at
: the action
Reward rt : a sparse reward is used as the reward function, which is shown as follows

This is a binary reward function that shows whether the task has been completed or not. The 5 cm threshold is the default setting in Fetch robotic arm environment and commonly used in the evaluation of the simulated robotic tasks. When the distance between the object and the target is less than the threshold, it is considered that the object is placed on the target position.
Network architecture and training details
The actor and critic networks are designed with three fully connected hidden layers, consisting of 256
In training, each epoch includes 100 episodes and each episode has 50 steps. In particular, in order to make the success rate curves look smoother, the exponential weighted average processing is carried out, as shown as follows

where
The effectiveness of our method
In order to verify that our method can effectively reduce the exploration time and speed up learning, two experiments with the demonstration data of both high and low success rates are conducted to compare our method with other four methods, DDPG with random sampling, DDPG with HER mechanism, DDPG from demonstrations and GAIL, respectively. Here, DDPG with random sampling is the original DDPG method. The number of demonstrations is 2000, the hyperparameter
Demonstrations of high success rate
Figures 2 and 3 show the learning curves of the push and pick-and-place tasks with high success rate demonstrations, respectively. We describe the best performance and the corresponding learning time of these methods in Table 1. The success rate of demonstrations for the push task is 0.996 and the success rate of demonstrations for the pick-and-place task is 0.985. The red, black, blue, purple, and cyan curves correspond to GAIL, DDPG with random sampling, DDPG with HER mechanism, DDPGfD and our method, respectively. The green dashed line represents the success rate of demonstrations. The horizontal and vertical coordinates in the figures are the number of epochs and the success rate of robot completing tasks in each epoch, respectively.

Learning curves of the push task with demonstrations of high success rate.

Learning curves of the pick-and-place task with demonstrations of high success rate.
The best performance and the corresponding learning time with the demonstrations of high success rate.

HER: Hindsight Experience Replay; GAIL: generative adversarial imitation learning.
Due to lack of clear reward signals guiding the learning of the agent, it is evident that the learning effect of DDPG with random sampling is very poor. DDPG with HER has achieved relatively good results in terms of final performance, but the breadth-first nature of HER makes that some states of the space take a very long time to be learned. 47 This problem is especially serious as the difficulty of the task increases. So, we use demonstrations to overcome the above problem of HER and use the CAHER mechanism to encourage the agent to explore effectively. In fact, we have achieved almost the same learning speed as DDPGfD. Furthermore, because our method does not need to learn a reward function like GAIL, it has a faster learning speed than GAIL.
Demonstrations of low success rate
However, we often have difficulties in acquiring high-quality demonstrations, so we need to consider how to make the algorithm work well with the demonstration data of low success rate. In this experiment, the success rate of demonstrations for the push task is 0.587 and the success rate of demonstrations for the pick-and-place task is 0.529. Figures 4 and 5 show the learning curves of the push and pick-and-place tasks with demonstrations of low success rate, respectively. The best performance and the corresponding learning time of these methods are described in Table 2.

Learning curves of the push task with demonstrations of low success rate.

Learning curves of the pick-and-place task with demonstrations of low success rate.
The best performance and the corresponding learning time with the demonstrations of low success rate.

HER: Hindsight Experience Replay; GAIL: generative adversarial imitation learning.
Same as above, the results show that both in the push and pick-and-place tasks, DDPG without the reward signal cannot learn effectively, which further confirms that traditional RL is heavily dependent on the reward function to guide the agent to learn. For example, whether the reward function is good or bad, sparse or not, and so on has a great influence on the RL algorithm. In addition, GAIL learns an optimal policy by performing occupancy measure matching. It can achieve similar results on two tasks due to its strong robustness, but it also has a disadvantage that it cannot outperform the demonstrations. Although DDPG with HER is not affected by the quality of demonstrations, its learning speed of complex tasks is significantly slowing. The DDPGfD method, which has similar performance with our method in the above experiment, has a poor stability and even has a performance degradation in the pick-and-place task due to the lack of high-quality demonstrations. In contrast, our method not only accelerates the learning process by leveraging demonstrations but also overcomes the influence of sparse rewards through CAHER, and therefore has good stability and achieves the best performance compared with other methods.
It can be seen from the above experiments that the proposed method can overcome the sparse reward problem and speed up learning. At the same time, compared with other methods that leverages demonstrations, our method reduces the requirement for high quality demonstrations, which is difficult to obtain in some scenarios.
The influence of demonstrations
In our method, demonstrations are used to speed up learning. In this part, two experiments on the number of demonstrations and the sampling ratio between demonstrations and experiences were conducted to analyze the influence of the chief factors of demonstrations on the learning effects.
The number of demonstrations
The experiment was conducted with different numbers of demonstrations, in which the sampling ratio between demonstrations and experiences is 1:1, and the hyperparameter
Figures 6 and 7 show that the learning results of the push and pick-and-place tasks with the demonstration data of high success rate. When the number of demonstrations is 200, 2000, 20000, three learning curves rise rapidly with almost identical shapes. In contrast, the rising speed of the learning curve slows down obviously when the number is 20.

Learning curves of the push task using different number of demonstrations of high success rate.

Learning curves of the pick-and-place task using different number of demonstrations of high success rate.
Figures 8 and 9 are the learning curves of the push and pick-and-place tasks with demonstrations of low success rate. When the number of demonstrations is 2000, 20000, these two learning curves are almost identical and rise rapidly. In contrast, the rising speed of learning curve slows down obviously when the number is 20. And when the number of demonstrations is 200, the rising speed lies between the 20 and 2000 groups.
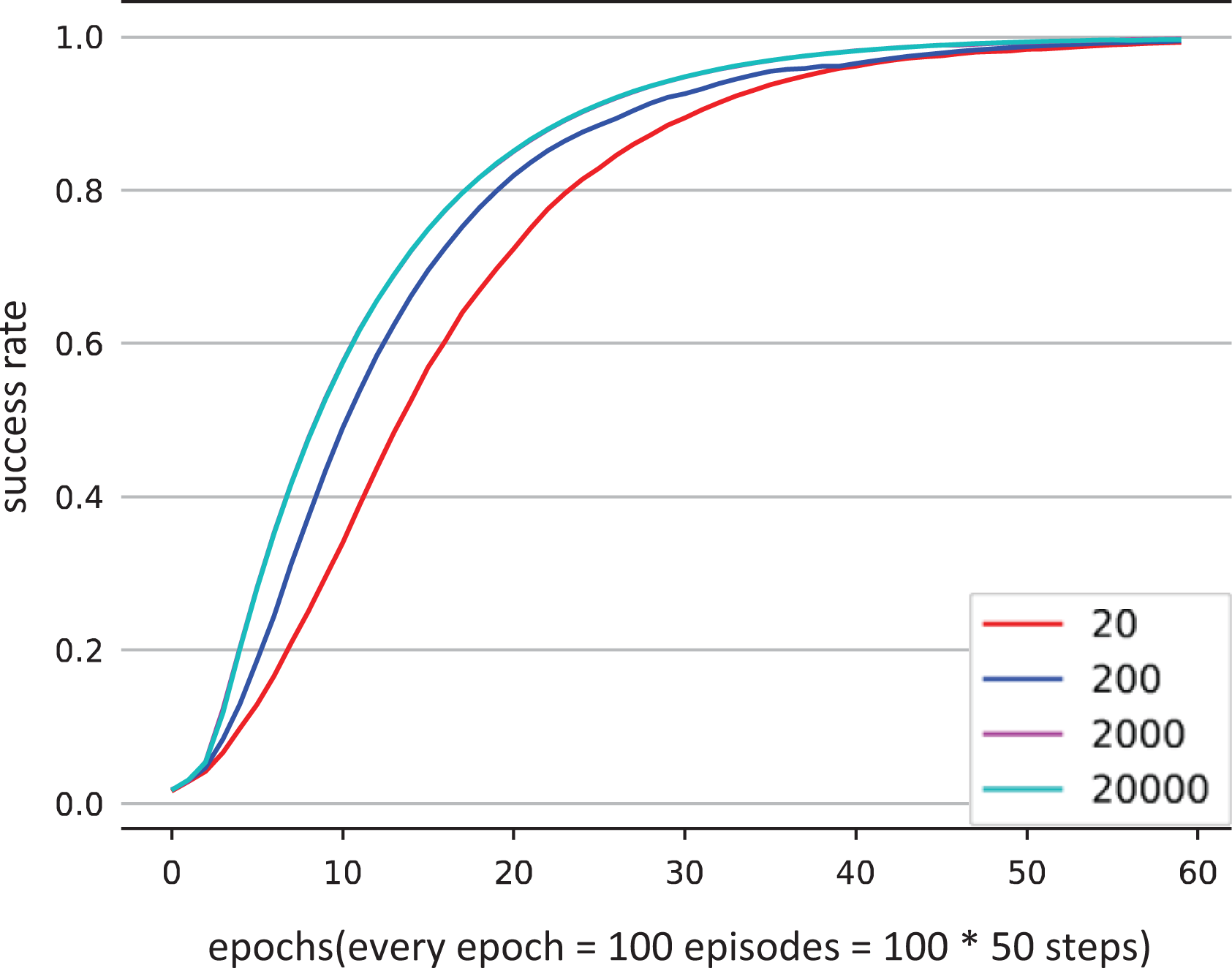
Learning curves of the push task using different number of demonstrations of low success rate.
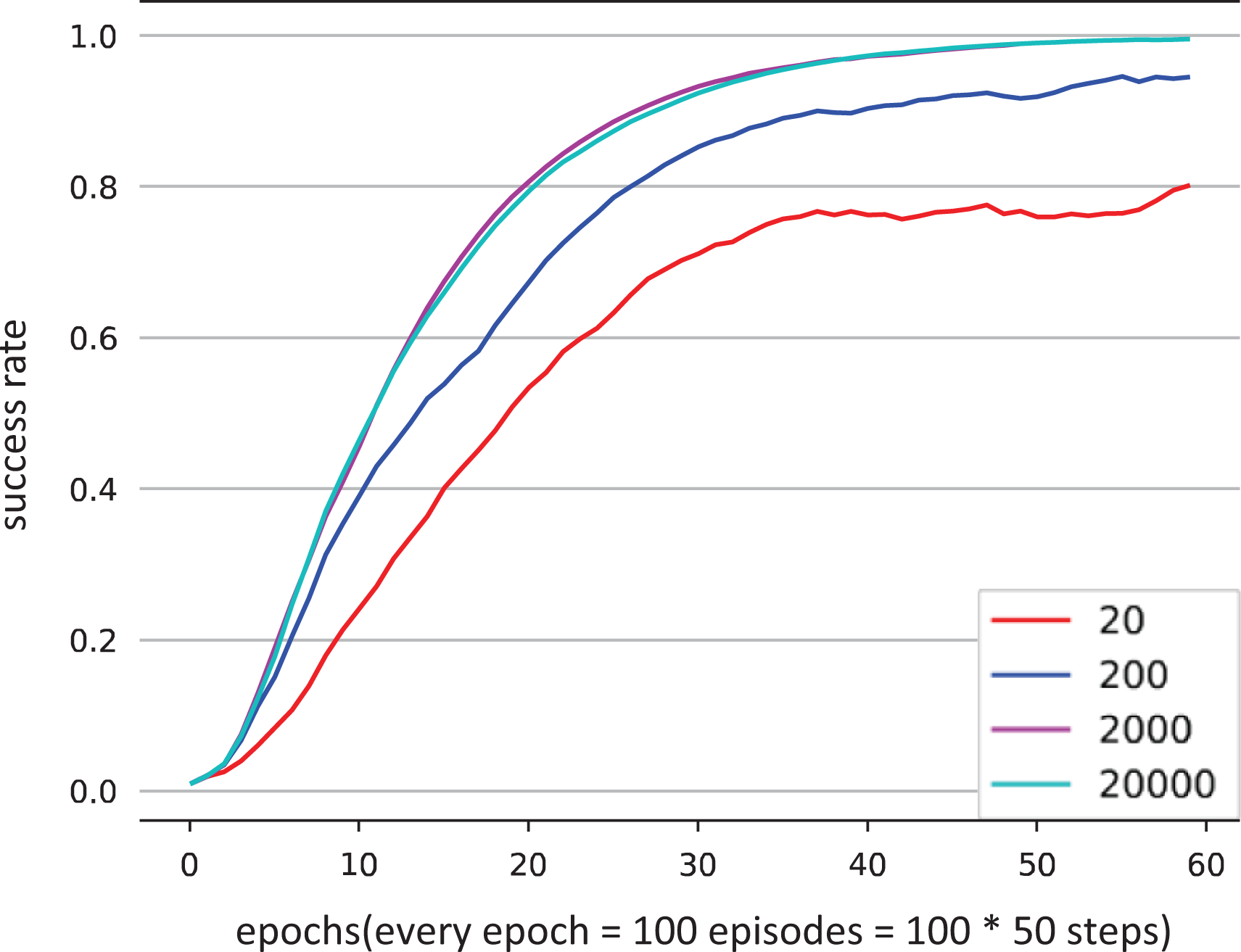
Learning curves of the pick-and-place task using different number of demonstrations of low success rate.
We can get the following conclusions from above: as the number of demonstrations increases, the learning effect of the agent gradually improves, especially when the success rate of demonstrations is low. However, the training time decreases logarithmically. For example, for the results with 2000 and 20000 demonstrations, we can see that even if the number of demonstrations differs by an order of magnitude, the difference in learning effect can be negligible. Therefore, for this kind of robotic tasks, 2000 demonstrations are used in our method.
The sampling ratio between demonstrations and experiences
The experiment was conducted with different sampling ratios between demonstrations and experiences, in which the number of demonstrations is 2000, and the hyperparameter
Figures 10 and 11 show the learning curves of the push and pick-and-place tasks with demonstrations of high success rate. The curves show that when the sampling ratio between demonstrations and experiences is between 3:1 and 1:7, there is almost no difference in the learning curves. Only when the ratio is 7:1, the rising speed of the learning curve decreases slightly, but this difference can be negligible.

Learning curves of the push task using different sampling ratios between demonstrations of high success rate and experiences.
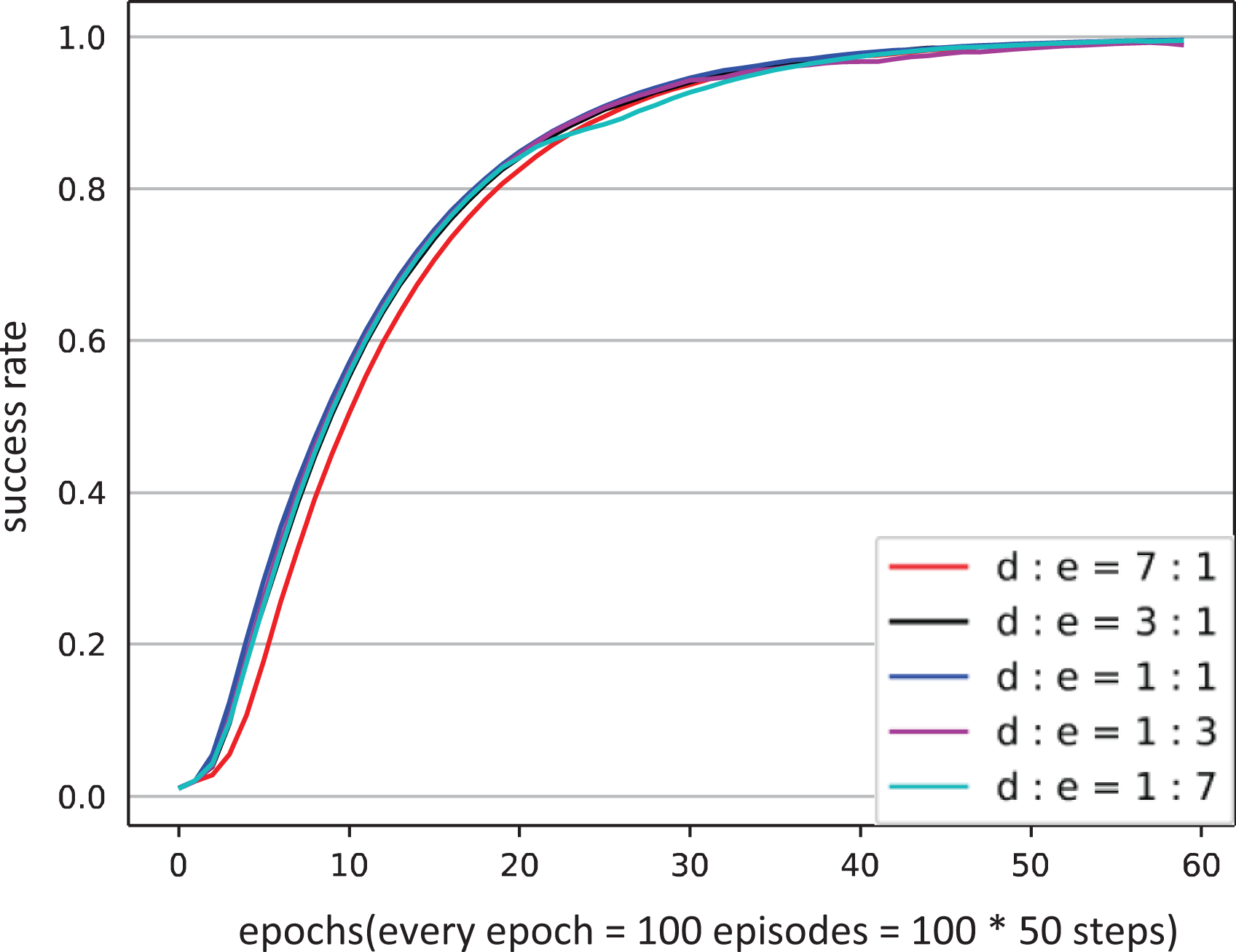
Learning curves of the pick-and-place task using different sampling ratios between demonstrations of high success rate and experiences.
Figures 12 and 13 show the learning results of the push and pick-and-place tasks with low success rate demonstrations. The results show that for the push task, changing the sampling ratio between demonstrations and experiences does not affect the learning process of the agent. For the more difficult task, pick-and-place, when the ratio is 7:1, the learning curve rises at the slowest speed, and there is still a certain gap of success rate compared with the others.

Learning curves of the push task using different sampling ratios between demonstrations of low success rate and experiences.
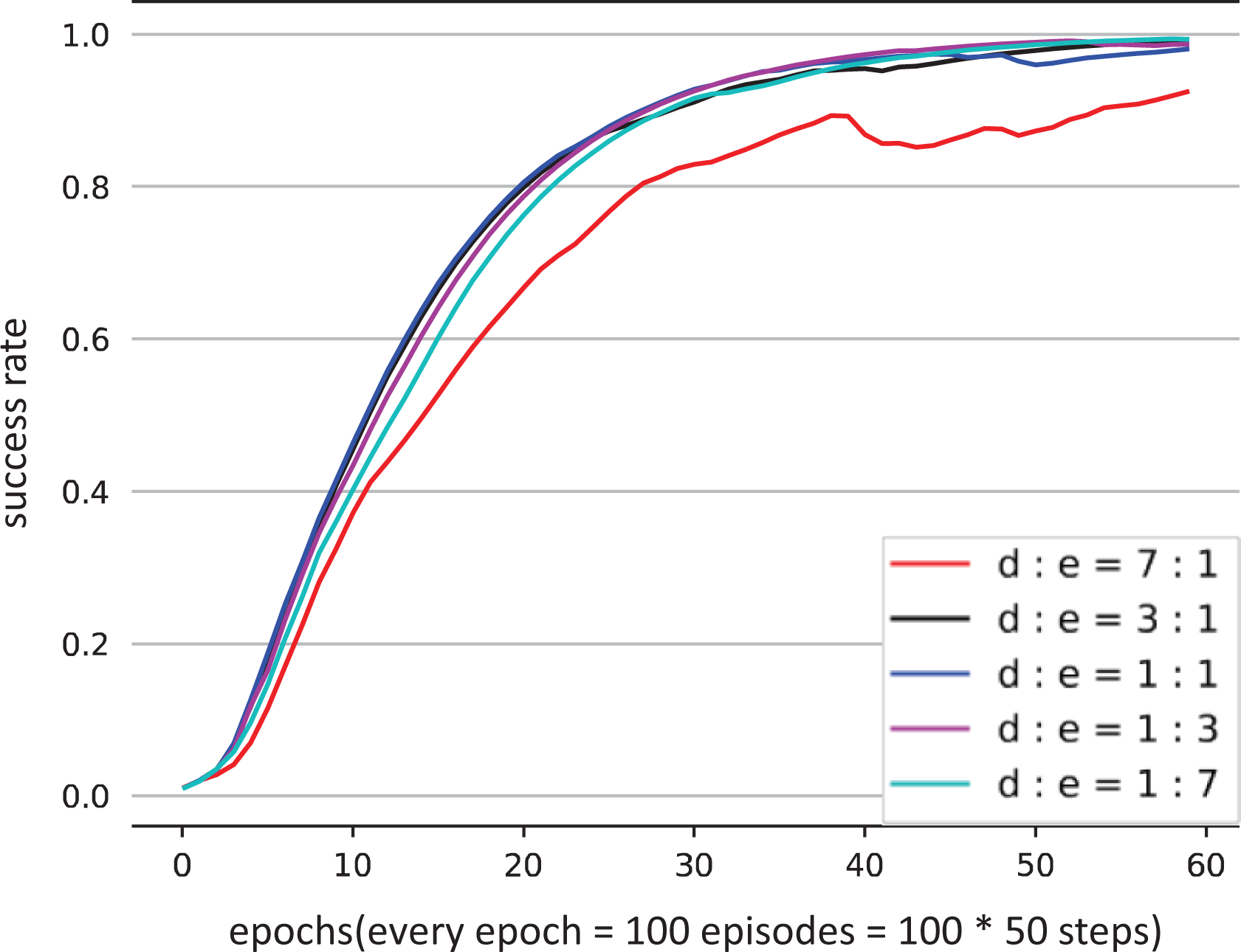
Learning curves of the pick-and-place task using different sampling ratios between demonstrations of low success rate and experiences.
We can get the following conclusions from above: generally, the sampling ratio between demonstrations and experiences does not affect the learning results of the agent. However, when the success rate of demonstrations is low, the agent still learns from a large amount of demonstrations, which will have an impact on the learning speed. Therefore, in the learning process, the sampling ratio should be kept between 1:3 and 3:1.
The effect of the action loss
In order to verify that the loss function can maintain the motion stability of the manipulator effectively, the methods both with and without action loss are performed in this experiment, in which the number of demonstrations is 2000, and the sampling ratio between demonstrations and experiences is 1:1.
Figure 14 shows the motion trajectories of the object which is grabbed by the manipulator in the pick-and-place task. The blue, cyan, black, and green curves represent the object trajectories when the hyperparameter

Motion trajectories of the object.
It is evident that the method without action loss has obvious vibrations during the operation process, especially in the target area. Although the vibration of the manipulator is very serious, the agent only knows that it has accomplished the task if the object is within 5 cm of the target point. In contrast, the method with action loss has no serious vibration during the operation process as the action loss we designed is to minimize the vibration amplitude of the output action, and larger the action loss parameter

Linear velocity curves of the object.
Conclusion
This article proposes an off-policy model-free RL algorithm which uses demonstrations to accelerate learning the robotic tasks with sparse rewards. Firstly, we design a new experience replay mechanism, CAHER, which introduces the curiosity and aggressive rewards into HER, in order to enable the agent to learn the robotic tasks only with sparse rewards effectively. Secondly, based on an off-policy RL algorithm, TD3, we use demonstration data as part of off-policy training data to accelerate learning. Finally, the action loss is added into the actor loss to make the robot action as smooth as possible. The experimental results show that our method is comparable to, even better than the other current RL methods in robotic manipulation tasks with sparse rewards. The action loss can also effectively reduce the jitter of the output action of the robot and make the output action look more like the action of human beings. The major limitation of this work is the sample efficiency of completing the harder tasks. In the next work, we will improve the sample efficiency of our method on header tasks and test it on the real robot.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Science Foundation of China (61873008) and Beijing Natural Science Foundation (4182008).