
Abstract
Vehicle detection is involved in a wide range of intelligent transportation and smart city applications, and the demand of fast and accurate detection of vehicles is increasing. In this article, we propose a convolutional neural network-based framework, called separable reverse connected network, for multi-scale vehicles detection. In this network, reverse connected structure enriches the semantic context information of previous layers, while separable convolution is introduced for sparse representation of heavy feature maps generated from subnetworks. Further, we use multi-scale training scheme, online hard example mining, and model compression technique to accelerate the training process as well as reduce the parameters. Experimental results on Pascal Visual Object Classes (VOC) 2007 + 2012 and MicroSoft Common Objects in COntext (MS COCO) 2014 demonstrate the proposed method yields state-of-the-art performance. Moreover, by separable convolution and model compression, the network of two-stage detector is accelerated by about two times with little loss of detection accuracy.
Keywords
Introduction
Vehicle detection is one of the essential tasks in surveillance systems, driver-assistance systems, and a wide range of intelligent transportation and smart city applications. With the rapid increasing of vehicles, population and complexity of traffic environments, accurate and fast vehicle detection problem has become more challenging due to the cluttered scene, variability of vehicle categories and attributes, size, camera viewpoint, and lighting variation. For real applications, vision-based vehicle detection systems should be robust, fast, and accurate so as to deal with different situation. Many efforts have been devoted to design methods and systems, yet the detection accuracy and speed are still unsatisfactory in real-world applications.
The goal of vehicle detection is to determine whether or not there are any vehicles from the given images and, if present, to return the spatial locations and some attributes, such as motor, bus, and car. Traditional vehicle detectors were mainly designed with handcrafted features, such as HOG, 1 SIFT, 2 Haar-like, 3 and sliding-window algorithms such as Selective Search 4 and Edge Box 5 were used to generate a large number of redundant windows. Due to the limited representation and discrimination ability of handcrafted features, such methods can hardly provide sufficient accuracy for detection in complex scenes.
In 2012, Krizhevsky et al. 6 proposed a deep convolutional neural network (CNN) which achieved record-breaking image classification accuracy in the large scale recognition challenge. Deep learning allows computational models consisting of multiple hierarchical layers to learn fantastically complex, subtle, and abstract representations. With the rapid progress of CNN in recent years, CNN-based vehicle detectors have also achieved remarkable performance and become dominant in detection tasks. Nevertheless, CNN and deep learning-based detectors still cannot meet the demands in real applications, particularly in the respects below.
Multiple category detection: There are many different categories of vehicles and each category has variable attributes (size, shape, and color). To simultaneously detect vehicles of multiple categories and attributes is challenging.
Multi-scale detection: Detecting vehicles at vastly different scales is challenging. Particularly, detecting vehicles of small size usually results in lower accuracy.
Speed of detection: Real-time vehicle detection is demanded in most applications, but CNN-based methods are hard to meet the demand due to the high complexity of CNN models.
Deep learning has driven significant progress in a broad range of problems. Recent years have seen big advances in CNN-based object detection to improve the accuracy and speed. CNN-based vehicle detectors can be categorized into two-stage and single-stage ones. A two-stage detector consists of a region proposal network (RPN) and a pipeline for bounding box regression and classification. Falling in this category are the famous R-CNN and its various extensions. For example, Girshick et al. 7 proposed a method to detect objects from region proposals generated by Selective Search through CNN layers. The detection speed of R-CNN was quite limited by generating a large number of proposals and classification of each proposal. Then, a fully convolutional network (FCN) and region of interest (RoI) pooling technique were applied in Girshick 8 called as fast R-CNN framework. The milestone faster R-CNN framework 9 introduced an RPN to generate proposals from convoluted features. The region-based FCN (R-FCN) uses position-sensitive feature map for more precise region proposals 10 and has achieved higher accuracy than R-CNN detectors. The deformable convolutional networks 11 also introduced geometric transformations by learning additional offsets without supervision. Lin et al. 12 proposed a feature pyramid network (FPN) for multi-scale detection through exploiting the inherent multi-scale hierarchy of deep convolutional networks. Top-down architecture with lateral connections is utilized to merge feature maps in the pyramid, and state-of-the-art performance has been achieved by the FPN framework.
Single-stage detectors directly predict objects with modified backbones so as to achieve high detection speed. The single shot multi-box detector (SSD) 13 contains different aspect ratios and scales on hierarchical feature maps for multi-scale object detection. The YOLO framework proposed by Redmon et al. 14 employed a light feature extractor and simplified the detection task as a regression problem. It performs much faster than region-based networks though its accuracy is not competitive. An extended version, YOLO v2 15 gained a great improvement in terms of speed and accuracy.
Generally, two-stage detectors achieve higher accuracy, while single-stage detectors excel in speed. Improved detection accuracy or speed has been achieved by designing more powerful or compact network structures. 16 –21 Some works also combine traditional features or filters with neural networks for improving the performance of vehicle detection. 22 –24 Fusing feature maps of different layers are shown to be beneficial for small object detection. 25,26
In this article, we propose a CNN-based framework, called separable reverse connected (SRC) network, for detecting multi-scale vehicles. In this framework, the reverse connected (RC) structure enriches the semantic context information of previous layers by a top-down pathway and lateral connections, while separable convolution (SC) is introduced for sparse representation of heavy feature maps generated from subnetworks. Further, we use multi-scale training scheme, online hard example mining (OHEM) 27 to make training process more efficient for multi-scale vehicle detection, and apply model compression technique 28 to reduce the parameters of the networks so as to accelerate detection. Experimental results on Pascal Visual Object Classes (VOC) 2007+2012 and MicroSoft Common Objects in COntext (MS COCO) 2014 demonstrate that the proposed method achieves state-of-the-art performance. Moreover, by SC and model compression, the network of two-stage detector is accelerated by about two times with little loss of detection accuracy.
Proposed method
The issues of multiple category, multi-scale and detection speed are hardly solved simultaneously by previous object detection methods, including two-stage and single-stage CNN-based ones. Some multi-scale feature fusion frameworks, such as the FPN 12 and RC network, 25 perform better for multi-scale object detection. However, they also incur increased parameters and computation complexity. Our proposed SRC network inherits the feature representation ability of RC network, and we also introduce SC to reduce the parameters and computation.
Figure 1 shows the overall structure of the proposed vehicle detection method. The backbone network extracts hierarchical convolutional features, which are fused by SRC to take full advantage of semantic context information from deeper feature maps, and SC is introduced to reduce the network parameters and computational costs. Moreover, we use training optimization and model compression techniques to further promote the network performance.

The overall structure of the proposed method.
Backbone network selection
As shown in Figure 1, the main performance of the entire system is determined by backbone network. To achieve a high-quality vehicle detector, we need to select appropriate network structure for our task of vehicle detection.
Among existing two-stage detectors, faster R-CNN is the most popular framework 29 which contains feature extraction and RPNs. R-FCN and FPN are networks which strengthen faster R-CNN in different aspects. ZF, VGG, 30 and ResNet 31 are usually adopted as the feature extractors of networks.
As for single-stage detectors, bounding boxes and class probabilities are predicted directly from full images. YOLO, 14 YOLO v2, 15 and SSD 13 are reported to be efficient. Darknet and VGG are usually used in these frameworks. The network backbones of typical vehicle detectors are listed in Table 1.
Network backbones of existing vehicle detectors.

CNN: convolutional neural network; FCN: fully convolutional network; FPN: feature pyramid network; SSD: single shot multi-box detector.
A series of comparative experiments are conducted for evaluating the performances of existing detectors with different backbones. The benchmark databases Pascal VOC0712 and MS COCO are used in the experiments. The experimental results indicate that FPN based on faster R-CNN 12 achieves the best performance among two-stage detectors. For single-stage detectors, the overall performance of SSD500 13 and YOLOv2 15 are similar. Therefore, faster R-CNN and YOLO are selected to be our backbone base networks. Details of implementation setting and experimental results are discussed in subsequent section.
SRC network
Our purpose is to enhance a CNN-based framework’s feature hierarchy, which has semantics from low to high levels, and build a feature pyramid with high-level semantics throughout. To this goal, we proposed an SRC network for efficient multi-scale vehicle detection.
First, SC is introduced in SRC network for parameters reduction as well as compact representation of feature maps. Recently, the series of inception-based neural networks are proposed and considered to be efficient. 32 –34 SC can be understood as an inception module with a maximally large number of towers. Chollet 35 claimed that after replacing inception module with SC, the performance of the deep convolution neural network achieved improvements in detection tasks, which brings the idea of flexible building blocks with deeper convolutions. SC has been adopted in faster R-CNN-based method 19 and achieved good trade-off between performance and computational speed through more efficient use of model parameters.
Usually, a convolution layer attempts to learn filters in a three-dimensional (3-D) space with a two spatial dimensions and a channel dimension. Thus, a single convolution kernel is tasked with simultaneously mapping cross-channel correlations and spatial correlations. SC is usually implemented as first depth-wise spatial convolution and then point-wise convolution. Specifically, SC separates the original

Illustration of separable convolution. SC: separable convolution.
According to this way, SC can not only be able to provide sparse representation of features but also make the network efficient. To obtain more compact feature maps, we attach two normal convolution layers to the SC layer. The resulting feature maps will be applied to build feature pyramids by the subsequent RC network.
Multi-scale detection has been the key problem of vehicle detection in real applications. It is shown that multi-scale representation can significantly improve detection performance of objects with various scales. 29 Featured image pyramids were widely used in the era of handmade features which proved to be critical for achieving good results.
For CNN-based methods, features computed by a deep convolutional network are inherent in multi-scale, pyramidal shape, and the resulting feature maps are of different spatial resolutions. However, large semantic gaps caused by different depths are inevitably incurred. The upper layers have larger receptive fields and strong semantics, while the lower layers have smaller receptive fields and rich geometric details. Clearly, it is not optimal to predict objects of different scales using features from one layer. The method proposed in Kong et al. 25 implemented multi-scale detection by detecting objects with different sizes on their corresponding network scales and achieved good performance.
Recently, combining fine-grained features with previous high-resolution feature maps of deeper layers is applied in several multi-scale detection tasks. One of the representative works is FPN, 12 which uses a top-down pathway and lateral connections.
Inspired by the previous works and driven by the success, we introduce an RC network to create a feature pyramid across all scales based on CNN feature hierarchy. Reverse connection adopted in RC network enables the network to detect vehicles on multi-level of CNNs. The proposed RC network has the similar architecture with FPN. 12 However, FPN simply merges the feature maps by 2× up-sampling, whereas in our network, deconvolution layer is used to connect with deep feature maps so as to enrich the semantic context information of previous layers. The proposed RC network performs as a feature pyramid, where predictions are independently made on each level, which makes multi-scale vehicle detection more precise. Structure of the proposed network is shown in Figure 3.

The structure of FPN and the proposed RCN. FPN: feature pyramid network; RCN: Reverse Connected network.
By integrating SC and reverse connection, the resulting SRC network provides a novel solution for feature map fusion and multi-scale detection while saving computation cost through reducing network parameters. The SRC network accomplishes multi-scale vehicle detection on their corresponding network scales, which is more accurate and easier to be optimized. Moreover, the SRC network can be trained end-to-end with all scales and is used consistently at train/test time, which would be memory friendly.
Figure 4 gives the detailed pipeline of the proposed vehicle detection system. Specifically, after a single-scale image of an arbitrary size is fed into the system, the backbone network extracts hierarchical convolutional features, which are fused by SRC to take full advantages of semantic context information from deeper feature maps. Vehicles are predicted in multiple scales using the rich semantic context information derived from the RC network. The top layer is for predicting vehicles with large size (such as buses and trucks), while the middle layer and the bottom layer are for middle size vehicles (most cars) and small size vehicles (most motors and partial cars), respectively.

Pipeline of the proposed vehicle detector.
The proposed SRC network is actually a generic feature extractor creating feature pyramids with semantic context information. Advances on optimization technique, such as hard example mining, could be naturally employed. Moreover, as an independent structure, it can be easily applied inside deep convolutional networks. The comparative experiments show that faster R-CNN-based methods 31 achieve competitive performances among two-stage detectors, while YOLOv2 15 is more potential single-stage detector. Therefore, the proposed SRC network is combined with faster R-CNN and YOLO respectively with the hope of achieving more efficient two-stage and single-stage detectors.
Optimization
The field of object detection has made significant advances riding on the wave of deep CNN. For further improvements, network training optimization, model refining, and multi-scale training are still necessary.
For vehicle detection problem in real-world scenes, negative examples (non-vehicle) are dominated, which unbalances the positive and negative training examples. Besides, hard examples appear much more often in vehicle detection problems due to the cluttered scenes in real applications. All this make network training inefficient since training deep convolutional network detectors typically requires hundreds of thousands of stochastic gradient decent (SGD) steps. To address these problems, Shrivastava et al. 27 proposed a method named OHEM, in which the loss values of all region proposals in an input image are calculated by the current classifier and only examples with the largest losses are picked for a minibatch. Therefore, by taking this reweighting scheme, OHEM can improve training efficiency as well as accuracy compared with heuristic methods.
In this article, we make use of OHEM algorithm modifying the loss layers to implement hard example selection. For RoIs generated from RPN, the loss layers sort them by computing loss for hard example searching and set non-hard RoIs to be 0. By this way, OHEM finally leads to a faster and more stable network.
From the perspective of practical application, two-stage detectors are always lack of efficiency due to expensive computational costs and intensive memory. Model compression technique can be a potential solution. In our work, parameter pruning 28 is applied for complexity reduction and over-fitting alleviation. After the connectivity via network training is learnable, the weak connections under a certain threshold are removed from the network. Then we retrain the network to learn the final weights for the remaining sparse connections. The number of parameters of original network can be reduced by about 10 times after several times of operations.
Quantization and weight sharing 28 are also introduced for further compressing the pruned network, which reduces the number of bits used to represent each weight. Specifically, all the weights quantized in the same bin share the same value, so the storage of parameters is taken placed by small indexes. Then the original 32-bit weights can be replaced with 2-bit units which are indexes of the codebook corresponding to the centroid of their cluster. Thus, multiple weights can share the same values. The weights fall into the same cluster are modified and fully trained to approximate to the weights of original network.
To accomplish the goal of multi-scale vehicle detection, we employ multi-scale training scheme proposed in the literature 15,36 to make network more robust. Simply to say, only a portion of images in data set are selected, then the selected images are resized in certain scales to make the images with sizes from 256 × 256 to 608 × 608. Finally, some of the resized images are chosen randomly for training.
Experimental results and discussion
Data sets
In this section, we evaluate the existing typical detectors as well as the proposed method. Data sets Pascal VOC 0712 and MS COCO are widely applied in object detection evaluation. 37 Data set Pascal VOC 0712 covers 20 categories closing to real-world application with many difficult samples, and it creates the precedent for standardized evaluation of object detection competitions.
Data set MS COCO consists of images with complex everyday scenes, which contain more instances of objects and richer annotation information. It has become the most widely used data set for generic object detection.
Both of Pascal VOC 0712 and MS COCO contains multi-scale vehicles in natural environments with multi-categories, such as car, bus, truck, motor and person. Therefore, the two data sets are adopted in our evaluation experiments.
Pascal VOC 07 trainval and Pascal VOC 12 trainval are used for training, while Pascal VOC 07 test set is applied for evaluation. As for MS COCO, there are 80k train set and 40k validation set. Following a common practice, we further split the 40k validation set into 35k
Evaluation criteria
Generally, there are three criteria for evaluating the performance of detection algorithms: detection speed (frames per second (FPS)), precision, and recall. The most commonly used metric is
Since there are multi-category objects in detection, AP is often computed for each category of object separately and mean AP (mAP) averaged over all object categories is adopted as the final measure of performance.
The definitions of criteria adopted in different data sets are slightly different. Pascal-style AP takes a single IoU threshold of 0.5. For MS COCO data set,
As said before, the proposed method can be utilized for generic object detection, but we focus on vehicle detection in this article. Therefore, we compute the AP for each vehicle category (such as motor, car, and bus) and overall average mAP for Pascal VOC 0712 data set. Following a common practice,
Implementation details
Our detectors are end-to-end trained on a GTX 1080 GPU using SGD with a weight decay of 0.0001 and momentum of 0.9. Learning rate is set to 0.001 at the beginning of the training process and then decreased by a factor of 0.1 every 50k iterations after 90k iterations. The batch size is optimally set to 16 by an experimental way.
Experimental results
For comparison of different vehicle detectors based on CNNs, we conduct a series of comparative experiments for evaluating the performances of existing frameworks as well as the proposed SRC method using the same image data sets and training schemes.
As for two-stage detectors, we first run the experiments to investigate the existing typical networks with different backbones and find that methods with backbone of ResNet101 perform better than ZF and VGG, while ZF consumes less computation costs due to fewer parameters. Both R-FCN 10 and FPN 12 achieve good performances by modifying faster R-CNN in terms of region proposal and feature representation. Taking advantages of feature pyramids, FPN method obtains the best results, especially on smaller vehicle detection.
Based on the above observations, we combine the proposed SRC network with faster R-CNN of ResNet101 to build a two-stage detector. As the SRC network consists of SC and RC network, experiments are conducted separately to explore the impact of each part on detection performance, which are denoted as faster R-CNN+SC, faster R-CNN+RC, and faster R-CNN+SRC, respectively. The overall experimental results are shown in Tables 2 and 3.
Evaluation results of two-stage detectors on Pascal VOC testset.a

CNN: convolutional neural network; FCN: fully convolutional network; FPN: feature pyramid network; mAP: mean average precision; FPS: frames per second; SC: separable convolution; RC: reverse connected; SRC: separable reverse connected.
aThe bold values emphasize the best results achieved.
Evaluation results of two-stage detectors on MS COCO testset.a

CNN: convolutional neural network; FCN: fully convolutional network; FPN: feature pyramid network; AP: average precision; mAP: mean average precision; AP: average precision; FPS: frames per second; SC: separable convolution; RC: reverse connected; SRC: separable reverse connected.
aThe bold values emphasize the best results achieved.
From the results, we can see that after combining with SC, detection speed of faster R-CNN network has been increased by more than two times with slight loss of accuracy, which demonstrates the ability of SC on computation cost reduction. The RC network significantly improves detection performance of faster R-CNN, while detection speeds are almost the same. The improvements are benefited from the RC structure which enriches the semantic context information of previous layers. Further, the proposed SRC combined with faster R-CNN achieves the best performance both in detection accuracy and speed. Specifically, the proposed SRC detector increases mAP by six points on Pascal VOC and seven points on COCO data sets. APs of small vehicle detection are higher than those of faster R-CNN by six points on Pascal VOC and seven points on COCO data sets, respectively. The solid and consistent detection improvements demonstrate the effectiveness of the proposed SRC network. Some detection examples are shown in Figures 5 and 6.

Detection results of faster R-CNN + SRC on Pascal VOC testset. CNN: convolutional neural network.

Detection results of faster R-CNN + SRC on COCO testset. CNN: convolutional neural network; SRC: separable reverse connected.
As for typical single-stage detectors, SSD, YOLO, and YOLOV2 with different backbones are investigated. It is shown that YOLOv2 with Darknet achieves the best detection accuracy on Pascal data set and slightly worse than SSD500 on COCO data set, while the detection speed of YOLOV2 is almost two times of other single-stage detectors. Consequently, we combine the proposed SRC network with YOLOV2.
Tables 4 and 5 give the experimental results of single-stage detectors. The SRC method increases over the best results by five points and two points on Pascal and COCO data set, respectively. On COCO data set, the proposed method increases AP of small vehicle detection by five points (13.8 vs. 8.7), mostly because of the powerful feature representation ability of SRC. It can be noted that the proposed SRC single-stage detector largely increases detection accuracy, while detection speed is still competitive. It can be seen that performances on detecting car and bus are improved more than that on motor. The reasons are considered as that SC is mainly designed for parameter reducing so as to save computation costs. Some detailed features contained in small objects, such as motor, may be neglected, while those contained in larger objects survive. Therefore, although performance of detecting motor is improved by the SRC, improvement is less than those on detecting car and bus.
Evaluation results of single-stage detectors on Pascal VOC testset.a
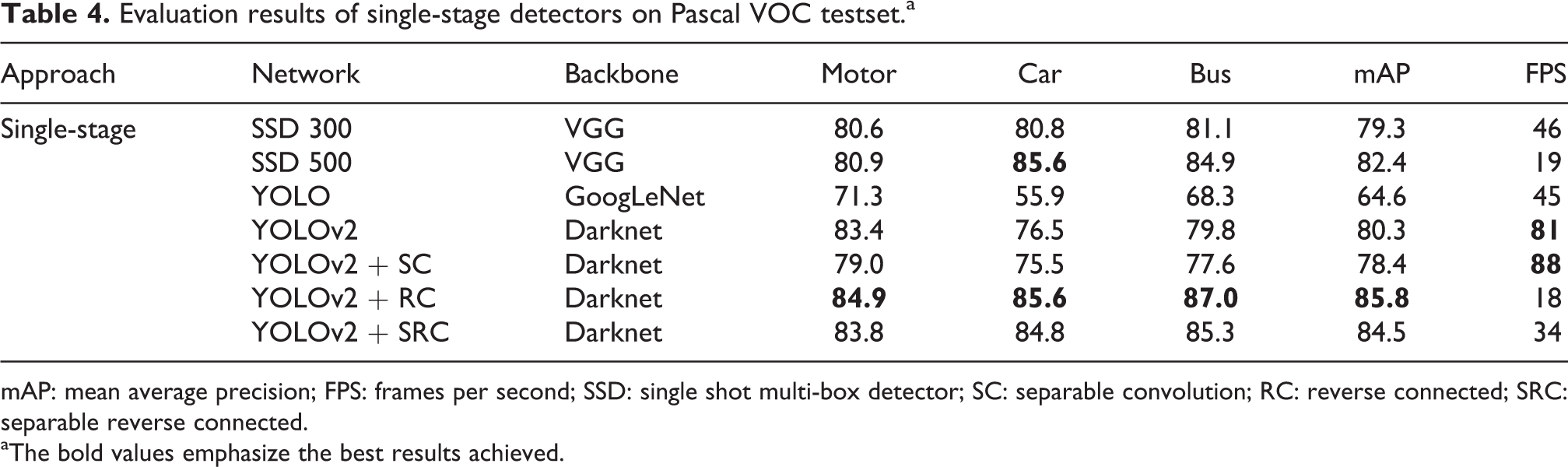
mAP: mean average precision; FPS: frames per second; SSD: single shot multi-box detector; SC: separable convolution; RC: reverse connected; SRC: separable reverse connected.
aThe bold values emphasize the best results achieved.
Evaluation results of single-stage detectors on MS COCO testset.a

AP: average precision; mAP: mean average precision; FPS: frames per second; SSD: single shot multi-box detector; SC: separable convolution; RC: reverse connected; SRC: separable reverse connected.
aThe bold values emphasize the best results achieved.
As an independent network, the proposed SRC network can be easily combined with either two-stage or single-stage detector. The resulting two-stage detector achieves higher detection accuracy with higher speed, while the resulting single-stage one significantly improves detection accuracy with competitive speed. Some detection examples of single-stage YOLOV2 + SRC are shown in Figures 7 and 8.

Detection results of YOLOv2 + SRC on Pascal VOC testset. SRC: separable reverse connected.

Detection results of YOLOv2 + SRC on COCO testset. SRC: separable reverse connected.
As described in the previous section, optimization methods, such as multi-scale training, OHEM, 27 and model compression, 28 are applied in our method. To make clear of the effectiveness of each optimization technique, we run several experiments on Pascal and COCO data sets. FSRC is used to represent the original version of the proposed SRC method, FSRC+ to represent the original version applied with multi-scale training, and FSRC++ to represent the original version applied with multi-scale training and OHEM. Besides, FSRC++A and FSRC++B denote the cases of application of model compression with different intensities.
The experimental results of two-stage detector on optimization are presented in Tables 6 and 7. It can be seen that the optimized SRC networks improve the detection accuracy of the original SRC method by about 1% mAP of vehicles on Pascal VOC0712 and about 2% mAP of vehicles on MS COCO. It is noted that the application of model compression significantly increases detection speed, which makes the proposed method be capable for real-time vehicle detection.
Multi-scale training, OHEM algorithm, and model compressing applied to the SRC of two-stage detector on Pascal VOC testset.a

OHEM: online hard example mining; SRC: separable reverse connected; mAP: mean average precision; FPS: frames per second.
a A and B indicate the different intensity of model compressing. The bold values emphasize the best results achieved.
Multi-scale training, OHEM algorithm, and model compressing applied to the SRC of two-stage detector on MS COCO testset.a

OHEM: online hard example mining; SRC: separable reverse connected; AP: average precision; mAP: mean average precision; FPS: frames per second.
a A and B indicate the different intensity of model compressing. The bold values emphasize the best results achieved.
Single-stage detectors have the advantages of simple structure and high detection speed, but detection accuracy is not satisfied. In this case, only multi-scale training has been applied to the proposed single-stage detector, denoted as YSRC+. Besides, YSRC++A and YSRC++B denote the cases of application of model compression with different intensity. Tables 8 and 9 give the comparison results on Pascal VOC and MS COCO, respectively. It is shown that the application of multi-scale training significantly improves the detection accuracy of the SRC single-stage detector. Applying model compression technique to single-stage SRC detector, detection speed is accelerated by two times, while detection accuracy decreases to some degree. Since single stage-detector already has an advantage in speed, more efforts should be put on improving detection accuracy.
Multi-scale training and model compressing applied to SRC of single-stage detector on Pascal VOC testset.a

SRC: separable reverse connected; mAP: mean average precision; FPS: frames per second.
aThe bold values emphasize the best results achieved.
Multi-scale training and model compressing applied to SRC of single-stage detector on MS COCO testset.a

SRC: separable reverse connected; AP: average precision; mAP: mean average precision; FPS: frames per second.
aThe bold values emphasize the best results achieved.
Conclusions
We have proposed a CNN-based framework, called SRC network, for multi-category and multi-scale vehicles detection. The RC structure enriches the semantic context information of previous layers, while SC is introduced for sparse representation of heavy feature maps generated from subnetworks. Multi-scale training, OHEM strategy, and model compression technique are applied for improving and accelerating detection task. The proposed method shows significant improvements over several strong baselines. By SC and model compression, the network of two-stage detector is accelerated by about two times with little loss of detection accuracy. The resulting single-stage detector largely increases detection accuracy, while detection speed is still competitive. Finally, despite the strong feature representation ability achieved by SRC, it is still critical to explore the solution to multi-scale detection problems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.